
[网络研讨会文摘] Orbit 中的 SEO:重复内容的新视角
已发表: 2019-11-20网络研讨会关于重复内容的新观点是 SEO in Orbit 系列的最后一集,于 2019 年 6 月 24 日播出。在这一集中,与 OnCrawl 大使 Omi Sido 和 Alexis Sanders 一起探讨重复内容的问题。 他们解决的问题如下:排名因素和不断发展的搜索技术如何影响我们处理重复内容的方式? 并且:网络上类似内容的未来会怎样?
Orbit 中的 SEO 是第一个将 SEO 送入太空的网络研讨会系列。 在整个系列中,我们与一些最优秀的 SEO 专家讨论了技术 SEO 的现在和未来,并于 2019 年 6 月 27 日将他们的重要技巧发送到了太空。
在这里观看重播:
介绍亚历克西斯·桑德斯
Alexis Sanders 在 Merkle 担任技术 SEO 客户经理。 SEO 技术团队确保该机构的技术建议在所有垂直领域的准确性、可行性和可扩展性。 她是 Moz 博客的撰稿人,也是 TechnicalSEO.expert 挑战和 SEO in the Lab 播客的创建者。
本期节目由近江西多主持。 Omi 是一位经验丰富的国际演说家,并以其幽默感和提供可操作见解的能力而闻名于业界,观众可以立即开始使用。 从为一些世界上最大的电信和旅游公司提供 SEO 咨询到在 HostelWorld 和 Daily Mail 管理内部 SEO,Omi 喜欢深入研究复杂的数据并寻找亮点。 目前,Omi 是 Canon Europe 的高级技术 SEO 和 OnCrawl 大使。
什么是重复内容?
Omi 提供了以下重复内容的定义:
与相同(或不同)网站上不同 URL 上的内容相似或几乎相似的重复内容。
重复内容处罚的神话
没有重复的内容惩罚。
这是一个性能问题。 我们不希望机器人查看两个特定的 URL,并认为它们是两个不同的内容,可以彼此相邻排列。
Alexis 将机器人对您网站的理解与 Joey 在《我讨厌你的 10 件事》中的图片进行了比较:机器人不可能找到两个版本之间的实质性差异。

您希望避免在搜索引擎排名情况下有两个完全相同的事物必须相互竞争。 相反,您希望拥有可以在搜索引擎中排名和执行的单一、整合的体验。
用户和机器人看到的区别
用户可能会看到一个令人信服的 URL,但机器人可能仍会看到多个看起来基本相同的版本。
– 对超大型网站的抓取预算的影响
对于非常大的网站(例如 Zillow 或 Walmart),不同页面的抓取预算可能会有所不同。
正如 Alexis 在 2018 年一篇基于 Frederic Dubut 在 SMX East 的演讲的文章中所讨论的那样,预算设置在不同的级别——在子域级别,在不同的服务器级别。 搜索引擎,无论是 Google 还是 Bing,都希望成为礼貌的爬虫; 他们不想降低实际用户的性能。 每当他们感觉到性能发生变化时,他们就会退缩。 这可能发生在不同的级别,而不仅仅是站点级别。
如果您有一个庞大的网站,您希望确保提供与您的用户相关的最统一的体验。
重复内容是内容还是技术问题?
尽管“重复内容”中有“内容”一词,但它在一定程度上是一个技术问题。
– 重复来源 – [07:50]
有很多因素会导致重复。 即使是部分列表似乎也可以永远持续下去:
- 重复页面
- 临时站点
- HTTP 与 HTTPS URL
- 不同的子域
- 不同的案例
- 不同的文件扩展名
- 尾部斜线
- 索引页
- 网址参数
- 刻面
- 排序
- 适合打印的版本
- 门口页
- 存货
- 联合内容
- 公关发布
- 重新发布内容
- 抄袭内容
- 本地化内容
- 稀薄的内容
- 仅图像
- 内部网站搜索
- 单独的移动站点
- 非唯一内容
- …
– 技术 SEO 和内容之间的问题分布
事实上,这些重复内容的来源可以分为技术和开发来源以及基于内容的来源,有些则属于两者之间的重叠区域。
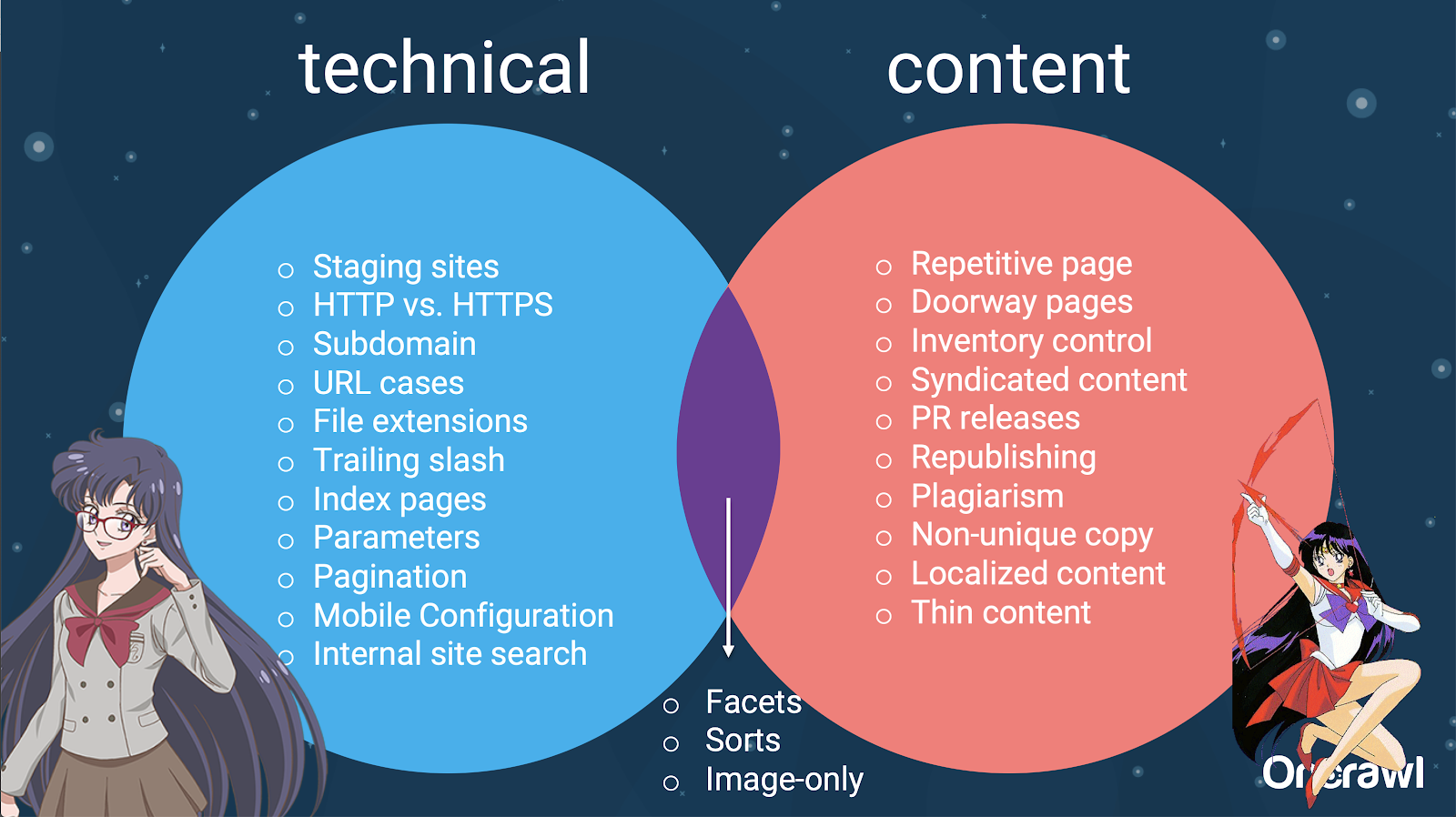
这使得重复内容成为一个跨团队的问题,这也是它如此有趣的部分原因。
如何查找重复的内容
大多数重复的内容是无意的。 对于 Omi,这表明内容和技术团队之间有共同的责任来查找和修复重复的内容。
– Omi 最喜欢的工具:Grammarly
Grammarly 是 Omi 最喜欢的查找重复内容的工具,它甚至不是 SEO 工具。 他使用抄袭检查器。 他要求内容发布者检查是否已经在其他任何地方发布了新内容。
- 无意重复内容的数量
无意重复内容的问题是工程师非常熟悉的问题。 在一本名为 Introduction to Information Retrieval (2008) 的书中,这本书显然已经过时了,他们估计当时大约 40% 的网络是重复的。

– 优先处理重复内容的策略
要处理重复的内容,您应该:
- 从了解您的用户旅程开始,这将帮助您了解每条内容的适合位置。 这可能很难做到,尤其是在 20 年前制作网站的时候,当时我们不知道它们会变得多大,也不知道它们会如何扩展。 了解您的用户在他们旅程中的任何给定点的位置将帮助您在接下来的一些步骤中确定优先级。
- 您需要一个有效的层次结构,以便为每种类型的内容提供一个位置。 在处理重复内容的步骤中,了解您的信息架构非常重要。
- 优先考虑影响性能的重复内容。 上面的部分来源列表太长了,你不能一次真正地攻击。
- 处理 100% 重复
- 信号重复内容
- 就如何处理重复做出战略选择:整合、创建、删除、优化
- 处理被盗内容

– 工具:在 OnCrawl 中使用分段
Alexis 非常喜欢在 OnCrawl 中对您的网站进行细分的能力,这使您可以深入研究对您有意义的事情。
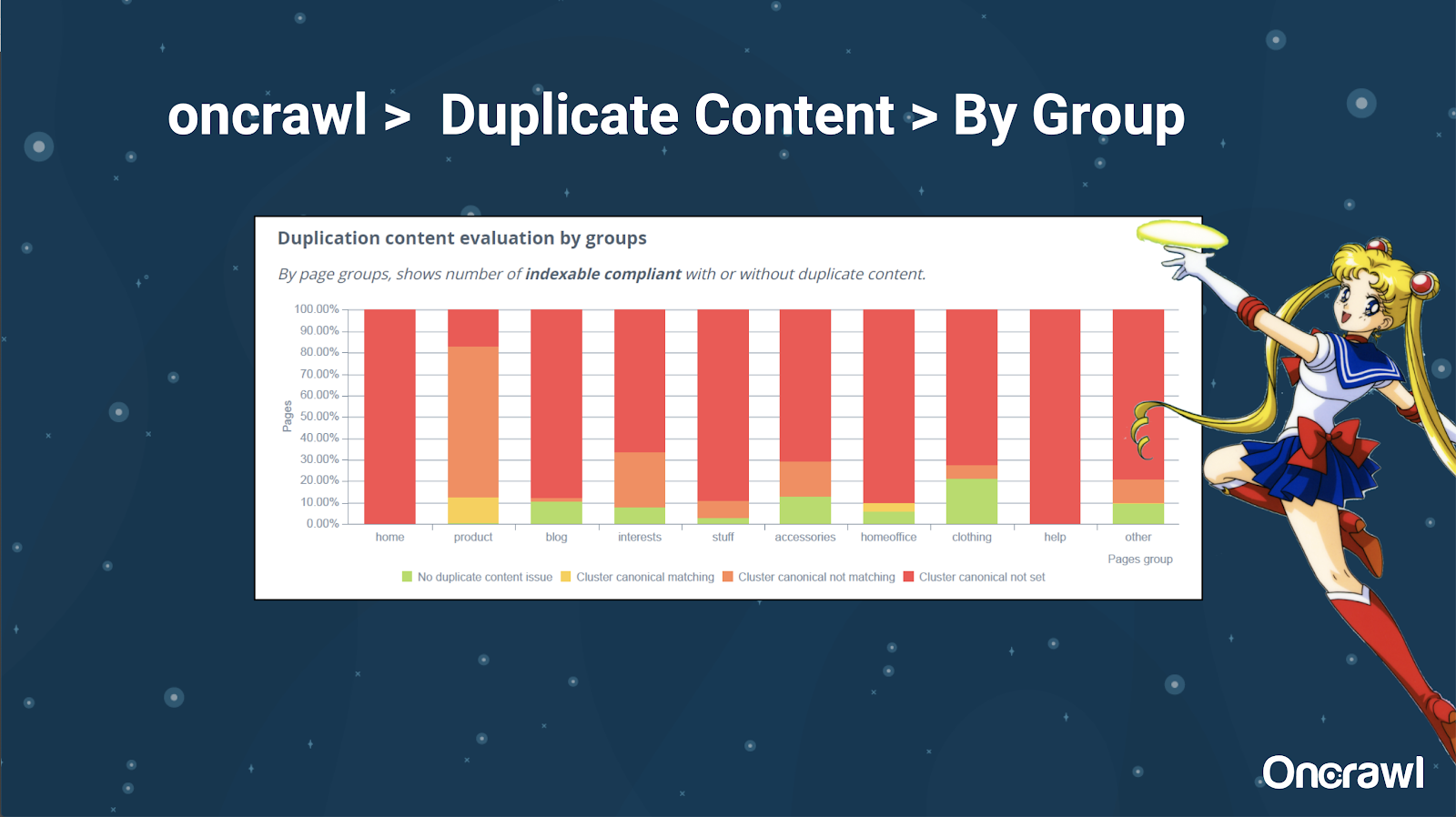
不同类型的页面有不同的重复量; 这允许查看问题最多的部分。 在上面的示例中,该站点需要大量关注。
– 工具:谷歌搜索和 GSC
您还可以使用搜索引擎本身检查重复的内容。 在 Google 中,您可以:
- 使用直接引号
- 使用站点:搜索
- 使用额外的运算符,如 inurl:、intitle: 或 filetype:

Google Search Console 还添加了重复内容报告,这对于从他们的角度识别 Google 认为是重复内容的内容非常有用。
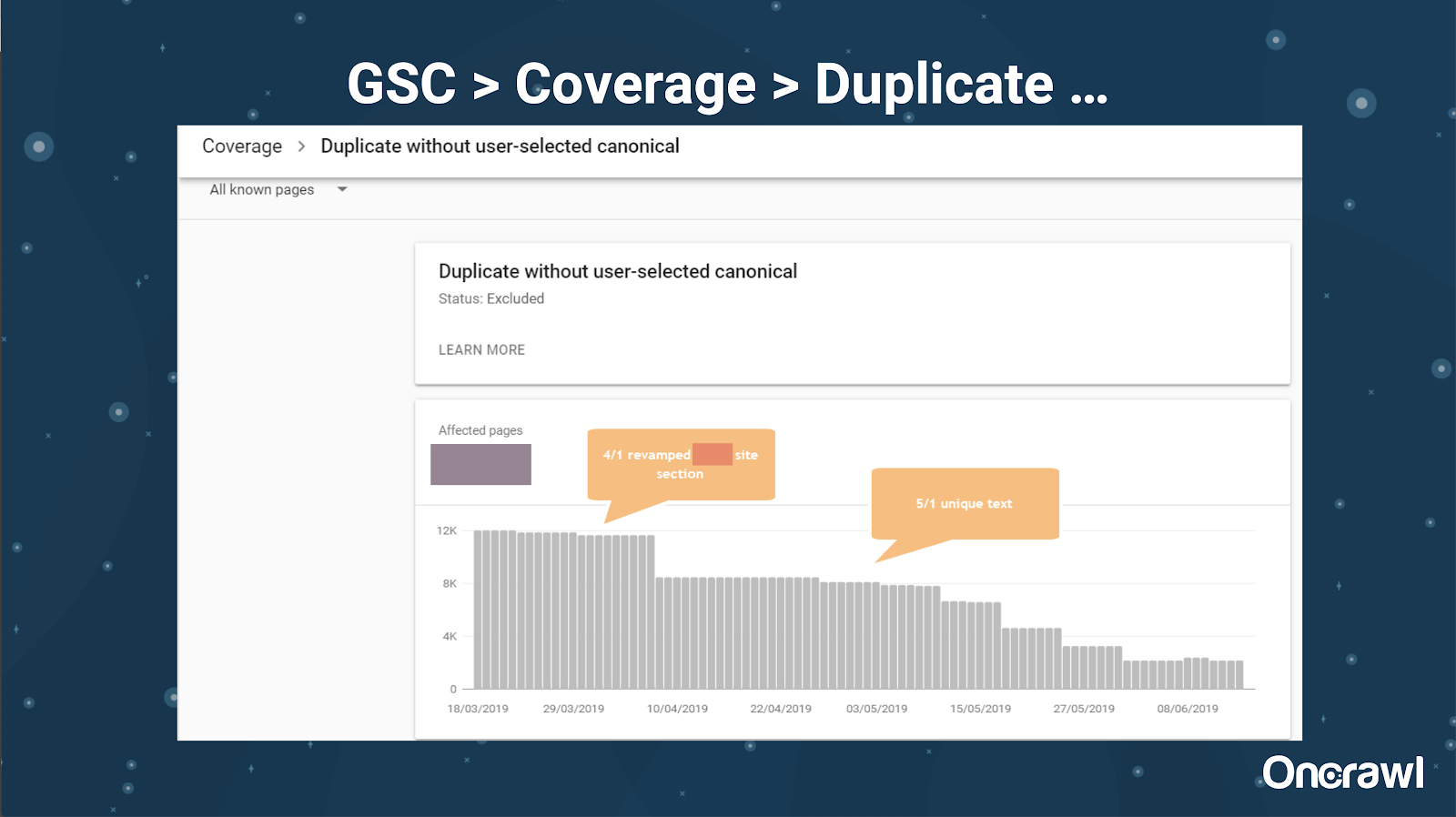
– 工具:抄袭工具
和 Omi 一样,Alexis 也使用不同的抄袭工具:
网文
诺普拉格
纸评者
语法
复制景观

您要确保您的内容不仅是原创的,而且从机器人的角度来看,它不会被认为是从其他来源获取的。
这些还可以帮助您在文章中找到可能与 Internet 上其他地方的内容相似的片段。
亚历克西斯喜欢我们拥有这些工具的方式,这些工具使我们能够“同情搜索引擎机器人”,因为我们都不是机器人。 当工具向我们发出内容过于相似的信号时,即使我们知道存在差异,这也是一个好兆头,有一些东西需要挖掘。
– 工具:关键字密度工具
Alexis 使用的关键字密度工具的两个示例是:
标记人群
搜索引擎优化书
取决于网站类型的问题
解决重复内容实际上取决于您发布的内容类型和您面临的问题类型。 例如,博客不会像电子商务网站那样面临重复内容的情况。
难忘的案例
Alexis 分享了她最近发现令人难忘的重复内容问题的客户案例。
- 大型网站:添加独特内容后的结果
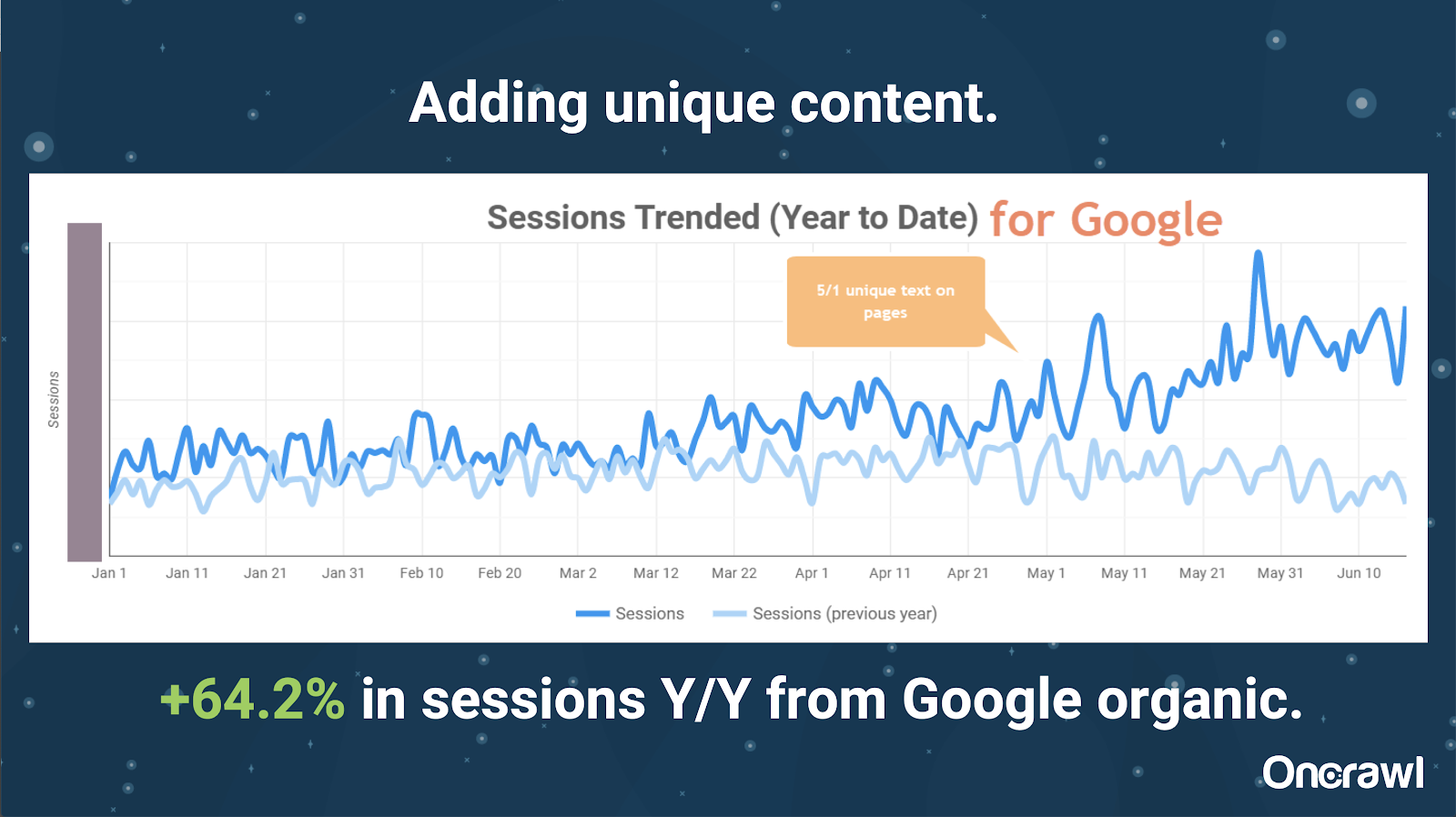
这个网站非常大,并且遇到了抓取预算问题。 它有 8600 万页尚未编入索引,其中只有大约 1% 的页面已编入索引。
这是一个房地产网站,很多内容并不是特别独特,而且他们的很多页面都非常非常相似。 Alexis 最终将内容添加到页面以添加特定于位置的信息以区分页面。 令人惊讶的是,它产生结果的速度如此之快。 (这只是谷歌的有机数据。)
对于亚历克西斯来说,这是一个非常通用的案例研究。 尽管我们今天谈论 EAT 和类似的事情,这表明只要搜索引擎认为内容是独特且有价值的,那仍然会得到回报。

在这个网站上,一个偶然的规范标签问题导致大约 250 个页面被发送到错误的协议。
这是规范标签指示错误的主要页面的一种情况,将 HTTP 页面推送到 HTTPS 页面的位置。
过去 18 个月的变化
亚历克西斯在本次网络研讨会前大约 18 个月写了一篇非常完整的文章,重复内容和战略解决方案。 SEO 变化迅速,您需要不断更新和重新评估您的知识。
对于 Alexis,文章中提到的大部分内容在今天仍然适用,但 rel=next/prev 除外。 不过,她希望它在未来五到十年内不再适用。
开发人员处理的技术问题:过于手动
许多与开发人员处理的重复内容相关的问题都过于手动。 Alexis 认为它们应该由 CMS 和 Adobe 来处理。 例如,您不必手动完成并确保所有规范都已设置且连贯。
– 自动化/通知机会
在重复内容的技术问题领域,自动化有很多机会。 举个例子:我们应该能够在任何链接应该转到 HTTPS 时立即检测到是否有任何链接转到 HTTP,并纠正它们。
– 站点年龄和遗留基础设施是一个障碍
一些后端系统太旧,无法支持某些更改和自动化。 将旧的 CMS 迁移到新的 CMS 非常困难。 Omi 给出了将佳能网站迁移到新的定制 CMS 的示例。 这不仅昂贵,而且花了他们 12 个月的时间。
Rel prev/next 和来自 Google 的通信
有时来自谷歌的沟通有点令人困惑。 Omi 举了一个例子,在应用 rel=prev/next 时,他的客户在 2018 年看到了性能的显着提升,尽管谷歌在 2019 年宣布这些标签已经多年没有使用了。
– 缺乏一刀切的解决方案
SEO 的困难在于,一个人在他们的网站上观察到的事情不一定与另一个 SEO 在他们自己的网站上看到的一样。 没有一刀切的 SEO。
谷歌发布与所有 SEO 相关的公告的能力应该被认为是一项重大成就,甚至他们的一些声明也是一个失误,比如 rel=next/prev 的情况。
希望重复内容管理的未来
亚历克西斯对未来的希望:
- 较少基于技术的重复内容(作为 CMS 明智的做法)。
- 更多的自动化(单元测试和外部测试)。 例如,像 OnCrawl 这样的工具可能会定期抓取您的网站,并在发现某些错误时立即通知您。
- 为作者和内容管理者自动检测高相似度页面和页面类型。 这将使目前在 Grammarly 等工具中手动完成的一些验证自动化:当有人尝试发布时,CMS 应该说“这有点相似——你确定要发布这个吗?” 查看单个网站以及跨网站比较具有很多价值。
- 谷歌继续改进他们现有的系统和检测。
- 也许是一个警报系统来升级 Google 未使用正确规范的问题。 能够提醒谷歌注意这个问题并解决它会很有用。
我们需要更好的工具,更好的内部工具,但希望随着谷歌开发他们的系统,他们会添加一些元素来帮助我们。
亚历克西斯最喜欢的技术技巧
Alexis 有几个最喜欢的技术技巧:
- EC2 远程计算机实例。 这是访问真实计算机以进行非常大的爬网或需要大量计算能力的任何事情的一种非常好的方法。 设置好后速度非常快。 只要确保在完成后终止它,因为它确实需要花钱。
- 检查移动优先测试工具。 谷歌已经提到这是他们正在查看的最准确的图片。 它着眼于 DOM。
- 将用户代理切换到 Googlebot。 这将使您了解 Googlebot 真正看到的内容。
- 使用 TechnicalSEO.com 的 robots.txt 工具。 这是 Merkle 的工具之一,但 Alexis 真的很喜欢它,因为 robots.txt 有时会让人很困惑。
- 使用日志分析器。
- 用 Love 的 htaccess 检查器制作。
- 使用 Google Data Studio 报告更改(将表格与更新同步,按相关更新过滤每个页面)。
技术 SEO 难点:robots.txt
Robots.txt 真的很混乱。
这是一个过时的文件,看起来应该能够支持 RegEx,但事实并非如此。
它对禁止和允许规则有不同的优先规则,这可能会让人感到困惑。
不同的机器人可以忽略不同的事情,即使他们不应该这样做。
你对什么是正确的假设并不总是正确的。

问答
– HSTS:是否需要拆分协议?
如果您有 HSTS,则必须拥有所有 HTTPS 才能获得重复内容。
– 翻译内容是否重复内容?
通常,当您使用 hreflang 时,您是在使用它来消除同一语言中的本地化版本之间的歧义,例如美国和爱尔兰英语页面。 Alexis 不会考虑这种重复的内容,但她肯定会建议您确保正确设置 hreflang 标记,以表明这是相同的体验,并针对不同的受众进行了优化。
– 您可以使用规范标签而不是 301 重定向来进行 HTTP/HTTPS 迁移吗?
检查 SERP 中实际发生的情况会很有用。 亚历克西斯的直觉是说这没关系,但这取决于谷歌的实际行为。 理想情况下,如果这些是完全相同的页面,您会希望使用 301,但她曾看到规范标签过去适用于这种类型的迁移。 事实上,她甚至亲眼目睹了这种意外发生。
以 Omi 的经验,他强烈建议使用 301s 来避免问题:如果您正在迁移网站,您不妨正确迁移它以避免当前和未来的错误。
– 重复页面标题的影响
假设您有一个在不同位置非常相似的标题,但内容却大不相同。 虽然这对亚历克西斯来说不是重复的内容,但她认为搜索引擎将其视为“整体”类型的东西,标题是可以用来识别可能存在问题的区域的东西。
这是您可能想要使用 [site: + intitle: ] 搜索的地方。
但是,仅仅因为您有相同的标题标签,它不会导致重复的内容问题。
即使在分页或其他非常相似的页面上,您仍然应该瞄准独特的标题和元描述。 这不是由于重复的内容,而是与优化您在 SERP 中呈现页面的方式有关。
最重要的提示
“重复内容既是技术挑战,也是内容营销挑战。”
Orbit 中的 SEO 进入太空
如果您错过了 6 月 27 日的太空之旅,请点击此处了解我们发送到太空的所有提示。