
使用 Python 和站点地图来审核内容策略
已发表: 2020-10-08使用 Python 库代表 SEO 可以做什么的兴趣不再是秘密。 但是,大多数没有编程经验的人在导入和使用大量库或推送时遇到困难,其结果超出了任何普通爬虫或SEO工具所能做的。
这就是为什么专门为 SEO、SEM、SMO、SERP 检查和内容分析创建的 Python 库对每个人都有用的原因。
在本文中,我们将了解一些可以使用由 Elias Dabbas 创建和开发的用于 SEO 的 Advertools Python 库完成的事情,我认为这些事情在 SEO、PPC 和编码能力方面具有巨大潜力在很短的时间内。 此外,我们将以教育和自适应的方式使用自定义 Python 脚本和其他 Python 库。
由于 Elias Dabbas 的 sitemap_to_df 函数有助于下载和分析 XML 站点地图(站点地图是 XML 格式的文档,用于向搜索引擎报告可抓取和可索引的 URL),我们将研究从站点地图中可以学到什么。
本文将向您展示如何编写自定义 Python 代码以根据不同的结构分析不同的网站,如何根据 SEO 解释数据,以及在内容配置文件、URL 和网站结构方面如何像搜索引擎一样思考.
基于站点地图分析网站的内容规模和策略
站点地图是网站的一个组件,可以捕获许多不同类型的数据,例如网站发布内容的频率、内容类别、发布日期、作者信息、内容主题……
在正常情况下,您可以使用 scrapy 抓取站点地图,使用 Pandas 将其转换为 DataFrame,并根据需要使用许多不同的辅助库对其进行解释。
但在本文中,我们将只使用 Advertools 和一些 Pandas 库方法和属性。 一些库将被激活以可视化我们获得的数据。
让我们直接进入并选择一个网站以使用其站点地图来总结一些重要的 SEO 见解。
使用 Advertools 从站点地图中提取和创建数据框
在 Advertools 中,您只需一行代码即可发现、浏览和组合网站的所有站点地图。
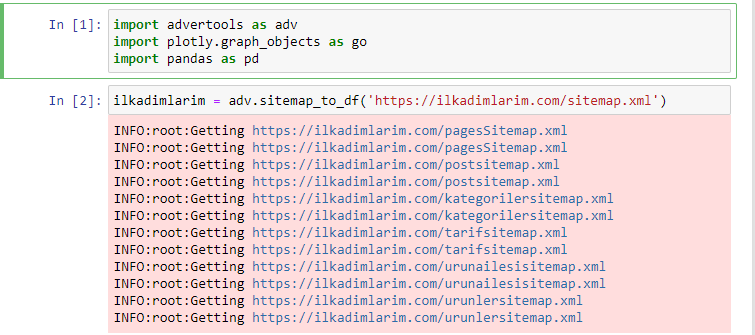
我喜欢使用 Jupyter Notebook 而不是常规的代码编辑器或 IDE。
在第一个单元格中,我们导入了用于收集和组织数据的 Pandas 和 Advertools,以及用于可视化数据的 Plotly.graph_objects。
adv.sitemap_to_df('sitemap address')命令简单地收集所有站点地图并将它们统一为一个 DataFrame。
如果您使用 Pandas 和 Advertools 执行相同操作,您可以发现哪个 URL 在哪个站点地图中可用。
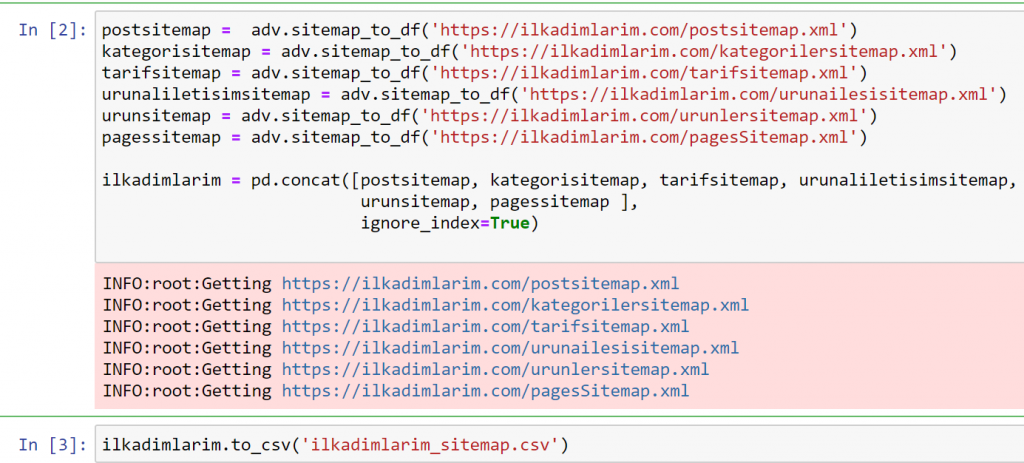
在上面的示例中,我们分别提取了相同的站点地图,然后将它们与pd.concat命令组合并将结果传输到 CSV。 前面的示例使用了站点地图索引文件,在这种情况下,该函数将检索所有其他站点地图。 因此,如果您对网站的特定部分感兴趣,您可以像我们在这里所做的那样选择特定的站点地图。
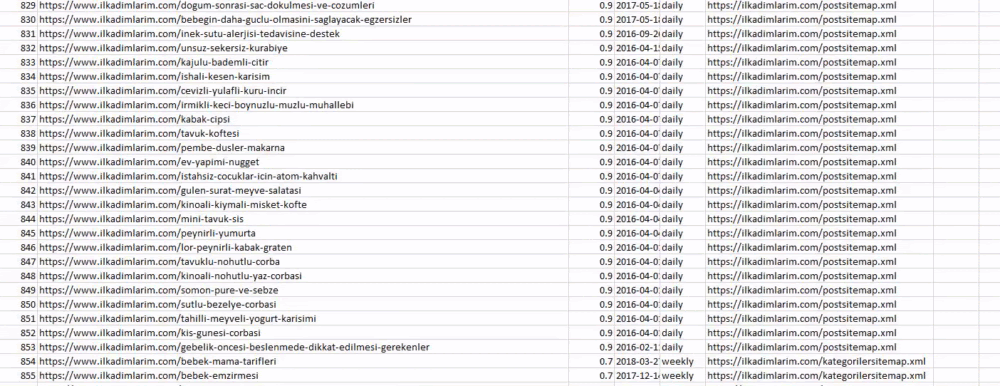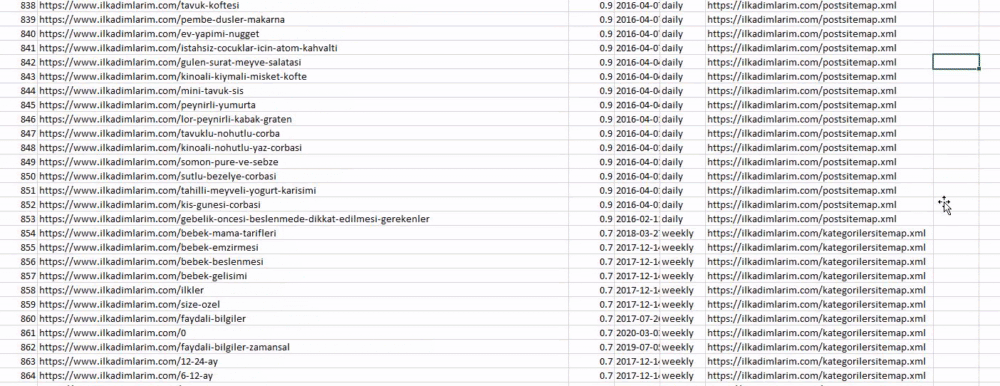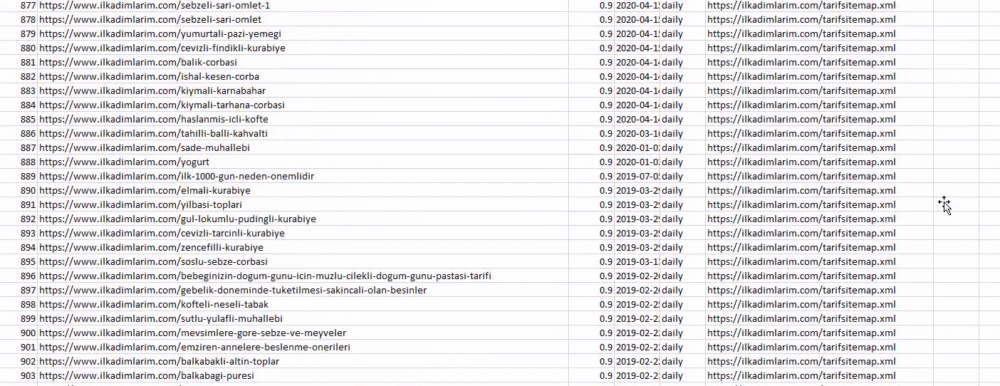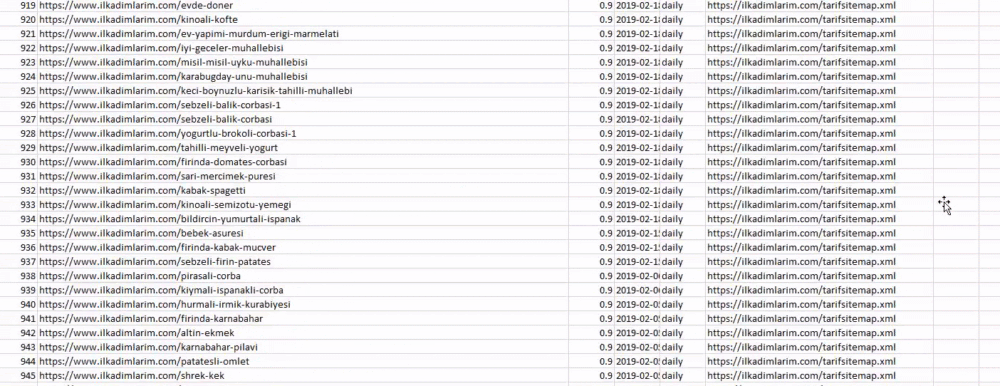
您可以在上方看到具有不同站点地图名称的列。 ignore_index=True 部分用于对不同 DataFrame 的索引号进行整齐排序,如果您已将多个索引号合并在一起。
抓取数据³
 学到更多
学到更多使用 Python 清理和准备用于内容分析的站点地图数据框
要通过站点地图了解网站的内容配置文件,我们需要准备它以查看我们使用 Advertools 获得的 DataFrame。
我们将使用 Pandas 库中的一些基本命令来塑造我们的数据:
ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(列 = '未命名:0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
“Ilkadimlarim”在土耳其语中的意思是“我的第一步”,你可以想象,它是婴儿、怀孕和母亲的网站。
我们对这些行执行了三个操作。
- 未命名:我们从 DataFrame 中删除了一个名为 0 的空列。 此外,如果您将“index = False”与pd.to_csv()函数一起使用,您将不会在开头看到此“未命名 0”列。
- 我们将 Last Modification 列中的数据转换为 Date Time。
- 我们将“lastmod”列带到了索引位置。
您可以在下面看到 DataFrame 的最终版本。
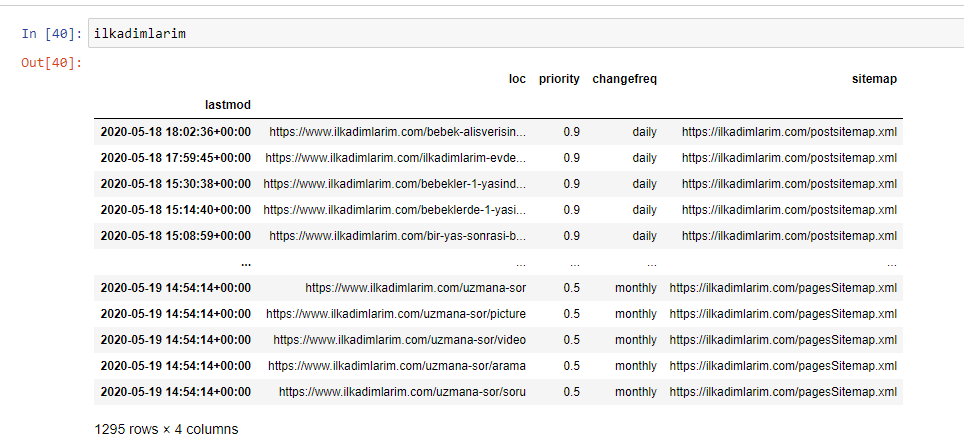
我们知道 Google 不会使用站点地图中的优先级和更改频率信息。 他们称之为“一袋噪音”。 但是,如果您重视您的网站对其他搜索引擎的性能,您可能会发现检查它们也很有用。 就个人而言,我不太关心这些数据,但我仍然不需要将其从 DataFrame 中删除。
我们还需要一个代码行来对另一列中的站点地图进行分类。
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
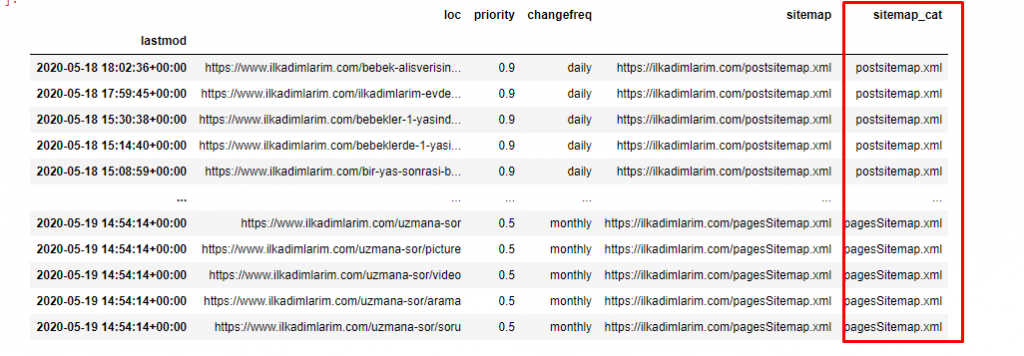
在 Pandas 中,您可以向 DataFrame 添加新的列或行,或者您可以轻松地更新它们。 我们使用DataFrame['new_columns']代码片段创建了一个新列。 DataFrame['column_name'].str允许我们通过更改列中的数据类型来执行不同的操作。 我们将.split('/')相关列中的字符串数据除以/字符,放到一个列表中。 使用.str [number] ,我们通过选择该列表中的特定元素来创建新列的内容。
根据站点地图计数和种类进行内容配置文件分析
根据站点地图的类型将站点地图放在不同的列中后,我们可以检查每个站点地图中的内容百分比。 因此,我们也可以推断网站的哪个部分更重要。
ilkadimlarim['sitemap_cat'].value_counts(normalize = True) * 100
- DataFrame['column_name']正在选择我们要进行处理的列。
- value_counts()计算列中值的频率。
- normalize=True采用十进制值的比率。
- 我们通过使用 *100 使十进制数字更大,使其更易于阅读。
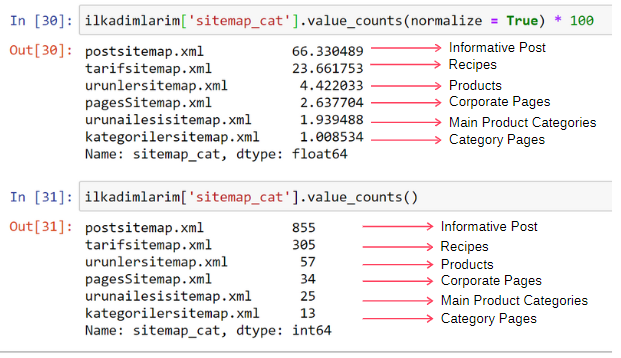
我们看到 65% 的内容在 Post Sitemap 中,23% 在 Recipe Sitemap 中。 产品站点地图只有 2% 的内容。
这表明我们有一个网站,必须为广大受众创建信息内容来推销自己的产品。 让我们检查一下我们的论点是否正确。
在继续之前,我们需要使用以下代码将 ilkadimlarim['sitemap_cat'] 列的名称更改为 'URL_Count':
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- rename() 函数可用于修改列或索引的名称以连接数据及其更深层次的含义。
- 由于'inplace=True'属性,我们已将列名更改为永久。
- 您还可以使用ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True)更改列和索引的字母样式。 这仅将 Ilkadimlarim 中每列的首字母大写。

现在,我们可以继续了。
要在单个帧中查看此信息,您可以使用以下代码:
(ilkadimlarim['sitemap_cat']
.value_counts()
.to_frame()
.assign(percentage=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', percent='{:.1%}')))
- to_frame()用于将 value_counts() 在选定列中测量的值框起来。
- assign()用于向框架添加某些值。
- lambda指的是 Python 中的匿名函数。
- 在这里,Lambda 函数和站点地图类型通过 Pandas div()方法除以站点地图总数。
- style()确定如何写入指定的最终值。
- 在这里,我们使用format()方法设置句点后写入的位数。
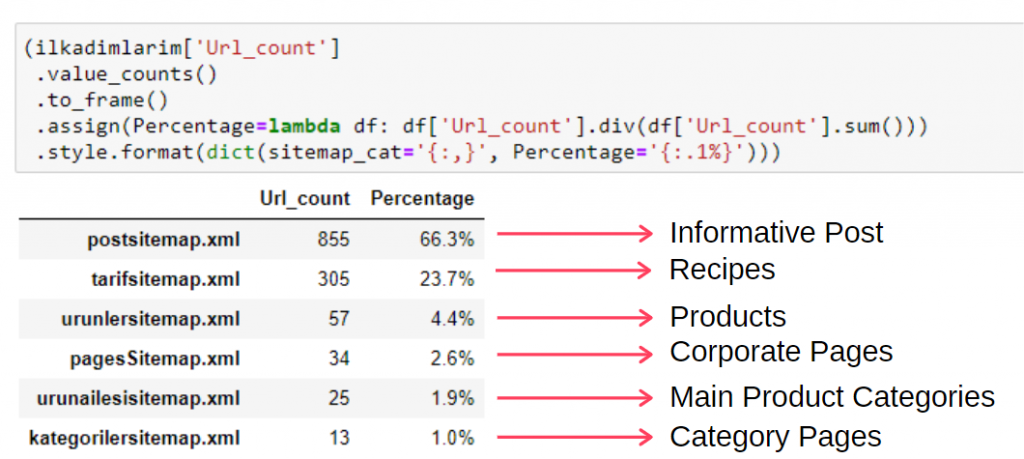
因此,我们看到了内容营销对这个网站的重要性。 我们还可以通过两行代码查看他们每年的文章发布趋势,以更深入地检查他们的情况。
通过站点地图和 Python 按年检查和可视化内容发布趋势
我们根据站点地图类别对被审查网站的内容和意图进行了匹配,但我们还没有进行基于时间的分类。 我们将使用resample()方法来完成此操作。
post_per_month = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample 是 Pandas 库中的一种方法。 resample('A') 检查年度数据帧的数据系列。 对于几周,您可以使用“W”,对于几个月,您可以使用“M”。
Loc在这里象征着索引; count 表示您要计算数据示例的总和。
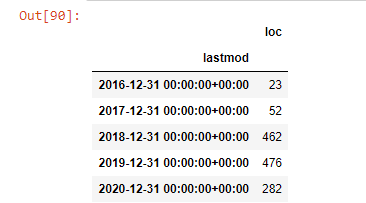
我们看到他们在 2016 年开始发表文章,但他们的主要发表趋势在 2017 年之后有所增加。我们也可以借助 Plotly Graph Objects 将其放入图形中。
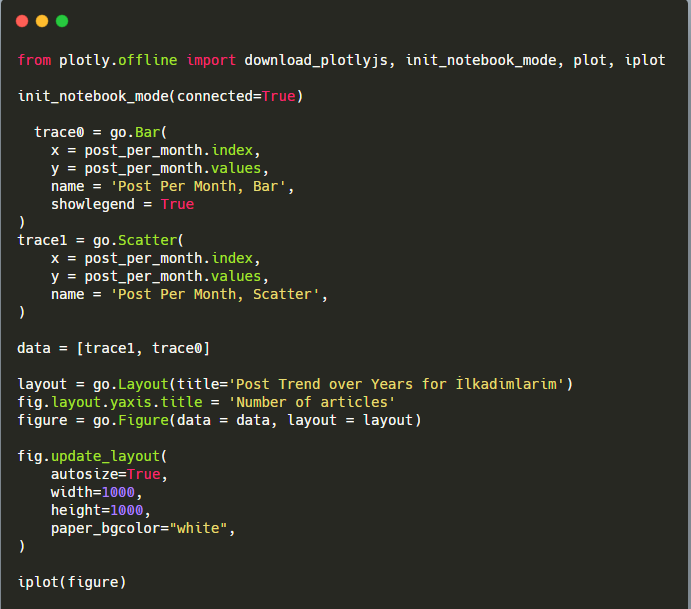
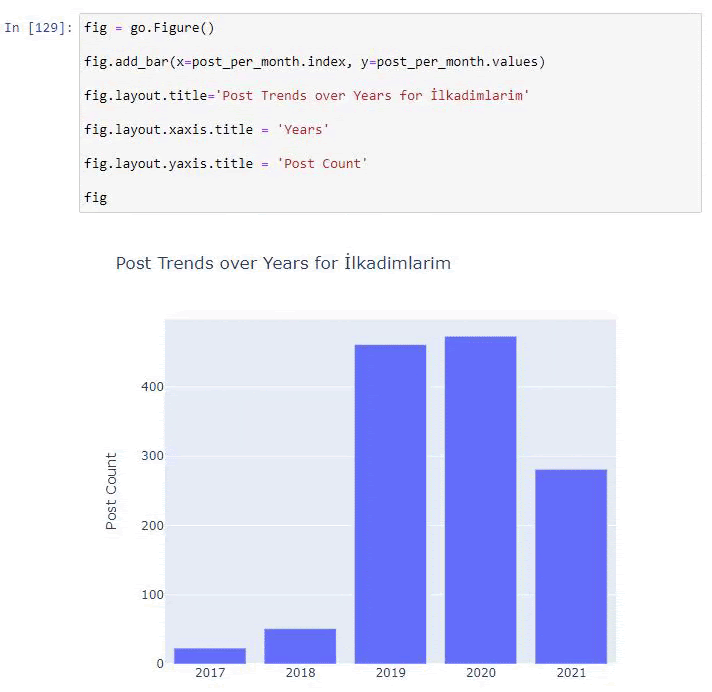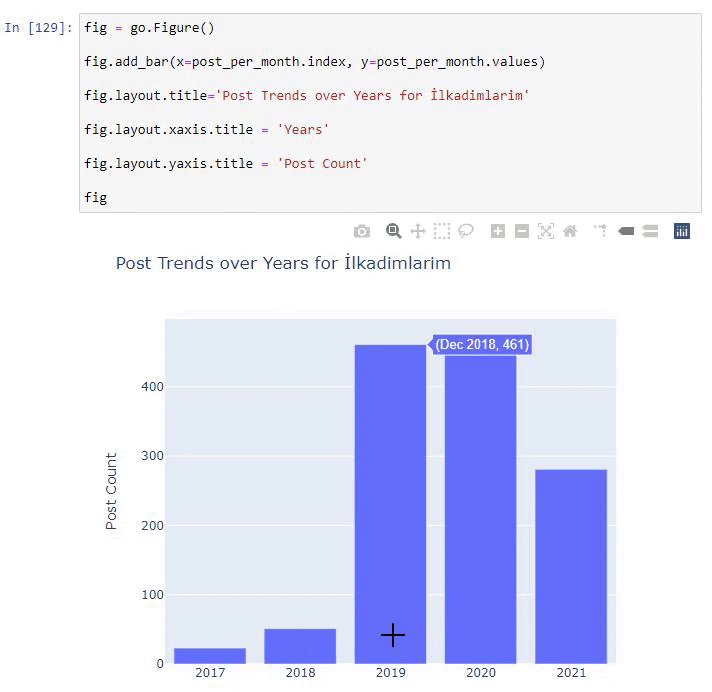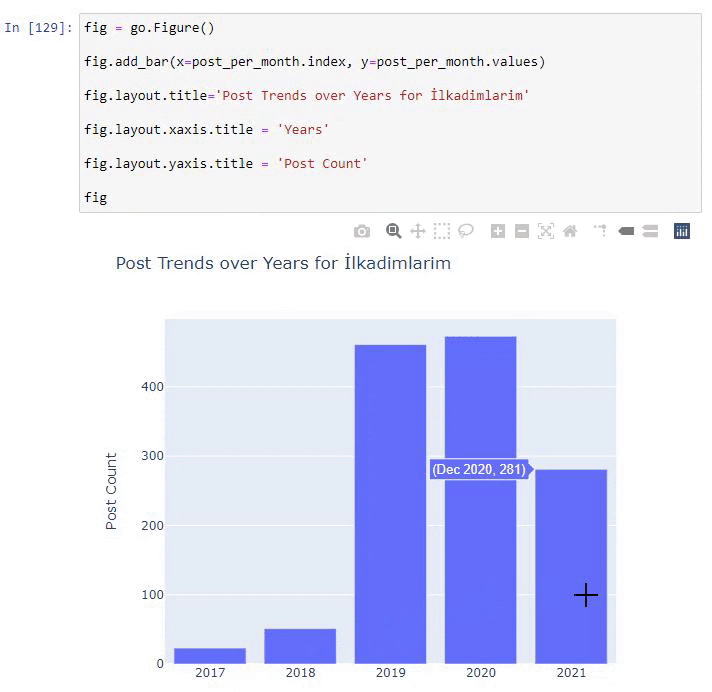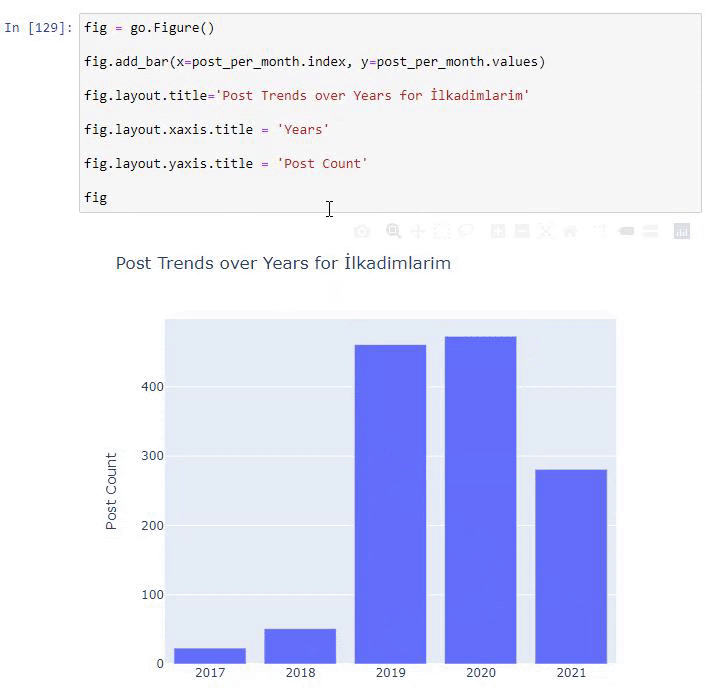
此 Plotly Bar Plot 代码片段的说明:
- fig = go.Figure()用于创建图形。
- fig.add_bar()用于在图中添加条形图。 我们还确定括号内的 X 轴和 Y 轴。
- Fig.layout用于为图形和轴创建一个通用标题。
- 在最后一行,我们使用 fig 命令调用我们创建的绘图,它等于go.Figure()
下面,您将按月找到相同的数据,包括散点图和条形图:
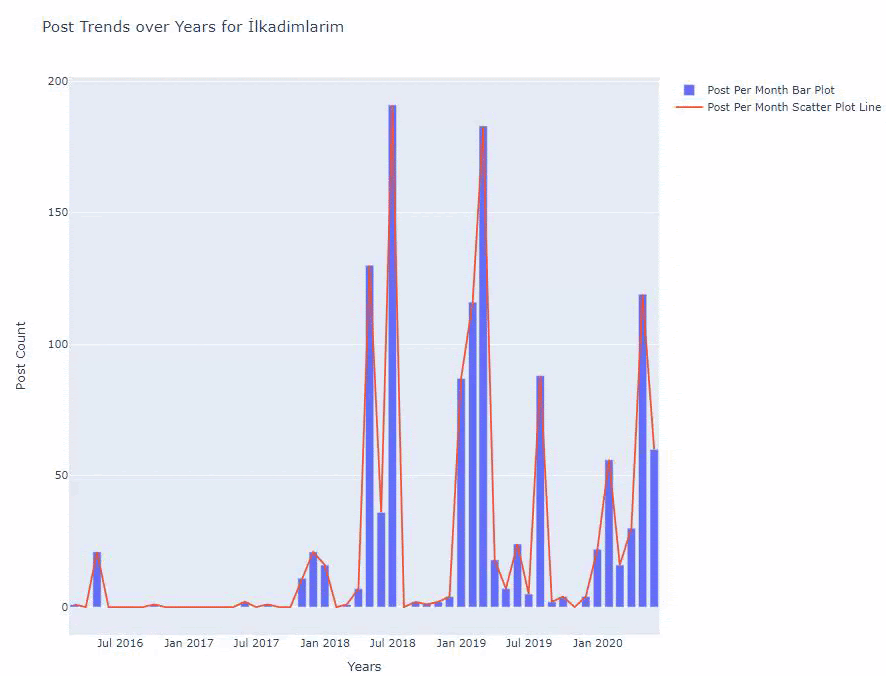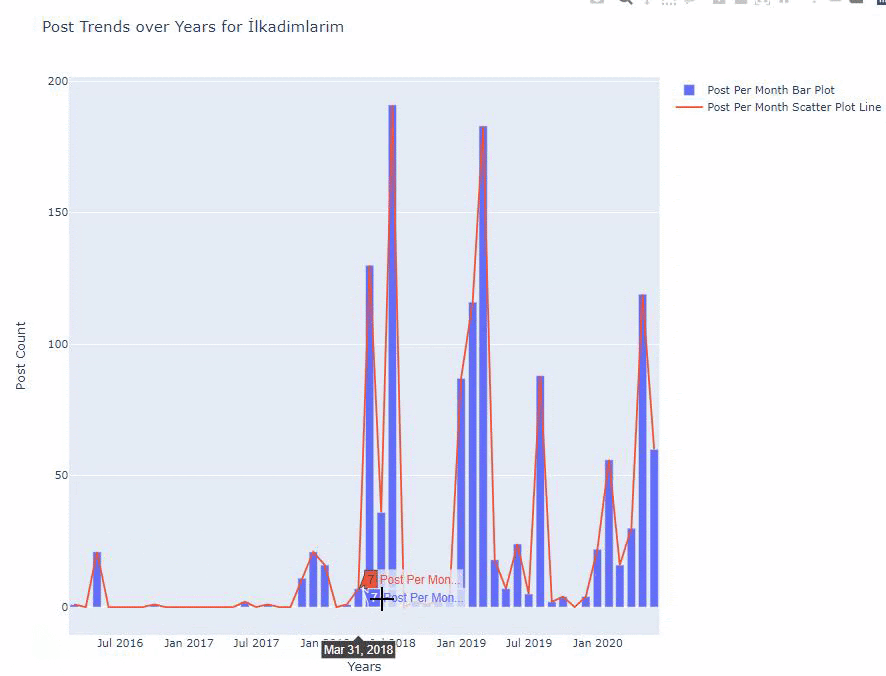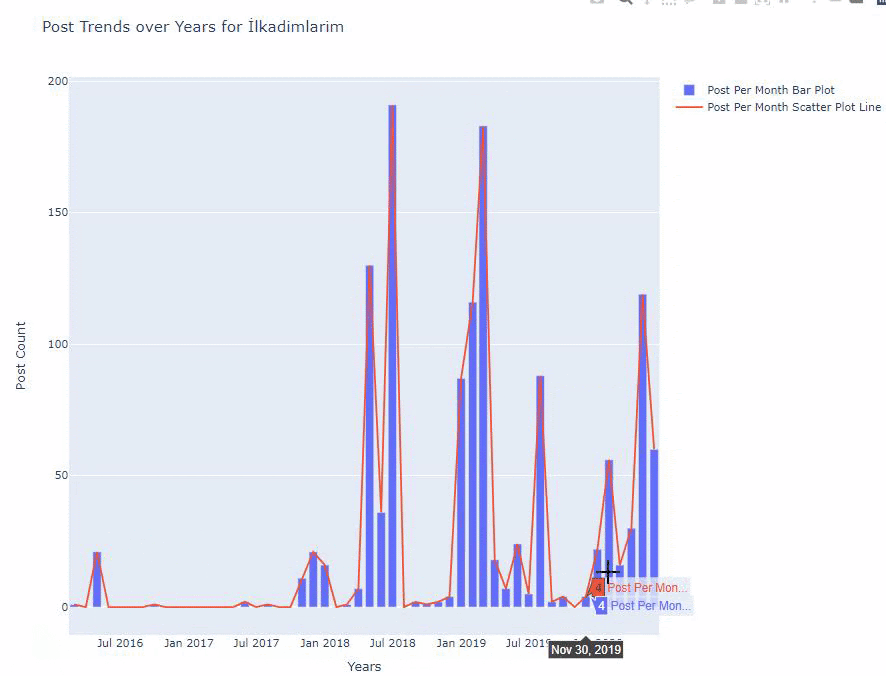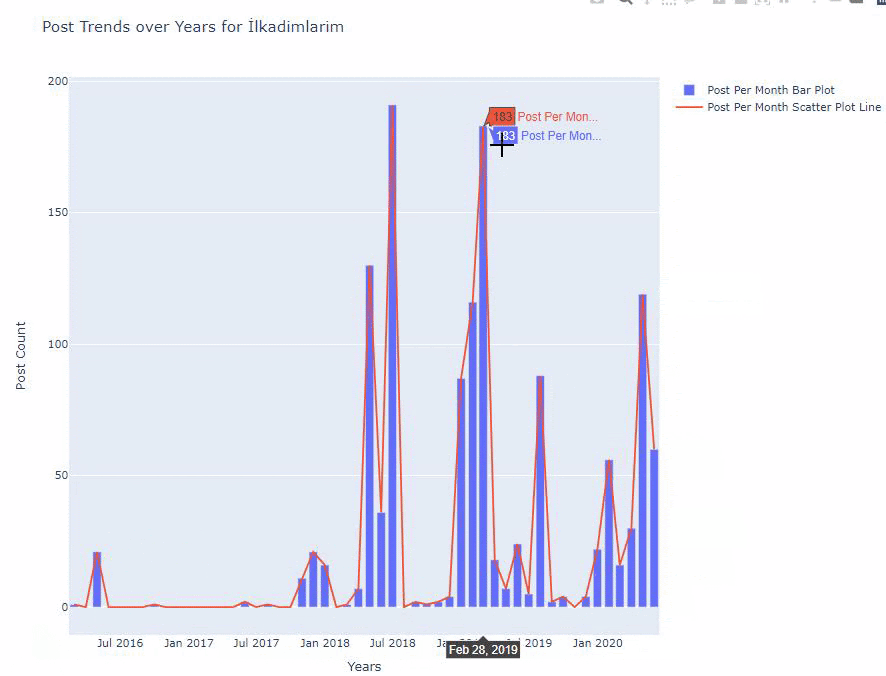
以下是创建此图的代码:
我们使用fig.add_scatter()添加了第二个绘图,并且我们还使用 name 属性更改了名称。 fig.update_layout()用于更改绘图的大小和背景颜色。
您还可以更改悬停模式、条形之间的距离等。 我认为只分享代码就足够了,因为在这里单独解释每个代码可能会导致我们偏离主题。
我们还可以根据以下类别比较竞争对手的内容发布趋势:
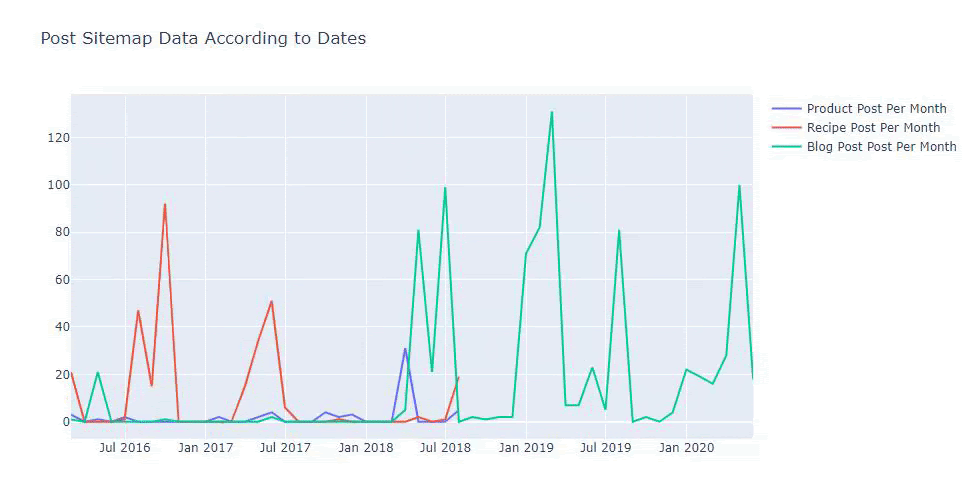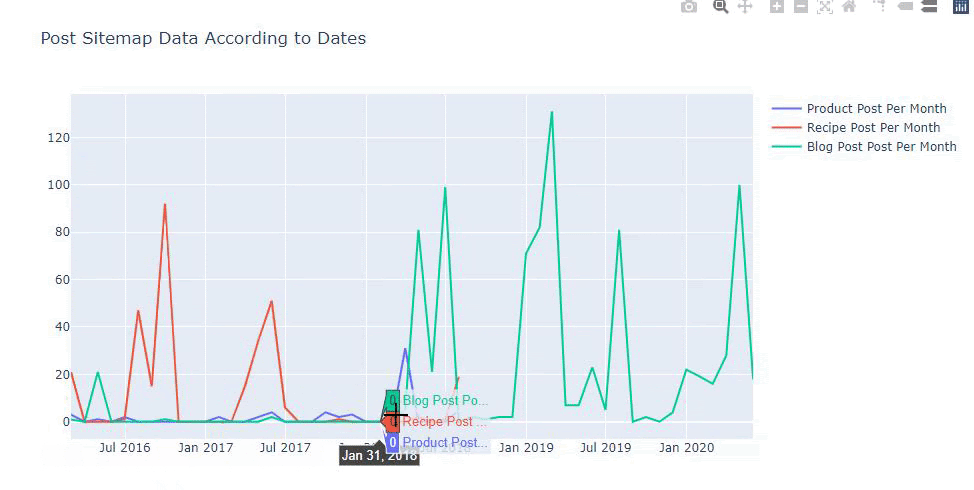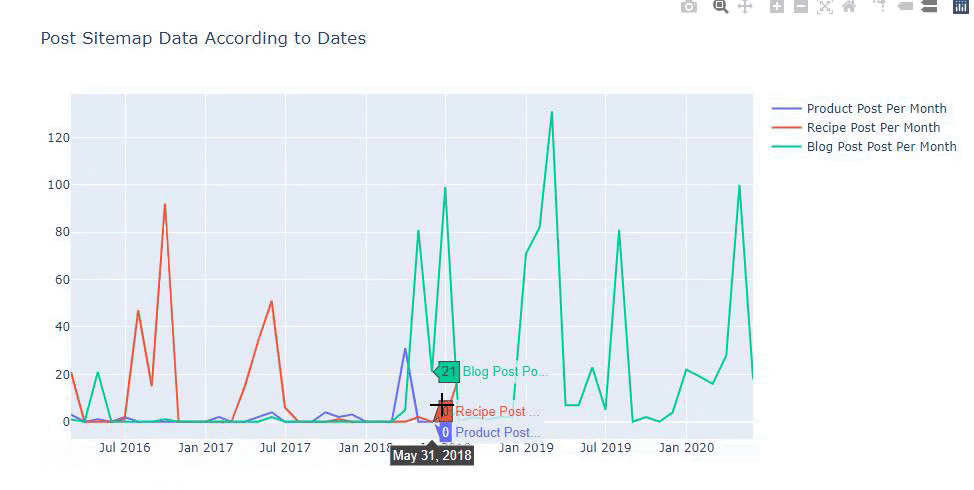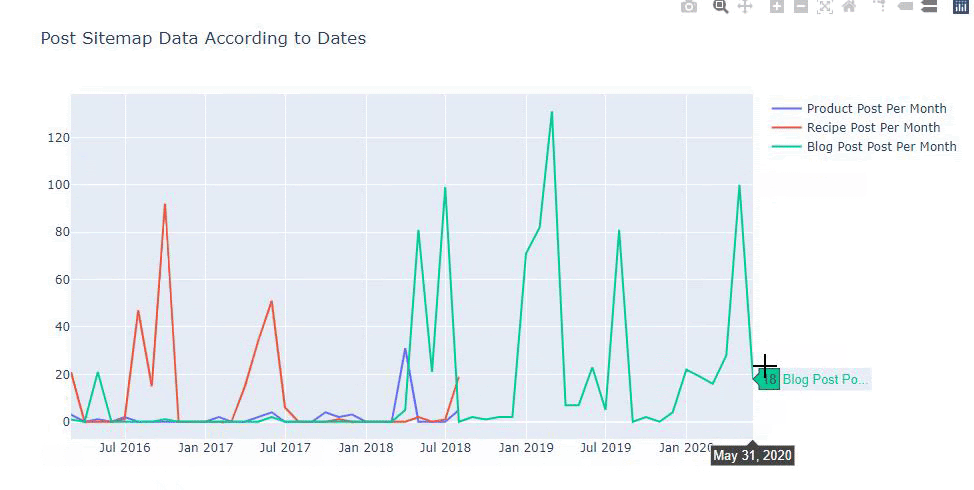
此图表是使用第二种方法创建的,您可能会看到没有区别,但其中一个非常简单。
为了绘制三个独立站点地图发布内容的频率和趋势,我们必须将间隔最长的站点地图放在 X 轴上。 因此,我们可以比较我们正在检查的网站针对不同搜索意图发布每种不同类型内容的频率。
当您检查下面的相关代码时,您会发现它与上面的并没有太大区别。
要创建具有多个 Y 轴的散点图,您可以使用以下代码。
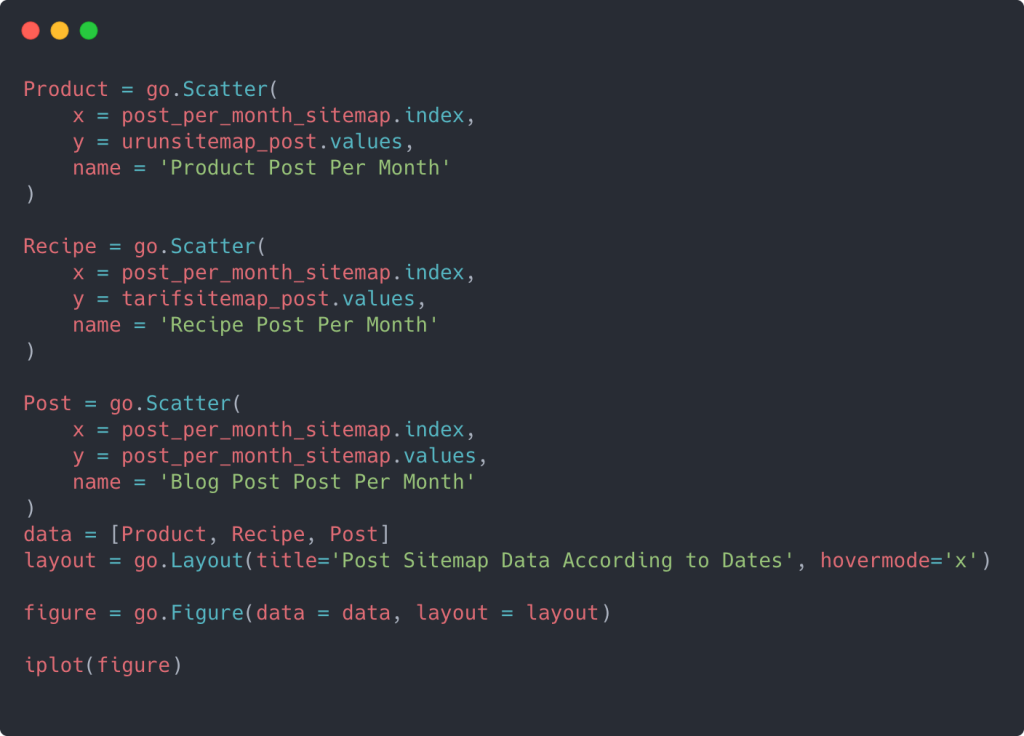
还有其他方法,例如统一不同的站点地图并为列使用 for 循环以在散点图中使用多个 Y 轴,但对于如此小的站点,我们不需要这样做。 在大多数情况下,在拥有数百个站点地图的网站上使用这种方法会更合乎逻辑。
此外,由于网站很小,图形可能看起来很浅,但正如您稍后将在具有数百万个 URL 的网站的文章中看到的那样,这些图形是比较不同网站以及比较不同类别的网站的好方法同一个网站。
使用站点地图和 Python 检查和可视化内容类别、意图和发布趋势
在本节中,我们将检查他们是否在特定知识领域编写了大量内容以推销少量产品,我们在文章开头说过。 多亏了这一点,我们可能会看到他们是否与其他品牌建立了内容合作伙伴关系。
为了显示在站点地图上还可以找到什么,我们将继续进行更多的挖掘。 我们还可以从站点地图的“loc”部分获取一些信息,例如其他信息。
Ilkadimlarim 的 URL 中没有类别细分。 如果一个网站的 URL 中有一个类别细分,我们可以了解更多关于内容分发的信息。 如果没有,我们可以通过编写额外的代码来访问相同的数据,但不确定性较低。
在这一点上,您可以想象,对于抓取数十亿网站以了解您的网站的搜索引擎来说,URL 故障的成本会降低多少。
a = ilkadimlarim['loc'].str.contains(“bebek|hamile|haftalik”)
贝贝克:宝贝
哈米尔:怀孕
Haftalik:每周或“怀孕几周”
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
这里的str()方法再次允许我们设置选择某些操作的列。
使用contains()方法,我们确定数据以检查它是否包含在转换为字符串的数据中。
这里,“|” 术语之间的意思是“或” 。
然后我们将我们过滤的数据分配给一个变量,并使用我们之前使用的resample()方法。
另一方面,计数方法测量使用了哪些数据以及使用了多少次。
使用 count() 获得的结果再次包含在to_frame()中。
此外, str.contains()默认采用 Regex 值,这意味着您可以用更少的代码创建更复杂的过滤条件。
换句话说,此时,我们将包含单词“baby”、“weekly”、“pregnant”的 URL 分配给ilkadimlarim中的变量,然后我们将 URL 的发布日期放在我们过滤器的适当条件中在一个框架中创建。
然后我们对包含单词“aptamil”的 URL 执行相同的操作。 Aptamil 是 Ilkadimlarim 推出的婴儿营养产品的名称。 因此,我们也可以关注信息性和商业性内容的播放密度。
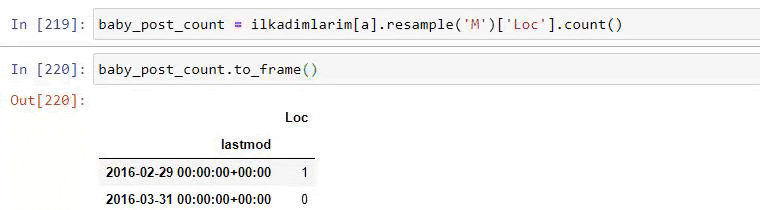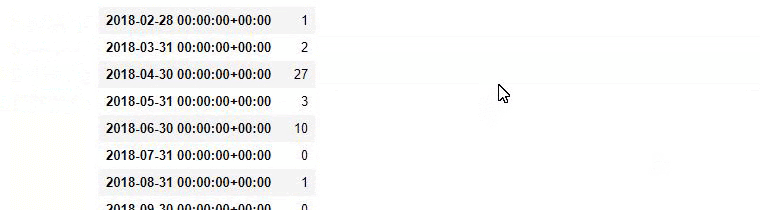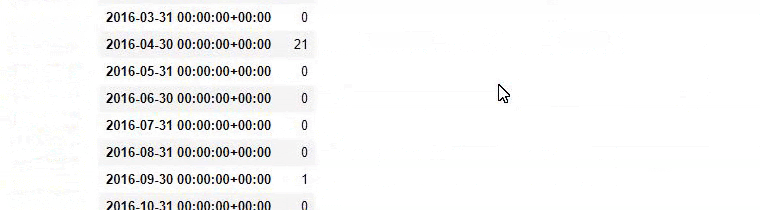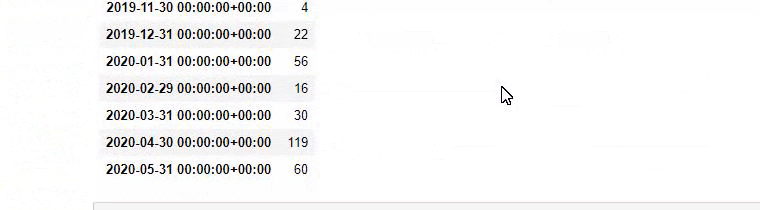
您可能会看到这两个不同的内容组多年来针对不同的搜索意图发布了时间表,其中来自 URL 的信息更加确定和准确。
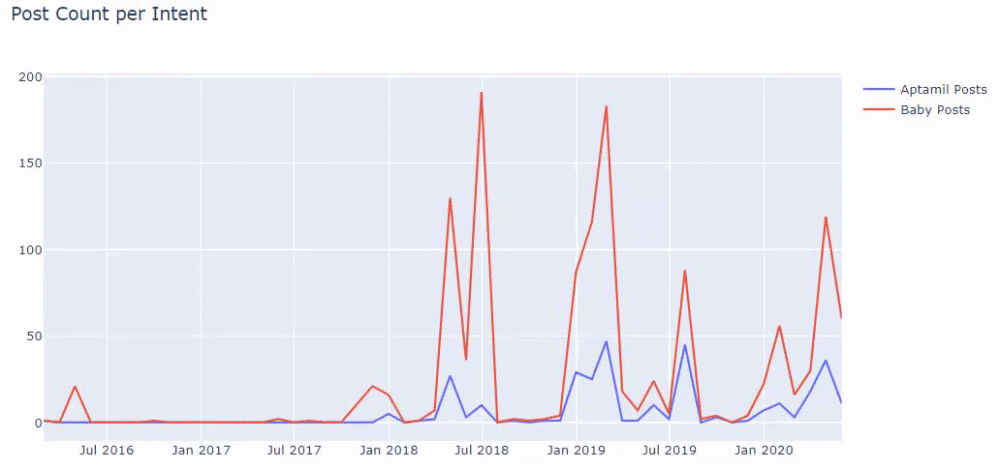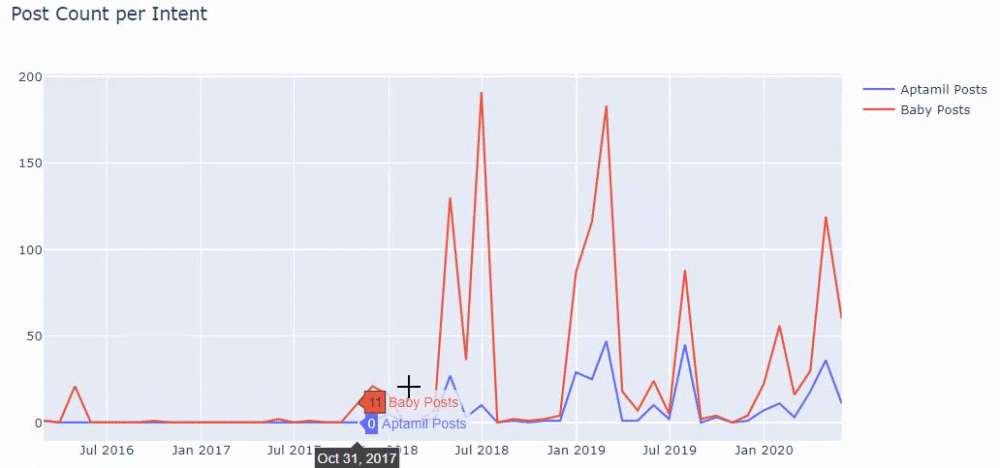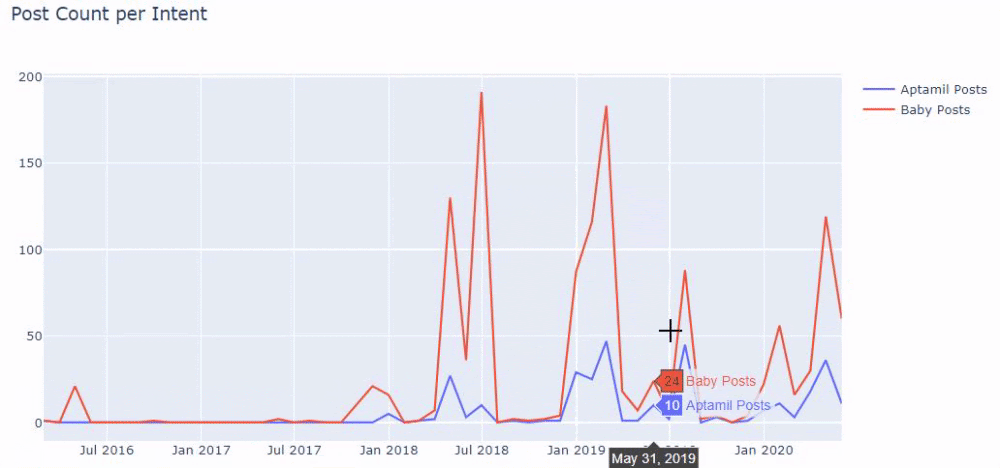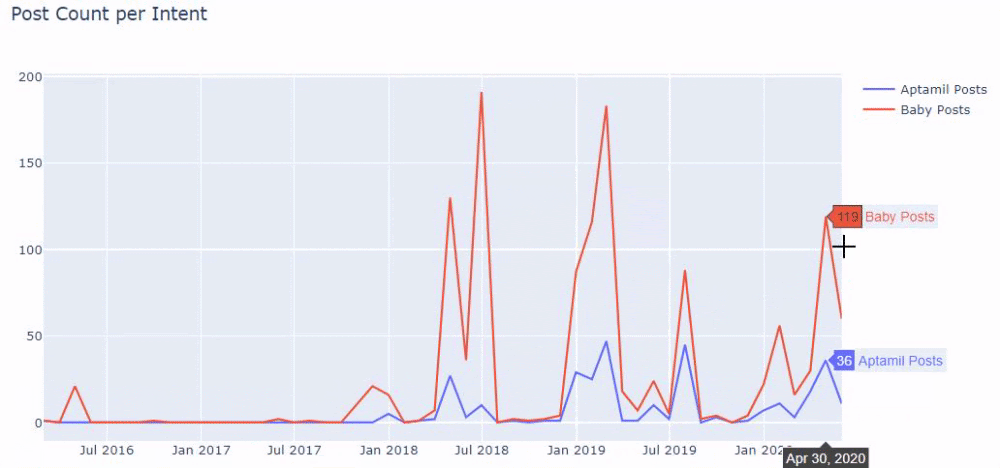
生成此图表的代码未共享,因为它与用于上一张图表的代码相同
在 Google 搜索运营商的帮助下,当我想要在 Ilkadimlarim.com 的锚文本中使用 Aptamil 一词的页面时,我得到了 38 个结果。 这些页面中有很多是信息丰富的,它们链接商业内容。

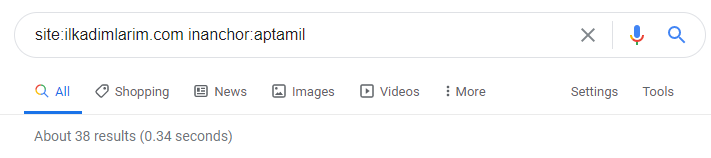
我们的论点已经得到证实。
“我的第一步”使用数百篇关于母性、婴儿护理和怀孕的信息内容来吸引目标受众。 “Ilkadimlarim”从该内容链接包含 Aptamil 产品的页面,并将用户引导到那里。
通过使用 Python 的站点地图比较内容分析和分析内容策略
现在,如果您愿意,让我们对同一行业的公司做同样的事情,并进行比较,以了解该行业的总体情况以及这两个品牌之间的战略差异。
作为第二个例子,我选择了 Prima.com.tr,它是帮宝适,但在土耳其使用品牌名称 Prima。 由于 Prima 有一个单一的站点地图,我们将无法按站点地图进行分类,但至少它们的 URL 有不同的中断。 所以我们很幸运:我们将不得不编写更少的代码。
想象一下,当您制作一个难以理解的网站时,Google 必须为您运行的算法成本要高出多少! 这可以帮助您更清楚地了解爬网成本计算,即使只是相对于 URL 结构也是如此。
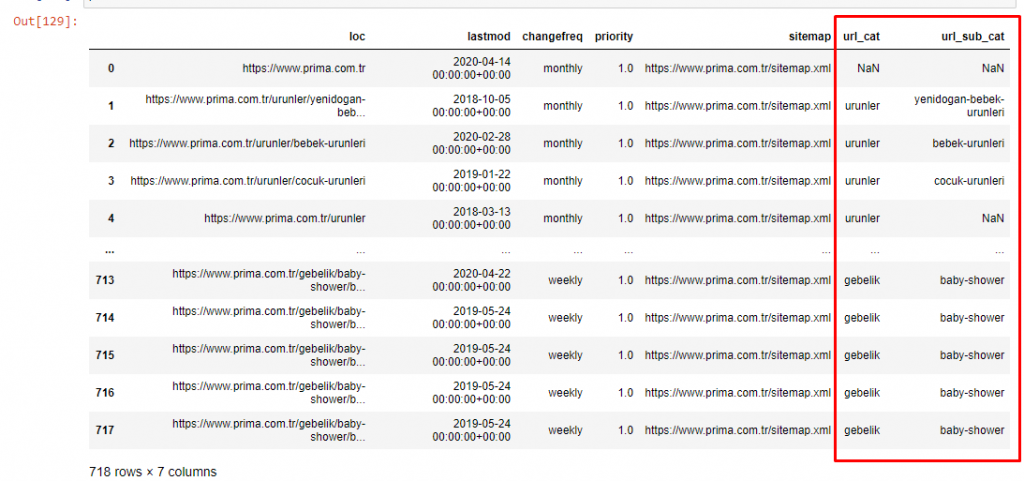
为了不进一步增加文章的体积,我们没有放置与我们已经做过的类似的过程的代码。
现在,我们可以通过 URL 类别和 URL 子类别检查它们的内容类别分布。 我们看到他们拥有过多的公司网页。 这些公司网页位于“prima-hakkinda”(“关于 Prima”)部分。 但是当我用 Python 检查它们时,我发现它们已经将他们的产品和公司网页统一在一个类别中。 你可以在下面看到他们的内容分布:

我们可以对以下子类别做同样的事情。
有趣的是,Prima 使用“gebelik”(土耳其语中的怀孕),它是“hamilelik”(阿拉伯语中的怀孕)的变体,两者都表示怀孕期。

现在我们看到对其内容进行更深入的分类。 9.2%的内容是关于健康怀孕,7.3%是关于婴儿的成长过程,8.3%的内容是关于可以和婴儿一起做的活动,0.7%是关于婴儿的睡眠顺序。 甚至还有 3.9% 的出牙、1.9% 的婴儿安全和 1.4% 的向家人透露怀孕等话题。 如您所见,您可以通过 URL 及其分布百分比了解一个行业。
这不是完美的分类,但至少我们可以看到竞争对手的心态和内容营销趋势,以及他们网站的内容分类。 现在让我们按月检查发布内容的频率。
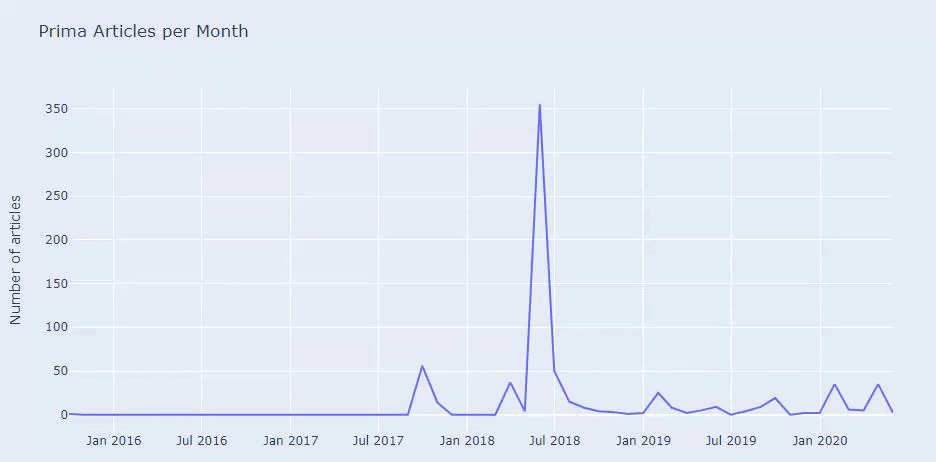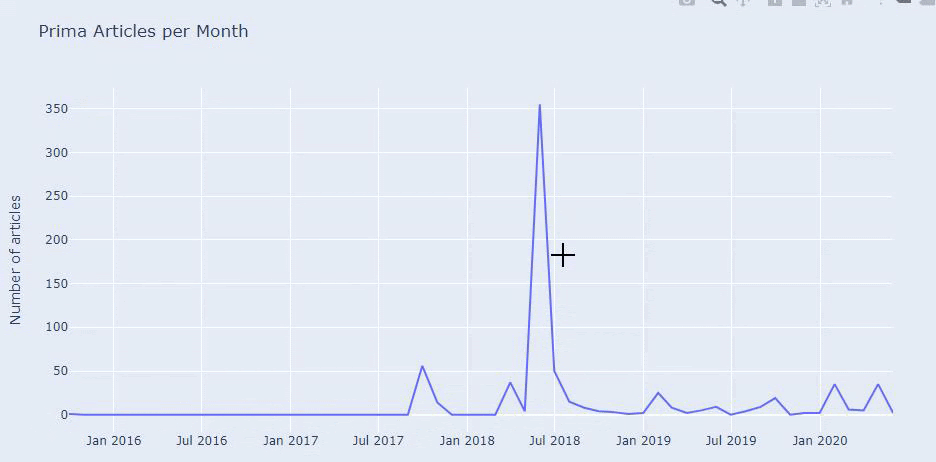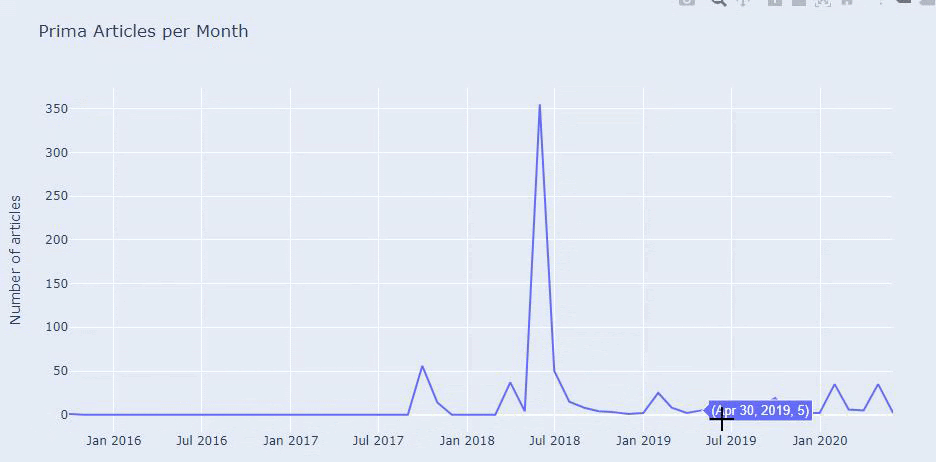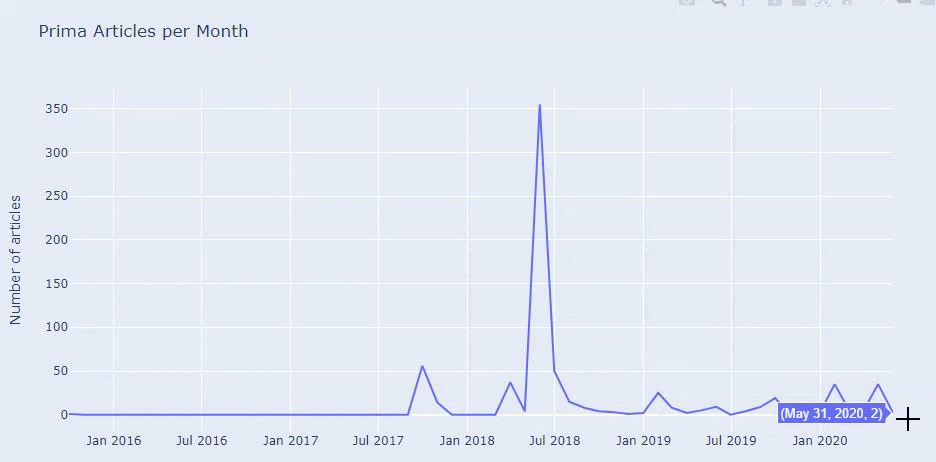
我们看到他们在 2018 年 7 月发表了 355 篇文章,根据 Sitemap,他们的内容从那时起就没有刷新过。 我们还可以根据多年来的类别比较他们的内容发布趋势。 如您所见,它们的内容主要位于四个不同的类别中,并且大多数都在同一个月内发布。
在继续之前,我必须说站点地图数据可能并不总是正确的。 例如,所有 URL 的 Lastmod 数据可能已更新,因为它们在该日期更新了所有站点地图。 为了解决这个问题,我们还可以使用 Wayback Machine 检查他们是否没有更改过他们的内容。
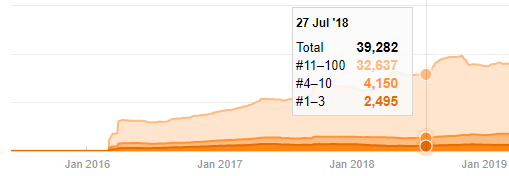
即使看起来可疑,这些数据也可能是真实的。 土耳其的许多公司倾向于先下大量订单并发布内容。 当我检查他们的关键字计数时,我看到了这段时间的跳跃。 因此,如果您正在执行比较内容配置文件和策略分析,您还应该考虑这些问题。
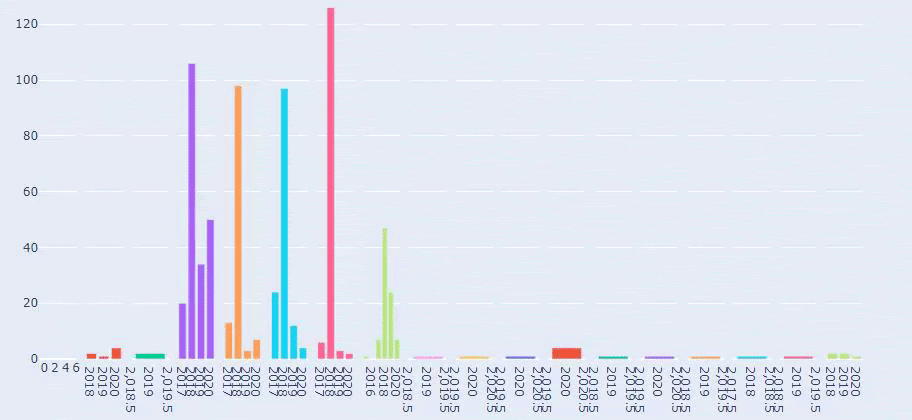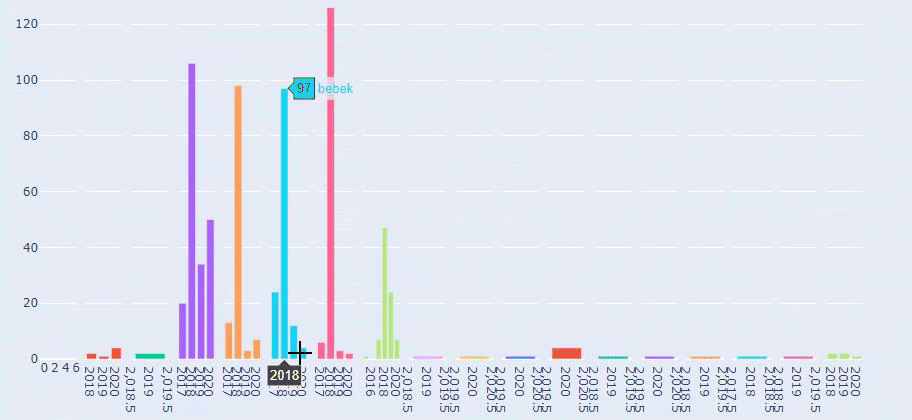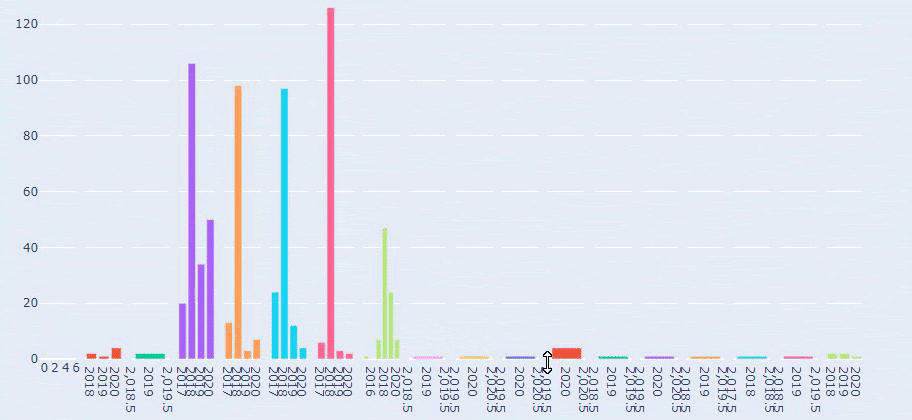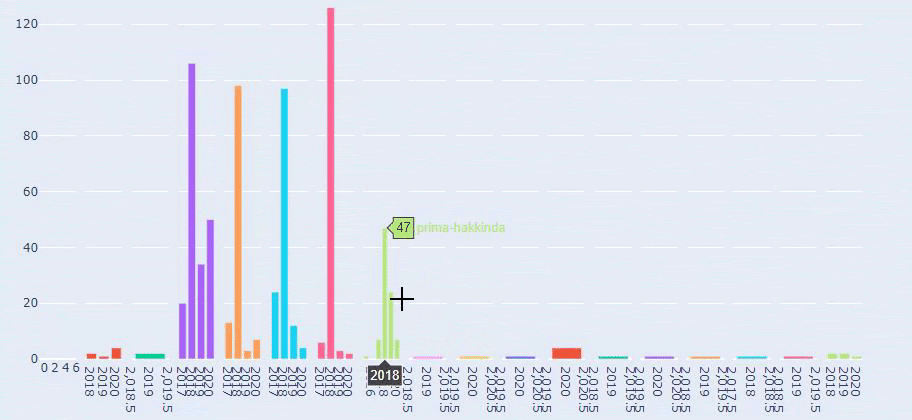
这是 Prima.com.tr 多年来每个类别的内容发布趋势之间的比较
现在,我们可以比较两个不同网站的内容类别及其发布趋势。
当我们查看 Prima 发表关于婴儿成长、怀孕和母亲的文章的频率时,我们发现与 Ilkadimlarim 的相似之处:
- 大多数文章都是在某个时间发表的。
- 他们已经很长时间没有更新了。
- 与信息内容页面的数量相比,产品和页面的数量非常少。
- 最近,他们刚刚在他们的网站上添加了新产品。
我们可以将这四个特征视为行业的默认思维方式,我们可以利用这些弱点来支持我们的活动。 毕竟,质量需要新鲜度(正如谷歌研究员 Amit Singhal 所说)。
在这一点上,我们也看到业界对 Googlebot 的行为并不熟悉。 与其一天上传250条内容,一年不做任何改动,不如定期添加新内容,定期更新旧内容。 因此,您可以保持内容的质量,Googlebot 可以更轻松地了解您的网站,并且您的抓取需求频率值将高于您的竞争对手。
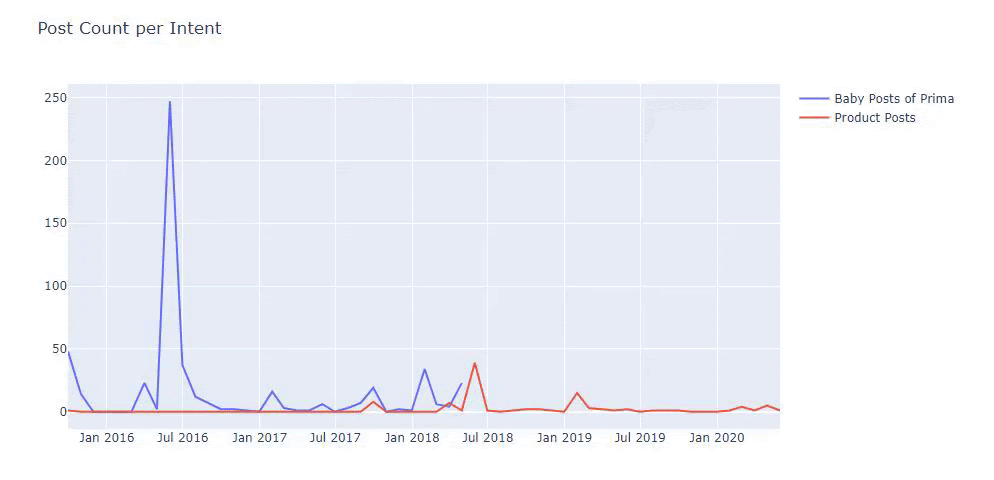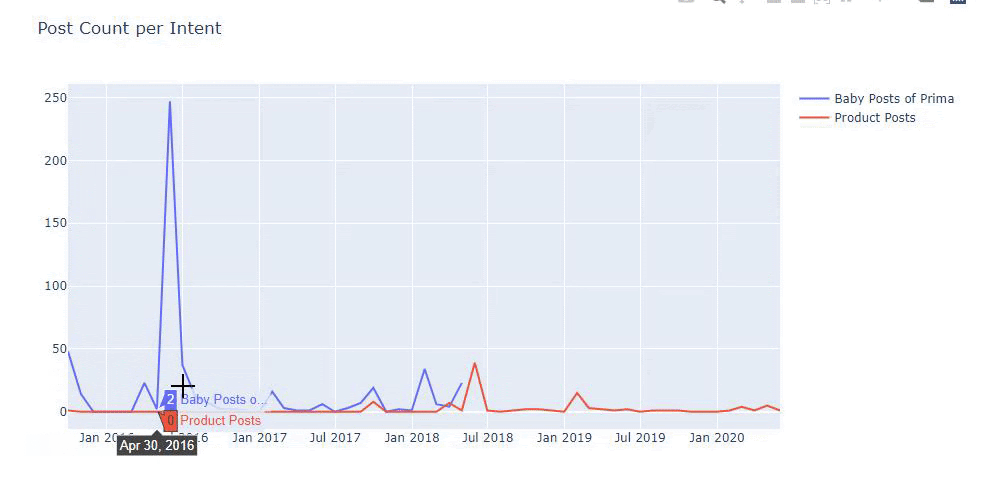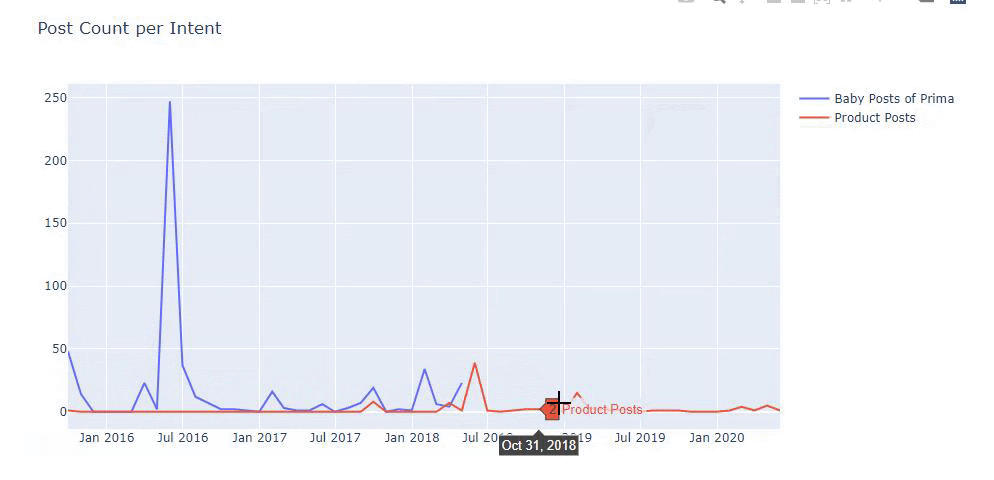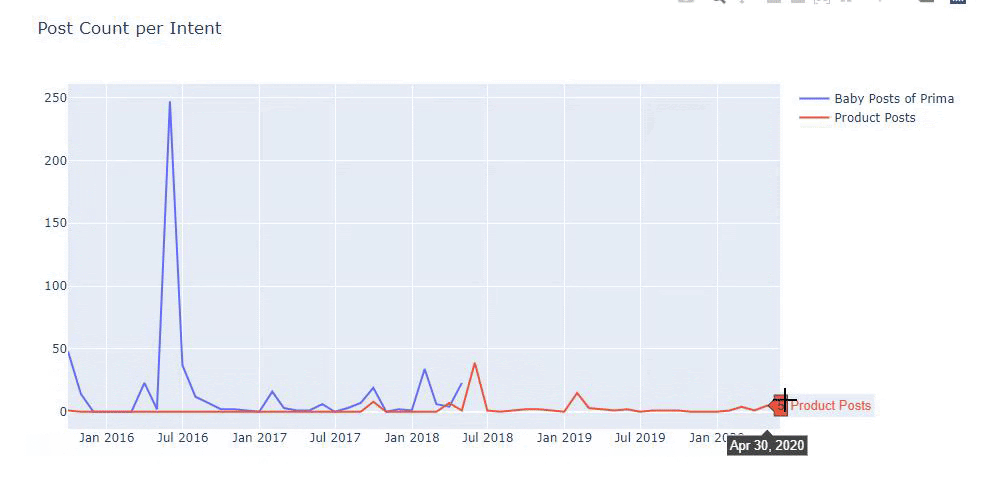
我使用以前的方法来区分产品页面和信息内容页面,并分析 URL 中最常用的词。 这里的宝贝帖子意味着这些是内容丰富的内容。
如您所见,他们在一天之内添加了 247 个内容。 此外,他们在一年多的时间里没有发布或更新信息性内容,只是偶尔添加一些新的产品页面。
现在让我们用两个不同的图表来比较他们的出版趋势。 我使用下面的代码来创建这个图:
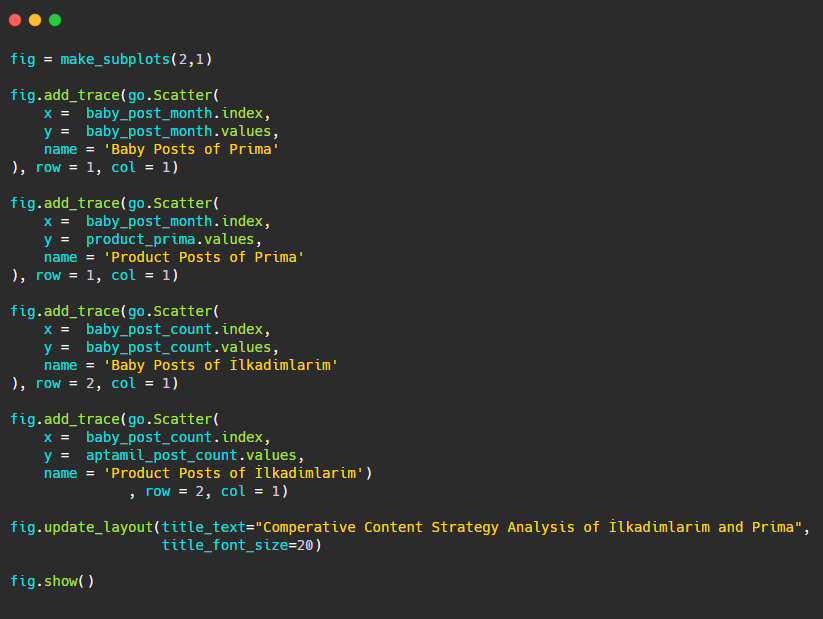
由于此图形与以前的图形不同,因此我想向您展示代码。 在这里,两个单独的图放置在同一个图中。 为此,使用来自plotly.subplots import make_subplots 的命令调用了 make_subplots 方法。
它是使用make_subplots (2,1)创建为两行一列的图形。
因此, col 和 row 写在迹线的末尾,并指定了它们的位置。 这是一个任何熟悉 CSS 中网格系统的人都可以轻松识别的系统。
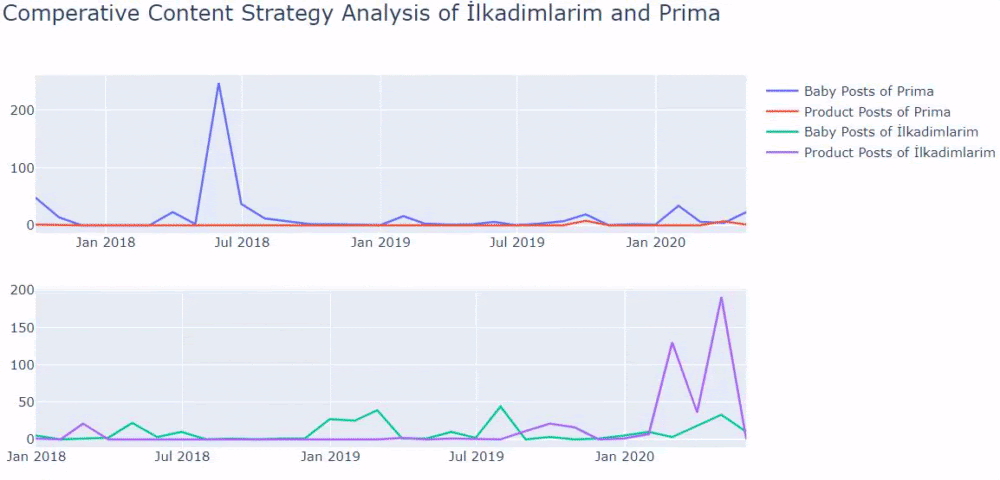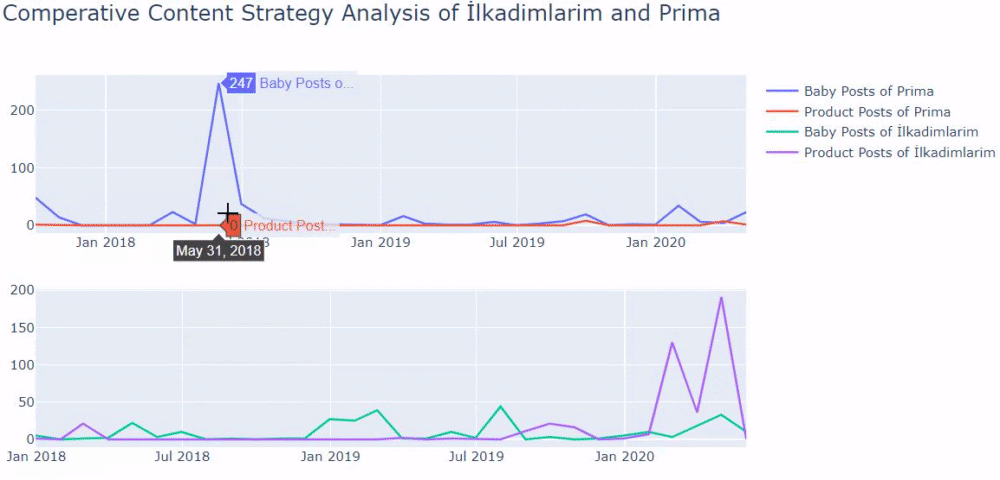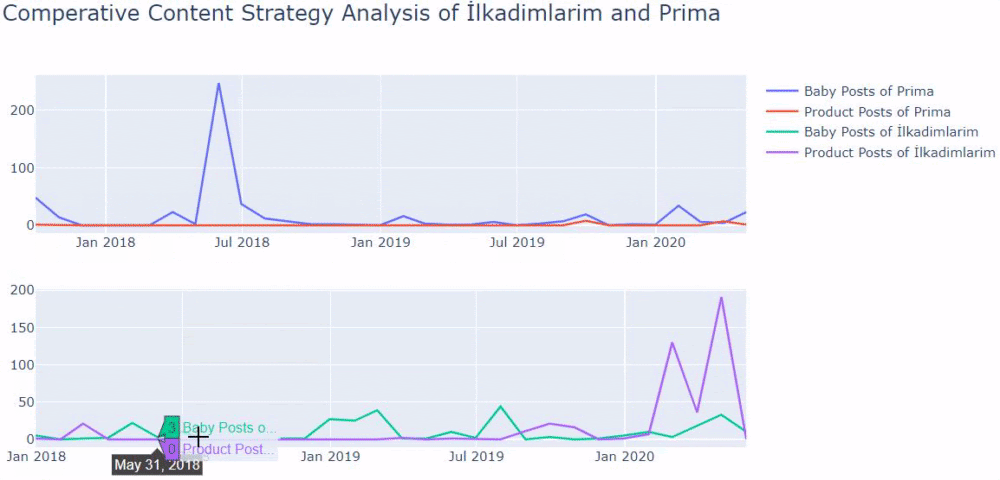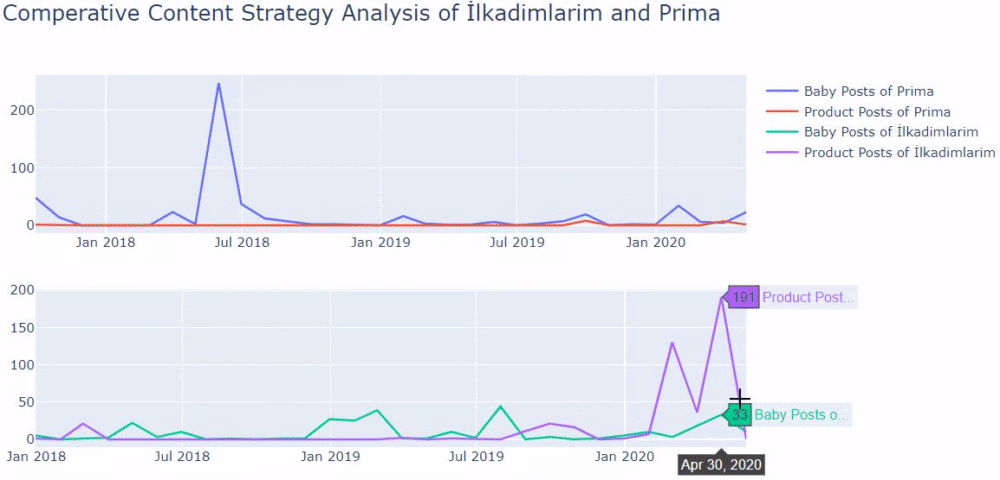
如果您有同一行业的客户,您可以使用这些数据来创建内容策略,查看竞争对手的弱点以及他们在 SERP 上的查询/登陆页面网络。 此外,您可以了解应该在同一知识领域或针对同一用户意图发布多少内容。
在总结我们可以从站点地图中学到的内容作为内容策略分析的一部分之前,我们可以检查最后一个来自另一个行业的 URL 计数更高的网站。
使用 Python 和站点地图对货币上的新闻 Web 实体进行内容策略分析
在本节中,我们将使用 Seaborn 的热图以及一些更高级的框架和数据提取方法。

Elias Dabbas 在数据科学和 SEO 方面有一个有趣且非常有用的 Kaggle 存档。 本月,他为土耳其新闻网站开设了一个新的 Kaggle 数据集部分,供我编写必要的代码并通过站点地图使用 Advertools 执行内容策略分析。
在我开始在 Kaggle 上使用这些技术之前,我想展示一些示例,说明如果我们在本文中在更大的 Web 实体上使用相同的技术会发生什么。
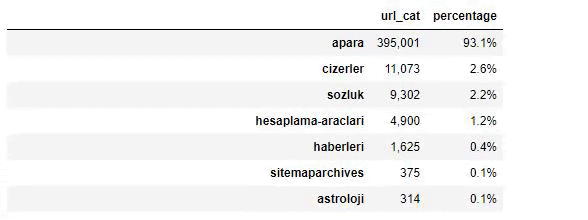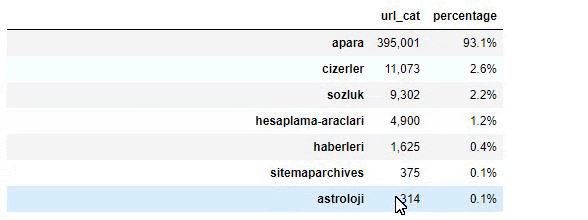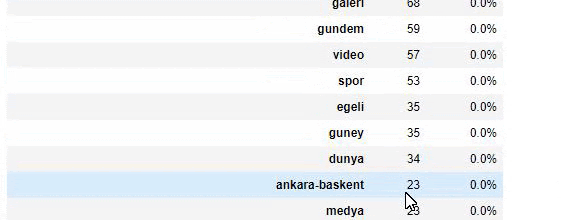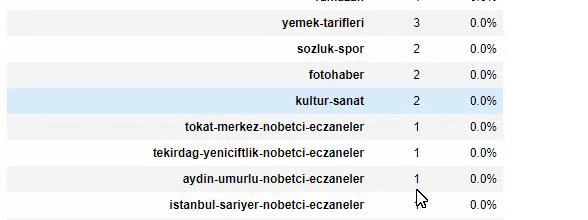
当我们分析沙巴报的内容时,我们发现其内容的很大一部分(81%)属于一个名为“apara”的类别。 此外,它们还有一些占星术、计算、字典、天气和世界新闻的大类别。 (Para 在土耳其语中是钱的意思)
对于沙巴报纸,我们也可以使用仅使用 Advertools 收集的站点地图来分析内容,但是由于所讨论的报纸非常大,我不喜欢它,因为站点地图的数量很多,并且不同站点地图的内容包含相同的 URL类别。
您还可以在下面看到使用 Advertools 的过多站点地图。
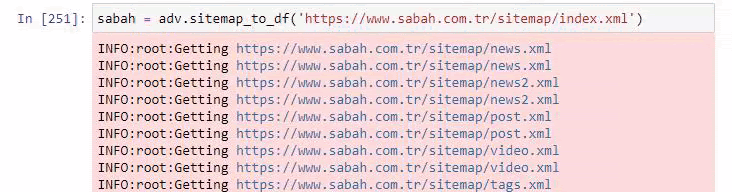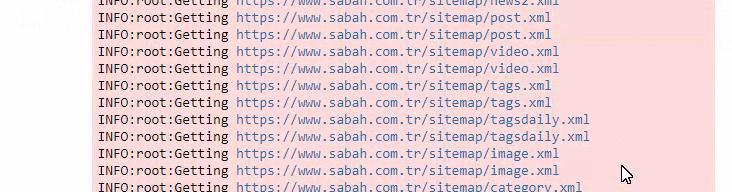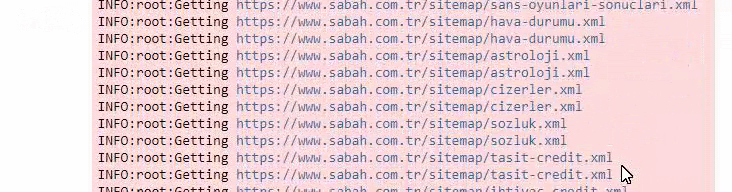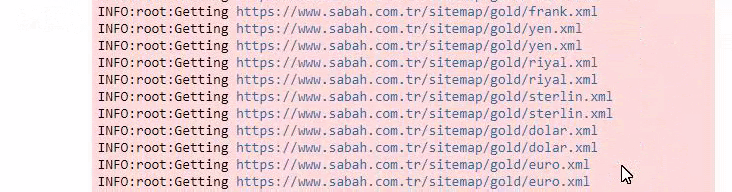
我们可能会看到他们对相同的 URL 类别有不同的站点地图,例如黄金、信用、货币、标签、祈祷时间和药房工作时间等……
简而言之,我们可以通过关注 URL 的子类别来实现这些细节。 而不是通过变量统一不同的站点地图。 所以,我用 Advertools 的 sitemap_to_df() 方法统一了所有的站点地图,就像文章开头一样。
我们还可以使用 Elias Dabbas 创建的另一组函数来创建更好的数据框。 如果您检查 dataset_utilites 函数,您可以看到一些示例。 下面的代码通过样式化给出了指定 URL 正则表达式的总数和百分比以及累积总和。
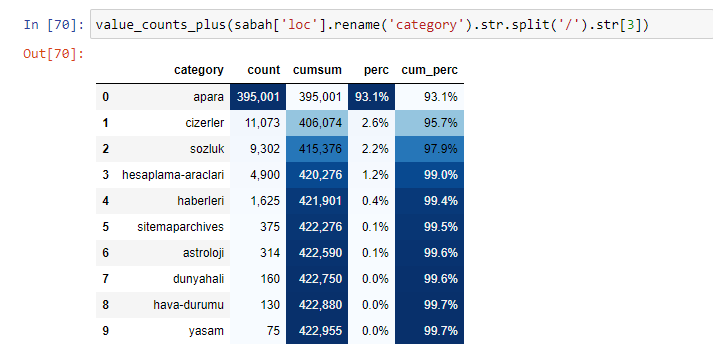
如果我们对 Sabah Newspaper 的子 URL 细分做同样的事情,我们将得到以下结果。
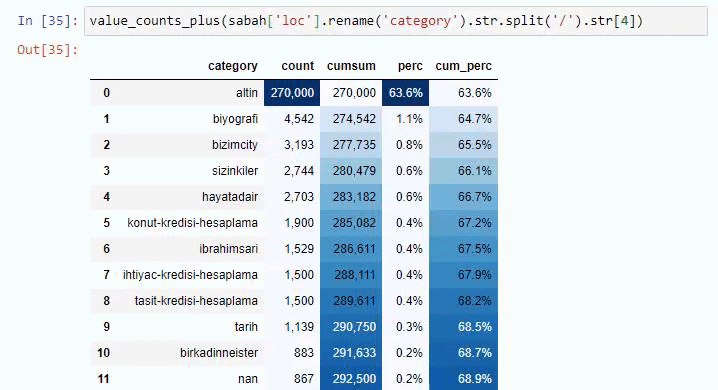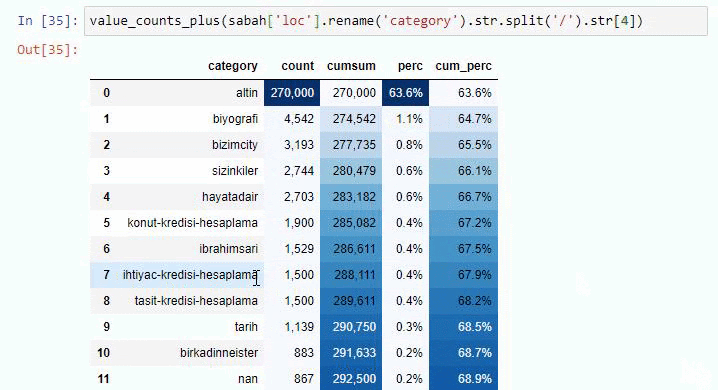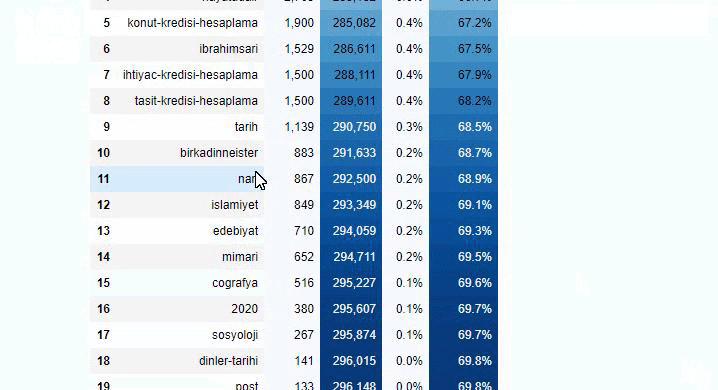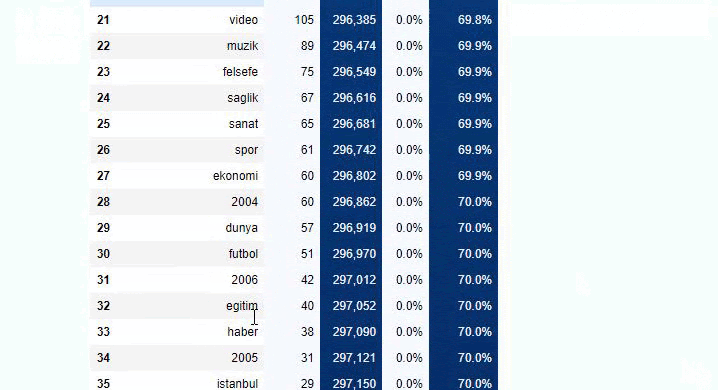
您可以通过更改下面的行来增加相关函数将输出的行数。 此外,如果您检查函数的内容,您会发现它与我们之前使用的类似。
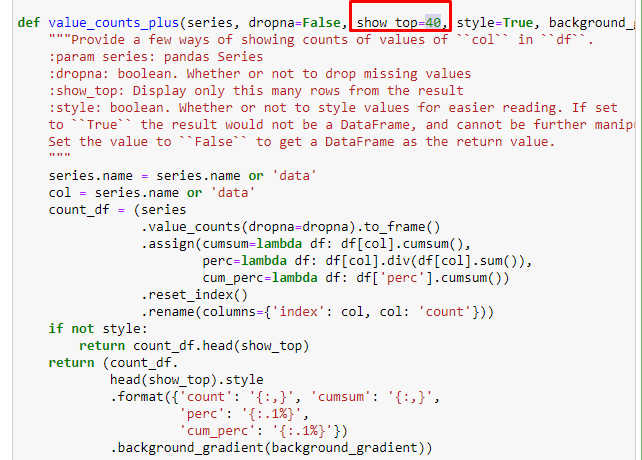
在细分中,我们看到了不同的细分,例如“宗教历史”、“传记”、“城市名称”、“足球”、“Bizimcity(漫画)”、“抵押贷款”。 最大的细分是“黄金”类别。
那么,一份报纸怎么会有 295,000 个黄金价格的 URL 呢?
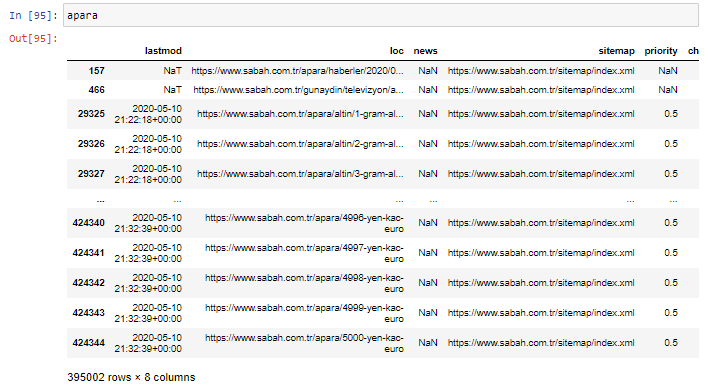
首先,我将沙巴报纸的第一个 URL 细分中包含“apara”的所有 URL 放入一个变量中。
apara = sabah[sabah['loc'].str.contains('apara')]
结果如下:
我们还可以使用 .filter() 方法过滤列:
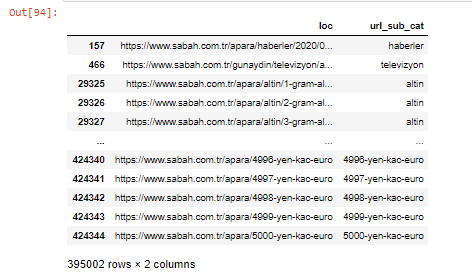
现在,我们可以在 DataFrame 的底部看到为什么 Sabah Newspaper 有过多的 Apara URL,因为他们为每笔货币计算(例如 5000 欧元、4999 欧元、4998 欧元等等)打开了不同的网页……
但是,在得出任何结论之前,我们需要确定,因为这些 URL 中有超过 250,000 个属于“altin (gold)”类别。
apara.filter(['loc', 'url_sub_cat' ]).tail(60) 将显示这个数据框的最后 60 行:

我们可以对 Apara 组中的黄金 URL 细分执行相同的操作。
金 = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
至此,我们看到《沙巴报》已经打开了 5000 个不同的页面,将每种货币兑换成美元、欧元、黄金和 TL(土耳其里拉)。 1 到 5000 之间的每个货币单位都有一个单独的计算页面。您可以在下面看到黄金组的前 85 行和后 85 行的示例。 每克黄金价格都打开了一个单独的页面。


我们毫不怀疑这些页面是不必要的,有很多重复的内容,而且过大,但沙巴报纸是这样一个品牌强大的网站,谷歌几乎在每个查询中都继续显示它,排名靠前。
在这一点上,我们也可以看到,对于一个具有高权限的旧新闻网站,Crawl Cost Tolerance 是很高的。
但是,这并不能解释为什么黄金类别的 URL 比其他类别多。
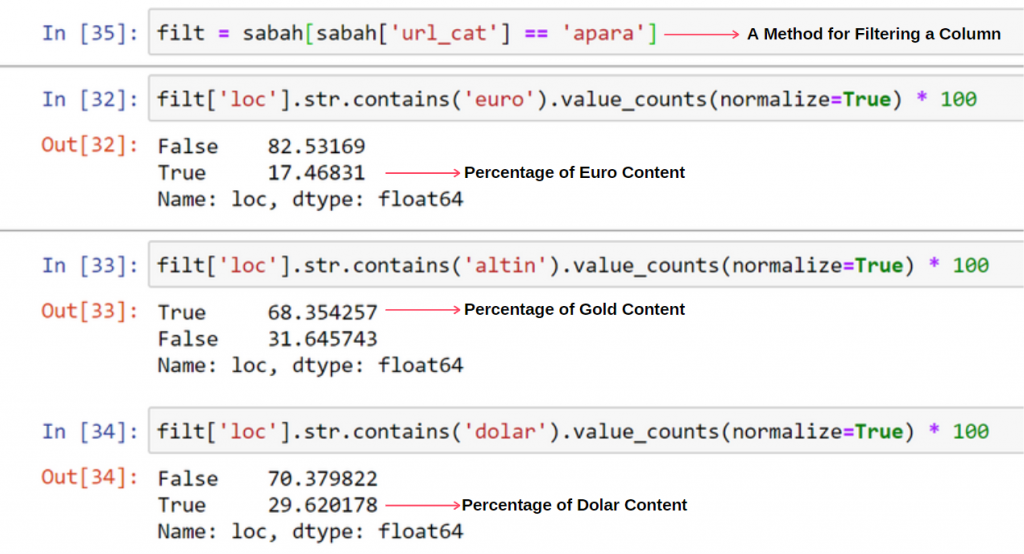
我没有看到重叠值加起来超过 100% 有什么奇怪的地方。
除非我错过了什么?
正如您会注意到的,当我们将所有真值相加时,我们得到 115.16% 的结果。 原因如下。
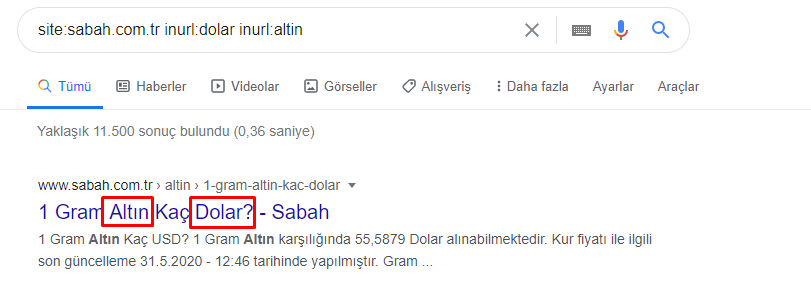
就连主队也有这样的交集。 我们也可以分析这些交叉点,但它可能是另一篇文章的主题。
我们看到 Apara URL 组中 68% 的内容与 GOLD 相关。
为了更好地理解这种情况,我们需要做的第一件事是扫描黄金折射中的 URL。
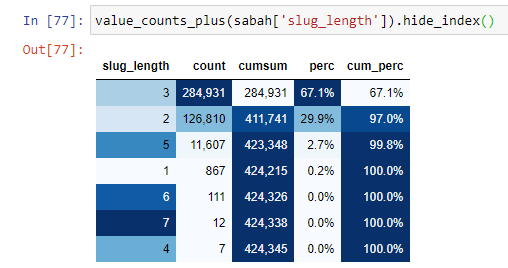
当我们根据自根部分以来的“/”数量对 URL 进行分类时,我们看到最多 3 个中断的 URL 的数量很高。 当我们分析这些 URL 时,我们看到 3 个 slug_length URL 中有 270.000 个属于 Gold 类别。
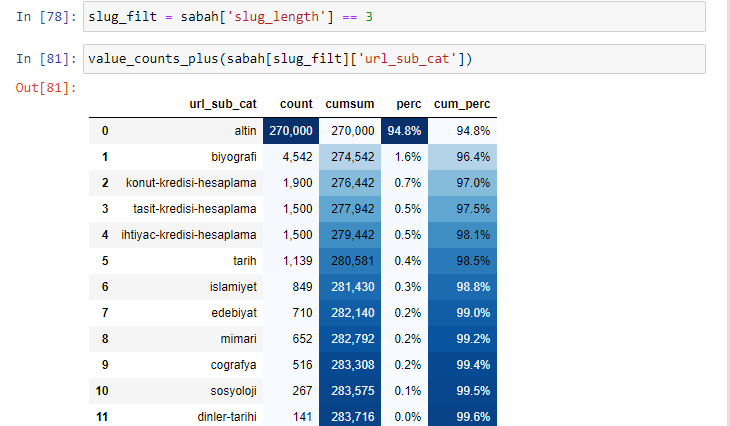
Morning_filt = Morning ['slug_length'] == 3 表示你只从某个数据帧的某一列的 int 数据类型的数据组中获取等于 3 的那些。 然后,基于这些信息,我们将适合条件的 URL 用计数、总和和聚合率与累积总和框起来。
当我们提取黄金 URL 中最常用的词时,我们会遇到代表“full”、“republic”、“quarter”、“gram”、“half”、“ancestor”的词。 Ata 和共和国黄金类型是土耳其独有的。 其中一位代表土耳其主权,另一位是共和国的创始人凯末尔·阿塔图尔克。 这就是他们的查询搜索量很高的原因。
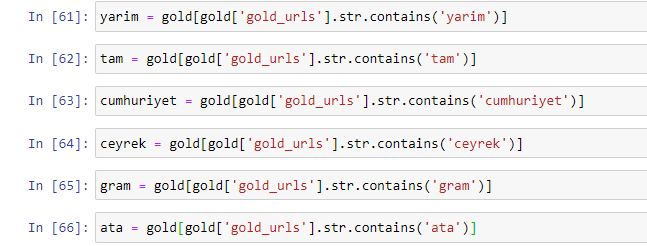
首先,我们删除了 URL 中的常用词,并将它们分配给单独的变量。 接下来,我们将在 Gold DataFrame 中使用这些变量来创建特定于其类型的列。
通过变量创建新列后,我们必须将它们与布尔值一起过滤。
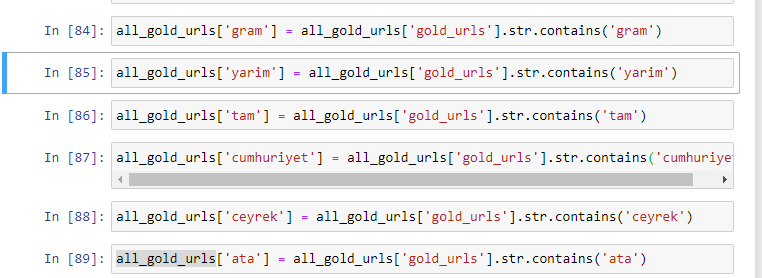
如您所见,我们能够将所有黄金 URL 分类为 270,000 行和 6 列。 黄金专用页面数量众多的主要原因是美元或欧元没有单独的类型,而黄金有单独的类型。 同时,由于传统上对土耳其人民的信任,黄金与不同货币之间的跨页多样性高于其他货币。
在我看来,所有类型的金页都应该平均分配,对吧?
我们可以使用 Seaborn 的 Heatmap 功能轻松测试这一点。
将 seaborn 导入为 sns
将 matplotlib.pyplot 导入为 plt
plt.figure(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.show()
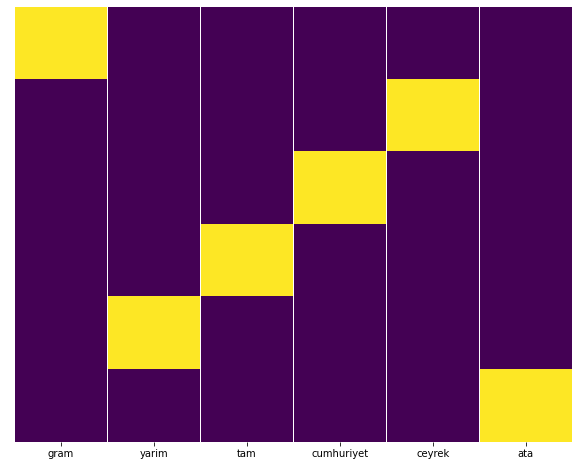
在热图上,每列中的真值都被简单地标记了。 可以看出,每一个的大小都是相互对称的,在地图上排列整齐。
因此,我们对 Sabah.com.tr 报纸关于货币和货币计算的内容政策采取了广泛的视角。
将来,我将根据 Elias Dabbas 推出的 Sitemaps Kaggle 编写土耳其新闻网站及其内容策略,但在本文中,我们已经充分讨论了使用站点地图在大型和小型网站上可以发现的内容.
结论和要点
我想我们已经看到了理解一个网站是多么容易,这要归功于流畅和语义化的 URL 结构。 我们还应该记住正确的 URL 结构对 Google 的价值。
未来,我们会看到越来越多的 SEO 越来越熟悉数据科学、数据可视化、前端编程等等……我认为这个过程是一个不可避免的变化的开始:SEO 和开发人员之间的差距将完全缩小几年内。
使用 Python,您可以更进一步地进行这种分析:可以从了解新闻网站的政治观点、谁写什么、多久写一次以及怀着什么样的心情来获取数据。 我不想在这里讨论这些,因为这些过程更多地是关于纯数据科学而不是 SEO(这篇文章已经很长了)。
但是,如果您有兴趣,可以通过站点地图和 Python 执行许多其他类型的审核,例如检查站点地图中 URL 的状态代码。
我期待着尝试和分享您可以使用 Python 和 Advertools 完成的其他 SEO 任务。