
理解人工智能:我们如何教授计算机自然语言
已发表: 2023-11-28自 20 世纪 50 年代以来,“人工智能”一词就一直与计算机相关,但直到去年,大多数人可能仍认为人工智能仍然更科幻,而不是技术现实。
OpenAI 的 ChatGPT 于 2022 年 11 月问世,突然改变了人们对机器学习能力的看法 - 但 ChatGPT 到底是什么让世界刮目相看并意识到人工智能已经大有作为?
简而言之,语言——ChatGPT 之所以让人感觉如此显着的飞跃,是因为它在自然语言方面表现得非常流利,这是聊天机器人从未有过的。
这标志着“自然语言处理”(NLP)的显着新阶段,即计算机解释自然语言并输出令人信服的响应的能力。 ChatGPT 建立在“大型语言模型”(LLM)之上,这是一种使用深度学习的神经网络,在海量数据集上进行训练,可以处理和生成内容。
“计算机程序是如何实现如此流畅的语言的?”
但我们是怎么到这里的呢? 计算机程序如何实现如此流畅的语言? 怎么听上去如此人性化?
ChatGPT 并不是凭空产生的——它建立在近几十年来无数不同的创新和发现的基础上。 ChatGPT 的一系列突破都是计算机科学的里程碑,但可以将它们视为模仿人类习得语言的阶段。
我们如何学习语言?
为了理解人工智能是如何达到这个阶段的,有必要考虑语言学习本身的本质——我们从单个单词开始,然后开始将它们组合成更长的序列,直到我们能够交流复杂的概念、想法和指令。
例如,儿童语言习得的一些常见阶段是:
- 全语阶段:9-18 个月期间,孩子们学会使用单个单词来描述他们的基本需求或愿望。 使用单个词进行交流意味着强调清晰度而不是概念完整性。 如果孩子饿了,他们不会说“我想要一些食物”或“我饿了”,而是简单地说“食物”或“牛奶”。
- 两个单词阶段:在 18-24 个月大的时候,孩子开始使用简单的两个单词分组来增强他们的沟通技巧。 现在,他们可以用“更多食物”或“读书”等表达方式来表达自己的感受和需求。
- 电报阶段:24-30 个月期间,儿童开始将多个单词串在一起形成更复杂的短语和句子。 使用的单词数量仍然很少,但正确的单词顺序和更多的复杂性开始出现。 孩子们开始学习基本的句子结构,例如“我想给妈妈看”。
- 多单词阶段:30个月后,孩子开始过渡到多单词阶段。 在这个阶段,孩子们开始使用语法更正确、复杂和多从句的句子。 这是语言习得的最后阶段,孩子们最终会用复杂的句子进行交流,例如“如果下雨,我想留在家里玩游戏”。
语言习得的第一个关键阶段之一是以非常简单的方式开始使用单个单词的能力。 因此,人工智能研究人员需要克服的第一个障碍是如何训练模型来学习简单的单词关联。
模型 1 – 使用 Word2Vec 学习单个单词(论文 1 和论文 2)
Word2Vec 是尝试以这种方式学习单词关联的早期神经网络模型之一,由 Tomaš Mikolov 和 Google 的一组研究人员开发。 2013年发表了两篇论文(可见这个领域发展得有多快。)
这些模型是通过学习将常用的单词关联起来来训练的。 这种方法建立在约翰·R·弗斯 (John R. Firth) 等早期语言学先驱的直觉之上,他指出意义可以从单词联想中得出:“你应该通过单词的陪伴来认识它。”
这个想法是,具有相似语义的单词往往更频繁地一起出现。 “猫”和“狗”这两个词通常比它们与“苹果”或“计算机”等词一起出现的频率更高。 换句话说,“猫”这个词与“狗”这个词应该比“猫”与“苹果”或“计算机”更相似。
Word2Vec 的有趣之处在于它是如何训练来学习这些单词关联的:
- 猜测目标单词:模型被给予固定数量的单词作为输入,但目标单词缺失,并且它必须猜测缺失的目标单词。 这称为连续词袋(CBOW)。
- 猜测周围的单词:模型被给予一个单词,然后负责猜测周围的单词。 这称为 Skip-Gram,与 CBOW 的方法相反,我们预测周围的单词。
这些方法的一个优点是,您不需要任何标记数据来训练模型 - 标记数据,例如将文本描述为“积极”或“消极”来教授情绪分析,毕竟是一项缓慢而费力的工作。
Word2Vec 最令人惊讶的事情之一是它通过相对简单的训练方法捕获了复杂的语义关系。 Word2Vec 输出表示输入单词的向量。 通过对这些向量进行数学运算,作者能够证明词向量不仅捕获语法上相似的元素,而且还捕获复杂的语义关系。
这些关系与词语的使用方式有关。 作者提到的例子是“King”和“Queen”以及“Man”和“Woman”等词之间的关系。
虽然这是向前迈出的一步,但 Word2Vec 也有局限性。 它的每个单词只有一个定义——例如,我们都知道“bank”可能有不同的含义,具体取决于你是打算持有一个还是从其中钓鱼。 Word2Vec 不在乎,它只是对“银行”一词有一个定义,并且会在所有上下文中使用它。
最重要的是,Word2Vec 无法处理指令甚至句子。 它只能将一个单词作为输入,并输出一个“单词嵌入”或向量表示,这是它为该单词学习的。 为了建立在这个单个单词的基础上,研究人员需要找到一种方法将两个或多个单词按顺序串在一起。 我们可以将其想象为类似于语言习得的两个单词阶段。
模型 2 – 使用 RNN 和文本序列学习单词序列
一旦孩子们开始掌握单个单词的用法,他们就会尝试将单词组合在一起来表达更复杂的想法和感受。 同样,NLP 发展的下一步是发展处理单词序列的能力。 处理文本序列的问题是它们没有固定的长度。 句子的长度可以从几个单词到很长的一段不等。 并非所有序列对于整体含义和上下文都很重要。 但我们需要能够处理整个序列,以了解哪些部分最相关。
这就是循环神经网络(RNN)出现的地方。
RNN 于 20 世纪 90 年代开发,其工作原理是在循环中处理其输入,其中先前步骤的输出在迭代序列中的每个步骤时通过网络进行。
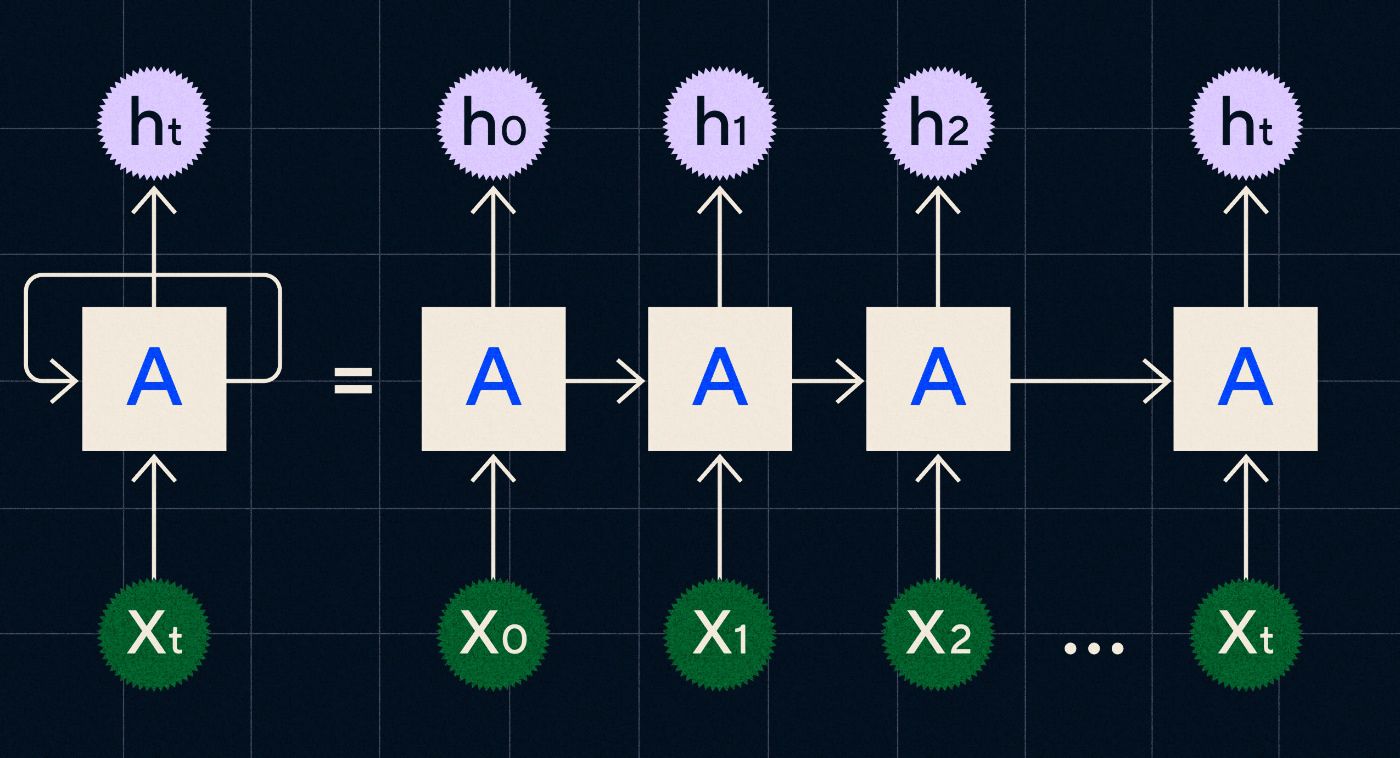
来源:Christopher Olah 关于 RNN 的博客文章
上图显示了如何将 RNN 描绘为一系列神经网络 (A),其中上一步的输出 (h0、h1、h2…ht) 被带入下一步。 在每个步骤中,网络也会处理新的输入(X0、X1、X2 … Xt)。
RNN(特别是长短期记忆网络,即 LSTM,Sepp Hochreiter 和 Jurgen Schmidhuber 在 1997 年引入的一种特殊类型的 RNN)使我们能够创建可以执行更复杂任务(例如翻译)的神经网络架构。
2014年,谷歌的Ilya Sutskever(OpenAI联合创始人)、Oriol Vinyals和Quoc V Le发表了一篇论文,描述了序列到序列(Seq2Seq)模型。 本文展示了如何训练神经网络来获取输入文本并返回该文本的翻译。 您可以将其视为生成神经网络的早期示例,您给它一个提示,它会返回一个响应。 然而,任务是固定的,所以如果它接受了翻译训练,你就不能“提示”它做任何其他事情。
请记住,之前的模型 Word2Vec 只能处理单个单词。 因此,如果你向它传递一个像“牙医拔掉我的牙齿”这样的句子,它只会为每个单词生成一个向量,就好像它们不相关一样。
然而,顺序和上下文对于翻译等任务很重要。 您不能只翻译单个单词,您需要解析单词序列,然后输出结果。 这就是 RNN 使 Seq2Seq 模型能够以这种方式处理单词的地方。
Seq2Seq 模型的关键是神经网络设计,它使用两个背靠背的 RNN。 一个是编码器,它将文本输入转换为嵌入,另一个是解码器,它将编码器输出的嵌入作为输入:
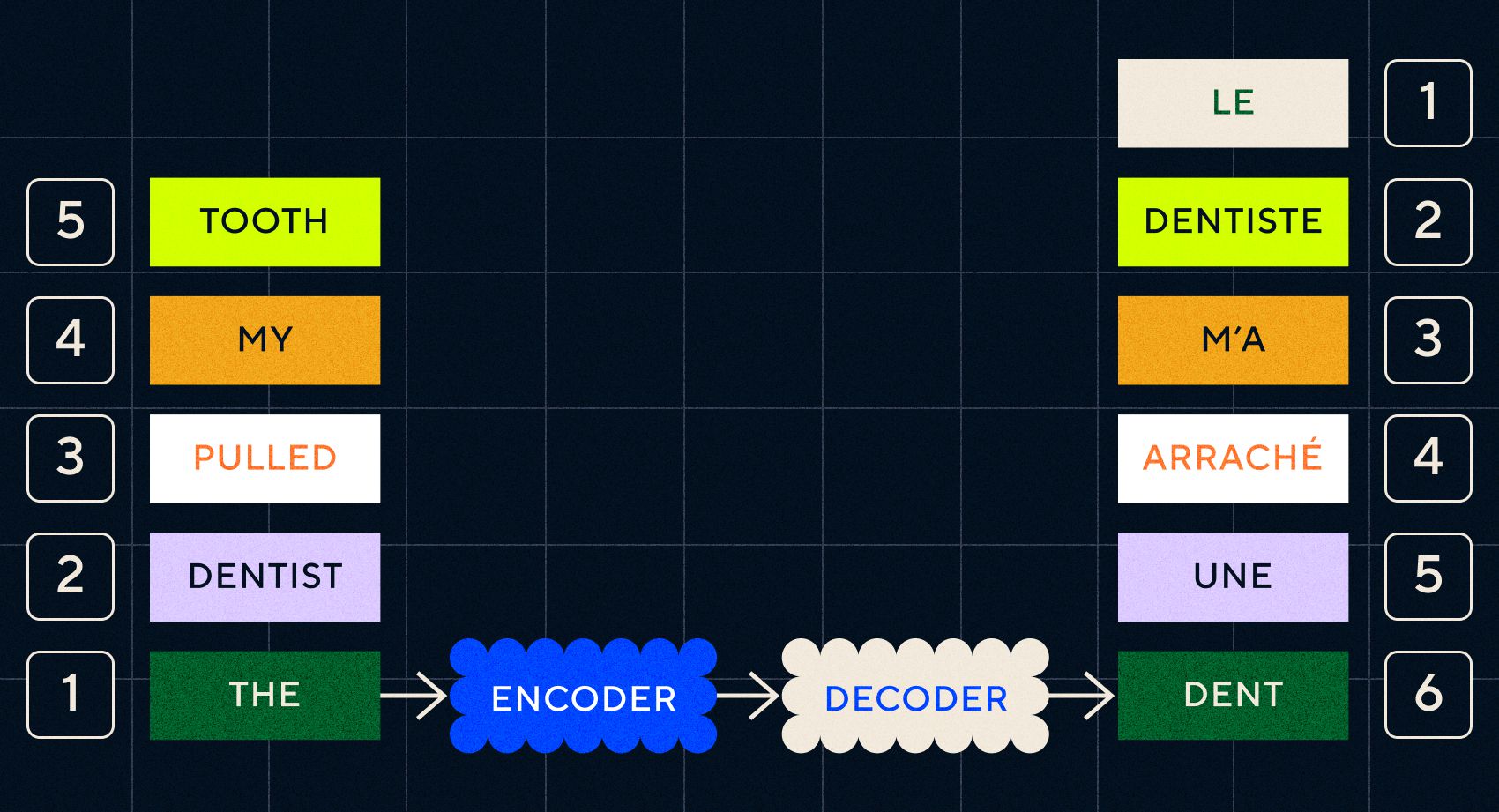
一旦编码器处理完每个步骤中的输入,它就会开始将输出传递给解码器,解码器将嵌入转换为翻译后的文本。
我们可以看到,随着这些模型的演变,它们开始以某种简单的形式类似于我们今天在 ChatGPT 中看到的模型。 然而,我们也可以看到相比之下这些模型有多么有限。 与我们自己的语言发展一样,要真正提高语言能力,我们需要确切地知道要注意什么,以便创建更复杂的短语和句子。
模型 3 – 通过注意力学习并使用 Transformer 进行扩展
我们之前注意到,电报阶段是孩子们开始用两个或更多单词创建短句的阶段。 这一语言习得阶段的一个关键方面是孩子们开始学习如何构建正确的句子。
RNN 和 Seq2Seq 模型帮助语言模型处理多个单词序列,但它们可以处理的句子长度仍然有限。 随着句子长度的增加,我们需要注意句子中的大部分内容。
例如,采用以下句子“房间里气氛太紧张,你可以用刀割它”。 那里发生了很多事情。 要知道我们在这里并不是真的用刀切割某物,我们需要在句子前面将“切割”与“张力”联系起来。
随着句子长度的增加,要知道哪些单词指的是哪个单词以推断正确的含义变得更加困难。 这就是 RNN 开始遇到限制的地方,我们需要一个新模型来进入语言习得的下一阶段。
“想象一下,当一段对话变得越来越长时,尝试用固定的字数来总结它。 每走一步,你都会开始丢失越来越多的信息”
2017 年,谷歌的一组研究人员发表了一篇论文,提出了一种技术,可以让模型更好地关注一段文本中的重要上下文。
他们开发的是一种让语言模型在处理文本输入序列时更轻松地查找所需上下文的方法。 他们将这种方法称为“变压器架构”,它代表了迄今为止自然语言处理领域的最大飞跃。
这种查找机制使模型更容易识别之前的哪些单词为当前正在处理的单词提供了更多上下文。 RNN 尝试通过传递每一步已处理过的所有单词的聚合状态来提供上下文。 想象一下,当对话变得越来越长时,尝试用固定的字数限制来总结对话。 每走一步,你都会开始丢失越来越多的信息。 相反,转换器根据单词(或标记,不是整个单词而是单词的一部分)对当前单词在上下文中的重要性进行加权。 这使得处理越来越长的单词序列变得更加容易,而不会出现 RNN 中出现的瓶颈。 这种新的注意力机制还允许并行处理文本,而不是像 RNN 那样顺序处理。

因此,想象一下这样的句子:“动物没有过马路,因为它太累了”。 对于 RNN,它需要在每一步表示所有先前的单词。 随着“it”和“animal”之间的单词数量增加,RNN 识别正确的上下文变得更加困难。
借助 Transformer 架构,模型现在能够查找最有可能指代“it”的单词。 下图显示了 Transformer 模型在尝试处理句子时如何能够专注于文本的“动物”部分。
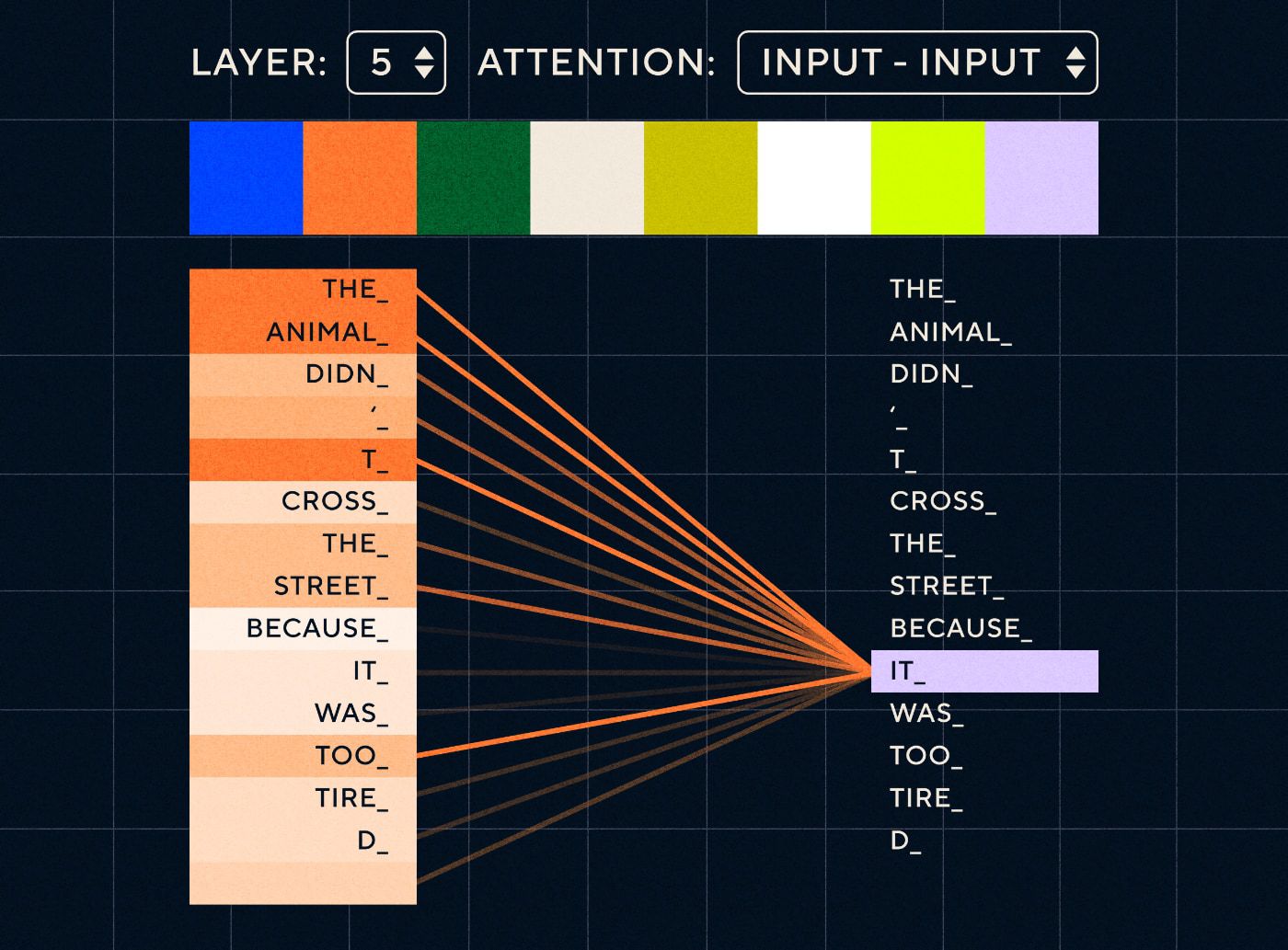
资料来源:《变形金刚图解》
上图显示了网络第 5 层的注意力。 在每一层,模型都在建立对句子的理解,并“关注”输入的特定部分,它认为该部分与当时正在处理的步骤更相关,即它更多地关注“动物”作为这一层中的“它”。 来源:图解变压器
把它想象成一个数据库,它可以检索得分最高的单词,该单词最有可能与“it”相关。
随着这种发展,语言模型不再局限于解析短文本序列。 相反,您可以使用更长的文本序列作为输入。 我们知道,通过“参与式对话”让孩子接触更多单词有助于改善他们的语言发展。
同样,通过新的注意力机制,语言模型能够解析更多、更多样化类型的文本训练数据。 这包括维基百科文章、在线论坛、Twitter 以及您可以解析的任何其他文本数据。 与童年发展一样,接触所有这些单词及其在不同上下文中的使用有助于语言模型发展新的、更复杂的语言能力。
正是在这个阶段,我们开始看到一场规模竞赛,人们向这些模型投入越来越多的数据,看看他们能学到什么。 这些数据不需要由人类标记——研究人员只需在互联网上抓取数据并将其输入模型,看看它学到了什么。
“像 BERT 这样的模型打破了所有可用的自然语言处理记录。 事实上,用于这些任务的测试数据集对于这些变压器模型来说太简单了”
出于几个原因,BERT(来自 Transformers 的双向编码器表示)模型值得特别提及。 它是最早利用作为 Transformer 架构核心的注意力特征的模型之一。 首先,BERT 是双向的,因为它可以查看当前输入左侧和右侧的文本。 这与只能从左到右顺序处理文本的 RNN 不同。 其次,BERT还使用了一种名为“掩蔽”的新训练技术,在某种程度上,通过“隐藏”或“掩蔽”随机标记迫使模型学习不同输入的含义,以确保模型无法“作弊”和在每次迭代中关注单个标记。 最后,BERT 可以进行微调以执行不同的 NLP 任务。 它不必从头开始接受这些任务的训练。
结果是惊人的。 像 BERT 这样的模型打破了所有可用的自然语言处理记录。 事实上,用于这些任务的测试数据集对于这些变压器模型来说太简单了。
现在我们有能力训练大型语言模型,作为新的自然语言处理任务的基础模型。 以前人们大多从头开始训练模型。 但现在像 BERT 和早期的 GPT 模型这样的预训练模型已经非常好了,你自己做就没有意义了。 事实上,这些模型非常好,人们发现它们可以用相对较少的示例执行新任务 - 它们被描述为“少样本学习者”,类似于大多数人不需要太多示例来掌握新概念。
这是这些模型及其语言能力发展的一个巨大转折点。 现在我们只需要更好地制作说明。
模型 4 – 使用 InstructGPT 学习指令
儿童在语言习得的最后阶段(多词阶段)学到的东西之一是使用功能词连接句子中携带信息的元素的能力。 功能词告诉我们句子中不同单词之间的关系。 如果我们想要创建指令,那么语言模型将需要能够创建包含捕获复杂关系的实词和虚词的句子。 例如,以下指令的功能词以粗体突出显示:
- “我想让你写一封信……”
- “告诉我你对上述文字的看法”
但在我们尝试训练语言模型遵循指令之前,我们需要准确了解它们已经了解的指令内容。
OpenAI 的 GPT-3 于 2020 年发布。这让我们得以一睹这些模型的能力,但我们仍然需要了解如何解锁这些模型的底层功能。 我们如何与这些模型交互以使它们执行不同的任务?
例如,GPT-3 表明,增加模型大小和训练数据可以实现作者所说的“元学习”——这就是语言模型开发广泛的语言能力的地方,其中许多能力是意想不到的,并且可以使用这些能力理解给定任务的技能。
“模型是否能够理解指令中的意图并执行任务,而不仅仅是简单地预测下一个单词?”
请记住,GPT-3 和早期的语言模型并不是为了培养这些技能而设计的——它们主要被训练来预测文本序列中的下一个单词。 但是,通过 RNN、Seq2Seq 和注意力网络的进步,这些模型能够处理更长序列中的更多文本,并更好地关注相关上下文。
您可以将 GPT-3 视为一项测试,看看我们能走多远。 我们可以制作多大的模型以及可以为其提供多少文本? 然后,完成此操作后,我们可以使用输入文本作为指令,而不是仅仅向模型提供一些输入文本来完成。 该模型是否能够理解指令中的意图并执行任务,而不仅仅是简单地预测下一个单词? 在某种程度上,这就像试图了解这些模型已经达到了语言习得的哪个阶段。
我们现在将其描述为“提示”,但在 2020 年,即该论文发表时,这是一个非常新的概念。
幻觉和对齐
正如我们现在所知,GPT-3 的问题在于它不能很好地遵循输入文本中的指令。 GPT-3可以遵循指令,但很容易失去注意力,只能理解简单的指令,并且容易胡编乱造。 换句话说,这些模型与我们的意图并不“一致”。 所以现在的问题不在于提高模型的语言能力,而在于他们遵循指令的能力。
值得注意的是,GPT-3 从未真正接受过指令训练。 没有人告诉它指令是什么,或者它与其他文本有何不同,或者它应该如何遵循指令。 在某种程度上,它通过像其他文本序列一样“完成”提示来“欺骗”它遵循指令。 因此,OpenAI 需要训练一个能够像人类一样更好地遵循指令的模型。 他们在 2022 年初发表的一篇题为“训练语言模型以遵循人类反馈指令”的论文中做到了这一点。同年晚些时候,InstructGPT 将被证明是 ChatGPT 的前身。
该论文中概述的步骤也用于训练 ChatGPT。 指导培训遵循 3 个主要步骤:
- 步骤 1 – 微调 GPT-3:由于 GPT-3 似乎在少样本学习方面表现得很好,因此我们的想法是,如果在高质量的教学示例上对其进行微调会更好。 目标是更容易地将指令中的意图与生成的响应保持一致。 为了做到这一点,OpenAI 让人类贴标者对使用 GPT-3 的人提交的一些提示做出响应。 作者希望通过使用真实的指令来捕获用户试图让 GPT-3 执行的任务的真实“分布”。这些指令用于微调 GPT-3,以帮助其提高即时响应能力。
- 第 2 步 – 让人们对新的和改进的 GPT-3 进行排名:为了评估经过微调的新指令 GPT-3,贴标签者现在在没有预定义响应的情况下对不同提示下的模型性能进行评级。 该排名与重要的一致性因素相关,例如有帮助、诚实、无毒、有偏见或有害。 因此,给模型一个任务,并根据这些指标评估其性能。 然后,使用此排名练习的输出来训练一个单独的模型,以预测贴标者可能更喜欢哪些输出。 该模型称为奖励模型(RM)。
- 步骤 3 – 使用 RM 训练更多示例:最后,RM 用于训练新的指令模型,以更好地生成符合人类偏好的响应。
要完全理解人类反馈强化学习 (RLHF)、奖励模型、策略更新等方面的情况是很棘手的。
一种简单的思考方式是,它只是一种使人类能够生成如何遵循指令的更好示例的方法。 例如,想象一下您将如何尝试教孩子说谢谢:
- 家长:“当有人给你X时,你说谢谢”。 这是第 1 步,提示和适当响应的示例数据集
- 家长:“现在,你对 Y 说什么?”。 这是第 2 步,我们要求孩子做出回应,然后家长对此进行评分。 “是的,那很棒。”
- 最后,在随后的遭遇中,父母会根据未来类似场景中反应的好或坏例子来奖励孩子。 这是第 3 步,即发生强化行为。
就 OpenAI 而言,它所做的只是解锁 GPT-3 等模型中已经存在的功能,“但仅通过即时工程很难获得”,正如论文所述。
换句话说,ChatGPT 并不是真正学习“新”功能,而只是学习更好的语言“界面”来利用它们。
语言的魔力
ChatGPT 感觉像是一次神奇的飞跃,但它实际上是数十年来艰苦技术进步的结果。
通过回顾近十年来人工智能和自然语言处理领域的一些重大发展,我们可以看到ChatGPT是如何“站在巨人的肩膀上”的。 早期的模型首先学会识别单词的含义。 然后后续模型将这些单词组合在一起,我们可以训练它们执行翻译等任务。 一旦他们能够处理句子,我们就开发了一些技术,使这些语言模型能够处理越来越多的文本,并培养将这些学习应用到新的和不可预见的任务的能力。 然后,通过 ChatGPT,我们最终开发出了通过以自然语言格式指定指令来更好地与这些模型交互的能力。
“由于语言是我们思想的载体,那么教授计算机语言的全部力量会带来独立的人工智能吗?”
然而,NLP 的发展确实揭示了我们通常忽视的更深层次的魔力——语言本身的魔力以及我们作为人类如何获得它的魔力。
关于儿童最初如何学习语言仍然存在许多悬而未决的问题和争议。 还有一个问题是所有语言是否都有一个共同的底层结构。 人类是进化到使用语言的还是相反?
奇怪的是,随着 ChatGPT 及其后代改善其语言发展,这些模型可能有助于回答其中一些重要问题。
最后,由于语言是我们思想的载体,教授计算机语言的全部力量会导致独立的人工智能吗? 和生活中一样,还有很多东西需要学习。
