
使用 Wikipedia 和 Google Language API 破解主题图
已发表: 2019-08-27过去十年中我最喜欢的幻灯片之一是 Mark Johnstone 在 2014 年完成的,当时他还在 Distilled 工作。 该套牌被称为“如何制作更好的内容创意”,几年来我一直将其用作我的圣经,同时组建团队来进行内容推广的艰苦工作。
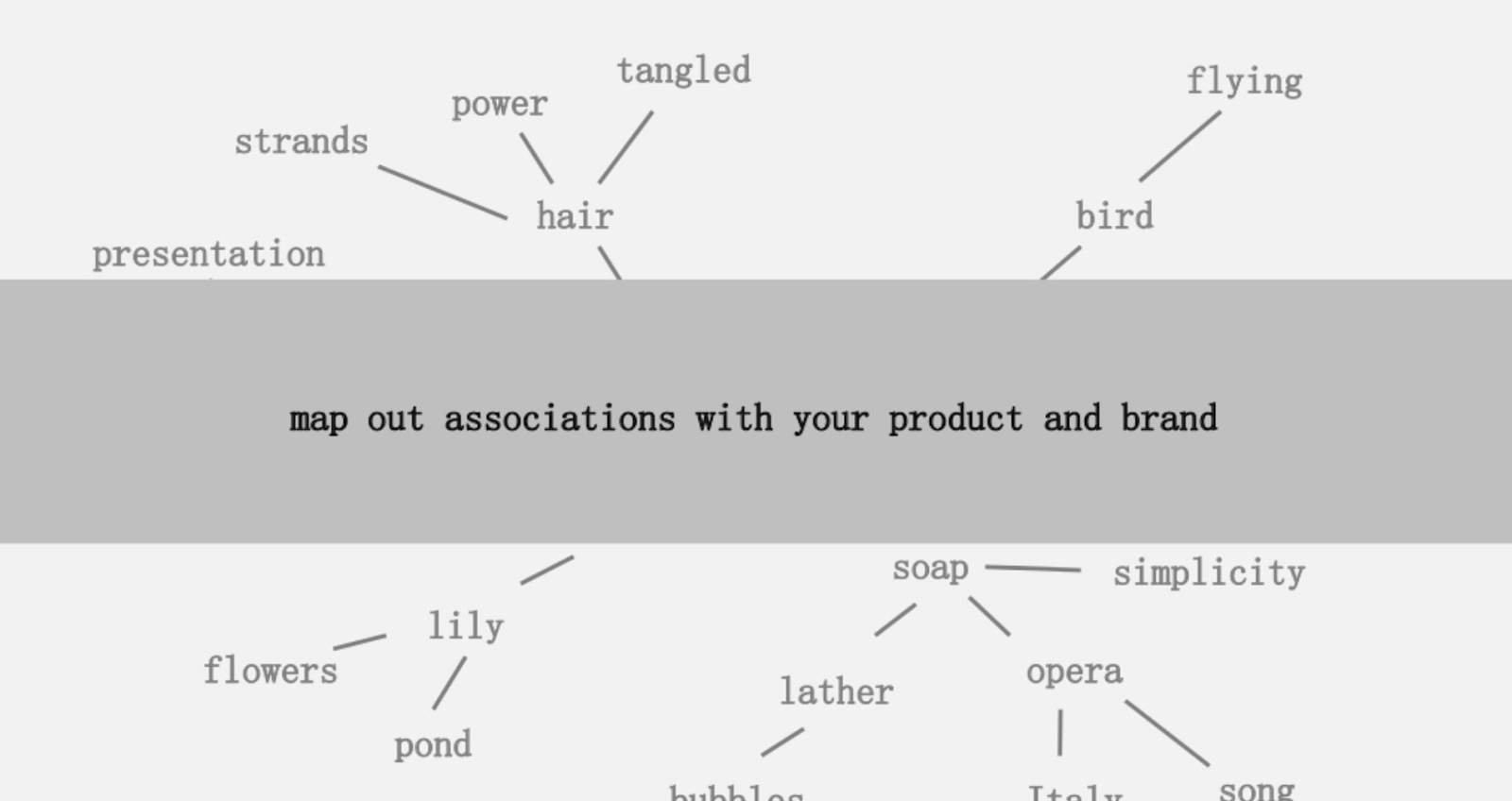
提供的想法之一是创建与您的产品或品牌相关联的单词的视觉映射,以便您可以退后一步,寻找将关联组合成有趣的方法。 目标是产生想法,他将其定义为“以增加价值的方式将以前未连接的元素组合在一起”。
在本文中,我们采用一种更左脑的方法,通过使用 Python、Google 的语言 API 以及 Wikipedia 来探索种子主题中存在的实体关联。 目标是沿着主题图对实体关系进行高级视图。 这篇文章不适合普通读者。 熟悉 Python 并至少具有基本编码能力的读者会发现它更有启发性。
理念
按照 Mark Johnstone 的映射想法,我认为让 Google 和 Wikipedia 从种子主题或网页开始定义主题结构会很有趣。 目标是在树状图中以可视方式构建与主要主题的关系映射,可以查看该图以寻找联系并可能产生内容创意。 下图代表了最初的设计理念。
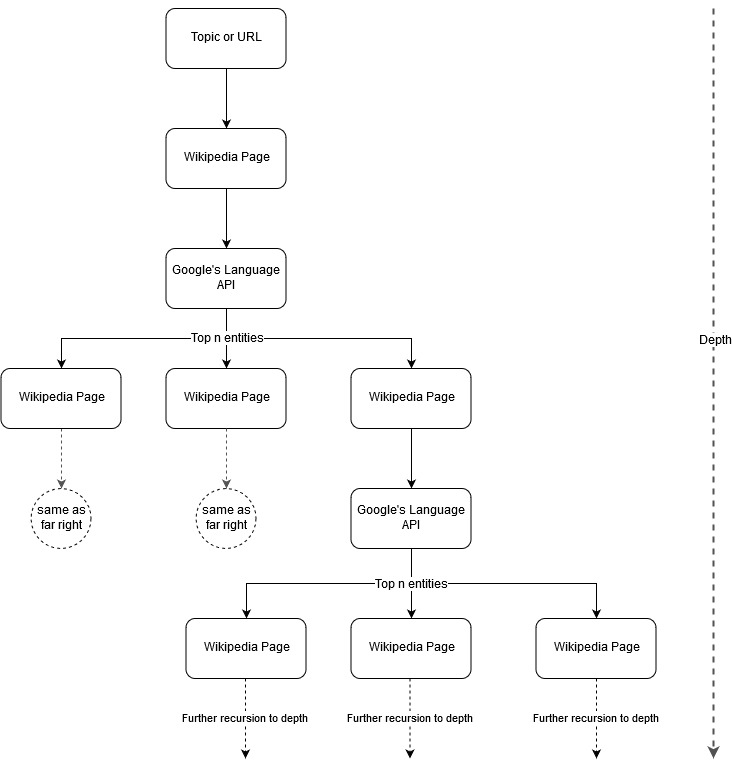
本质上,我们为工具提供了一个主题或 URL,并让 Google 的语言 API 为每个实体页面选择前 n 个(在我们的示例中为 3 个)实体(包括 Wikipedia URL),然后我们递归地为每个找到的实体构建一个网络图达到最大深度。
使用工具的背景
谷歌语言 API
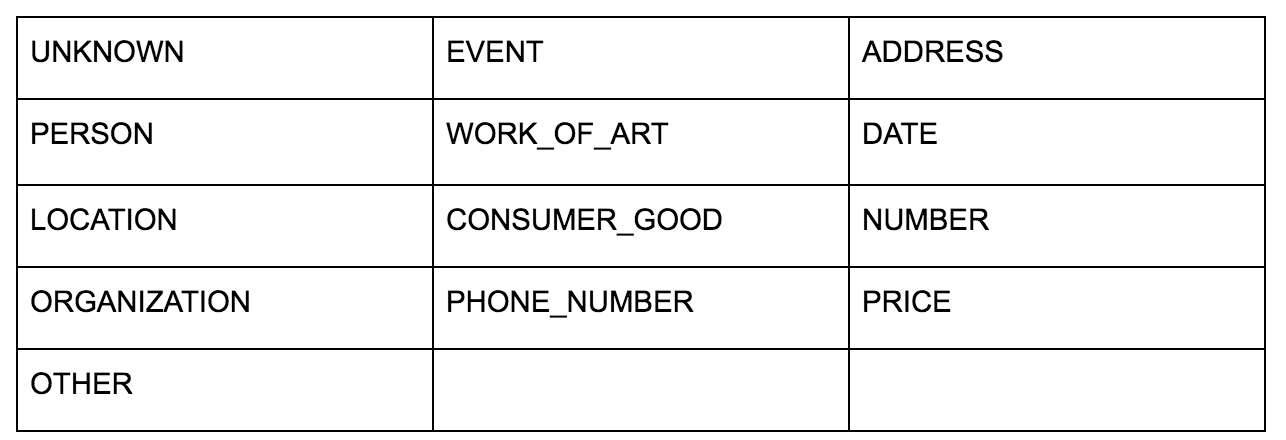
Google 的语言 API 允许您将纯文本或 HTML 传递给它,它会神奇地返回与内容相关的所有各种实体。 API 做的远不止这些,但是对于这个分析,我们将只关注这部分。 以下是它返回的实体类型列表:
长期以来,实体识别一直是自然语言处理 (NLP) 的基本部分,该任务的正确术语是命名实体识别 (NER)。 NER 是一项艰巨的任务,因为许多单词根据使用的上下文具有不同的含义,因此 NLP 工具或 API 必须了解术语周围的完整上下文,才能正确地将它们识别为特定实体。
如果您想在完成本文之前了解一些上下文,我在 opensource.com 上的一篇文章中给出了这个 API 的非常详细的概述,特别是实体。
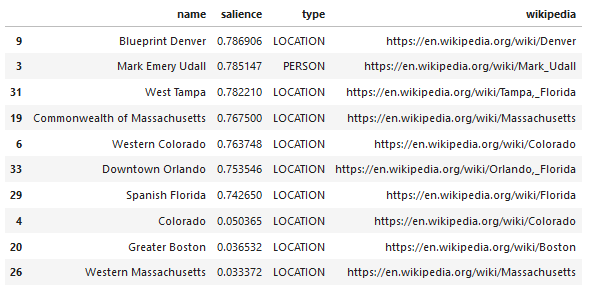
Google 语言 API 的一个有趣功能是,除了查找相关实体之外,它还标记它们与整个文档(显着性)的相关程度,并且对于某些人来说,它提供了代表实体的相关 Wikipedia(知识图)文章。
以下是 API 返回的示例输出(按显着性排序):
爬虫开发者
 学到更多
学到更多Python
Python 是一种在数据科学领域变得流行的软件语言,因为它拥有庞大且不断增长的库集,可以轻松地摄取、清理、操作和分析大型数据集。 它还受益于一个名为 Jupyter notebooks 的协作环境,它允许用户轻松地测试和注释他们的代码。
在本次审查中,我们将使用一些关键库,这将使我们能够使用 Google 的 NLP 数据做一些有趣的事情。
- Pandas:想象一下能够编写 Microsoft Excel 脚本来读取、保存、解析或重新排列电子表格,您就会了解 Pandas 的功能。 熊猫很棒。 (关联)
- Networkx: Networkx 是一种工具,用于构建定义节点之间关系的节点和边图。 它还具有对绘制图形的内置支持,因此它们易于可视化。 (关联)
- Pywikibot: Pywikibot 是一个库,允许您与 Wikipedia 交互以搜索、编辑、查找关系等,其中包含每个 Wikipedia 站点的所有内容。 (关联)
过程
我们在这里共享一个 Google Colab 笔记本,可用于跟进。 (特别感谢 Tyler Reardon 对文章和本笔记本进行了全面检查。)
配置
笔记本中的前几个单元处理安装一些库,使这些库可用于 Python,并分别为 Google 的语言 API 和 Pywikibot 提供凭据和配置文件。 以下是我们需要安装以确保该工具可以运行的所有库:
- 熊猫
- 要求
- httplib2
- 谷歌云语言
- pywikibot
- 网络x
- 验证者
- BS4
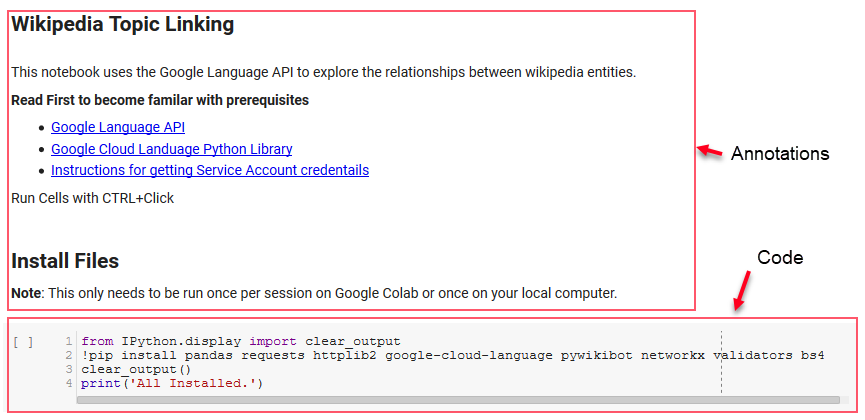
注意:能够运行此笔记本最困难的部分是从 Google 获取凭据以访问其 API。 对于那些没有这方面经验的人,这需要一个小时左右才能弄清楚。 我们在笔记本顶部链接了获取服务帐户凭据的说明以帮助您。 以下是我们如何包含我们的示例。
致胜的功能
在“为 Google NLP 定义一些函数”指示的单元格中,我们开发了 8 个函数来处理查询语言 API、与 Wikipedia 交互、提取网页文本以及构建和绘制图形等事务。 函数本质上是小的代码单元,它们接收一些设置数据,做一些工作,并产生一些东西。 所有的函数都被注释以告诉他们接受的变量,以及他们产生的东西。
测试 API
以下两个单元格获取一个 URL,从 URL 中提取文本,然后从 Google 的 Language API 中提取实体。 一个只提取具有 Wikipedia URL 的实体,另一个提取该页面中的所有实体。

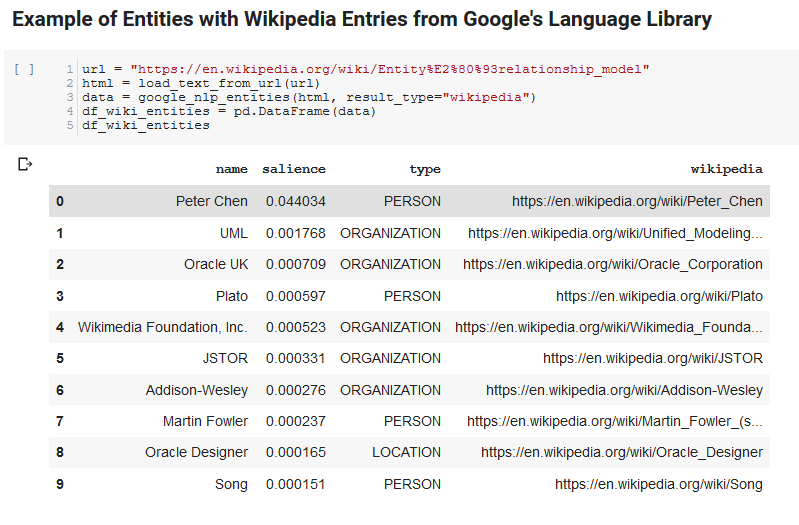
这是重要的第一步,只是为了使内容提取部分正确并了解语言 API 如何工作和返回数据。
网络x
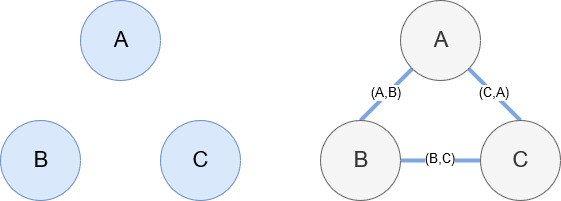
如前所述,Networkx 是一个很棒的库,使用起来相当直观。 本质上,您必须告诉它您的节点是什么以及节点是如何连接的。 例如,在下图中,我们给 Networkx 三个节点(A、B、C)。 然后我们告诉 Networkx 它们是由定义节点之间关系的边 (A,B)、(B,C)、(C,A) 连接的。 对于我们的使用,具有 Wikipedia URL 的实体将是节点,而边缘由在当前实体页面上找到的新实体定义。 因此,如果我们正在查看实体 A 的 Wikipedia 页面,并且在该页面上发现了实体 B,那么这就是实体 A 和实体 B 之间的边缘。
把它们放在一起
笔记本的下一部分称为Wikipedia Topic Branching by URL。 这就是魔法发生的地方。 我们之前已经定义了一个特殊的函数(recurse_entities),它通过谷歌语言 API 定义的新实体在 Wikipedia 上的页面中递归。 我们还添加了一个非常难以理解的函数 (hierarchy_pos),它是从 Stack Overflow 中提取出来的,它很好地呈现了具有许多节点的树状图。 在下面的单元格中,我们将输入定义为“搜索引擎优化”,并指定深度为 3(这是它递归跟踪的页面数)和限制为 3(这是它每页拉出多少个实体)。
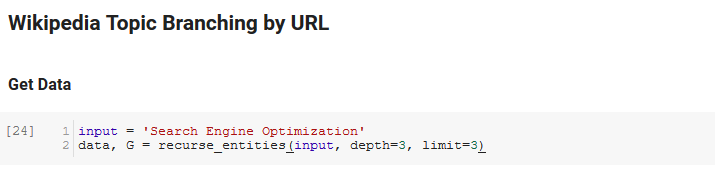
为“搜索引擎优化”一词运行它,我们可以看到该工具采用的以下路径,从维基百科的搜索引擎优化页面(0 级)开始,递归地跟踪页面直到指定的最大深度(3)。

然后我们获取所有找到的实体并将它们添加到 Pandas DataFrame 中,这使得保存为 CSV 变得非常容易。 我们按显着性(即实体对找到它的页面的重要性)对这些数据进行排序,但这个分数在这种情况下有点误导,因为它没有告诉您实体与原始术语的相关程度(“搜索引擎优化”)。 我们将把进一步的工作留给读者。

最后,我们绘制该工具构建的图形以显示所有实体的连通性。 在下面的单元格中,您可以传递给函数的参数是:( G :由 recurse_entities 函数预先构建的图形, w:绘图的宽度, h:绘图的高度, c:圆形的百分比绘图和文件名:保存到图像文件夹的 PNG 文件。)

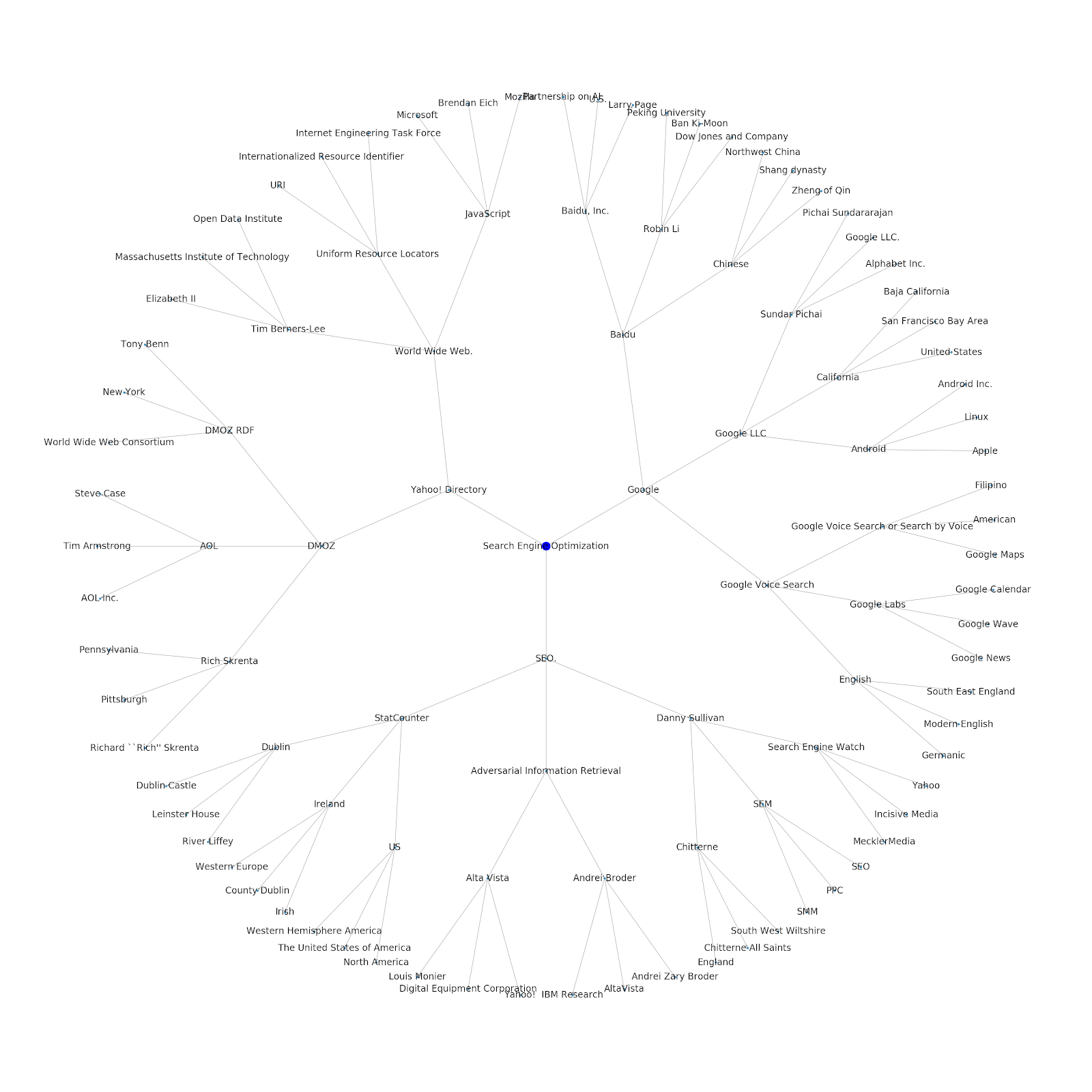
我们添加了为其提供种子主题或种子 URL 的功能。 在这种情况下,我们查看与 Google 的索引问题继续但这篇不同的文章相关的实体
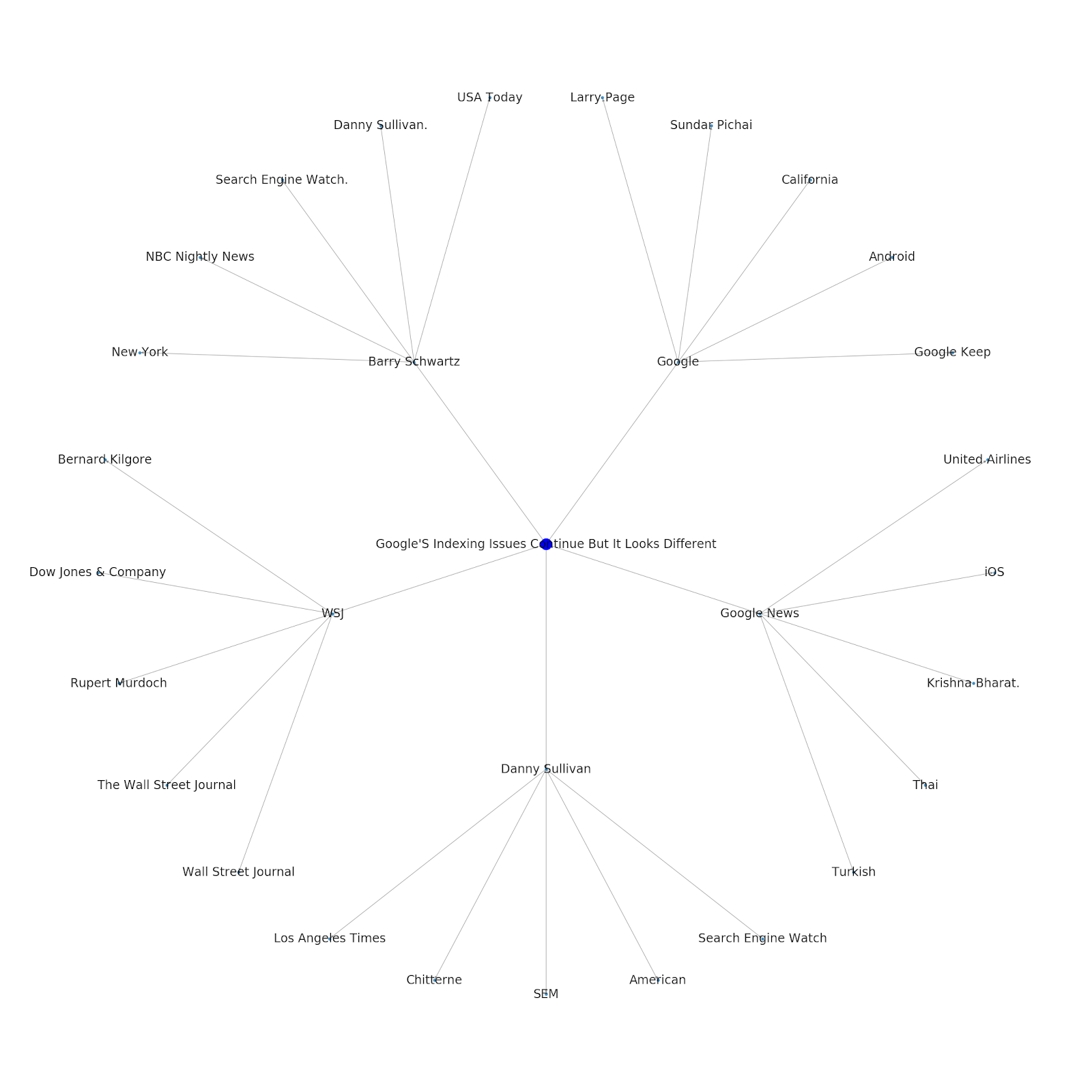
这是 Python 的 Google/Wikipedia 实体图。
这意味着什么
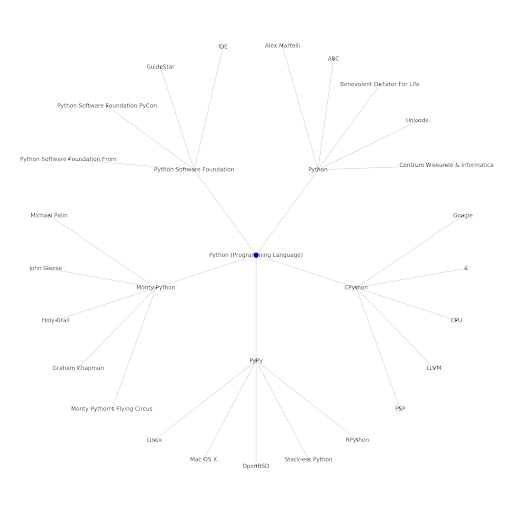
从 SEO 的角度来看,了解 Internet 的主题层很有趣,因为它迫使您考虑事物的连接方式,而不仅仅是单个查询。 由于谷歌正在使用这一层将个人用户的亲和力与主题相匹配,正如他们在谷歌发现重新引入中提到的那样,它可能成为以数据为中心的 SEO 的更重要的工作流程。 在上面的“Python”图中,可以推断出用户对与种子主题相关的主题的熟悉程度可能是他们对种子主题的专业水平的合理衡量标准。
下面的示例显示了两个用户,其中绿色突出显示了他们对相关主题的历史兴趣或亲和力。 左边的用户,了解 IDE 是什么,了解 PyPy 和 CPython 的含义,将比知道它是一种语言的人更有经验的 Python 用户,但仅此而已。 对于每个用户,这很容易转化为每个主题的数字分数。

结论
我今天的目标是分享一个非常标准的过程,我使用 Jupyter Notebooks 测试和审查各种工具或 API 的有效性。 探索主题图非常有趣,我们希望您发现共享的工具可以为您提供开始自己探索所需的良好开端。 使用这些工具,您可以构建探索许多关系级别的主题图,仅限于 Google 语言 API 的配额范围(每天 800,000 个)。 (更新:定价基于发送到 API 的 1,000 个 unicode 字符的单位,最多可免费使用 5k 个单位。由于 Wikipedia 文章可能会很长,因此您需要注意自己的花费。向 John Murch 致敬,指出这一点。)如果您对笔记本进行了增强或发现了有趣的案例,希望您能告诉我。 你可以在 Twitter 上的@jroakes 找到我。