
构建有效的 Robots.txt 的关键
已发表: 2020-02-18机器人程序,也称为爬虫或蜘蛛,是使用链接作为道路自动从一个网站“旅行”到另一个网站的程序。 尽管他们总是表现出一定的好奇心,robot.txt 文件可以是非常有效的工具。 谷歌和必应等搜索引擎使用机器人来抓取网络内容。 robots.txt 文件为不同的漫游器提供指导,说明它们不应在您的网站上抓取哪些页面。 您还可以从 robots.txt 链接到您的 XML 站点地图,以便机器人拥有它应该抓取的每个页面的地图。
为什么 robots.txt 有用?
在搜索引擎机器人的情况下,robots.txt 限制了机器人需要抓取和索引的页面数量。 如果您想避免 Google 抓取管理页面,您可以在 robots.txt 中阻止它们,以尝试将页面保留在 Google 服务器之外。
除了防止页面被索引外,robots.txt 还非常适合优化抓取预算。 抓取预算是 Google 确定将在您的网站上抓取的页面数。 通常权限多、页面多的网站比页面少、权限低的网站的爬取预算要大。 由于我们不知道为我们的网站分配了多少抓取预算,因此我们希望通过允许 Googlebot 访问最重要的网页而不是抓取我们不想被编入索引的网页来充分利用这段时间。
关于 robots.txt,您需要了解的一个非常重要的细节是,虽然 Google 不会抓取被 robots.txt 阻止的页面,但如果该页面是从其他网站链接的,它们仍然可以被编入索引。 要正确防止您的页面被编入索引并出现在 Google 搜索结果中,您需要对服务器上的文件进行密码保护,使用 noindex 元标记或响应标头,或完全删除页面(响应 404 或 410)。 有关抓取和控制索引的更多信息,您可以阅读 OnCrawl 的 robots.txt 指南。
[案例研究] 管理 Google 的机器人抓取
 阅读案例研究
阅读案例研究正确的 Robots.txt 语法
robots.txt 语法有时会有点棘手,因为不同的爬虫对语法的解释不同。 此外,一些信誉不佳的爬虫将 robots.txt 指令视为建议,而不是他们需要遵循的明确规则。 如果您的网站上有机密信息,除了使用 robots.txt 阻止爬虫外,使用密码保护也很重要
下面我列出了在处理 robots.txt 时需要牢记的一些事项:
- robots.txt 文件需要位于域下而不是子目录下。 爬虫不会检查子目录中的 robots.txt 文件。
- 每个子域都需要自己的 robots.txt 文件:
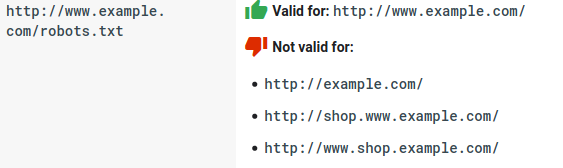
- Robots.txt 区分大小写:
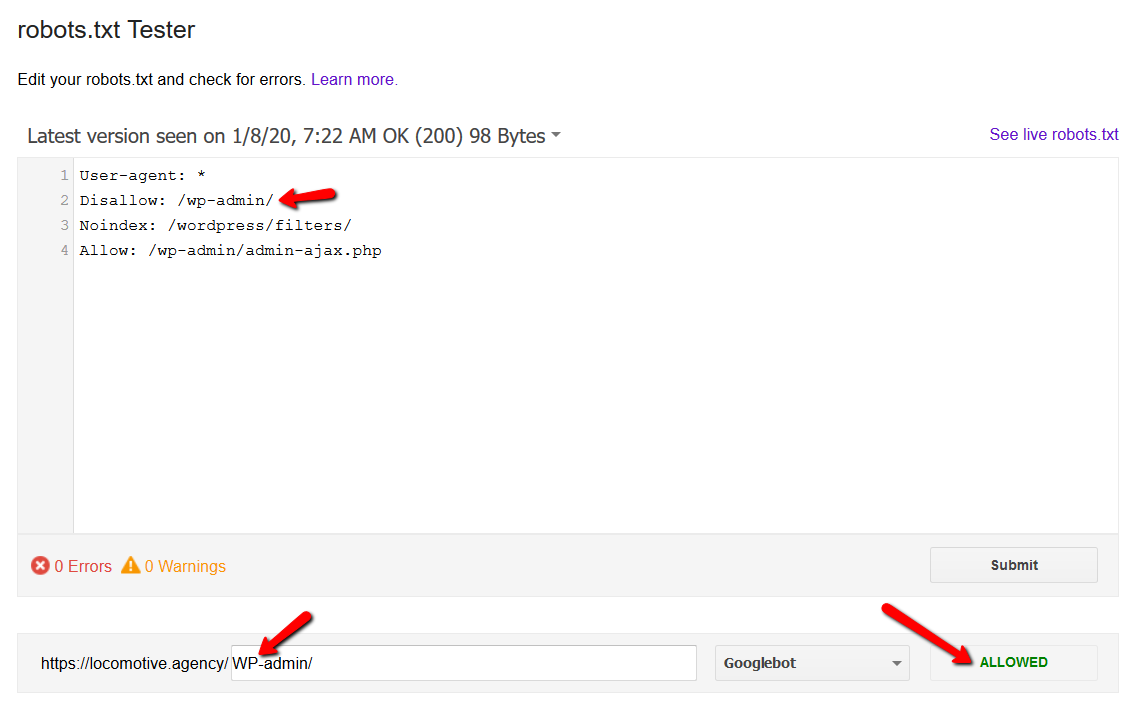
- noindex 指令:当您在 robots.txt 中使用 noindex 时,它的工作方式与 disallow 相同。 Google 将停止抓取该页面,但会将其保留在其索引中。 @jroakes 和我创建了一个测试,我们在文章 /wordpress/filters/ 上使用了 Noindex 指令,并在 Google 中提交了页面。 您可以在下面的屏幕截图中看到它显示 URL 已被阻止:
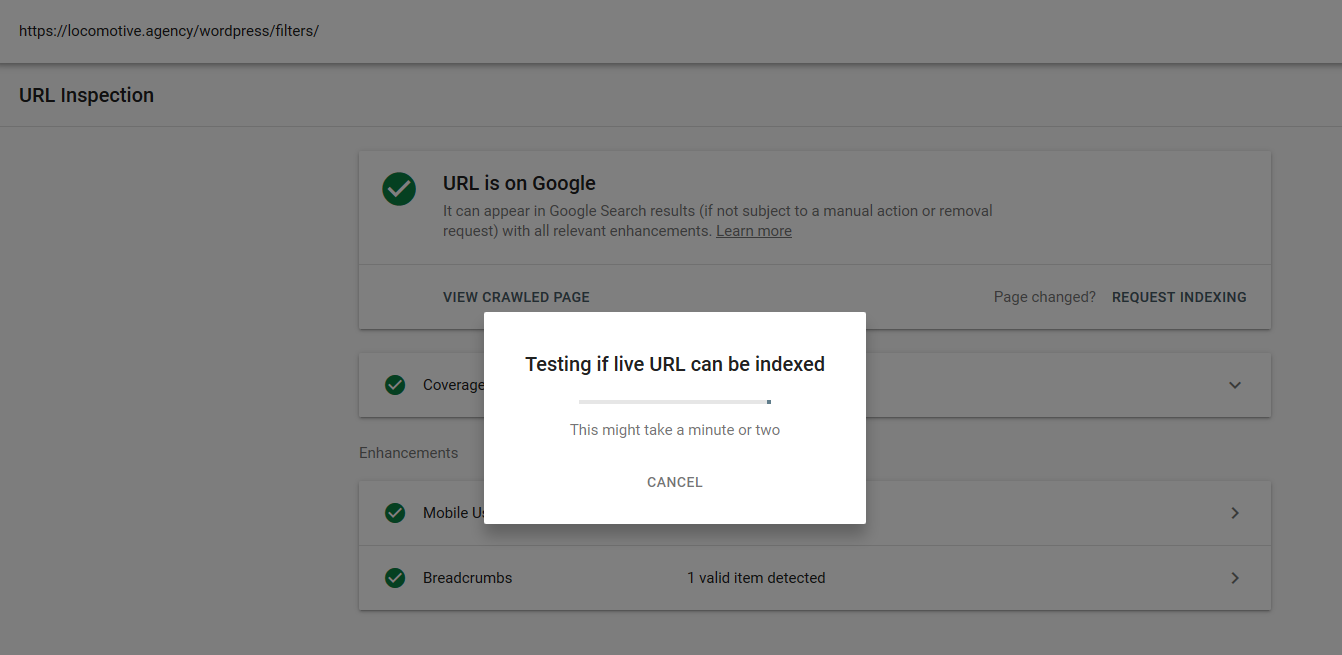
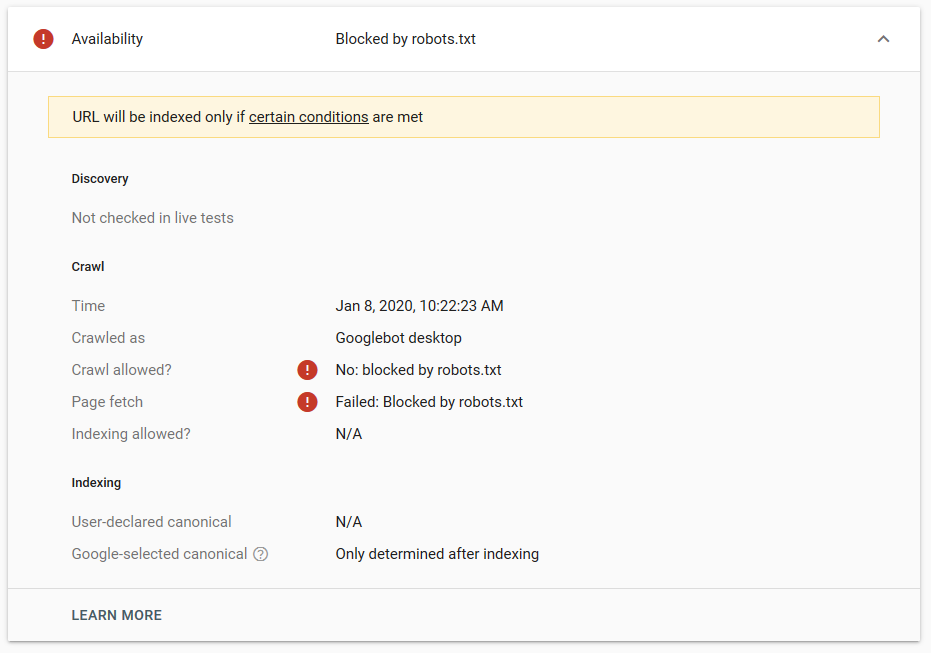
我们在 Google 中进行了几次测试,并且该页面从未从索引中删除:
去年有一个关于在 robots.txt 中工作的 noindex 指令的讨论,删除页面但谷歌。 这是 Gary Illyes 表示它正在消失的线程。 在这个测试中,我们可以看到谷歌的解决方案已经到位,因为 noindex 指令没有从搜索结果中删除页面。

最近,克里斯蒂安·奥利维拉(Christian Oliveira)在 Twitter 上发布了另一个有趣的帖子,他在其中分享了一些细节,以供在处理您的 robots.txt 时考虑。
- 如果我们想拥有通用规则和仅适用于 Googlebot 的规则,我们需要复制 User-agent: Google bot 规则集下的所有通用规则。 如果未包含它们,Googlebot 将忽略所有规则:

- 另一个令人困惑的行为是规则的优先级(在同一个用户代理组内)不是由它们的顺序决定的,而是由规则的长度决定的。
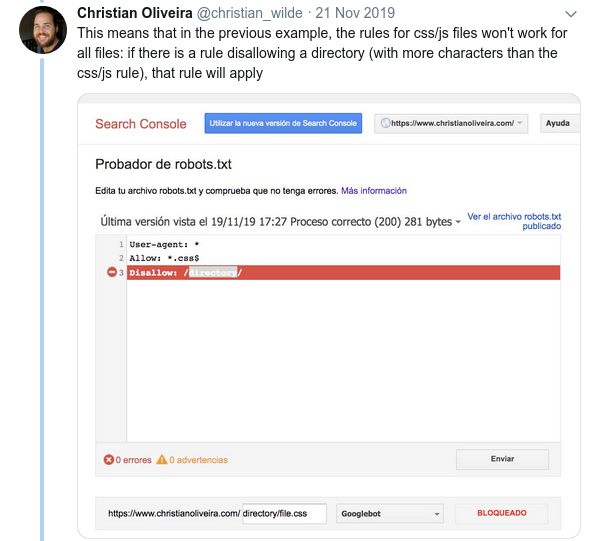
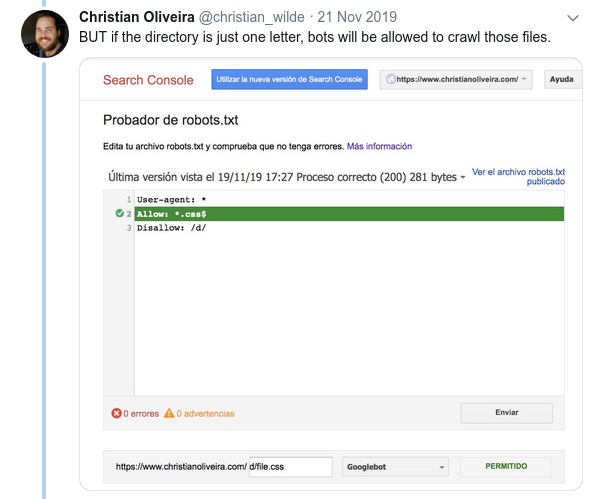
- 现在,当您有两条规则,具有相同的长度和相反的行为(一个允许爬行,另一个不允许爬行)时,限制较少的规则适用:
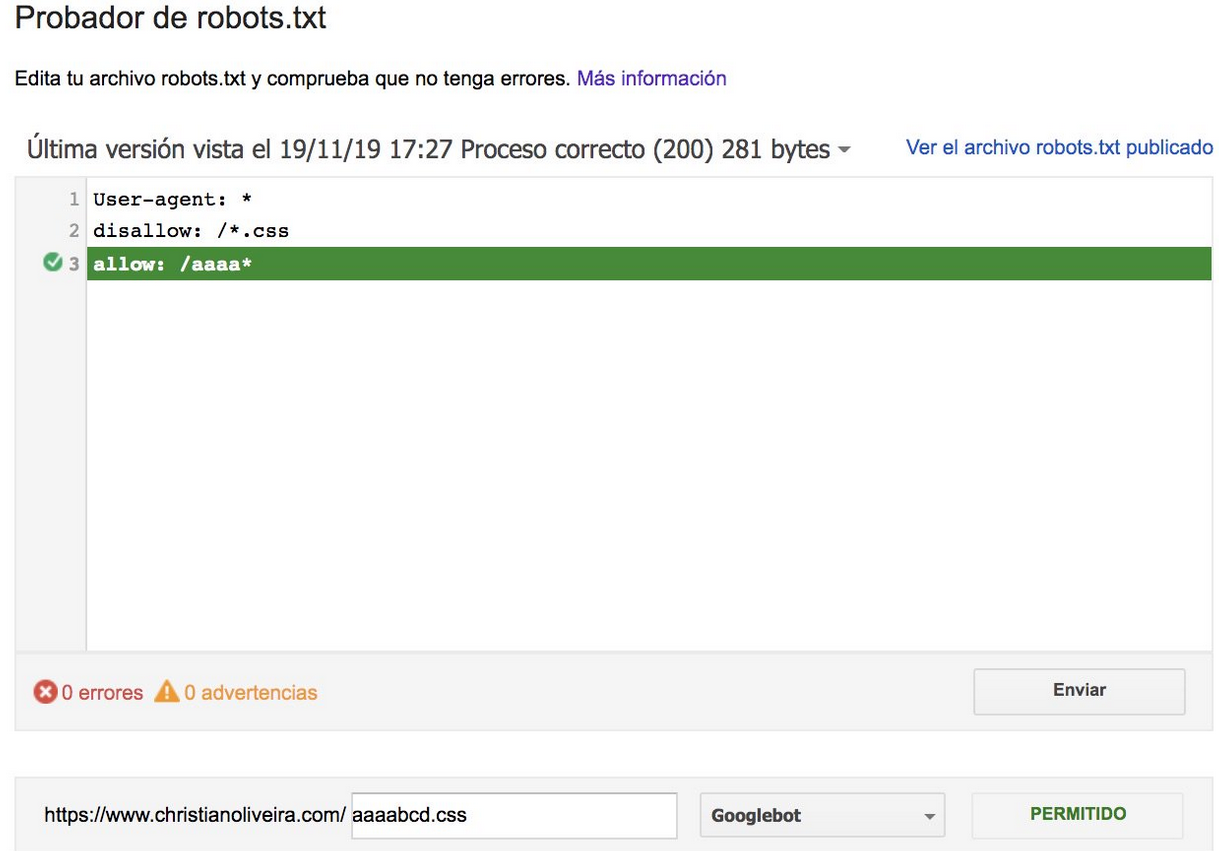
如需更多示例,请阅读 Google 提供的 robots.txt 规范。
测试您的 Robots.txt 的工具
如果你想测试你的 robots.txt 文件,有几个工具可以帮助你,如果你想自己制作,还有几个 github 存储库:
- 蒸馏的
- Google 已将旧 Google Search Console 中的 robots.txt 测试工具留在此处
- 在 Python 上
- 在 C++ 上
示例结果:有效使用 Robots.txt 进行电子商务
下面我介绍了一个案例,我们正在使用一个没有 robots.txt 文件的 Magento 站点。 Magento 和其他 CMS 都有管理页面和目录,其中包含我们不希望 Google 抓取的文件。 下面,我们包含了我们在 robots.txt 中包含的一些目录的示例:
## 通用 Magento 目录 禁止:/app/ 禁止:/下载器/ 不允许:/错误/ 禁止:/包括/ 禁止:/lib/ 禁止:/pkginfo/ 禁止:/shell/ 禁止:/var/ ##不索引搜索页面和未优化的链接类别 禁止:/catalog/product_compare/ 禁止:/catalog/category/view/ 不允许:/catalog/product/view/ 禁止:/catalog/product/gallery/ 禁止:/catalogsearch/
大量不打算被抓取的页面影响了他们的抓取预算,Googlebot 无法抓取网站上的所有产品页面。
您可以在下图中看到索引页面在 10 月 25 日(即 robots.txt 实施之时)之后如何增加:
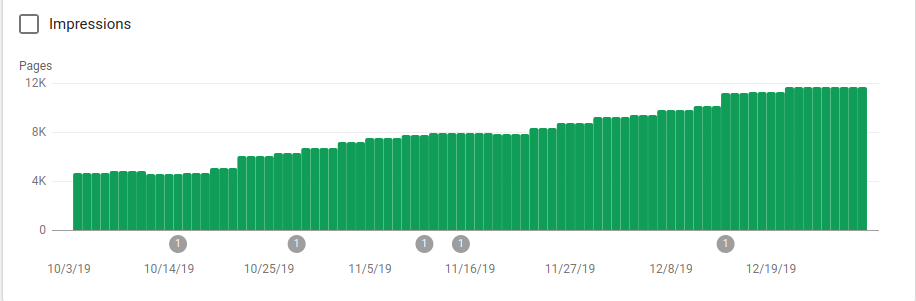
除了阻止几个不打算被抓取的目录之外,机器人还包括一个指向站点地图的链接。 在下面的屏幕截图中,您可以看到与排除的页面相比,索引页面的数量是如何增加的:
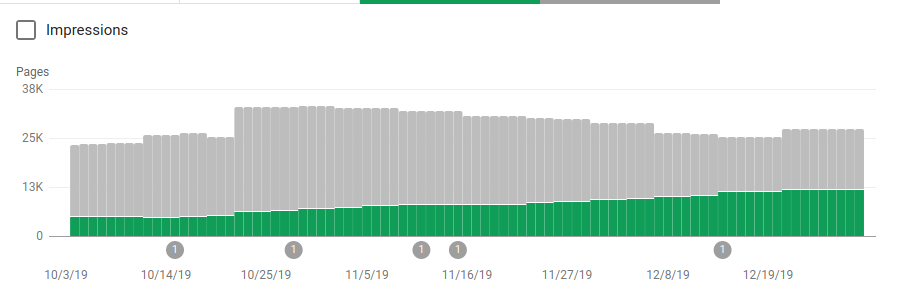
如绿色条所示,已编入索引的有效页面呈正趋势,而灰色条表示的排除页面呈负趋势。
包起来
robots.txt 的重要性有时会被低估,正如您从这篇文章中看到的那样,在创建一个文件时需要考虑很多细节。 但工作得到了回报:我已经展示了正确设置 robots.txt 可以获得的一些积极结果。