
在野外看到的 7 次 SEO 失败(以及如何避免它们)
已发表: 2022-06-12
我们经常收到人们的疑问,他们想知道为什么他们的网站没有排名,或者为什么它没有被搜索引擎索引。
最近,我遇到了几个存在重大错误的网站,只要所有者知道看,这些错误很容易修复。 虽然一些 SEO 错误非常复杂,但这里有一些经常被忽视的“撞头”错误。
因此,请查看这些 SEO 错误——以及如何避免自己犯这些错误。
SEO 失败 #1:Robots.txt 问题
robots.txt 文件功能强大。 它指示搜索引擎机器人从其索引中排除什么。
过去,我看到网站在重新设计网站后忘记从该文件中删除一行代码,并将整个网站置于搜索结果中。
因此,当花卉网站突出显示问题时,我会从我经常在网站上进行的第一项检查开始——查看 robots.txt 文件。
我想知道该网站的 robots.txt 是否阻止搜索引擎为其内容编制索引。 但是,我看到的不是预期的文本文件,而是一个向 Robots.Txt 提供鲜花的页面。
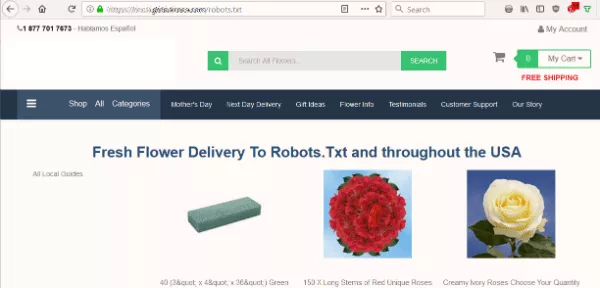
该网站没有 robots.txt,这是机器人在抓取网站时首先查找的内容。 那是他们的第一个错误。 但是把那个文件作为目的地……真的吗?
SEO 失败 #2:自动生成变得疯狂
其次,该网站会自动生成无意义的内容。 它可能会传递给圣诞老人或我在 URL 中输入的任何文本。
我运行了一个检查服务器页面工具来查看自动生成的页面显示的状态。 如果它是 404(未找到),那么机器人将忽略该页面。 但是,页面的服务器标头给出了 200 (OK) 状态。 结果,虚假页面为搜索引擎的索引打开了绿灯。
搜索引擎希望在每页看到独特且有意义的内容。 因此,索引这些非页面可能会损害他们的 SEO。
SEO失败#3:规范错误
接下来,我查看了搜索引擎对这个网站的看法。 他们可以抓取和索引页面吗?
查看各个页面的源代码,我注意到另一个重大错误。
每个页面都有一个指向主页的规范链接元素:
<link rel=”canonical” href=”https://www.domain.com/” />
换句话说,搜索引擎被告知每个页面实际上都是主页的副本。 基于此标签,机器人应该忽略该域上的其余页面。
幸运的是,谷歌足够聪明,可以找出这些标签何时可能被错误使用。 所以它仍然在索引网站的一些页面。 但是这个普遍的规范要求并没有帮助网站的搜索引擎优化。
如何避免这些 SEO 失败
对于花卉网站的多个错误,以下是修复:
- 有一个有效的 robots.txt 文件来告诉搜索引擎如何抓取和索引站点。 即使它是一个空白文件,它也应该存在于您的域的根目录中。
- 为每个页面生成适当的规范链接元素。 并且不要指向要编入索引的页面。
- 当页面 URL 不存在时显示自定义 404 页面。 确保它返回 404 服务器代码,以便向搜索引擎提供明确的信息。
- 小心自动生成的页面。 避免为搜索引擎和用户生成无意义或重复的页面。
即使您没有遇到网站问题,为了安全起见,这些都是定期检查的好点。
哦,永远不要在您的 404 页面上放置规范标签,尤其是指向您的主页……只是不要。
SEO失败#4:隔夜排名自由落体
有时,一个简单的改变可能是一个代价高昂的错误。 这个故事来自我们的一位 SEO 客户的经历。
当他们的域名的 .org 扩展名可用时,他们将其抢购一空。 到目前为止,一切都很好。 但他们的下一步行动导致了灾难。
他们立即设置了一个 301 重定向,将新获得的 .org 指向他们的主要 .com 网站。 他们的推理是有道理的——捕捉可能输入错误扩展名的任性访客。
但是第二天,他们打电话给我们,很疯狂。 他们的网站流量不存在。 他们不知道为什么。
一些快速检查显示,他们的搜索排名在一夜之间从谷歌中消失了。 不需要太多的问答就可以弄清楚发生了什么。
他们在不考虑风险的情况下进行了重定向。 我们进行了一些挖掘,发现 .org 有一段肮脏的过去。

.org 网站的前任所有者已将其用于垃圾邮件。 通过重定向,Google 将所有这些毒药分配给了公司的主站点! 我们只用了两天时间就恢复了该网站在 Google 中的地位。
如何避免这种 SEO 失败
始终研究您注册的任何域名的链接配置文件和历史记录。
合格的 SEO 顾问可以做到这一点。 您还可以运行一些工具来查看站点的壁橱中可能有哪些骷髅。
每当我选择一个新域名时,我喜欢让它休眠至少六个月到一年,然后再尝试使用它。 我希望搜索引擎能够清楚地区分我的网站的新版本与过去的版本。 这是保护您的投资的额外预防措施。
SEO失败#5:不会消失的页面
有时网站可能会遇到不同的问题——搜索索引中的页面太多。
搜索引擎有时会保留不再有效的页面。 如果人们在从搜索结果中进入错误页面时,这是一种糟糕的用户体验。
一些网站所有者出于挫败感,在 robots.txt 文件中列出了各个 URL。 他们希望谷歌能接受提示并停止索引它们。
但是这种方法失败了! 如果 Google 尊重 robots.txt,则不会抓取这些网页。 因此,Google 永远不会看到 404 状态,也不会发现页面无效。
如何避免这种 SEO 错误
修复的第一部分是不允许robots.txt 中的这些 URL。 您希望机器人四处爬行并知道应该从搜索索引中删除哪些 URL。
之后,在旧 URL 上设置 301 重定向。 将访问者(和搜索引擎)发送到网站上最近的替换页面。 这会照顾您的访问者,无论他们来自搜索还是来自直接链接。
SEO失败#6:错过的链接资产
我点击了一个大学网站的链接,收到了 404(未找到)错误。
这种情况并不少见,除了链接指向 /home.html — 该站点以前的主页 URL。
在某些时候,他们一定改变了他们的网站架构并删除了旧式的 /home.html,在洗牌中失去了重定向。
具有讽刺意味的是,他们的 404 页面说您可以从主页重新开始,这正是我最初想要达到的。
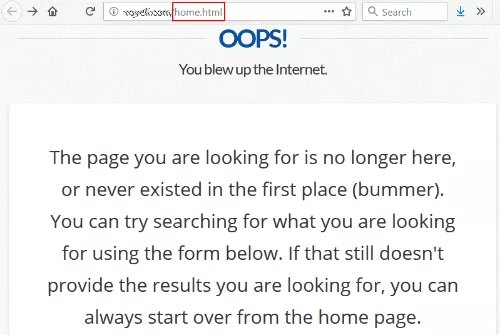
这是一个非常安全的赌注,这个网站希望有一个来自受人尊敬的大学的很好的链接到他们的主页。 而实现这一点完全在他们的控制范围内。 他们甚至不必联系链接站点。
如何解决此故障
要修复此链接,他们只需将 301 重定向指向 /home.html 到当前主页。 (有关如何设置 301 重定向的说明,请参阅我们的文章。)
如需额外积分,请访问 Google Search Console 并查看索引覆盖率状态报告。 查看所有报告为返回 404 错误的页面,并在此处修复尽可能多的错误。
SEO失败#7:复制/粘贴失败
网站重新设计启动,规范标签到位,并安装了新的谷歌标签管理器。 然而,仍然存在排名问题。 事实上,一个新的着陆页并没有在 Google Analytics 中显示任何访问者。
开发团队回应说,他们已经按照书本完成了所有工作,并且严格按照示例进行操作。
他们完全正确。 他们遵循示例——包括留下示例代码! 复制粘贴后,开发者忘记输入自己的目标站点信息。
以下是我们的分析师在网站代码中遇到的三个示例:
- <link rel=”canonical” href=”http://example.com/”>
- 'analyticsAccountNumber':'UA-123456-1'
- _gaq.push(['_setAccount', 'UA-000000-1']);
如何避免这种 SEO 失败
当事情不正常时,不要只看“这个元素在源代码中吗?” 可能从未在您的 HTML 代码中指定正确的验证代码、帐号和 URL。
错误发生了,人只是人。 我希望这些示例将帮助您避免自己的类似 SEO 错误。 为了您的利益,我们创建了一个深入的 SEO 指南,概述了 SEO 技巧和最佳实践。
但是一些 SEO 问题比你想象的要复杂。 如果您有索引问题,那么我们随时为您提供帮助。 致电我们或填写我们的申请表,我们会与您取得联系。
喜欢这个帖子吗? 请订阅我们的博客,以便将新帖子发送到您的收件箱。