
Python中的语义关键字聚类
已发表: 2021-04-19在一个充满数字营销神话的世界中,我们相信为日常问题提出切实可行的解决方案是我们所需要的。
在 PEMAVOR,我们始终分享我们的专业知识和知识,以满足数字营销爱好者的需求。 因此,我们经常发布免费的 Python 脚本来帮助您提高投资回报率。
我们使用 Python 进行的 SEO 关键字聚类为获得大型 SEO 项目的新见解铺平了道路,Python 代码仅不到 50 行。
该脚本背后的想法是允许您对关键字进行分组,而无需支付“夸大的费用”来……好吧,我们知道谁……
但我们意识到仅靠这个脚本是不够的。 需要另一个脚本,所以你们可以进一步理解你的关键字:你需要能够“按含义和语义关系对关键字进行分组。 ”
现在,是时候将Python 用于 SEO更进一步了。
抓取数据³
 学到更多
学到更多传统的语义聚类方式
如您所知,语义的传统方法是建立word2vec 模型,然后使用Word Mover's Distance 对关键字进行聚类。
但是这些模型需要花费大量时间和精力来构建和训练。 因此,我们想为您提供更直接的解决方案。 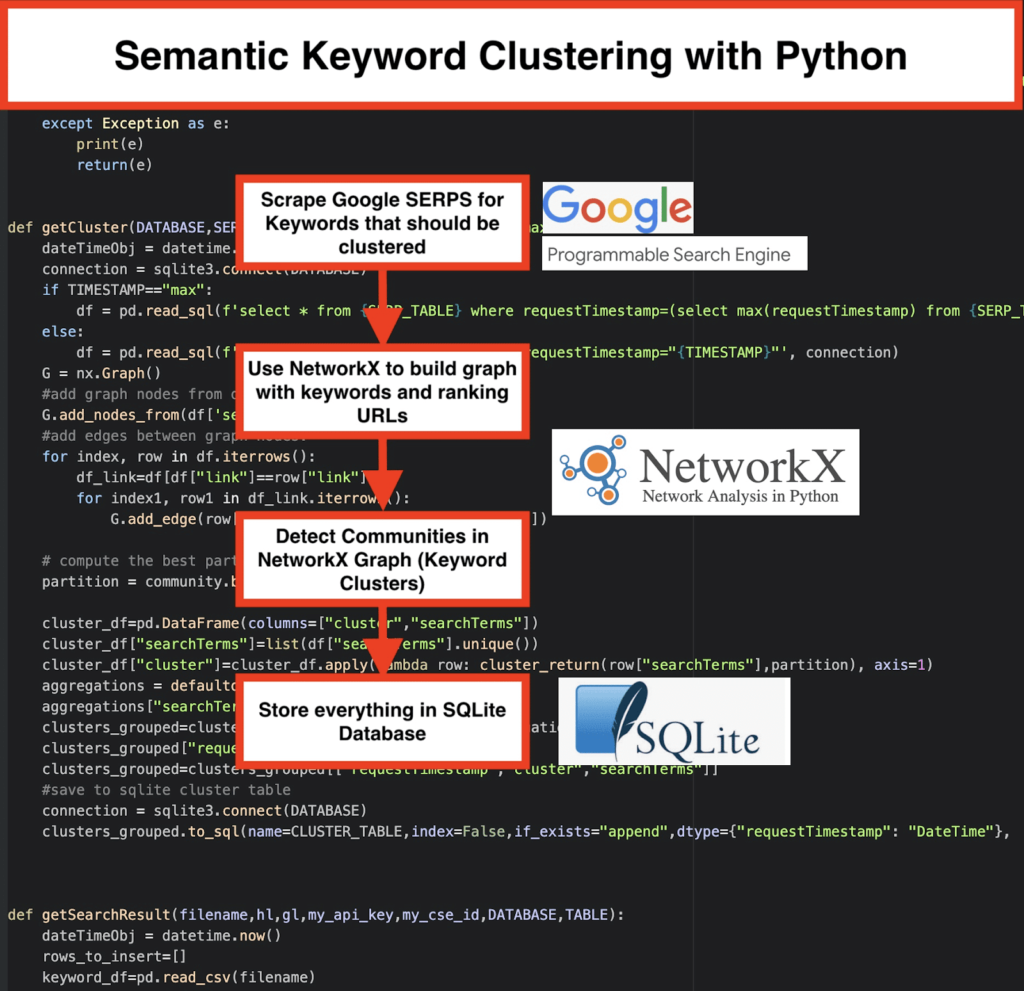
Google SERP 结果和发现语义
Google 利用 NLP 模型提供最佳搜索结果。 这就像潘多拉的盒子被打开,我们并不完全知道。
但是,我们可以使用此框按语义和含义对关键字进行分组,而不是构建我们的模型。
我们是这样做的:
️首先,拿出一个主题的关键字列表。
️ 然后,为每个关键字抓取 SERP 数据。
️ 接下来,创建一个图表,其中包含排名页面和关键字之间的关系。
️ 只要相同的页面针对不同的关键字排名,就意味着它们是相关的。 这是创建语义关键字集群的核心原则。
是时候用 Python 把所有东西放在一起了
Python 脚本提供以下功能:
- 通过使用 Google 的自定义搜索引擎,下载关键字列表的 SERP。 数据保存到SQLite 数据库。 在这里,您应该设置一个自定义搜索 API。
- 然后,利用每天 100 个请求的免费配额。 但是,如果您不想等待或拥有大型数据集,他们还提供每 1000 个任务 5 美元的付费计划。
- 如果您不着急,最好使用SQLite 解决方案- SERP 结果将在每次运行时附加到表中。 (当你第二天再次有配额时,只需采取一系列新的 100 个关键字。)
- 同时,您需要在Python Script中设置这些变量。
- CSV_FILE=”keywords.csv” => 在此处存储您的关键字
- 语言 = “en”
- 国家=“en”
- API_KEY=” xxxxxxx”
- CSE_ID=”xxxxxxx”
- 运行
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)会将 SERP 结果写入数据库。 - 聚类由networkx和社区检测模块完成。 数据是从SQLite 数据库中获取的——使用
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)调用集群 - 聚类结果可以在SQLite 表中找到——只要不更改,默认名称为“keyword_clusters”。
下面,您将看到完整的代码:
# Pemavor.com 的语义关键字聚类
# 作者:Stefan Neefischer (stefan.neefischer@gmail.com)
从 googleapiclient.discovery 导入构建
将熊猫导入为 pd
进口文史丹
从日期时间导入日期时间
从fuzzywuzzy导入fuzz
从 urllib.parse 导入 urlparse
从 tld 导入 get_tld
导入懒惰
导入json
将熊猫导入为 pd
将 numpy 导入为 np
将 networkx 导入为 nx
进口社区
导入 sqlite3
导入数学
导入 io
从集合导入 defaultdict
def cluster_return(searchTerm,partition):
返回分区[searchTerm]
def 语言检测(str_lan):
lan=langid.classify(str_lan)
返回局域网[0]
def extract_domain(url, remove_http=True):
uri = urlparse(url)
如果删除_http:
domain_name = f"{uri.netloc}"
别的:
domain_name = f"{uri.netloc}://{uri.netloc}"
返回域名
def extract_mainDomain(url):
res = get_tld(url, as_object=True)
返回 res.fld
def 模糊比率(str1,str2):
返回 fuzz.ratio(str1,str2)
def blur_token_set_ratio(str1,str2):
返回 fuzz.token_set_ratio(str1,str2)
def google_search(search_term, api_key, cse_id,hl,gl, **kwargs):
尝试:
service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False)
res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='查询(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute()
返回资源
例外为 e:
打印(e)
返回(e)
def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs):
尝试:
service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False)
res = service.cse().list(q=search_term,gl=gl,fields='查询(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute()
返回资源
例外为 e:
打印(e)
返回(e)
def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"):
dateTimeObj = datetime.now()
连接 = sqlite3.connect(数据库)
如果 TIMESTAMP=="max":
df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp=(select max(requestTimestamp) from {SERP_TABLE})', 连接)
别的:
df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp="{TIMESTAMP}"', 连接)
G = nx.Graph()
#从数据框列添加图形节点
G.add_nodes_from(df['searchTerms'])
#在图节点之间添加边:
对于索引,df.iterrows() 中的行:
df_link=df[df["link"]==row["link"]]
对于 df_link.iterrows() 中的 index1、row1:
G.add_edge(row["searchTerms"], row1['searchTerms'])
# 计算社区(集群)的最佳分区
分区 = community.best_partition(G)
cluster_df=pd.DataFrame(columns=["cluster","searchTerms"])
cluster_df["searchTerms"]=list(df["searchTerms"].unique())
cluster_df["cluster"]=cluster_df.apply(lambda row: cluster_return(row["searchTerms"],partition), axis=1)
聚合 = defaultdict()
聚合["searchTerms"]=' | '。加入
clusters_grouped=cluster_df.groupby("cluster").agg(聚合).reset_index()
clusters_grouped["requestTimestamp"]=dateTimeObj
clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]]
#保存到sqlite集群表
连接 = sqlite3.connect(数据库)
clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection)
def getSearchResult(文件名,hl,gl,my_api_key,my_cse_id,DATABASE,TABLE):
dateTimeObj = datetime.now()
rows_to_insert=[]
关键字_df=pd.read_csv(文件名)
关键字=keyword_df.iloc[:,0].tolist()
用于关键字查询:
如果 hl=="默认":
结果 = google_search_default_language(查询,my_api_key,my_cse_id,gl)
别的:
结果 = google_search(查询,my_api_key,my_cse_id,hl,gl)
如果结果中出现“项目”,结果中出现“查询”:
对于范围内的位置(0,len(result [“items”])):
结果[“项目”][位置][“位置”]=位置+1
结果["items"][position]["main_domain"]= extract_mainDomain(result["items"][position]["link"])
结果["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["title"],query)
结果["items"][position]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["snippet"],query)
结果["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],query)
结果["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query)
结果["items"][position]["snipped_language"]=language_detection(result["items"][position]["snippet"])
对于范围内的位置(0,len(result [“items”])):
rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl,
"totalResults":result["queries"]["request"][0]["totalResults"],"link":result["items"][position]["link"],
"displayLink":result["items"][position]["displayLink"],"main_domain":result["items"][position]["main_domain"],
“位置”:结果[“项目”][位置][“位置”],“片段”:结果[“项目”][位置][“片段”],
"snipped_language":result["items"][position]["snippet_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"],
"snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["title"],
"title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][position]["title_matchScore_token"],
})
df=pd.DataFrame(rows_to_insert)
#将serp结果保存到sqlite数据库
连接 = sqlite3.connect(数据库)
df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection)
################################################# ################################################# #########################################
#读我:#
################################################# ################################################# #########################################
#1- 你需要设置一个谷歌自定义搜索引擎。 #
# 请提供 API Key 和 SearchId。 #
# 还要设置您想要监控 SERP 结果的国家和语言。 #
# 如果你还没有 API Key 和 Search Id,#
# 您可以按照此页面 https://developers.google.com/custom-search/v1/overview#prerequisites 的先决条件部分下的步骤进行操作 #
##
#2- 您还需要输入用于保存结果的数据库、serp 表和集群表名称。 #
##
#3-输入包含将用于serp的关键字的csv文件名或完整路径#
##
#4- 对于关键字聚类,输入将用于聚类的 serp 结果的时间戳。 #
# 如果您需要对最后一个 serp 结果进行聚类,请输入“max”作为时间戳。 #
# 或者您可以输入特定的时间戳,例如“2021-02-18 17:18:05.195321”#
##
#5- 通过数据库浏览器浏览 Sqlite 程序的结果 #
################################################# ################################################# #########################################
#csv 包含 serp 关键字的文件名
CSV_FILE="keywords.csv"
# 确定语言
语言 = "en"
#确定城市
国家=“en”
#google自定义搜索json api键
API_KEY="在此处输入密钥"
#搜索引擎ID
CSE_
#sqlite 数据库名称
数据库="keywords.db"
#table name 将serp结果保存到它
SERP_TABLE="keywords_serps"
# 为关键字运行 serp
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)
#table 名称,集群结果将保存到它。
CLUSTER_TABLE="keyword_clusters"
#请输入时间戳,如果你想为特定的时间戳制作集群
#如果您需要为最后一个serp结果制作集群,请使用“max”值发送
#TIMESTAMP="2021-02-18 17:18:05.195321"
TIMESTAMP="最大"
#根据网络和社区算法运行关键字集群
getCluster(数据库,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)
Google SERP 结果和发现语义
我们希望您喜欢这个脚本,它可以在不依赖语义模型的情况下将关键字分组到语义集群中。 由于这些模型通常既复杂又昂贵,因此寻找其他方法来识别共享语义属性的关键字非常重要。
通过将语义相关的关键字放在一起,您可以更好地涵盖某个主题,更好地将您网站上的文章相互链接,并提高您网站针对给定主题的排名。