
多模式和多语言搜索的兴起
已发表: 2022-01-06将搜索扩展到文本查询之外并消除语言障碍是塑造搜索引擎未来的最新趋势。 借助新的人工智能功能,搜索引擎正在寻求提升更好的搜索体验,同时引入新工具来帮助用户检索特定信息。 在本文中,我们将讨论多模式和多语言搜索系统这一新兴话题。 我们还将展示我们在 Wordlift 构建的演示搜索工具的结果。
下一代搜索引擎
良好的用户体验包含用户和搜索引擎之间的多个交互方面。 从用户界面的设计及其可用性到对搜索意图的理解和解决其模糊查询,大型搜索引擎正在准备下一代搜索工具。
多模式搜索
描述多模式搜索引擎的一种方法是考虑一个能够在单个查询中处理文本和图像的系统。 这样的搜索引擎将允许用户通过多模式搜索界面表达他们的输入查询,从而实现更自然和直观的搜索体验。
在电子商务网站上,多模式搜索引擎将允许从索引数据库中检索相关文档。 通过测量可用产品与以多种格式(例如文本、图像、音频或视频)的给定查询的相似性来评估相关性。 因此,这个搜索引擎是一个多模式系统,因为它的底层机制能够同时处理不同的输入模式,即格式。
例如,搜索查询可以采用“花裙”的形式。 在这种情况下,网上商店有大量的花卉连衣裙。 但是,搜索引擎返回的礼服并不真正让用户满意,如下图所示。
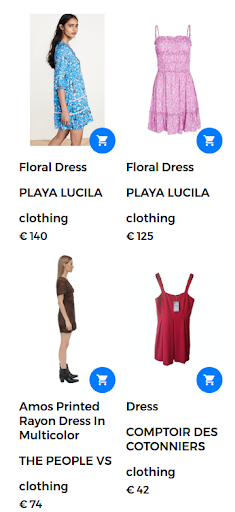
查询“floral dress”的返回结果。
为了提供良好的搜索体验并返回高度相关的结果,多模式搜索引擎能够在单个查询中组合文本和图像。 在这种情况下,用户提供所需产品的样本图像。 将此搜索作为多模式搜索运行时,输入图像是下图所示的花卉连衣裙。

用于多模式查询的用户提供的图像。
在这种情况下,查询的第一部分保持不变(花裙),第二部分将视觉方面添加到多模式查询中。 返回的结果产生与用户提供的花卉连衣裙相似的连衣裙。 在此用例中,可以使用完全相同的连衣裙,因此是与其他类似连衣裙一起返回的第一个结果。
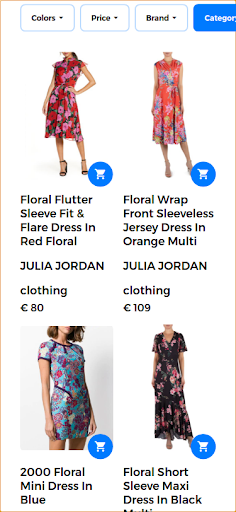
响应多模式查询返回的相关搜索结果。
妈妈
谷歌推出了一项新技术来帮助用户完成复杂的搜索任务。 这项名为 MUM 的新技术代表多任务统一模型,能够打破语言障碍并跨网页和图片等不同内容格式解释信息。
Google Lens是首批利用将图像和文本组合成一个查询的优势的产品之一。 在搜索上下文中,MUM 将使用户更容易在用户提供的图像中找到特定的花卉图案等图案。
MUM 是理解信息的新 AI 里程碑,如下所示:
“虽然我们处于探索 MUM 的早期阶段,但它是迈向未来的重要里程碑,谷歌可以理解人们自然交流和解释信息的所有不同方式。”
要了解有关 Google 的 MUM 多模式搜索的更多信息,请查看此网络故事: 
跨语言扩展搜索
虽然图像与语言无关,但搜索词是特定于语言的。 设计多语言系统的任务归结为跨多种语言构建语言模型。
多语言搜索
当前搜索系统的一个关键限制是它们检索以用户编写搜索查询的语言编写或注释的文档。通常,这些引擎仅支持英语。 这种单语搜索引擎限制了这些系统在查找用不同语言编写的有用信息方面的有用性。
另一方面,多语言系统接受一种语言的查询并检索以其他语言编制索引的文档。 实际上,如果搜索系统能够通过将用一种语言编写的文档内容或标题与另一种语言的文本查询相匹配,从而从数据库中检索相关文档,那么它就是多语言的。 匹配技术的范围从语法机制到语义搜索方法。
将不同语言的句子与视觉概念配对是促进跨语言视觉语言模型使用的第一步。 好消息是,所有人类几乎都以相同的方式解释视觉概念。 这些系统能够整合来自多于一种来源和多于一种语言的信息,称为多模式多语言系统。 然而,图像-文本配对并不总是适用于大规模的所有语言,如下一节所述。
[案例研究] 通过页面 SEO 推动新市场的增长
 阅读案例研究
阅读案例研究从妈妈到壁画
将先进的深度学习和自然语言处理技术应用于搜索引擎的努力越来越多。 谷歌展示了一项新的研究工作,允许用户使用图像来表达单词。 例如,“valiha”一词指的是一种由管古筝制成的乐器,由马达加斯加人演奏。 这个词没有直接翻译成大多数语言,但可以很容易地用图像来描述。
这个名为 MURA 的新系统代表 Multimodal, Multi-task Retrieval Across Languages。 它允许解决一种语言中的单词可能无法直接翻译成目标语言的问题。 由于这些问题,许多预训练的多语言模型将无法找到语义相关的单词或准确地将单词翻译成资源不足的语言或从资源不足的语言中翻译出来。 事实上,MURAL 可以解决许多现实世界的问题:
- 用不同语言传达不同心理含义的词:一个例子是英语和印地语中的“婚礼”一词,它传达了不同的心理图像,如下图所示来自谷歌博客。
- 网络上资源不足语言的数据稀缺性:网络上90% 的文本图像对属于前 10 名资源丰富的语言。

图像取自维基百科,归功于 Psoni2402(左)和 David McCandless(右)并获得 CC BY-SA 4.0 许可。

减少查询的歧义并为资源不足的语言的图像-文本对稀缺问题提供解决方案是对由人工智能驱动的下一代搜索引擎的另一项改进。
多语言和多模式搜索在行动
在这项工作中,我们使用现有的工具和可用的语言和视觉模型来设计一个多模态多语言系统,该系统超越了单一语言,并且一次可以处理多个模态。
首先,要设计一个多语言系统,在语义上连接来自不同语言的单词很重要。 其次,为了使系统具有多模态,有必要将语言的表示与图像相关联。 因此,这是朝着多模式搜索多语言的长期目标迈出的一大步。
上下文
这种多模式多语言系统的主要用例是在给定同时结合图像和文本的查询的情况下从数据集中返回相关图像。 在这种情况下,我们将展示一些示例来说明各种多模式和多语言场景。
这个演示应用程序的主干由开源神经搜索生态系统 Jina AI 提供支持。 由深度神经网络信息检索(或神经 IR)提供支持的神经搜索是构建多模式系统的一种有吸引力的解决方案。 在这个演示中,我们使用 Hugging Face 的 MPNet Transformer 架构 multilingual-mpnet-base-v2 来处理文本描述和字幕。 至于视觉部分,我们使用 MobileNetV2。
接下来,我们将展示一系列测试来展示多语言和多模式搜索引擎的强大功能。 在展示我们的演示工具的结果之前,这里列出了描述这些测试的关键元素:
- 该数据库由 1k 幅描绘人们演奏音乐的图像组成。 这些图像取自公共数据集 Flickr30K。
- 每张图片都有一个用英文写的标题。
第 1 步:从英文文本查询开始
首先,我们从反映大多数搜索引擎当前运行方式的文本查询开始。 查询是“音乐家组”。
查询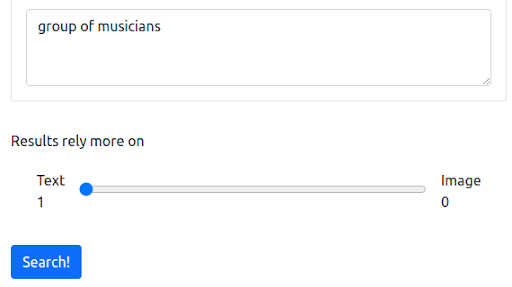
结果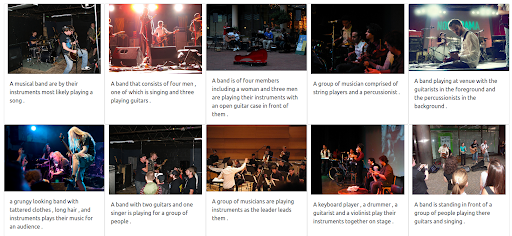
我们基于 Jina 的演示搜索引擎返回与输入查询语义相关的音乐家图像。 然而,这可能不是我们想要的音乐家类型。
第 2 步:添加多模态
现在让我们通过发出一个结合了先前文本查询和图像的查询来添加一些多模态。 该图像更准确地代表了我们正在寻找的音乐家。
首先,UI 需要支持发出这种类型的查询。 然后,我们必须分配一个权重来平衡每个模态在检索结果时的重要性。 在这种情况下,文本和图像都具有相同的权重 (0.5)。 正如我们在下面看到的,新的搜索结果包括许多在视觉上与输入图像查询相似的图像。
查询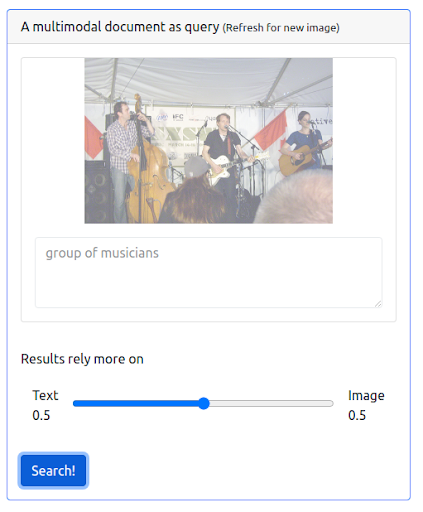
结果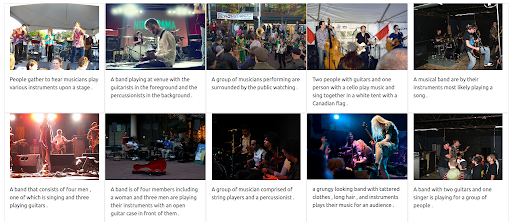
第 3 步:为图像分配最大权重
也可以为图像赋予最大权重。 这样做会从查询中排除输入文本。 在这种情况下,返回更多与输入图像在视觉上相似的图像并将其排在第一位。 要记住的一件事是,结果仅限于数据集中可用的图像。
查询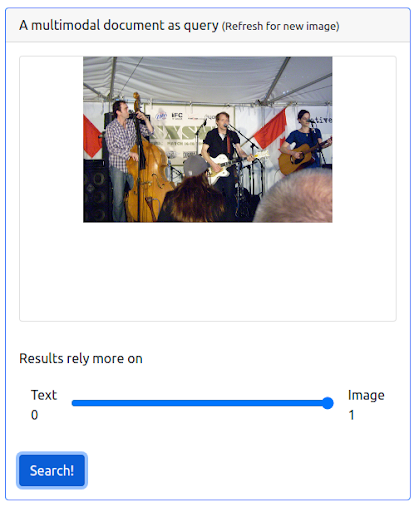
结果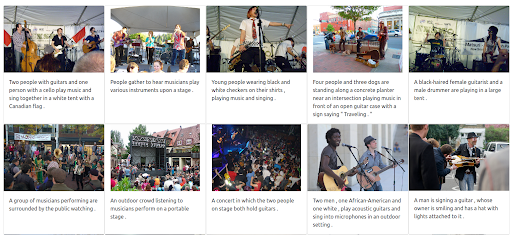
第 4 步:测试多语言搜索
现在让我们尝试发出相同的查询,但使用不同的语言。 为了说明这个多语言系统的全部功能,文本的权重被最大化。 请记住,图片的标题只有英文。 重复搜索以涵盖以下语言:
- 法语: Groupe de musiciens
- 意大利语: Gruppo di musicisti
- 德语: Gruppe von Musikern
无论输入查询的语言是什么,返回的结果都是相关的,并且在三种语言中是一致的。 结果如下所示。
法语查询的结果
意大利语查询的结果
德语查询的结果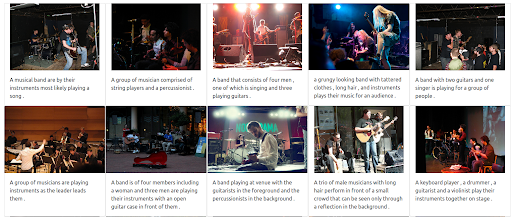
多模式多语言搜索的未来
未来几年,人工智能将越来越多地改变搜索方式,并为人们提供表达查询和探索信息的全新方式。 正如谷歌已经宣布的那样,通过 MUM 了解信息是人工智能的一个里程碑。 未来更多由人工智能驱动的系统将包括功能和改进,从提供更好的搜索体验到回答复杂的问题,从打破语言障碍到将不同的搜索模式组合到一个查询中。