
评估因果影响预测的质量
已发表: 2022-02-15CausalImpact 是 SEO 实验中最流行的软件包之一。 它的受欢迎程度是可以理解的。
SEO 实验为 SEO 提供了令人兴奋的见解和方法来报告其工作的价值。
然而,任何机器学习模型的准确性都取决于它所提供的输入信息。
简而言之,错误的输入可能会返回错误的估计。
在这篇文章中,我们将展示 CausalImpact 是多么可靠(和不可靠)。 我们还将学习如何对您的实验结果更有信心。
首先,我们将简要概述 CausalImpact 的工作原理。 然后,我们将讨论 CausalImpact 估计的可靠性。 最后,我们将学习一种可用于估计您自己的 SEO 实验结果的方法。
什么是因果影响,它是如何工作的?
CausalImpact 是一个包,它使用贝叶斯统计来估计在没有实验的情况下事件的影响。 这种估计称为因果推断。
因果推理估计观察到的变化是否由特定事件引起。
它通常用于评估 SEO 实验的性能。
例如,当给定事件的日期时,CausalImpact (CI) 将使用干预前的数据点来预测干预后的数据点。 然后它将预测与观察到的数据进行比较,并以一定的置信度阈值估计差异。
此外,控制组可用于使预测更准确。
不同的参数也会对预测的准确性产生影响:
- 测试数据的大小。
- 实验前的时间长度。
- 选择要与之比较的对照组。
- 季节性超参数。
- 迭代次数。
所有这些参数都有助于为模型提供更多上下文并提高其可靠性。
爬行BI
 发现
发现为什么评估 SEO 实验的准确性很重要?
在过去的几年里,我分析了许多 SEO 实验,有些事情让我印象深刻。
很多时候,在相同的测试集和干预日期上使用不同的对照组和时间框架会产生不同的结果。
为了说明,下面是同一事件的两个结果。
第一个返回了统计上的显着下降。 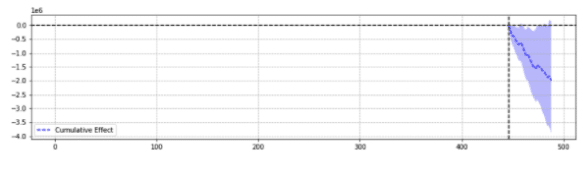
第二个没有统计学意义。 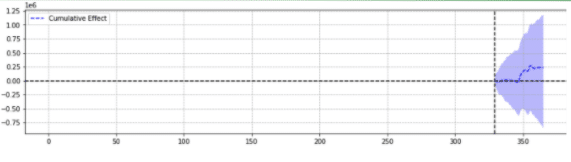
简单地说,对于同一个事件,根据选择的参数返回不同的结果。
人们不得不怀疑哪种预测是准确的。
最后,“统计显着性”不应该增强我们估计的信心吗?
定义
为了更好地了解 SEO 实验的世界,读者应该了解 SEO 实验的基本概念:
- 实验:为检验假设而进行的程序。 在因果推理的情况下,它有一个特定的开始日期。
- 测试组:应用更改的数据子集。 它可以是整个网站或网站的一部分。
- 对照组:未应用更改的数据子集。 您可以拥有一个或多个控制组。 这可以是同一行业中的单独站点,也可以是同一站点的不同部分。
下面的示例将有助于说明这些概念:
修改标题(实验)应该会使五个城市(测试组)的产品页面的有机点击率增加 1%(假设)。 将使用所有其他城市(对照组)的未更改标题来改进估计。
准确 SEO 实验预测的支柱
- 为简单起见,我整理了一些有趣的见解,供 SEO 专业人士学习如何提高实验的准确性:
- CausalImpact 中的一些输入将返回错误的估计,即使在统计上显着。 这就是我们所说的“假阳性”和“假阴性”。
- 没有一个通用规则来管理对测试集使用哪个控件。 需要进行实验来定义用于特定测试集的最佳控制数据。
- 使用具有正确控制和正确长度的前期数据的 CausalImpact 可以非常精确,平均误差低至 0.1%。
- 或者,使用带有错误控制的 CausalImpact 可能会导致很高的错误率。 个人实验显示统计显着变化高达 20%,而实际上没有变化。
- 不是所有的东西都可以测试。 一些测试组几乎从不返回准确的估计。
- 有或没有对照组的实验在干预之前需要不同长度的数据。
并非所有测试组都会返回准确的估计值
一些测试组总是会返回不准确的预测。 它们不应该用于实验。
具有较大异常流量变化的测试组通常返回不可靠的结果。
例如,同一年某网站进行了网站迁移,受新冠肺炎疫情影响,部分网站因技术错误连续 2 周“无索引”。 在该站点上进行实验将提供不可靠的结果。
上述要点是通过使用下述方法进行的一系列广泛测试收集的。
不使用控制组时
- 使用控件而不是简单的 pre-post 可以将估计精度提高多达 18 倍。
- 使用之前 16 个月的数据与使用 3 年的数据一样精确。
使用控制组时
- 使用正确的控件通常比使用多个控件更好。 但是,在控件的流量变化很大的情况下,单个控件会增加错误预测的风险。
- 选择正确的控制可以将精度提高 10 倍(例如,一个报告 +3.1%,另一个报告 +4.1%,而实际上它是 +3%)。
- 测试数据和控制数据之间的大多数相关流量模式不一定意味着更好的估计。
- 使用之前 16 个月的数据不如使用 3 年精确。
实验前注意数据长度
有趣的是,在对对照组进行实验时,使用 16 个月之前的数据会导致非常高的错误率。
事实上,在没有实际变化的情况下,错误可能与估计流量增加 3 倍一样大。
然而,使用 3 年的数据消除了该错误率。这与简单的事后实验形成对比,后者的错误率并未通过将长度从 16 个月增加到 36 个月而增加。
这并不意味着使用控件是不好的。 情况恰恰相反。
它只是显示了添加控制如何影响预测。
当对照组有很大的变化时就是这种情况。
对于在过去一年中出现异常流量变化(关键技术错误、COVID 大流行等)的网站来说,这一点尤为重要。
如何评估因果影响预测?
现在,CausalImpact 库中没有内置准确度分数。 因此,必须以其他方式推断。

人们可以看看其他机器学习模型如何估计其预测的准确性,并意识到平方和误差 (SSE) 是一个非常常见的指标。
平方和误差或残差平方和计算期望值 (yi) 和实际结果 (f(xi)) 之间的所有 (n) 差异的平方和。 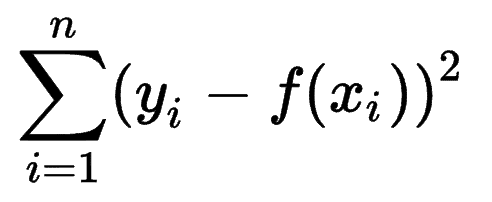
SSE 越低,结果越好。
挑战在于,对于 SEO 流量的事前实验,没有实际结果。
尽管现场没有进行任何更改,但某些更改可能超出了您的控制范围(例如,Google 算法更新、新竞争对手等)。 SEO 流量也没有固定数量的变化,而是逐渐上下变化。
SEO 专家可能想知道如何克服这一挑战。
引入假变体
为了确定一个事件引起的变化的大小,实验者可以在不同的时间点引入固定的变化,看看 CausalImpact 是否成功地估计了变化。
更好的是,SEO 专家可以为不同的测试组和对照组重复该过程。
使用 Python,在后期的不同干预日期将固定变化引入数据。
然后在 CausalImpact 报告的变异和引入的变异之间估计平方误差之和。
这个想法是这样的:
- 选择测试和控制数据。
- 在不同日期对真实数据进行虚假干预(例如,增加 5%)。
- 将 CausalImpact 估计值与每个引入的变体进行比较。
- 计算平方和误差 (SSE)。
- 对多个控件重复步骤 1。
- 为实际实验选择具有最小 SSE 的对照
方法论
使用下面的方法,我创建了一个表,我可以用它来确定哪个控件在不同时间点具有最佳和最差错误率。
首先,选择一个测试和控制数据并引入从 -50% 到 50% 的变化。
然后,运行 CausalImpact (CI) 并将 CI 报告的变化减去您实际引入的变化。
之后,计算这些差异的平方并将所有值相加。
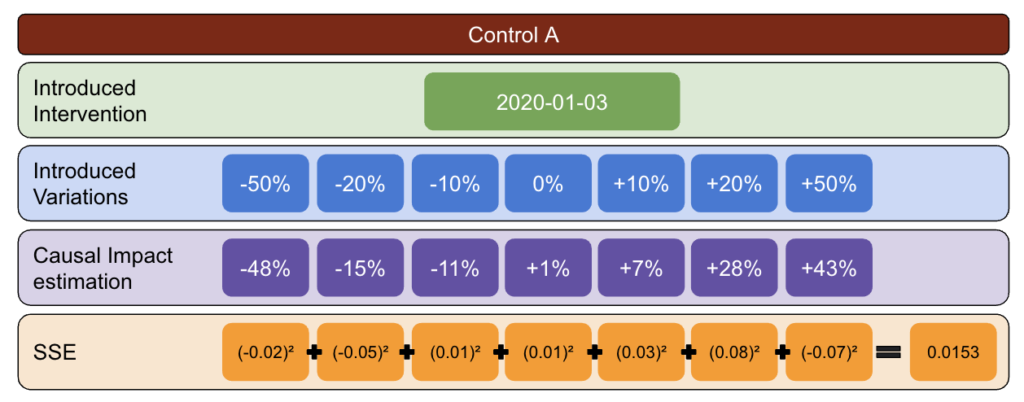
接下来,在不同的日期重复相同的过程,以降低因特定日期的实际变化而导致偏差的风险。
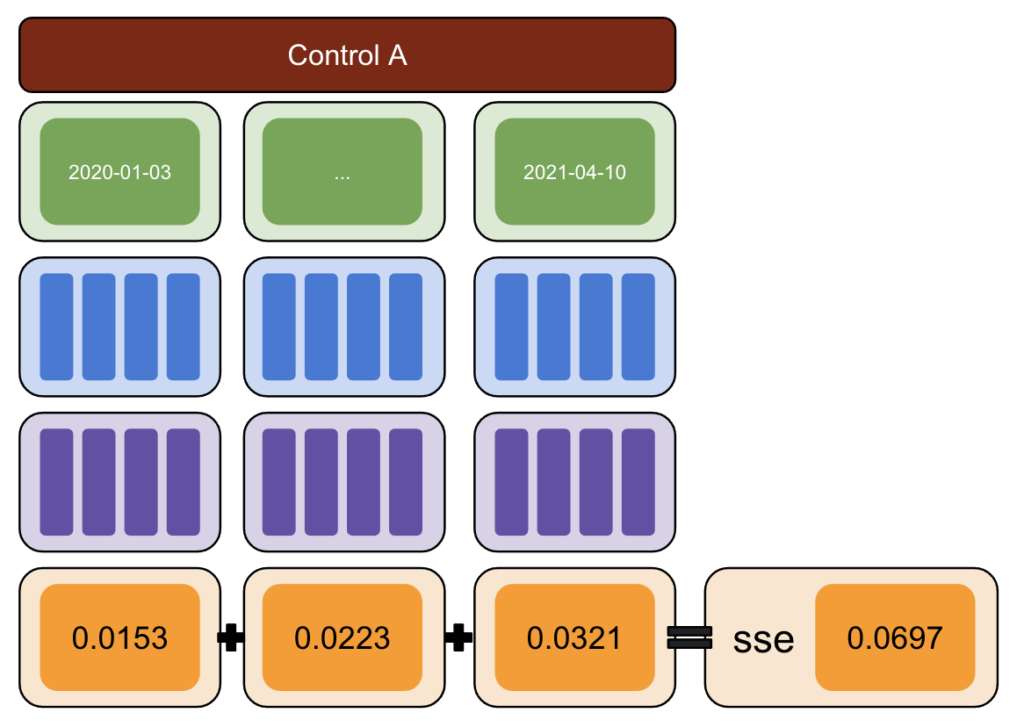
再次,重复多个对照组。
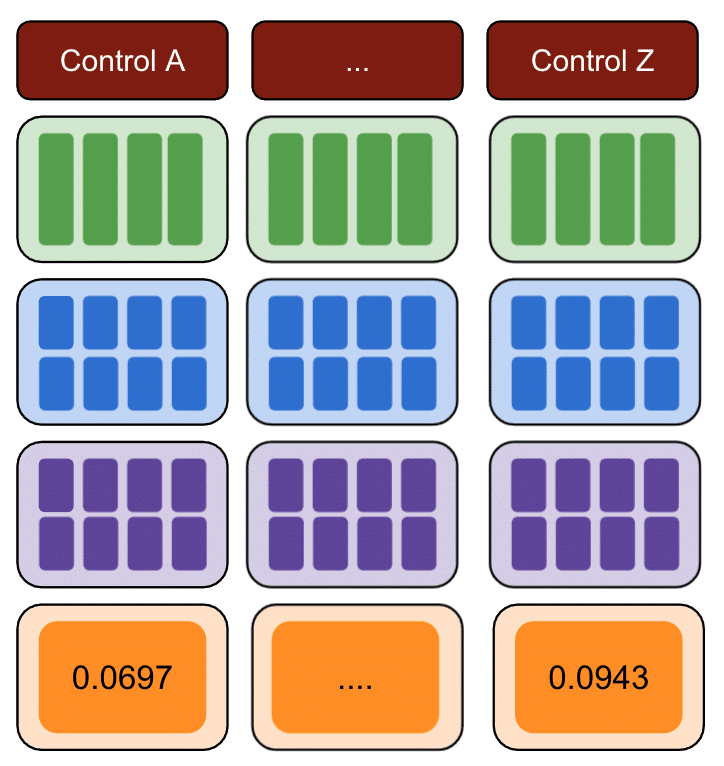
最后,误差平方和最小的控制组是用于测试数据的最佳控制组。
如果您对每个测试数据重复每个步骤,结果会有所不同。
在结果表中,每一行代表一个对照组,每一列代表一个测试组。 里面的数据是SSE。
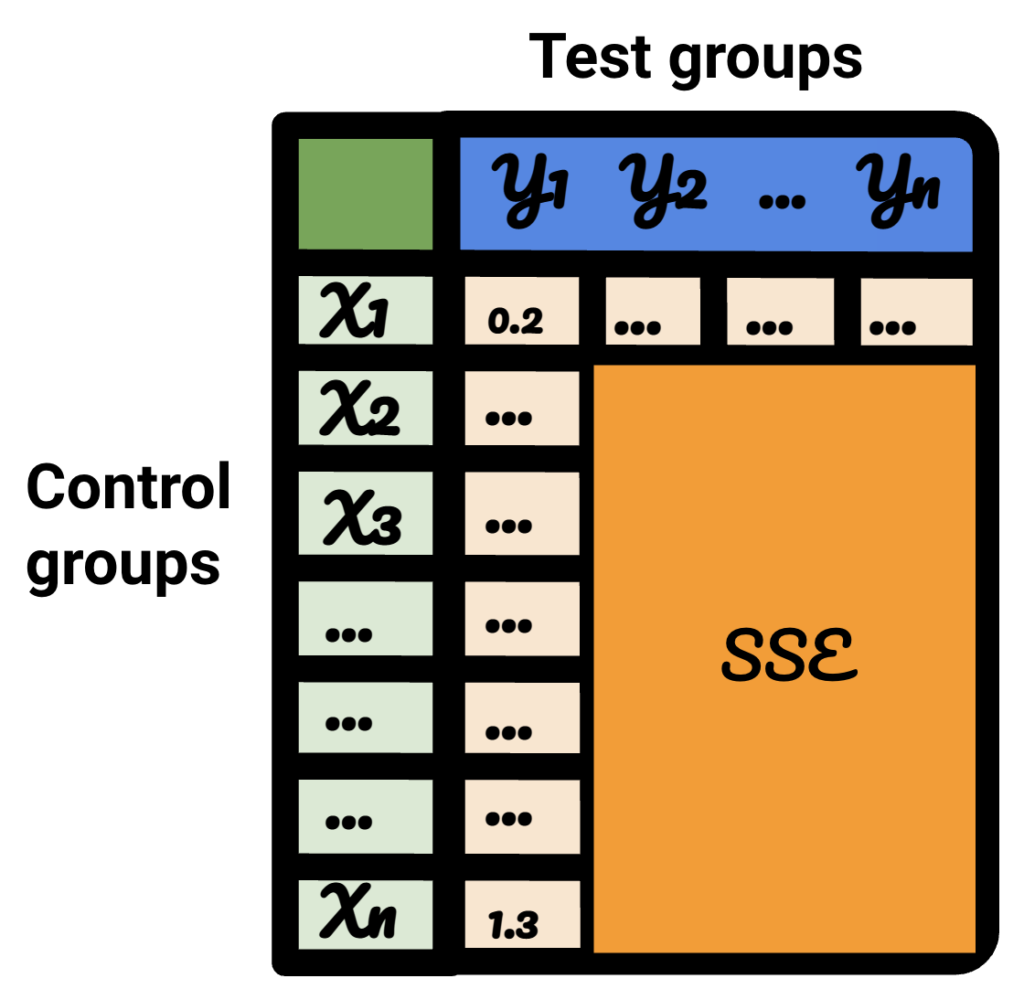
对该表进行排序,我现在确信,对于每个测试组,我都可以为其选择最佳控制组。
我们应该使用控制组吗?
有证据表明,与简单的事前发布相比,使用对照组有助于获得更好的估计。
然而,只有当我们选择正确的控制组时,这才是正确的。
估计期应该多长?
答案取决于我们选择的控件。
当不使用对照时,16 个月前的实验似乎就足够了。
使用对照时,仅使用 16 个月可能会导致大量错误率。 使用 3 年有助于降低误解的风险。
我们应该使用 1 个控件还是多个控件?
该问题的答案取决于测试数据。
与多个对照相比,非常稳定的测试数据可以表现良好。 在这种情况下,这很好,因为使用大量控制可以减少模型受到其中一个控制中意外波动的影响。
在其他数据集上,使用多个控件可以使模型的精度比使用单个控件低 10-20 倍。
SEO社区中有趣的工作
CausalImpact 不是唯一可用于 SEO 测试的库,上述方法也不是测试其准确性的唯一解决方案。
要了解替代解决方案,请阅读 SEO 社区中人们分享的一些令人难以置信的文章。
首先,Andrea Volpini 写了一篇关于使用 CausalImpact Analysis 测量 SEO 有效性的有趣文章。
然后,Daniel Heredia 介绍了 Facebook 的 Prophet 包,用于使用 Prophet 和 Python 预测 SEO 流量。
虽然 Prophet 库比实验更适合预测,但值得学习各种库以牢牢掌握预测世界。
最后,我对 Sandy Lee 在 Brighton SEO 上的演讲感到非常高兴,他分享了对 SEO 测试的数据科学的见解,并提出了 SEO 测试的一些陷阱。
做 SEO 实验时要考虑的事情
- 第三方 SEO 拆分测试工具很棒,但也可能不准确。 选择解决方案时要彻底。
- 尽管我过去曾写过它,但除非在服务器端,否则您无法使用 Google 跟踪代码管理器进行 SEO 拆分测试实验。 最好的方法是通过 CDN 进行部署。
- 测试时要大胆。 CausalImpact 通常不会接受小的变化。
- SEO 测试不应该总是您的首选。
- 除了测试较小的更改(例如标题标签)之外,还有其他方法。 Google Ads A/B 测试或平台 A/B 测试。 真正的 A/B 测试比 SEO 拆分测试更准确,通常可以更深入地了解标题的质量。
可重现的结果
在本教程中,我想专注于如何在不知道如何编码的情况下提高 SEO 实验的准确性。 此外,数据的来源可能会有所不同,并且每个站点都不同。
因此,我用来生成此内容的 Python 代码不在本文的讨论范围之内。
但是,通过逻辑,您可以重现上述实验。
结论
如果您从这篇文章中只有一个收获,那就是因果影响分析可能非常准确,但总是很遥远。
对于希望使用此软件包的 SEO 了解他们正在处理的内容非常重要。 我自己的旅程的结果是,如果不首先在输入数据上测试模型的准确性,我不会相信 CausalImpact。