
Crawl over Crawl 现在可用
已发表: 2019-11-21我们的 Crawl over Crawl 功能允许您比较两种不同的抓取并显示抓取演变。
2016 年,它建立在我们之前发布的“趋势”的基础上,让您有机会发现不同抓取之间的全球趋势。 现在,您可以访问您的 SEO 改进的完整视图,并突出显示给定主题的爬网之间的差异。 Crawl over Crawl 更新包括新类型的图表来读取您的数据。
2019 年,Crawl over Crawl 功能得到了改进。 您现在可以检查:
- 包含相同或相似页面的网站的两个版本,例如生产与临时网站,或移动与桌面版本。
- 同一个网站在两个不同的时间点,比如网站发生变化之前和之后。
比较网站的两个版本
为了比较两个网站,OnCrawl 会查看您为两个不同的爬网提供的起始 URL,以确定不同网站的网址的差异。 它假定这两个版本的网站包含相同(或几乎相同)的内容。 这意味着您要比较的两个域、文件夹或子域中的大多数 URL 段必须是相同的。
以下是一些可以比较的网站示例:
| 用例 | 抓取 1 – 起始 URL | 抓取 2 – 起始 URL |
|---|---|---|
| 生产与暂存站点 | https://www.example.com | http://staging.example.com/site/ |
| 桌面与移动网站 | https://www.example.com | https://m.example.com |
| 区域版本 | https://www.example.com/en-us/ | https://www.example.com/en-ca/ |
| 区域版本 | https://www.example.com | https://www.example.co.uk |
对于起始 URL 之间的复杂差异,自动匹配可能不够。 如果是这种情况,您会在设置爬网时看到一个错误,要求您通过聊天联系 OnCrawl。 我们能够覆盖自动匹配以适应您的具体情况。
在两个不同时间点比较一个网站
要在两个不同的时间点比较一个网站,例如网站改进或重大更改前后,您需要提供:
- 相同的起始 URL
- 相同的爬取宽度(相同的子域探索规则)
如何在爬行中设置爬行
您可以在两个现有爬网之间运行 Crawl over Crawl,或者在创建新爬网时请求与以前的爬网进行比较。 更多关于创建 Crawl over Crawl 的信息可以在 OnCrawl 的知识库中找到。
如何阅读 Crawl over Crawl sunburst
您可以像阅读传统馅饼一样阅读旭日形文字。 这些图形对于跟踪网站的演变、一次又一次地抓取或检查网站的两个版本之间的差异(例如在实时版本之间和在重组期间)非常有用。
此多级饼图可让您根据给定主题比较两次爬网:
- 第一级和内圈:显示属于第一次爬网(旧爬网)的页面。
- 二级外圈:显示内圈各段对应的二次爬取(较新的)的页面。
因此,您可以轻松地找到,例如,第一次爬网中不再出现在第二次爬网中的可索引页面,反之亦然。
在此图表中,内圈显示了从第一次抓取的角度(较旧的角度)对页面的重新分区。 您可以看到有可索引的页面,没有可索引的页面以及不在第一次爬网但出现在第二次(灰色部分)中的页面。
然后,对于内圈的每个部分,您可以在第二次抓取中看到页面对给定部分的重新分区。 内部灰色部分表示那些页面在第一次爬网中不存在,但出现在第二次爬网中(外部绿色和红色部分属于内部灰色部分)。
灰色部分表示页面在结构中是新的还是不存在的,具体取决于它们属于哪个区域。
通过单击图例,您可以决定要显示或关注哪些数据。 Crawl 2 提供了更全球化的视图。
让我们看看内圈。
第一次爬网中页面的可索引性分布
 第一次爬网包含 10854 个可索引页面和 177 个不可索引页面。 仅在第二次爬取中发现了 1 661 个页面。
第一次爬网包含 10854 个可索引页面和 177 个不可索引页面。 仅在第二次爬取中发现了 1 661 个页面。

现在看看外圈。 对于第一个圈的每个段,我们在第二次爬取中找到这些页面的分布。
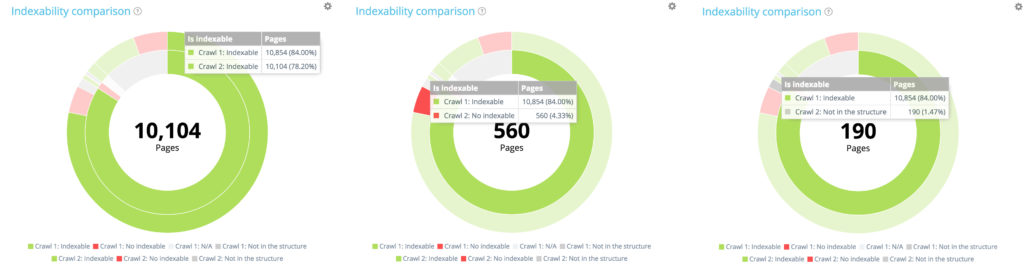
在第一次爬网的 10 854 个可索引页面中,只有 10 104 个在第二次爬网中仍可索引。 560 个现在不可索引,190 个页面在第二次抓取时不再是可抓取网站的一部分。
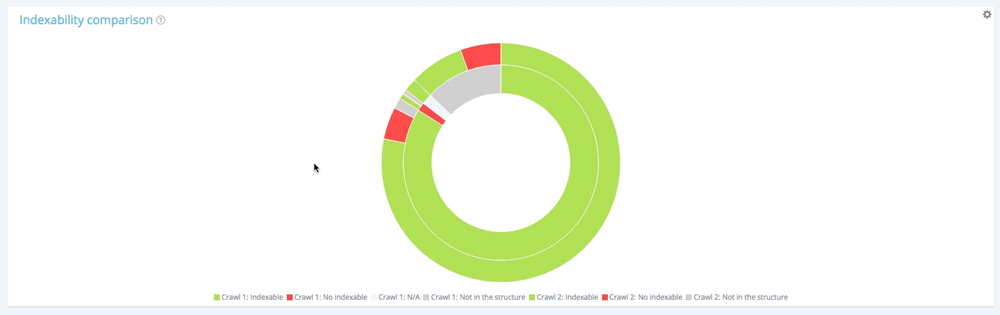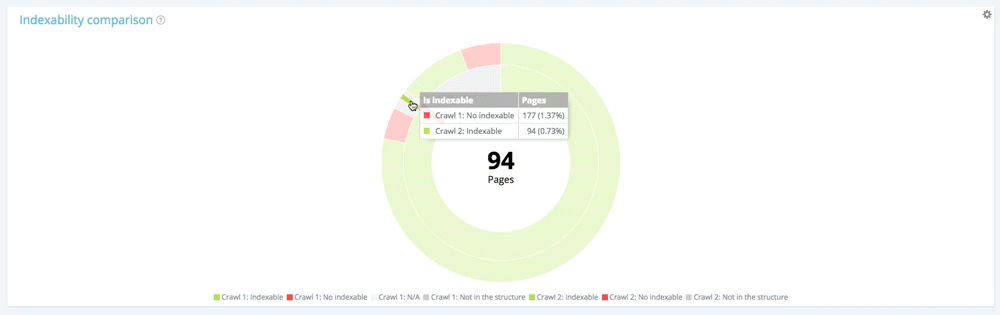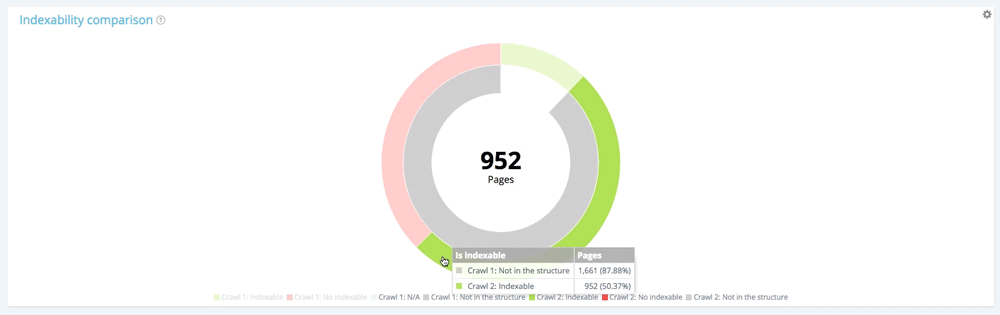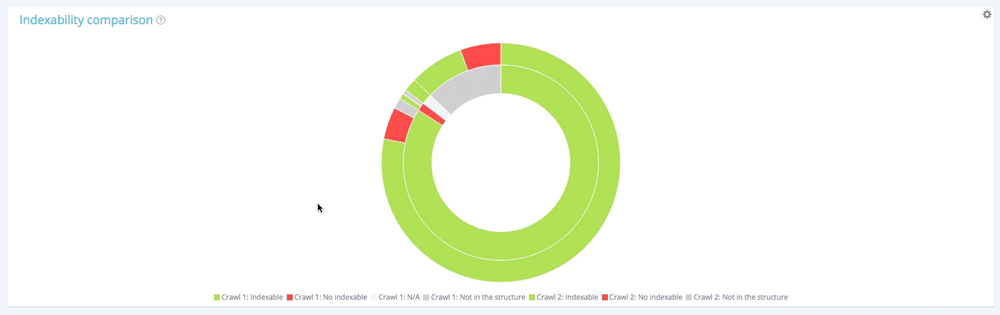
让我们关注一个小部分:第一次爬取的不可索引页面
通过使用图例隐藏第一次爬取时可索引的页面和不在网站结构中的页面,我们可以只专注于第一次爬取时不可索引的页面。
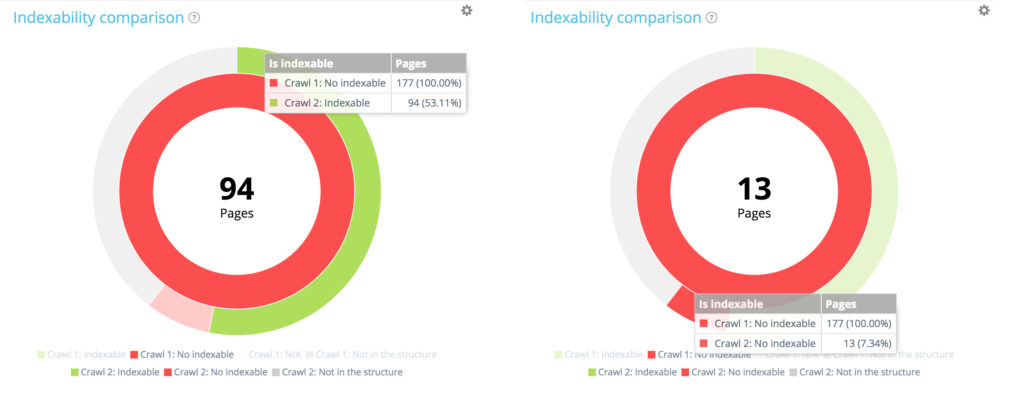 在第一次爬网的 177 个不可索引页面中,现在有 94 个可以在第二次爬网中索引,13 个仍然可以索引。
在第一次爬网的 177 个不可索引页面中,现在有 94 个可以在第二次爬网中索引,13 个仍然可以索引。
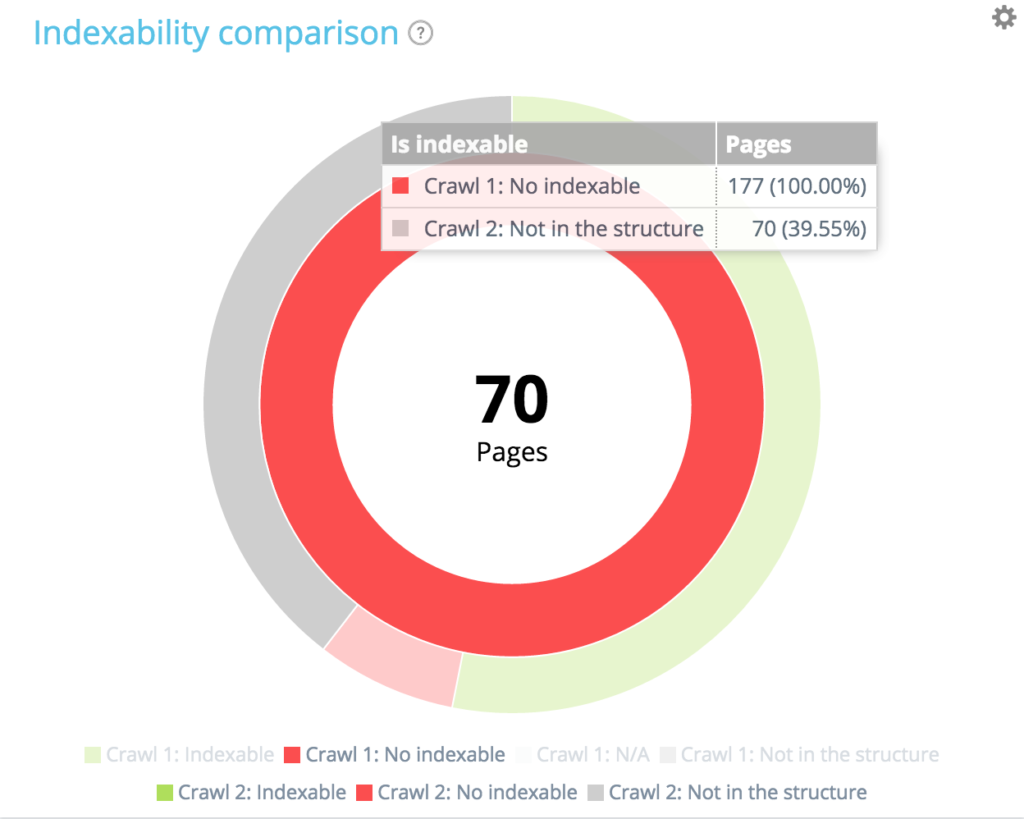
在第一次爬网中的 177 个不可索引页面中,有 70 个在第二次爬网中不再存在。 94 + 13 + 70 = 177。我们从第一次抓取中找到了 177 个不可索引页面的预期细分。
关注新页面:仅在第二次抓取中找到的页面
现在让我们使用图例从第一次爬网中隐藏可索引和不可索引的页面,并仅显示在此爬网期间不属于网站结构的页面。 这使您可以根据索引查看新页面的状态。
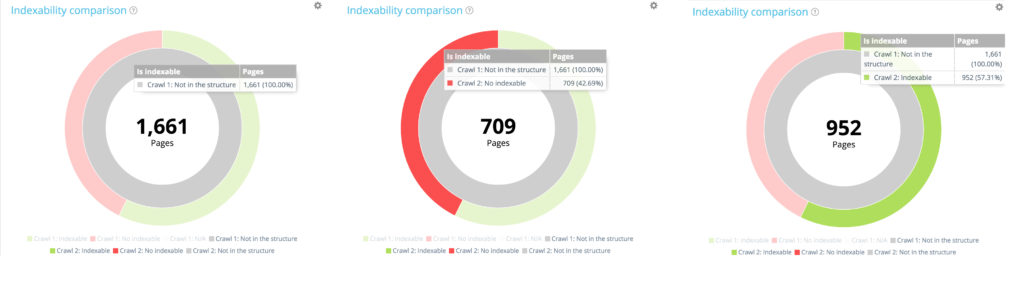
所有新页面:1 661 页。
在 1 661 个新创建的页面中,有 709 个不可索引。
在 1661 个新创建的页面中,952 个是可索引的。
摘要:第二次抓取的所有页面
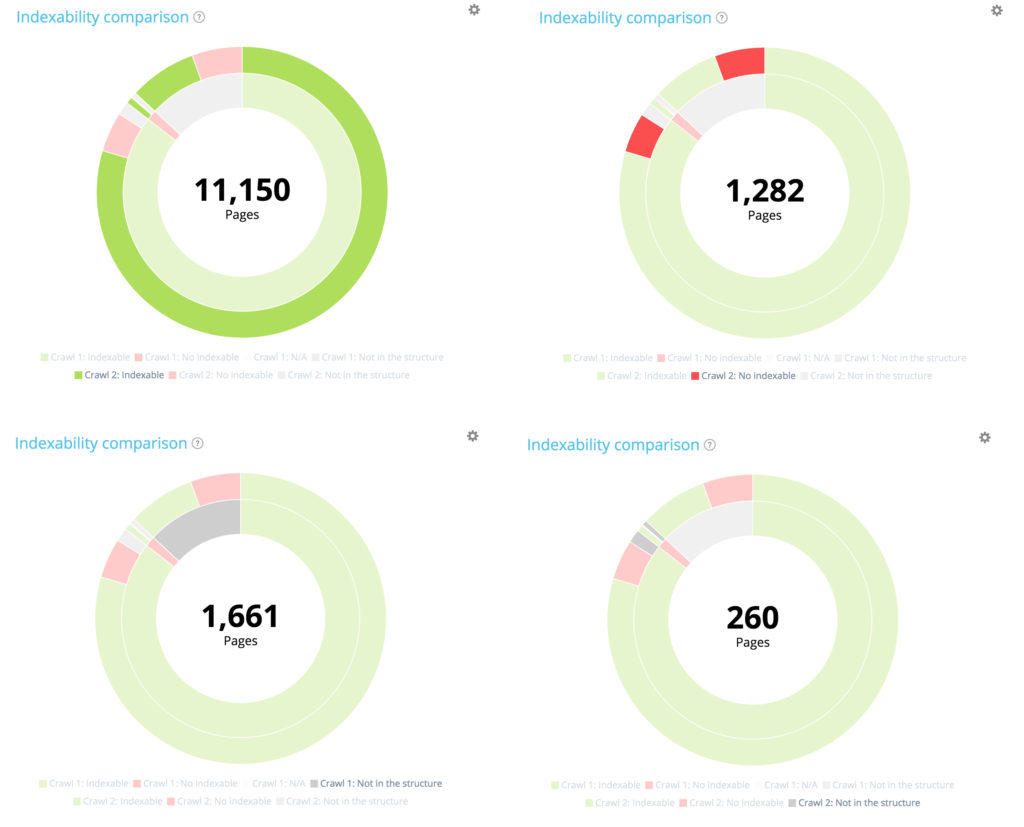 在第一次爬网中,有 10104 个页面是可索引的。 11 150 现在可以在第二个中进行索引。 177 个页面在第一次爬网中不可索引,但现在有 1282 个页面在第二次爬网中不可索引。
在第一次爬网中,有 10104 个页面是可索引的。 11 150 现在可以在第二个中进行索引。 177 个页面在第一次爬网中不可索引,但现在有 1282 个页面在第二次爬网中不可索引。
已创建 1661 个页面,并已从结构中删除 260 个页面。
Crawl over Crawl:可用数据
此新功能按业务专业知识划分并在以下选项卡之间:
- 结构
- 内部链接
- 内容
- 状态码
- 表现
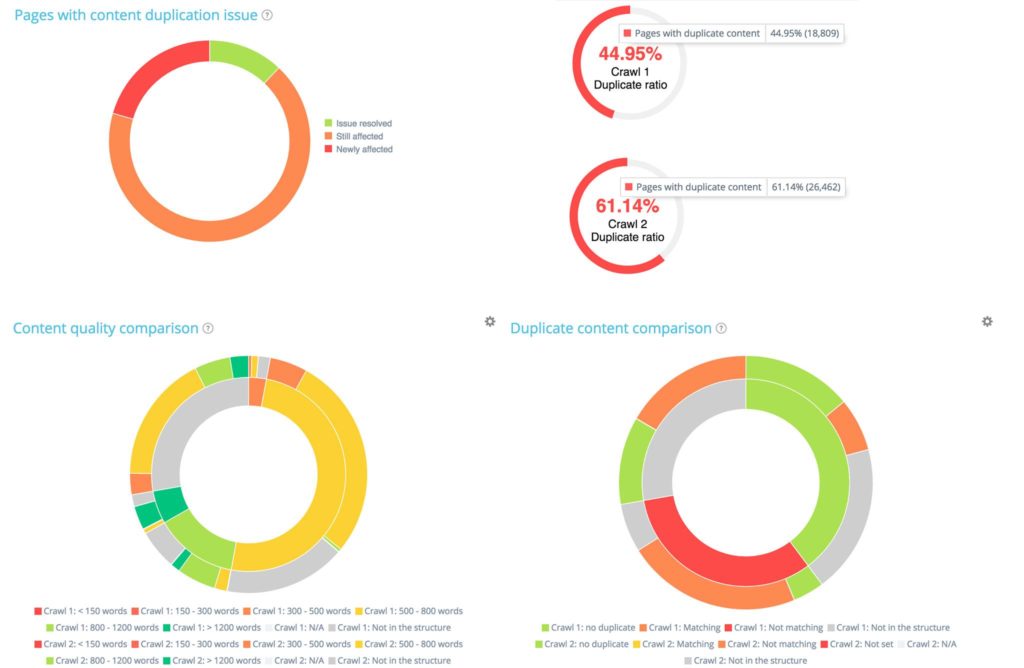
例如,在“内容”部分,您会发现两个抓取之间的重复差异非常重要:
此外,您可以分析两次爬网之间的页面深度有何不同。 在下图中,您可以看到深度差异:
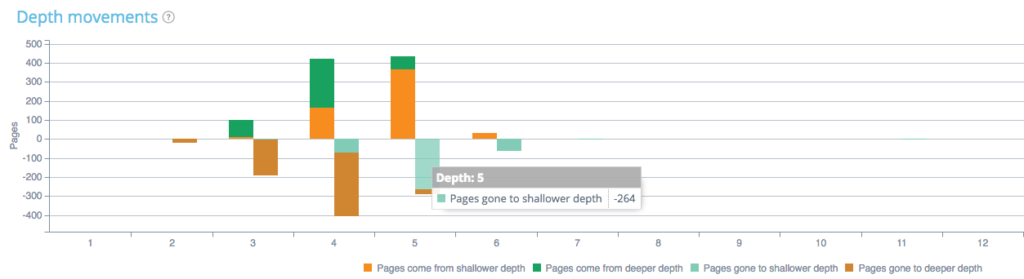
例如,如果我们查看深度 5,我们可以看到进入较浅或较深深度的页面,或者在爬行 1 和 2 之间来自较浅或较深深度的页面。这里,在爬行 1 和深度 5 中的 264 个页面已进入较浅的深度(深度 4、3 或 2)。
这只是对可用内容的概述。 我们的数据浏览器还可以让您深入了解 700 多个指标以进行爬网比较。