
优化 SEO 的构面过滤器
已发表: 2019-11-26在包含产品列表的大量页面的网站上,分面搜索是一个反复出现的问题; 如果实施得当,分面搜索对网站非常有益。 事实上,创建新的、更具体的页面可以响应更多的搜索查询,从而提高搜索结果的可见性。
除了提供逻辑站点架构和优化的内部链接外,分面导航还允许用户快速找到他们正在寻找的产品。
分面搜索的实现必须遵循一定的规则。 否则,可能会导致重大问题,例如大量创建不必要/重复的页面或出现蜘蛛陷阱。
什么是面?
分面搜索通常可以在电子商务或房地产网站的列表页面上找到:这种类型的搜索是指用户可以选择以优化搜索的不同特征组合。
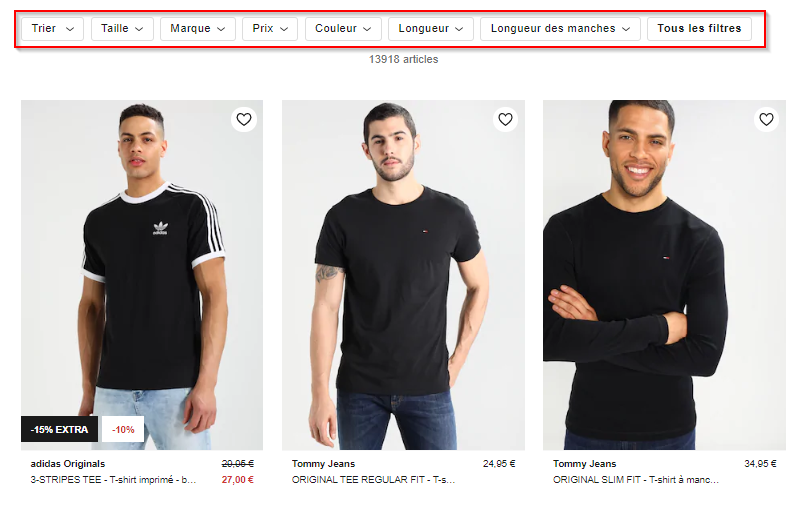
Zalando 上男士 T 恤的多面导航示例
在可用的组合中,区分构面和过滤器很重要。
方面:这是一个过滤的类别页面,应该是爬行友好和可索引的。 它对应于用户具有一定搜索量的查询,它的创造为网站带来了价值和潜在的流量。
过滤器:这是一个仅为用户过滤的类别页面。 无法匹配每月搜索量的查询; 它只允许用户使类别页面更准确并浏览产品的不同属性。
为什么要创建分面?
如上所述,分面导航对于具有大量包含产品/属性列表的页面的网站是有益的。 优化管理的方面策略将具有 3 个主要优点:
- 定位通用或长尾关键字。 因此,创建面向特定请求的构面并提出相应属性的列表是很有趣的。
- T 恤:每月 74,000 次搜索量
- 男士 T 恤:每月 9,900 次搜索量
- 男士黑色 T 恤:每月搜索量 590
- 根据一定的规则自动创建页面:由于适用的站点通常有大量页面,自动创建页面是一个优势;
- 通过自动创建这些页面的内部链接自动化。
如何选择创建哪些方面?
要选择最有益的方面进行创建,遵循 3 个步骤很重要:
语义研究:经典语义研究,收集与网站相关的关键词;
分类:根据通常的方法对关键词进行分类,考虑到不同的相关方式来分解方面(例如价格、尺寸、品牌、性别、材料等)
结果分析:使用突出不同类别和可能组合的数据透视表分析语义研究结果。 这个想法是确定与每个可能的交叉相关的搜索量。
例如,为 T 恤类别中的某些颜色创建构面将是有益的:

抓取和索引:为什么需要控制构面的创建?
如果分面导航正确实现,它将增加用户和机器人的合格页面数量,但如果不正确,则会导致几种类型的问题:
- 蜘蛛陷阱的风险:
蜘蛛陷阱是创建大量或无限数量的 URL,以防止站点被正确浏览。 由于分面导航允许您创建大量重要的组合,如果管理不当,很容易导致蜘蛛陷阱。
- 爬行废物:
网站结构中大量不可索引的链接必然会导致爬取浪费(即使从长远来看,这些链接会被更少爬取)。
- 稀释内部人气:
网站结构内的大量不可抓取链接可能会损害内部人气的分布。
- 创建重复或接近重复的内容:
分面搜索自动创建的某些页面具有相同或非常相似的内容。 应避免这种情况,以免创建内部重复内容。
- 创建空白页面:
与内容相似的页面一样,不应生成没有内容的页面。
控制构面创建要遵循的规则
管理多个方面
首先,您需要定义如果同时选择多个变量(无论是否在同一类别中),是否应创建一个构面
示例:创建性别 + 颜色方面
Example: Do not create gender facets when men's + children's are selected
示例:不要创建性别 + 模式方面

定义产品/商品的最小数量
仅当产品/商品数量足够时才应自动创建构面
示例:当至少有 3 件待售 T 恤时,创建性别(男式或女式)方面

文本:
类别页面
男士方面
女性方面
至少有 3 件男士 T 恤
没有3 件女士 T 恤
设置 SEO 标签
创建的构面必须包含经典的 SEO 优化标记,因此有必要定义自动标记规则。
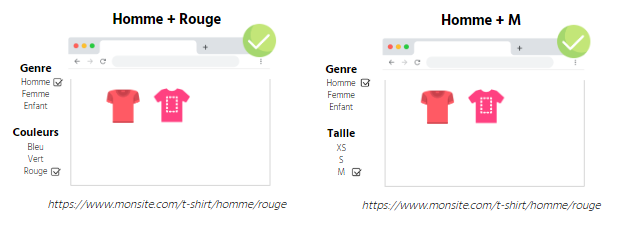
文本:
男装+红
男装 + M
性别:男装、女装、儿童装
颜色:蓝色、绿色、红色
性别:男装、女装、儿童装
尺码: XS, S, M
| 刻面 | H1 | 标题规则 | 描述规则 |
| 性别+颜色 | [性别] [颜色] T 恤 | [性别] [颜色] T 恤 – 我的品牌 | 在 Mysite.com 上发现我们所有的 ➤ [性别] [颜色] T 恤! 免费送货✚ 1 500 款! |
| 性别+尺寸 | [性别] [尺码] T 恤 | [性别] [尺码] T 恤 – 我的品牌 | 在 Mysite.com 上发现我们所有的 ➤ [性别] [尺码] T 恤! 免费送货✚ 1 500 款! |
设置 URL 重写
由于构面最初是您要索引的过滤器,因此在打开索引时将创建“丑陋”的 URL。 然后必须重写这些 URL 以获得“干净”的 URL(即没有特殊字符,例如 %、? 或 &)。

示例:我正在寻找耐克的黑色T 恤

这些“干净”的 URL 针对抓取和索引进行了优化
管理 URL 稳定性
URL 结构不得根据用户所遵循的路径而改变。
示例:两个人正在寻找一件黑色耐克品牌 T 恤,但方式不同。

因此,有必要定义一个默认顺序,例如:[服装类别] > [颜色] > [品牌] 并保持此顺序而不管用户的路径如何。
优化内部链接
与传统的站点结构一样,要使开放构面可抓取和索引,该站点的 URL 必须具有指向该开放构面的永久链接。 后者必须存在于 DOM 中并且即使 JavaScript 和 CSS 被禁用也可以访问。
示例:已创建男士+彩色T 恤的刻面
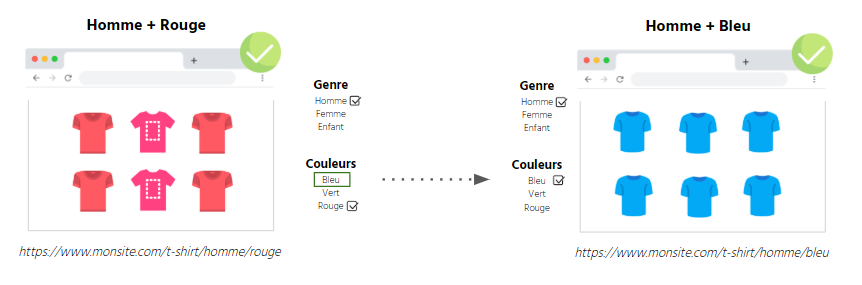
Men's blue t-shirts 我确实有一个“静态”链接<a href =”https://mysite.com/t-shirts/mens/blue”>男士蓝色 T 恤使构面无法访问的几种方法
既然我们已经讨论了有关创建构面的规则,我们需要定义一种方法来使不应创建的构面不可抓取/不可索引。
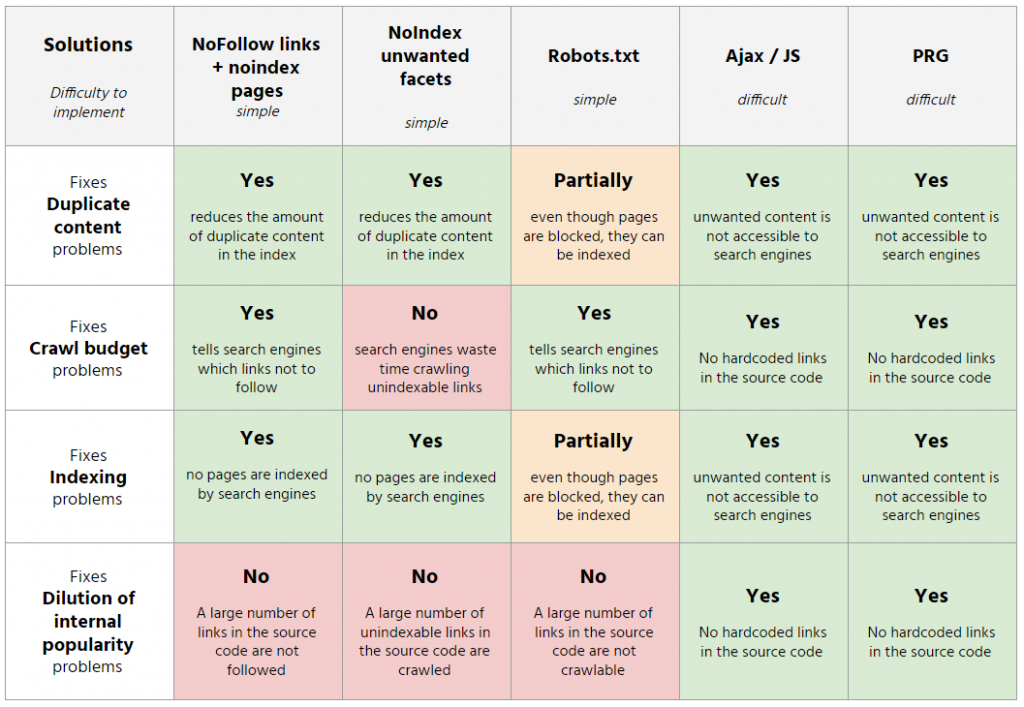
通常,可以通过多种方式阻止不需要的方面,每种方式都有其优点和缺点。
- 在不需要的方面链接上添加 nofollow + 元机器人 noindex
此解决方案限制了不需要的页面上的爬网浪费,并确保关闭的页面不会被索引(如果它们通过其他方式被搜索引擎知道)。 但是,这并不能解决内部人气稀释的问题,因为页面上存在大量不可抓取的链接。
- 在不需要的页面上添加元机器人 noindex
使用这种方法,只能解决索引和重复内容问题。 事实上,爬虫的浪费和内部人气的稀释仍然会出现在网站上。
- 使用 robots.txt 阻止构面
通过使用 robots.txt 阻止不需要的方面的模式,一种易于设置的解决方案。 尽管此选项可以避免在无用页面上浪费爬网预算,但它不提供涉及索引、重复内容和稀释内部流行度的解决方案。
- JS/阿贾克斯
使用 Javascript / Ajax 来阻止 facets 可以让我们有效地解决所有问题。 事实上,不需要的方面的链接只有用户可以访问,并且不存在于页面的源代码中,因此机器人无法访问它们。 请注意,Google 执行 Javascript,并且此解决方案的理想实现是在客户端完成的:类别页面的过滤应直接在浏览器中进行,并且不会创建新页面。
- PRG(Post-Redirect-Get):就像使用JS/Ajax一样,这种方法可以高效地解决所有问题。 提醒一下,GET 请求允许在 URL 中传输信息,并且可由 Google 执行。 另一方面,对于 POST 请求,信息包含在表单中,Google 无法执行。
因此,PRG 方法的目的是在 POST 模式下使用表单来处理不需要的方面,以便 Google 不会执行它们。 这将产生:
第 1 步 POST:用户单击不需要的方面的过滤器,然后使用 POST 方法发送请求。
第 2 步 REDIRECT:服务器通过重定向到过滤后的 URL 来响应请求。
步骤 3 GET:遵循重定向,过滤后的 URL 使用 GET 方法返回。 用户会看到过滤后的结果。
[案例研究] 处罚后网站重新设计的监控和优化
 阅读案例研究
阅读案例研究总结
综上所述
为了顺利进行构面创建,有必要遵循几条规则并在预生产环境中为所有可能的情况进行计划。 同样重要的是要注意,构面管理特定于站点上使用的 CMS,并且有不同的解决方案来管理创建和限制构面,每种都有优点和缺点。