
如何使用 MMM 数据馈送电子表格自动化营销组合建模
已发表: 2022-06-16营销组合建模或 MMM 正在迎来复兴,自它被普遍使用以来已有 60 多年的历史。 与大多数营销归因方法不同,MMM 不需要用户级别的数据,而是通过将支出的高峰和低谷统计映射到营销渠道中的行动和事件来建模哪些渠道值得销售。 从简单的线性回归升级到岭回归或贝叶斯方法等技术,营销组合建模正在为现代重新发明。

想了解更多关于 MMM 的信息吗?
阅读有关营销组合建模与归因建模的优缺点
然而,有一些重大障碍需要克服。 根据 Meta/Facebook 的说法,构建模型可能需要 3 到 6 个月,该公司自 2021 年 10 月以来一直致力于其开源 MMM 库。据估计,在建模开始之前,大约 50% 的时间用于收集和清理数据. 这与我在 Recast 以及之前在 Harry's 的经验以及 CrowdFlower 研究的结果相吻合,该研究发现 60% 的数据科学时间用于清理和组织数据。
快进>>
- 数据清洗
- 建立营销组合模型
- 自动化建模
数据清洗是60%的工作,如何做到0%
要构建准确的模型,您需要特定格式的数据。 准备好数据非常耗时,因此 MMM 项目花费的时间比他们需要的要长。 这使得 MMM 成为一项专业且昂贵的技能,因此大多数公司一年只能制造一到两个模型。 如果您可以使用 Supermetrics 等工具自动执行该过程来构建 MMM 数据馈送,则可以定期更新模型,从而更好地优化营销预算。
表格数据格式
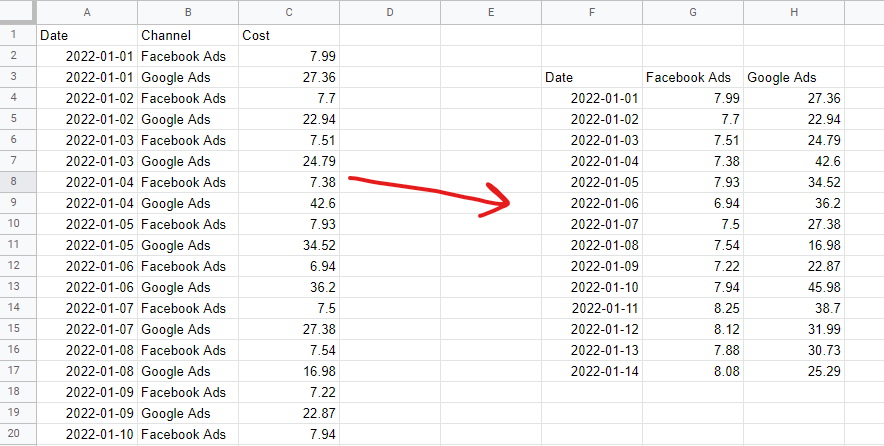
要构建营销组合模型,您必须以未堆叠的表格格式布置数据。 这意味着每次观察一行——通常是几天或几周——和每个模型“特征”一列——通常是媒体支出和有机或外部变量。 分类数据(例如,国定假日列表)需要编码为虚拟变量——1 表示是那个假期,0 表示不是。
连接的数据源
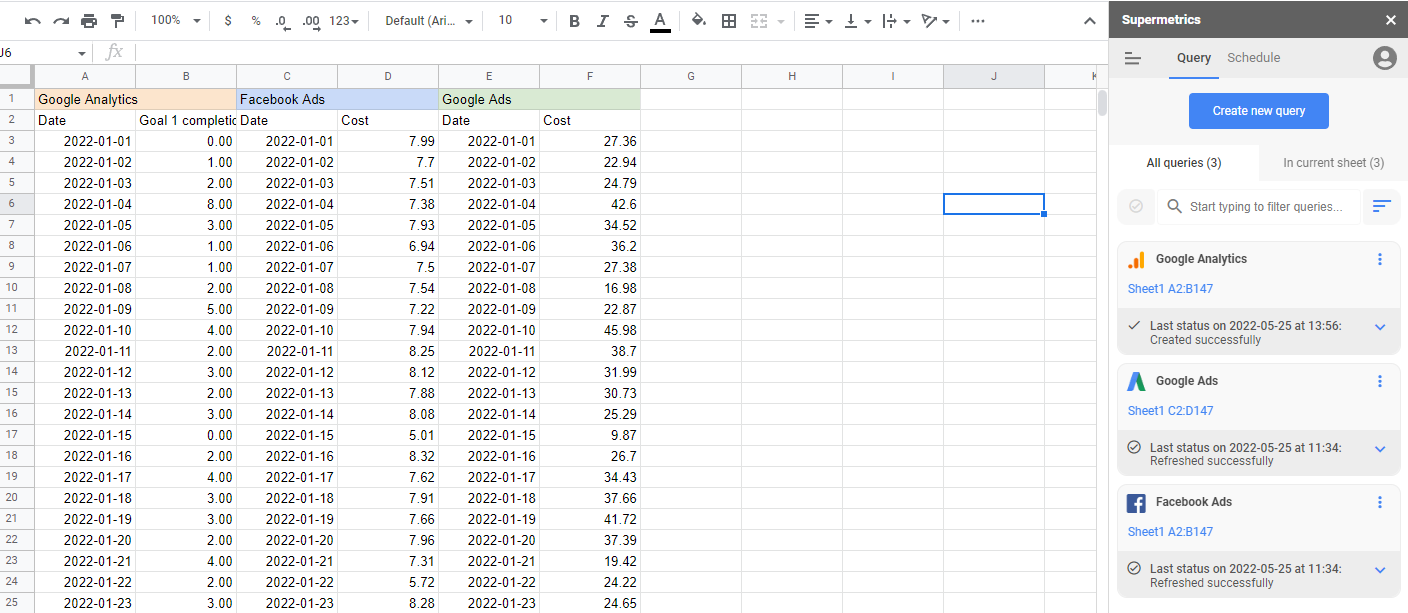
要构建营销归因模型,您需要将所有营销数据放在一个位置。 这是 Supermetrics 自动为您处理的。 借助 90 多个连接器,您可以将所有营销支出、事件和活动集中到一个地方,根据需要进行操作,然后导出为您需要的格式和位置。
导出到 Google 表格
拥有 Supermetrics 帐户后,您只需转到 Extensions > Add-ons > Get add-ons 并安装它。 它会要求您使用链接到您的 Supermetrics 帐户的 Google 帐户进行身份验证,然后边栏将出现在扩展菜单中。
完成此操作后,您可以启动侧边栏(如果尚未启动)并单击以创建新查询。 查询是您决定从哪些帐户提取哪些数据的方式。 当您选择 Facebook Ads 和 Google Ads 等广告平台之一时,它会提示您进行身份验证并授予 Supermetrics 访问权限。
然后,您将选择要从中提取数据的帐户和日期范围。 最后,选择您的指标——通常是 MMM 的成本或展示次数——和维度——只选择与表格格式一致的日期。
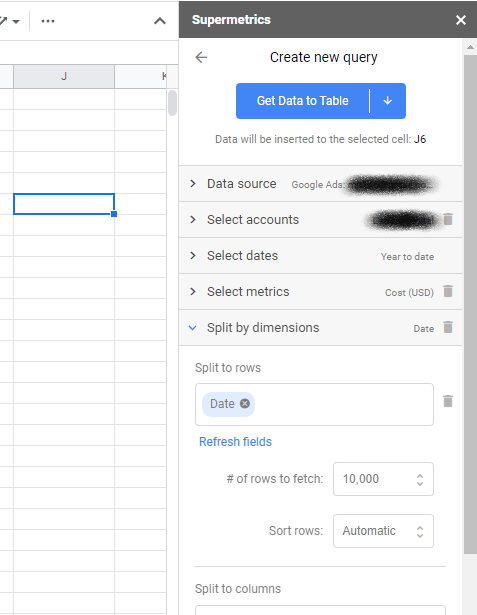
或者,如果您需要选择一组特定的广告系列,您可能需要添加过滤器。 例如,如果您的 YouTube 广告系列名称中有“YT:”,您可能希望选择这些作为单独的来源,然后为您的其他每个广告系列类型复制查询和过滤器。
完成查询后,请确保您已选择要将数据拉入的单元格,然后单击“获取数据到表”。 如果你犯了错误,只需复制查询并将其放在正确的位置,删除另一个。
我发现将每个来源的名称放在表格上方的单元格中很有帮助,这样我就知道我从哪里提取数据。 结果应如下所示:
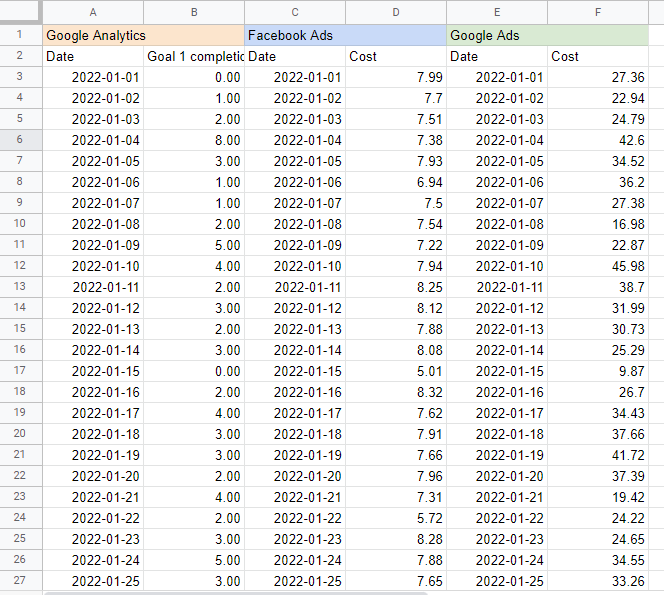
在 Google 表格中构建营销组合模型
营销组合建模是一种强大的归因工具,但它实际上比您想象的更容易获得。 大多数从业者使用自定义代码和高级统计信息,但您可以在一个下午完成基础知识,只需要 Excel 或 Google 表格。
使用 LINEST 函数进行线性回归
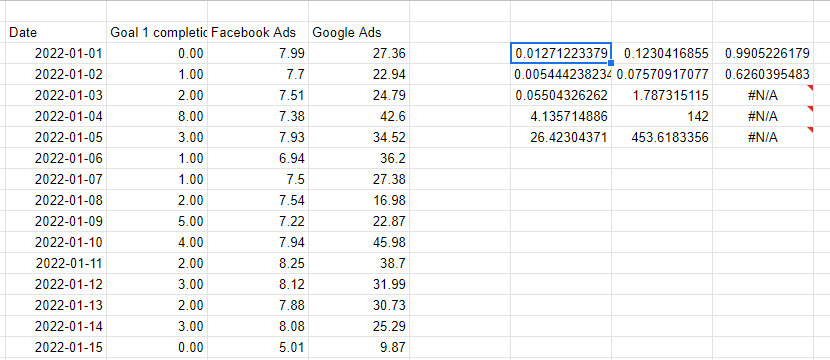
Excel 和 Google 表格都提供了一种简单的方法,即 LINEST 函数,用于进行多变量线性回归。 LINEST 的工作原理是传递我们试图预测的列,然后传递代表我们用来进行预测的变量的多个列。 最后两个参数是我们是否需要截距线(通常为 1 表示是)以及我们是否希望输出详细(包含模型的所有统计信息,而不仅仅是系数)。
请注意,我们用来进行预测的 X 变量需要是连续的,所以我刚刚引用了左侧的列来重复相邻的值。
用模型系数重新预测
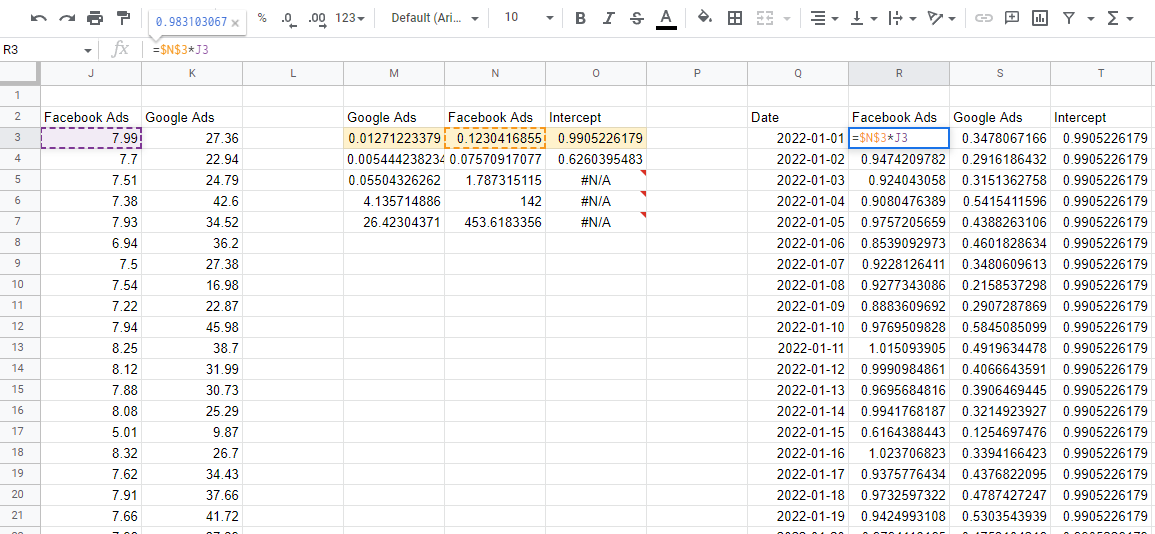
现在我们有了模型,我们需要使用系数来估计每个通道的影响。 如果我们取第一行数字,这些就是系数,并将它们乘以我们数据中的相应输入值——我们将得到每个变量对总销售额的贡献。
需要注意的一件事是 LINEST 向后输出系数。 从左边开始的第一个值始终是您输入的最后一个变量,然后它们以相反的顺序继续,直到您到达最后一个值,即截距。 如果您将所有这些贡献值相加,它会为您提供模型的预测,您可以将其与实际值进行比较以确保模型准确。
检查模型准确度指标
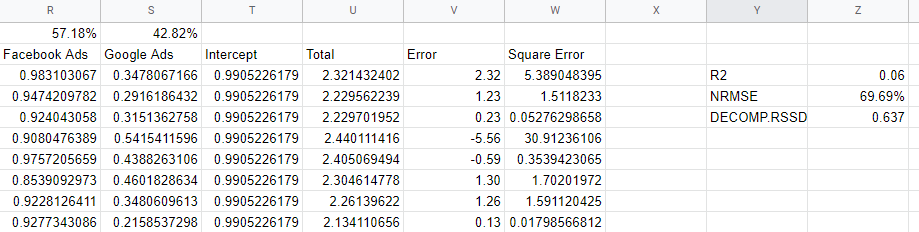
我们如何知道我们的模型是否可靠? 该模型应该很好地拟合数据,它应该能够预测它没有看到的新数据,并且它应该具有合理的系数。 几个验证指标捕获了这些要求。

检查模板中的函数以了解如何计算这些指标。
要使用该模板,请从附加组件列表中转到“文件”>“制作副本”>“启动 Supermetrics”> 将此文件复制到另一个帐户,然后继续进行帐户选择。
R2 或 R-Squared 衡量模型解释了数据方差的多少,它介于 0 和 1 之间:一个好的模型应该高于 0.7,但任何接近 1 的值都可能是可疑的。 接近 0,就像我们的模型一样,表明我们的模型中没有包含足够的变量,需要纳入有机渠道、假期和宏观经济因素等因素。
“归一化均方根误差”是我们衡量准确性的方式,它是通过获取模型预测值与实际值之间的差异,然后将平方值的根作为实际值的百分比来找到的。 理想情况下,这是基于看不见的数据(保留组)完成的,但在我们的简单模型中,我们只是针对样本内数据计算误差。
根和平方过程为我们处理负值并采取行动惩罚真正的大错误。 这可以解释为模型在任何一天关闭的百分比,因此它是一种有用且直观的度量。
合理性是一个很大的话题,通常分析师应该拥有最终决定权。 但是,拥有一个可以以编程方式计算的指标会很有帮助,这样您就可以了解模型与当前渠道组合的发现偏差有多远。
Decomp RSSD 是 Facebook 的 Robyn 团队发明的一个指标,用于衡量您当前的支出分配与哪些渠道产生最大影响之间的差异,正如模型所预测的那样。 如果模型说您最大的渠道实际上并没有推动那么多销售,那么您将拥有高 Decomp RSSD。
在我们的例子中,我们有一个 0.6 的高值,因为该模型给 Facebook 提供了太多的功劳,这代表了少量的支出。
自动大规模交付 MMM
营销组合建模是可无限扩展的活动之一。 就像我们在这里所做的那样,您可以在一个下午使用 Excel 或 Google 表格和 Supermetrics 获得不错的结果,但您也可以花 3 个月的时间与 6 名数据科学家组成的团队使用贝叶斯 MCMC 等复杂算法编写自定义代码来构建更多东西健壮和准确。
有一个用于构建高级模型的功能清单,其中一些需要高级统计知识。 如果您不使用 Supermetrics 为您自动化该部分,请添加几位昂贵的数据工程师来构建数据管道。
想了解更多关于建模混合自动化的信息吗?
查看我们的自动化营销组合建模文章
请注意:MMM 很难。 您可以在建模上花费 500 美元、5,000 美元或 50,000 美元,并在准确性和稳健性方面看到截然不同的结果。 真正重要的是让您的营销支出分配错误的机会成本。
如果您每月花费 10 美元,那么每季度使用一次电子表格模型就可以了。 但是,如果您每月花费超过 100,000 美元,即使减少 5% 也可能在一年内花费您数万美元。
不确定您的 MMM 提要需要哪种数据访问模型?
查看我们的文章以选择适合您业务的文章
那时投资更高级的建模是有意义的。 进行构建与购买分析,以决定是基于 Facebook 的 Robyn 等开源库构建的自定义解决方案,还是我们在 Recast 构建的高级归因软件。
关于作者
Michael Kaminsky 是一位训练有素的计量经济学家,拥有医疗保健和环境经济学背景。 在共同创立 Recast 之前,他曾在男士美容品牌 Harry's 建立营销科学团队。

提高您的业务绩效
通过在您的数据仓库中结合营销和商业智能