
日志文件分析:Google Analytics 的智能替代方案
已发表: 2022-03-08您知道您网站上每天发生的事情吗? 回答这个问题时首先想到的可能是使用受众和行为跟踪工具。 市场上有许多此类工具,包括:Google Analytics、At Internet、Matomo、Fathom Analytics 和 Simple Analytics 等等。 虽然这些工具确实让我们能够很好地了解我们网站上任何特定时间发生的事情,但这些工具所采用的道德实践,更具体地说是谷歌分析,再次受到质疑。
这表明所有网站所有者目前还没有充分利用其他数据来源:日志。
分析工具和 GDPR(专注于 Google Analytics)
自通用数据保护条例 (GDPR) 实施和国家信息与自由委员会 (CNIL) 成立以来,个人数据已成为法国的一个敏感主题。 数据保护已成为优先事项。
那么,您的网站是否仍然“对 GDPR 友好”?
如果我们查看所有网站,我们会发现许多网站已经找到了一种绕过规则的方法,即使用他们的 cookie(数据收集横幅)来收集他们需要的信息,而其他网站仍然严格遵守官方规定。
通过收集这些信息,数据分析工具使我们能够分析观众的来源和访问者的行为。 这种分析需要一个无可挑剔的标记计划来收集尽可能可靠和准确的数据,最终收集的数据是网站上每个动作和事件的结果。
在收到大量投诉后,CNIL 决定暂时将 Google Analytics 在法国定为非法行为,从而引起人们的注意。 这种制裁来自于在向美国情报机构转移个人数据方面明显缺乏监督,尽管之前已获得同意收集访问者信息。 应密切监测事态发展。
在当前情况下,对 Google Analytics 的访问受限或无法访问,看看其他数据收集选项可能会很有趣。 一个站点历史事件的汇编和相对简单的恢复,日志文件是一个很好的信息来源。
尽管日志文件提供了对有趣信息存档的访问权限以进行分析,但它们不允许我们显示业务价值或网站访问者的真实行为,例如从开始到他或她验证购物车或离开网站的网站导航地点。 然而,行为方面仍然特定于上述工具; 日志分析可以帮助我们走得更远。
了解日志文件
什么是日志文件? 日志是一种文件类型,其主要任务是存储事件的历史。
我们在谈论什么样的事件? 从本质上讲,“事件”是每天访问您网站的访问者和机器人。
谷歌搜索控制台也可以收集这些信息,但出于多种原因——特别是隐私原因——它应用了一个非常具体的过滤器。
(来源:https://support.google.com/webmasters/answer/7576553。“Search Console 和其他工具之间的差异”。)
因此,您将只有一个日志分析可以提供的样本。 使用日志文件,您可以访问 100% 的数据!
分析日志文件的行可以帮助您确定未来操作的优先级。
以下是过去从不同机器人访问 Oncrawl 站点的一些示例:
FACEBOOK:
66.220.149.10 www.oncrawl.com - [07/Feb/2022:00:18:35 +0000] "GET /feed/ HTTP/1.0" 200 298008 "-" "facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)"
SEMRUSH:
185.191.171.20 fr.oncrawl.com - [13/Feb/2022:00:18:27 +0000] "GET /infographie/mises-jour-2017-algorithme-google/ HTTP/1.0" 200 50441 "-" "Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html)"
必应:
207.46.13.188 www.oncrawl.com - [22/Jan/2022:00:18:40 +0000] "GET /wp-content/uploads/2018/04/url-detail-word-count.png HTTP/1.0" 200 156829 "-" "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)"
谷歌机器人:
66.249.64.6 www.oncrawl.com - [21/Jan/2022:00:19:12 +0000] "GET /product-updates/introducing-search-console-integration-skyrocket-organic-search/ HTTP/1.0" 200 73497 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
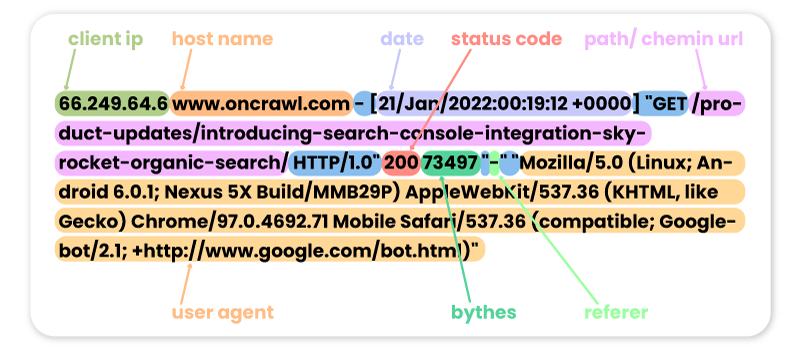
请注意,某些机器人访问可能是假的。 请务必记住验证 IP 地址以了解它们是否是来自 Googlebot、Bingbot 等的真实访问。在这些虚假用户代理的背后,可能会有专业人员有时会启动机器人来访问您的网站并检查您的价格、您的内容或其他他们认为有用的信息。 为了识别它们,只有 IP 会有所帮助!
以下是互联网用户访问 Oncrawl 网站的一些示例:
来自 Google.com:
41.73.11x.xxx fr.oncrawl.com - [13/Feb/2022:00:25:29 +0000] "GET /seo-technique/predire-trafic-seo-prophet-python/ HTTP/1.0" 200 57768 "https://www.google.com/" "Mozilla/5.0 (Linux; Android 10; Orange Sanza touch) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.98 Mobile Safari/537.36"
来自 Google Ads UTM:
199.223.xxx.x www.oncrawl.com - [11/Feb/2022:15:18:30 +0000] "GET /?utm_source=sea&utm_medium=google-ads&utm_campaign=brand&gclid=EAIaIQobChMIhJ3Aofn39QIVgoyGCh332QYYEAAYASAAEgLrCvD_BwE HTTP/1.0" 200 50423 "https://www.google.com/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36"

来自LinkedIn,感谢推荐人:
181.23.1xx.xxx www.oncrawl.com - [14/Feb/2022:03:54:14 +0000] "GET /wp-content/uploads/2021/07/The-SUPER-SEO-Game-Building-an-NLP-pipeline-with-BigQuery-and-Data-Studio.pdf HTTP/1.0" 200 3319668 "https://www.linkedin.com/"
[电子书] 利用 SEO 日志分析的四个用例
 免费下载
免费下载为什么要分析日志内容?
现在我们知道日志实际包含什么,我们可以用它做什么? 答案:分析它们,就像任何其他分析工具一样。
机器人或机器人
在这里,我们可以问自己以下问题:
哪些机器人在我的网站上花费的时间最多?
如果我们专注于搜索引擎,详细了解每个机器人,我们可以看到以下内容:
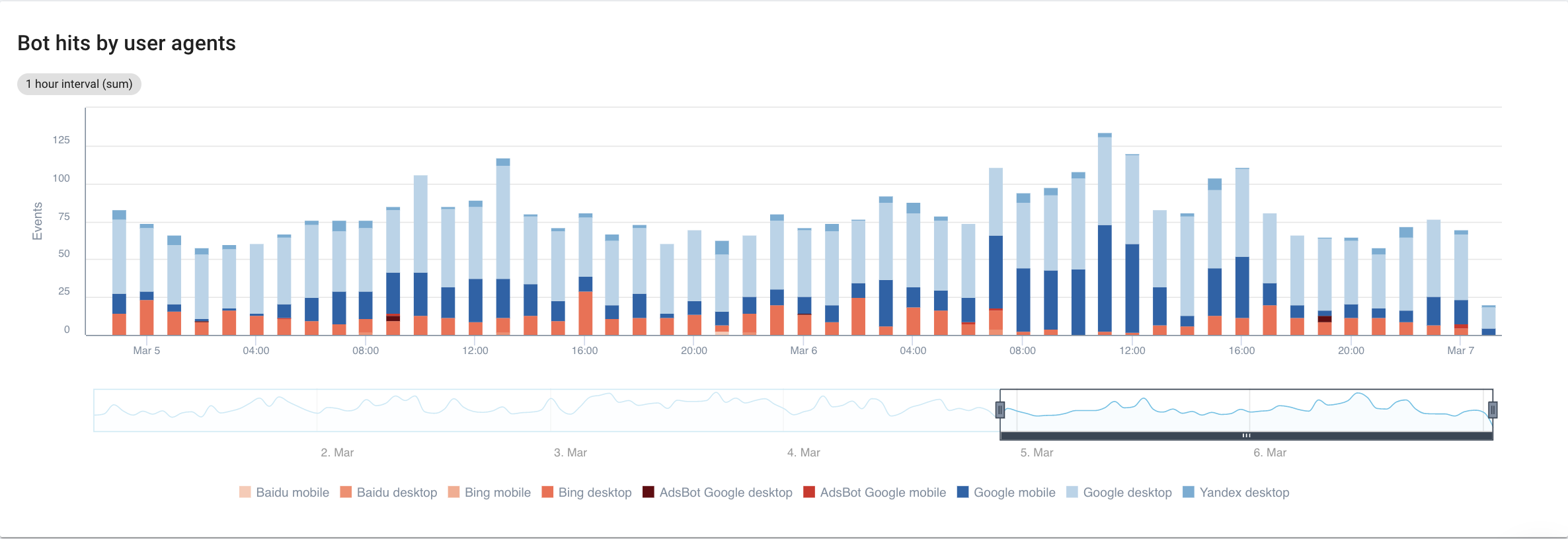
来源:Oncrawl 应用程序
显然,谷歌移动和桌面比 Bing 或 Yandex 机器人花费更多的时间进行爬行。 Googlebot 拥有超过 90% 的全球市场份额。
如果 Google 抓取我的网页,它们会自动编入索引吗? 不,不一定。
如果我们回到几年前,谷歌会在访问页面后直接使用自动反射来索引页面。 今天,考虑到它必须处理的页面量,情况已不再如此。 结果,关于抓取预算的搜索引擎优化之战随之而来。
说了这么多,您可能会问:知道哪个机器人在我的网站上花费的时间比另一个机器人多有什么意义?
这个问题的答案完全取决于每个机器人的算法。 它们每个都有点不同,并且不一定出于相同的原因返回。
每个搜索引擎都有自己的抓取预算,分配给这些机器人。 换句话说,这意味着谷歌将其抓取预算分配给所有这些机器人。 因此,仔细研究一下 GooglebotAds 的作用变得非常有趣,尤其是在我们周围有 404 的情况下。 清理它们是优化抓取预算并最终优化您的 SEO 的一种方法。
Oncrawl 日志分析器
 学到更多
学到更多使用 Oncrawl Crawler 数据交叉引用 Googlebot 数据
为了更深入地分析 Googlebot 的行为,Oncrawl 将日志数据与抓取数据进行交叉引用,以获得最详细、最准确的信息。
目标也是肯定或反驳与深度、内容、性能等几个 KPI 相关的假设。
因此,您必须问自己正确的问题:
- Googlebot 会抓取您网站上的所有网页吗? 对爬网率感兴趣,它清楚地提供了这些信息,您也可以通过页面分段来过滤这些信息。
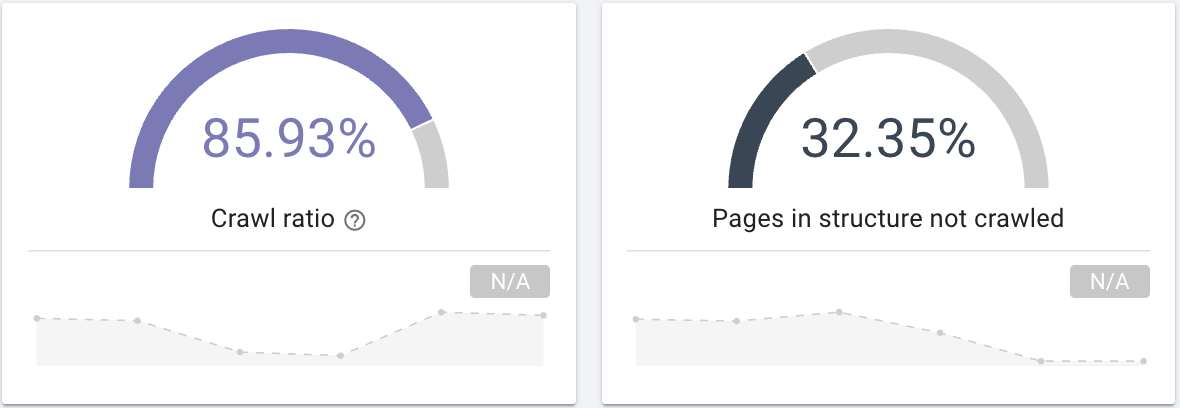
来源:Oncrawl 应用程序
- Googlebot 将时间花在哪个类别上? 这是对爬网预算的最佳使用吗? Oncrawl 的 SEO 影响报告中的这张图表交叉引用了数据并为您提供了这些信息。
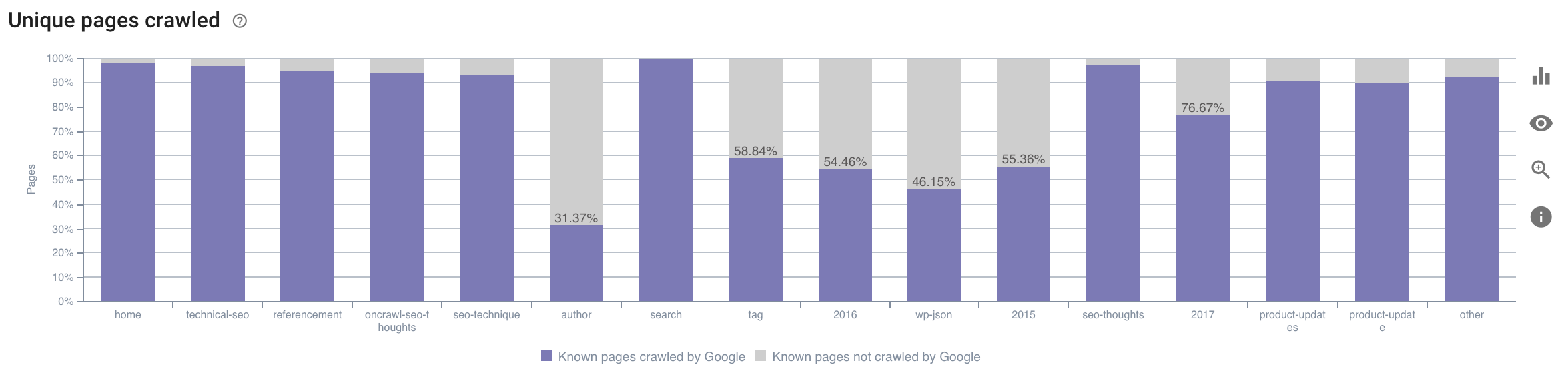 来源:Oncrawl 应用程序
来源:Oncrawl 应用程序
- 我们可能还会对 Oncrawl 爬网报告默认提供的范围之外的问题存有疑问。 例如,描述的长度是否会影响 Googlebot 的行为? 由于爬网,我们拥有这方面的数据,因此我们可以使用它来创建细分,如下所示:
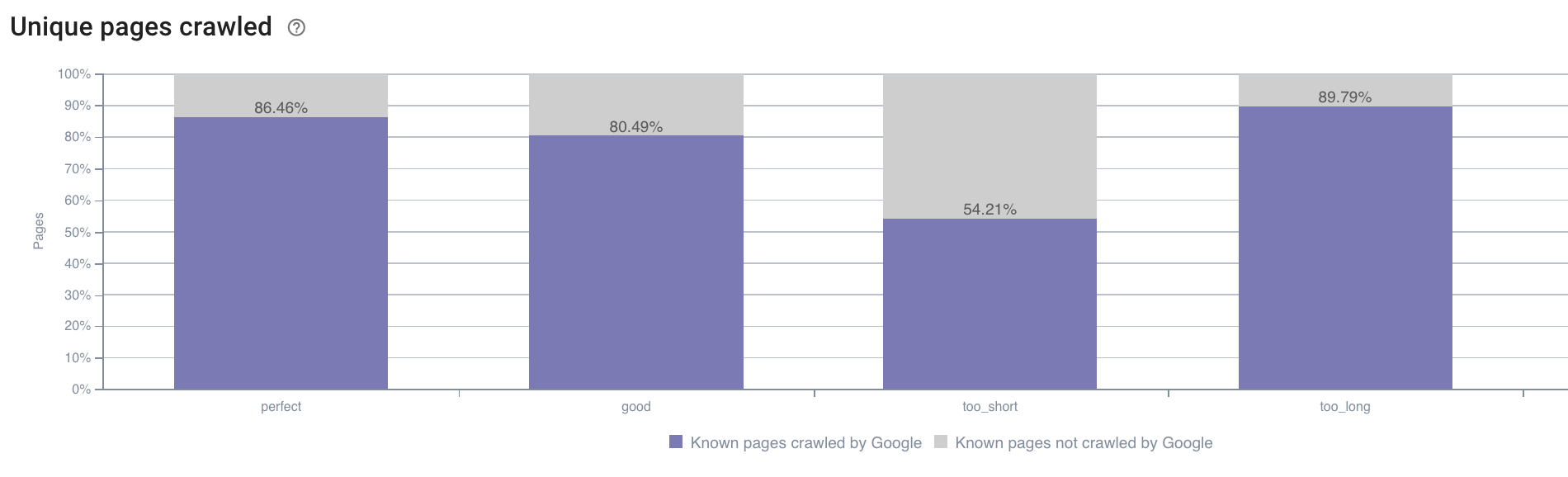
来源:Oncrawl 应用程序
与在此处被 Oncrawl 应用程序指定为“完美”或“良好”的理想尺寸(110 到 169 个字符之间)的描述相比,太短的描述被抓取的次数要少得多。
如果描述符合相关性和大小等标准,Googlebot 将很乐意增加其在相关页面上的抓取预算。
注意:被认为太长的页面有时会被 Google 重写。
使用日志分析网站访问
接下来,如果我们看一下 SEO 的例子,因为这是我们试图用 Oncrawl 分析的内容,我建议你再问自己一个问题:
- Googlebot 的行为与 SEO 访问之间有什么关联?
Oncrawl 具有相同的图表来交叉引用爬取数据和在日志中检索到的 SEO 访问之间的数据。
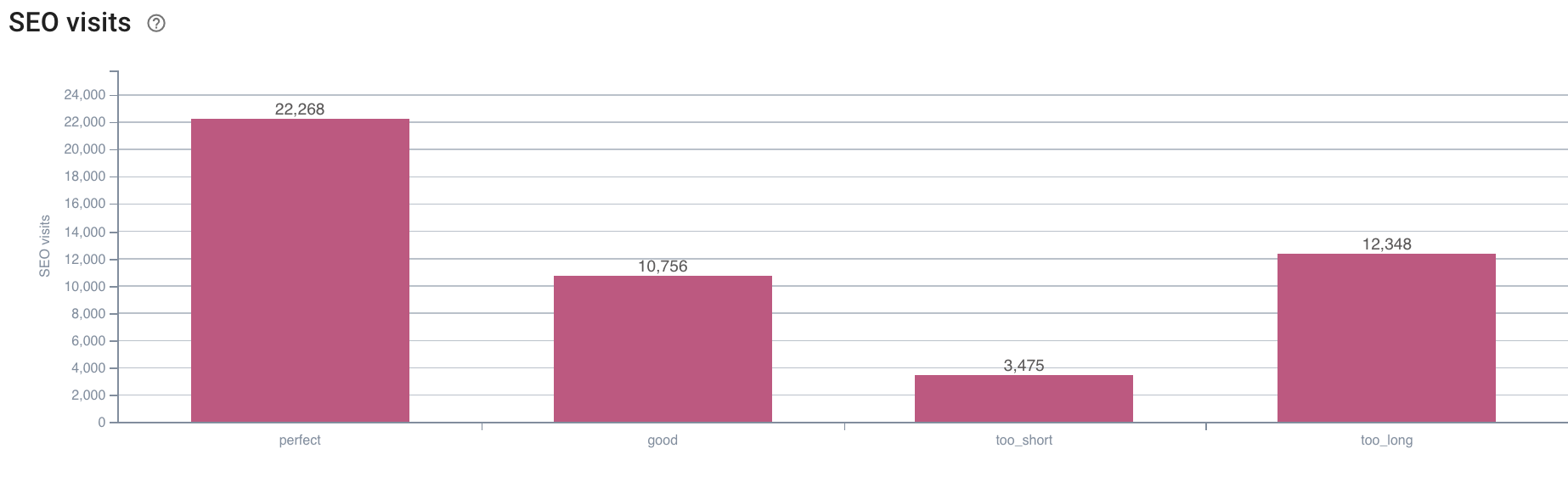 来源:Oncrawl 应用程序
来源:Oncrawl 应用程序
答案很明确:具有“完美”描述长度的页面似乎会产生最多的 SEO 访问。 因此,我们必须集中精力在这个轴心上。 除了“喂”Googlebot,用户似乎还欣赏描述的相关性。
Oncrawl 应用程序为许多其他 KPI 提供了类似的数据。 随意验证你的假设!
综上所述
既然您知道并理解了通过日志探索您网站上每天发生的事情的可能性,我鼓励您分析互联网用户和机器人访问,以便找到各种优化您的网站的方法。 答案可能与技术或内容相关,但请记住,良好的细分是良好分析的关键。
然而,谷歌分析工具无法进行这种分析; 他们的数据有时会与我们的爬虫数据混淆。 拥有尽可能多的数据供您使用也是一个很好的解决方案。
要从您的日志数据和爬网分析中获得更多信息,请随时查看 Oncrawl 团队进行的一项研究,该研究汇编了与电子商务网站上的日志相关的 5 个 SEO KPI。