
网络研讨会文摘:Bill Hartzer 的实时 SEO 审计和日志文件
已发表: 2018-10-029 月 25 日,OnCrawl 很高兴邀请 Bill Hartzer 参加关于日志文件分析及其对 SEO 审计的重要性的网络研讨会。 他浏览了自己的网站,以展示优化对机器人活动和爬网频率的影响。
介绍比尔·哈泽尔
Bill Hartzer 是一位拥有 20 多年经验的 SEO 顾问和域名专家。 比尔是国际公认的他所在领域的专家,最近作为该国领先的搜索专家之一接受了 CBS 新闻的采访。
在这个长达一小时的网络研讨会过程中,Bill 向我们展示了他的日志文件,并讨论了他如何在现场审核中使用它们。 他展示了他用来验证网站性能和网站上机器人行为的不同工具。
最后,Bill 回答了有关如何使用 OnCrawl 可视化有意义的结果的问题,并为其他 SEO 提供了提示。
如何通过 WordPress 的 cPanel 插件访问您的日志文件
如果您的网站是使用 WordPress 构建的并且您使用插件 cPanel,您可以直接在 WordPress 界面中找到您的服务器日志。
导航到 Metrics,然后导航到 Raw Access。 在那里,您可以从文件管理器下载每日日志文件,以及旧日志文件的压缩存档。 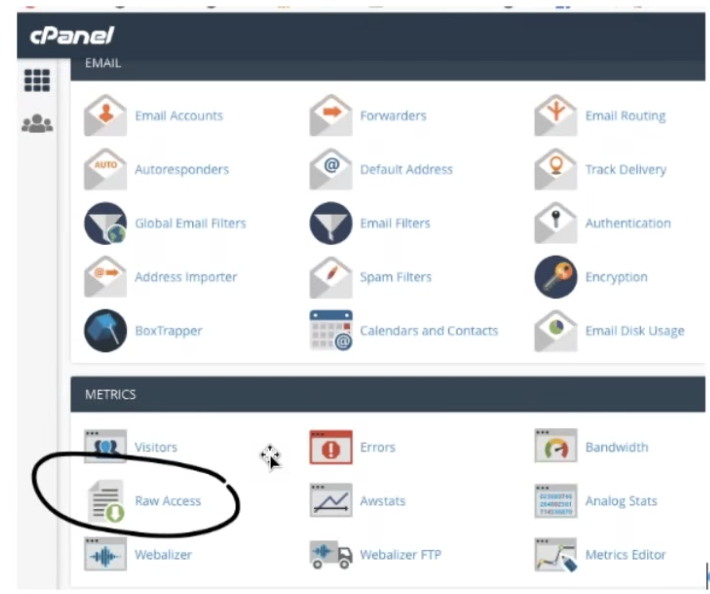
检查日志文件的内容
日志文件是一个大型文本文件,其中包含有关您网站的所有访问者(包括机器人)的信息。 您可以使用基本的文本编辑器打开它。
发现来自 googlebot 或 bing 的潜在机器人点击并不难,它们确实在日志文件中标识了自己,但使用 IP 查找确认机器人标识是个好主意。
您可能还会发现其他爬取您的网站的机器人,但它们可能对您没有用处。 您可以阻止这些机器人访问您的网站。
OnCrawl 将处理您的日志文件中的原始分析,让您清楚地了解访问您网站的机器人。

使用您的日志文件获取有关 Crawl Stats 的更多信息
与日志文件中的信息相比,在旧版 Google Search Console 中的“Crawl”>“Crawl Stats”下提供了有关 Crawl Stats 的信息,具有新的含义。
您应该知道,Google Search Console 中显示的数据不仅限于 Google 的 SEO 机器人,因此可能不如通过分析日志文件获得的更准确信息有用。
最近发生的异常爬网活动
Bill 查看了 Google Search Console 中抓取统计数据中可见的三个最近的峰值。 这些对应于触发增加的爬网活动的大事件。
移动优先索引峰值
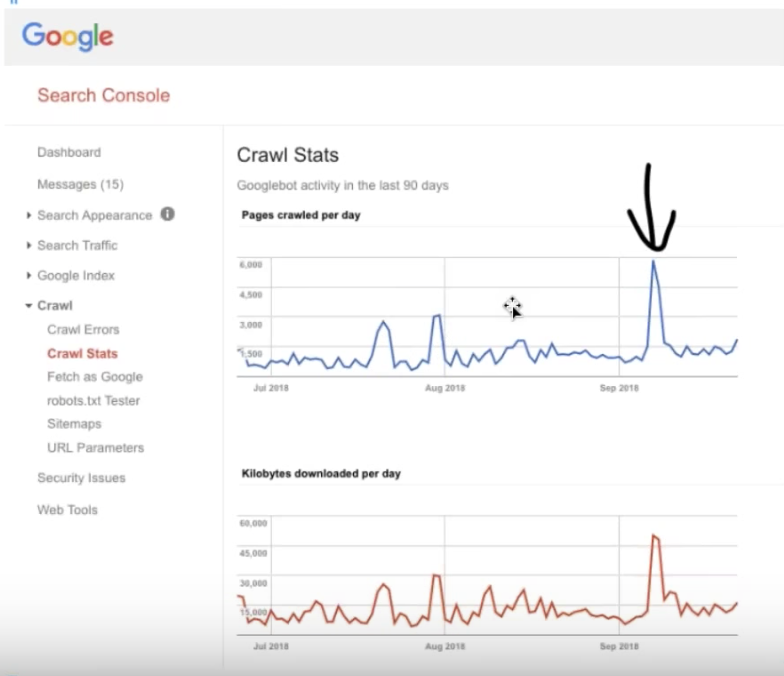
起初,Google Search Console 9 月 7 日的高峰似乎与网站上的事件无关。 但是,查看 OnCrawl 中的日志分析提供了线索:
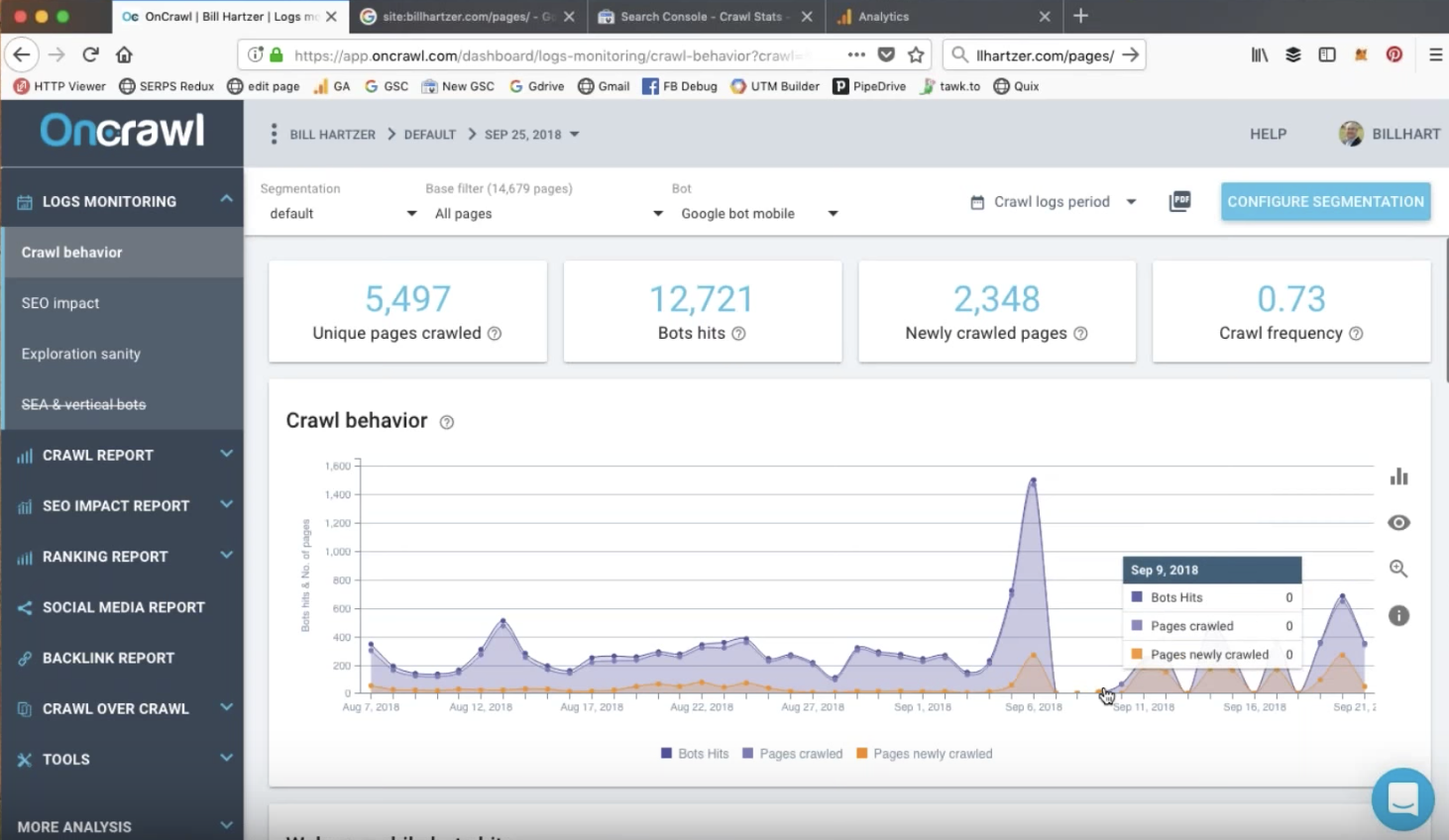
通过对日志文件的分析,我们可以看到 Google 用于抓取页面的不同机器人的细分。 很明显,在此日期之前,桌面 Googlebot 的活动急剧下降,而且这个峰值 - 与早期的较小峰值不同 - 几乎完全由移动 Google bot 已编入索引的独特页面上的点击组成。
谷歌分析记录的自然流量增加了 50%,证实这一峰值对应于 9 月初网站的移动优先索引,比谷歌发出警报早了几周!
修改网站的 URL 结构
8 月中旬,Bill 对他的 URL 结构进行了更改,以使其对 SEO 更友好。
谷歌搜索控制台在修改后记录了两个大的峰值,确认谷歌识别了主要的网站事件并将它们用作重新抓取网站 URL 的信号。
当我们在 OnCrawl 中观察到这些点击的细分时,很明显第二个峰值不是峰值,但该网站上页面的高爬取率会持续数天。 很明显,谷歌已经接受了这些变化,因为比尔能够通过观察变化后几天内抓取活动的差异来确认。
用于进行技术审核的有用 OnCrawl 报告和功能
SEO 访问和 SEO 活动页面
OnCrawl 处理您的日志文件数据以提供有关 SEO 访问或来自 Google SERP 列表的人类访问者的准确信息。
您可以跟踪访问次数,或查看 SEO 活动页面,这些页面是网站上接收自然流量的各个页面。
作为审计的一部分,您可能想要调查的一件事是某些排名页面没有收到自然流量(或者,换句话说,不是 SEO 活动页面)的原因。
新鲜排名
OnCrawl 的 Fresh Rank 等指标提供了重要信息。 在这种情况下:从 Google 首次抓取页面到页面获得第一次 SEO 访问之间的平均延迟天数。
#FreshRank 可帮助您了解第一次需要抓取页面多少天并获得其第一次 #SEO 访问 #oncrawlwebinar pic.twitter.com/WVojWXKStC
— OnCrawl (@OnCrawl) 2018 年 9 月 25 日
内容推广策略和开发反向链接可以帮助更快地为新页面赢得流量。 在本次审核中,网站上的某些页面(例如通过社交网络推广的博客文章)获得的新鲜排名要低得多。
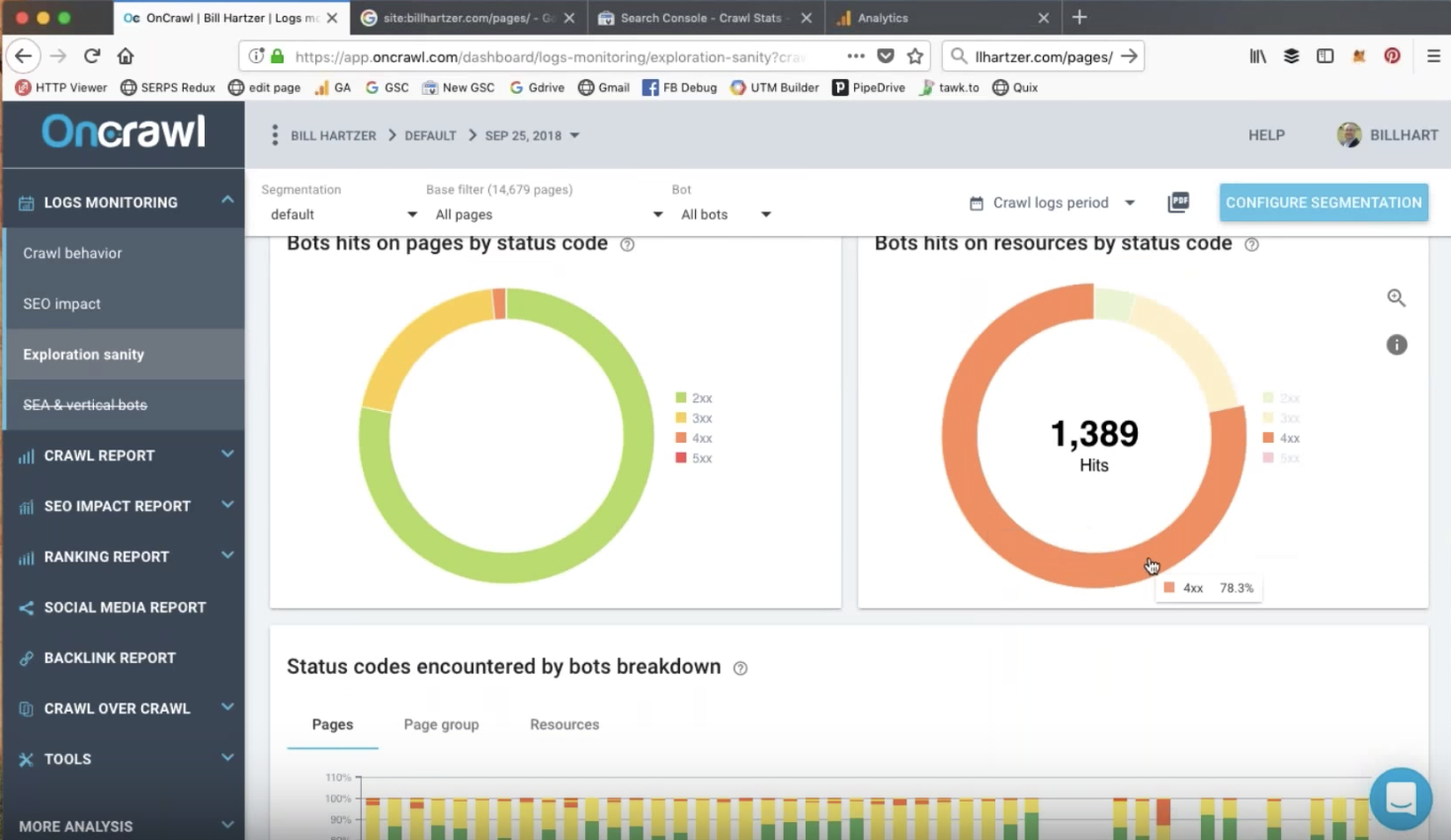
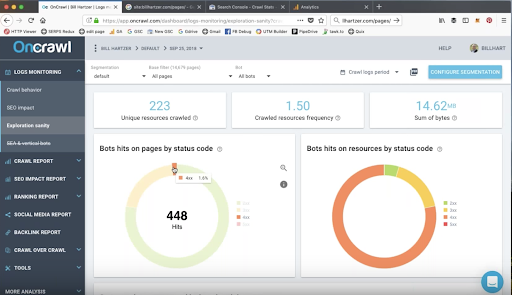
机器人通过状态码点击页面和资源
漫游器可能正在访问返回 404 或 410 错误的 URL。 这可能涉及 CSS、JavaScript、PDF 或图像文件等资源。
这些是您在审核期间肯定要调查的元素。 重定向这些 URL 并删除指向它们的内部链接可以快速获胜。
在审核期间,记录应处理的元素会很有帮助,例如向机器人返回状态错误的 URL。

数据浏览器报告:自定义报告
OnCrawl 数据浏览器提供快速过滤器来生成您可能感兴趣的报告,但您也可以根据您感兴趣的标准提取自己的报告。 例如,您可能想要调查具有反弹和高加载时间的 SEO 活动页面。
数据浏览器报告:活动孤立页面
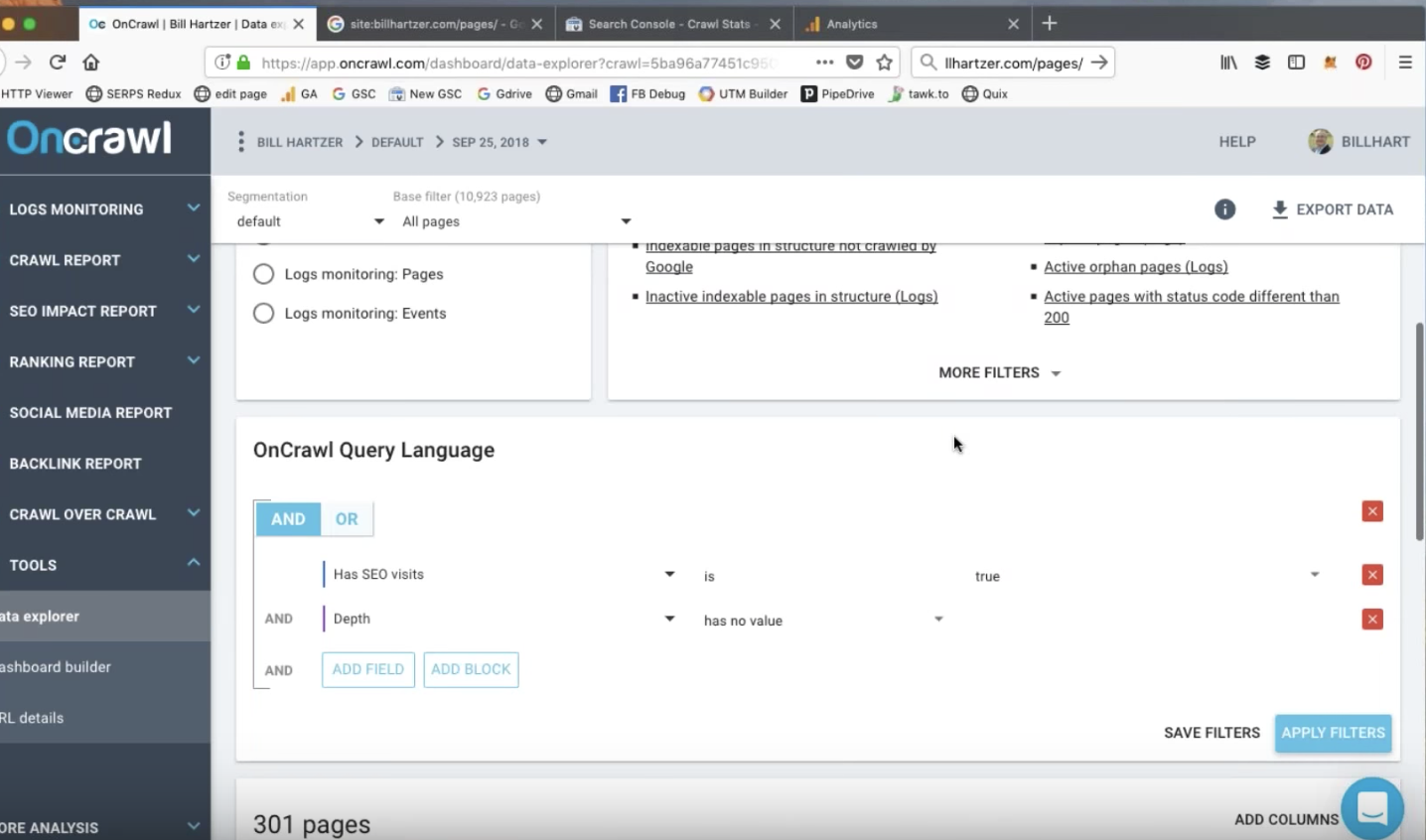
通过结合分析、爬网和日志文件数据,OnCrawl 可以帮助您发现具有自然人工访问的页面,这些页面并不总是为您的网站带来价值。 使用来自日志文件的数据的优势在于,您可以发现您网站上已访问的每个页面,包括可能没有 Google Analytics 代码的页面。
比尔能够识别 RSS 提要页面上的 SEO 有机访问,可能是通过来自外部来源的链接。 这些页面是他网站上的孤立页面; 他们没有链接到他们的“父”页面。 这些页面不会为他的 SEO 策略带来任何额外的价值,但它们仍然会收到一些来自自然流量的访问。
这些页面非常适合开始优化。
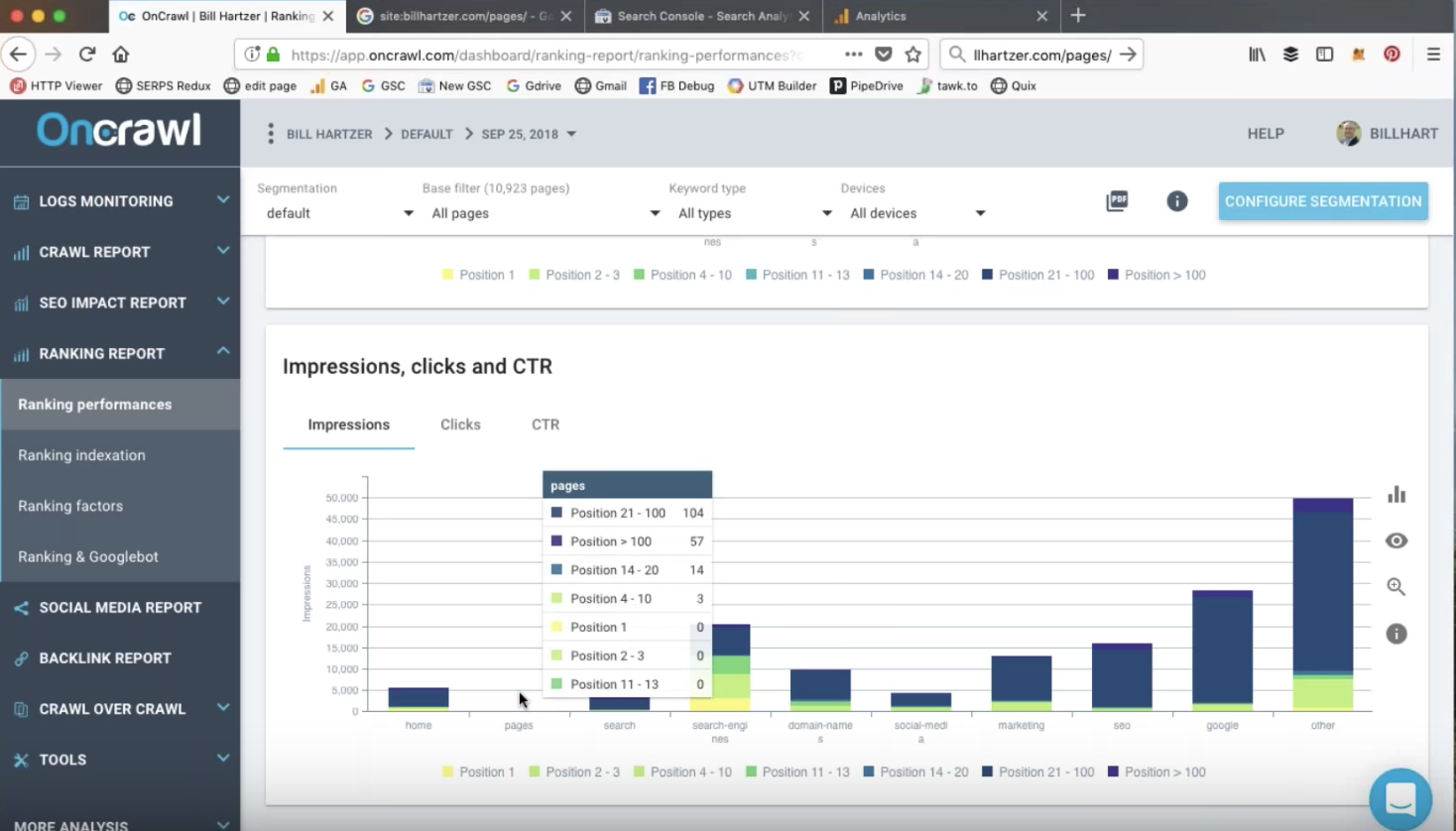
关键字排名的搜索分析
排名数据可以从 Google Search Console 中获取。 直接在旧版 Google Search Console 中,您可以前往 Search Traffic,然后 Search Analytics,查看过去 90 天的 Clicks、Impressions、CTR 和 Positions。
OnCrawl 提供有关此信息如何与整个站点相关的清晰报告,使您可以比较站点上的页面总数、排名页面的数量以及获得点击的页面数量。
展示次数、点击率和点击次数
网站细分允许您一目了然地确认您网站上的哪些类型或页面组正在排名,以及结果在哪个页面上。
在这次审计中,Bill 能够使用 OnCrawl 的指标来发现排名靠前的页面类型。 这些是他知道他应该继续制作以增加网站流量的页面类型。
排名页面的点击量与排名位置密切相关:超过 10 的位置不再出现在搜索结果的第一页,此时大多数关键字的点击量将急剧下降。
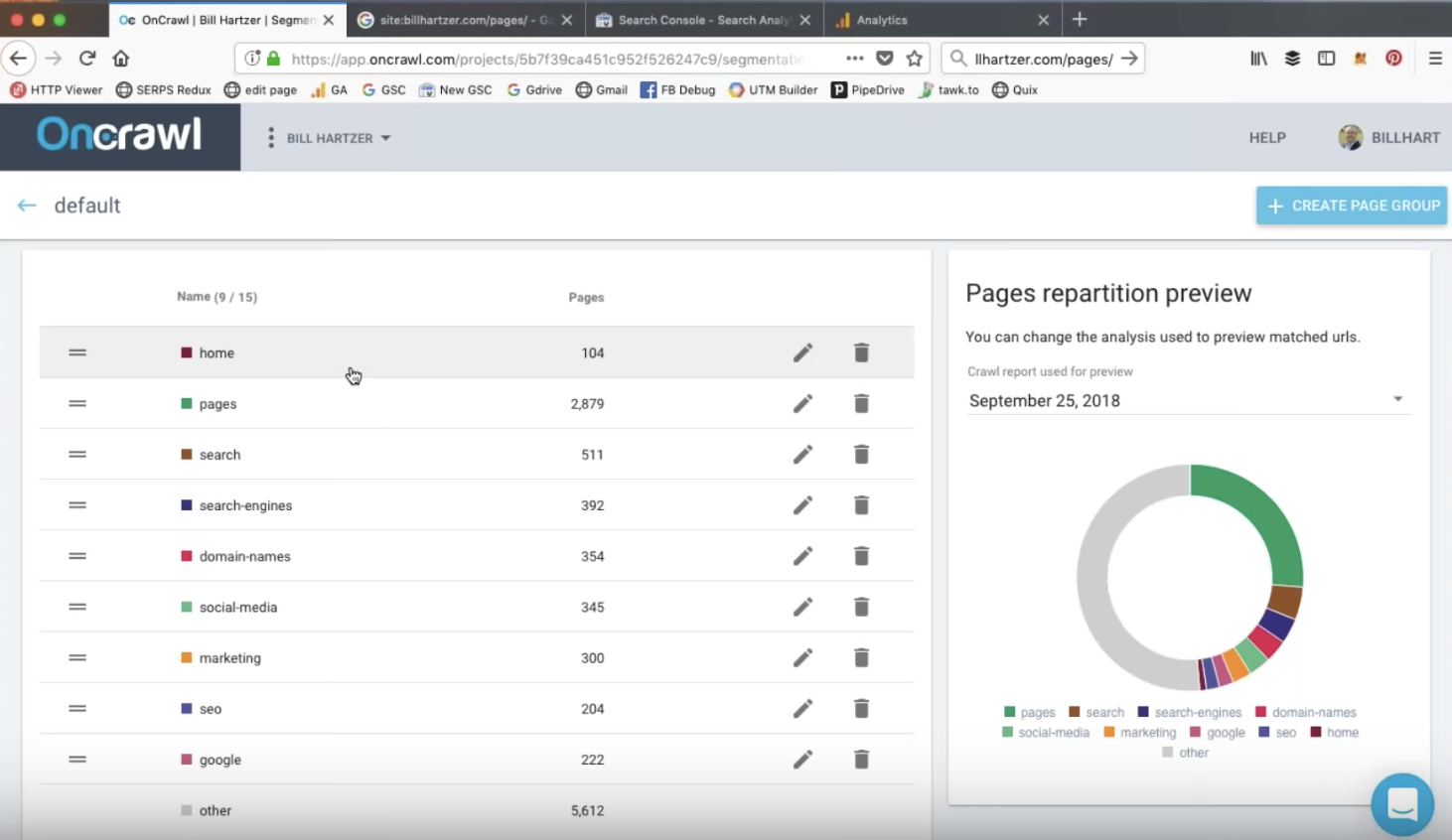
网站细分
OnCrawl 的分段是一种将您的页面分组为有意义的集合的方法。 虽然提供了自动分段,但您可以编辑过滤器,或从头开始创建自己的分段。 使用 OnCrawl 查询语言过滤器,您可以根据许多不同的条件在组中包含或排除页面。
在 Bill 在网络研讨会中查看的网站上,细分基于网站上的不同目录。
结构中的页面 > 已爬网 > 排名 > 活跃
在 OnCrawl 排名报告中,“结构中的页面 > 已爬网 > 排名 > 活动”图表可以提醒您页面排名和访问的问题。
此图表向您展示:
- 结构中的页面:通过您网站上的不同链接可以到达的页面数量
- 已抓取:Google 已抓取的页面
- 排名:出现在 Google SERP 中的页面
- 活跃:获得自然访问的页面
您的审核将希望查看此图中条形之间差异的原因。
但是,结构中的页数与抓取的页数之间的差异可能是故意的,例如,如果您通过在 robots.txt 文件中禁止漫游器来阻止 Google 抓取某些网页。 这是您要在审核期间验证的内容。
您可以通过单击图表在 OnCrawl 中查看此类数据。
关键要点
日志文件分析可帮助您检测机器人命中的峰值并每天监控机器人活动#oncrawlwebinar
今天与@bhartzer pic.twitter.com/3DAC5d36j9 的网络研讨会— OnCrawl (@OnCrawl) 2018 年 9 月 25 日
本次网络研讨会的主要内容包括:
- 网站结构的重大变化会导致抓取活动发生重大变化。
- Google 的免费工具会报告以可能使其看起来不准确的方式聚合、平均或四舍五入的数据。
- 日志文件允许您查看真实的机器人行为和自然访问。 结合爬取数据和日常监控,它们是检测峰值的强大工具。
- 准确的数据对于理解发生的原因和事件是必要的,而这只能通过在 OnCrawl 等工具中对分析、爬网、排名和特别是日志文件数据进行交叉分析来实现。
免费试用 OnCrawl
您是否有兴趣将这些技术应用于您的站点以获得可操作的审计见解?
错过了直播? 观看重播!
即使您无法参加实时网络研讨会,或者您无法参加完整的会议,您仍然可以查看完整版本。