
Javascript:如何使用 Oncrawl 测试 SSR 和/或预渲染实现?
已发表: 2021-09-13用网站的 JavaScript 实现诊断 SEO 问题并不总是那么容易。 当您为机器人选择服务器端渲染或预渲染时,任务可能会变得更加复杂。
您必须确保提供给 Google bot 的版本是完整的,所有 javascript 元素都已在服务器端执行,并且存在于 bot 抓取的 html 中。
在本文中,我们将了解如何使用 Oncrawl 快速轻松地测试所有页面的 JS 渲染。
搜索引擎优化和 JS
在开始实践之前,让我们快速回顾一下对服务器端渲染(SSR)的 SEO 和网站 javascript 元素的预渲染的兴趣。
JS 和 Google:良好实践
默认情况下,javascript 的 HTML 呈现由客户端完成,即您的 Web 浏览器。 当您请求包含 JS 元素的页面时,是您的浏览器执行此 javascript 代码以显示完整页面。 这称为客户端渲染 (CSR)。
对于谷歌来说,这是一个问题,因为它需要大量的时间,尤其是资源。 它强制它浏览你的页面两次,一次是检索代码,第二次是在呈现 JS 的 HTML 之后。
作为您的 SEO 的 CSR 的直接后果,Google 不会立即看到您页面的完整内容,因此它可能会延迟它们的索引。 此外,授予您网站的抓取预算也会受到影响,因为您的页面需要被抓取两次。
SSR(服务器端渲染)
在 SSR 的情况下,javascript 的 HTML 呈现是在服务器端为网站的所有访问者、人类和机器人完成的。 这样一来,Google 就不需要在 JS 中管理内容了,因为它在抓取的时候直接获取了完整的 html。 这纠正了 javascript 在 SEO 中的缺陷。
另一方面,在服务器端实现这种渲染的资源成本可能很重要。 这是第三个选项出现的地方,预渲染。
预渲染
在这种混合配置中,除了搜索引擎机器人之外,所有访问者 (CSR) 都在客户端执行 JS。 将预渲染的 HTML 内容提供给 Google 机器人,以保持 SSR 的 SEO 优势以及 CSR 的经济优势。
这种乍一看可以被视为伪装(为机器人和网页访问者提供不同版本)的做法实际上是 Google 强烈推荐的一种想法。 我们很容易猜到原因。
如何使用 Oncrawl 测试 Javascript 渲染?
有很多方法可以诊断 JS 实现中的 SEO 错误。 通过使用 Oncrawl,您将能够自动测试所有页面,而无需进行任何手动比较。
Oncrawl 能够通过在客户端运行 javascript 来抓取网站。 这个想法是启动两次爬网并生成以下比较:
- 启用 JS 渲染的爬网
- 禁用 JS 渲染的爬网
然后通过几个指标来衡量这两个爬虫之间的差异,这表明部分 javascript 没有在服务器端执行。
请注意,在预渲染的情况下,应使用 Google 用户代理进行第二次抓取,以便抓取网站的预渲染版本。
该测试可以分三个步骤完成:
- 创建爬网配置文件
- 使用每个配置文件爬取站点并生成爬取爬取
- 分析结果
创建爬网配置文件
带有 JS 的配置文件
在您的项目页面中,单击“+ 设置新爬网” 。
这将带您进入爬网设置页面。 将显示您的默认爬网设置。 您可以更改它们或创建新的爬网配置。
爬网配置文件是一组以名称保存以供将来使用的设置。
要创建新的抓取配置文件,请单击右上角的蓝色“+ 创建抓取配置文件”按钮。
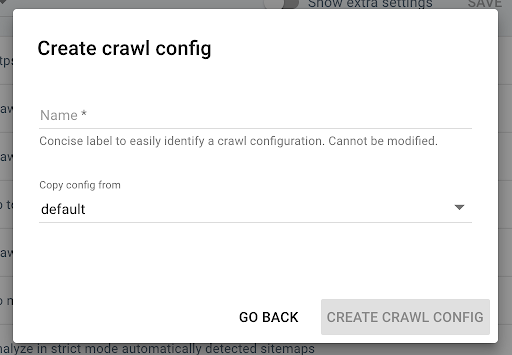
将其命名为“使用 JS 抓取”并复制您通常的抓取配置文件(例如默认值)。
要在这个新配置文件上激活 JS,您必须显示默认隐藏的附加参数。 要访问它们,请单击页面顶部的“显示额外设置”按钮。
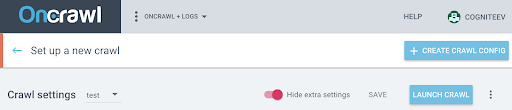
然后转到额外设置并单击 Crawl JS 选项中的“启用” 。
注意:请记住根据您网站服务器的容量调整您的抓取速度,因为 Oncrawl 会为每个 URL 进行更多调用,以便执行 Javascript 中的元素。 理想的速度是您的服务器和站点架构最能支持的速度。 如果 OnCrawl 的爬取速度过快,你的服务器可能跟不上。
没有 JS 的配置文件
对于第二个爬网配置文件,按照相同的步骤并取消选中JS 启用框。
注意:重要的是要有两个具有相同范围的配置文件,以便比较有意义。
如果您的站点处于服务器端渲染中,请转到下一步。
如果您的网站处于基于 Google 漫游器的预渲染状态,您应该向我们发送请求以修改用户代理以进行抓取。 创建配置文件后,直接在应用程序中通过对讲机向我们发送消息,以便我们可以将 Oncrawl 用户代理替换为 Google 机器人用户代理。
开始您的 14 天免费试用
 开始试用
开始试用启动您的爬网并生成 Crawl over Crawl
创建这两个配置文件后,您只需依次使用这两个配置文件来抓取您的网站。 为方便起见,您可以使用爬虫编程功能。

安排爬网
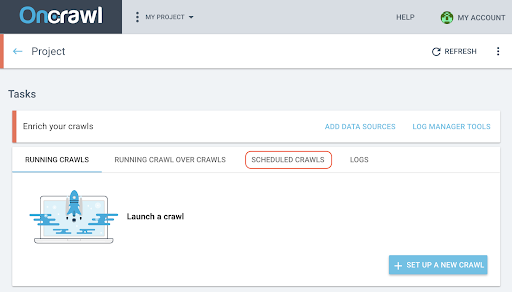
- 在项目页面上,单击抓取跟踪框顶部的“计划抓取”选项卡。
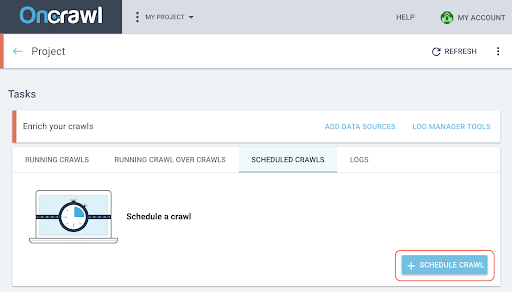
- 单击“+计划抓取”以安排新的抓取。
- 然后,您将需要选择:
- 您要用于未来爬网的爬网配置文件
- 重复抓取的频率,选择“仅一次”。
- 您希望开始爬网的日期、时间(24 小时格式)和时区(按城市)。
- 点击“计划抓取” 。
一旦您的爬网的两种分析都可用,您需要生成一次爬网。 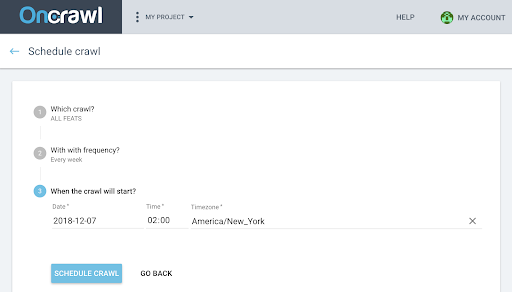
在爬行中生成爬行
- 从项目的主页,启动爬虫爬虫:
- 在“任务”下,单击“运行爬行而不是爬行”选项卡。
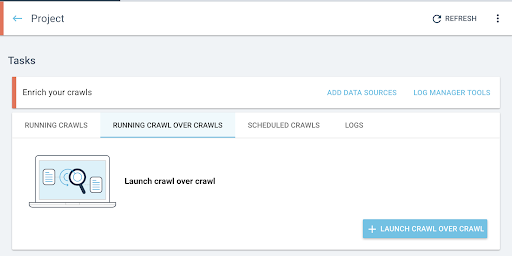
- 点击“+开始爬行而不是爬行” 。
- 选择要比较的两个爬网。
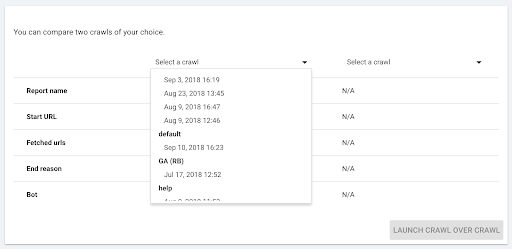
当您点击“+ Run Crawl Over Crawl”时,Oncrawl 会分析两个现有爬取的差异,并将 Crawl Over Crawl 报告添加到两个爬取的分析结果中。
您可以在项目主页的“Start crawl over crawl”选项卡中跟踪此爬取的进度。 由于爬取已经完成,过度爬取将跳过“Crawling”状态,直接从“Analysis”开始。
分析结果
转到以下三个视图的爬虫报告:
- 结构
- 内容
- 内部链接
您还可以下载我们的自定义仪表板。
要看哪些指标?
页面爬网、每页平均字数和平均文本代码比
如果两个配置文件已爬取了相同数量的页面,第一个指标 Page crawled 会立即向您显示。
如果差异不显着,您可以检查两个页面指示器:
- 每页平均字数
- 平均文本与代码的比率
这两个指标将突出显示在客户端执行或不执行 javascript 的 html 内容的差异。
如果平均每页字数较少,则说明部分页面内容没有JS渲染是不可用的。
同理,如果 text to ratio 较低,则表示部分页面内容在没有 JS 渲染的情况下是不可用的。
文本与代码的比率衡量页面内容有多少是可见的(文本),有多少是编码的内容(代码)。 报告的百分比越高,与代码量相比,页面包含的文本就越多。
深度、排名和链接
然后,您可以查看与内部网格相关的更敏感的指标。 如果没有 JS 渲染,一小部分页面内容不可用,这对您的 SEO 来说不一定有问题,但如果它影响您的内部网格,那么对您网站的可抓取性和抓取预算的影响更为重要。
比较平均深度、平均 Inrank、平均 Inlinks 数和内部外链数。
平均深度的增加、平均 inrank 的减少以及内链和外链的平均数量的减少是在服务器端未预渲染的 JS 中管理的网格块存在的指标。 因此,某些链接无法立即提供给 google bot。
这可能会对您的网站的全部或部分产生影响。 然后有必要按页面组研究这些修改,以确定某些类型的页面是否因这个 javascript 网格而处于不利地位。
数据浏览器将允许您使用过滤器来突出这些元素。
进一步使用数据浏览器和 URL 详细信息
在数据浏览器中
当您在数据资源管理器中查看 Crawl over Crawl 数据时,您将看到两列 URL:一列用于 Crawl 1 URL,另一列用于 Crawl 2 URL。
然后,您可以将上面提到的每个指标(抓取的页面、字数、文本编码比率、深度、排名、链接)添加两次,以并排显示 Crawl 1 和 Crawl 2 的值。
通过使用过滤器,您将能够识别差异最大的 URL。
网址详情
如果您已确定 SSR 和/或预渲染版本与客户端渲染版本之间的差异,那么您需要更详细地了解哪些 JS 元素未针对 SEO 进行优化。
通过单击数据浏览器中的页面,您可以切换到 URL 详细信息,然后您可以通过单击“查看源”选项卡查看 Oncraw 所看到的源代码。
然后,您可以通过单击复制 HTML 源来检索 HTML 代码。
在左上角,您可以从一个爬取切换到另一个爬取来检索另一个版本的代码。
通过使用 html 代码比较工具,您可以比较一个页面的两个版本,在客户端执行 JS 和不执行 JS。 剩下的就看你自己了!