
如何为下一次 SEO 迁移扩展产品重定向
已发表: 2020-07-21向任何 SEO 询问与 SEO 相关的哪些任务最让他们畏缩。 他们可能会通过链接构建或网站迁移来回应。 大多数人都同意第一个:链接建设真的很痛苦。 第二个反应总是让我感到惊讶。 我是网站迁移的忠实粉丝,甚至写过为什么你现在应该优先考虑迁移。
为什么对网站迁移如此焦虑? 这并非没有优点。 没有考虑到 SEO 的糟糕迁移可能会导致性能显着下降。 下面是一张让 SEO 彻夜难眠的例子。 我不会写成功迁移的每一步,但会详细介绍针对更大痛点之一的扩展解决方案:重定向。
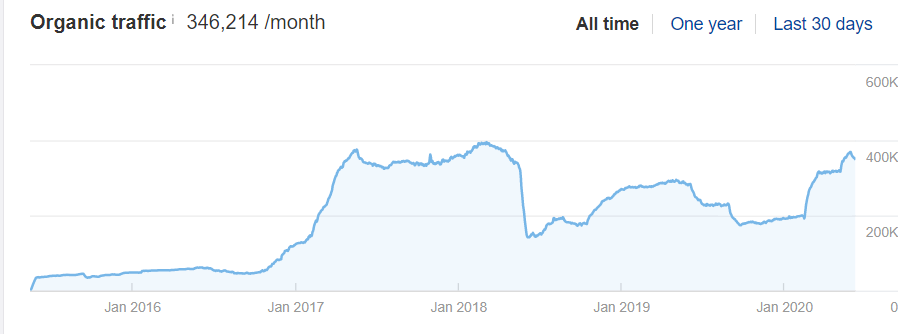
该网站在 2018 年迁移失败,他们用了近 3 年的时间才恢复了有机性能
网站迁移重定向的目的
为了避免发生网站迁移后灾难性的自然性能下降,需要实施 301 重定向。 该过程从将旧网站上的每个页面映射到新网站开始。 这需要 1:1 映射。 映射 URL 后,您可以利用 HTACCESS 文件为每个 URL 实现 301 状态重定向。 未能正确映射重定向或使用正确的 301 状态通常是启动后自然流量下降的原因。
即使是手动完成,映射您的核心网站页面(主页、关于我们、类别页面甚至文章/博客)也相当简单。 但是,您如何为拥有数千、数十万甚至数百万项目页面的电子商务网站映射重定向? 让我们介绍两种独特的方法。
方法一:识别 URL 模式
利用您当前的网站和开发环境,您将能够比较单个产品。 假设您的迁移现在需要更改 URL,是时候确定任何模式了。 例如,如果您当前网站的 CMS 是 Magento 并且您正在迁移到 Shopify,则以下是同一产品的两个不同 URL。
MAGENTO .com/product-name.html
SHOPIFY .com/products/product-name
在这种情况下,我们可以使用一些 Excel 向导来扩展 URL 映射,而无需单独映射每个产品。

A 列 –列出您现有网站的所有产品 URL(利用您最喜欢的爬虫获取此信息)
B 列 –使用“连接”公式 =CONCATENATE(“/products”,A2)
C 列 –通过 LEFT 公式删除最后 5 个字符 (.html) =LEFT(B2, LEN(B2)-5)
通过您的 SEO 爬虫(在附加您的开发 URL 之后)运行您的 C 列值,以确保所有行的状态为 200。 如果此操作成功,您现在可以为从旧 Magento 站点到新 Shopify 站点的所有产品 URL 提供可扩展的解决方案。
方法二:如果产品 URL 不同怎么办?
如果您的旧网站产品 URL 没有使用产品名称或由数据库动态生成怎么办? 我也有这方面的提示。 这将需要识别模式和 SEO 爬虫,例如 OnCrawl 或 Screaming Frog SEO Spider。
示例:旧网站根据产品 SKU 值生成产品 URL。
旧网址:.com/product/38472
新网址:/com/product/grey-baseball-cap
解决方案 1:比较/匹配标题标签 (VLOOKUP)
如果两个站点之间不存在简单的 URL 匹配解决方案,我们将不得不转向下一个解决方案。 生产标题标签值是否被拉到新的开发站点? 如果是这样,我们可以利用爬虫来比较生产站点和新开发站点以找到匹配值。
示例:没有产品 URL 相关性,但标题标签值匹配
第一步:运行当前生产网站和开发环境的完整爬网。
第二步:将两个爬网导出到一个 Excel 文档,每个文档都在自己的专用选项卡中。


第二步:我们将运行一个 VLOOKUP 值,为了使这个函数正常工作,我们需要将标题标签值放在 URL 的前面。 将 G 列移动到 B 列后,每个选项卡将如下所示。
第三步:打开“sheet 3”选项卡,在 A 列中复制并粘贴开发选项卡中的标题标签值。 设置 B 列以列出您的生产 URL。 C 列将是您的新开发 URL。
第四步:从 sheet3 中针对匹配标题标签值的生产和开发选项卡运行 VLOOKUP。 如果您完全按照我的方式设置工作表,这就是每个值都需要的 VLOOKUP 代码。
=VLOOKUP(A2,生产!$A1:B100000,2,FALSE)
=VLOOKUP(A2,发展!$A1:B100000,2,FALSE)
*请注意,如果您的电子表格中有超过 100,000 个值,那么您需要将 B1 值更改为大于我设置的默认值 100,000。

运行爬网、组织电子表格中的数据和运行 VLOOKUP 的最终结果是一张包含当前 URL 和新开发站点 URL 的工作表。

解决方案 2:比较产品正文副本 (XPath/VLOOKUP)
当 URL 完全不同并且标题标签不匹配时,您可能会想卷起袖子并开始手动匹配 URL。 停止- 我还有一个提示给你。
我们将使用自定义提取来提取和匹配单个产品页面的正文副本。 然后,我们将利用我们在标题标签示例中使用的 VLOOKUP 命令来匹配这两个 URL。
第一步:在生产和开发站点上打开一个匹配的产品页面。 验证两个站点上的产品描述确实相同。
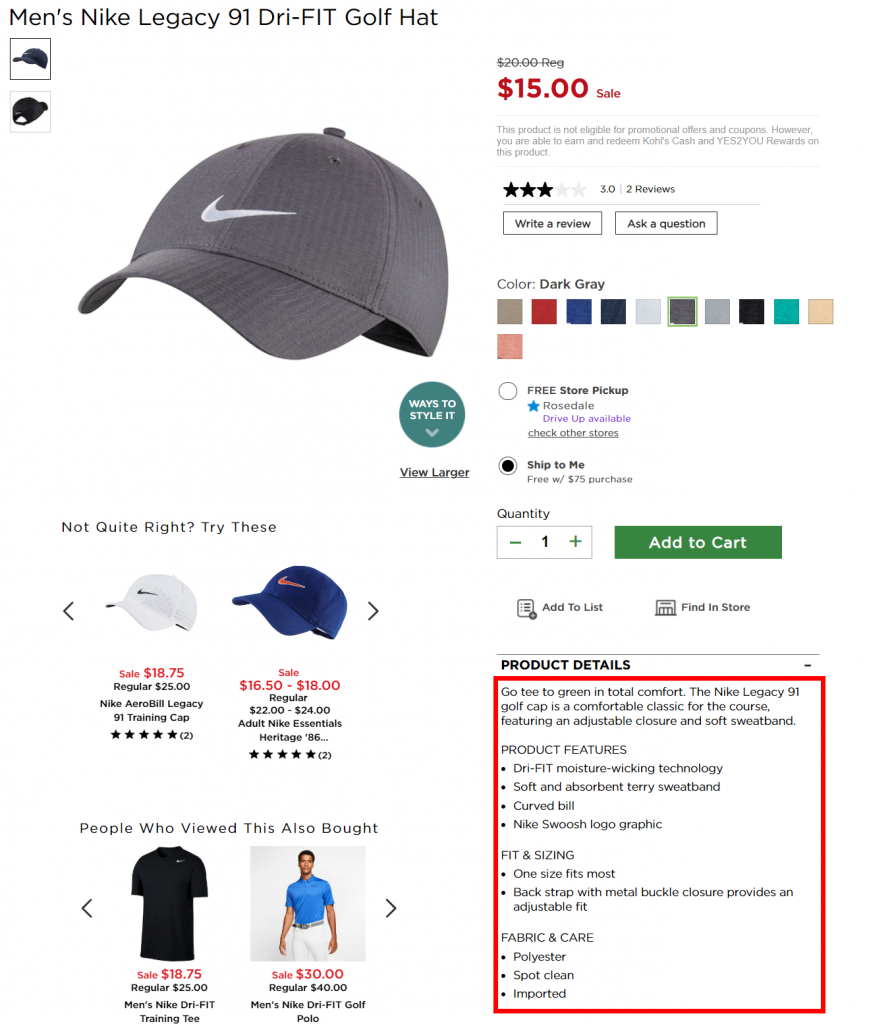
第二步:在 Chrome 网络浏览器中,您可以右键单击产品描述,然后单击“检查元素”。 这将打开 Chrome 开发工具并将您带到我们将要抓取的代码部分。
在 Chrome 开发工具中,再次右键单击并选择“复制”,然后选择“复制 XPath”。 您将获得类似于 //*[@id=”3796805_productDetails”]/div/p[1] 的值
第三步:在 OnCrawl 中,导航到抓取配置文件设置中的抓取(+ 设置新抓取 > 抓取)。 输入此字段的名称,例如“说明”,然后粘贴您最近从 Chrome 开发工具复制的 XPath 代码。 您需要在末尾添加“/text()”以捕获产品描述文本。
在此示例中,我还选中了“压缩空白”以避免描述中出现任何段落字符。
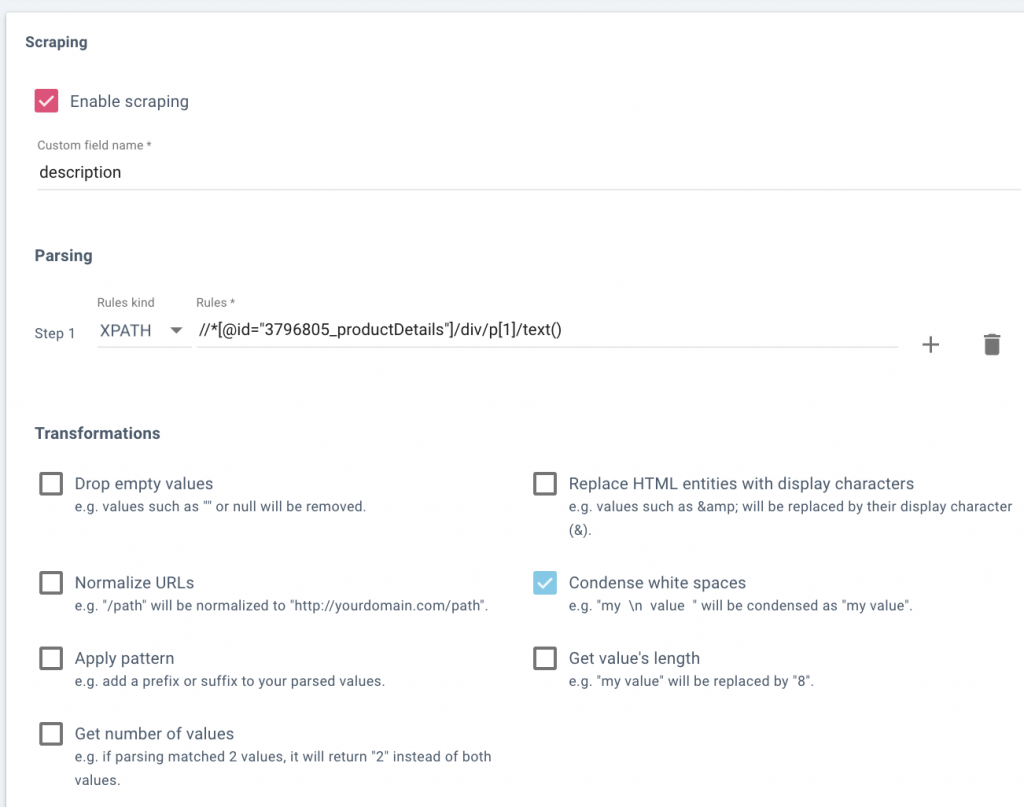
第四步:测试您的自定义提取逻辑。
在 OnCrawl 中,在保存规则之前,您应该在底部的“检查输出”框中输入几个 URL,并确保当您单击“检查”时,您会看到右侧框中的说明:
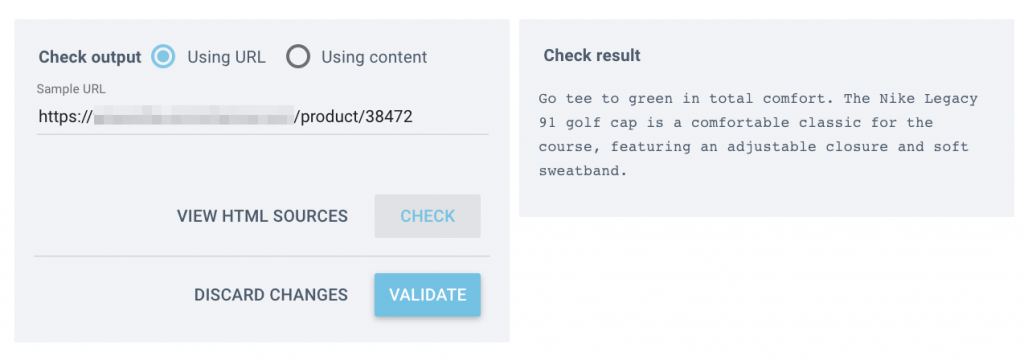
验证提取逻辑是否正常工作后,继续运行所有产品 URL。 抓取完成后,您将能够导出所有提取的描述(绑定到 URL)。

第五步:此时,您将为您的开发站点重复步骤 1-3。 现在,每个环境都有两个不同的选项卡,其中每个产品 URL 都有与其关联的提取描述。
第六步:与标题标签示例类似,我们将使用 VLOOKUP 来匹配生产和开发站点之间的产品描述。 如果操作正确,您将获得一个新旧 URL 列表,您现在可以使用它们来映射您的重定向。

URL 逻辑、标题标签和描述匹配失败?
不要放弃。 我向您保证,您要做的最后一件事是花费手动匹配所有这些 URL 所需的小时数。 以下是我见过的其他一些取得不同程度成功的策略:
- 识别和匹配 Schema.org 标记值
- 识别并匹配图像名称和/或图像 alt 标签
- 有时您很幸运,实际的 SKU 将成为产品模板的一部分
- 识别和匹配产品评论
映射产品重定向的最后努力
有时产品会经历这样的大修,以至于不必手动构建 1:1 映射是不可能的。 如果这是您的情况,请考虑使用上述所有策略来尽可能多地识别。 作为最后的手段,请考虑分配您的暑期实习生或更多初级资源来帮助解决剩余的无与伦比的产品。
虽然上面列出的策略不是防火解决方案,但我发现它可以解决大量工作。 即使它解决了 75% 的重定向问题,您也会很感激能够节省您原本会花费在手动映射这些重定向上的时间。