
如何使用 Python 根据 URL 位置预测非品牌自然流量收入
已发表: 2022-05-24什么是SEO预测?
SEO 预测或自然流量估算是使用您自己网站的数据或第三方数据来估算您网站未来的自然流量、SEO 收入和 SEO 投资回报率的过程。 这个估计可以根据我们的数据使用许多不同的方法来计算。
在本教程中,我们希望根据我们的 URL 位置及其当前收入来预测我们的非品牌自然收入和非品牌自然流量。 这可以帮助我们作为 SEO 获得其他利益相关者的更多支持:从增加每月、每季度或每年的预算到产品和开发团队的更多工时。
请记住,本教程不仅适用于非品牌自然流量; 通过进行一些更改并了解 Python,您可以使用它来估计您的目标页面流量。
因此,我们可以生成如下图所示的 Google Sheet。
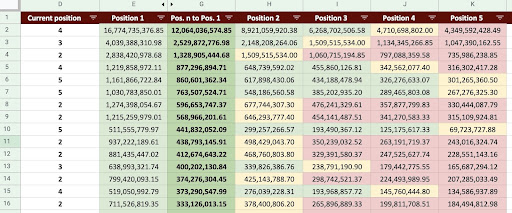
谷歌表格图片
非品牌SEO流量预测
阅读介绍后,您可能会问的第一个问题是,“为什么要计算非品牌自然流量?”。
让我们考虑像亚马逊这样的公司。 当您想购买书籍或口罩时,只需搜索“buy mask amazon”即可。
品牌通常是最重要的,当你想买东西时,你的偏好是从这些公司购买你需要的东西。 在每个行业中,都有影响用户在 Google 搜索中的行为的品牌公司。
如果我们检查亚马逊的 Google Search Console (GSC) 数据,我们可能会发现它从品牌查询中获得了大量流量,而且大多数时候,品牌查询的第一个结果是该品牌的网站。
作为一名 SEO,和我一样,您可能已经听过很多次了,“只有我们的品牌才能帮助我们的 SEO!” 我们如何说“不,不是这样”,并显示非品牌查询的流量和收入?
证明这一点更加复杂,因为我们知道谷歌的算法非常复杂,很难将品牌搜索与非品牌搜索区分开来。 但这就是使我们作为 SEO 所做的一切变得更加重要的原因。
在本教程中,我将向您展示如何区分品牌和非品牌这两者,并向您展示 SEO 的强大功能。
即使您的公司没有品牌,您仍然可以从这篇文章中获益良多:您可以了解如何估算您网站的自然数据。
基于流量估计的 SEO ROI
无论您身在何处或做什么,资源都是有限的; 无论是预算还是工作日的小时数。 了解如何最好地分配资源在整体和 SEO 投资回报率 (ROI) 中起着重要作用。
CMO、营销副总裁或绩效营销人员都有不同的 KPI,并且需要不同的资源来实现他们的目标。 确保您获得所需的最佳方法是通过展示它将给公司带来的回报来证明其必要性。 SEO 投资回报率也不例外。 当一年中的预算分配时间到来并且您的团队想要请求更大的预算时,估算您的 SEO 投资回报率可以让您在谈判中占上风。 计算出非品牌流量估算后,您可以更好地评估实现预期结果所需的预算。
SEO预测对SEO策略的影响
正如我们所知,每 3 或 6 个月我们都会审查我们的 SEO 策略并对其进行调整,以尽可能获得最佳结果。 但是,当您不知道对您的公司来说最大的利润在哪里时会发生什么? 您可以做出决定,但是当您对网站的流量有更全面的了解时,它们不会像做出的决定那样有效。
非品牌有机流量收入估算可以与您的登录页面和查询细分相结合,以提供全局,帮助您作为 SEO 经理或 SEO 策略师制定更好的策略。
预测自然流量的不同方法
SEO 社区中有很多不同的方法和公共脚本来预测未来的自然流量。
其中一些方法包括:
- 全站有机流量预测
- 特定页面(博客、产品、类别等)或单个页面的自然流量预测
- 针对特定查询(查询包含“购买”、“操作方法”等)或查询的有机流量预测
- 特定时期的自然流量预测(尤其是季节性事件)
我的方法是针对特定页面的,时间范围是一个月。
[案例研究] 通过页面 SEO 推动新市场的增长
 阅读案例研究
阅读案例研究如何计算自然流量收入
准确的方法基于您的 Google Analytics (GA) 数据。 如果您的网站是全新的,则必须使用 3rd 方工具。 当您拥有自己的数据时,我宁愿避免使用此类工具。
请记住,您需要针对您的一些真实页面数据测试您正在使用的第 3 方数据,以发现其数据中可能存在的任何错误。
如何用 Python 计算非品牌 SEO 流量收入
到目前为止,我们已经介绍了许多我们应该熟悉的理论概念,以便更好地理解我们的自然流量和收入预测的不同方面。 现在,我们将深入探讨本文的实际部分。
首先,我们将从计算 CTR 曲线开始。 在我关于 Oncrawl 的CTR 曲线文章中,我解释了两种不同的方法以及您可以通过对我的代码进行一些更改来使用的其他方法。 我建议你先阅读点击曲线文章; 它为您提供有关本文的见解。
在本文中,我调整了我的代码的某些部分以获得我们在流量估计中想要的特定结果。 然后,我们将从 GA 中获取数据并使用 GA 收入维度来估算我们的收入。
使用 Python 预测非品牌自然流量收入:入门
您可以自己运行此代码,无需了解任何 Python。 但是,我希望您对 Python 语法和我将在此预测代码中使用的 Python 库的基本知识有所了解。 这将帮助您更好地理解我的代码并以对您有用的方式对其进行自定义。
为了运行此代码,我将使用 Visual Studio Code 和 Microsoft 的 Python 扩展,其中包括“Jupyter”扩展。 但是,您可以使用 Jupyter notebook 本身。
对于整个过程,我们需要用到这些 Python 库:
- 麻木的
- 熊猫
- 情节
此外,我们将导入一些 Python 标准库:
- JSON
- 打印
# 导入我们流程所需的库 导入json 从 pprint 导入 pprint 将 numpy 导入为 np 将熊猫导入为 pd 将 plotly.express 导入为 px
第一步:计算相对点击率曲线(Relative click curve)
第一步,我们要计算我们的相对 CTR 曲线。 但是,什么是相对点击率曲线?
什么是相对点击率曲线?
让我们首先谈谈“绝对点击率曲线”。 当我们计算绝对 CTR 曲线时,我们说第一个位置的 CTR 中值(或平均 CTR)为 36%,第二个位置为 20%,以此类推。
在相对 CTR 曲线中,百分比瞬间,我们将每个位置的中位数除以第一个位置的 CTR。 例如,第一个位置的相对 CTR 曲线为 0.36 / 0.36 = 1,第二个位置为 0.20 / 0.36 = 0.55,依此类推。
也许您想知道为什么计算它很有用? 想想排名第一的页面,它的点击率为 44%。 如果此页面转到位置二,CTR 曲线不会下降到 20%,它的 CTR 很可能会下降到 44% * 0.55 = 24.2%。
1. 从 GSC 获取品牌和非品牌自然流量数据
对于我们的计算过程,我们需要从 GSC 获取数据。 第一次,所有数据都将基于品牌查询,下一次,所有数据都将基于非品牌查询。
要获取此数据,您可以使用不同的方法:从 Python 脚本或从“Search Analytics for Sheets”Google 表格插件。 我将使用 GSC API 资源管理器。
此数据的输出是两个 JSON 文件,显示每个页面的性能。 一个 JSON 文件显示基于品牌查询的着陆页性能,另一个显示基于非品牌查询的着陆页性能。
要从 GSC API 资源管理器获取数据,请执行以下步骤:
- 转到 https://developers.google.com/webmaster-tools/v1/searchanalytics/query。
- 最大化页面右上角的 API 资源管理器。
- 在“
siteUrl”字段中,插入您的域名。 例如“https://www.example.com”或“http://your-domain.com”。 - 在请求正文中,首先我们需要定义“
startDate”和“endDate”参数。 我的偏好是过去 30 天。 - 然后我们添加“
dimensions”并为此列表选择“page”。 - 现在我们添加“
dimensionFilterGroups”来过滤我们的查询。 一次用于品牌查询,另一次用于非品牌查询。 - 最后,我们将“
rowLimit”设置为 25,000。 如果您每月获得自然流量的网站页面超过 25K,则必须修改您的请求正文。 - 发出每个请求后,保存 JSON 响应。 对于品牌性能,将 JSON 文件保存为“
branded_data.json”,对于非品牌性能,将 JSON 文件保存为“non_branded_data.json”。
在我们了解了请求正文中的参数后,您唯一需要做的就是复制并粘贴到请求正文下方。 考虑用“ brand variation names ”替换您的品牌名称。
您必须使用管道或“ | ”。 例如“ amazon|amazon.com|amazn ”。
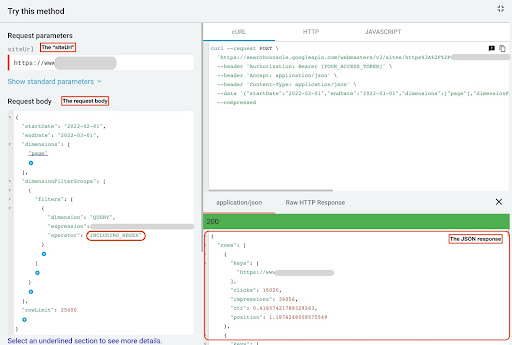
GSC API 浏览器
品牌请求正文:
{
"开始日期": "2022-02-01",
"endDate": "2022-03-01",
“方面”: [
“页”
],
“维度过滤器组”:[
{
“过滤器”:[
{
“维度”:“查询”,
“表达”:“品牌变体名称”,
“操作员”:“INCLUDING_REGEX”
}
]
}
],
“行限制”:25000
}
非品牌请求正文:
{
"开始日期": "2022-02-01",
"endDate": "2022-03-01",
“方面”: [
“页”
],
“维度过滤器组”:[
{
“过滤器”:[
{
“维度”:“查询”,
“表达”:“品牌变体名称”,
“操作员”:“EXCLUDING_REGEX”
}
]
}
],
“行限制”:25000
}
2. 将数据导入我们的 Jupyter notebook 并提取站点目录
现在,我们需要将数据加载到 Jupyter 笔记本中,以便能够对其进行修改并从中提取我们想要的内容。 让我们从上面离开的地方继续。
为了加载品牌数据,您需要执行以下代码块:
# 为品牌的网站 URL 性能和品牌查询创建一个 DataFrame
使用 open("./brand_data.json") 作为 json_file:
brand_data = json.loads(json_file.read())["rows"]
brand_df = pd.DataFrame(brand_data)
# 将“keys”列重命名为“landing page”列,并将“landing page”列表转换为 URL
brand_df.rename(columns={"keys": "landing page"}, inplace=True)
brand_df["着陆页"] = brand_df["着陆页"].apply(lambda x: x[0])
对于着陆页非品牌性能,您需要执行以下代码块:
# 为非品牌查询的网站 URL 性能创建一个 DataFrame
使用 open("./non_brand_data.json") 作为 json_file:
non_brand_data = json.loads(json_file.read())["rows"]
non_brand_df = pd.DataFrame(non_brand_data)
# 将“keys”列重命名为“landing page”列,并将“landing page”列表转换为 URL
non_brand_df.rename(columns={"keys": "landing page"}, inplace=True)
non_brand_df["着陆页"] = non_brand_df["着陆页"].apply(lambda x: x[0])
我们加载我们的数据,然后我们需要定义我们的站点名称以提取其目录。
# 在引号之间定义您的站点名称。 例如,“https://www.example.com/”或“http://mydomain.com/” SITE_NAME = "https://www.your_domain.com/"
我们只需要从非品牌表现中提取目录。
# 获取每个登陆页面(URL)目录
non_brand_df["目录"] = non_brand_df["着陆页"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
然后我们打印出目录,以便选择哪些目录对这个过程很重要。 您可能希望选择所有目录以更好地了解您的站点。
# 为了获取输出中的所有目录,我们需要操作 Pandas 选项
pd.set_option("display.max_rows", 无)
# 网站目录
non_brand_df["目录"].value_counts()
在这里,您可以插入对您很重要的目录。
""" 选择哪些目录对于获取他们的 CTR 曲线很重要。
将目录插入到“important_directories”变量中。
例如,“产品、标签、产品类别、杂志”。 用逗号分隔目录值。
"""
IMPORTANT_DIRECTORIES = "你的重要目录"
IMPORTANT_DIRECTORIES = IMPORTANT_DIRECTORIES.split(",")
3.根据页面位置标记页面并计算相对CTR曲线
现在我们需要根据它们的位置标记我们的着陆页。 我们这样做是因为我们需要根据每个目录的着陆页位置来计算每个目录的相对 CTR 曲线。
# 标记非品牌职位
对于范围内的 i (1, 11):
non_brand_df.loc[
(non_brand_df["position"] >= i) & (non_brand_df["position"] < i + 1),
“位置标签”,
] = 我
然后,我们根据目录对登录页面进行分组。

# 根据“目录”值对登录页面进行分组 non_brand_grouped_df = non_brand_df.groupby(["目录"])
让我们定义计算相对 CTR 曲线的函数。
def each_dir_relative_ctr_curve(dir_df, key):
"""函数计算每条IMPORTANT_DIRECTORIES的相对CTR曲线。
"""
# 根据“位置标签”值对“non_brand_grouped_df”进行分组
dir_grouped_df = dir_df.groupby(["位置标签"])
# 保存每个位置中值 CTR 的列表
中位数_ctr_list = []
# 将每个目录存储为键,并将其“median_ctr_list”作为值
目录_median_ctr = {}
# 遍历每个“dir_grouped_df”组
对于范围内的 i (1, 11):
# 一个 try-except 用于处理目录例如位置 4 没有任何数据的情况
尝试:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"]))
除了:
中位数_ctr_list.append(0)
# 计算相对点击率曲线
directory_median_ctr[key] = np.array(median_ctr_list) / np.array(
[median_ctr_list[0]] * 10
)
返回目录_median_ctr
定义函数后,我们运行它。
# 遍历目录并执行 'each_dir_relative_ctr_curve' 函数
目录_median_ctr_dict = dict()
对于 key,non_brand_grouped_df 中的项目:
如果键入 IMPORTANT_DIRECTORIES:
目录_median_ctr_dict.update(每个_dir_relative_ctr_curve(项目,键))
pprint(directories_median_ctr_dict)
现在,我们将加载我们的着陆页、品牌和非品牌、性能并计算我们的非品牌数据的相对 CTR 曲线。 为什么我们只对非品牌数据这样做? 因为我们要预测非品牌的自然流量和收入。
第 2 步:预测非品牌自然流量收入
在第二步中,我们将了解如何检索我们的收入数据并预测我们的收入。
1. 合并品牌和非品牌有机数据
现在,我们将合并我们的品牌和非品牌数据。 这将帮助我们计算每个着陆页上的非品牌自然流量与所有流量相比的百分比。
# 'main_df' 是“整个站点数据”和“非品牌数据”数据帧的组合。
# 使用这个DataFrame,你可以找出我们的点击次数和展示次数最多的地方
# 来自未标记的查询。
main_df = non_brand_df.merge(
brand_df, on="着陆页", suffixes=("_non_brand", "_brand")
)
然后我们修改列以删除无用的列。
# 将 'main_df' 列修改为我们需要的列
main_df = main_df[
[
“登陆页面”,
"clicks_non_brand",
"ctr_non_brand",
“目录”,
“位置标签”,
"clicks_brand",
]
]
现在,让我们计算非品牌点击次数占着陆页总点击次数的百分比。
# 根据着陆页计算非品牌查询点击次数占整个着陆页点击次数的百分比
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x: x["clicks_non_brand"] / (x["clicks_non_brand"] + x["clicks_brand"]),
轴=1,
)
[电子书] 使用 Oncrawl 自动化 SEO
 阅读电子书
阅读电子书2.加载自然流量收入
就像检索 GSC 数据一样,我们有多种获取 GA 数据的方法:我们可以使用“Google Analytics Sheets 插件”或 GA API。 在本教程中,我更喜欢使用 Google Data Studio (GDS),因为它很简单。
要从 GDS 获取 GA 数据,请执行以下步骤:
- 在 GDS 中,创建一个新报表或资源管理器和一个表格。
- 对于维度,添加“着陆页”,对于指标,我们必须添加“收入”。
- 然后,您需要在 GA 中基于来源和媒介创建自定义细分。 过滤“谷歌/自然”流量。 段创建后,将其添加到 GDS 中的段部分。
- 在最后一步,导出表格并将其保存为“
landing_pages_revenue.csv”。
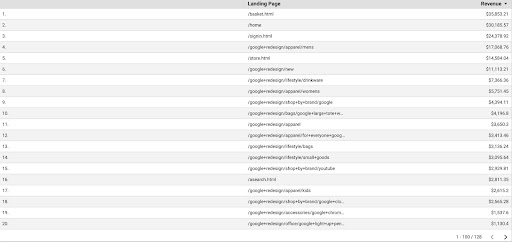
着陆页收入 csv 导出
让我们加载我们的数据。
Organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
现在,我们需要将我们的网站名称附加到 GA 登录页面的 URL。
当我们从 GA 导出数据时,着陆页是相对形式,但我们的 GSC 数据是绝对形式。
不要忘记检查您的 GA 着陆页数据。 在我使用的数据集中,我发现 GA 数据每次都需要稍微清理一下。
# 将 GA 着陆页 URL 与 SITE_NAME 连接起来。
# 另外,重命名列
Organic_revenue_df.loc[:, "登陆页面"] = (
SITE_NAME[:-1] + organic_revenue_df[organic_revenue_df.columns[0]]
)
Organic_revenue_df.rename(columns={"Landing Page": "landing page", "Revenue": "revenue"}, inplace=True)
现在,让我们将 GSC 数据与 GA 数据合并。
# 在这一步中,我将 'main_df' 与 'dk_organic_revenue_df' DataFrame 合并,其中包含非品牌查询数据的百分比 main_df = main_df.merge(organic_revenue_df, on="登陆页", how="left")
在本节的最后,我们对 DataFrame 列进行了一些清理。
# 稍微清理一下 'main_df' DataFrame
main_df = main_df[
[
“登陆页面”,
"clicks_non_brand",
"ctr_non_brand",
“目录”,
“位置标签”,
"clicks_non_brand_percentage",
“收入”,
]
]
3.计算非品牌收入
在本节中,我们将处理数据以提取我们正在寻找的信息。
但在此之前,让我们根据“ IMPORTANT_DIRECTORIES ”过滤我们的登录页面:
# 删除其他目录登陆页面,不包含在“IMPORTANT_DIRECTORIES”中
main_df = (
main_df[main_df["目录"].isin(IMPORTANT_DIRECTORIES)]
.dropna(子集=["收入"])
.reset_index(drop=True)
)
现在,让我们计算非品牌有机收入流量。
我定义了一个我们无法轻易计算的指标,它比其他任何东西都更直观,可以让我们为其分配一个数字。
“ brand_influence ”指标显示了您的品牌实力。 如果您认为 non_brand 搜索会减少对您的业务的销售额,请降低此数字; 例如 0.8 之类的东西。
# 如果您的品牌非常强大,以至于没有您的品牌的查询与使用您的品牌的查询一样多,那么 1 对您有好处。
# 考虑寻找一本书,但查询中没有包含品牌名称。 当您看到亚马逊时,您会从其他市场或商店购买吗?
品牌影响 = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
lambda x: x["revenue"] * x["clicks_non_brand_percentage"] * brand_influence, axis=1
)
让我们绘制一个饼图,以了解基于重要目录的非品牌收入。
# 在这个单元格中,我想根据他们的目录获得所有非品牌登陆页面的收入
non_brand_directory_dist_revenue_df = pd.pivot_table(
main_df,
索引="目录",
值=[“non_brand_revenue”],
aggfunc={"non_brand_revenue": "sum"},
)
pie_fig = px.pie(
non_brand_directory_dist_revenue_df,
values="non_brand_revenue",
名称=non_brand_directory_dist_revenue_df.index,
title="基于网站目录的非品牌收入",
)
pie_fig.update_traces(textposition="inside", textinfo="percent+label")
pie_fig.show()
该图显示了IMPORTANT_DIRECTORIES上的非品牌查询分布。
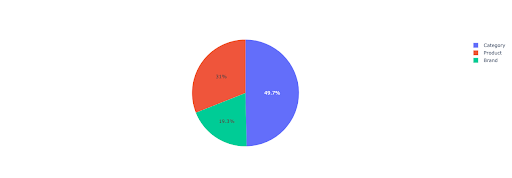
非品牌查询分布
根据我的 CTR 曲线数据,我发现我不能依赖高于 5 的位置的 CTR。因此,我根据位置过滤我的数据。
您可以根据您的数据修改以下代码块。
# 由于我们的 CTR 曲线中的 CTR 准确性,我认为我们可以跳过位置超过 5 的着陆页。因此,我过滤了其他着陆页 main_df = main_df[main_df["位置标签"] < 6].reset_index(drop=True)
4. 计算“每次点击收入”(RPC)
在这里,我创建了一个自定义指标并将其称为“每次点击收入”或 RPC。 这向我们展示了每次非品牌点击产生的收入。
您可以通过不同方式使用此指标。 我发现了一个 RPC 高但点击率低的页面。 当我检查页面时,我发现它在不到一周前被索引,我们可以使用不同的方法来优化页面。
# 计算每次点击产生的收入(RPC:Revenue Per Click)
main_df["rpc"] = main_df.apply(
lambda x: x["non_brand_revenue"] / x["clicks_non_brand"], axis=1
)
5. 预测收入!
我们快到头了,我们一直等到现在才预测我们的非品牌有机收入。
让我们运行最后的代码块。
# 主函数根据不同职位计算收益
对于 main_df.iterrows() 中的索引,row_values:
# 在目录之间切换 CTR 列表
ctr_curve = 目录_median_ctr_dict[row_values["directory"]]
# 循环位置 1 到 5,根据 CTR 的增减计算收益
对于范围内的 i (1, 6):
如果 i == row_values["位置标签"]:
main_df.loc[index, i] = row_values["non_brand_revenue"]
别的:
# main_df.loc[index, i + 1] ==
main_df.loc[index, i] = (
row_values["non_brand_revenue"]
* (ctr_curve[i - 1])
/ ctr_curve[int(row_values["位置标签"] - 1)]
)
# 计算“N to 1”度量。 这显示了当您的排名从“N”变为“1”时收入的增加
main_df.loc[index, "N to 1"] = main_df.loc[index, 1] - main_df.loc[index, row_values["位置标签"]]
查看最终输出,我们有新的列。 这些列的名称是“1”、“2”、“3”、“4”、“5”。
这些名字是什么意思? 例如,我们有一个位于第 3 位的页面,如果它提高了它的位置,我们想预测它的收入,或者我们想知道如果我们的排名下降我们会损失多少。
“1”和“2”列显示了当该页面的平均排名提高时该页面的收入,“4”和“5”列显示了当我们排名下降时该页面的收入。
此示例中的“3”列显示页面的当前收入。
此外,我创建了一个名为“N to 1”的指标。 这会显示此页面的平均排名是否从“3”(或 N)变为“1”,以及该移动对收入的影响程度。
包起来
我在本文中介绍了很多内容,现在轮到您动手并预测您的非品牌自然流量收入了。
这是我们可以使用此预测的最简单方法。 我们可以让这个算法更复杂,并将它与一些 ML 模型结合起来,但这会使文章变得更复杂。
我更喜欢将这些数据保存在 CSV 中并将其上传到 Google 表格。 或者,如果我打算与我的团队或组织的其他成员共享它,我将使用 excel 打开它并使用颜色设置列的格式,以便于阅读。
根据这些数据,您可以预测您的非品牌自然流量投资回报率并将其用于您的谈判过程。