
如何处理机器人放牧和蜘蛛争夺排名?
已发表: 2020-01-23
Google 抓取工具会将您在网站上发布的每条内容都编入索引。 这些爬虫是经过编程的软件,它们跟踪链接和代码并将其传递给算法。 然后,算法将其编入索引并将您的内容添加到庞大的数据库中。 这样,每当用户搜索关键字时,搜索引擎都会从已索引页面的数据库中提取相关结果并对其进行排名。
Google 会为每个网站分配一个抓取预算,并且抓取工具会相应地执行您网站的抓取。 您必须管理和利用抓取预算,以确保对整个网站进行智能抓取和索引。
在这篇文章中,您可以了解处理搜索引擎机器人/蜘蛛或爬虫如何抓取和索引您的网站的技巧和工具。
1、优化Robot.txt的Disallow指令:

Robots.txt 是一个具有严格语法的文本文件,它的作用类似于蜘蛛确定如何抓取您的网站的指南。 robots.txt 文件保存在您网站的主机存储库中,爬虫可从该存储库中查找 URL。 要优化这些 Robots.txt 或“机器人排除协议”,您可以使用一些技巧来帮助您网站的 URL 被 Google 爬虫抓取以获得更高的排名。
其中一个技巧是使用“禁止指令” ,这就像在您网站的特定部分放置“限制区域”的招牌。 要优化 Disallow 指令,您必须了解第一道防线: “用户代理”。
什么是用户代理指令?
每个 Robots.txt 文件都包含一个或多个规则,其中,用户代理规则最为重要。 此规则为爬虫提供对网站上特定列表的访问权和非访问权。
因此,用户代理指令用于寻址特定的爬虫,并为它提供有关如何执行爬虫的指令。
常用的谷歌爬虫类型:

禁止指令:
现在,在了解了用于抓取您网站的机器人之后,您可以根据用户代理的类型优化它的不同部分。 您可以遵循一些基本技巧和示例来优化您网站的 disallow 指令:
- 使用可在浏览器中显示的完整页面名称以用于禁止指令。
- 如果要从目录路径重定向爬虫,请使用“/”标记。
- 使用 * 表示路径前缀、后缀或整个字符串。
使用 disallow 指令的示例如下:
# 示例 1:仅阻止 Googlebot
用户代理:Googlebot
不允许: /
# 示例 2:阻止 Googlebot 和 Adsbot
用户代理:Googlebot
用户代理:AdsBot-Google
不允许: /
# 示例 3:阻止除 AdsBot 爬虫之外的所有爬虫
用户代理: *
不允许: /
2. Robots.txt 的非索引指令:
当其他网站链接到您的网站时,您不希望爬虫索引的 URL 可能会被暴露。 要解决此问题,您可以使用非索引指令。 让我们看看,我们如何将非索引指令应用于 Robots.txt:
有两种方法可以为您的网站应用非索引指令:
<元> 标签:
元标记是以简短的透视方式描述页面内容的文本片段,让访问者知道接下来会发生什么? 我们可以使用相同的方法来避免爬虫索引页面。
首先,在页面的“<head>”部分放置一个元标记“<meta name=”robots” content=”noindex”>”,您不希望抓取工具对其进行索引。
对于 Google 爬虫,您可以在“<head>”部分使用“<meta name=”googlebot” content=”noindex”/>”。
由于不同的搜索引擎爬虫正在寻找您的页面,它们可能会以不同的方式解释您的非索引指令。 因此,您的页面可能会出现在搜索结果中。
因此,如果您根据爬虫或用户代理为页面定义指令,将会有所帮助。
您可以使用以下元标记将指令应用于不同的爬虫:
<元名称=”googlebot” 内容=”noindex”>
<元名称=”googlebot-news” 内容=”nosnippet”>
X-Robots 标签:
我们都知道 HTTP 标头用于响应客户端或搜索引擎对与您的网页相关的额外信息(例如位置或提供它的服务器)的请求。 现在,要针对非索引指令优化这些 HTTP 标头响应,您可以添加 X-Robots 标记作为您网站的任何给定 URL 的 HTTP 标头响应的元素。
您可以将不同的 X-Robots 标签与 HTTP 标头响应结合起来。 您可以在以逗号分隔的列表中指定各种指令。 下面是一个 HTTP 标头响应示例,其中包含不同指令和 X-Robots 标签。
HTTP/1.1 200 正常
日期:格林威治标准时间 2020 年 1 月 25 日星期二 21:42:43
(……)
X-Robots-标签:noarchive
X-Robots-标签:不可用_之后:2020 年 7 月 25 日 15:00:00 PST
(……)

3.掌握规范链接: 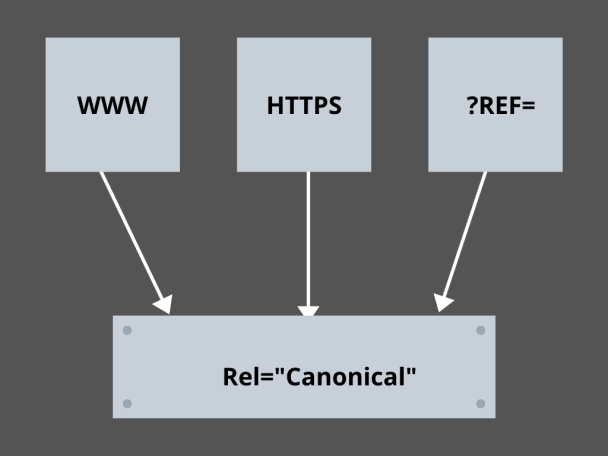
当今 SEO 中最可怕的因素是什么? 排名? 交通? 不! 担心搜索引擎会因重复内容而惩罚您的网站。 因此,在制定抓取预算策略时,您需要注意不要暴露重复的内容。
在这里,掌握您的规范链接将帮助您处理重复的内容问题。 重复内容这个词不是它的意思。 让我们以电子商务网站的两个页面为例:
例如,您有一个电子商务网站,其中包含一对相同的智能手表页面,并且两者都有相似的内容。 当搜索引擎机器人抓取您的 URL 时,它们会检查重复的内容,并且它们可能会选择任何 URL。 要将它们重定向到对您至关重要的 URL,可以为页面设置规范链接。 让我们看看你是怎么做到的:
- 从两页中选择任何一页作为您的规范版本。
- 选择接待更多访客的那个。
- 现在将 rel=”canonical” 添加到您的非规范页面。
- 将非规范页面链接重定向到规范页面。
- 它将您的两个页面链接合并为一个规范链接。
4. 构建网站:
爬虫需要标记和招牌来帮助他们发现您网站的重要 URL,如果您不构建您的网站,爬虫会发现很难对您的 URL 执行爬网。 为此,我们使用站点地图,因为它们为爬虫提供了指向您网站所有重要页面的链接。
通过移动应用程序开发流程开发的网站甚至应用程序的标准站点地图格式是 XML 站点地图、Atom 和 RSS。 要优化抓取,您需要结合 XML 站点地图和 RSS/Atom 提要。
- 由于 XML 站点地图为爬虫提供了指向您网站或应用程序上所有页面的路线。
- 并且 RSS/Atom 提要在您的网站页面中向爬虫提供更新。
- 由于 XML 站点地图为爬虫提供了指向您网站或应用程序上所有页面的路线。
5. 页面导航:
页面导航对于蜘蛛甚至您网站的访问者来说都是必不可少的。 这些靴子在您的网站上查找页面,预定义的层次结构可以帮助爬虫找到对您的网站重要的页面。 要获得更好的页面导航,要遵循的其他步骤是:
- 将编码保留在 HTML 或 CSS 中。
- 分层排列您的页面。
- 使用浅层网站结构以获得更好的页面导航。
- 使标题上的菜单和选项卡保持最小和具体。
- 它将帮助页面导航更容易。
6.避免蜘蛛陷阱:
蜘蛛陷阱是当抓取工具抓取您的网站时,指向相同页面上相同内容的无限 URL。 这更像是射击空白。 最终,它会吃掉你的爬虫预算。 此问题会随着每次爬网而升级,并且您的网站被认为具有重复的内容,因为在陷阱中爬网的每个 URL 都不是唯一的。
您可以通过 Robots.txt 阻止该部分来打破陷阱,或者使用跟随或不跟随指令之一来阻止特定页面。 最后,您可以通过阻止无限 URL 的出现来从技术上解决问题。
7.链接结构:
互连是爬网优化的重要组成部分之一。 爬虫可以通过整个网站结构良好的链接更好地找到您的页面。 一个伟大的链接结构的一些关键技巧是:
- 使用文本链接,因为搜索引擎很容易抓取它们: <a href=”new-page.html”>文本链接</a>
- 在链接中使用描述性锚文本
- 假设您经营一个健身房网站,并且想要链接您所有的健身房视频,您可以使用这样的链接 - 随意浏览我们所有的<a href=”videos.html”>健身房视频</a>。
8. HTML 幸福:
清理您的 HTML 文档并保持 HTML 文档的有效负载大小最小很重要,因为它允许爬虫快速爬取 URL。 HTML 优化的另一个优点是,由于搜索引擎的多次抓取,您的服务器会负载过重,这可能会减慢您的页面加载速度,这对于 SEO 或搜索引擎抓取来说不是一个好兆头。 HTML优化可以减少服务器的爬取负载,保持页面加载迅速。 它还有助于解决由于服务器超时或其他重要问题导致的抓取错误。
9.嵌入简单:
今天,任何网站都不会提供没有精美图像和视频来支持内容的内容,因为这使得它们的内容在视觉上更具吸引力,并且对于搜索引擎爬虫来说更容易获得。 但是,如果这个嵌入的内容没有被优化,它会降低加载速度,让爬虫远离你可以排名的内容。
在这里,坚持嵌入内容的 HTML 有助于更好地从搜索引擎中抓取。 AJAX、Javascript 等技术非常擅长提供新功能,但它们也使搜索引擎的抓取变得相当棘手。
结论:
随着对 SEO 和更高流量的更多关注,每个网站所有者都在寻找更好的方法来处理机器人群聚和蜘蛛争吵。 但是,解决方案在于您需要在您的网站和抓取 URL 中进行细粒度优化,这可以使搜索引擎抓取更加具体和优化,以代表您的网站中可以在搜索引擎结果页面中排名更高的最佳网站。