
谷歌抓取统计报告与日志文件分析:谁是赢家?
已发表: 2020-12-2211 月 24 日,Google 发布了新版本的 Search Console Crawl Stats 报告。 此更新为您提供可用于调试爬网问题和检查站点运行状况的数据。
以前的版本只表示每天爬取的页面数,每天下载的千字节,每天下载页面所花费的时间。
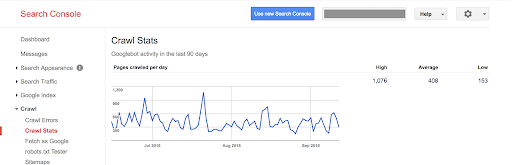
在这个新版本中,相同的信息具有更新的外观和风格,以匹配 Search Console 的其余部分:
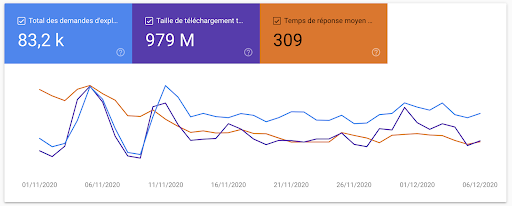
但它并不止于此。 谷歌提供了更多关于他们如何抓取你的网站的信息。 有了这么多直接从 Google 获得的信息,这就引出了一个问题:我们还需要日志文件吗?
让我们先看看新报告本身。
您需要了解的有关 Google Search Console 抓取统计报告的所有信息
在哪里可以找到新的抓取统计报告?
拥有 Google Search Console 帐户的任何人都可以自动使用新的抓取统计信息报告。
登录 Search Console 并导航到左侧边栏中的“设置”。 然后点击“抓取统计”。
新的抓取统计报告中有什么内容?
为了帮助您在广泛的新信息中找到自己的方式,我们推荐 Tomek Rudzki 在 Twitter 上的演练:
新的 GSC 抓取统计数据很棒!
第一张截图与之前版本的报告类似,但在其他报告中有隐藏的宝石
1/n pic.twitter.com/oCNzMhnGsQ- Tomek Rudzki (@TomekRudzki) 2020 年 11 月 24 日
Tomek 重点介绍了每个新数据和 SEO 用例:
- Googlebot 点击次数最多的主机:查找 Google 最常抓取的子域。
- 返回给 Googlebot 的状态代码:了解非 200(即:重定向、丢失页面和错误)响应使用了多少百分比的抓取预算。
- 文件类型:了解 Googlebot 请求 CSS 文件、JavaScript 文件和图像等资源文件的频率。
- Googlebot 访问的目的:了解 Google 是在发现新内容还是在更新它已经知道的内容。
- 智能手机 Googlebot 发出的请求与桌面 Googlebot 发出的请求之间的区别:确认您的网站是否已准备好在 2021 年 3 月全面转向移动优先索引。
- 抓取的 URL 示例:了解您网站上最近抓取的一些 URL。
- 主机状态:显示您的服务器最近是否出现问题的新指标。 例如,这会考虑 robots.txt 的可用性和 DNS 解析。
关于抓取统计报告,我们最喜欢的三件事
Crawl Stats Report 提供了太多好处,无法全部列出,尤其是在您无权访问日志文件的情况下。 但这是我们的前三名:
1. 本报告适用于所有人。
它提供易于阅读的高级 Googlebot 抓取统计信息。 什么时候做得好,什么时候有问题需要解决,这一点很清楚。 在某些情况下,它甚至更进一步:例如,它提供主机状态的绿色/黄色/红色状态指示器等提示。
即使您不熟悉 bot 和爬网预算跟踪,在查看这些报告时也不应该迷失方向。
2. 文档很棒。
该文档不仅回答了您 99% 的问题,而且还提供了有关服务器运行状况、危险信号、抓取频率管理和基本 googlebot 争论的最佳实践和提示。
3. Googlebot 请求背后的“原因”数据
我们可以跟踪 Googlebot,但关于 Google 为什么访问页面的许多结论必须基于有限的数据得出。 “按目的抓取”部分和“页面资源加载”下可见的呈现请求为我们的一些问题提供了明确的答案。 我们现在可以确定 Google 是在发现页面、更新页面还是在单独的第二遍下载资源以呈现页面。
[案例研究] 管理 Google 的机器人抓取
 阅读案例研究
阅读案例研究日志文件中可用的信息和抓取统计报告中的信息有什么区别?
抓取统计信息仅限于 Googlebots
抓取统计:0
日志:1
您的服务器的日志文件记录了对构成您网站的任何文件和资源的每个请求,无论它们来自谁。 这意味着日志可以告诉您的不仅仅是 Googlebot。
但是,Google 的抓取统计报告(自然!)仅限于 Google 自己在您网站上的活动。
以下是您可以从未显示在 Crawl Stats 中的日志文件中获得的一些见解:
- 有关其他搜索引擎的信息,例如 Bing。 您可以查看他们如何抓取您的网站,还可以查看他们的行为与 Googlebot 的行为有何不同或一致:
Logflare 非常有用。 在实时日志中看到 Googlebots 与 Bingbots 不同的抓取行为很有趣。 Googlebot 看到 301,然后返回的下一个 URL 是重定向到的 URL,但 Bingbot 似乎没有这样做。 只是看到301然后去别的地方
——黎明安德森 (@dawnieando) 2020 年 1 月 22 日
- 有关哪些工具(和竞争对手)正在尝试抓取您的网站的信息。 由于可用信息不仅限于 Googlebot,因此您还可以查看您网站上是否有其他机器人处于活动状态。
- 有关引用页面的信息。 这可以帮助您找到有关最活跃反向链接的更多信息。 在 HTTPS 中,访问的最后一个页面或“引用页面”也会记录在每个请求中。
- 有关自然流量的信息……而不仅仅是来自 Google 的流量! 使用引用页面,您可以识别来自搜索引擎结果页面的流量,并更好地了解这些访问者如何与您的网站互动。 如果您使用此类信息,可以使用此类信息来确认或更正您的 Analytics 解决方案提供的数字。
- 孤立页面的识别。 由于您的日志包含访问者请求的所有 URL,因此您的网站结构中未链接到的任何具有机器人或人工流量的“活动”页面都将显示在您的日志中。 通过将日志文件中的 URL 列表与爬网中的站点结构中的 URL 列表进行比较,很容易发现孤立页面。
完整且最新?
抓取统计:0
日志:2
您的数据是否完整且最新? 你的日志是。 你的抓取统计数据可能是。
许多人很快注意到 Google Search Console 报告和他们的日志文件之间存在 20-40% 的差异:Crawl Stats 报告目前低估了 Googlebot 的活动。 这是 Crawl Stats 中的一个已知问题,但不在您的日志中!

此外,与 Search Console 中的所有信息一样,数据的最后可用日期与今天的日期之间可能存在滞后。 到目前为止,我们已经在抓取统计报告中看到了长达八天的差异。
另一方面,您可以使用日志文件进行实时监控:绝不会有延迟!
已抓取 URL 的汇总与完整列表
抓取统计:0
日志:3
Crawl Stats 为您的所有 URL 提供汇总数据。 该报告相当于一个仪表板。 当您查找给定指标背后的 URL 列表时,您会看到“示例”列表。 例如,您可能有数百个 4.56K 图像文件请求示例:
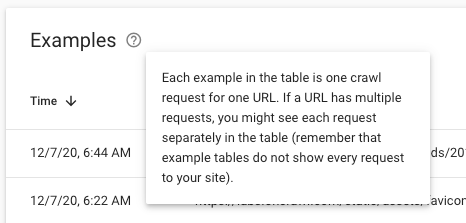
但是,在日志文件中,您拥有任何指标背后的 URL 的完整列表。 您可以在日志中看到所有请求,而不仅仅是示例。
过滤地区、日期、URL……
抓取统计:0
日志:4
为了真正有用,Crawl Stats 可以受益于适用于所有请求的更广泛的过滤器,而不仅仅是样本: 
拥有更大的灵活性会很棒:
- 更改我们正在查看的日期范围
- 通过 IP 查找关注给定的地理区域
- 更好地按 URL 组过滤
- 将过滤器选项应用于图表
您可以在日志文件中完成所有这些——甚至更多。
Googlebot 特定信息
抓取统计:1
日志:4
正如我们所见,Google 使用抓取统计报告来提供有关其抓取目的的信息:
- 刷新与发现
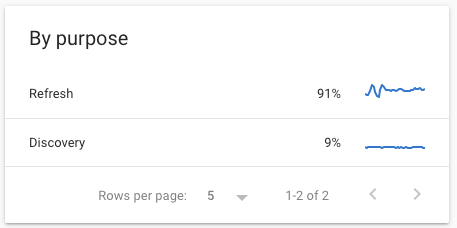
- 页面资源(二次提取)

无论您如何巧妙地查看日志文件中的数据,这些信息都无法在其他任何地方找到。
容易接近
爬行统计:2
日志:4
访问 Crawl Stats 报告很简单:任何有权访问 Search Console 的人都可以自动使用 Crawl Stats。
从技术上讲,日志文件也应该可供任何网站管理员使用。 但通常情况并非如此。 开发团队、IT 团队或客户公司通常不了解提供对日志文件的访问权限的重要性。 在欧盟等地区,隐私法限制访问“个人身份数据”(如 IP 地址),访问日志文件可能会带来法律问题。 您可以使用不存储敏感信息的某些工具,例如 OnCrawl。
一旦您可以访问日志文件,就有分析数据的免费工具,而且专有格式很少。 换句话说,日志文件是一个非常民主的数据来源……一旦你掌握了它们。
这是事实:许多 SEO 无法访问日志。 因此,虽然从理论上讲,日志文件可以轻松访问数据,但这一点的重点在于抓取统计报告,点击两次即可从 Google 的免费工具中获得该报告。
Oncrawl 日志分析器
 学到更多
学到更多(尚未)可用于集成到其他工具和分析中
爬行统计:2
日志:5
Google Search Console 允许您通过 Crawl Stats Report 的 Web 界面导出和下载可用信息。 但是,这意味着下载的信息与屏幕上的版本具有相同的限制。
此外,Crawl Stats (还没有?)可通过 API 获得,因此很难将这些信息连接到自动化流程以进行报告和分析,甚至很难将其备份以获取更广泛的历史数据视图。
对于日志文件,存储、访问和重用通常取决于您。 这使得日志文件在与排名跟踪、爬网数据或分析数据等其他数据源合并时更易于使用。 它们也更容易集成到报告、仪表板和数据可视化流程中。
最终获胜者:日志文件!
Crawl Stats 报告只有 5 分到 2 分,如果您想全面了解搜索引擎如何与您的网站交互,日志文件显然是赢家。
但让我们明确一点:升级后的 Crawl Stats 报告提供了许多新信息:状态代码、文件类型、子域(用于域属性)、主机状态详细信息等等。 它为您提供更精细的见解和可操作的数据,以了解您的网站是如何被抓取的,现在,您可以跟踪抓取模式的变化。
对于无法访问他们或他们客户的日志文件的人来说,这将是一个巨大的进步。
然而,这并不是所有的优点!
新 GSC 抓取统计数据的优缺点:https://t.co/bjpG7QjeVt
优点:
+升级的数据指标
+更好的用户体验(低酒吧 TBH)
+抓取的网址的可下载数据!
+抓取请求故障
+注意到重要的主机问题缺点:
- 没有日期范围的过滤器
- 没有过滤器选项来改变图表— Micah Fisher-Kirshner (@micahfk) 2020 年 11 月 24 日
新报告的缺点是,虽然它是 Googlebot 监控的一个很好的仪表板,并且是补充日志文件分析的一个很好的补充,但它在很多方面都受到限制。 不要忘记,只有您的日志文件会向您显示每个 URL 的所有请求,而不是汇总趋势。
此外,GSC 报告中存在一个已知问题,其中一些请求目前未计算在内,并且在撰写本文时,数据可能需要长达一周的时间才能出现在 Crawl Stats 报告中。 (但是,我们相信 Google 正在解决这些问题,它们很快就会消失!)
以下是我们的建议:使用此报告可以准确了解要在日志文件中查找的内容。 然后深入您的日志分析!