
Google 核心更新:YMYL 网站的影响、问题和解决方案
已发表: 2019-12-04在本案例研究中,我将研究 Hangikredi.com,它是土耳其最大的金融和数字资产之一。 我们将看到技术 SEO 副标题和一些图形。
该案例研究在两篇文章中介绍。 本文介绍了 3 月 12 日的 Google 核心更新,该更新对网站产生了强烈的负面影响,以及我们采取了哪些措施来抵消它。 我们将研究 13 个技术问题和解决方案,以及整体问题。
阅读第二部分,了解我如何应用从这次更新中学到的知识,成为每次 Google 核心更新的赢家。
问题和解决方案:修复 3 月 12 日 Google 核心更新的影响
在 3 月 12 日核心算法更新之前,根据分析数据,网站的一切都很顺利。 一天之内,核心算法更新的消息传出后,排名大跌,办公室里一片沮丧。 我个人没有看到那一天,因为我是在 14 天后他们雇用我开始新的 SEO 项目和流程时才到的。
[案例研究] 通过日志文件分析提高排名、自然访问量和销售额
 阅读案例研究
阅读案例研究3 月 12 日核心算法更新后公司网站的损坏报告如下:
- 36% 有机会话损失
- 65% 点击率下降
- 30% 点击率损失
- 33% 自然用户流失
- 每天损失 100 000 次展示。
- 9.72% 印象损失
- 8 000 个关键词丢失

现在,正如我们在案例研究文章开头所说的那样,我们应该问一个问题。 我们不能问“下一次核心算法更新什么时候发生?” 因为它已经发生了。 只剩下一个问题。
“谷歌在我和我的竞争对手之间考虑了哪些不同的标准?”
从上图和损坏报告中可以看出,我们失去了主要流量和关键字。
1.问题:内部链接
我注意到,当我第一次检查内部链接数、锚文本和链接流时,我的竞争对手领先于我。
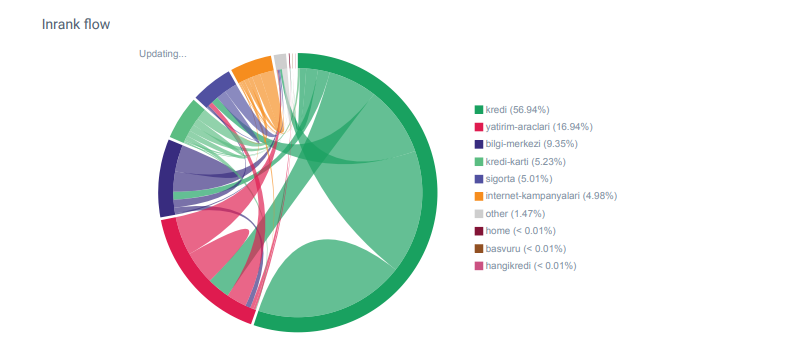
来自 OnCrawl 的 Hangikredi.com 类别的 Linkflow 报告
我的主要竞争对手拥有超过 340 000 个内部链接和数千个锚文本。 在这些日子里,我们的网站只有 70 000 个没有有价值的锚文本的内部链接。 此外,缺乏内部链接影响了网站的抓取预算和生产力。 尽管我们 80% 的流量仅在 20 个产品页面上收集,但我们网站的 90% 包含为用户提供有用信息的指南页面。 我们的财务查询的大部分关键字和相关性得分都来自这些页面。 而且,孤页数不胜数。
由于缺少内部链接结构,当我使用 Kibana 进行日志分析时,我注意到爬取次数最多的页面是流量最少的页面。 此外,当我将其与内部链接网络配对时,我发现流量最低的公司页面(隐私、Cookie、安全、关于我们页面)具有最大数量的内部链接。
正如我将在下一节中讨论的那样,这导致 Googlebot 在爬取网站时从 Pagerank 中删除了内部链接因素,并意识到内部链接没有按预期构建。
2. 问题:网站架构、国际网页排名、流量和爬网效率
根据 Google 的声明,内部链接和锚文本有助于 Googlebot 了解网页的重要性和上下文。 内部 Pagerank 或 Inrank 的计算基于多个因素。 根据 Bill Slawski 的说法,内部或外部链接并不完全相同。 Pagerank 流的链接值根据其位置、种类、样式和字体粗细而变化。

如果 Googlebot 了解哪些页面对您的网站很重要,它会更多地抓取它们并更快地将它们编入索引。 内部链接和正确的站点树设计是其中的重要因素。 多年来,其他专家也对这种相关性发表了评论:
“大多数链接确实通过它们的锚文本提供了一些额外的上下文。 至少他们应该,对吧?”
——约翰·穆勒,谷歌 2017“如果您认为您的网站上有重要的页面,请不要将它们隐藏在您的网站深处 15 个链接,我不是在谈论目录长度,我说的是实际您必须点击 15 个链接才能找到该页面如果有一个页面很重要,或者有很大的利润空间或者转化率真的——嗯——升级,从你的根页面放置一个指向该页面的链接,这是很有意义的事情。”
——马特·卡茨,谷歌 2011“如果一个页面使用“联系人”或“关于”一词链接到另一个页面,并且链接到的页面包含地址,则该地址位置可能被认为与进行该链接的页面相关。
12 种可能已经改变的 Google 链接分析方法——Bill Slawski
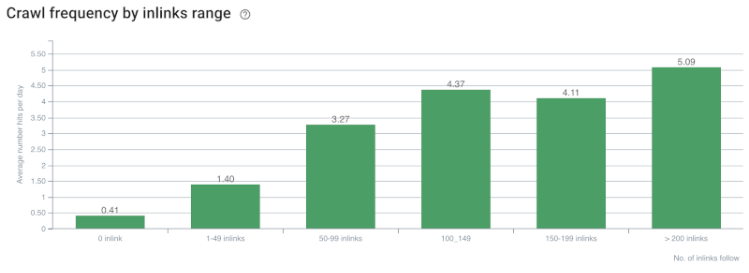
爬网率/需求和内部链接计数相关性。 资料来源:OnCrawl。
到目前为止,我们可以做出以下推论:
- 谷歌关心点击深度。 如果一个网页离主页更近,它应该更重要。 John Mueller 在 2018 年 7 月 1 日英语谷歌网站管理员环聊中也证实了这一点。
- 如果一个网页有很多指向它的内部链接,那么它应该很重要。
- 锚文本可以赋予网页上下文的力量。
- 内部链接可以根据其位置、类型、字体粗细或样式传输不同的 Pagerank 数量。
- 向搜索引擎爬虫提供有关内部页面权限的明确消息的 UX 友好型站点树是 Inrank 分发和爬网效率的更好选择。
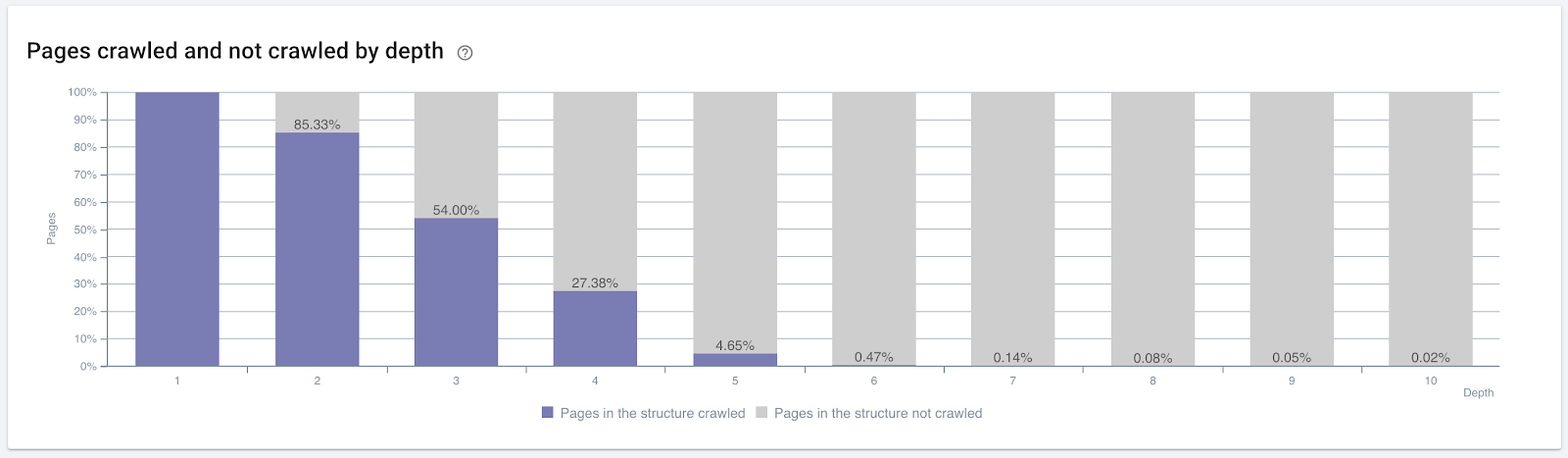
按点击深度抓取的页面百分比。 资料来源:OnCrawl。
但这些还不足以了解内部链接的性质和对爬网效率的影响。
Oncrawl 搜索引擎优化爬虫
 学到更多
学到更多如果您最内部链接的页面没有产生流量或被点击,它会发出信号,表明您的站点树和内部链接结构不是根据用户意图构建的。 谷歌总是试图找到与用户意图或搜索实体最相关的页面。 我们从 Bill Slawski 那里得到另一个引文,使这个主题更加清晰:
“如果一个资源与通过使用这些链接接收的流量不成比例的多个资源链接,则该资源可能会在排名过程中被降级。”
土拨鼠更新刚刚发生在谷歌吗? — 比尔·斯拉夫斯基“导致停留时间长(例如,大于阈值时间段)的选择的选择质量分数可能高于导致短停留时间的选择的选择质量分数。”
土拨鼠更新刚刚发生在谷歌吗? — 比尔·斯拉夫斯基
所以我们还有两个因素:
- 链接页面中的停留时间。
- 链接产生的用户流量。
内部链接数量和样式/位置不是唯一的因素。 关注这些链接的用户数量及其行为指标也很重要。 此外,我们知道被点击/访问的链接和页面被 Google 抓取的次数远远多于未被点击或访问的链接和页面。
“我们越来越倾向于了解网站的各个部分,以了解这些部分的质量。”
John Mueller,2017 年 5 月 2 日,英文版 Google Webmasters Hangout。
鉴于所有这些因素,我将分享两个不同且不同的 Pagerank Simulator 结果:
这些 Pagerank 计算是在假设所有页面都相等的情况下进行的,包括主页。 真正的区别是由链接层次结构决定的。
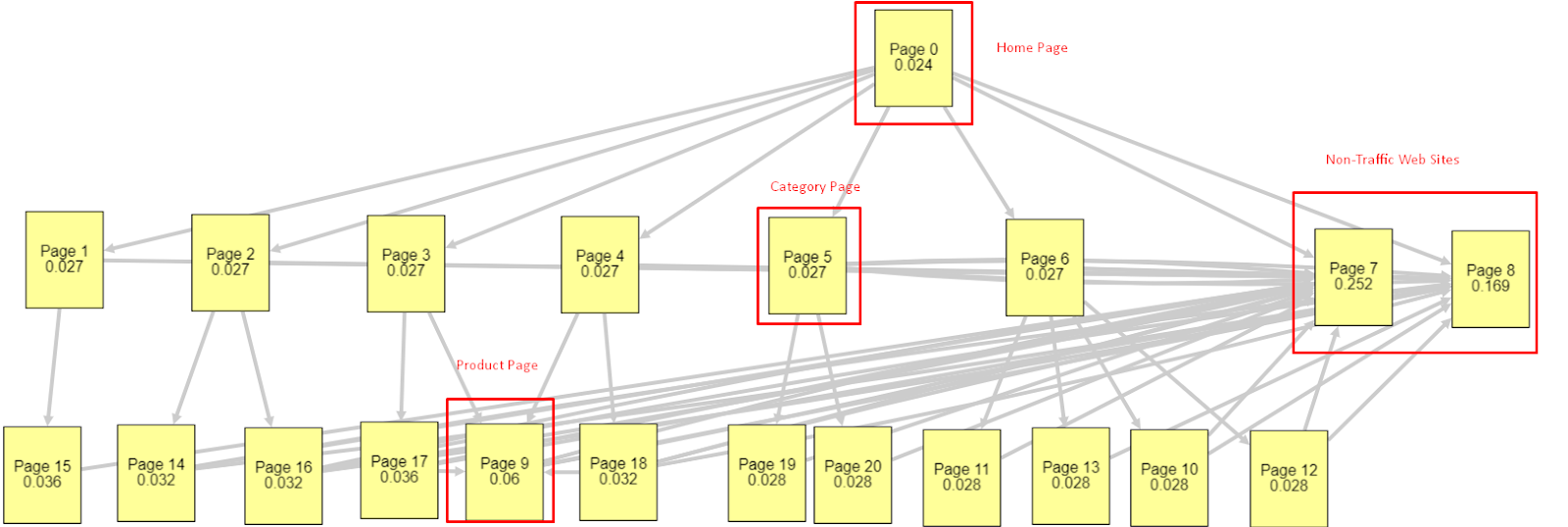
此处显示的示例更接近 3 月 12 日之前的内部链接结构。 主页 PR:0.024,类别页面 PR:0.027,产品页面 PR:0.06,非流量网页 PR:0.252。
您可能会注意到,Googlebot 无法信任这种内部链接结构来计算内部页面排名和内部页面的重要性。 非流量和无产品页面的权限是主页的 12 倍。 它不仅有产品页面。

这个例子更接近我们在 6 月 5 日核心算法更新之前的情况。主页 PR:0.033,类别页面:0,037,产品页面:0,148 和非流量页面的 PR:0,037。
您可能会注意到,内部链接结构仍然不正确,但至少非流量网页没有比类别页面和产品页面更多的 PR。
有什么进一步的证据表明谷歌根据用户流量和请求和意图将内部链接和站点结构排除在 Pagerank 范围之外? 当然 Googlebot 的行为与 Inlink Pagerank 和 Ranking 相关性:
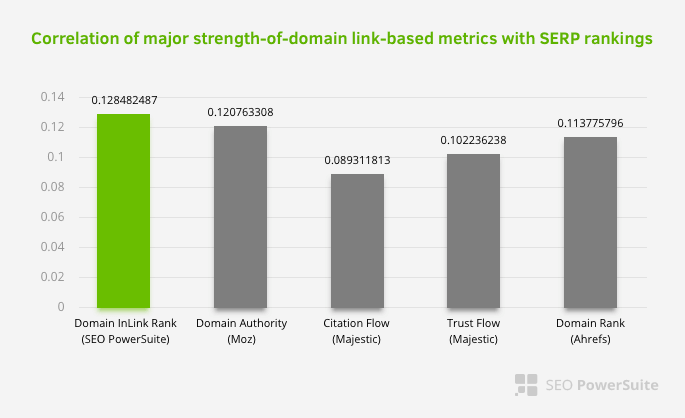
这并不意味着内部链接网络尤其比其他因素更重要。 专注于单点的 SEO 视角永远不会成功。 在第三方工具之间的比较中,它表明内部 Pagerank 值相对于其他标准正在进步。
根据 Aleh Barysevich 的 Inlink Rank 和排名相关性研究,内部链接最多的页面的排名高于网站的其他页面。 根据 2019 年 3 月 4 日至 6 日进行的调查,根据 33,500 个关键字的内部 Pagerank 指标分析了 1,000,000 个页面。 SEO PowerSuite 进行的这项研究的结果与 Moz、Majestic 和 Ahrefs 的不同指标进行了比较,并给出了更准确的结果。
以下是 3 月 12 日核心算法更新之前我们网站的一些内部链接号:
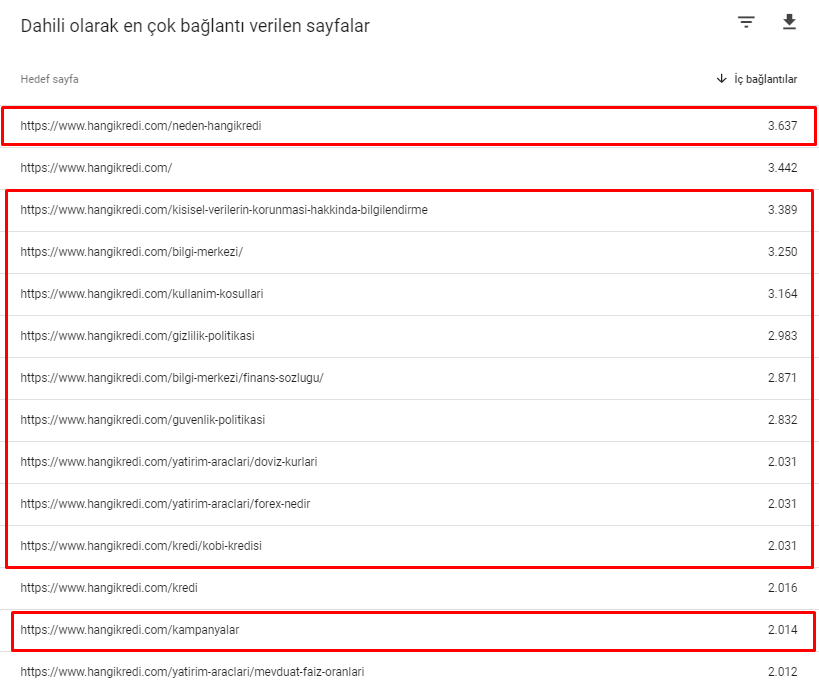
如您所见,我们的内部连接方案并没有反映用户意图和流量。 获得最少访问量的页面(次要产品页面)或从未获得访问量的页面(红色)直接在 1st Click Depth 并从首页获得 PR。 有些甚至比主页有更多的内部链接。
鉴于这一切,我们只能在这个主题上展示最后两点。
- 对内部链接最多的页面的抓取率/需求
- 链接雕刻和Pagerank
在 2 月 1 日至 3 月 31 日期间,以下是 Googlebot 最常抓取的网页:
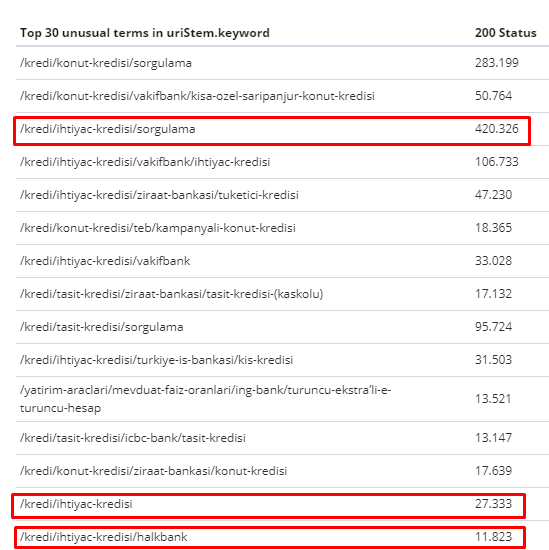
您可能会注意到,抓取的页面和具有最多内部链接的页面彼此完全不同。 内部链接最多的页面不便于用户使用; 他们没有有机关键字或任何类型的直接 SEO 价值。 (
红色框中的 URL 是我们访问量最大和最重要的产品页面类别。 此列表中的其他页面是访问量第二或第三的重要类别。)
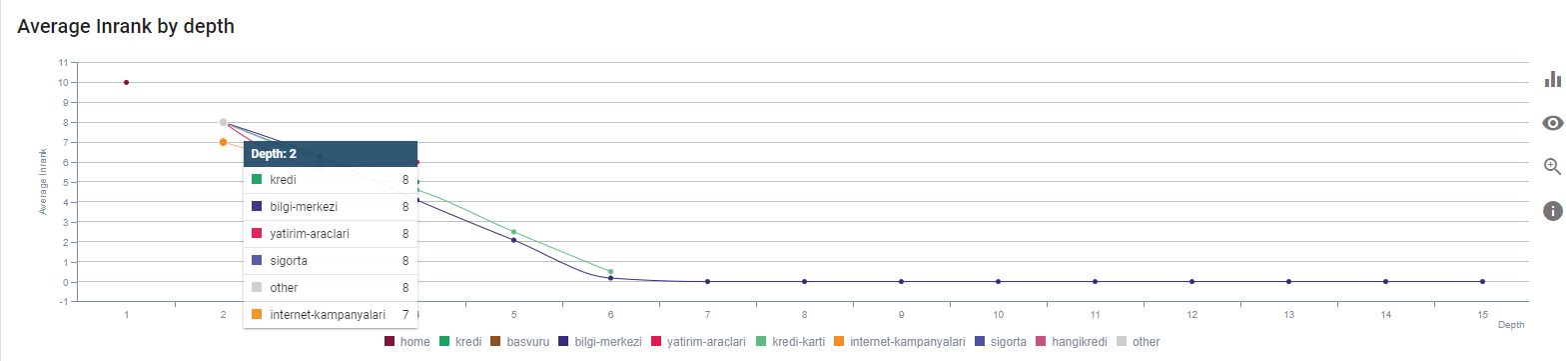
我们当前按页面深度排列的 Inrank。 资料来源:Oncrawl。
什么是链接雕刻以及如何处理内部未遵循的链接?
与大多数 SEO 认为的相反,标有“nofollow”标签的链接仍然传递内部 Pagerank 值。 对我来说,这么多年过去了,没有人比 Matt Cutts 在他 2009 年 6 月 15 日的 Pagerank Sculpting 文章中更好地叙述了这个 SEO 元素。
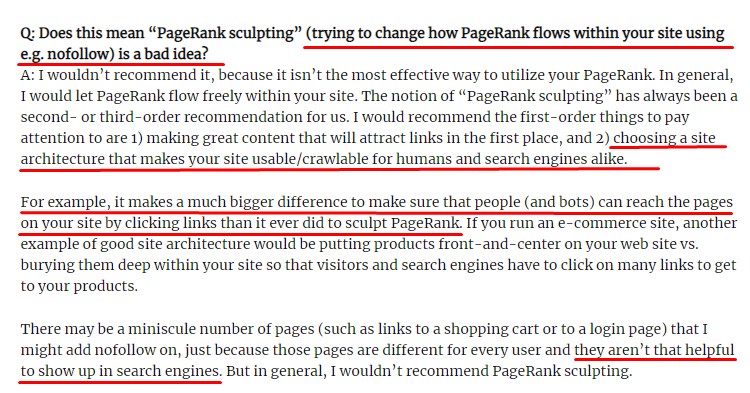
Link Sculpting 的一个有用部分,它显示了 Pagerank Sculpting 的真正用途。
“我建议不要在网站内使用 nofollow 来进行 PageRank 雕刻,因为它可能不会像您认为的那样做。”
——约翰·穆勒,谷歌 2017
如果您的网页在 Google 和用户方面毫无价值,则不应将它们标记为“nofollow”。 它不会停止 Pagerank 流程。 您应该从 robots.txt 文件中禁止它们。 这样,Googlebot 不会抓取它们,也不会将内部 Pagerank 传递给它们。 但正如十年前马特卡茨所说,你应该只将它用于真正毫无价值的页面。 为联属网络营销进行自动重定向的页面或几乎没有内容的页面是这里的一些方便示例。
解决方案:更好更自然的内部链接结构
我们的竞争对手有一个劣势。 他们的网站有更多的锚文本,更多的内部链接,但它们的结构并不自然和有用。 在他们网站的每个页面上,相同的锚文本与相同的句子一起使用。 每个页面的条目段落都覆盖了这种重复的内容。 每个用户和搜索引擎都可以很容易地认识到,这不是一个考虑用户利益的自然结构。
所以我决定做三件事来修复内部链接结构:
- 站点信息架构或站点树应该遵循与放置在内容中的链接不同的路径。 它应该更紧密地跟随用户的思想和关键字神经网络。
- 在每条内容中,侧关键字应与目标页面的主要关键字一起使用。
- 锚文本应该自然,适应内容,并且应该在每个页面的不同点使用,同时注意用户的感知
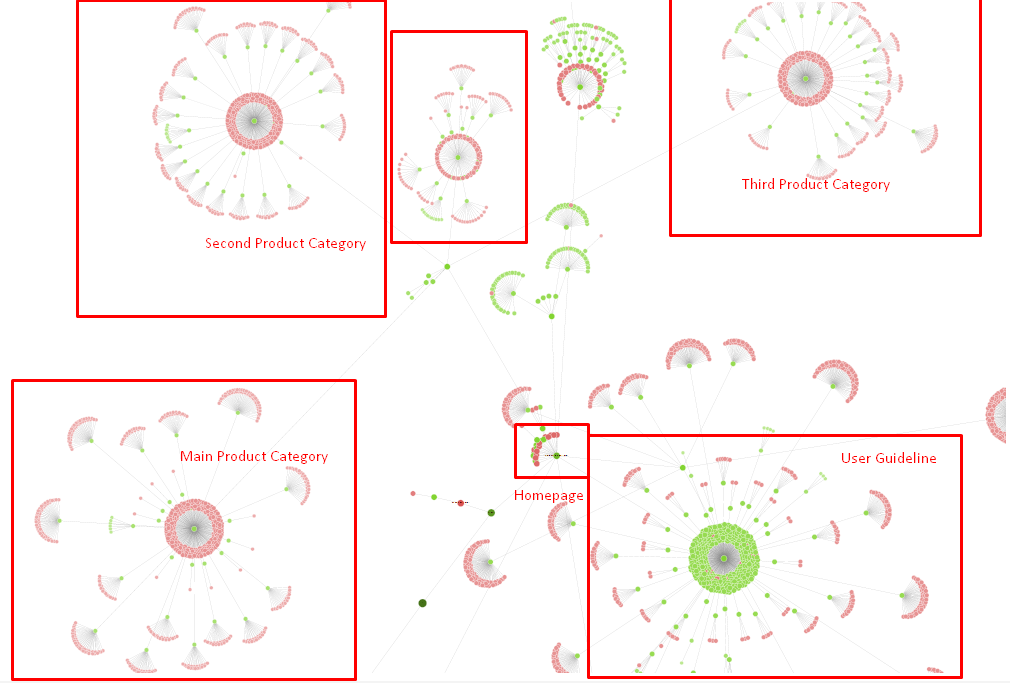
我们现在的站点树和链接结构的一部分。
在上图中,您可以看到我们当前的内部链接链接和站点树。
我们为解决此问题所做的一些事情如下:
- 我们用有用的锚创建了 30 000 多个内部链接。
- 我们为用户使用了自然景点和关键词。
- 我们没有使用重复的句子和模式进行内部链接。
- 我们向 Googlebot 提供了有关网页 Inrank 的正确信号。
- 我们通过日志分析检查了正确的内部链接结构对爬取效率的影响,我们发现与之前的统计数据相比,我们的主要产品页面被爬取的次数更多。
- 为孤立页面创建了超过 50 000 个内部链接。
- 使用主页内部链接为子页面提供动力,并在主页上创建更多内部链接源。
- 为了保护 Pagerank Power,我们还对一些不必要的外部链接使用了 nofollow 标签。 (这不是关于内部链接,但它服务于相同的目标。)
3.问题:内容结构
谷歌表示,对于 YMYL 网站,可信度和权威性比其他类型的网站更重要。

在过去,关键字只是关键字。 但现在,它们也是定义明确的、单一的、有意义的和可区分的实体。 在我们的内容中,有四个主要问题:
- 我们的内容很短。 (通常,内容的长度并不重要。但在这种情况下,它们没有包含足够的主题信息。)
- 我们作家的名字作为一个实体不是单一的、有意义的或可区分的。
- 我们的内容对眼睛不友好。 换句话说,它不是“快餐”内容。 这是没有副标题的内容。
- 我们使用营销语言。 在一个段落的空间中,我们可以为用户识别品牌名称及其广告。
- 有很多按钮可以将用户从信息页面引导到产品页面。
- 在我们产品页面的内容中,没有足够的信息或全面的指南。
- 设计不是用户友好的。 我们对字体和背景使用基本相同的颜色。 (由于基础设施问题,大多数情况仍然如此。)
- 图片和视频并未被视为内容的一部分。
- 特定关键字的用户意图和搜索意图以前并不被视为重要。
- 同一主题有很多重复、不必要和重复的内容。
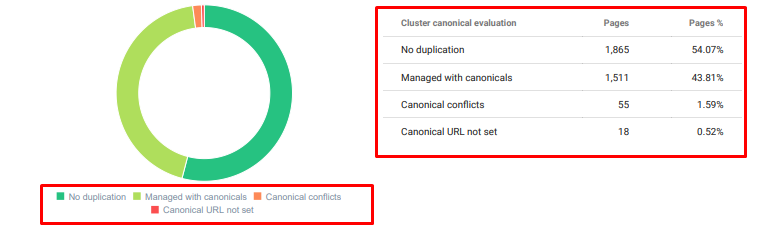
Oncrawl 从今天开始重复内容审核。
解决方案:更好的用户信任内容结构
在检查站点范围的问题时,使用站点范围的审计程序作为助手是组织花在 SEO 项目上的时间的更好方法。 与内部链接部分一样,我使用了 Oncrawl Site Audit 以及其他工具和 Xpath 检查。
首先,解决内容部分中的每个问题会花费太多时间。 在那些崩溃的危机日子里,时间是一种奢侈。 所以我决定解决速成问题,例如:
- 删除重复、不必要和重复的内容
- 统一缺乏全面信息的简短内容
- 重新发布缺少副标题和眼球追踪结构的内容
- 在内容中固定密集的营销基调
- 从内容中删除大量号召性用语按钮
- 通过图像和视频更好地进行视觉传达
- 使内容和目标关键字与用户和搜索意图兼容
- 在内容中使用和展示金融和教育实体以获得信任
- 使用社交社区创建社会认可证明
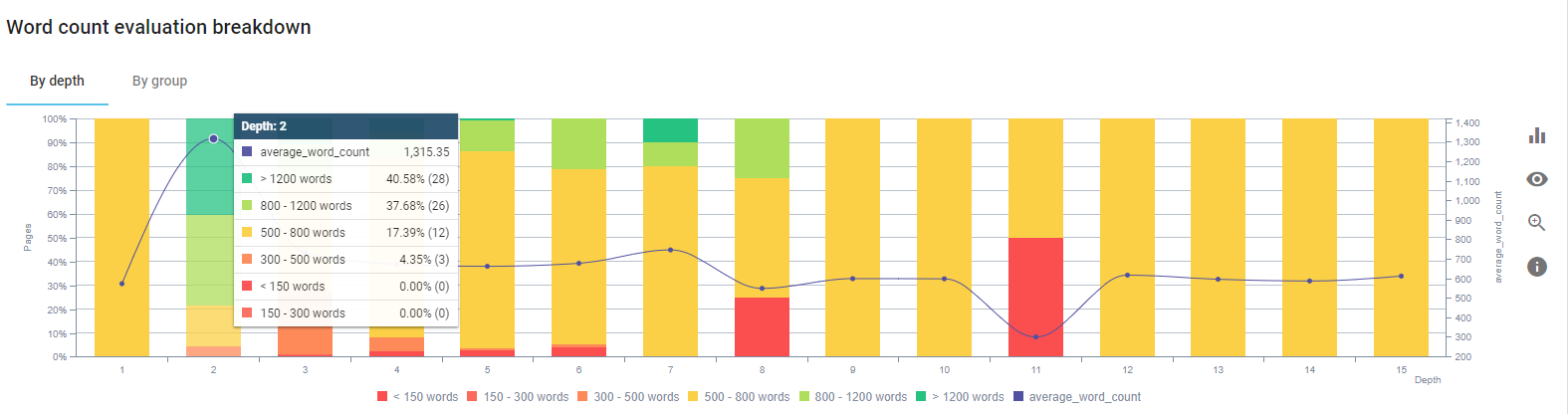

我们专注于修复产品页面和最接近它们的指南页面的内容。
在此过程开始时,我们的大多数产品和交易登陆/指南页面都少于 500 字,没有全面的信息。
在 25 天内,我们开展的行动如下:
- 删除了包含重复、不必要和重复内容的 228 页。 (在删除过程之前检查了 Ccontent 的反向链接配置文件。我们使用 301 或 410 状态代码来更好地与 Googlebot 通信。)
- 合并超过 123 页,缺乏全面的信息。
- 根据内容的重要性和用户需求使用副标题。
- 删除了带有营销风格语言的品牌名称和 CTA 按钮。
- 在图像中包含文本以强化主题。
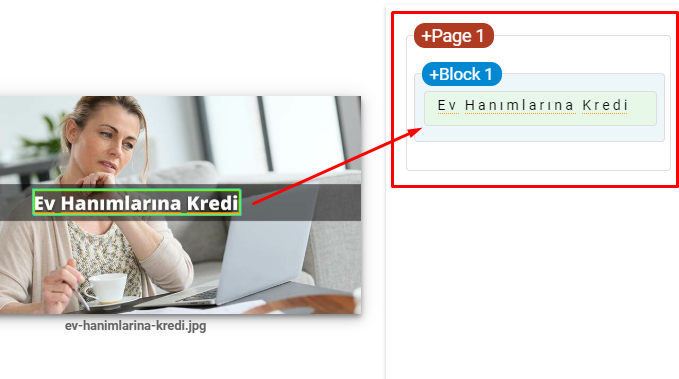
这是谷歌 Vision AI 的截图。 Google 可以读取图像中的文本并检测实体中的感受和身份。
- 激活我们的社交网络以吸引更多用户。
- 检查竞争对手与我们之间的内容差距,并创建了 80 多个新内容。
- 使用 Google Analytics、Search Console 和 Google Data Studio 来确定跳出率高、流量低的表现不佳的页面。
- 对精选片段及其关键字和内容结构进行了研究。 我们在相关内容中添加了相同的标题和内容结构,这增加了我们的精选片段。
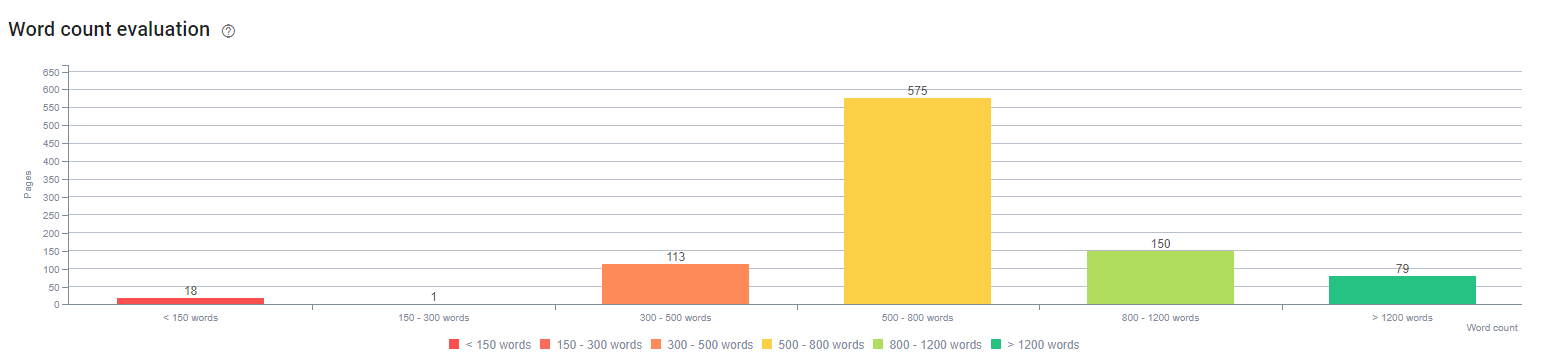
在这个过程开始时,我们的内容主要由 150 到 300 个单词组成。 我们网站范围内的平均内容长度增加了 350 个字。
4. 问题:索引污染、膨胀和规范标签
谷歌从未就索引污染发表过声明,事实上我不确定是否有人曾将其用作 SEO 术语。 应该从 Google 索引页面中删除所有对 Google 没有意义以获得更有效的索引分数的页面。 导致索引污染的页面是几个月没有产生流量的页面。 他们的点击率为零,自然关键字为零。 在他们有一些自然关键字的情况下,他们将不得不成为您网站上其他页面的相同关键字的竞争对手。
此外,我们对索引膨胀进行了研究,发现更多不必要的索引页面。 由于错误的站点信息结构或错误的 URL 结构而存在这些页面。
这个问题的另一个原因是错误地使用了规范标签。 两年多来,规范标签一直被视为对 Googlebot 的提示。 如果使用不当,Googlebot 在评估网站时不会计算或关注它们。 而且,对于这个计算,您可能会低效地消耗您的爬网预算。 由于不正确的规范标签使用,我们有超过 300 个带有重复内容的评论页面被编入索引。
我的理论旨在向 Google 展示只有质量和必要的页面,这些页面具有获得点击和为用户创造价值的潜力。
解决方案:修复索引污染和膨胀
首先,我听取了 Google 的 John Mueller 的建议。 我问他我是否对这些页面使用了 noindex 标签,但仍然让 Googlebot 跟踪它们,“我会失去链接权益和抓取效率吗?”
你可以猜到,他一开始说是的,但后来他建议使用内部链接可以克服这个障碍。
我还发现,在 dofollow 的同时使用 noindex 标签会降低 Googlebot 在这些页面上的抓取率。 这些策略让我可以让 Googlebot 更频繁地抓取我的产品和重要指南页面。 我还按照 John Mueller 的建议修改了我的内部链接结构。
短时间内:
- 发现了不必要的索引页面。
- 从索引中删除了 300 多页。
- 实施了 Noindex 标签。
- 对于从索引中删除的页面接收链接的页面,已修改内部链接结构。
- 随着时间的推移,对爬网效率和质量进行了检查。
5. 问题:错误的状态码
一开始,我注意到 Googlebot 会访问很多过去已删除的内容。 甚至八年前的页面仍在被抓取。 这是由于使用了不正确的状态代码,尤其是对于已删除的内容。
404 和 410 功能之间存在巨大差异。 其中一个用于不存在内容的错误页面,另一个用于已删除的内容。 此外,有效页面还引用了大量已删除的源和内容 URL。 一些已删除的图像和 CSS 或 JS 资产也被用作有效发布页面上的资源。 最后,还有很多软 404 页面和多个重定向链,以及用于永久重定向页面的 302-307 临时重定向。
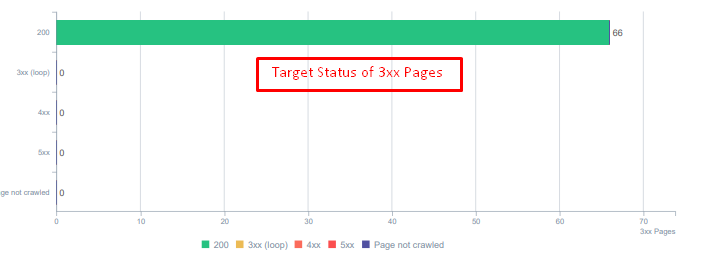
今天重定向资产的状态代码。
解决方案:修复错误的状态码
- 每个 404 状态码都转换为 410 状态码。 (超过30000)
- 每个具有 404 状态代码的资源都被替换为新的有效资源。 (超过 500 个)
- 每个 302-307 重定向都转换为 301 永久重定向。 (超过 1500 个)
- 重定向链已从正在使用的资产中删除。
- 每个月,我们在 Log Analysis 中收到超过 25,000 次页面和资源点击,状态码为 404。 现在,每月 404 个状态码少于 50 个,410 个状态码的命中率为零……
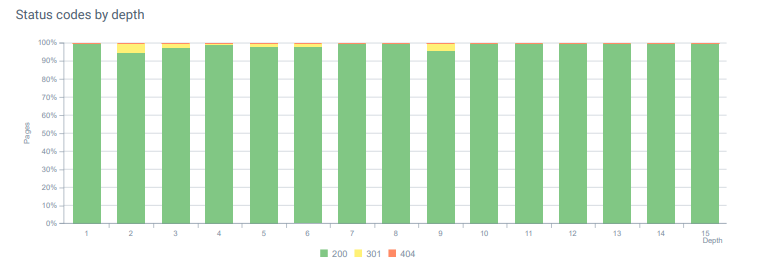
今天整个页面深度的状态代码。
6.问题:语义HTML
语义是指事物的含义。 语义 HTML 包括为层次结构中的页面组件赋予含义的标签。 通过这种分层代码结构,您可以告诉 Google 部分内容的用途是什么。 此外,在 Googlebot 无法抓取完整呈现您的页面所需的所有资源的情况下,您至少可以将网页的布局和内容部分的功能指定给 Googlebot。
在 Hangikredi.com 上,在 3 月 12 日 Google 核心算法更新之后,我知道由于网站结构未优化,抓取预算不足。 因此,为了让 Googlebot 更容易理解网页的目的、功能、内容和有用性,我决定使用 Semantic HTML。
解决方案:语义 HTML 用法
根据谷歌的质量评估指南,每个搜索者都有一个意图,每个网页都有一个根据这个意图的功能。 为了向 Googlebot 证明这些功能,我们对一些被 Googlebot 抓取较少的页面的 HTML 结构进行了一些改进。
- 使用 <main> 标签来显示页面的主要内容和功能。
- <nav> 用于导航部分。
- 使用 <footer> 作为网站的页脚。
- 使用 <article> 表示文章。
- 每个标题标签都使用 <section> 标签。
- 使用 <picture>、<table>、<citation> 标签用于内容中的图像、表格和引号。
- 用于补充内容的 <aside> 标记。
- 修复了 H1-H6 层次结构问题(尽管谷歌最新的“使用两个 H1 不是问题”声明,使用正确的结构,有助于 Googlebot。)
- 就像在内容结构部分一样,我们也为精选片段使用语义 HTML,我们使用表格和列表来获得更多精选片段结果。

对我们来说,这对于整个网站来说并不是一个切实可行的开发。 尽管如此,随着每次设计更新,我们将继续为其他网页实施语义 HTML 标签。
7. 问题:结构化数据的使用
与语义 HTML 的使用一样,结构化数据可用于向 Googlebot 显示网页部件的功能和定义。 此外,结构化数据对于丰富的结果是必不可少的。 在我们的网站上,直到 3 月底,结构化数据都没有被使用,或者更常见的是被错误地使用。 为了与我们网站上的实体和离页帐户建立更好的关系,我们开始实施结构化数据。
解决方案:正确且经过测试的结构化数据使用
对于金融机构和 YMYL 网站,结构化数据可以解决很多问题。 例如,它们可以显示品牌的身份、内容的种类并创建更好的片段视图。 我们为网站范围和单个页面使用了以下结构化数据类型:
- 主要产品页面的常见问题解答结构化数据
- 网页结构化数据
- 组织结构化数据
- 面包屑结构化数据
8.站点地图和Robots.txt优化
在 Hangikredi.com 上,没有动态站点地图。 当时现有的站点地图不包括所有必要的页面,还包括已删除的内容。 此外,在 Robots.txt 文件中,一些包含数千个外部链接的附属引荐页面未被禁止。 这还包括一些与内容无关的第三方 JS 文件以及 Googlebot 不需要的其他附加资源。
应用了以下步骤:
- 为根据站点类别创建的多个站点地图创建了一个 sitemap_index.xml,以便更好地抓取信号和更好的覆盖检查。
- robots.txt 文件中不允许使用一些第三方 JS 文件和一些不必要的 JS 文件。
- 正如我们在 Pagerank 或 Internal Link Sculpting 部分中提到的那样,不允许使用具有外部链接且没有登录页面值的附属页面。
- 修复了 500 多个覆盖问题。 (其中大部分是尽管被 Robots.txt 禁止但仍被编入索引的页面。)
您可以从下表中看到我们的抓取速度、负载和需求增加:
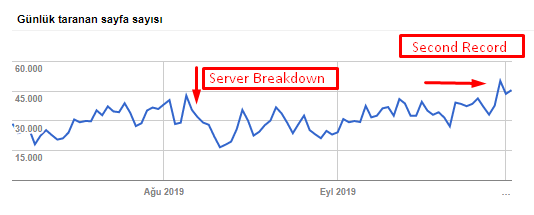
Googlebot 每天抓取的页面数。 直到 8 月 1 日,每天抓取的页面数量稳步增加。 在 8 月初的一次攻击导致服务器故障后,它在一个多月的时间里恢复了稳定。

Googlebot 每天抓取的负载与每天抓取的页面数量同步发展。
9. 修复 AMP 问题
在公司的网站上,每个博客页面都有一个 AMP 版本。 由于不正确的代码实现和缺少 AMP 规范,所有 AMP 页面都被反复从索引中删除。 这造成了一个不稳定的指数得分和网站缺乏信任。 此外,AMP 页面在土耳其语内容中默认包含英语术语和单词。
- 为 400 多个 AMP 页面修复了规范标签。
- 发现并修复了不正确的代码实现。 (这主要是由于 AMP-Analytics 和 AMP-Canonical 标记的实施不正确。)
- 默认情况下,英语术语被翻译成土耳其语。
- 为公司网站的博客部分创建了索引和排名稳定性。
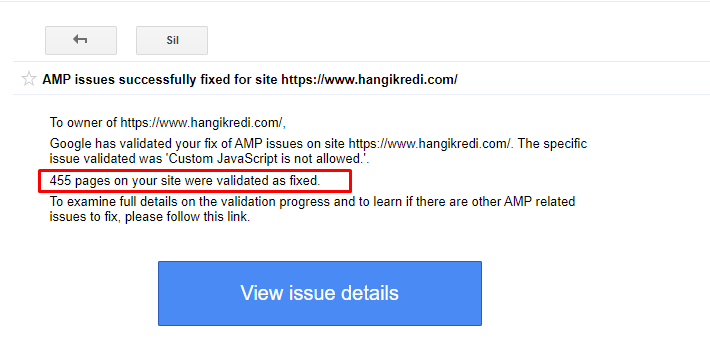
GSC 中有关 AMP 改进的示例消息
10. 元标签问题和解决方案
由于抓取预算问题,有时在重要的主要产品页面的关键搜索查询中,Google 没有索引或显示元标记中的内容。 SERP 列表没有显示元标题,而是仅显示由两个单词组成的公司名称。 没有显示片段描述。这降低了我们的点击率并损害了我们的品牌形象。 我们通过将元标记移动到源代码顶部来解决此问题,如下所示。
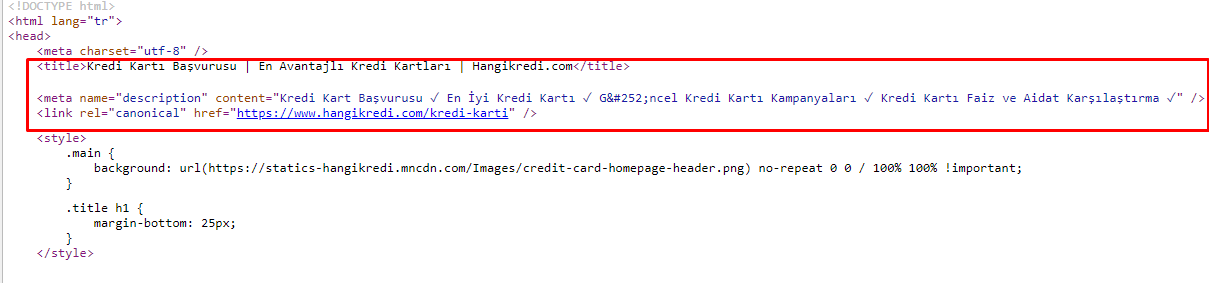
除了抓取预算外,我们还为交易和信息页面优化了 600 多个元标记:
- 优化移动设备的字符长度。
- 在标题中使用更多关键字
- 使用不同风格的元标签并检查点击率、关键字差距和排名变化
- 由于这些优化过程,创建了更多具有正确站点树结构的页面,以更好地定位次要关键字。
- 在我们的网站上,我们仍然有不同的元标题、描述和标题,用于测试 Google 的算法和搜索用户 CTR。
11. 图像性能问题及解决方案
图像问题可以分为两种类型。 为了内容方便和页面速度。 对于两者而言,公司的网站仍然有很多事情要做。
在 3 月 12 日负面核心算法更新之后的 3 月和 4 月:
- 图像没有 alt 标签或它们有错误的 alt 标签。
- 他们没有头衔。
- 他们没有正确的 URL 结构。
- 他们没有下一代扩展。
- 他们没有被压缩。
- 他们没有适合每种设备屏幕尺寸的分辨率。
- 他们没有字幕。
为下一次 Google 核心算法更新做准备:
- 图像被压缩。
- 他们的扩展部分被改变了。
- Alt 标签是为它们中的大多数编写的。
- 为用户固定了标题和说明。
- URL 结构为用户部分固定。
- 我们发现浏览器仍在加载一些未使用的图像,并将其从系统中删除。
由于网站基础设施,我们部分实施了图像 SEO 更正。
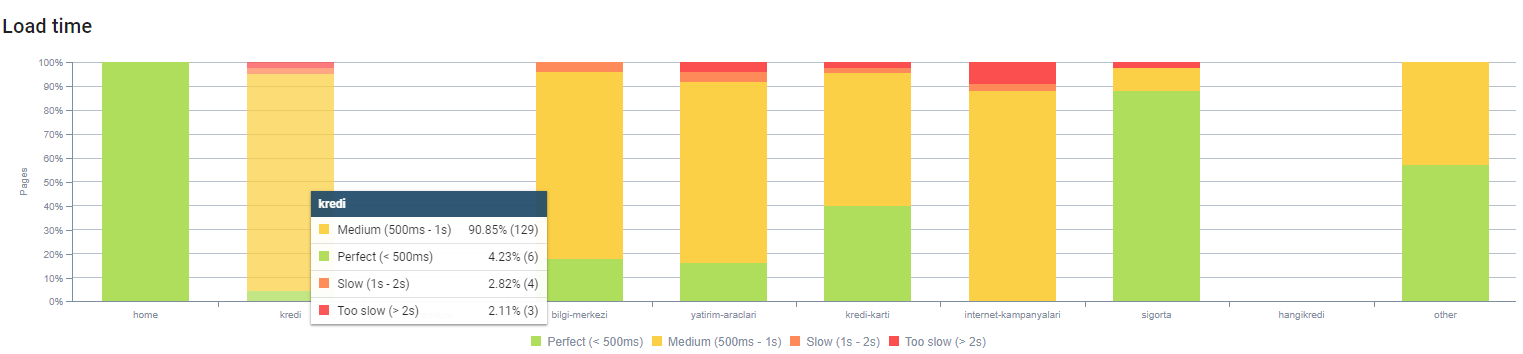
您可以通过上面的页面深度观察我们的页面加载时间。 如您所见,大多数产品页面仍然很重。
12. 缓存、预取和预加载问题及解决方案
在 3 月 12 日核心算法更新之前,公司网站上有一个松散的缓存系统。 一些内容部分在缓存中,但其中一些不在。 这对于产品页面尤其成问题,因为它们比我们竞争对手的产品页面慢 2 倍。 我们网页的大部分组件实际上都是静态资源,但它们仍然没有用于说明缓存范围的 Etag。
为下一次 Google 核心算法更新做准备:
- 我们为每个网页缓存了一些组件并使它们成为静态的。
- 这些页面是重要的产品页面。
- 由于站点基础设施,我们仍然不使用电子标签。
- 尤其是图像、静态资源和一些重要的内容部分现在已在站点范围内完全缓存。
- 我们已经开始对一些被遗忘的外包资源使用 dns-prefetch 代码。
- 我们仍然不使用预加载代码,但我们正在网站上开发用户旅程,以便将来实施。
13. HTML、CSS 和 JS 优化和缩小
由于网站基础设施问题,网站速度方面没有太多事情要做。 我试图用我能做到的每一种方法来缩小差距,包括删除一些页面组件。 对于重要的产品页面,我们清理了 HTML 代码结构,对其进行了缩小和压缩。
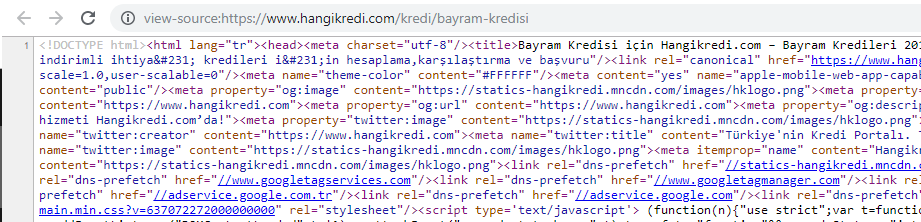
我们季节性但重要的产品页面源代码之一的屏幕截图。 使用常见问题解答结构化数据、HTML 缩小、图像优化、内容刷新和内部链接让我们在正确的时间获得了第一名。 (关键字是土耳其语中的“Bayram Kredisi”,意思是“假日信用”)
我们还通过小步骤部分实现了 CSS Factoring、Refactoring 和 JS Compression。 当排名下降时,我们检查了竞争对手页面与我们的页面之间的网站速度差距。 我们选择了一些我们可以加快速度的紧急页面。 我们还对这些页面上的关键 CSS 文件进行了部分纯化和压缩。 我们启动了删除公司不同部门使用的一些第三方JS文件的过程,但尚未删除。 对于某些产品页面,我们还能够更改资源加载顺序。
检查竞争对手
除了每项技术 SEO 改进之外,检查竞争对手是我了解核心算法更新的性质和目标的最佳指南。 我使用了一些有用且有帮助的程序来跟踪我的竞争对手的设计、内容、排名和技术变化。
- 对于关键字排名变化,我使用了 Wincher、Semrush 和 Ahrefs。
- 对于品牌提及,我使用了 Google Alerts、BuzzSumo、Talkwalker。
- 对于新链接和新关键字获取报告,我使用了 Ahrefs Alert。
- 对于内容和设计更改,我使用了 Visualping。
- 对于技术变革,我使用了 SimilarTech。
- 对于 Google Update News and Inspection,我主要使用了 Semrush Sensor、Algoroo 和 CognitiveSEO Signals。
- 为了检查竞争对手的 URL 历史,我使用了 Wayback Machine。
- 对于竞争对手的服务器速度,我使用了 Chrome DevTools 和 ByteCheck。
- 对于抓取和渲染成本,我使用了“我的网站成本是多少”。 (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.