
使用 Prophet 和 Python 预测 SEO 流量
已发表: 2021-03-16设定目标并随着时间的推移评估成就是一项非常有趣的练习,以便了解我们能够实现什么以及我们使用的策略是否有效。 然而,设定这些目标通常并不容易,因为我们首先需要做出预测。
创建预测并不是一件容易的事,但由于一些可用的预测程序、我们的 CPU 和一些编程技能,我们可以大大降低其复杂性。 在这篇文章中,我将向您展示我们如何做出准确的预测,以及如何通过使用 Python 和 Prophet 库将其应用于 SEO,而无需拥有算命先生的超能力。
如果您从未听说过 Prophet,您可能想知道它是什么。 简而言之,Prophet 是一个预测程序,由 Facebook 的核心数据科学团队发布,提供 Python 和 R 语言版本,可以很好地处理异常值和季节性影响
提供准确和快速的预测。
当我们谈论预测时,我们需要考虑两件事:
- 我们拥有的历史数据越多,我们的模型就越准确,因此我们的预测也就越准确。
- 预测模型只有在内部因素保持不变且没有外部因素影响的情况下才有效。 这意味着,例如,如果我们每周发布一篇文章,而我们开始每周发布两篇文章,则此模型可能无法有效预测此策略更改的结果。 另一方面,如果有算法更新,模型也可能无效。 请记住,该模型是基于历史数据构建的。
要将其应用于 SEO,我们要做的是在接下来的步骤之后预测下个月的 SEO 会话:
- 从 Google Analytics 获取特定时间段内自然会话的数据。
- 训练我们的模型。
- 预测下个月的 SEO 流量。
- 用平均绝对误差评估我们的模型有多好。
您想进一步了解此预测程序的工作原理吗? 让我们开始吧!
从 Google Analytics 获取数据
我们可以通过两种方式从 Google Analytics 中提取数据:从普通界面导出 Excel 文件或使用 API 检索这些数据。
从 Excel 文件导入数据
从 Google Analytics 获取这些数据的最简单方法是转到侧栏上的 Channels 部分,单击 Organic 并使用页面顶部的按钮导出数据。 确保在图表顶部的下拉菜单中选择要分析的变量,在本例中为 Sessions。
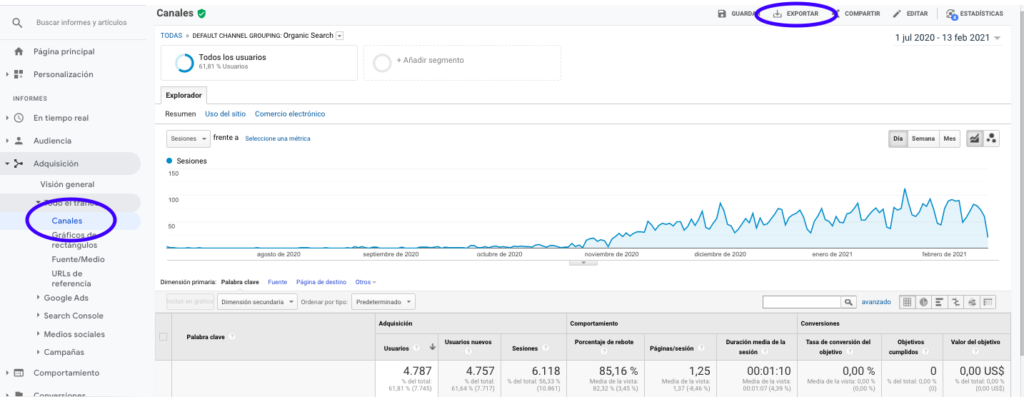
将数据导出为 Excel 文件后,我们可以使用 Pandas 将其导入到我们的笔记本中。 请注意,具有此类数据的 Excel 文件将包含不同的选项卡,因此需要在下面的代码中将具有每月流量的选项卡指定为参数。 我们还删除了最后一行,因为它包含会话总数,这会扭曲我们的模型。
将熊猫导入为 pd
df = pd.read_excel ('.xlsx', sheet_name="")
df = df.drop(len(df) - 1)
我们可以用 Matplotlib 画出数据的样子:
从 matplotlib 导入 pyplot
df["Sesiones"].plot(title = "Sesiones")
pyplot.show() 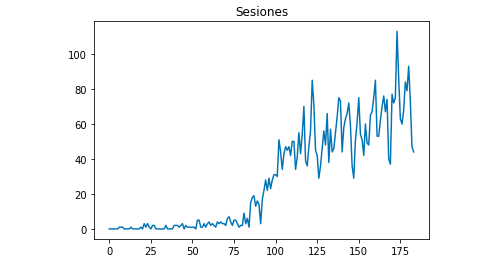
使用谷歌分析 API
首先,为了使用 Google Analytics API,我们需要在 Google 的开发者控制台上创建一个项目,启用 Google Analytics Reporting 服务并获取凭证。 Jean-Christophe Chouinard 在这篇文章中很好地解释了如何设置它。
获得凭据后,我们需要在发出请求之前进行身份验证。 身份验证需要使用最初从 Google 开发者控制台获得的凭证文件来完成。 我们还需要在我们的代码中写下我们想要使用的属性的 GA View ID。
从 apiclient.discovery 导入构建 从 oauth2client.service_account 导入 ServiceAccountCredentials SCOPES = ['https://www.googleapis.com/auth/analytics.readonly'] KEY_FILE_LOCATION = '' 看法_ 凭据 = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, SCOPES) 分析=构建('analyticsreporting','v4',凭证=凭证)
身份验证后,我们只需要发出请求。 我们需要用来获取每天有机会话数据的方法是:
响应 = analytics.reports().batchGet(body={
“报告请求”:[{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
“指标”:[
{“表达式”:“ga:会话”}
], “方面”: [
{“名称”:“ga:日期”}
],
"filtersExpression":"ga:channelGrouping=~Organic",
“includeEmptyRows”:“真”
}]})。执行()请注意,我们在 dateRanges 中选择时间范围。 就我而言,我将从 9 月 1 日到 1 月 31 日检索数据:[{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
在此之后,我们只需要获取响应文件以将其有机会话的日期附加到列表中:
列表值 = [] 对于 x 响应 ["reports"][0]["data"]["rows"]: list_values.append([x["dimensions"][0],x["metrics"][0]["values"][0]])
如您所见,使用 Google Analytics API 非常简单,它可以用于许多目标。 在本文中,我解释了如何使用 Google Analytics API 创建警报以检测表现不佳的页面。

使列表适应数据框
要使用 Prophet,我们需要输入一个包含两列需要命名的 Dataframe:“ds”和“y”。 如果您从 Excel 文件中导入数据,我们已经将其作为 Dataframe,因此您只需将列命名为“ds”和“y”:
df.columns = ['ds', 'y']
如果您使用 API 来检索数据,那么我们需要将列表转换为数据框并根据需要命名列:
从熊猫导入数据框 df_sessions = DataFrame(list_values,columns=['ds','y'])
训练模型
一旦我们有了所需格式的数据框,我们就可以很容易地确定和训练我们的模型:
导入 fbprophet 从 fbprophet 导入 Prophet 模型 = 先知() model.fit(df_sessions)
做出我们的预测
最后在训练我们的模型之后,我们就可以开始预测了! 为了继续进行预测,我们首先需要创建一个列表,其中包含我们想要预测的时间范围并调整日期时间格式:
从熊猫导入 to_datetime 预测天数 = [] 对于范围内的 x (1, 28): 日期 = "2021-02-" + str(x) Forecast_days.append([日期]) 预测天数 = 数据帧(预测天数) forecast_days.columns = ['ds'] forecast_days['ds']= to_datetime(forecast_days['ds'])
在这个例子中,我使用了一个循环来创建一个数据框,该数据框将包含从 2 月开始的所有日期。 现在只需要使用之前训练的模型即可:
预测 = model.predict(forecast_days)
我们可以绘制一个突出显示预测时间段的图:
从 matplotlib 导入 pyplot model.plot(预测) pyplot.show()
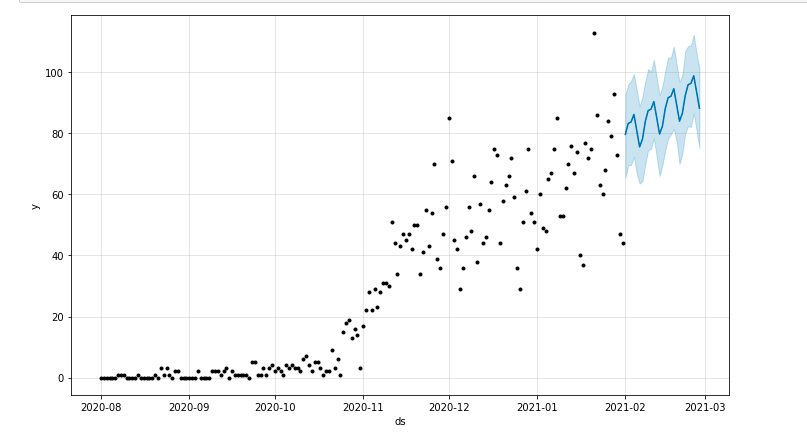
评估模型
最后,我们可以通过从用于训练模型的数据中剔除一些天数、预测这些天数的会话并计算平均绝对误差来评估我们的模型的准确性。
例如,我要做的是从原始数据帧中剔除从一月份开始的最后 12 天,预测每天的会话并将实际流量与预测流量进行比较。
首先,我们使用 pop 从原始数据框中删除最后 12 天,然后创建一个新数据框,其中仅包含将用于预测的那 12 天:
火车 = df_sessions.drop(df_sessions.index[-12:]) 未来 = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]
现在我们训练模型,进行预测并计算平均绝对误差。 最后,我们可以绘制一个图表,显示实际预测值与真实值之间的差异。 这是我从 Jason Brownlee 撰写的这篇文章中学到的。
从 sklearn.metrics 导入 mean_absolute_error
将 numpy 导入为 np
从 numpy 导入数组
#我们训练模型
模型 = 先知()
模型.fit(火车)
#将用于预测天数的数据框调整为 Prophet 所需的格式。
未来 = 列表(未来)
未来 = 数据帧(未来)
未来 = future.rename(columns={0: 'ds'})
# 我们做出预测
预测 = 模型.预测(未来)
# 我们计算实际值和预测值之间的 MAE
y_true = df_sessions['y'][-12:].values
y_pred = 预测['yhat'].values
mae = mean_absolute_error(y_true, y_pred)
# 我们绘制最终输出以进行视觉理解
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true, label='实际')
pyplot.plot(y_pred, label='Predicted')
pyplot.legend()
pyplot.show()
打印(前) 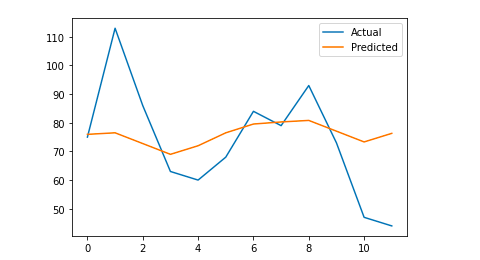
我的平均绝对误差是 13,这意味着我的预测模型每天分配的会话数比实际会话数多 13,这似乎是一个可以接受的错误。
这就是所有的人! 我希望您发现这篇文章很有趣,并且您可以开始进行 SEO 预测以设定目标。
更进一步:OnCrawl 实验室
如果您喜欢使用这种方法预测您的流量,您也会对 OnCrawl Labs 感兴趣,它是 OnCrawl 的数据科学和机器学习实验室,可为您的 SEO 工作流程提供预编码项目。
在 SEO 预测中,OnCrawl Labs 将帮助您完善您的 SEO 预测:
- 更好地理解 Facebook Prophet 算法背后的理论和流程
- 分析一段流量,例如仅针对长尾关键词的流量,或仅针对品牌关键词的流量……
- 按照循序渐进的过程设置历史事件,调整其影响和再次发生的可能性。