
使用 OnCrawl 的 Splunk 集成改进 SEO 日志分析的五种方法
已发表: 2019-01-03OnCrawl 最近发布了一个 Splunk 集成,以方便 Splunk 用户的日志监控。 我们发现公司将我们的 Splunk 集成用于两个主要目的:流程自动化和增强的安全控制。 但该工具的优势还不止于此。 这里有五种方法可以让您使用 OnCrawl Splunk 集成来改进您的技术 SEO。
SEO日志分析:基础知识
什么是SEO日志分析?
您的日志文件代表网站服务器本身记录的您网站上的所有活动。 它是有关您网站上发生的事情的最完整和最可靠的信息来源。 这包括机器人点击的数量和频率、来自 SERP 的 SEO 有机点击的数量和频率、按设备类型(台式机与移动设备)或 URL 类型(页面与资源)的细分、精确的页面大小和实际 HTTP 状态代码。
SEO日志分析提供的众多优势中的一些:
- 发现抓取行为的峰值或变化,表明 Google 处理您的网站的方式发生了变化
- 了解新页面平均需要多长时间才能被编入索引并接收第一批自然访问者
- 监控机器人和用户活动如何影响页面的排名
- 了解机器人和用户行为如何与其他 SEO 因素相关联

什么是 Splunk?
Splunk 是用于机器数据聚合的企业解决方案。 能够大规模索引和管理来自多个来源的数据,它包括用于站点安全和报告目的的服务器日志处理功能。
Splunk 的一些优点:
- 索引和搜索改进的数据相关性
- 向下钻取和透视功能以获得更好的报告
- 实时警报
- 数据仪表板
- 高度可扩展
- 灵活的部署选项
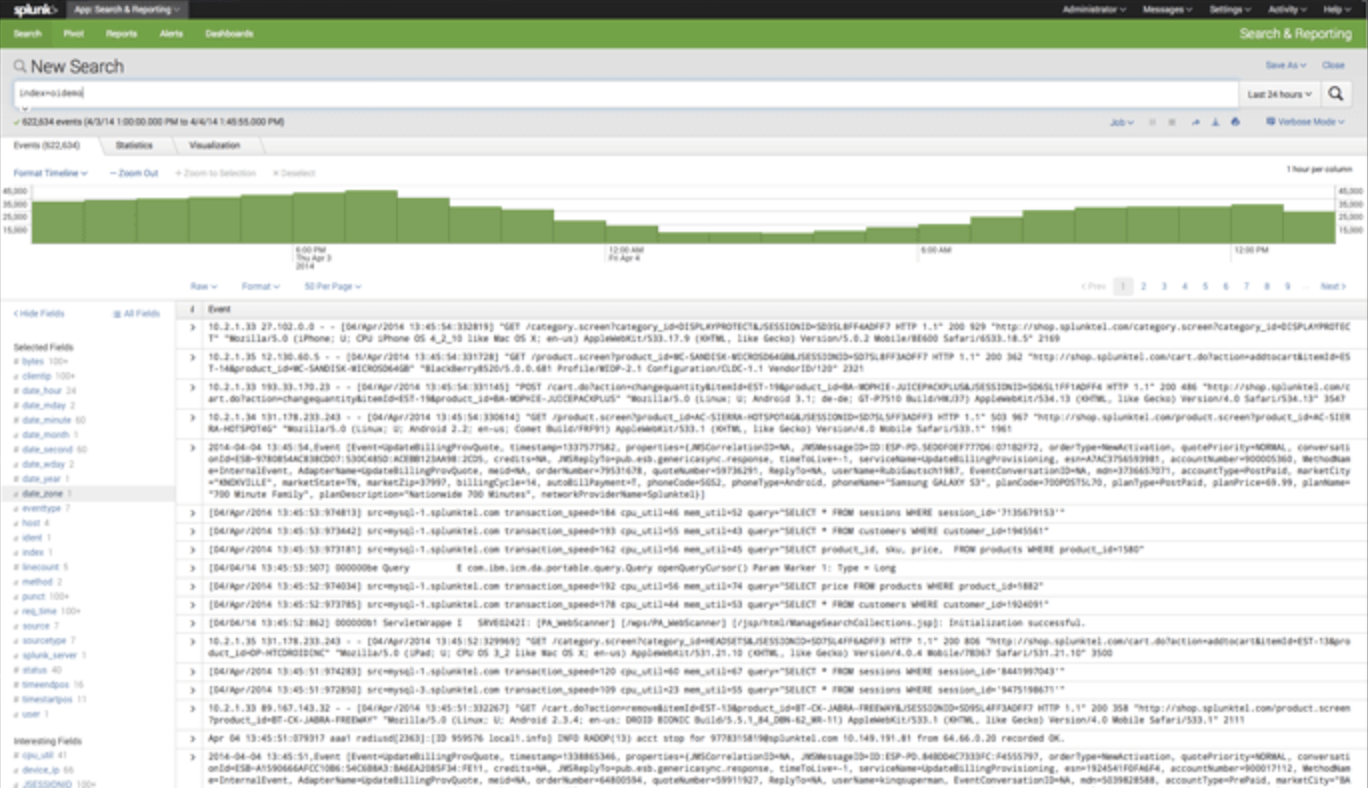
Splunk 中的日志监控
Splunk 用户受益于 OnCrawl 集成,将 Splunk 中管理的服务器日志数据与 OnCrawl 平台中的 SEO 数据连接起来。
Oncrawl 日志分析器
 学到更多
学到更多使用 OnCrawl + Splunk 改进您的技术 SEO
1. 使用日志进行深入的 SEO 分析
Splunk 证明了聚合、搜索、监控和设置日志数据警报的能力。 它解析和重新索引服务器日志中的内容。 使用强大的搜索和过滤器,它可以回答有关日志文件中数据的问题。 此处理步骤提供日志数据中显示的趋势的统计信息。
但是,当您想将其应用于 SEO 数据时,最好从原始数据开始。 这正是 OnCrawl Splunk 集成所做的。
这不仅可以显示日志数据的单独统计信息,还允许您将来自日志的信息与 OnCrawl 平台中的所有其他数据源集成。 反过来,这允许您检查 SEO 指标与日志文件中有关用户和机器人行为的信息之间的关系。

按页面点击深度划分的自然访问次数。
这种跨数据分析可以包括对 SEO 有用的轴:
- 单个机器人的抓取行为细分
- 第一次抓取和第一次自然访问之间的时间
- 提供给用户和机器人的页面与审计爬网期间提供的页面之间的比较
- 发现孤立页面
- 抓取频率与排名、展示次数、点击率之间的相关性
- 内部链接策略对用户/机器人活动的影响
- 页面点击深度与用户/机器人活动之间的关系
- 内部页面流行度与用户/机器人活动之间的关系
- 按 SEO 性能分组的页面中的用户和机器人活动细分
2. 使设置更容易
无论您是否需要自动化或更精细的数据安全控制,如果您是 Splunk 用户,您将
就像设置有多简单。

如果您不是系统管理员,那么为 SEO 设置日志监控似乎是一项复杂的任务。
我们的建议是简单地跳过困难的部分。 您现在可以直接在 Splunk 中设置所有内容,并使用您生成的密钥创建与 OnCrawl 的连接。
就是这样。 你准备好了。 这再简单不过了。
3. 利用 Splunk 的流程自动化
使用 Splunk 中收集的日志数据的手动过程需要多个步骤:
- 创建过滤器以搜索正确选择的日志数据
- 创建已保存的搜索
- 为运行搜索设置自动化
- 输出到 CSV
- 在 SSH 中连接到您的 Splunk 实例
- 导航到 CSV 输出文件夹
- 将文件传输到您的计算机
- 连接到 OnCrawl ftp 空间
- 将文件传输到 OnCrawl...
必须定期重复此过程,以避免日志数据出现空白。 这通常成为一项日常任务。
如果您选择为 OnCrawl 使用 Splunk 集成,则不再需要定期启动任务。 您只需要设置流程(而且,如前所述,这再简单不过了)。 您不再需要担心每天启动脚本——或者更糟糕的是,一系列手动操作; 集成为您处理。
4. 保护您的流程
在出现问题时保护自己免于丢失数据。 由于日志监控依赖于连续的数据流,因此差距可能会导致错误的结论。 你不应该问这样的问题:今天早上明显没有自然访问是由于谷歌上发生的事情,还是我只是错过了数据?
OnCrawl Splunk 集成可在您的服务器关闭或连接丢失时保护您,并在您没有时间或忘记上传数据时防止人为错误。 如果我们无法连接到服务器,也不会导致您的数据出现空白; 我们稍后会收集它。 如果您发现忘记添加到 Splunk 的一组较早日期的数据,OnCrawl 集成也会自动获取它。
5. 控制数据安全
在 OnCrawl,我们非常重视您数据的安全性。
与往常一样,日志中的敏感数据会保存在您将它们放在您的私有、安全 FTP 空间中的位置,并且永远不会在其他地方提供。 例如,在验证 Googlebot 访问的真实性时,我们处理的唯一个人数据是 IP 地址。 我们不记录所使用的 IP 地址——只记录验证的结果。 如有必要,您可以随时通过从 FTP 空间中删除文件来删除可供分析的敏感信息。
Splunk 的集成更进一步。 我们确保您在整个过程中保持对数据的控制。 您可以在 OnCrawl 中定义访问权限、要共享的数据以及更新频率。 当您通过 Splunk 集成与 OnCrawl 共享数据时,我们使用标准的安全协议与 Splunk 进行通信,并受您设置的密码和密钥的保护。
因为设置是在 Splunk 中完成的,所以 OnCrawl 永远不会看到您不允许我们看到的任何内容。 您选择与 OnCrawl 共享的信息。 不仅如此,由于您管理设置,如果您的日志记录过程或您公司的标准发生变化,您可以随时进行更改。