
如何从 HTML 页面中提取相关的文本内容?
已发表: 2021-10-13语境
在 Oncrawl 的研发部门,我们越来越希望为您网页的语义内容增加价值。 使用自然语言处理 (NLP) 的机器学习模型,可以执行对 SEO 具有真正附加值的任务。
这些任务包括以下活动:
- 微调页面内容
- 制作自动摘要
- 为您的文章添加新标签或更正现有标签
- 根据您的 Google Search Console 数据优化内容
- 等等
这次冒险的第一步是提取这些机器学习模型将使用的网页的文本内容。 当我们谈论网页时,这包括 HTML、JavaScript、菜单、媒体、页眉、页脚…… 自动正确地提取内容并不容易。 通过这篇文章,我建议探索这个问题,并讨论一些工具和建议来完成这个任务。
问题
从网页中提取文本内容可能看起来很简单。 用几行 Python,例如,几个正则表达式(regexp),一个像 BeautifulSoup4 这样的解析库,就完成了。
如果您暂时忽略越来越多的网站使用 Vue.js 或 React 等 JavaScript 渲染引擎这一事实,那么解析 HTML 并不是很复杂。 如果你想通过在你的爬虫中利用我们的 JS 爬虫来解决这个问题,我建议你阅读“如何用 JavaScript 爬取网站?”。
但是,我们希望提取有意义的文本,即尽可能提供信息。 例如,当您阅读有关 John Coltrane 的最后一张遗作专辑的文章时,您会忽略菜单、页脚……显然,您并没有查看整个 HTML 内容。 这些几乎出现在所有页面上的 HTML 元素称为样板。 我们想去掉它,只保留一部分:携带相关信息的文本。
因此,我们只想将这段文本传递给机器学习模型进行处理。 这就是为什么提取尽可能定性至关重要的原因。
解决方案
总的来说,我们希望摆脱“挂在”主文本周围的一切:菜单和其他侧边栏、联系元素、页脚链接等。有几种方法可以做到这一点。 我们最感兴趣的是 Python 或 JavaScript 中的开源项目。
法理
jusText 是博士论文中提出的 Python 实现:“Removing Boilerplate and Duplicate Content from Web Corpora”。 该方法允许来自 HTML 的文本块根据不同的启发式分类为“好”、“坏”、“太短”。 这些启发式方法主要基于字数、文本/代码比、链接的存在与否等。您可以在文档中阅读有关该算法的更多信息。
螳螂
trafilatura 也是在 Python 中创建的,它提供关于 HTML 元素类型及其内容的启发式方法,例如文本长度、元素在 HTML 中的位置/深度或字数。 trafilatura 也使用 jusText 进行一些处理。
可读性
你有没有注意到 Firefox 的 URL 栏中的按钮? 这是阅读器视图:它允许您从 HTML 页面中删除样板以仅保留主要文本内容。 用于新闻网站非常实用。 此功能背后的代码是用 JavaScript 编写的,Mozilla 将其称为可读性。 它基于 Arc90 实验室发起的工作。
以下是如何为 France Musique 网站上的文章呈现此功能的示例。 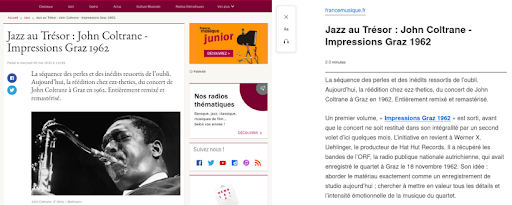
左边是原始文章的摘录。 右侧是 Firefox 中阅读器视图功能的渲染。
其他
我们对 HTML 内容提取工具的研究也使我们考虑了其他工具:
- 报纸:一个内容提取库,专门用于新闻网站(Python)。 该库用于从 OpenWebText2 语料库中提取内容。
- 锅炉py3 是锅炉管库的Python 端口。
- dragnet Python 库也受到锅炉管的启发。
抓取数据³
 学到更多
学到更多评估和建议
在评估和比较不同工具之前,我们想知道 NLP 社区是否使用其中一些工具来准备他们的语料库(大量文档)。 例如,用于训练 GPT-Neo 的名为 The Pile 的数据集包含来自 Wikipedia、Openwebtext2、Github、CommonCrawl 等的 +800 GB 英文文本。与 BERT 一样,GPT-Neo 是一种使用类型转换器的语言模型。 它提供了一个类似于 GPT-3 架构的开源实现。

文章“The Pile: An 800GB Dataset of Diverse Text for Language Modeling”提到了在 CommonCrawl 的大部分语料库中使用 jusText。 这组研究人员还计划对不同的提取工具进行基准测试。 不幸的是,由于缺乏资源,他们无法完成计划的工作。 在他们的结论中,应该指出:
- jusText 有时会删除太多内容,但仍然提供了良好的质量。 鉴于他们拥有的数据量,这对他们来说不是问题。
- trafilatura 更擅长保留 HTML 页面的结构,但保留了太多样板文件。
对于我们的评估方法,我们使用了大约 30 个网页。 我们“手动”提取了主要内容。 然后,我们将不同工具的文本提取与这种所谓的“参考”内容进行了比较。 我们使用主要用于评估自动文本摘要的 ROUGE 分数作为衡量标准。
我们还将这些工具与基于 HTML 解析规则的“自制”工具进行了比较。 事实证明,trafilatura、jusText 和我们自制的工具在这个指标上的表现优于大多数其他工具。
以下是 ROUGE 分数的平均值和标准偏差表:
| 工具 | 意思是 | 标准 |
|---|---|---|
| 螳螂 | 0.783 | 0.28 |
| 爬行 | 0.779 | 0.28 |
| 法理 | 0.735 | 0.33 |
| 锅炉py3 | 0.698 | 0.36 |
| 可读性 | 0.681 | 0.34 |
| 拉网 | 0.672 | 0.37 |
鉴于标准偏差的值,请注意提取的质量可能会有很大差异。 HTML 的实现方式、标签的一致性以及语言的适当使用都会导致提取结果的很多变化。
表现最好的三个工具是 trafilatura,这是我们为这种场合命名为“oncrawl”的内部工具和 jusText。 由于 trafilatura 使用 jusText 作为后备,我们决定使用 trafilatura 作为我们的首选。 但是,当后者失败并提取零词时,我们使用自己的规则。
请注意,trafilatura 代码还提供了数百页的基准。 它根据提取的内容中是否存在某些元素来计算精度分数、f1 分数和准确度。 两个工具脱颖而出:trafilatura 和 goose3。 您可能还想阅读:
- 选择正确的工具从 Web 中提取内容 (2020)
- Github 存储库:文章提取基准:开源库和商业服务
结论
HTML 代码的质量和页面类型的异质性使得提取优质内容变得困难。 正如 The Pile 和 GPT-Neo 背后的 EleutherAI 研究人员发现的那样,没有完美的工具。 当没有删除所有样板文件时,有时会在文本中截断的内容和残余噪音之间进行权衡。
这些工具的优点是它们是上下文无关的。 这意味着,除了页面的 HTML 之外,它们不需要任何数据来提取内容。 使用 Oncrawl 的结果,我们可以想象一种混合方法,使用站点所有页面中某些 HTML 块的出现频率将它们分类为样板。
至于我们在 Web 上遇到的基准测试中使用的数据集,它们通常是同一类型的页面:新闻文章或博客文章。 它们不一定包括保险、旅行社、电子商务等网站,其中文本内容有时更难以提取。
关于我们的基准测试并且由于缺乏资源,我们知道三十页左右不足以获得更详细的分数视图。 理想情况下,我们希望有更多不同的网页来完善我们的基准值。 我们还希望包含其他工具,例如 goose3、html_text 或 inscriptis。