
A/B 测试统计意义:如何以及何时结束测试
已发表: 2020-05-22
在我们最近对 Convert 客户运行的 28,304 个实验的分析中,我们发现只有 20%的实验达到了 95% 的统计显着性水平。 Econsultancy 在其 2018 年优化报告中发现了类似的趋势。 三分之二的受访者认为只有 30% 或更少的实验是“明显且具有统计学意义的赢家”。
所以大多数实验(70-80%)要么没有结论,要么提前停止。
其中,早期停止的那些是一个奇怪的案例,因为优化者会在他们认为合适的时候调用结束实验。 当他们可以“看到”明显的赢家(或输家)或明显无关紧要的测试时,他们就会这样做。 通常,他们也有一些数据来证明这一点。
考虑到 50% 的优化器在他们的实验中没有标准的“停止点”,这可能并不令人惊讶。 对于大多数人来说,这样做是必要的,因为必须保持一定的测试速度(每月 XXX 次测试)以及争夺主导竞争的压力。
此外,负面实验也有可能损害收入。 我们自己的研究表明,非成功的实验平均会导致转化率下降 26% !
总而言之,提前结束实验还是有风险的……
......因为它留下了实验运行其预期长度的概率,由正确的样本量提供支持,其结果可能会有所不同。
那么,提前结束实验的团队如何知道什么时候结束呢? 对大多数人来说,答案在于制定加速决策的停止规则,同时又不影响决策质量。
摆脱传统的停止规则
对于网络实验,0.05 的 p 值作为标准。 这 5% 的容错或 95% 的统计显着性水平有助于优化人员保持测试的完整性。 他们可以确保结果是实际结果,而不是侥幸。
在用于固定水平测试的传统统计模型中——测试数据在固定时间或特定数量的参与用户中仅评估一次——当 p 值低于 0.05 时,您将接受结果为显着。 此时,您可以拒绝零假设,即您的控制和治疗是相同的,并且观察到的结果不是偶然的。
与允许您在收集数据时评估数据的统计模型不同,此类测试模型禁止您在实验运行时查看实验数据。 这种做法(也称为窥视)在此类模型中是不鼓励的,因为 p 值几乎每天都在波动。 你会发现某天实验很重要,第二天,它的 p 值会上升到不再重要的程度。
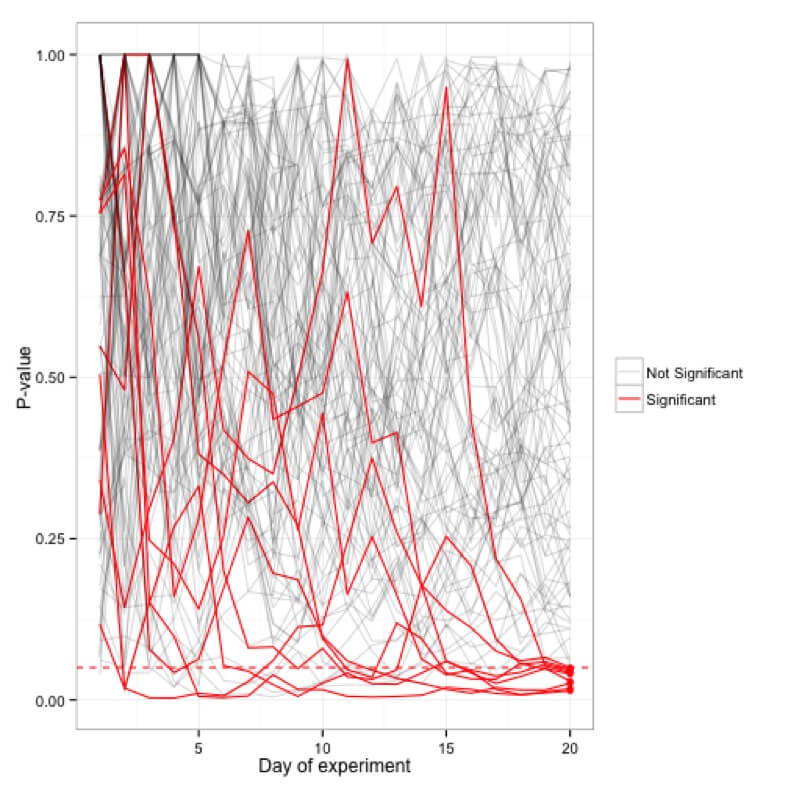
为一百个(20 天)实验绘制的 p 值模拟; 实际上只有 5 个实验最终在 20 天大关时具有显着性,而许多实验偶尔会在过渡期间达到 <0.05 的临界值。
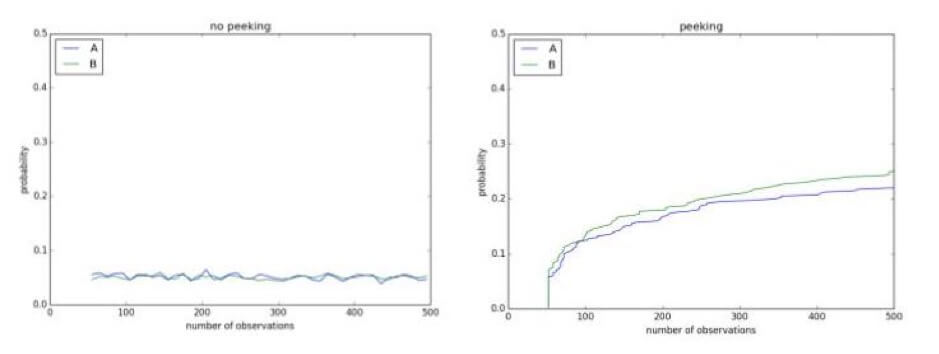
在此期间查看您的实验可能会显示不存在的结果。 例如,下面有一个使用显着性水平 0.1 的 A/A 测试。 由于它是 A/A 测试,因此控制和治疗之间没有区别。 然而,在正在进行的实验中进行 500 次观察后,有超过 50% 的机会得出结论认为它们不同并且可以拒绝原假设:
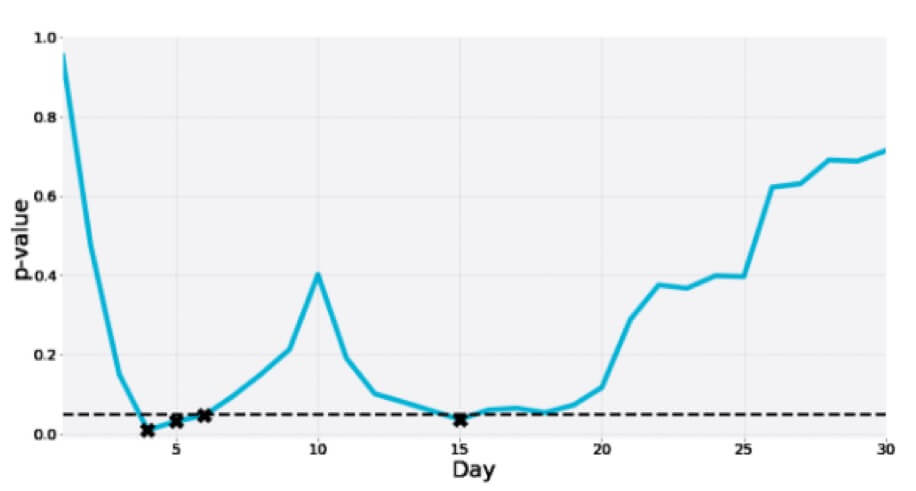
这是另一个为期 30 天的 A/A 测试,其中 p 值在过渡期间多次跌至显着性区域,但最终远高于临界值:
正确报告固定水平实验的 p 值意味着您需要预先承诺固定的样本量或测试持续时间。 一些团队还会在此实验停止标准和预期长度中添加一定数量的转换。
然而,这里的问题是,对于大多数网站来说,使用这种标准做法来获得足够的测试流量来支持每个实验以实现最佳停止是很困难的。
这里是使用支持可选停止规则的顺序测试方法有帮助的地方。
转向灵活的停止规则,以实现更快的决策
顺序测试方法可让您在实验数据出现时利用它,并使用您自己的统计显着性模型更快地发现获胜者,并具有灵活的停止规则。
CRO 成熟度最高的优化团队通常会设计自己的统计方法来支持此类测试。 一些 A/B 测试工具也将这一点融入其中,并且可以建议某个版本是否会胜出。 有些可以让您完全控制您希望如何计算统计显着性,以及您的自定义值等等。 因此,即使在正在进行的实验中,您也可以窥视并发现获胜者。

Georgi Georgiev 是流行的 A/B 测试统计 CXL 课程的统计学家、作者和讲师,他非常喜欢这样的顺序测试方法,这些方法允许中期分析的数量和时间灵活:
“顺序测试允许您通过尽早部署获胜的变体来最大化利润,并尽早停止产生获胜可能性很小的测试。 后者将由于劣质变体造成的损失降至最低,并在变体根本不可能胜过对照时加快测试速度。 在所有情况下都保持统计严谨性。 ”
Georgiev 甚至开发了一个计算器,它可以帮助团队放弃固定样本测试模型,转而使用一种可以在实验仍在运行时检测出获胜者的模型。 他的模型考虑了很多统计数据,并帮助您调用测试比标准统计显着性计算快 20-80%,而不会牺牲质量。
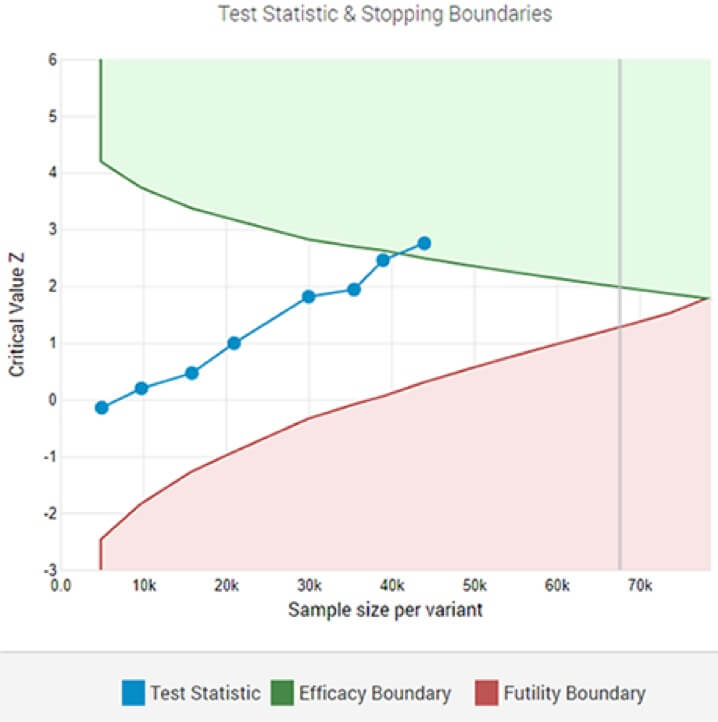
在第 8 次中期分析后,自适应 A/B 测试显示在指定显着性阈值处具有统计学意义的获胜者。
虽然此类测试可以加快您的决策过程,但有一个重要方面需要解决:实验的实际影响。 在此期间结束实验可能会导致您高估它。
Georgiev 警告说,查看效应大小的未经调整的估计值可能是危险的。 为了避免这种情况,他的模型使用了一些方法来应用调整,这些调整考虑到了由于临时监控而产生的偏差。 他解释了他们的敏捷分析如何“根据停止阶段和观察到的统计值(超调,如果有的话)”来调整估计值。 下面,您可以看到上述测试的分析:(注意估计的提升如何低于观察到的,并且间隔不是以它为中心。)
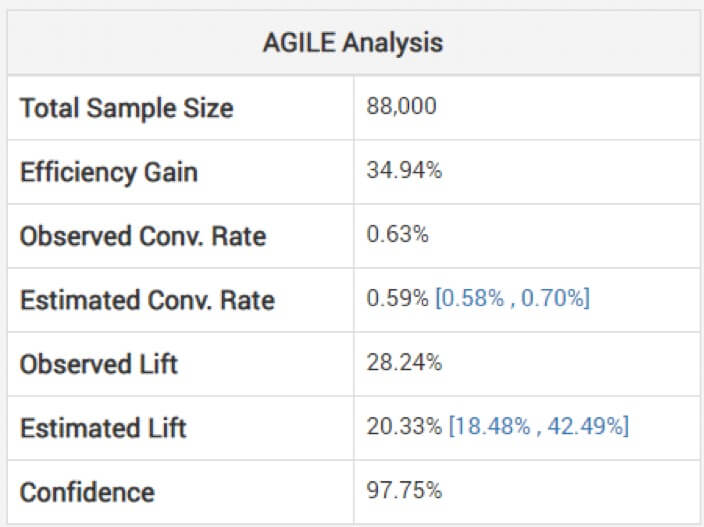
因此,根据您的短于预期的实验,胜利可能没有看起来那么大。
损失也需要考虑在内,因为您最终可能仍然错误地过早地称赢家。 但即使在固定水平测试中也存在这种风险。 然而,与运行时间较长的固定水平测试相比,在早期调用实验时,外部有效性可能是一个更大的问题。 但正如 Georgiev 解释的那样,这是“样本量较小以及测试持续时间较小的简单结果。 “
最后……这与赢家或输家无关……
……但正如 Chris Stucchio 所说,关于更好的商业决策。
或者正如汤姆·雷德曼(《数据驱动:从您最重要的商业资产中获利》一书的作者)所断言的那样:“在商业中,通常有比统计显着性更重要的标准。 重要的问题是,“结果是否在市场上站得住脚,哪怕只是短暂的一段时间? ''
Georgiev 指出,“如果它具有统计学意义,并且在设计阶段以令人满意的方式解决了外部有效性考虑,那么它很可能会,而且不仅仅是短期内。”
实验的全部本质是使团队能够做出更明智的决定。 因此,如果您可以更快地传递结果(您的实验数据指向的结果),那为什么不呢?
这可能是一个小的 UI 实验,您实际上无法获得“足够”的样本量。 这也可能是一个实验,你的挑战者粉碎了原版,你可以接受这个赌注!
正如 Jeff Bezos 在给亚马逊股东的信中所写的那样,大型实验付出了巨大的时间:
“假设有 10% 的机会获得 100 倍的回报,你应该每次都下注。 但是十有八九你还是会错。 我们都知道,如果你在围栏上挥杆,你会打出很多三振,但你也会打出一些本垒打。 然而,棒球和商业之间的区别在于,棒球有一个截断的结果分布。 当你挥杆时,无论你与球的连接有多好,你最多可以跑四次。 在商业中,每隔一段时间,当你踏上盘子时,你就可以获得 1000 分。 这种长尾的回报分布就是为什么大胆很重要。 大赢家为如此多的实验买单。 “
在很大程度上,提早进行实验就像每天都在偷看结果,然后停在一个可以保证下注的地方。

