
爬网、索引和 Python:所有你需要知道的
已发表: 2021-05-31我想从一个非常简单的等式开始这篇文章:如果您的页面没有被抓取,它们将永远不会被索引,因此,您的 SEO 性能将永远受到影响(并且很糟糕)。
因此,SEO 需要努力找到使他们的网站可抓取的最佳方法,并向 Google 提供他们最重要的页面,以使它们被编入索引并开始通过它们获取流量。
值得庆幸的是,我们有许多资源可以帮助我们提高网站的可抓取性,例如 Screaming Frog、Oncrawl 或 Python。 我将向您展示 Python 如何帮助您分析和提高您的爬取友好性和索引指标。 大多数情况下,这些改进也会推动更好的排名、更高的 SERP 可见性,并最终让更多的用户登陆您的网站。
1. 使用 Python 请求索引
1.1。 对于谷歌
可以通过多种方式为 Google 请求索引,但遗憾的是,我对其中任何一种都不太信服。 我将引导您了解三种不同的选择及其优缺点:
- Selenium 和 Google Search Console:从我的角度来看,在对其和其他选项进行测试之后,这是最有效的解决方案。 但是,经过多次尝试后,可能会有一个验证码弹出窗口将其破坏。
- ping 站点地图:这肯定有助于使站点地图按请求进行爬网,但对特定 URL 没有帮助,例如在新页面已添加到网站的情况下。
- Google Indexing API:除了广播公司和工作平台网站外,它不是很可靠。 它有助于提高抓取速度,但不能索引特定的 URL。
在对每种方法进行快速概述之后,让我们一一深入研究它们。
1.1.1。 Selenium 和谷歌搜索控制台
本质上,我们将在第一个解决方案中做的是从带有 Selenium 的浏览器访问 Google Search Console,并复制我们手动遵循的相同过程,以使用 Google Search Console 提交许多 URL 进行索引,但以自动化方式。
注意:不要过度使用此方法,仅在其内容已更新或页面全新时才提交页面以供索引。
使用 Selenium 登录 Google Search Console 的诀窍是首先访问 OUATH Playground,正如我在本文中解释的如何自动下载 GSC 抓取统计报告。
#我们导入这些模块
进口时间
从硒导入网络驱动程序
从 webdriver_manager.chrome 导入 ChromeDriverManager
从 selenium.webdriver.common.keys 导入密钥
#我们安装我们的 Selenium 驱动程序
驱动程序 = webdriver.Chrome(ChromeDriverManager().install())
#我们访问 OUATH 游乐场帐户以登录 Google 服务
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
#在使用 Xpath 选择元素并引入我们的电子邮件地址之前,我们稍等片刻以确保渲染完成。
时间.sleep(10)
form1=driver.find_element_by_xpath('//*[@]')
form1.send_keys("<您的电子邮件地址>")
form1.send_keys(Keys.ENTER)
#这里也是,我们稍等片刻,然后我们介绍我们的密码。
时间.sleep(10)
form2=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
form2.send_keys("<你的密码>")
form2.send_keys(Keys.ENTER)
之后,我们可以访问我们的 Google Search Console URL:
driver.get('https://search.google.com/search-console?resource_id=your_domain')
时间.sleep(5)
box=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div /div[1]/输入[2]')
box.send_keys("your_URL")
box.send_keys(Keys.ENTER)
时间.sleep(5)
indexation = driver.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div /div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
indexation.click()
时间.sleep(120)
不幸的是,正如介绍中所解释的,似乎在多次请求之后,它开始需要一个拼图验证码才能继续索引请求。 由于自动化方法无法解决验证码,这是阻碍该解决方案的因素。
1.1.2。 ping 站点地图
可以使用 ping 方法将站点地图 URL 提交给 Google。 基本上,您只需向以下端点发出请求,将您的站点地图 URL 作为参数引入:
http://www.google.com/ping?sitemap=URL/of/file
正如我在本文中解释的那样,这可以通过 Python 和请求非常容易地自动化。
导入 urllib.request url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" 响应 = urllib.request.urlopen(url)
1.1.3。 谷歌索引 API
Google Indexing API 可以是提高抓取速度的一个很好的解决方案,但通常它不是一种让您的内容被索引的非常有效的方法,因为它只应该在您的网站在 VideoObject 中嵌入 JobPosting 或 BroadcastEvent 时使用。 但是,如果您想尝试一下并自己进行测试,您可以按照以下步骤操作。
首先,要开始使用此 API,您需要转到 Google Cloud Console,创建一个项目和一个服务帐户凭据。 之后,您将需要从库中启用索引 API,并将使用服务帐户凭据提供的电子邮件帐户添加为 Google Search Console 上的财产所有者。 您可能需要使用旧版 Google Search Console 才能将此电子邮件地址添加为业主。
按照前面的步骤操作后,您将能够通过使用下一段代码开始使用此 API 请求索引和取消索引:
从 oauth2client.service_account 导入 ServiceAccountCredentials
导入 httplib2
范围= [“https://www.googleapis.com/auth/indexing”]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
client_secrets = "path_to_your_credentials.json"
凭据 = ServiceAccountCredentials.from_json_keyfile_name(client_secrets, scopes=SCOPES)
如果凭据为无或凭据。无效:
凭据 = tools.run_flow(流,存储)
http = credentials.authorize(httplib2.Http())
list_urls = ["https://www.example.com", "https://www.example.com/test2/"]
对于范围内的迭代(len(list_urls)):
内容='''{
'url': "'''+str(list_urls[iteration])+'''",
“类型”:“URL_UPDATED”
}'''
响应,内容 = http.request(ENDPOINT, method="POST", body=content)
打印(响应)
打印(内容)如果您想要求取消索引,您需要将请求类型从“URL_UPDATED”更改为“URL_DELETED”。 前一段代码将打印来自 API 的响应以及通知时间及其状态。 如果状态为 200,则请求已成功发出。
1.2. 对于必应
很多时候,当我们谈论 SEO 时,我们只会想到 Google,但我们不能忘记,在某些市场中还有其他主要的搜索引擎和/或其他搜索引擎,它们拥有可观的市场份额,例如 Bing。
重要的是从一开始就提到 Bing 在 Bing Webmaster Tools 上已经有一个非常方便的功能,在大多数情况下,您可以每天请求提交多达 10,000 个 URL。 有时,您的每日配额可能低于 10,000 个 URL,但如果您认为需要更大的配额来满足您的需求,您可以选择请求增加配额。 您可以在此页面上阅读有关此内容的更多信息。
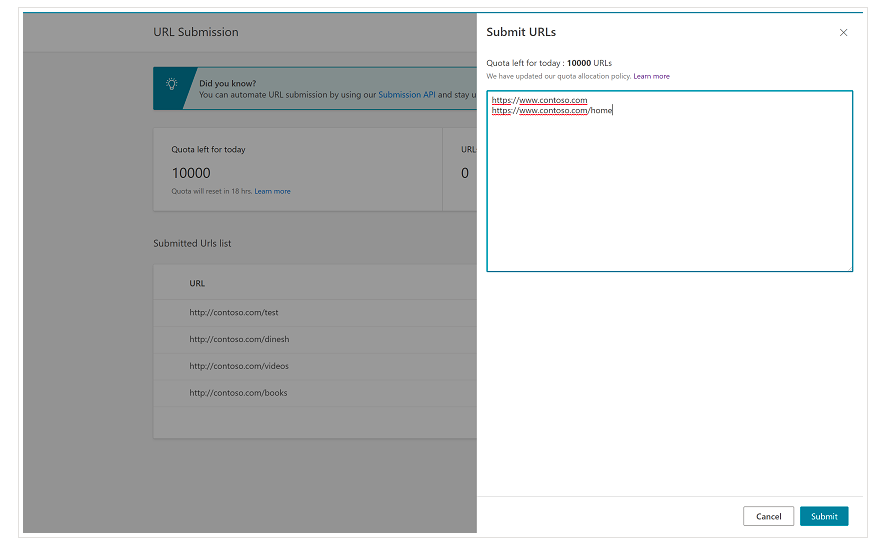
此功能对于批量提交 URL 确实非常方便,因为您只需要从 Bing 网站管理员工具的正常界面在 URL 提交工具中的不同行中引入您的 URL。
1.2.1。 必应索引 API
Bing Indexing API 可以与需要作为参数引入的 API 密钥一起使用。 此 API 密钥可以在 Bing 网站管理员工具上获取,进入 API 访问部分,然后生成 API 密钥。
获取 API 密钥后,我们可以使用以下代码来使用 API(您只需要添加 API 密钥和站点 URL):
导入请求
list_urls = ["https://www.example.com", "https://www.example/test2/"]
对于 list_urls 中的 y:
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj = '{"siteUrl":"https://www.example.com", "urlList":["'+ str(y) +'"]}'
headers = {'内容类型':'应用程序/json; 字符集=utf-8'}
x = requests.post(url, data=myobj, headers=headers)
打印(str(y)+“:”+str(x))这将在每次迭代时打印 URL 及其响应代码。 与 Google Indexing API 相比,此 API 可用于任何类型的网站。
[案例研究] 通过提高 Googlebot 的网站可抓取性来提高知名度
 阅读案例研究
阅读案例研究2. 站点地图分析、创建和上传
众所周知,站点地图是非常有用的元素,可以为搜索引擎机器人提供我们希望它们抓取的 URL。 为了让搜索引擎机器人知道我们的站点地图在哪里,它们应该被上传到谷歌搜索控制台和必应网站管理员工具,并包含在 robots.txt 文件中以供其他机器人使用。
使用 Python,我们主要可以处理与站点地图相关的三个不同方面:它们的分析、创建以及从 Google Search Console 上传和删除。
2.1。 使用 Python 导入和分析站点地图
Advertools 是由 Elias Dabbas 创建的一个很棒的库,可用于站点地图导入以及许多其他 SEO 任务。 您只需使用以下命令即可将站点地图导入数据框:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
该库支持常规 XML 站点地图、新闻站点地图和视频站点地图。
另一方面,如果您只对从站点地图导入 URL 感兴趣,您也可以使用库请求和 BeautifulSoup。
导入请求
从 bs4 导入 BeautifulSoup
r = requests.get("https://www.example.com/your_sitemap.xml")
xml = r.text
汤 = BeautifulSoup(xml)
urls = soup.find_all("loc")
urls = [[x.text] for x in urls]
导入站点地图后,您可以使用提取的 URL 并按照 Koray Tugberk 在本文中的说明执行内容分析。
2.2. 使用 Python 创建站点地图
正如 JC Chouinard 在本文中所解释的那样,您还可以利用 Python 从 URL 列表中创建 sitemaps.xml。 这对于 URL 快速变化的非常动态的网站特别有用,并且与上面解释的 ping 方法一起,它可以是一个很好的解决方案,为 Google 提供新的 URL 并让它们快速被抓取和索引。
最近,Greg Bernhardt 还用 Streamlit 和 Python 创建了一个 APP 来生成站点地图。
2.3. 从 Google Search Console 上传和删除站点地图
Google Search Console 有一个 API,主要可用于两种不同的方式:提取有关 Web 性能的数据和处理站点地图。 在这篇文章中,我们将重点介绍上传和删除站点地图的选项。
首先,从 Google Cloud Console 创建或使用现有项目以获取 OUATH 凭据并启用 Google Search Console 服务非常重要。 JC Chouinard 在本文中很好地解释了使用 Python 访问 Google Search Console API 所需遵循的步骤以及如何发出第一个请求。 基本上,我们可以完全利用他的代码,但只有通过引入更改,在范围内我们将添加“https://www.googleapis.com/auth/webmasters”而不是“https://www.googleapis.com” /auth/webmasters.readonly”,因为我们不仅会使用 API 来读取站点地图,还会使用它来上传和删除站点地图。

一旦我们连接到 API,我们就可以开始使用它,并使用下一段代码列出我们 Google Search Console 属性中的所有站点地图:
对于已验证站点 URL 中的站点 URL:
打印(site_url)
# 检索提交的站点地图列表
站点地图 = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
如果站点地图中有“站点地图”:
sitemap_urls = [s['path'] for s in sitemaps['sitemap']]
打印 (" " + "\n ".join(sitemap_urls))
对于特定的站点地图,我们可以执行三个任务,我们将在下一节中详细说明:上传、删除和请求信息。
2.3.1。 上传站点地图
要使用 Python 上传站点地图,我们只需要指定站点 URL 和站点地图路径并运行以下代码:
网站 = '您的 GSC 财产' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().submit(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.2. 删除站点地图
硬币的另一面是当我们想要删除站点地图时。 我们还可以使用 Python 使用“删除”方法而不是“提交”方法从 Google Search Console 中删除站点地图。
网站 = '您的 GSC 财产' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().delete(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.3。 从站点地图请求信息
最后,我们还可以使用“get”方法从站点地图请求信息。
网站 = '您的 GSC 财产' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().get(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
这将返回 JSON 格式的响应,例如: 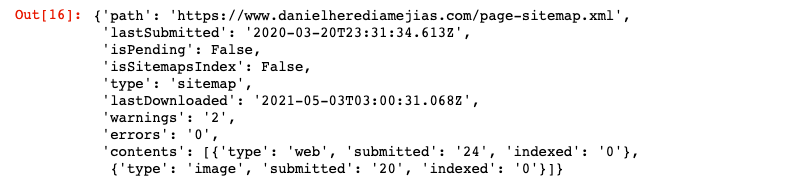
3. 内部链接分析和机会
拥有适当的内部链接结构对于促进搜索引擎机器人抓取您的网站非常有帮助。 通过审核许多具有非常复杂的技术设置的网站,我遇到的一些主要问题是:
- 通过点击事件引入的链接:简而言之,Googlebot 不会点击按钮,因此如果您的链接是通过点击事件插入的,Googlebot 将无法跟踪它们。
- 客户端渲染链接:尽管 Googlebot 和其他搜索引擎在执行 JavaScript 方面变得越来越好,但这对他们来说仍然是相当具有挑战性的,因此最好在服务器端渲染这些链接并将它们提供为原始 HTML 以搜索引擎机器人比期望它们执行 JavaScript 脚本。
- 登录和/或年龄限制弹出窗口:登录弹出窗口和年龄限制可以防止搜索引擎机器人抓取这些“障碍”背后的内容。
- Nofollow 属性过度使用:使用许多指向有价值的内部页面的 nofollow 属性将阻止搜索引擎机器人抓取它们。
- Noindex 和 follow:从技术上讲,noindex 和 follow 指令的组合应该让搜索引擎机器人抓取该页面上的链接。 但是,Googlebot 似乎会在一段时间后停止使用 noindex 指令抓取这些页面。
使用 Python,我们可以分析我们的内部链接结构,并在批量模式下找到新的内部链接机会。
3.1。 使用 Python 进行内部链接分析
几个月前,我写了一篇关于如何使用 Python 和库 Networkx 来创建图形,以非常直观的方式显示内部链接结构的文章:
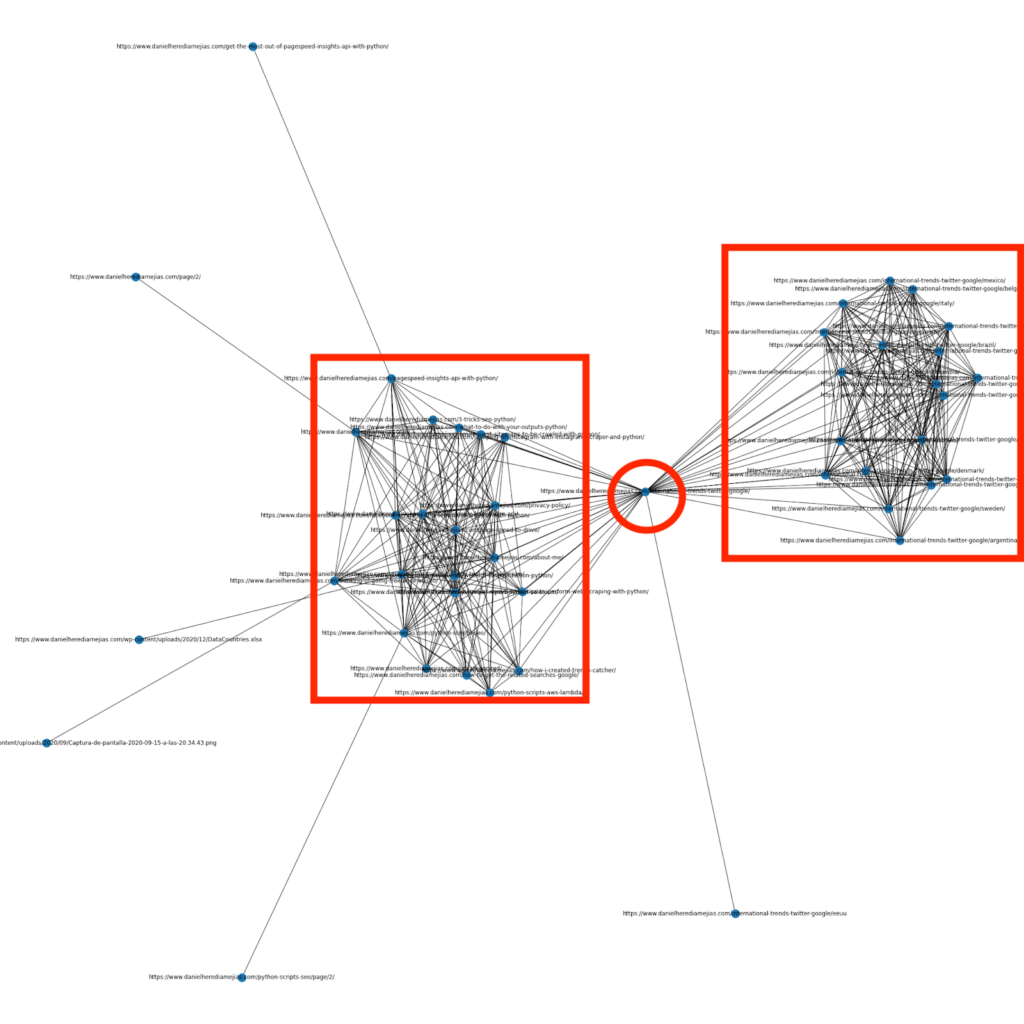
这与您可以从 Screaming Frog 获得的内容非常相似,但使用 Python 进行此类分析的优势在于,基本上您可以选择要包含在这些图表中的数据并控制大多数图表元素,例如作为颜色、节点大小甚至是您想要添加的页面。
3.2. 使用 Python 寻找新的内部链接机会
除了分析站点结构外,您还可以利用 Python 通过提供许多关键字和 URL 并遍历这些 URL 来查找新的内部链接机会,以在其内容片段中搜索提供的术语。
这可以很好地与 Semrush 或 Ahrefs 导出一起使用,以便从一些已经为关键字排名的页面中找到强大的上下文内部链接,因此已经具有某种类型的权限。
您可以在此处阅读有关此方法的更多信息。
4. 网站速度、5xx 和软错误页面
正如 Google 在此页面上关于抓取预算对 Google 的意义所述,让您的网站更快可以改善用户体验并提高抓取速度。 另一方面,还有其他可能影响抓取预算的因素,例如软错误页面、低质量内容和现场重复内容。
4.1。 页面速度和 Python
4.2.1 用 Python 分析你的网站速度
Page Speed Insights API 非常有用,可以分析您的网站在页面速度方面的表现,并获取有关许多不同页面速度指标(近 50 个)以及 Core Web Vitals 的大量数据。
使用 Python 使用 Page Speed Insights 非常简单,只需一个 API 密钥和请求即可使用它。 例如:
导入 urllib.request, json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" #注意,您可以插入带有参数 URL 的 URL,如果您想获取桌面数据,还可以修改设备参数。 响应 = urllib.request.urlopen(url) 数据 = json.loads(response.read())
此外,您还可以使用 Python 和 Lighthouse 评分计算器预测在进行请求的更改以提高页面速度的情况下,您的整体性能得分会提高多少,如本文所述。
4.2.2 使用 Python 进行图像优化和调整大小
与网站速度相关,Python 还可用于优化、压缩和调整图像大小,如 Koray Tugberk 和 Greg Bernhardt 撰写的这些文章中所述:
- 通过 FTP 使用 Python 自动进行图像压缩。
- 使用 Python 批量调整图像大小。
- 通过 Python 为 SEO 和 UX 优化图像。
4.2. 使用 Python 提取 5xx 和其他响应代码错误
5xx 响应代码错误可能表明您的服务器速度不够快,无法处理接收到的所有请求。 这会对您的抓取速度产生非常负面的影响,并且还会损害用户体验。
为了确保您的网站按预期运行,您可以使用 Python 和 Selenium 自动下载爬网统计报告,并且您可以密切关注您的日志文件。
4.3. 使用 Python 提取软错误页面
最近,Jose Luis Hernando 发表了一篇文章以纪念 Hamlet Batista,介绍如何使用 Node.js 自动提取覆盖率报告。 这可能是提取软错误页面甚至 5xx 响应错误的绝佳解决方案,这些错误可能会对您的抓取速度产生负面影响。
我们还可以使用 Python 复制相同的过程,以便仅在一个 Excel 选项卡中编译 Google Search Console 提供的所有错误、有效但有警告、有效和排除的 URL。
首先,我们需要使用 Python 和 Selenium 登录 Google Search Console,如本文前面所述。 之后,我们将选择所有 URL 状态框,每页最多添加 100 行,我们将开始迭代 GSC 报告的所有类型的 URL 并下载每个 Excel 文件。
进口时间
从硒导入网络驱动程序
从 webdriver_manager.chrome 导入 ChromeDriverManager
从 selenium.webdriver.common.keys 导入密钥
驱动程序 = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
时间.sleep(5)
searchBox=driver.find_element_by_xpath('//*[@]')
searchBox.send_keys("<你的邮箱地址>")
searchBox.send_keys(Keys.ENTER)
时间.sleep(5)
searchBox=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
searchBox.send_keys("<你的密码>")
searchBox.send_keys(Keys.ENTER)
时间.sleep(5)
yourdomain = str(input("在此处插入您的 http 属性或域。如果是域包括:'sc-domain':"))
driver.get('https://search.google.com/search-console/index?resource_https://search.google.com/search-console/index?resource_Tabla')
listvalues = [list_problems[x] for i in range(len(df1["URL"]))]
df1['Type'] = 列表值
list_results = df1.values.tolist()
别的:
df2 = pd.read_excel(yourdomain.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Coverage-Drilldown-" + 今天 + " (" + str(x) + ").xlsx", 'Tabla')
listvalues = [list_problems[x] for i in range(len(df2["URL"]))]
df2['Type'] = 列表值
list_results = list_results + df2.values.tolist()
df = pd.DataFrame(list_results, columns= ["URL","TimeStamp", "Type"])
df.to_csv('<文件名>.csv', header=True, index=False, encoding = "utf-8")
最终输出如下所示: 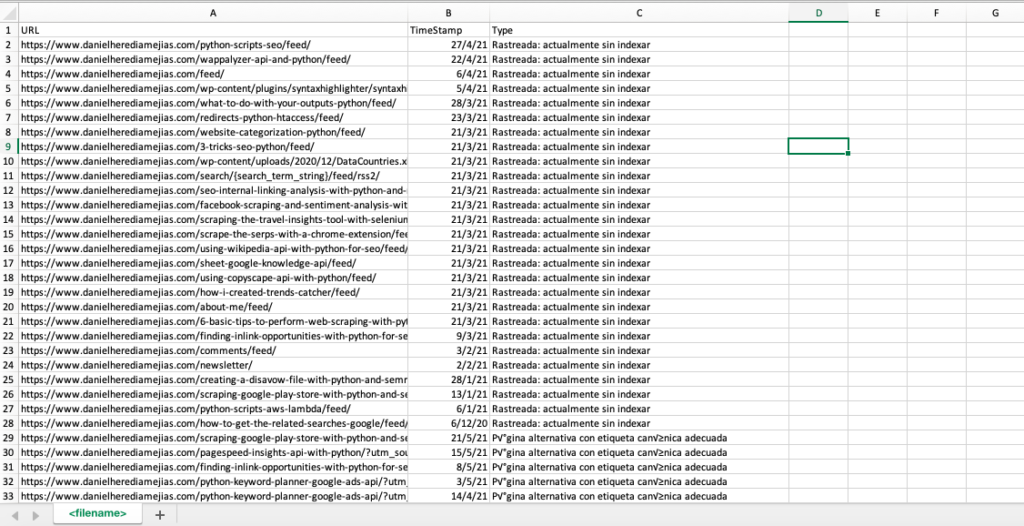
4.4. 使用 Python 进行日志文件分析
除了 Google Search Console 的抓取统计报告中提供的数据外,您还可以使用 Python 分析您自己的文件,以获取有关搜索引擎机器人如何抓取您的网站的更多信息。 如果您还没有使用 SEO 日志分析器,您可以阅读 SEO Garden 的这篇文章,其中解释了使用 Python 进行日志分析。
[电子书] 利用 SEO 日志分析的四个用例
免费下载5. 最终结论
我们已经看到,Python 可以成为以多种不同方式分析和改进我们网站的抓取和索引的重要资产。 我们还了解了如何通过自动化大多数需要数千小时时间的繁琐和手动任务来让生活变得更轻松。
我必须说,不幸的是,我并不完全相信谷歌目前提供的请求为大量 URL 建立索引的解决方案,尽管我可以在一定程度上理解它对提供更好解决方案的恐惧:许多 SEO 可能倾向于过度使用它。
与此相反,Bing 提供了卓越而便捷的解决方案,可通过 API 甚至通过 Bing Webmaster Tools 上的普通界面请求 URL 索引。
由于 Google 索引 API 有改进的空间,因此其他元素(例如拥有可访问和更新的站点地图、内部链接、页面速度、软错误页面以及重复和低质量的内容)变得更加重要,以确保您的网站已被正确抓取,并且您最重要的页面已被编入索引。