
10 个常见的技术 SEO 问题——以及如何发现它们
已发表: 2019-06-04在跨多个行业开展 SEO 服务后,有时您能够解决常见问题,尤其是在使用 WordPress、Shopify 或 SquareSpace 等常见 CMS 时。
在这里,我概述了优化网站时可能遇到的 10 个非常常见的技术 SEO 问题。
我并不是说这些问题肯定会给您或您的客户带来问题——通常情况下背景仍然非常重要。 并不总是有一种万能的解决方案,但对下面概述的情况保持警惕可能仍然是件好事。
1 – Robots.txt 文件阻止访问 Googlebot
这对于大多数技术 SEO 来说并不是什么新鲜事,但仍然很容易忽略检查机器人文件——不仅在运行技术审计时,而且作为定期检查。
您可以使用 Search Console(旧版本)之类的工具来查看 Google 是否存在访问问题,或者您可以尝试使用 OnCrawl 之类的工具将您的网站作为 Googlebot 抓取(只需选择他们的用户代理)。 除非您另有说明,否则 OnCrawl 将遵守 robots.txt。
导出抓取结果并与您网站上的已知页面列表进行比较,并检查是否存在抓取工具盲点。
为了表明这种情况仍然经常发生,并且在一些相当大的网站上,几周前我注意到 Pingdom 的速度测试工具在谷歌中被阻止了。
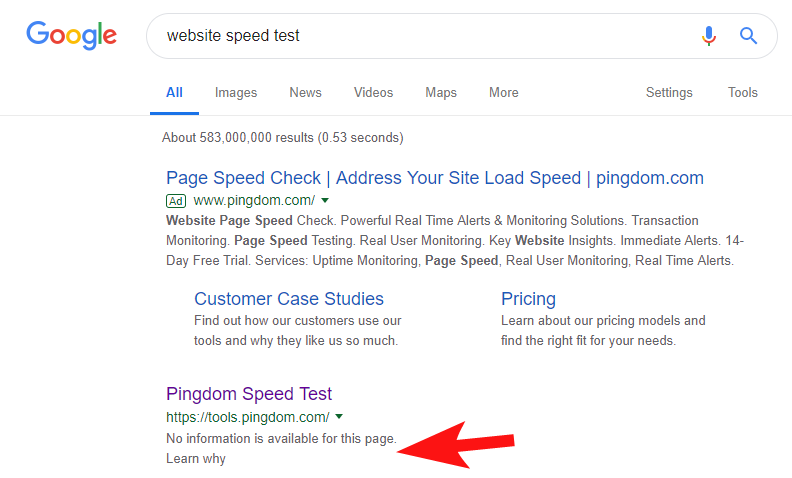
查看他们的机器人文件(并随后尝试以 Googlebot 的身份从 OnCrawl 抓取他们的页面)证实了我的怀疑,即他们阻止了对他们网站的访问。
有罪的 robots.txt 文件如下所示:

我用“FYI”联系了他们,但没有任何回应,但几天后发现一切恢复正常。 呼——我又可以轻松入睡了!
在他们的情况下,似乎每当您扫描您的网站作为他们速度审核的一部分时,它都会创建一个 URL,其中包含在上面的 robots 文件中突出显示的散列字符。
也许这些被爬网甚至以某种方式编入索引,并且他们想控制它(这很容易理解)。 在这种情况下,他们可能没有完全测试潜在的影响——这最终可能是微乎其微的。
这是他们目前的机器人,供任何感兴趣的人使用。

值得注意的是,在某些情况下,您可以使用 Internet Wayback Machine 访问历史 robots.txt 文件更改。 根据我的经验,这在你可以想象的更大的网站上效果最好——它们更经常被 Wayback Machine 的存档器抓取。
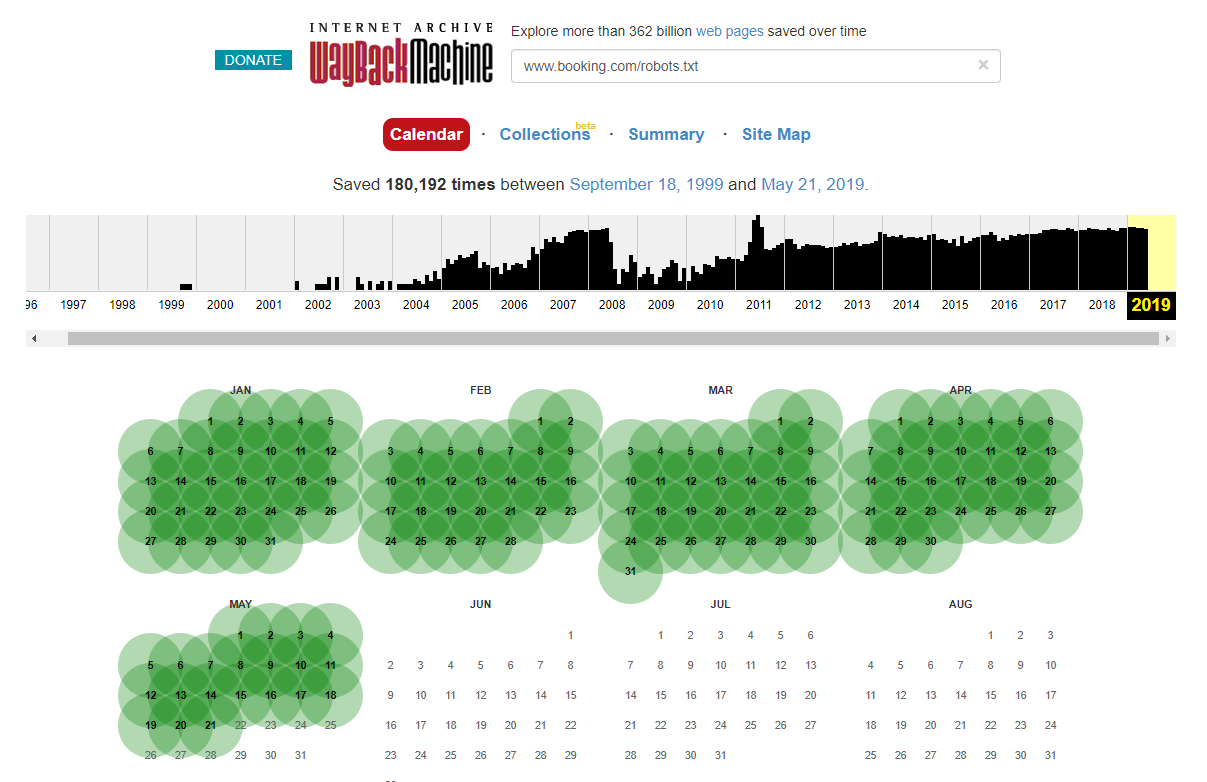
这不是我第一次在野外看到实时 robots.txt 对 SERPS 造成一些破坏。 它绝对不会是最后一个——这是一件很容易被忽视的事情(毕竟它实际上是一个文件),但检查它应该是每个 SEO 正在进行的工作计划的一部分。
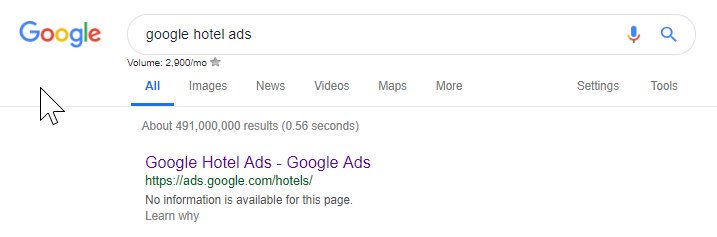
从上面你可以看到,即使是谷歌有时也会弄乱他们的机器人文件,阻止他们自己访问他们的内容。 这可能是故意的,但看看下面他们的机器人文件的语言,我有点怀疑。
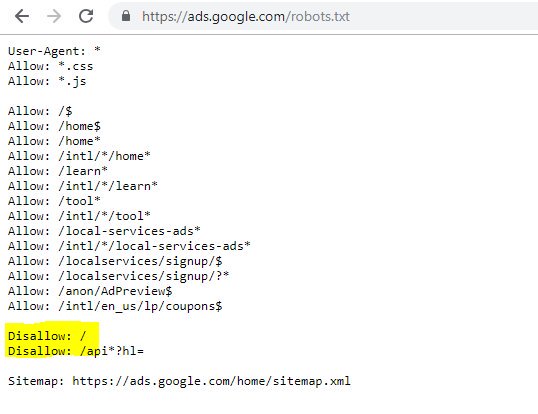
突出显示的 Disallow: / 在这种情况下阻止了对任何 URL 路径的访问; 列出不应该被抓取的网站的特定部分会更安全。
2 – DNS 级别的域配置问题
这是一个令人惊讶的常见问题,但通常它是一个快速修复。 这是技术 SEO 所钟爱的低成本、*可能*具有高影响力的 SEO 变化之一。
通常使用 SSL 实现我看不到正确配置的非 WWW 域版本,例如 302 重定向到下一个 URL 并形成链,或者根本不加载的最坏情况。
酒店足球网站就是一个很好的例子。
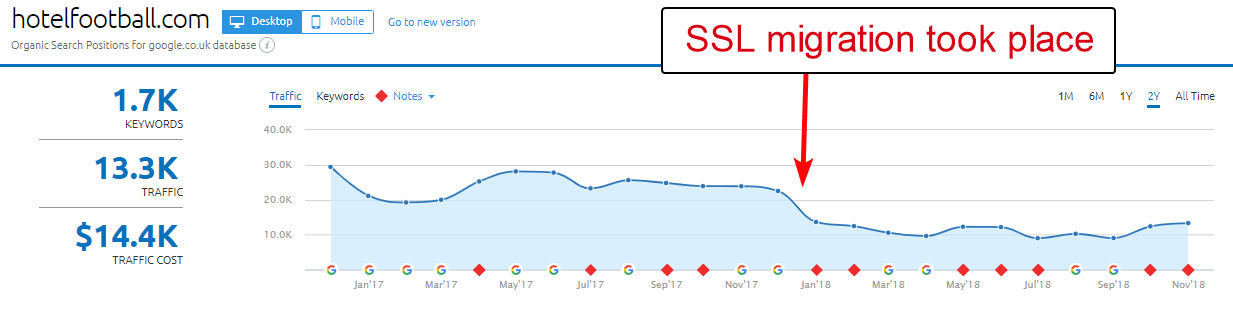
他们去年初进行了 SSL 迁移,从上面 SEMRush 的域概述报告来看,这对他们来说并不是那么好。
不久前我注意到了这一点,因为我在旅游和酒店业工作了很多 - 并且由于对足球的热爱,我很想看看他们的网站是什么样的(当然还有它是如何有机地运作的! )。
这实际上很容易诊断——该网站有大量非常好的反向链接,都指向非 SSL 的 WWW 域 http://www.hotelfootball.com/
如果您尝试访问上面的那个 URL,它不会加载。 哎呀。 至少,这种情况已经持续了大约 18 个月。 我确实通过 Twitter 联系了管理该网站的机构,让他们知道这件事,但没有任何回应。
有了这个,他们需要做的就是确保 DNS 区域设置正确,并为“WWW”版本的域设置一个“A”记录,该记录指向正确的 IP 地址(CNAME 也可以)。 这将防止域无法解析。
唯一的缺点,或者说这个问题需要这么长时间才能解决的原因,是访问站点的域管理面板可能很棘手,甚至密码已经丢失,或者它不被视为高优先级。
向持有域名密钥的非技术人员发送修复指令也不总是一个好主意。
如果/当他们能够进行上述调整时,我非常希望看到有机影响——特别是考虑到自前曼联足球运动员加里·内维尔、瑞恩·吉格斯推出酒店以来非 WWW 域已经建立的所有反向链接和公司。
虽然他们的酒店名称确实在 Google 中排名第一(正如您想象的那样),但对于任何更具竞争力的非品牌搜索词来说,他们似乎根本没有强大的排名(他们目前在第 10 位在 Google 上搜索“老特拉福德附近的酒店”)。
他们在上述情况下打进了一点乌龙球——但解决这个问题可能至少在某种程度上解决了这个问题。
Oncrawl 搜索引擎优化爬虫
 学到更多
学到更多3 – XML 站点地图中的恶意页面
同样,这是一个非常基本的页面,但它很常见 - 在查看站点 XML 站点地图时(几乎总是在 domain.com/sitemap.xml 或 domain.com/sitemap_index.xml,这里列出的页面可能确实没有'没有任何需要被索引。
典型的罪魁祸首包括隐藏的感谢页面(感谢您提交联系表格)、可能导致重复内容问题的 PPC 登录页面,或您已经在其他地方没有索引的其他形式的页面/帖子/分类法。
将它们再次包含在 XML 站点地图中可能会向搜索引擎发送相互冲突的信号——您实际上应该只列出您希望它们查找和索引的页面,这主要是站点地图的重点。
您现在可以使用 Search Console 中的便捷报告,通过“检查 URL”选项确定页面是否已包含在站点 XML 站点地图中。
如果您有一个相当小的站点,您可能只需在浏览器中手动查看您的 XML 站点地图 - 否则下载它并将其与可索引 URL 的完整爬网进行比较。
通常,您可以通过在 Google 中进行 site:domain.com 搜索以返回所有已编入索引的内容,从而捕捉到这种低质量、无价的内容。
在这里值得注意的是,这可能包含旧内容,不应该依赖于 100% 最新,但这是一个简单的检查,以确保没有大量的内容使您的 SEO 工作膨胀并消耗爬网预算。
4 – Googlebot 呈现内容的问题
这个值得一整篇专门介绍它的文章,我个人觉得我已经花了一生的时间在玩 Google 的 fetch 和 render 工具。
一些非常有能力的 SEO 已经对此(以及关于 JavaScript)说了很多,所以我不会深入研究这个问题,但检查 Googlebot 如何呈现您的网站总是值得您花时间的。
通过在线工具运行一些检查有助于发现 Googlebot 盲点(网站上他们无法访问的区域)、托管环境问题、有问题的 JavaScript 烧毁资源,甚至是屏幕缩放问题。
通常,这些第三方工具在诊断问题方面非常有帮助(例如,Google 甚至会告诉您资源何时因您的 robots 文件而被阻止),但有时您可能会发现自己在绕圈子。
为了展示一个有问题的网站的实时示例,我将在脚下开枪并参考我自己的个人网站——以及我正在使用的一个特别令人沮丧的 WordPress 主题。
有时,从 Search Console 运行 URL 检查时,我会收到“页面不适合移动设备”警告(见下文)。
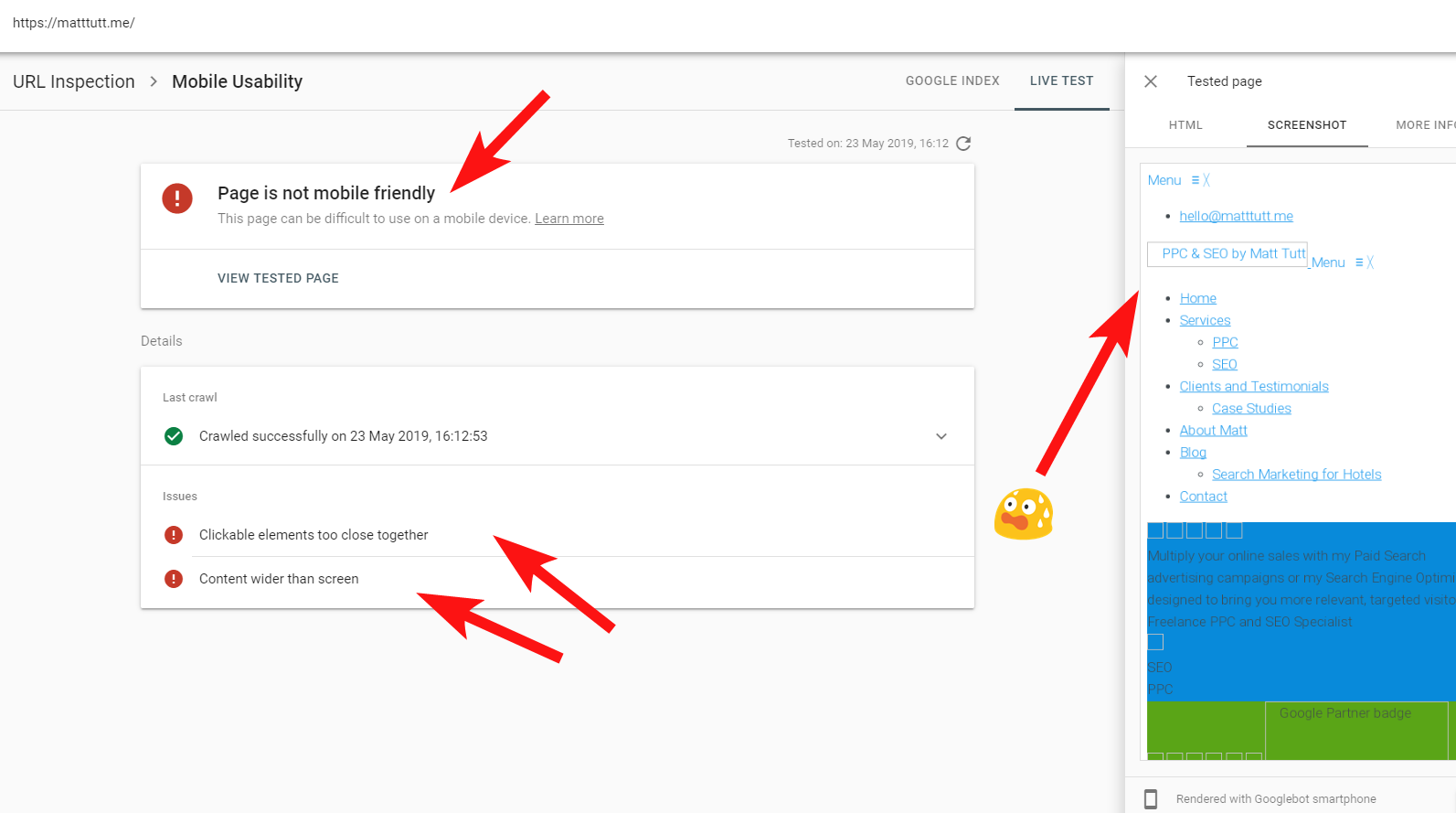
通过单击更多信息选项卡(右上角),它会列出 Googlebot 无法访问的资源列表,主要是 CSS 和图像文件。
这很可能是因为 Googlebot 无法始终将全部“精力”投入到渲染页面中——有时是因为 Google 担心我的网站崩溃(就是这样),而其他时候我可能会因为他们使用过而受到限制已经有很多资源可以获取和呈现我的网站。
有时由于上述原因,值得在分散的时间间隔运行这些测试几次以获得更真实的故事。 我还建议您尽可能检查服务器日志,以检查 Googlebot 如何访问(或未访问)您的网站内容。
这些资源的 404 或其他不良状态显然是一个不好的迹象,特别是如果它是一致的。
就我而言,谷歌称该网站不适合移动设备,这主要是由于某些 CSS 样式文件在渲染过程中失败,这可以正确地敲响警钟。
更令人困惑的是,在运行 Google 的移动设备友好测试时,或使用任何其他第三方工具时,都没有检测到问题:该网站是移动设备友好的。
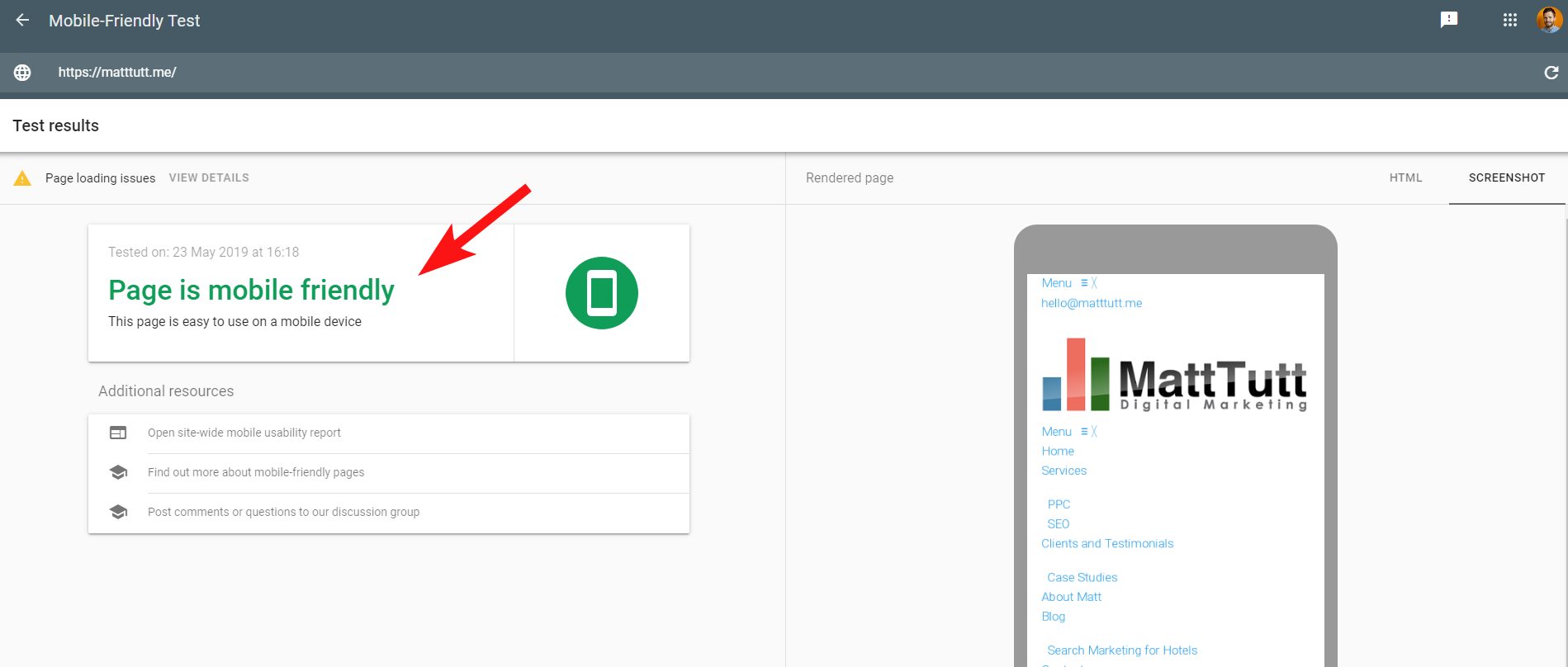
来自 Google 的这些相互冲突的消息对于 SEO 和 Web 开发人员来说可能很难解码。 为了进一步了解,我联系了 John Mueller,他建议我检查我的网络主机(没有问题),并且 CSS 文件确实可以被 Google 缓存。
与移动友好工具相比,Search Console 使用较旧的 Web 渲染服务 (WRS),因此现在我倾向于更加重视后者。
随着 Google 宣布推出具有最新渲染功能的更新的 Googlebot,这一切都可能发生变化,因此有必要及时了解哪些工具最适合用于渲染检查。
另一个提示——如果你想看到一个完整的可滚动的页面渲染,你可以从谷歌的移动测试工具切换到 HTML 标签,点击 CTRL+A 突出显示所有渲染的 HTML 代码,然后复制并粘贴到文本编辑器中另存为 HTML 文件。
在浏览器中打开它(手指交叉,有时这取决于使用的 CMS!)会给你一个可滚动的渲染。 这样做的好处是您可以检查任何网站的呈现方式——您不需要访问 Search Console。
5 – 被黑网站和垃圾邮件反向链接
这是一个非常有趣的发现,并且经常可以在运行在旧版本 WordPress 或其他需要定期安全更新的 CMS 平台上的网站上偷偷摸摸。
对于这个客户端(美容水疗中心),我注意到 Search Console 中出现了一些奇怪的搜索字词。
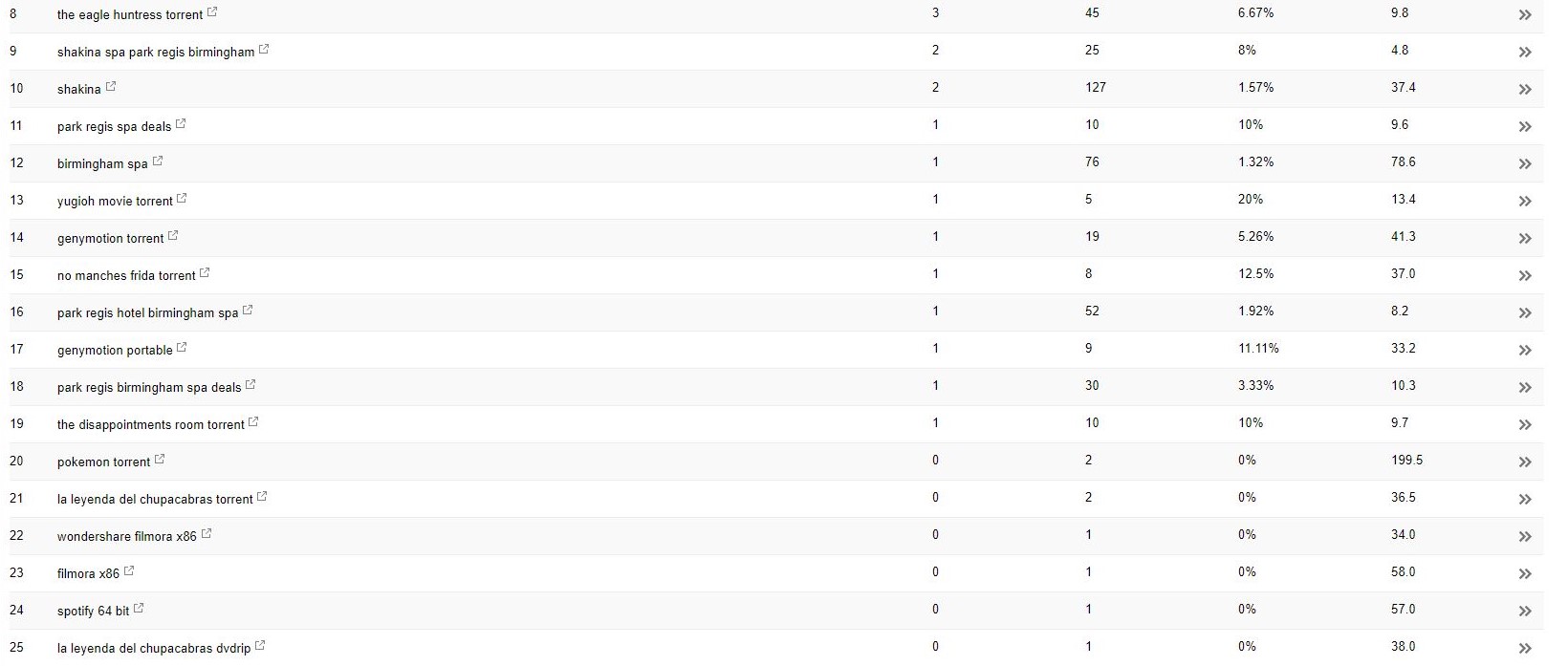
令人惊讶的是,他们不仅在 Search Console 中获得了展示次数,而且还获得了点击次数——这意味着必须在域中编入索引。
从查询来看,这显然是非常垃圾的,而不是客户希望与他们的业务相关联的东西。
在 Google 中进行简单的“site:domain.com”搜索,发现了数百页假定的种子文件,这些文件据称是客户托管在其网站上的。
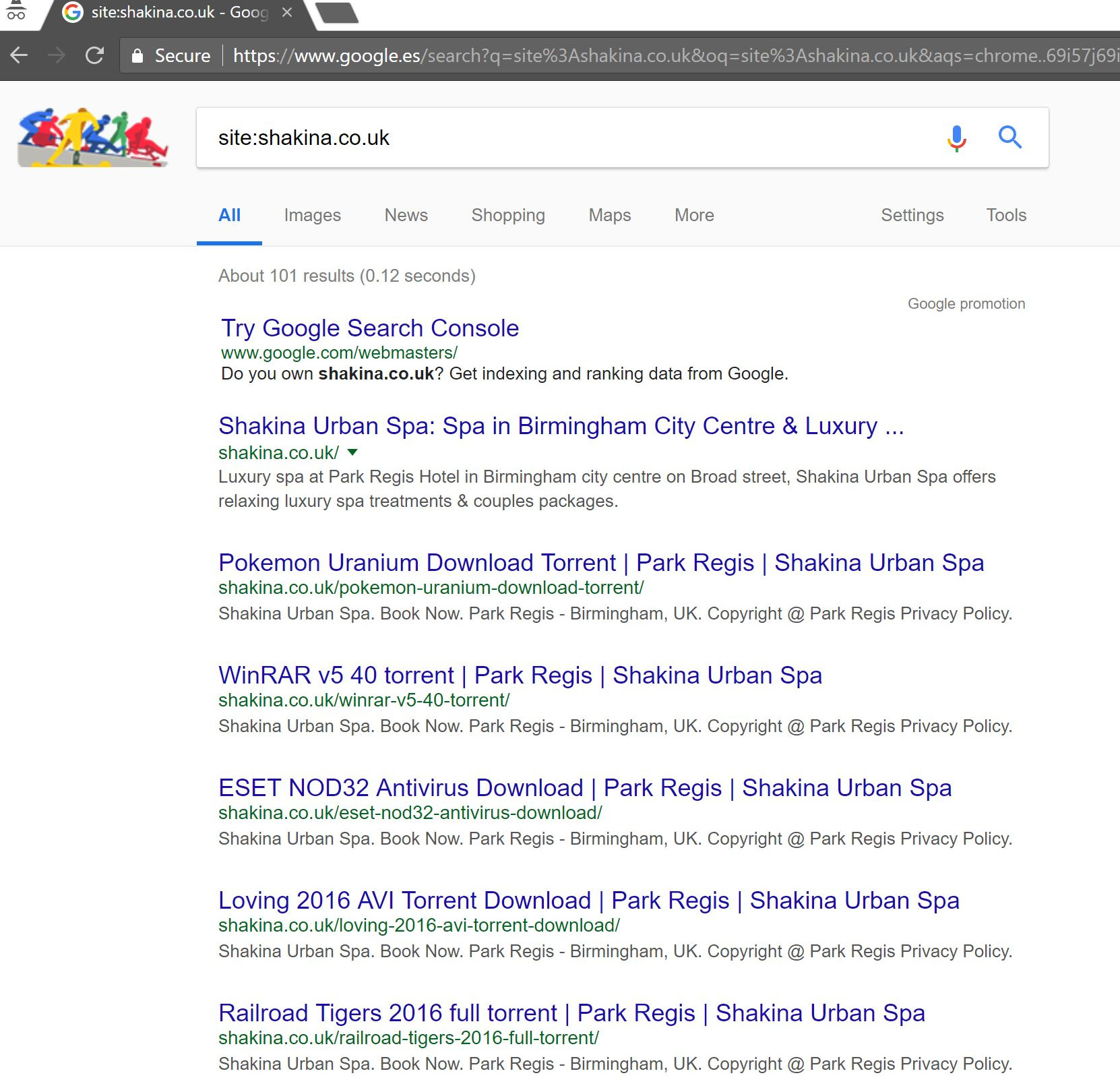
访问这些 URL 中的任何一个实际上都会导致 404——但它们仍然被编入索引(我还检查了各种用户代理,它们都得到了相同的 404 错误)。

接下来,我通过 Majestic 的反向链接检查器运行该域,它给出了一个长长的列表,其中包含指向客户网站上这些页面的质量非常低的反向链接——这可能有助于将它们编入索引。
查看 Majestic 的反向链接锚云确实显示了问题的严重程度。

唯一的解决方法是按域拒绝所有这些反向链接,然后对 WordPress 安装进行彻底清理,以清除任何代码注入,或安装新的 WordPress 副本。
如果您真的担心上述情况下的索引内容,您还可以提供 410 状态代码来真正澄清搜索爬虫的内容。
上述内容适用于那些因电影制片人的版权主张而受到法律警告的网站——如果问题没有迅速解决,有时可能会出现这种情况。
6 – 糟糕的国际 SEO 设置
总部设在西班牙,但用我的母语英语浏览互联网,我经常会发现自己被自动重定向到网站的西班牙语版本。
虽然我理解逻辑(我在西班牙,因此我想用西班牙语浏览网站),但从用户体验的角度来看,这很烦人,如果做得不正确,也会对您的国际 SEO 造成一些破坏。
像 Google Ads 这样的网站将这一点提升到了另一个层次——利用 Angular JavaScript 根据我的位置动态生成内容,甚至不通过任何类型的页面重定向并将内容直接加载到 DOM 中。
当有多种语言可用时,我首选的方法是根据用户的 Internet 浏览器设置 302 将用户重定向到一种语言。
因此,如果有人在 Google Chrome 中将德语作为默认语言,那么无论他们身在何处,他们都可能很乐意用德语阅读该网站。
当某人位于使用多种语言的地区时,这也有助于解决困难,例如在使用法语、意大利语、德语和罗曼什语的瑞士。
确保可以根据您的偏好切换语言的选项对于可用性目的也很关键——以防万一他们想要切换。
在一个案例中,我在巴塞罗那的一家酒店工作,在没有考虑 SEO 影响的情况下,将 JavaScript 语言重定向脚本添加到网站。
该脚本通过客户端 JavaScript 重定向根据用户的浏览器语言设置(本身还不错)重定向用户。
遗憾的是,在这种情况下,由于站点永久链接的怪异配置,脚本没有正确设置,再加上站点上所有页面都缺少 HTML lang 标记这一事实,Googlebot 有点发疯了……
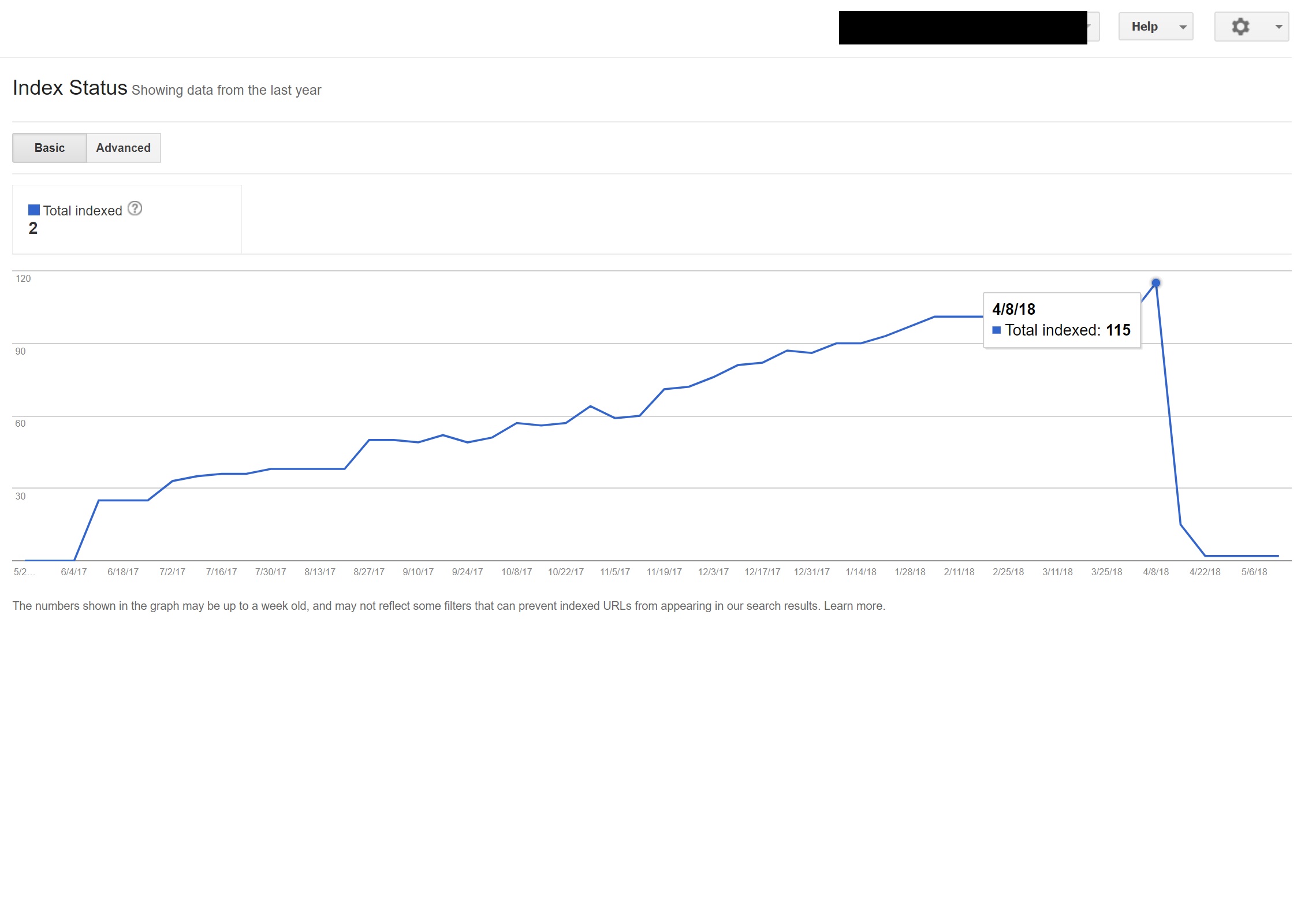
在这个例子中,几乎所有网站上的非英语内容都被谷歌取消索引,因为它被重定向到不存在的页面,从而产生多个 404 错误。
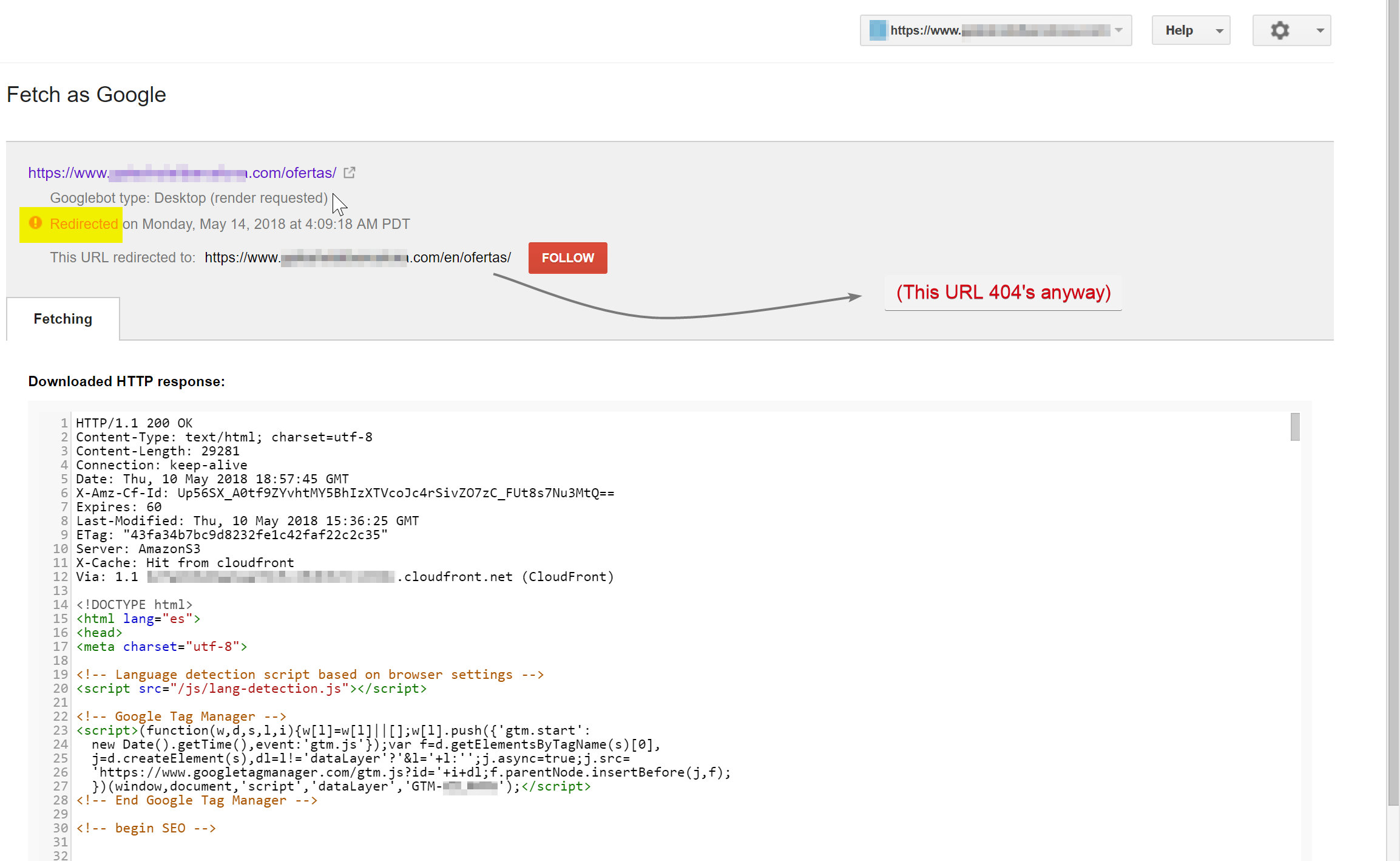
Googlebot 试图抓取西班牙语内容(存在于 hotelname.com/ofertas)并被重定向到 hotelname.com/en/ofertas——一个不存在的 URL。
令人惊讶的是,在这种情况下,Googlebot 会跟踪所有这些 JavaScript 重定向,并且由于找不到这些 URL,它被迫将它们从索引中删除。
在上述情况下,我可以通过访问该站点的服务器日志、过滤到 Googlebot 并检查它在何处获得 404 服务来确认这一点。
删除错误的 JavaScript 重定向脚本解决了这个问题,幸运的是,翻译后的页面没有长时间取消索引。
全面测试总是一个好主意——投资 VPN 可以帮助诊断这些类型的场景,甚至可以更改您在 Chrome 浏览器中的位置和/或语言。
[案例研究] 处理多个现场审核
 阅读案例研究
阅读案例研究7 – 重复内容
重复内容是一个很常见且被广泛讨论的问题,您可以通过多种方式检查网站上的重复内容——Richard Baxter 最近就该主题写了一篇很棒的文章。
就我而言,这个问题可能要简单一些。 我经常看到网站发布很棒的内容,通常是作为博客文章,但随后几乎立即在 Medium.com 等第 3 方网站上分享了一些内容。
Medium 是一个很好的网站,可以重新利用现有内容以覆盖更广泛的受众,但应注意如何处理。
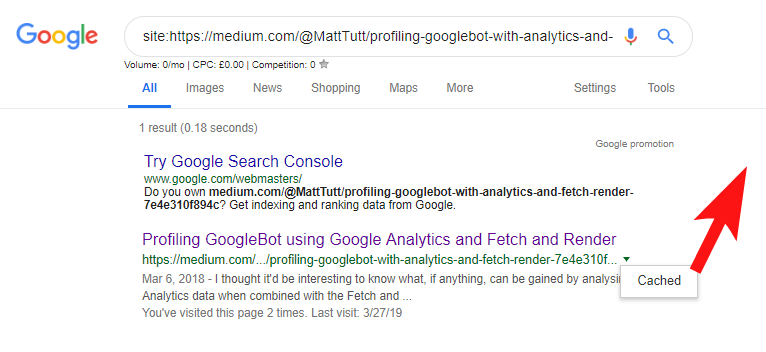
将内容从 WordPress 导入到 Medium 时,在此过程中,Medium 将使用您的网站 URL 作为其规范标签。 因此,从理论上讲,它应该有助于为您的网站提供内容的信誉,作为原始来源。
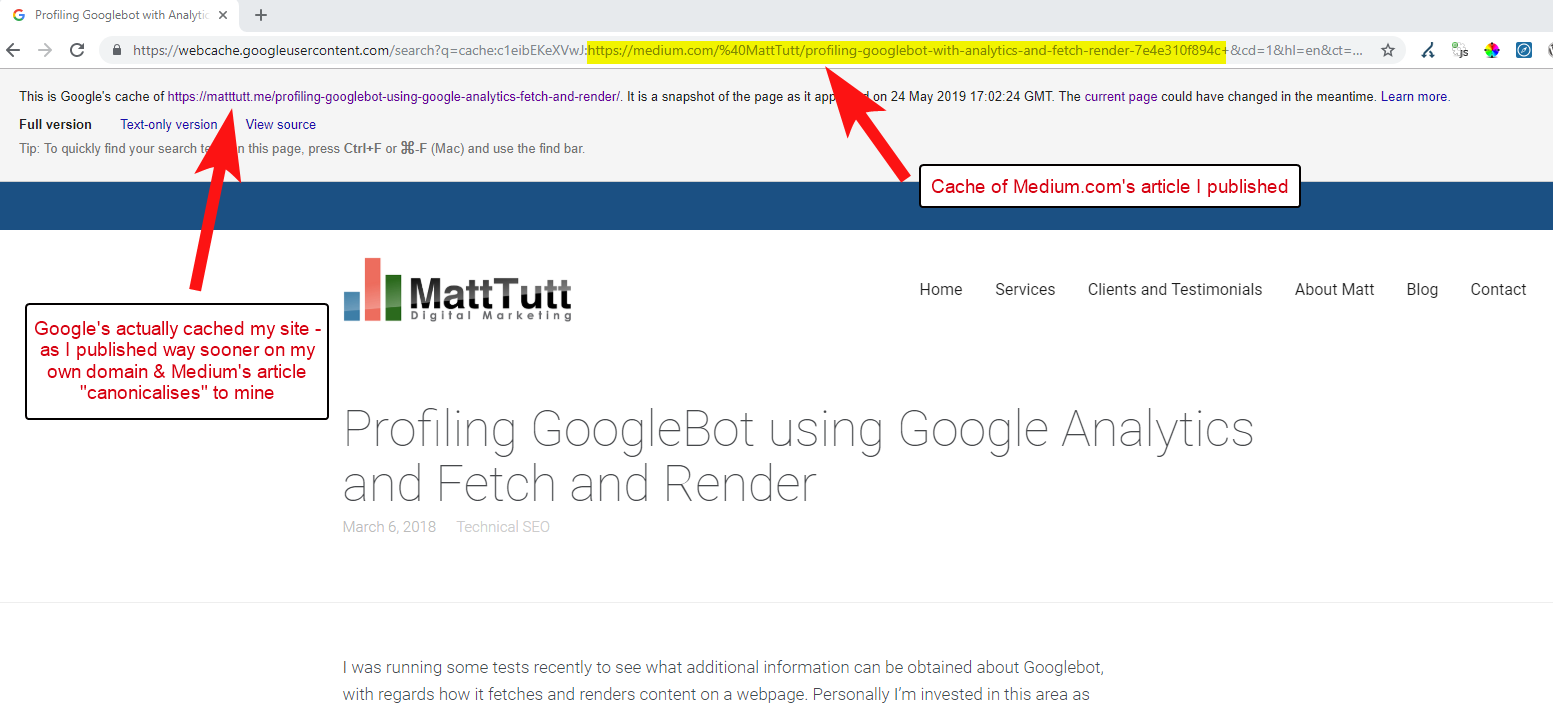
从我的一些分析来看,虽然它并不总是这样工作。
我相信是这样的,因为当一篇文章在 Medium 上发布而没有先让 Google 有时间在你的域中抓取和索引文章时,如果文章在 Medium 上表现良好(有点命中或错过),你的内容就会得到索引并与 Medium 的站点相关联,尽管它们的规范指向您的站点。
一旦内容被添加到 Medium(特别是如果它很受欢迎),您几乎可以保证该作品几乎会立即被抓取并重新发布到其他地方的网络上——因此您的内容再次被复制到其他地方。
虽然这一切都在发生,但如果您的域在权限方面非常小,Google 甚至可能没有机会抓取和索引您发布的内容 - 甚至可能是抓取/索引尚未完成,或者有大量的 JavaScript 导致内容的抓取、呈现和索引之间存在很大的时间延迟。
我见过这样的情况,一家大公司发表了一篇很棒的文章,但第二天他们把它作为一篇思想文章发表在一个庞大的行业新闻博客上。 最重要的是,他们的网站存在内容在 https://domain.com 和 https://www.domain.com 上被复制(和索引)的问题。
发表几天后,当在谷歌内搜索引用文章的确切短语时,公司网站无处可寻。 取而代之的是,权威的行业博客位居榜首,其他重新发布者占据了下一个位置。
在这种情况下,内容已与行业博客相关联,因此该作品获得的任何链接都将使该网站受益 - 而不是原始发布者。
如果您要在网络上的任何地方重新利用内容,它可能会被编入索引,那么您真的应该等到您完全确定它已被 Google 在您自己的域中编入索引。
您可能会努力创建和制作您的内容 - 不要因为太热衷于在其他地方重新发布而将其全部丢弃!
8 – 错误的 AMP 配置(缺少 AMP URL 声明)
只有少数我协助过的客户选择尝试使用 AMP,这可能是基于 Google 资助的关于其使用的许多案例研究中的一些。
有时我什至根本不知道客户拥有他们网站的 AMP 版本——在 Analytics 推荐报告中出现了一些奇怪的流量——其中 AMP 版本的网站链接回了非 AMP 网站版本。
在这种情况下,AMP 页面版本配置不正确,因为非 AMP 页面的头部没有 URL 引用。

如果不告诉搜索引擎某个 AMP 页面存在于特定 URL,那么设置 AMP 没有多大意义——关键是它会被索引并在 SERPS 中为移动用户返回。
添加对非 AMP 页面的引用是向 Google 告知 AMP 页面的重要方式,重要的是要记住 AMP 页面上的规范标签不应该是自引用的:它们链接回非 AMP 页面。
虽然不是真正的技术 SEO 考虑因素,但值得注意的是,如果您希望能够报告任何流量和用户行为信息,您仍然需要在 AMP 页面上包含跟踪代码。
通常,作为我的 SEO 审核的一部分,我也喜欢对分析实施进行一些基本检查——否则你提供的数据实际上可能并没有那么有用,特别是如果有一个坚固的分析设置。
9 – 302 重定向或形成重定向链的传统域
在与美国的一个大型独立酒店品牌合作时,该品牌在过去几年经历了多次品牌重塑(在酒店业中很常见),监控之前的域名请求的行为非常重要。
这很容易忘记,但它可能是一个简单的半定期检查,尝试使用 OnCrawl 之类的工具抓取他们的旧网站,甚至是检查状态代码和重定向的第三方网站。
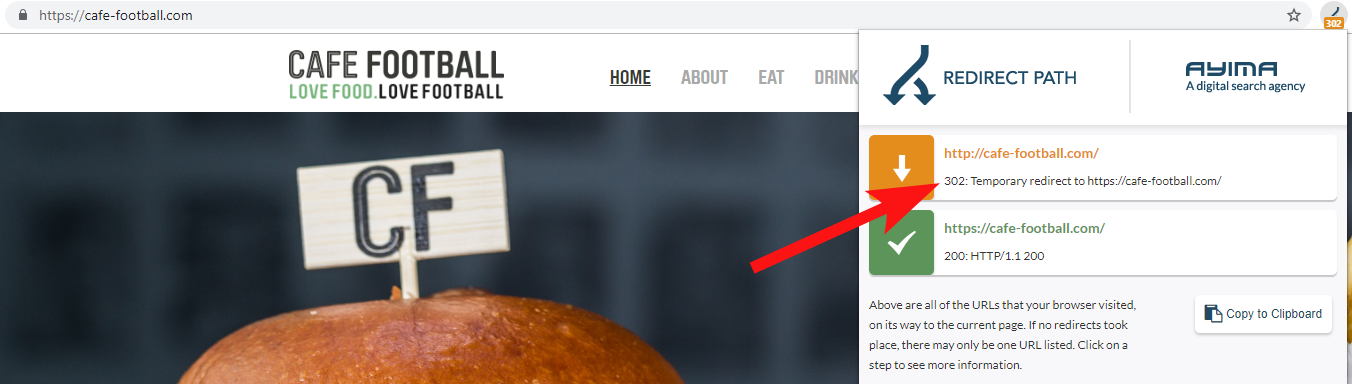
通常情况下,您会发现域 302 重定向到最终目的地(301 始终是这里的最佳选择)或 302 重定向到 URL 的非 WWW 版本,然后再跳转几个重定向,然后到达最终 URL。
谷歌的约翰·穆勒(John Mueller)之前曾表示,他们在放弃之前只遵循 5 次重定向,而众所周知,每次通过重定向都会丢失一些链接值。 出于这些原因,我更喜欢坚持尽可能干净的 301 重定向。
Ayima 的 Redirect Path 是一款出色的 Chrome 浏览器扩展程序,可在您浏览网页时显示重定向状态。
我检测到属于客户的旧域名的另一种方法是在 Google 上搜索他们的电话号码,使用完全匹配的引号或部分地址。
像酒店这样的企业不会经常更改地址(至少是其中的一部分),您可能会发现链接到旧域的旧目录/企业配置文件。
使用 Majestic 或 Ahrefs 之类的反向链接工具也可能会显示来自以前域的一些旧链接,因此这也是一个很好的停靠港 - 特别是如果您没有直接与客户联系。
10 – 糟糕地处理内部搜索内容
这实际上是我之前在 OnCrawl 上写过的一个主题——但我再次将其包括在内,因为我仍然经常看到有问题的内部内容“在野外”发生。
我开始这篇文章谈论的是 Pingdom 的 robots.txt 指令问题,从我的外部看来,这是一个防止它们输出的内容被抓取和索引的修复程序。
任何将内部搜索结果作为内容提供给 Google 的网站,或者输出大量用户生成内容的网站,都需要非常小心他们这样做的方式。
如果网站以非常直接的方式向 Google 提供内部搜索结果,那么这可能会导致某种人工处罚。 谷歌可能会认为这是一种糟糕的用户体验——他们搜索 X,然后登陆一个网站,然后他们必须手动过滤他们想要的内容。
在某些情况下,我认为提供内部内容是可以的,这取决于上下文和环境。 例如,一个工作网站可能希望提供几乎每天更新的最新工作结果——所以他们几乎必须处理这个问题。
Indeed 是一个著名的求职网站示例,它可能会走得太远,根据流行的搜索查询生成各种类型的内容(请参阅下面的内容,了解使用这种策略会发生什么)。
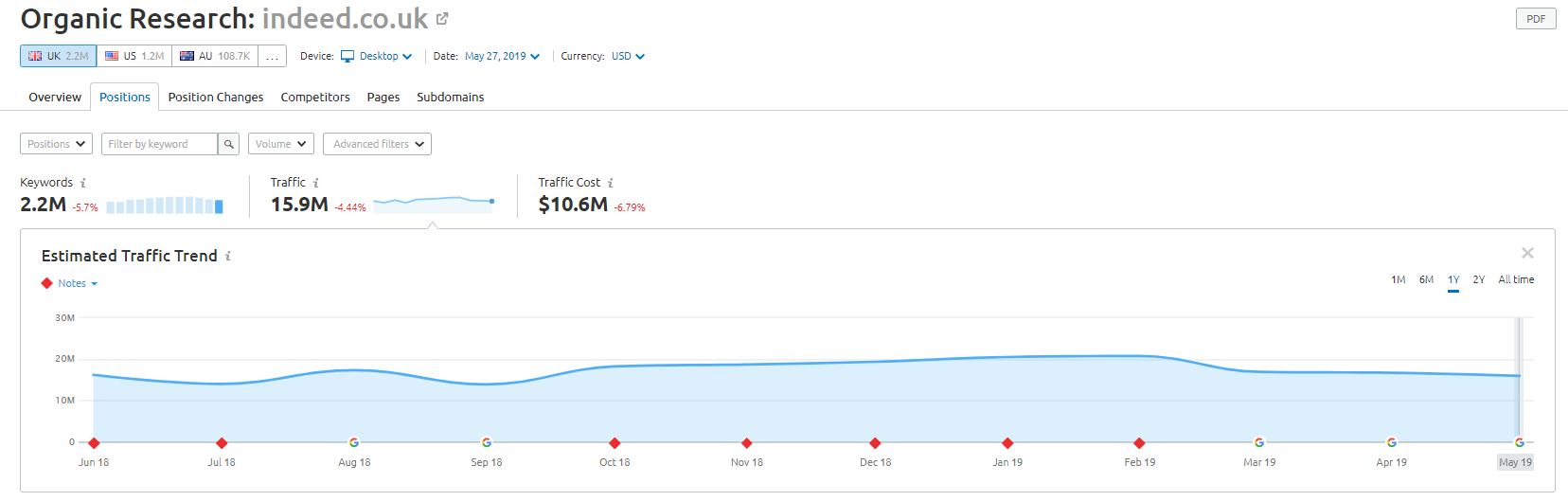
尽管如此,根据 SEMRush 的数据,他们的自然流量做得很好——但这些都是细线,这样的行为会让你面临谷歌处罚的高风险。
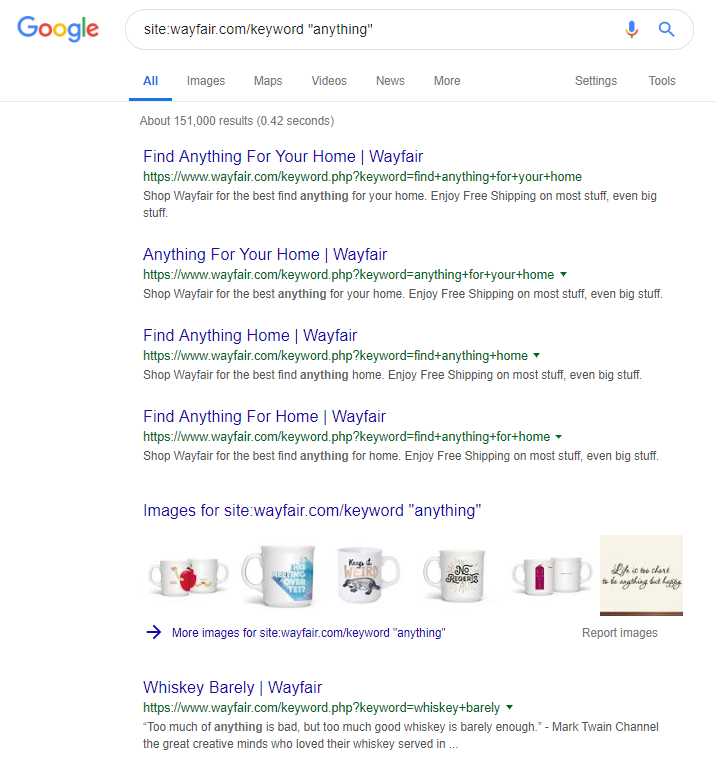
在线零售商 Wayfair.com 是另一个喜欢顺风航行的品牌。 凭借数以百万计的索引 URL(以及大量自动生成的关键字 URL),他们在自然流量方面做得很好——但他们很有可能因为以这种方式向搜索引擎提供内容而受到惩罚。
通过实施适当的站点结构,包括对所有内容进行分类、构建不同的父/子层次结构,甚至使用标签或其他自定义分类法,您可以帮助帮助客户和搜索爬虫导航。
使用上述技巧可能会在短期内获胜,但从长远来看,它不太可能对你有太大帮助。 这使得从一开始就获得网站结构的关键,或者至少提前正确规划它。
包起来
本文讨论的 10 个错误是我在现场审核中遇到的一些最常见的技术问题。
纠正您网站上的这些错误是确保您的网站在技术上健康的第一步。 一旦这些问题得到纠正,技术审核就可以专注于特定于您的站点的问题。