
基于 AWS 服务的商业智能管道 – 案例研究
已发表: 2019-05-16近年来,我们看到人们对大数据分析越来越感兴趣。 高管、经理和其他业务利益相关者使用商业智能 (BI) 来做出明智的决策。 它使他们能够立即分析关键信息,并不仅根据他们的直觉,而且根据他们可以从客户的真实行为中学到什么来做出决策。
当您决定创建一个有效且信息丰富的 BI 解决方案时,您的开发团队需要做的第一步就是规划数据管道架构。 有几种基于云的工具可用于构建这样的管道,没有一种解决方案对所有企业都是最好的。 在决定特定选项之前,您应该考虑您当前的技术堆栈、工具定价以及开发人员的技能组合。 在本文中,我将展示一个使用 AWS 工具构建的架构,该架构已成功部署为 Timesheets 应用程序的一部分。
架构概述
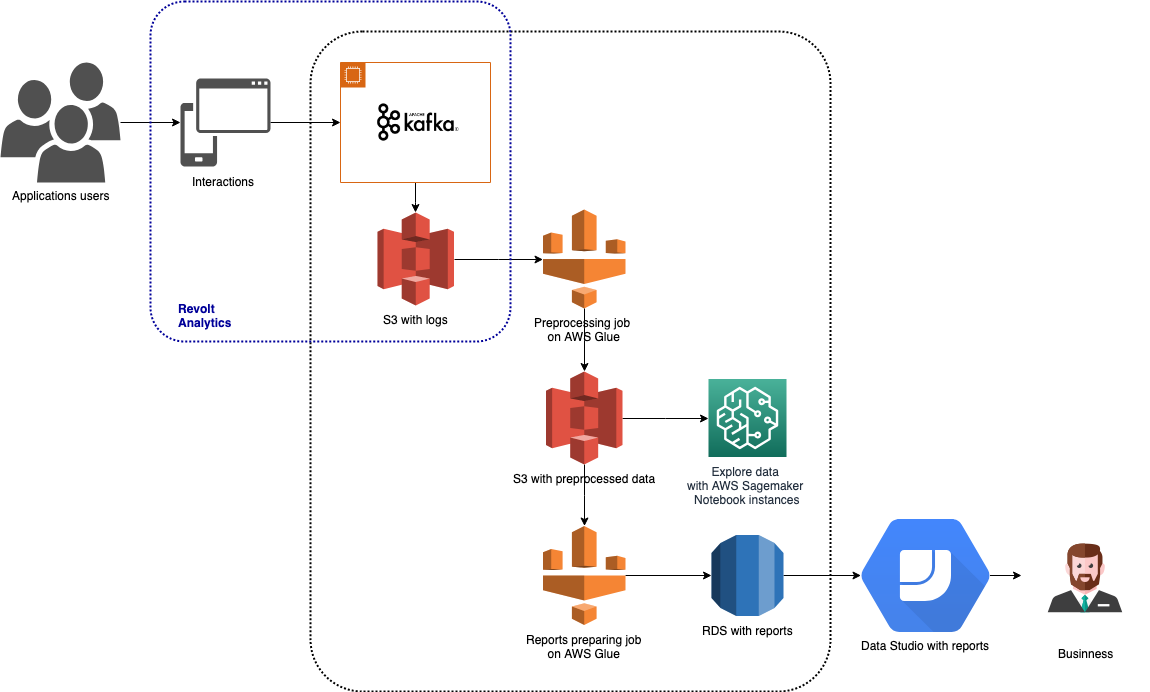
Timesheets 是一种跟踪和报告员工时间的工具。 它可以通过网络、iOS、Android 和桌面应用程序、与 Hangouts 和 Slack 集成的聊天机器人以及 Google Assistant 上的操作来使用。 由于有许多类型的应用程序可用,因此也有许多不同的数据需要跟踪。 数据通过 Revolt Analytics 收集,存储在 Amazon S3 中,并使用 AWS Glue 和 Amazon SageMaker 进行处理。 分析结果存储在 Amazon RDS 中,并用于在 Google Data Studio 中构建可视化报告。 该架构如上图所示。
在以下段落中,我将简要介绍此架构中使用的每个大数据工具。
反抗分析
Revolt Analytics 是 Miquido 开发的一种工具,用于跟踪和分析来自所有类型应用程序的数据。 为了简化客户端系统中的 Revolt 实现,已经构建了 iOS、Android、JavaScript、Go、Python 和 Java SDK。 Revolt 的关键特性之一是它的性能:所有事件都以数据包的形式排队、存储和发送,从而确保它们能够快速有效地传递。 Revolt 使应用程序所有者能够识别用户并跟踪他们在应用程序中的行为。 这使我们能够构建带来价值的机器学习模型,例如完全个性化的推荐系统和流失预测模型,以及基于用户行为的客户分析。 Revolt 还提供了会话化功能。 有关应用程序中用户路径和行为的知识可以帮助您了解客户的目标和需求。
Revolt 可以安装在您选择的任何基础设施上。 这种方法使您可以完全控制成本和跟踪事件。 在本文介绍的 Timesheets 案例中,它是基于 AWS 基础设施构建的。 由于对数据存储的完全访问权限,产品所有者可以轻松深入了解他们的应用程序并在其他系统中使用该数据。
Revolt SDK 被添加到 Timesheets 系统的每个组件中,其中包括:
- Android 和 iOS 应用程序(使用 Flutter 构建)
- 桌面应用程序(使用 Electron 构建)
- Web 应用程序(用 React 编写)
- 后端(用 Golang 编写)
- 环聊和 Slack 在线聊天
- 对 Google 助理的操作
Revolt 为 Timesheets 管理员提供有关应用程序客户使用的设备(例如设备品牌、型号)和系统(例如操作系统版本、语言、时区)的知识。 此外,它还会发送与用户在应用程序中的活动相关的各种自定义事件。 因此,管理员可以分析用户行为,并更好地了解他们的目标和期望。 他们还可以验证实现的功能的可用性,并评估这些功能是否符合产品负责人关于如何使用它们的假设。

AWS 胶水
AWS Glue 是一项 ETL(提取、转换和加载)服务,可帮助为分析任务准备数据。 它在 Apache Spark 无服务器环境中运行 ETL 作业。 通常,它由以下三个要素组成:
- 爬虫定义——爬虫用于扫描各种存储库和源中的数据,对其进行分类,从中提取模式信息,并将有关它们的元数据存储在数据目录中。 例如,它可以扫描存储在 Amazon S3 上 JSON 文件中的日志,并将其架构信息存储在数据目录中。
- 作业脚本– AWS Glue 作业将数据转换为所需的格式。 AWS Glue 可以自动生成脚本来加载、清理和转换您的数据。 您还可以提供自己用 Python 或 Scala 编写的 Apache Spark 脚本,以运行所需的转换。 它们可能包括处理空值、会话化、聚合等任务。
- 触发器——爬虫和作业可以按需运行,也可以设置为在指定触发器发生时启动。 触发器可以是基于时间的计划或事件(例如,指定作业的成功执行)。 此选项使您能够轻松管理报告中的数据新鲜度。
在我们的 Timesheets 架构中,这部分管道呈现如下:
- 基于时间的触发器启动预处理作业,该作业执行数据清理、分配适合会话的事件日志并计算初始聚合。 此作业的结果数据存储在 AWS S3 上。
- 第二个触发器设置为在预处理作业完成并成功执行后运行。 此触发器启动一项准备数据的作业,这些数据直接用于产品负责人分析的报告中。
- 第二个作业的结果存储在 AWS RDS 数据库中。 这使得它们可以在 Google Data Studio、PowerBI 或 Tableau 等商业智能工具中轻松访问和使用。
AWS SageMaker
Amazon SageMaker 提供用于构建、训练和部署机器学习模型的模块。
它允许以任何规模训练和调整模型,并支持使用 AWS 提供的高性能算法。 尽管如此,您也可以在提供适当的 docker 映像后使用自定义算法。 AWS SageMaker 还通过比较不同模型参数集的指标的可配置作业来简化超参数调整。
在 Timesheets 中,SageMaker Notebook Instances 帮助我们探索数据、测试 ETL 脚本并准备可视化图表的原型,以在 BI 工具中用于创建报告。 该解决方案支持并改进了数据科学家的协作,因为它确保他们在相同的开发环境中工作。 此外,这有助于确保没有敏感数据(可能是笔记本单元输出的一部分)存储在 AWS 基础设施之外,因为笔记本只存储在 AWS S3 存储桶中,并且不需要 git 存储库来在同事之间共享工作.
包起来
决定使用哪些大数据和机器学习工具对于为商业智能解决方案设计管道架构至关重要。 这种选择会对系统功能、成本以及将来添加新功能的难易程度产生重大影响。 AWS 工具当然值得考虑,但您应该选择适合您当前技术堆栈和开发团队技能的技术。
利用我们在构建面向未来的解决方案方面的经验并联系我们!