
Breadcrumb SEO、Python 3 和 Oncrawl:走向自动化!
已发表: 2021-04-14让我们学习如何使用 OnCrawl 和 Python 3 自动创建基于面包屑的分割。
Oncrawl 中的分段是什么?
Oncrawl 使用分段将一组页面分成组。 这使得分析抓取报告、日志分析和其他交叉分析报告中的数据变得非常容易,这些报告将抓取数据与谷歌分析、谷歌搜索控制台、AT Internet、Adobe Analytics 或 Majestic 用于反向链接。
为什么创建细分很重要?
爬网完成后,创建自定义细分是最重要的事情。 这使您可以从最适合您的站点及其结构的角度阅读分析。
有很多方法可以分割您网站的页面,并且没有正确或错误的方法。 例如,可以根据 URL 结构跟踪您网站的结构。
例如,这种 URL “ https://www.mydomain.com/news/canada/politics ”,很容易被分割成这样:
- 一个用来隔离主页的组
- 所有新闻的群组
- 加拿大目录的子组
- 政治目录的子组
如您所见,可以为您的细分创建多达 3 个深度级别。 这使您可以专注于 SEO 分析中的某些组或子组,而无需切换细分。
如何创建基本细分?
您应该知道 Oncrawl 自己负责创建第一个分段。 这基于 URL 中遇到的“第一个路径”或第一个目录。
这使您可以在爬网完成后立即进行分析。
可能是这种细分没有反映您网站的结构,或者您想从不同的角度分析事物。
因此,您将使用我们所说的 OQL(代表 Oncrawl 查询语言)创建一个新的分段。 它有点像 SQL,只是更简单、更直观: 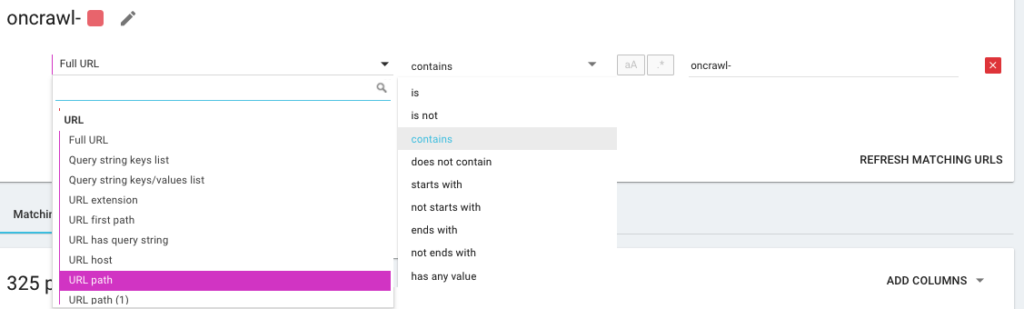
也可以尽可能精确地使用 AND/OR 条件运算符: 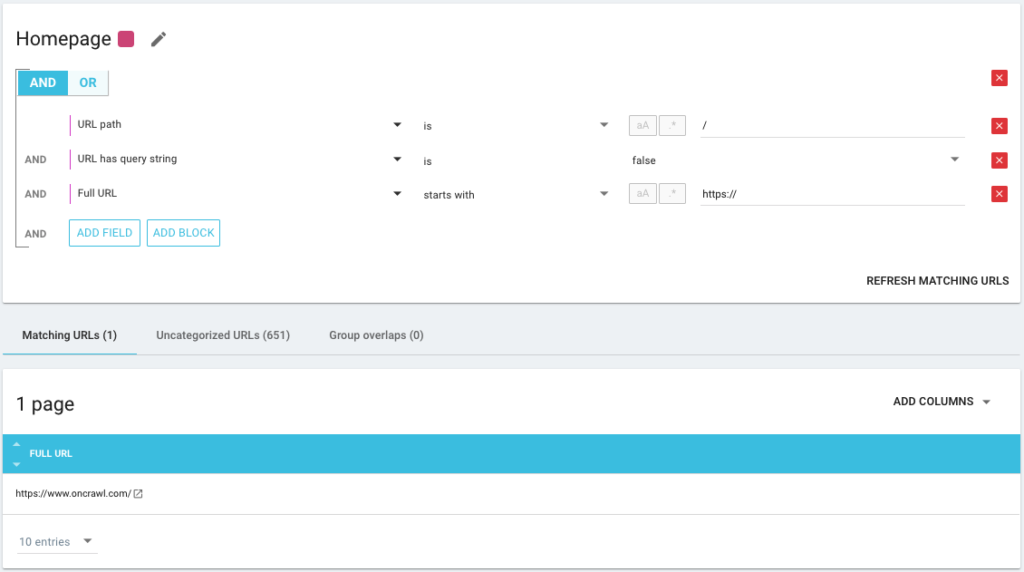
使用不同的方法分割我的页面
使用其他 KPI
基于 URL 的分段很好,但如果我们还可以结合其他 KPI 就更完美了,例如对以/car-rental/开头且 H1 具有“汽车租赁机构”表达的 URL 和另一个 H1 所在的组进行分组“公用事业租赁公司”,这可能吗?
是的,有可能! 在创建细分期间,您可以使用我们使用的所有 KPI,不仅包括来自爬虫的 KPI,还包括来自连接器的 KPI。 这使得细分的创建非常强大,并允许您拥有完全不同的分析角度!
例如,借助 Google Search Console 连接器,我喜欢使用 URL 的平均位置创建分段。
通过这种方式,我可以轻松识别结构深处仍在执行的 URL,或者靠近我的主页的位于 Google 第 2 页上的 URL。
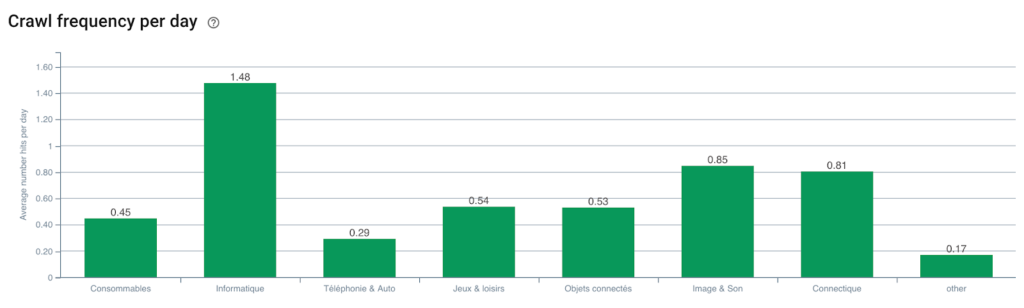
我可以查看这些页面是否有重复的内容、一个空的标题标签、是否接收到足够的链接……我还可以查看 Googlebot 在这些页面上的行为。 爬行频率是好是坏? 简而言之,它可以帮助我确定优先级并做出对我的 SEO 和 ROI 产生真正影响的决策。
抓取数据³
 学到更多
学到更多使用数据摄取
如果您不熟悉我们的数据摄取功能,我邀请您先阅读有关该主题的这篇文章。 这是另一个非常强大的工具,允许您将外部数据源添加到 Oncrawl。
例如,您可以添加来自 SEMrush、Ahrefs、Babbar.tech 的数据……优点是您可以根据从这些工具中获取的指标对页面进行分组,并根据您感兴趣的数据进行分析,即使它不是原生于 Oncrawl。
最近,我与一家全球酒店集团合作。 他们使用内部评分方法来了解酒店记录是否填写正确,是否有图像、视频、内容等……他们确定完成百分比,我们用它来交叉分析爬网和日志文件数据。
结果让我们知道 Googlebot 是否在正确填充的页面上花费更多时间,知道分数超过 90% 的某些页面是否太深,没有收到足够的链接……得分,页面获得的访问次数越多,Google 探索的次数越多,它们在 Google SERP 中的位置就越好。 鼓励酒店经营者填写酒店清单的不可阻挡的论据!
根据 SEO 面包屑跟踪创建细分
这是本文的主题,所以让我们进入问题的核心。 如果 URL 的结构没有将页面附加到某个目录,则有时很难对站点的页面进行分段。 这通常是电子商务网站的情况,其中产品页面都位于根目录。 因此,不可能从 URL 中知道页面属于哪个组。
为了将页面组合在一起,我们必须找到一种方法来识别它们所属的组。 因此,我们有了检索每个 URL 的面包屑 seo 跟踪的想法,并使用 Oncrawl 提供的 Scraper 功能根据面包屑 seo 中的值对它们进行分类。
使用 Oncrawl 进行 SEO 面包屑抓取
正如我们在上面看到的,我们将设置一个抓取规则来检索面包屑路径。 大多数时候它很简单,因为我们可以去检索一个div中的信息,然后每个级别的字段都在ul和li列表: 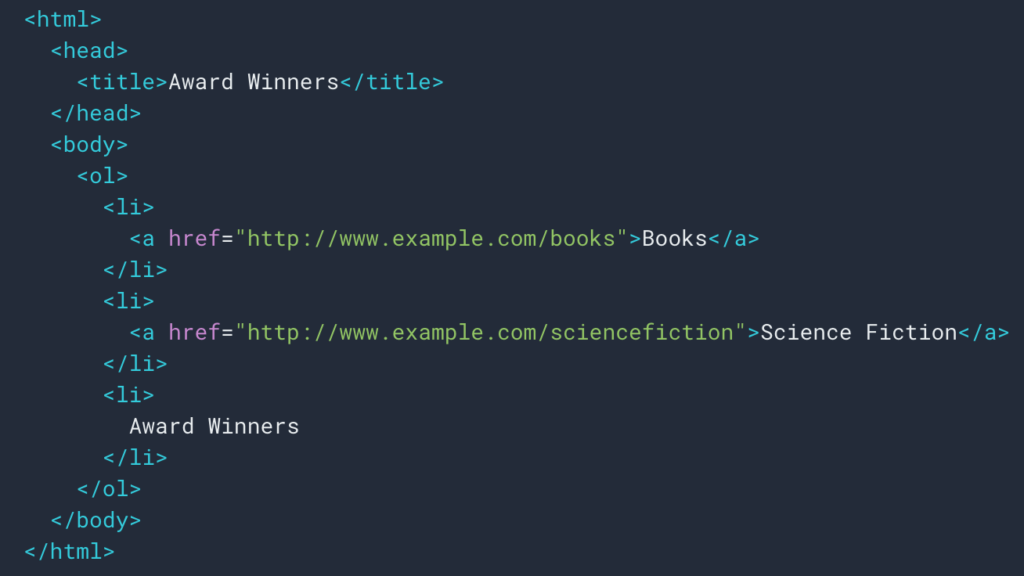
由于结构化数据类型面包屑,有时我们也可以轻松检索信息。 因此,很容易检索每个位置的“名称”字段的值。 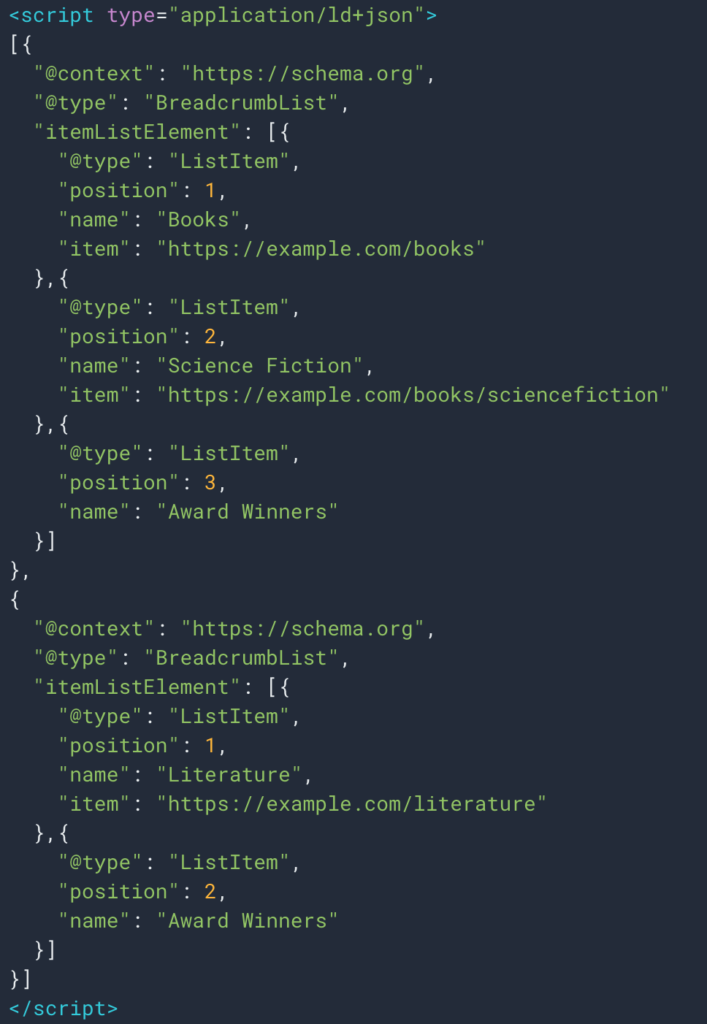
这是我使用的抓取规则的示例: 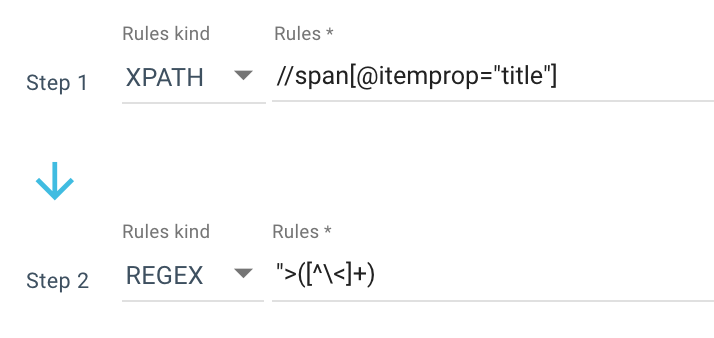
或者这条规则: //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()
所以我用 Xpath 获得了所有span itemprop=”title” ,然后使用正则表达式提取“>之后不是>字符的所有内容。 如果您想了解更多关于 Regex 的信息,我建议您阅读有关该主题的这篇文章和我们的 Regex 备忘单。
我得到几个这样的值作为输出: 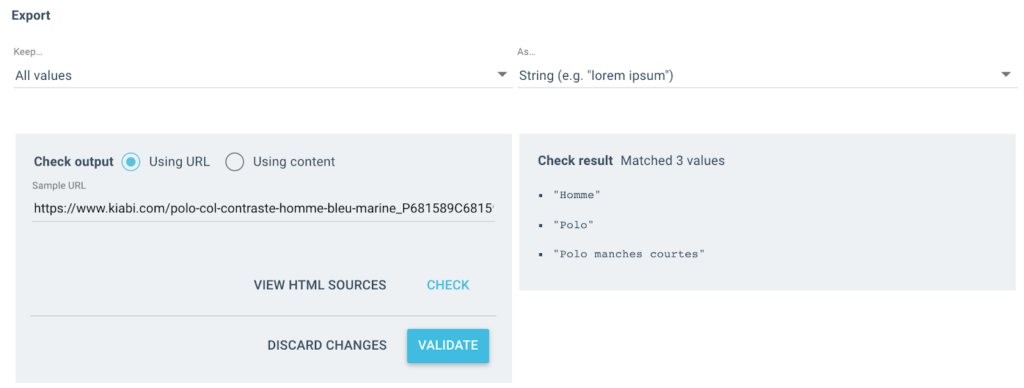
对于测试的 URL,我将有一个包含 3 个值的“面包屑”字段:

- 男人
- Polo衫
- 短袖马球
导入json
随机导入
导入请求
# 认证
# 两种方式,使用 x-oncrawl-token 可以从浏览器获取请求标头
# 或者在这里使用 api 令牌:https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN = ' '
# 在有面包屑自定义字段的地方设置爬取id
爬行_
# 更新分割中你不想得到的禁止面包屑项
FORBIDDEN_BREADCRUMB_ITEMS = ('Accueil',)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
v.strip()
对于 FORBIDDEN_BREADCRUMB_ITEMS.split(',') 中的 v
]
定义随机颜色():
random_number = random.randint(0, 16777215)
hex_number = str(hex(random_number))
hex_number = hex_number[2:].ljust(6, '0')
返回 f'#{hex_number}'
def value_to_group(值):
返回 {
“颜色”:随机颜色(),
“名称”:值,
'oql': {'or': [{'field': ['custom_Breadcrumb', 'equals', value]}]}
}
def walk_dict(字典,级别=0):
回复 = {
“图标”:“仪表板”,
“转座”:错误,
“名称”:“面包屑”
}现在已经定义了规则,我可以启动我的爬网,Oncrawl 将自动检索面包屑值并将它们与每个爬网的 URL 相关联。
使用 Python 自动创建多级分割
现在我已经有了每个 URL 的所有 SEO 面包屑值,我们将在 Google Colab 中使用seo 自动化 python脚本来自动创建与 Oncrawl 兼容的分段。
对于脚本本身,我们使用 3 个库,它们是:
- json(生成我们用 Json 编写的分段)
- CSV
- 随机(为每组生成十六进制颜色代码)
脚本启动后,它会自动负责在您的项目中创建分段! 
分析中的数据预览
现在我们的分割已经创建,可以使用基于我的面包屑跟踪的分割视图访问不同的分析。 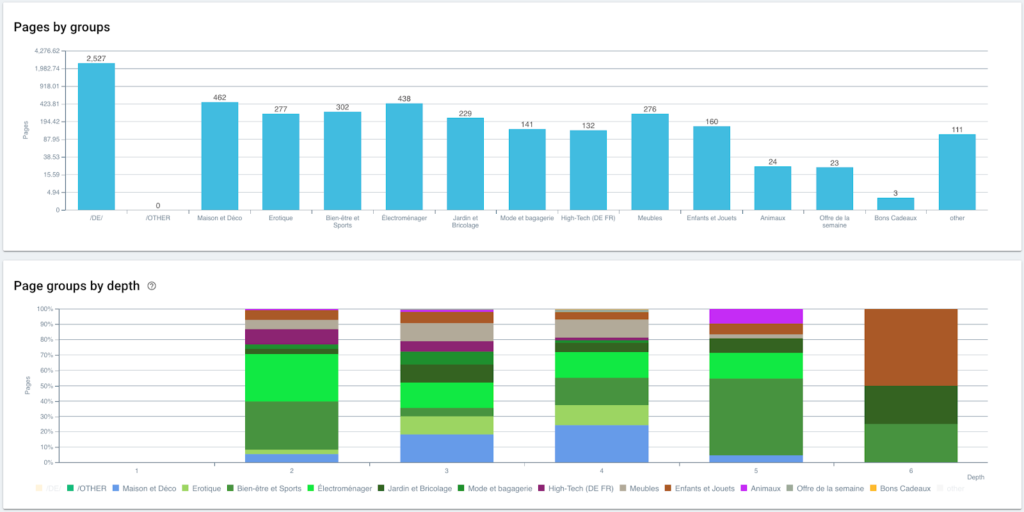
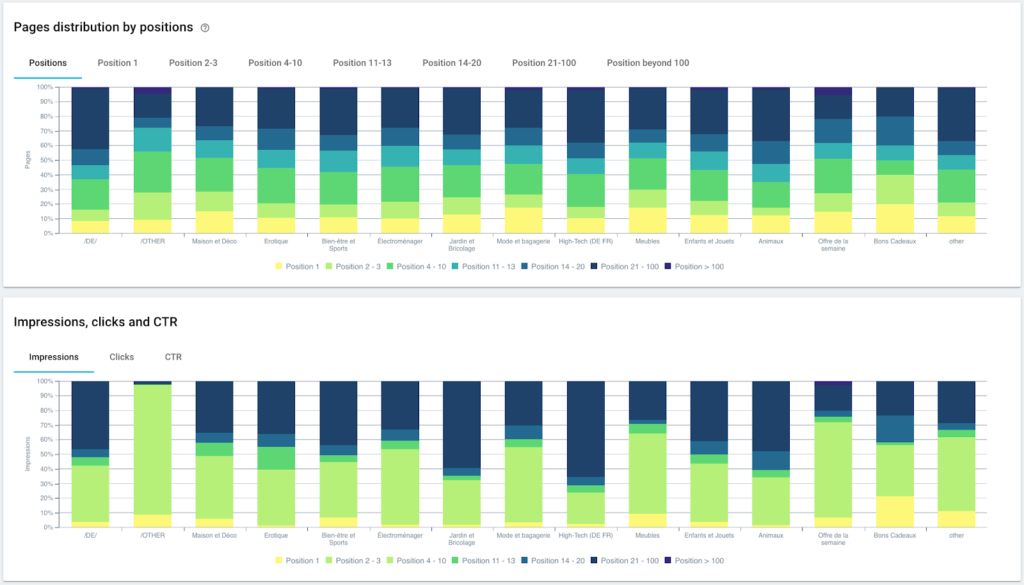
按组和深度分布页面
排名表现(GSC)
Googlebot 抓取频率
SEO访问和活跃页面比率
用户遇到的状态代码与 SEO 会话
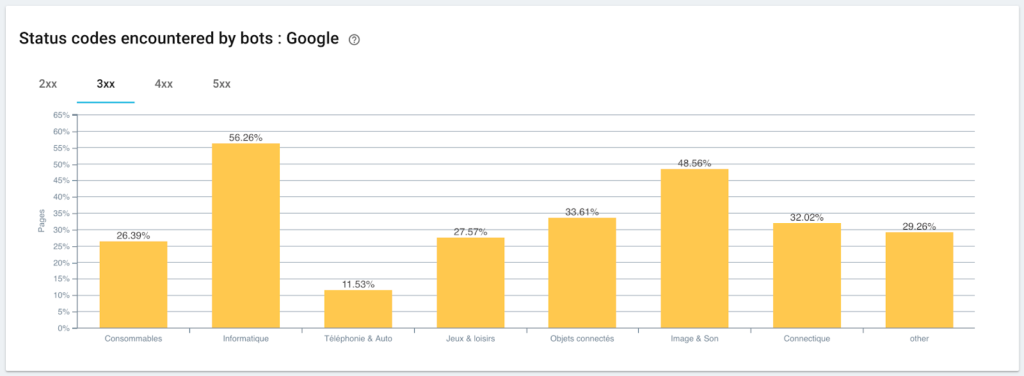
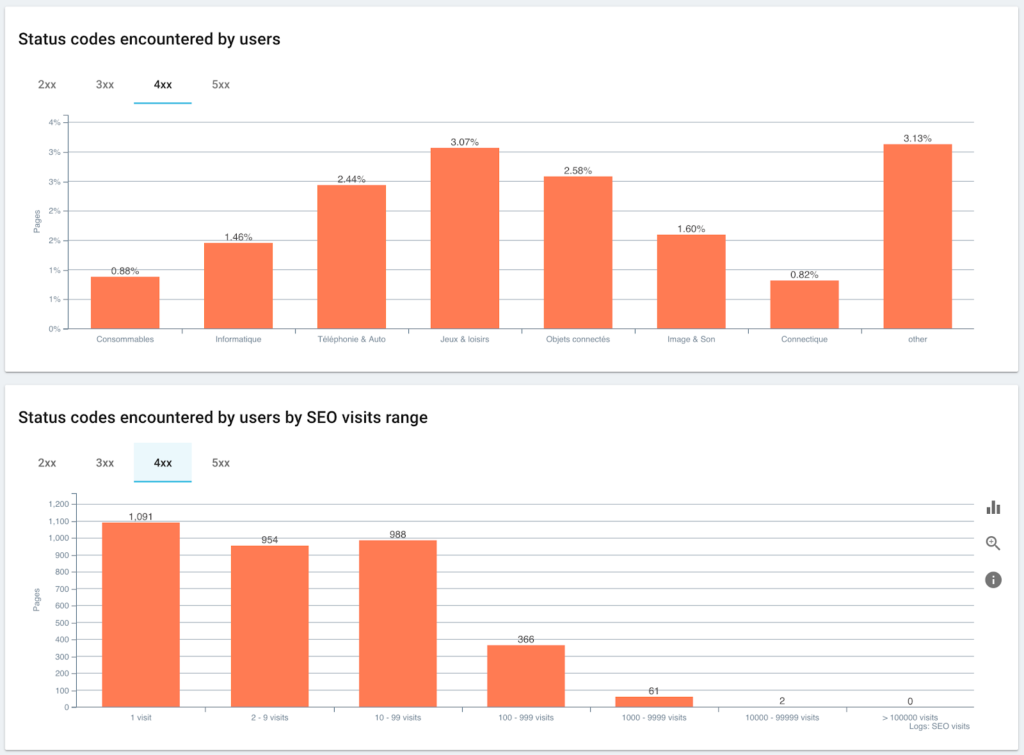
监控 Googlebot 遇到的状态码
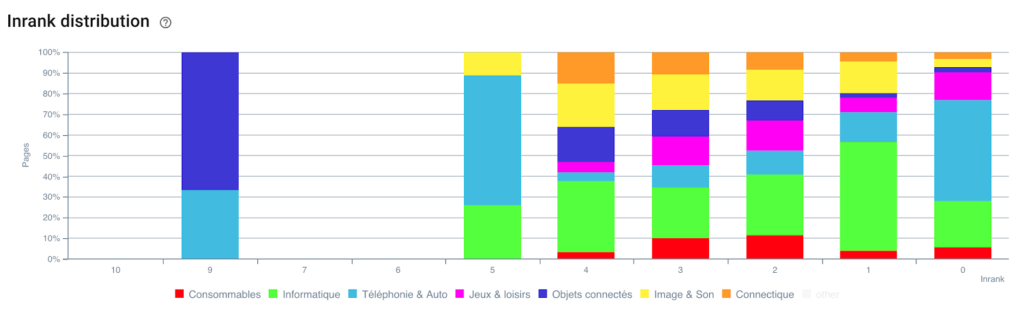
排名的分布
在这里,由于使用 Python 和 OnCrawl 的脚本,我们刚刚自动创建了一个分段。 现在所有页面都根据面包屑路径分组,并且分为 3 个深度级别: 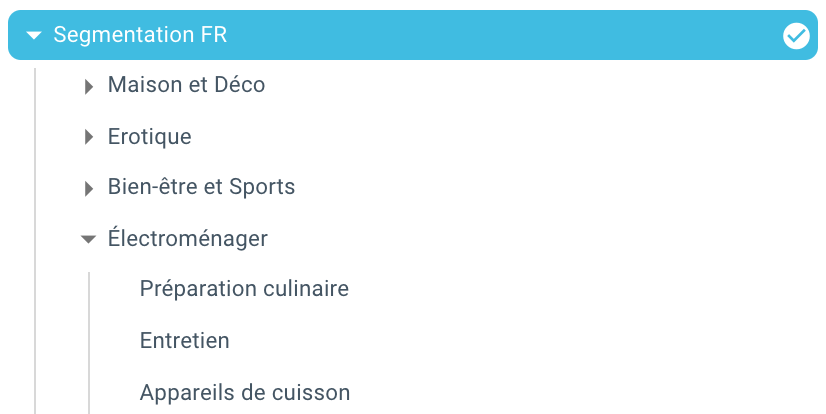
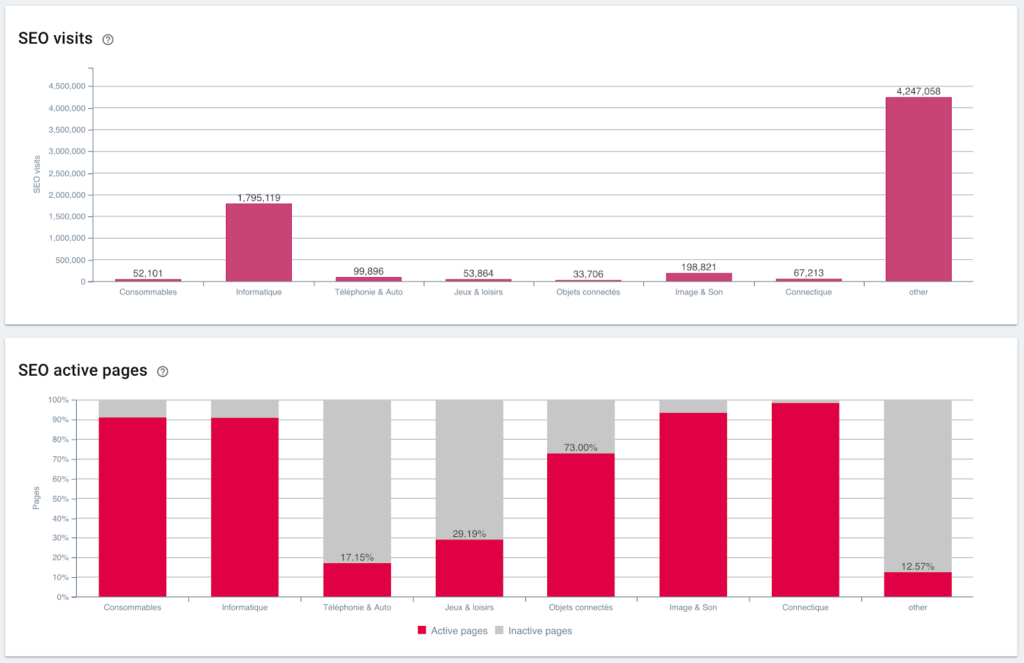
优点是我们现在可以监控每个页面组和子组的不同 KPI(抓取、深度、内部链接、抓取预算、SEO 会话、SEO 访问、排名性能、加载时间)。
Oncrawl 的 SEO 未来
您可能认为拥有这种“开箱即用”的功能很棒,但您不一定有时间做这一切。 好消息是,我们正在努力在不久的将来直接集成此功能。
这意味着您很快就可以通过简单的点击在任何报废的字段或Data Ingest的字段上自动创建分段。 这将为您节省大量时间,同时允许您执行令人难以置信的横截面 SEO 分析。
想象一下,能够从页面的源代码中抓取任何数据或为每个 URL 集成任何 KPI。 你的想象力是唯一的限制!
例如,您可以检索产品的销售价格,并根据价格查看深度、Inrank、反向链接、抓取预算。
但我们也可以检索您的媒体文章作者的姓名,看看谁表现最好,并应用最有效的写作方法。
我们可以检索您的产品的评论和评分,并查看最好的产品是否可以通过最少的点击访问、是否收到足够的链接、是否有反向链接、是否被 Googlebot 很好地抓取等等……
我们可以整合您的业务数据,例如营业额、利润、转化率、您的 Google Ads 费用。
现在由您来想象如何交叉引用数据以扩展您的分析并做出正确的 SEO 决策。
您想测试面包屑路径上的自动分割吗? 直接在 Oncrawl 中通过聊天框联系我们。
享受你的爬行!