
如何使用 AWS 将机器学习解决方案添加到您的业务中
已发表: 2020-05-13机器学习不断发展,并在全球经济中发挥着巨大的作用,因为它允许对大部分数据进行快速和自动分析。
为了让机器学习技术更接近程序员,亚马逊目前在其 AWS 平台上提供了 10 多种机器学习和人工智能服务。 借助这些服务,您可以以简单的方式开始构建模型,从而将您的业务提升到一个新的水平。
这些服务中的大多数都是完全托管的,这意味着要使用它们,您不需要任何机器学习经验,因为这些工具利用预先训练的模型来处理数据。 根据您的业务问题,您可以从计算机视觉、自然语言处理、建议和预测等领域的预训练 ML 服务中进行选择。 下图显示了机器学习解决方案工作流程,以及您可以在每个阶段使用的 AWS 工具。
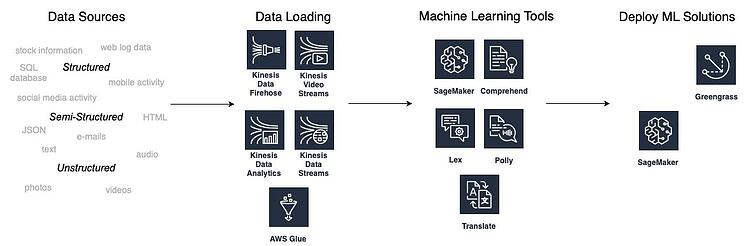
如何通过 AWS 将机器学习应用到业务中
首先:收集数据
创建 ML 解决方案最重要的元素是数据。 有 3 种类型的数据:结构化、半结构化和非结构化。
- 结构化数据的元素是可寻址的,并且可以存储在关系数据库中。 这种类型的数据有一个预定义的模式。 结构化数据的一个示例是具有数字和字符串(文本)数据的关系数据库。
- 半结构化数据集不驻留在关系数据库中,但它们仍然具有一些预定义的元素(模式),使它们更易于分析。 半结构化数据文件类型的示例是 XML、HTML、RDF 或 JSON。
- 非结构化数据就是其他一切。 这种数据类型没有预定义的结构,它们通常存储为一组文件。 最流行的非结构化数据示例是文本文档、照片、视频和音频文件以及应用程序日志。
数据加载——什么是 Kinesis?
AWS Kinesis服务摄取可以从各种来源(例如 Web 和移动应用程序)连续生成的数据。 它是一种实时数据流服务,可以非常快速地捕获千兆字节的数据。 Kinesis提供以下工具:
- Kinesis Video Streaming – 一种可以帮助您将视频从设备流式传输到 AWS 的工具
- Kinesis Data Streaming – 一种可帮助您收集 IT 日志、网站点击或金融交易等数据的工具
- Kinesis Data Firehose – 一种将流式数据加载到数据存储(例如 S3、Redshift)或分析工具中的工具
- Kinesis Data Analytics – 一种使用 SQL 或 Java 实时处理流数据的工具
数据加载——什么是胶水?
另一项可以帮助加载数据的 AWS 服务是由 Apache Spark 管理的Glue 。 它是一种提取、转换和加载工具 (ETL),可用于在用于分析之前准备数据。 Glue 可以处理结构化和半结构化数据。
Glue 的元素是数据目录、ETL 引擎和调度程序。 Glue 数据目录是该工具最重要的部分。 它保存有关给定数据的元数据,这些元数据由遍历数据源并检测其架构的爬虫自动发现。
ETL 引擎可以生成 Python 和 Scala 代码,以供非编程用户在 ETL 过程中使用。 它还可以使用用户提供的代码处理数据。 调度程序可以监控作业、运行任务,并根据某些事件(例如在每周一的特定时间,或者当另一个任务完成或失败时)触发它们。
其次:选择正确的机器学习工具
在我们收集到所需的数据后,我们可以开始构建我们的 ML 解决方案。 AWS 提供了一些机器学习工具,可以处理各种类型的数据。
现在让我们来看看这些工具中的每一个,并介绍它们在商业中可能的主要应用领域。
什么是 SageMaker?
SageMaker对机器学习开发人员和数据科学家最有用。 该服务是一个完整的解决方案,可帮助您轻松地将机器学习模型从概念转变为生产。 Amazon SageMaker 拥有一套丰富的工具(Ground Truth、Notebooks、Experiments、Debugger、Model Monitor、Neo),可以帮助标记数据、构建、优化、训练、测试和部署模型。
为给定问题手动找到正确的算法通常需要数小时的训练和测试。 SageMaker 有一个 AutoPilot 选项,它使用 50 种不同的预训练 ML 模型来自动找到适合手头案例的最佳 ML 模型。 开发人员可以使用该解决方案快速找到基线模型。
什么是个性化?
Personalize是一种机器学习服务,可帮助构建推荐系统。 Personalize 可以处理来自应用程序的活动流,例如点击、页面浏览、购买,并使用它们来创建个性化推荐。 您还可以使用有关用户的其他信息,例如年龄或地理位置。 通过简短的 API 调用可以简化在应用程序中显示推荐结果。 多年来,Amazon.com 对 Personalize 中的机器学习技术进行了改进。

什么是领悟?
Comprehend是一项自然语言处理 (NLP) 服务,它使用机器学习从非结构化文本数据中提取有价值的见解。 该服务应用情感分析、词性提取和标记化来检测文本的关键特征。 理解有助于理解给定文本的积极或消极程度。
Comprehend 有一个额外的工具:Amazon Comprehend Medical,专门用于医疗行业。 Amazon Comprehend Medical 可以分析医疗文档(如患者的医疗记录、临床记录)并提取有关药物、剂量和频率的信息。 Comprehend 是一项完全托管的服务。
什么是预测?
Forecast使用机器学习来构建时间序列预测模型。 它可以将历史时间序列数据与其他变量(您认为这些变量可能会影响预测)结合起来构建预测模型。 此亚马逊解决方案适用于预测股票价格或客户产品需求等价值。 预测也是一项完全托管的服务,可以根据业务需求进行扩展。
什么是莱克斯?
Lex使用自动语音识别 (ASR) 将语音转换为文本,并使用自然语言理解 (NLU) 来识别文本的意图。 该解决方案使用户能够构建对话机器人。
例如,您可以使用 Lex 作为手动客户支持的替代品,它会自动回答客户查询。 Amazon Lex 使用与 Amazon Alexa(亚马逊的虚拟助手 AI)相同的深度学习技术。
什么是波莉?
Polly是一种云服务,它使用深度学习算法将文本转换为逼真的语音。 它目前支持 29 种语言的 60 种男性和女性声音,包括日语、汉语、韩语和阿拉伯语。 Polly 还可以处理时间、日期、单位、分数和缩写。 该解决方案允许用户创建可以说话的应用程序。
什么是欺诈检测器?
Fraud Detector是一项 AWS 服务,可帮助识别欺诈性在线活动,例如付款欺诈或虚假账户。 该服务是完全托管的,因此只需单击几下即可创建欺诈检测模型。
什么是文本?
Textract是一种可以自动从扫描文档中读取数据的服务。 Textract 可以在几个小时内处理数百万页,并且可以帮助自动化文档工作流程。 该服务在处理贷款申请或医疗文件等文件时很有用。
什么是翻译?
Translate是一种 AWS 机器学习服务,可用于执行语言到语言的文本翻译。 与传统的统计算法相比,它使用深度学习模型来提供更准确、更自然的翻译。 Translate 支持 54 种语言(包括南非荷兰语、保加利亚语、爱沙尼亚语)和 2,804 种语言对。
什么是识别?
Rekognition是一种计算机视觉服务,可以识别图像和电影中的对象、人物和文本。 Rekognition 能够识别和比较面部,分析它们并识别一些面部特征,如嘴巴、鼻子或眼睛。
Rekognition 有一个模块可以自动检测面部图像中的快乐、悲伤或惊讶等情绪。 它还可以执行用户面部验证,通过将实时图像与存储的参考图像进行比较来确认用户的身份。
第三:部署机器学习解决方案
部署模型最广泛使用的方法是 SageMaker 服务,您可以通过以下两种方式之一使用它:
- 使用 SageMaker 托管服务设置 HTTPS 端点。 在此解决方案中,客户端应用程序向 HTTPS 端点发送请求,以从部署的模型中获取预测。 要使用此解决方案,您必须将其与 Docker 映像一起提供。 如果需要部署多个模型,也可以使用多模型端点。
- 使用 SageMaker 批量转换,它可以帮助您获得整个数据集的预测。 要使用批量转换部署模型,您需要一个 S3 存储桶来存储模型、数据集和预测。
部署替代方案是使用AWS IoT Greengrass 。 该服务将 AWS 扩展到物联网 (IoT) 设备。 使用这项服务,设备可以收集、过滤、处理数据,即使没有云连接,它们也可以运行 Lambda 函数、Docker 容器并基于 ML 模型执行预测。 当连接到互联网时,Greengrass 会将所有数据与云服务同步。
概括
如您所见,Amazon Web Service 提供了一套丰富的工具,可以帮助您为您的业务创建有影响力的机器学习解决方案。 借助 ML AWS 工具,您可以向应用程序添加新功能,例如人脸检测、聊天机器人、语音识别、社交媒体内容的情绪分析。 AWS 每隔几个月就会根据新的用例添加新的 ML 服务,这使其成为创建 AI 解决方案的增长最快的平台之一。
使用 Miquido 开发面向未来的机器学习解决方案!