
自动从文本中提取概念和关键词(第一部分:传统方法)
已发表: 2022-02-22在 Oncrawl 的研发部门,我们越来越希望增强您网页的语义内容。 使用机器学习模型进行自然语言处理 (NLP),我们可以详细比较您的网页内容、创建自动摘要、完善或更正您的文章标签、根据您的Google Search Console数据优化内容等。
在之前的文章中,我们谈到了从 HTML 页面中提取文本内容。 这一次,我们想谈谈从文本中自动提取关键字。 本主题将分为两篇文章:
- 第一个将通过几个具体示例介绍上下文和所谓的“传统”方法
- 即将推出的第二个将处理基于转换器和评估方法的更多语义方法,以便对这些不同的方法进行基准测试
语境
除了标题或摘要之外,还有什么比使用几个关键字更好的方法来识别文本、科学论文或网页的内容。 这是识别更长文本的主题和概念的简单且非常有效的方法。 这也是对一系列文本进行分类的好方法:识别它们并按关键字对它们进行分组。 提供科学文章的网站(例如 PubMed 或 arxiv.org)可以根据这些关键字提供类别和建议。
关键字对于索引非常大的文档和信息检索也非常有用,这是搜索引擎众所周知的专业领域
缺少关键词是科学文章自动分类中经常出现的问题[1]:许多文章没有指定关键词。 因此,必须找到从文本中自动提取概念和关键字的方法。 为了评估一组自动提取的关键字的相关性,数据集通常会将算法提取的关键字与几个人提取的关键字进行比较。
可以想象,这是搜索引擎在对网页进行分类时所共有的问题。 更好地理解关键字提取的自动化过程可以更好地理解为什么网页定位于这样或这样的关键字。 它还可以揭示语义差距,使其无法为您定位的关键字排名。
显然有几种方法可以从文本或段落中提取关键字。 在第一篇文章中,我们将描述所谓的“经典”方法。
[电子书] 数据 SEO:下一次大冒险
 阅读电子书
阅读电子书约束
然而,我们在选择算法时有一些限制和先决条件:
- 该方法必须能够从单个文档中提取关键字。 有些方法需要完整的语料库,即数百甚至数千个文档。 尽管搜索引擎可以使用这些方法,但它们对单个文档没有用处。
- 我们处于无监督机器学习的情况。 我们手头没有带注释数据的法语、英语或其他语言的数据集。 换句话说,我们没有数千个已经提取关键字的文档。
- 该方法必须独立于文档的域/词法域。 我们希望能够从任何类型的文档中提取关键字:新闻文章、网页等。请注意,一些已经为每个文档提取了关键字的数据集通常是领域特定的医学、计算机科学等。
- 一些方法基于词性标注模型,即 NLP 模型通过语法类型识别句子中单词的能力:动词、名词、限定词。 确定作为名词而不是限定词的关键字的重要性显然是相关的。 但是,根据语言的不同,POS 标记模型有时质量非常不均衡。
关于传统方法
我们区分了所谓的“传统”方法和最近使用 NLP(自然语言处理)技术的方法,例如词嵌入和上下文嵌入。 这个主题将在以后的文章中介绍。 但首先,让我们回到经典方法,我们区分其中两种:
- 统计方法
- 图法
统计方法将主要依赖于词频及其共现。 我们从简单的假设开始构建启发式并提取重要词:一个非常频繁的词,一系列出现多次的连续词等。基于图的方法将构建一个图,其中每个节点可以对应一个词,一组单词或句子。 那么每条弧线都可以表示同时观察这些词的概率(或频率)。
这里有一些方法:
- 基于统计
- 特遣部队
- 耙
- 雅克
- 基于图
- 文本排名
- 主题排名
- 单排
给出的所有示例都使用来自此网页的文本:Jazz au Tresor : John Coltrane – Impressions Graz 1962。
统计方法
我们将向您介绍 Rake 和 Yake 两种方法。 在 SEO 环境中,您可能听说过 TF-IDF 方法。 但由于它需要一个文档语料库,我们将不在这里处理它。
耙
RAKE 代表快速自动关键字提取。 这个方法在 Python 中有几个实现,包括 rake-nltk。 每个关键词的得分,也称为关键短语,因为它包含几个词,它基于两个元素:词的频率和它们共现的总和。 每个关键短语的构成非常简单,它包括:
- 将文本切割成句子
- 将每个句子切成关键词
在下面的句子中,我们将采用标点符号或停用词分隔的所有词组:
就在之前,Coltrane 正在带领一个五重奏组,Eric Dolphy 在他身边,而 Reggie Workman 则负责低音提琴。
这可能会导致以下关键词:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" 。
请注意,停用词是一系列非常常见的词,例如“ the ”、“ in ”、“and” or “ it ”。 由于经典方法通常基于单词出现频率的计算,因此仔细选择停用词很重要。 大多数时候,我们不希望在我们的关键词提案中出现>"to" 、 "the" or "of" 之类的词。 事实上,这些停用词与特定的词汇领域无关,因此与“ jazz ”或“ saxophone ”等词的相关性要低得多。
一旦我们分离出几个候选关键词,我们就会根据单词的频率和共现给它们打分。 分数越高,关键词应该越相关。
让我们快速尝试一下关于 John Coltrane 的文章中的文字。
# rake 的 python 片段 从 rake_nltk 导入耙子 # 假设你已经在 'text' 变量中找到了文章 耙子=耙子(停用词=FRENCH_STOPWORDS,最大长度=4) rake.extract_keywords_from_text(文本) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
以下是前 5 个关键词:

“奥地利国家公共广播电台”、“抒情山峰更天堂”、“格拉茨有两个特点”、“约翰·科尔特兰次中音萨克斯风”、“唯一录音版”
这种方法有一些缺点。 第一个是停用词选择的重要性,因为它们用于将句子拆分为候选关键词。 二是当keyphrases太长时,往往会因为出现的词共现而得分较高。 为了限制关键短语的长度,我们使用max_length=4设置方法。
雅克
YAKE 代表又一个关键字提取器。 此方法基于以下文章 YAKE! 从 2020 年开始,使用多个本地特征从单个文档中提取关键字。这是一种比 RAKE 更新的方法,RAKE 的作者提出了在 Github 上可用的 Python 实现。
对于 RAKE,我们将依赖词频和共现。 作者还将添加一些有趣的启发式方法:
- 我们将区分小写单词和大写单词(第一个字母或整个单词)。 我们将在这里假设以大写字母开头的单词(句首除外)比其他单词更相关:人名、城市、国家、品牌。 这是所有大写单词的相同原则。
- 每个候选关键词的得分将取决于它在文本中的位置。 如果候选关键词出现在文本的开头,则它们的得分将高于出现在末尾的得分。 例如,新闻文章经常在文章开头提到重要的概念。
# yake 的 python 片段 从 yake 导入 KeywordExtractor 作为 Yake yake = Yake(lan="fr", 停用词=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(文本)
与 RAKE 一样,以下是前 5 个结果:
“珍宝爵士”、“约翰·科尔特兰”、“格拉茨印象”、“格拉茨”、“科尔特兰”
尽管在某些关键短语中某些单词有一些重复,但这种方法似乎很有趣。
图法
这种方法与统计方法相差不远,我们还将计算单词共现。 与TextRank等一些方法名称相关的Rank后缀是基于PageRank算法的原理,根据每个页面的传入和传出链接计算每个页面的流行度。
[电子书] 使用 Oncrawl 自动化 SEO
 阅读电子书
阅读电子书文本排名
该算法来自于 2004 年的论文 TextRank:Bringing Order into Texts,其原理与PageRank算法相同。 但是,我们不会用页面和链接构建图表,而是用单词构建图表。 每个单词将根据它们的共现与其他单词链接。
Python中有几种实现。 在本文中,我将介绍 pytextrank。 我们将打破关于 POS 标记的限制之一。 实际上,在构建图形时,我们不会将所有单词都包含为节点。 只考虑动词和名词。 与以前使用停用词过滤不相关候选词的方法一样,TextRank 算法使用语法类型的词。
这是将由 algo 构建的图的一部分的示例: 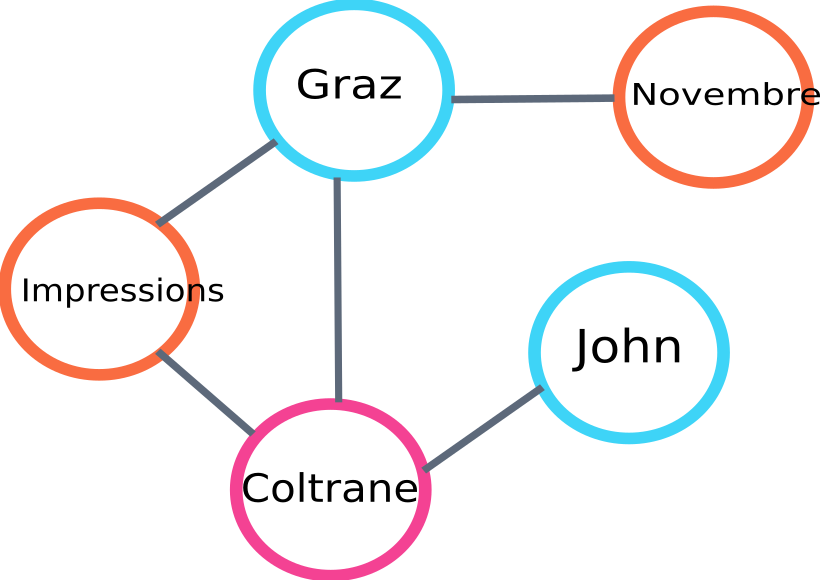
文本排名图示例
这是一个在 Python 中使用的示例。 请注意,此实现使用 spaCy 库的管道机制。 正是这个库能够进行 POS 标记。
# pytextrank 的 python 片段
进口空间
导入 pytextrank
# 加载一个法国模型
nlp = spacy.load("fr_core_news_sm")
# 将 pytextrank 添加到管道
nlp.add_pipe("textrank")
doc = nlp(文本)
textrank_keyphrases = doc._.phrases
以下是前 5 名的结果:
“哥本哈格”、“十一月”、“格拉茨印象”、“格拉茨”、“约翰·科尔特兰”
除了提取关键短语,TextRank 还提取句子。 这对于制作所谓的“提取摘要”非常有用——本文将不涉及这一方面。
结论
在这里测试的三种方法中,后两种在我们看来似乎与本文的主题非常相关。 为了更好地比较这些方法,我们显然必须在大量示例上评估这些不同的模型。 确实有衡量这些关键词提取模型相关性的指标。
这些所谓的传统模型生成的关键字列表为检查您的页面是否有针对性提供了极好的基础。 此外,它们给出了搜索引擎如何理解和分类内容的初步近似值。
另一方面,其他使用预训练 NLP 模型的方法(如 BERT)也可用于从文档中提取概念。 与所谓的经典方法相反,这些方法通常可以更好地捕捉语义。
不同的评估方法、上下文嵌入和转换器将在第二篇文章中介绍!
以下是使用提到的三种方法之一从本文中提取的关键字列表:
“方法”、“关键词”、“关键词”、“文本”、“提取的关键词”、“自然语言处理”
参考书目
- [1] 在提供更多语言知识的情况下改进自动关键字提取,Anette Hulth,2003
- [2] 从单个文档中自动提取关键字,Stuart Rose 等。 2010 年
- [3] 耶克! 使用多个局部特征从单个文档中提取关键字,Ricardo Campos 等。 2020 年
- [4] TextRank:为文本带来秩序,Rada Mihalcea 等。 2004 年
开始您的 14 天免费试用
 开始试用
开始试用