
真实性、Dalle-2 和 Midjourney 以及我们对 AI 生成的图像和艺术的迷恋
已发表: 2022-08-04这篇文章是关于像 Dalle-2 和 Midjourney 这样的平台背后的技术,以及为什么创造者 Open AI 应该给你钱——而不是向你收费……
互联网上越来越多的人将 Dalle-2 和 Open AI 命名为骗局。 原因是 Dalle-2 现在突然变成了一种货币化服务,如果你使用超过 beta 限制的平台,你需要购买积分。
DALLE 2 只是众多新平台之一,可让您访问 AI 生成的内容,并声称您可以将其用于商业目的。 其他平台包括 Midjourney、Jasper Art、Nightcafe、Starry AI 和 Craiyon。 在这篇博文中,我们将重点关注 Dalle 2,但在涉及法律挑战和问题时,它们几乎是相同的。
在我们看来,诈骗是一个非常严厉的说法,但是在使用其他人创建的数据(照片、视频、注释、图像上的人等)然后开始将其卖回给同一个人时存在一个明显的问题。
我们中的许多人可能会忽略这个问题,因为我们只是对新技术着迷。 完全可以理解的东西。
然而,尽管说到底 DALL-E 2 只是一台先进的模式识别机,但它的输出并不是中性的,而且模式也不是来自新鲜空气。
它们基于大量数据,其中需要提出多个法律问题。 作为您生成的图像的潜在用户,对您很重要的问题。
 由 DALLE-2 创建的图像
由 DALLE-2 创建的图像
人工智能模型无法与人类相提并论
在开始考虑将 DALL-E 2 图像用于商业目的之前,您应该先阅读 Engadget 中的这篇精彩文章。
在 Engadget 文章中,他们指出了另一件非常重要的事情。 也就是说,DALL-E 2 和 OpenAI 并没有放弃将用户使用 DALL-E 创建的图像商业化的权利。 基本上意味着您可以生成图像,然后他们将商业出售给其他人。
这表明意图与有时使用的类比非常不同,其中 DALLE-2 发起人将其与阅读知名作者作品的学生进行比较。 在这个例子中,学生可以学习作者的风格和模式,然后发现它们适用于其他环境并在那里重新使用它们。
然而,这并不是关于人类大脑使用创造性记忆来创造新的创造性作品。 这是关于模式识别机器重复使用并在某些情况下复制图像中的训练数据,然后使用甚至商业销售。 这只是两个不同的世界——无论是隐喻还是字面意义上的。
 来自现实世界的真实照片
来自现实世界的真实照片
JumpStory 的真实性承诺
这篇文章是为那些想要更深入地了解这种新的人工智能图像生成技术是如何工作的人准备的。 但在我们开始之前,请简单介绍一下为什么 JumpStory 目前没有构建类似的机器。
当然,我们多次被问到这个问题。 尤其是考虑到我们公司已经在使用人工智能,而且我们可以访问数百万张真实图像。
然而,这对我们来说不是技术讨论,而是伦理讨论。 导致我们的真实性承诺的讨论。
我们从根本上反对人工智能生成的图像成为常态而非例外的未来。 称我们为守旧派,但我们相信真实世界是美丽的。
我们很自豪我们的照片和视频以不同的形状和大小描绘了真实的人类。 我们不反对使用人工智能,但我们认为不应该用它来生成虚假的人或现实。
合成介质和 DALL-E 2 等技术表面上可能很吸引人,但它们也带来了真正的风险。 他们冒着模糊真假界限的风险,这将对人类之间的信任构成根本威胁。
这就是为什么 JumpStory 不使用人工智能来生成假图像,而是使用人工智能来识别哪些图像是原创的、真实的,当然还有合法的商业用途。
这些是您使用我们的服务找到的图像,我们将我们的方法命名为“真实智能”。
了解如何生成 AI 图像
关于 JumpStory 和 DALL-E 2 的法律问题,现在已经足够了。 让我们看看 AI 图像是如何在 DALLE-2、Imagen、Crayion(以前称为 Dall-E Mini)、Midjourney 等平台上生成的……使用 DALLE-2 作为目前最受宣传的例子。

首先,DALLE-2 可以执行不同类型的任务,但我们将在这篇博文中专注于图像生成任务。
它的工作原理是将文本提示输入到文本编码器中。 该编码器经过训练以将提示映射到表示空间。 之后,所谓的先验模型将编码文本映射到相应的图像编码,该图像编码捕获文本编码提示的语义信息。
(如果这已经变得有点怪异了,我很抱歉,但它会变得更糟)
图像编码器的最后一步是生成图像,将编码器接收到的语义信息可视化。 这是 Open AI 等机器的基础知识。
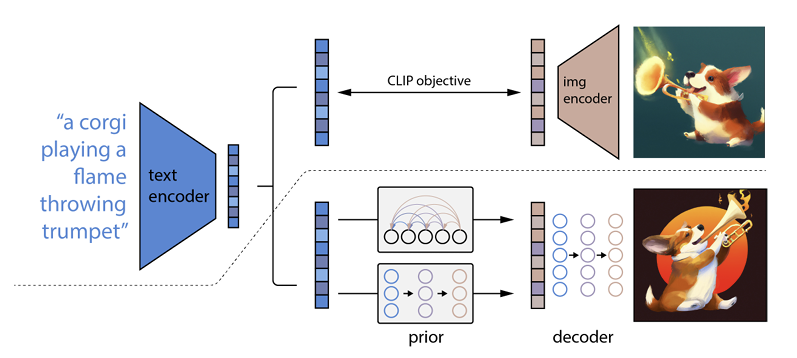
文字与视觉的关系
DALL-E 2 和类似技术通常被称为文本到图像生成器。 原因是它们能够接收文本输入并提供图像输出。
举个例子,这是“一位宇航员以安迪·沃霍尔 (Andy Warhol) 的风格骑马:

来源:DALLE-2
这里发生的事情是基于 Open AI 的名为 CLIP 的模型。 CLIP 是“Contrastive Language-Image Pre-training”的缩写,是一个非常复杂的模型,经过数百万张图像和字幕的训练。
CLIP 特别擅长的是了解特定文本与特定图像的关联程度。 这里的关键不是标题,而是某个标题与某个图像的相关程度。
这种技术被命名为“对比”,CLIP 能够做的就是从自然语言中学习语义。 CLIP 了解这一点的方法是通过一个过程,其目标是(现在引用技术文档): “同时最大化 N 个正确编码图像/字幕对之间的余弦相似度,并最小化 N 2 – N 个不正确编码图像之间的余弦相似度/字幕对。”
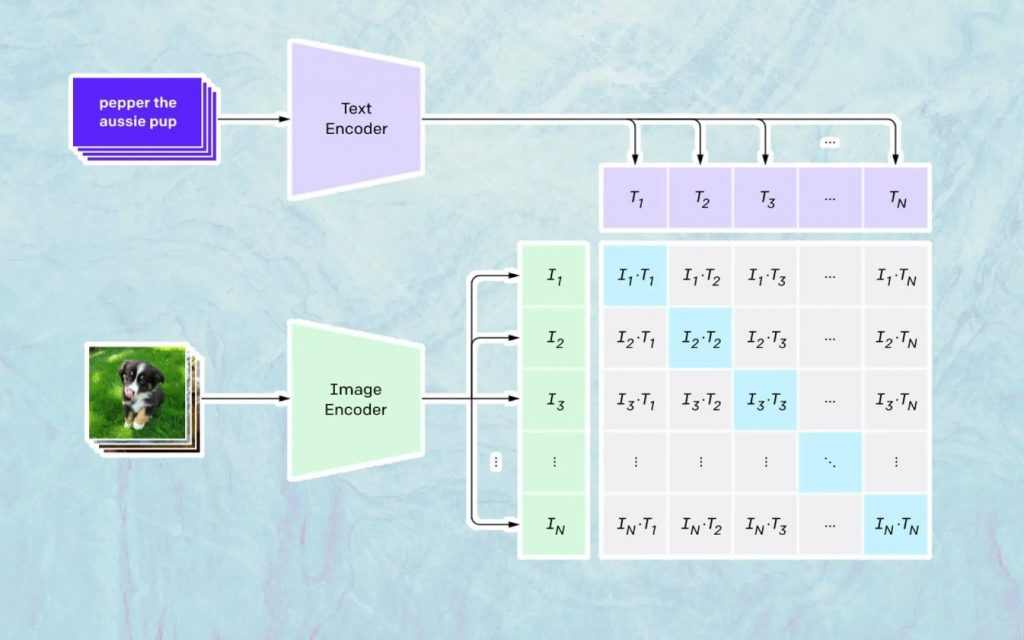
生成图像
如上所述,CLIP 模型学习了一个表示空间,它可以在其中确定图像和文本的编码是如何相关的。
下一个任务是使用这个空间来生成图像。 为此,Open AI 开发了另一个名为 GLIDE 的模型,该模型能够使用来自 CLIP 的输入,并使用扩散模型执行图像生成。
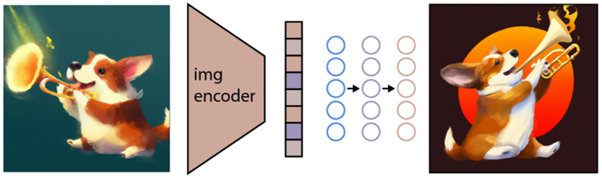
简单解释一下什么是扩散模型,它基本上是一个通过反转渐进式噪声过程来学习生成数据的模型。 抱歉,这现在变得非常技术性,所以引用 Open AI 文档中的描述:
“噪声过程被视为一个参数化的马尔可夫链,它逐渐向图像添加噪声以破坏它,最终(渐近地)产生纯高斯噪声。 扩散模型学习沿着这条链向后导航,在一系列时间步长上逐渐消除噪声以逆转这一过程。”

如果您想更深入地了解这项技术,我们建议您阅读 Ryan O'Connor 撰写的这篇出色的文章。