
如何在 Oncrawl 之外使用 Oncrawl 数据回答复杂的数据问题
已发表: 2022-01-04Oncrawl 对于企业 SEO 的优势之一是可以完全访问您的原始数据。 无论您是将 SEO 数据连接到 BI 还是数据科学工作流程,执行您自己的分析,还是在您的组织的数据安全准则范围内工作,原始 SEO 和网站审计数据都可以用于多种用途。
今天我们将看看如何使用 Oncrawl 数据来回答复杂的数据问题。
什么是复杂数据问题?
复杂数据问题是无法通过简单的数据库查找来回答的问题,但需要数据处理才能获得答案。
以下是 SEO 经常遇到的一些“复杂”数据问题的常见示例:
- 创建指向页面的所有链接列表,这些页面重定向到具有 404 状态的其他页面
- 基于非 URL 指标创建一个包含所有链接及其锚文本的列表,这些链接指向一个分段中的页面
如何在 Oncrawl 中回答复杂的数据问题
Oncrawl 的数据结构旨在允许几乎所有站点近乎实时地查找数据。 这涉及将不同类型的数据存储在不同的数据集中,以确保在界面中将查找时间保持在最低限度。 例如,我们将与 URL 相关的所有数据存储在一个数据集中:响应代码、传出链接的数量、存在的结构化数据类型、字数、自然访问次数……我们将与链接相关的所有数据存储在一个单独的数据集中:链接目标、链接来源、锚文本……
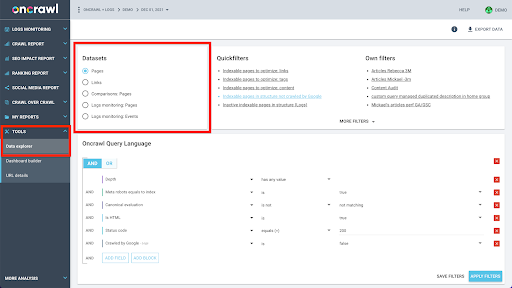
加入这些数据集在计算上很复杂,并且在 Oncrawl 应用程序的界面中并不总是支持。 当您有兴趣查找需要过滤一个数据集以便在另一个数据集中查找的内容时,我们建议您自行处理原始数据。
由于您可以使用所有 Oncrawl 数据,因此有很多方法可以连接数据集和表达复杂的查询。
在本文中,我们将使用 Google Cloud 和 BigQuery 来研究其中之一,这适用于我们的许多客户在检查具有大量页面的网站的数据时遇到的非常大的数据集。
你需要什么
要遵循我们将在本文中讨论的方法,您需要访问以下工具:
- 爬行
- Oncrawl 的大数据导出 API
- 谷歌云存储
- 大查询
- 用于将数据从 Oncrawl 传输到 BigQuery 的 Python 脚本(我们将在本文中构建它。)
在开始之前,您需要在 Oncrawl 中访问已完成的爬网报告。
如何在 Google BigQuery 中利用 Oncrawl 数据
今天这篇文章的计划如下:
- 首先,我们将确保将 Google Cloud Storage 设置为从 Oncrawl 接收数据。
- 接下来,我们将使用 Python 脚本运行 Oncrawl 的大数据导出,以将数据从给定的爬网导出到 Google Cloud Storage 存储桶。 我们将导出两个数据集:页面和链接。
- 完成后,我们将在 Google BigQuery 中创建一个数据集。 然后,我们将从 BigQuery 数据集中的两个导出中的每一个创建一个表。
- 最后,我们将尝试查询单个数据集,然后将两个数据集放在一起以找到复杂问题的答案。
在 Google Cloud 中设置以接收 Oncrawl 数据
要在专用的沙盒环境中运行本指南,我们建议您创建一个新的 Google Cloud 项目,以将其与您现有的正在进行的项目隔离开来。
让我们从 Google Cloud 的家开始。
在您的 Google Cloud 主页上,您可以访问除 Cloud Storage 之外的许多内容。 我们对 Google Cloud Platform 的云存储层中提供的 Cloud Storage 存储分区感兴趣: 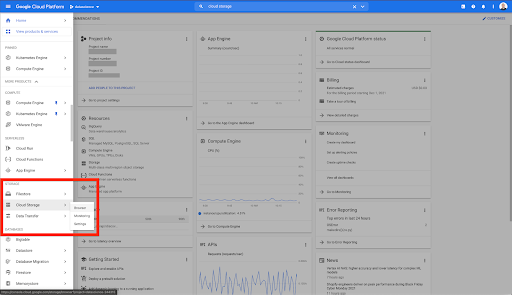
您还可以通过 https://console.cloud.google.com/storage/browser 直接访问 Cloud Storage 浏览器。
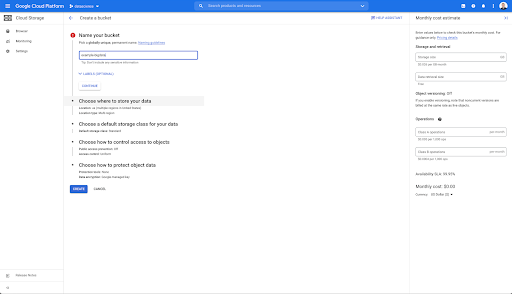
然后,您需要创建一个 Cloud Storage 存储桶,并授予正确的权限,以便允许 Oncrawl 的服务帐户在您选择的前缀下写入其中。
Google Cloud Storage 存储桶将用作临时存储,用于保存从 Oncrawl 导出的大数据,然后再将它们加载到 Google BigQuery 中。
在这个存储桶中,我还创建了两个文件夹:“links”和“pages”: 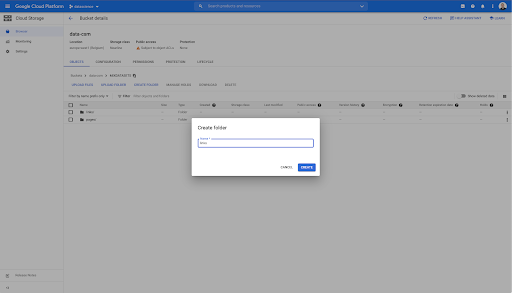
从 Oncrawl 导出数据集
现在我们已经设置了要保存数据的空间,我们需要从 Oncrawl 中导出它。 使用 Oncrawl 导出到 Google Cloud Storage 存储桶特别容易,因为我们可以以正确的格式导出数据,并将其直接保存到存储桶中。 这消除了任何额外的步骤。
创建 API 密钥
从 Oncrawl 以 Parquet 格式导出 BigQuery 的数据将需要使用 API 密钥以编程方式代表 Oncrawl 帐户的所有者对 API 进行操作。 Oncrawl 应用程序允许用户创建命名的 API 密钥,以便您的帐户始终井井有条且干净整洁。 API 密钥还与不同的权限(范围)相关联,以便您可以管理密钥及其用途。
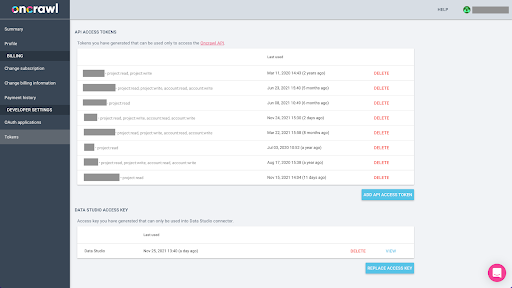
让我们将新密钥命名为“知识会话密钥”。 大数据导出功能需要帐户中的写入权限,因为我们正在创建数据导出。 要执行此操作,我们需要对项目具有读取权限以及对帐户具有读写权限。
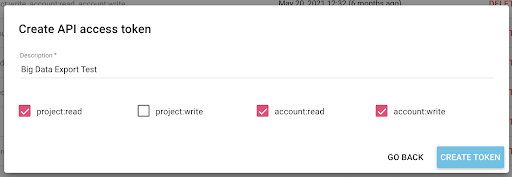
现在我们有了一个新的 API 密钥,我将把它复制到我的剪贴板。
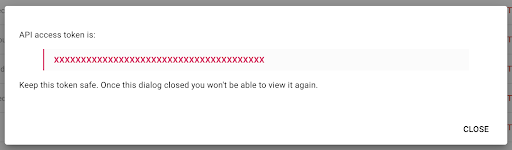
请注意,出于安全原因,您只能复制一次密钥。 如果您忘记复制密钥,则需要删除该密钥并创建一个新密钥。
创建你的 Python 脚本
我为此构建了一个 Google Colab 笔记本,但我将分享下面的代码,以便您可以创建自己的工具或自己的笔记本。
1. 将您的 API 密钥存储在全局变量中
首先,我们引导环境并在名为“Oncrawl Token”的全局变量中声明 API 密钥。 然后,我们为剩下的实验做准备:
#@title 访问 Oncrawl API
#@markdown 在下方提供您的 API 令牌以允许此笔记本访问您的 Oncrawl 数据:
# 你的 ONCRAWL API 代币
ONCRAWL_TOKEN = "" #@param {type:"string"}
!pip 安装监狱
从 IPython.display 导入 clear_output
清除输出()
print('全部加载完毕。') 
2. 创建一个下拉列表以选择您要使用的 Oncrawl 项目
然后,使用该键,我们希望能够通过获取项目列表并从该列表中创建一个下拉小部件来选择我们想要玩的项目。 通过运行第二个代码块,执行以下步骤:
- 我们将调用 Oncrawl API 以使用刚刚提交的 API 密钥获取帐户上的项目列表。
- 从 API 响应中获得项目列表后,我们使用项目名称和项目的起始 URL 将其格式化为列表。
- 我们存储响应中提供的项目 ID。
- 我们构建一个下拉菜单并将其显示在代码块下方。
#@title 通过选择对应的Oncrawl项目选择要分析的网站
导入请求
进口监狱
将 ipywidgets 导入为小部件
导入json
# 获取项目列表
response = requests.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
限制=1000,
排序='名称:asc'
),
headers={ '授权': '承载'+ONCRAWL_TOKEN }
)
json_res = response.json()
#prepare 下拉菜单让用户选择一个项目
项目 = []
对于 json_res['projects'] 中的项目:
projects.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
输出 = 小部件。输出()
dropdown_ purpose = widgets.Dropdown(options = projects, description="Project: ")
def dropdown_project_eventhandler(更改):
output.clear_output()
输出:
展示(项目)
dropdown_purpose.observe(dropdown_project_eventhandler, names='value')
显示(下拉目的) 从这创建的下拉菜单中,您可以看到 API 密钥有权访问的项目的完整列表。 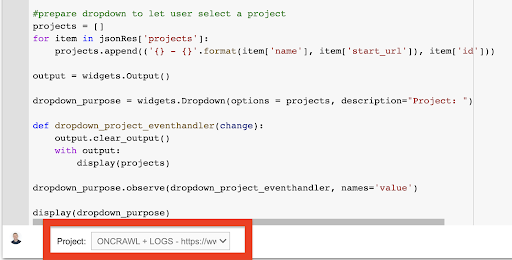
出于今天演示的目的,我们使用的是基于 Oncrawl 网站的演示项目。
3. 创建一个下拉列表以在您要使用的项目中选择爬网配置文件
接下来,我们将决定使用哪个爬网配置文件。 我们想在这个项目中选择一个爬网配置文件。 演示项目有很多不同的爬取配置: 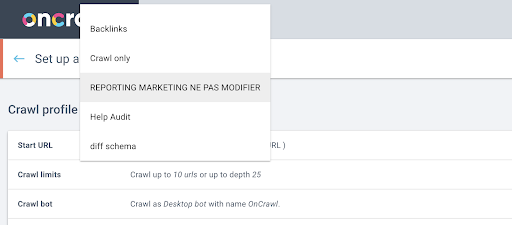
在本例中,我们正在查看 Oncrawl 团队经常用于实验的项目,因此我将选择营销团队使用的爬网配置文件来监控 Oncrawl 网站的性能。 由于这应该是最稳定的爬取配置文件,因此它是今天实验的不错选择。
为了获取爬取配置文件,我们将使用 Oncrawl API 来请求项目中每个爬取配置文件中的最后一次爬取:
- 我们准备查询给定项目的 Oncrawl API。
- 我们将根据“创建于”日期按降序要求返回所有爬网。
导入请求
导入json
将 ipywidgets 导入为小部件
project_id = dropdown_ purpose.value
# 获取项目详情(包括项目中的所有爬取)
project = requests.get("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=True, sort="created_at:desc"),
headers={ '授权': '承载'+ONCRAWL_TOKEN }).json()
# 按爬取配置文件分组爬取(爬取名称)
crawls_by_config = {}
尝试:
在项目中爬行['crawls']:
if crawl['status'] in ["done"]:
如果 crawl['crawl_config']['name'] 不在 crawls_by_config.keys() 中:
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
如果 len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id'])
如果 crawl['status'] == "archived":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = True
例外为 e:
raise Exception("error {} , {}".format(e, project))
# 为下拉选择构建列表
list = [("{} ({})".format(k, len(v['crawl_ids'])), k) for k, v in crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(options = list, description="抓取配置:")
def dropdown_cc_eventhandler(更改):
output.clear_output()
输出:
显示(crawls_by_config)
如果 len(crawls_by_config.values()) == 0:
print('在这个项目中没有找到实时抓取')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, names='value')
显示(dropdown_crawl_configs)运行此代码时,Oncrawl API 将通过“created at”属性的降序向我们响应爬取列表。
然后,由于我们只想关注已完成的爬网,因此我们将遍历爬网列表。 对于状态为“完成”的每一次爬网,我们将保存爬网配置文件的名称并存储爬网 ID。
我们将按爬网配置文件最多保留一次爬网,这样我们就不想暴露太多的爬网。
结果是从项目中的爬网配置文件列表创建的这个新下拉菜单。 我们会选择我们想要的。 这将采取营销团队进行的最后一次爬网: 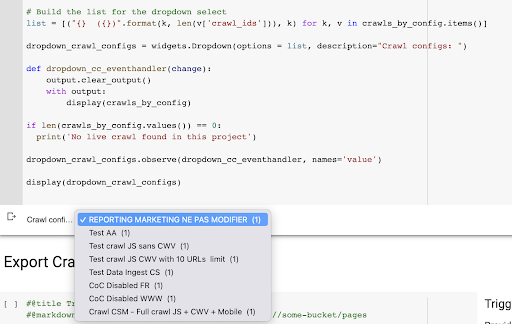
4. 用我们要使用的配置文件识别最后一次爬取
我们已经拥有与所选配置文件中的最后一次爬网关联的爬网 ID。 它隐藏在“crawl_by_config”对象字典中。 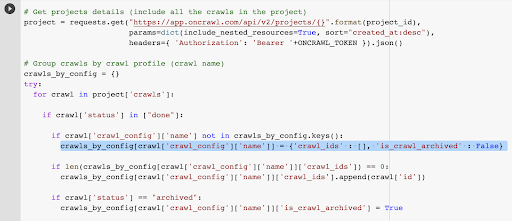
您可以在界面中轻松检查:在此配置文件分析中查找最后完成的爬网。 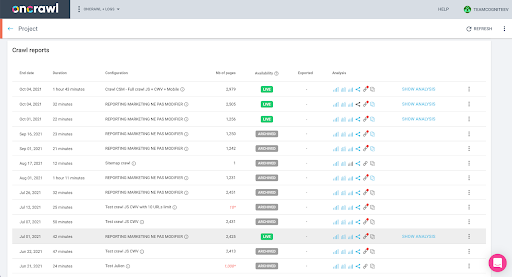
如果我们点击查看分析,会看到爬取ID以E617结尾。 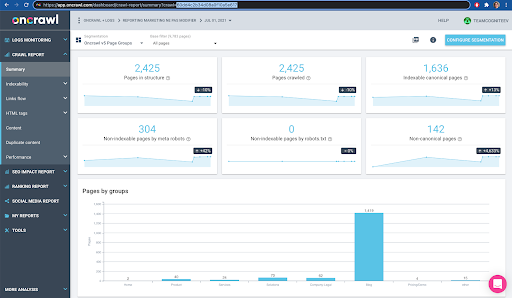
为了今天的演示,我们只记下爬网 ID。
当然,如果您已经知道自己在做什么,您可以跳过我们刚刚介绍的步骤调用 Oncrawl API 以获取项目列表和爬取配置文件的爬取列表:您已经从接口,这个 ID 就是你运行导出所需要的全部。
到目前为止,我们执行的步骤只是为了简化获取给定项目的给定爬网配置文件的最后一次爬网的过程,给定 API 密钥可以访问的内容。 如果您将此解决方案提供给其他用户,或者您希望将其自动化,这可能会很有用。
5.导出爬取结果
现在,我们来看看导出命令:
#@title 触发大数据导出
#@markdown 提供您的 GCS 存储桶和前缀 gs://some-bucket/pages
# 你的 GCS 存储桶
gcs_bucket = #@param {type:"string"}
gcs_prefix = #@param {type:"string"}
# 从给定项目/爬网配置文件中获取最后一次爬网 ID
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# 数据导出查询的模板载荷
有效载荷 = {
“数据导出”:{
"data_type": '页面',
“resource_id”:last_crawl_id,
“输出格式”:“镶木地板”,
“目标”:'gcs',
“目标参数”:{
“gcs_bucket”:gcs_bucket,
“gcs_prefix”:gcs_prefix
}
}
}
# 触发导出
export = requests.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ '授权': '承载'+ONCRAWL_TOKEN }).json()
# 显示 API 响应
展示(出口)
# 存储导出 ID 以供将来使用
export_id = 出口['data_export']['id']我们想要导出到我们之前设置的 Cloud Storage 存储分区。
在其中,我们将导出最后一个爬网 ID 的页面:
- 最后一个爬网 ID 是从爬网 ID 列表中获得的,该列表存储在“crawls_by_config”字典中的某个位置,该字典是在步骤 3 中创建的。
- 我们要在第4步中选择下拉菜单对应的那个,所以我们使用下拉菜单的value属性。
- 然后,我们提取 crawl_ID 属性。 这是一个列表。 我们将保留列表中的前 50 项。 我们需要这样做,因为在第 2 步中,您会记得,当我们创建 crawls_by_config 字典时,我们只为每个配置名称存储了一个爬网 ID。
我设置了输入字段,以便轻松提供 Google Cloud Storage 存储桶和前缀或文件夹,我们要在其中发送导出。 
为了演示的目的,今天,我们将写入我已经设置的文件夹之一中的“混合数据集”文件夹。 当我们在 Google Cloud Storage 中设置存储桶时,您会记得我为“链接”导出和“页面”导出准备了文件夹。
对于第一次导出,我们希望使用 Parquet 文件格式将页面导出到最后一个爬网 ID 的“pages”文件夹中。 
在下面的结果中,您将看到要发送到数据导出端点的有效负载,该端点是使用 API 密钥请求大数据导出的端点:
# 数据导出查询的模板载荷
有效载荷 = {
“数据导出”:{
"data_type": '页面',
“resource_id”:last_crawl_id,
“输出格式”:“镶木地板”,
“目标”:'gcs',
“目标参数”:{
“gcs_bucket”:gcs_bucket,
“gcs_prefix”:gcs_prefix
}
}
}
这包含几个元素,包括您要导出的数据集的类型。 您可以导出页面数据集、链接数据集、集群数据集或结构化数据数据集。 如果您不知道可以做什么,您可以在此处输入错误,当您调用 API 时,您将收到一条消息,指出数据类型的选择必须是页面或链接或集群或结构化数据。 消息如下所示:
{'fields': [{'message': '不是一个有效的选择。 必须是“page”、“link”、“cluster”、“structured_data”之一。',
“名称”:“数据类型”,
'类型':'invalid_choice'}],
'类型':'invalid_request_parameters'}
出于今天实验的目的,我们将分别导出页面数据集和链接数据集。

让我们从页面数据集开始。 当我运行这个代码块时,我打印了 API 调用的输出,如下所示:
{'data_export': {'data_type': '页面',
'export_failure_reason':无,
'id': 'XXXXXXXXXXXXXX',
'输出格式':'镶木地板',
“输出格式参数”:无,
'output_row_count':无,
'output_size_in_bytes: 1634460016000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'状态':'请求',
'目标':'gcs',
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASETS/pages/'}}}
这使我可以看到已请求导出。
如果我们想检查导出的状态,这很简单。 使用我们在此代码块末尾保存的导出 ID,我们可以随时通过以下 API 调用请求导出状态:
# 出口状况
export_status = requests.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ '授权': '承载'+ONCRAWL_TOKEN }).json ()
显示(出口状态)
这将指示状态作为返回的 JSON 对象的一部分:
{'data_export': {'data_type': '页面',
'export_failure_reason':无,
'id': 'XXXXXXXXXXXXXX',
'输出格式':'镶木地板',
“输出格式参数”:无,
'output_row_count':无,
'output_size_in_bytes':无,
'requested_at':1638350549000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'状态':'出口',
'目标':'gcs',
'target_parameters': {'gcs_bucket': 'data-csm',
'gcs_prefix': 'MIXDATASETS/pages/'}}} 导出完成后( 'status': 'DONE' ),我们可以返回 Google Cloud Storage。
如果我们查看存储桶,然后进入“链接”文件夹,这里还没有任何内容,因为我们导出了页面。 
但是,当我们查看“pages”文件夹时,我们可以看到导出成功。 我们有一个 Parquet 文件: 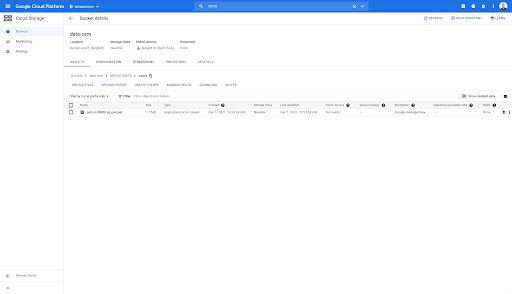
在此阶段,页面数据集已准备好导入 BigQuery,但首先我们将重复上述步骤以获取链接的 Parquet 文件:
- 确保设置链接前缀。
- 选择“链接”数据类型。
- 再次运行此代码块以请求第二次导出。

这将在“links”文件夹中生成一个 Parquet 文件。
创建 BigQuery 数据集
在导出运行时,我们可以继续前进并开始在 BigQuery 中创建数据集,并将 Parquet 文件导入单独的表中。 然后我们将把这些表连接在一起。
我们现在想做的是使用 Google Big Query,它是 Google Cloud Platform 的一部分。 您可以使用屏幕顶部的搜索栏,或直接访问 https://console.cloud.google.com/bigquery。
为您的工作创建数据集
我们需要在 Google BigQuery 中创建一个数据集: 
您需要为数据集提供名称,并选择存储数据的位置。 这很重要,因为它将决定数据处理的位置,并且无法更改。 如果您的数据包含 GDPR 或其他隐私法所涵盖的信息,这可能会产生影响。 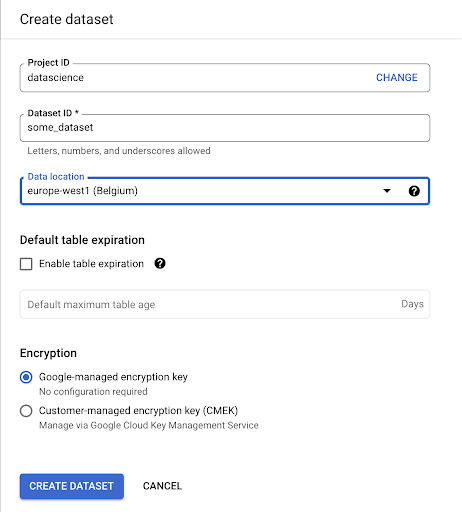
该数据集最初是空的。 当您打开它时,您将能够创建表、共享数据集、复制、删除等。
为您的数据创建表
我们将在这个数据集中创建一个表。 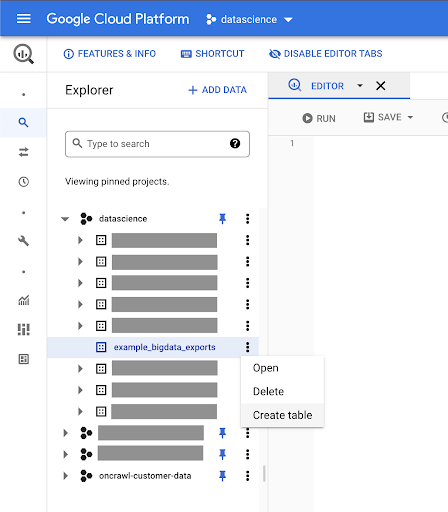
您可以创建一个空表,然后提供架构。 架构是表中列的定义。 您可以定义自己的架构,也可以浏览 Google Cloud Storage 以从文件中选择架构。
我们将使用最后一个选项。 我们将导航到我们的存储桶,然后导航到“页面”文件夹。 让我们选择页面文件。 只有一个文件,所以我们只能选择一个,但如果导出生成了多个文件,我们可以选择所有文件。 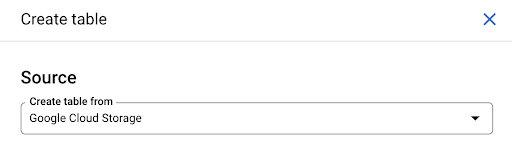
当我们选择文件时,它会自动检测它是 Parquet 文件格式。 我们要创建一个名为“pages”的表,并且模式将由源文件定义。 
当我们加载 Parquet 文件时,它嵌入了一个模式。 换句话说,我们正在创建的表的列的定义将从 Parquet 文件中已经存在的模式中推断出来。 这实际上是魔法的一部分发生的地方。
让我们继续前进,简单地从 Parquet 文件创建表。 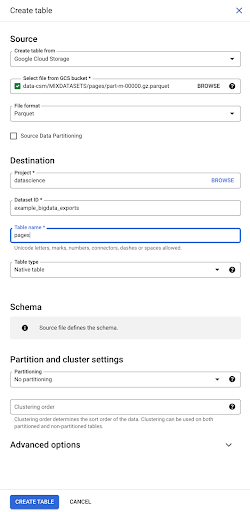
在左侧边栏中,我们现在可以看到数据集中出现了一个表格,这正是我们想要的:
因此,我们现在有了 pages 表的模式,其中包含从 Parquet 文件自动推断的所有字段。 我们有 Inrank,页面的深度,如果页面是重定向等等等等: 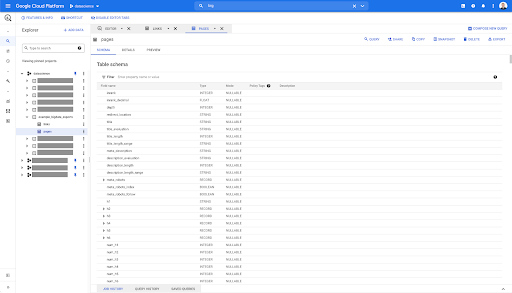
其中大部分字段与通过 Oncrawl Data Studio 连接器在 Data Studio 中提供的字段相同,并且与您在 Oncrawl 界面的 Data Explorer 中看到的字段相同。 
但是,存在一些差异。 当我们使用原始大数据导出时,您拥有所有原始数据。
- 在 Data Studio 中,一些字段被重命名,一些字段被隐藏,一些字段被添加,例如状态。
- 在 Data Explorer 中,一些字段就是我们所说的“虚拟字段”,这意味着它们可能是一种通往底层字段的快捷方式。 Data Explorer 中可用的这些虚拟字段不会在模式中列出,但可以根据 Parquet 文件中可用的内容重新创建它们。
现在让我们关闭此表并为链接再次执行此操作。
对于链接表,架构要小一些。 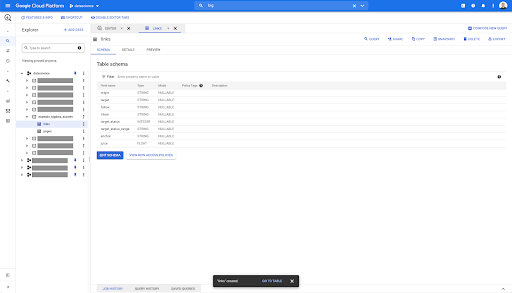
它仅包含以下字段:
- 链接的来源,
- 链接的目标,
- 跟随属性,
- 内部属性,
- 目标状态,
- 目标状态的范围,
- 锚文本,和
- 链接购买的果汁或股权。
在 BigQuery 中的任何表上,当您单击预览选项卡时,您可以在不查询数据库的情况下预览该表: 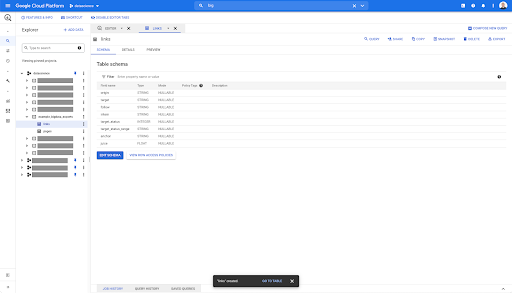
这使您可以快速查看其中的可用内容。 在上面链接表的预览中,您可以预览每一行和所有列。
在某些 Oncrawl 数据集中,您可能会看到一些跨越多行的行。 我没有给你的例子,但如果是这种情况,那是因为某些字段包含值列表。 例如,在页面上的 h2 标题列表中,单行将跨越 Big Query 中的多行。 如果我们看到一个例子,我们稍后会看。
创建您的查询
如果您从未在 BigQuery 中创建过查询,那么现在是时候尝试一下以熟悉它的工作原理了。 BigQuery 使用 SQL 来查找数据。
查询的工作原理
作为一个例子,让我们看看所有的 URL 和它们的排名……
选择网址,排名...
从页面数据集...
选择 url,inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` ...
页面的状态码是 200…
选择 url,inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 ...
并且只保留前 10 个结果:
选择 url,inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 10
当我们运行这个查询时,我们将获得状态码为 200 的页面列表的前 10 行。
可以修改这些属性中的任何一个。 f 我想要 1000 行而不是 10 行,我可以设置 1000 行:
选择 url,inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 1000
如果我想排序,我可以用“order-by”来做到这一点:这将给我所有按 Inrank 降序排序的行。
选择 url,inrank FROM `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
这是我的第一个查询。 如果需要,我可以保存它,这将使我能够在以后重用此查询: 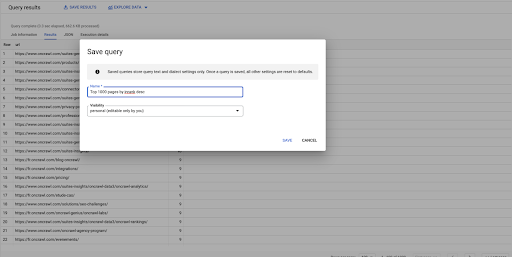
使用查询回答简单问题:列出所有指向 301 状态页面的内部链接
现在我们知道了如何编写查询,让我们回到最初的问题。
我们想回答数据问题,无论是简单的还是复杂的。 让我们从一个简单的问题开始,例如“指向具有 301(重定向)状态的页面的所有内部链接是什么,我在哪里可以找到它们?”
创建新查询
我们将从探索它是如何工作的开始。
我想要来自“链接”数据库的以下元素的列:
- 起源
- 目标
- 目标状态码
从 `datascience-oncrawl.example_bigdata_exports.links` 中选择来源、目标、目标状态
我只想将这些限制为内部链接,但假设我不记得列的名称或指示链接是内部链接还是外部链接的值。 我可以去架构查找它,并使用预览来查看值: 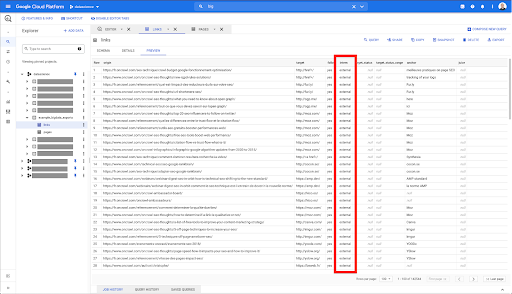
这告诉我该列名为“intern”,值的可能范围是“external”或“internal”。
在我的查询中,我想指定“intern 在哪里”,并且现在将结果限制为前 100 个:
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' LIMIT 100
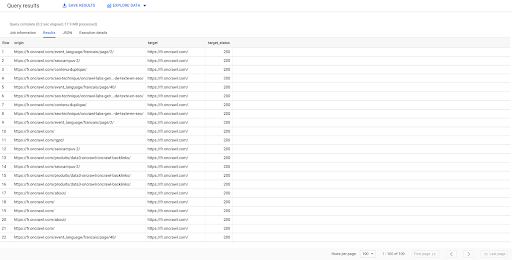
上面的结果显示了链接列表及其目标状态。 我们只有内部链接,我们有 100 个,如查询中所指定。
如果我们只想有指向该点的内部链接到重定向页面,我们可以说“intern like internal and target status 等于 301”:
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' AND target_status = 301
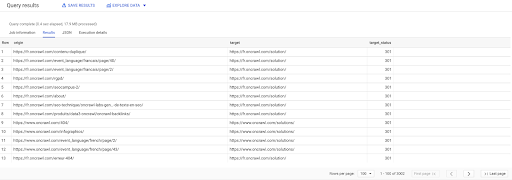
如果我们不知道其中有多少,我们可以运行这个新查询,我们将看到有 3002 个目标状态为 301 的内部链接。
加入表格:查找指向重定向页面的链接的最终状态代码
在网站上,您通常有指向被重定向页面的链接。 我们想知道他们被重定向到的页面的状态代码(或最终目标 URL)。
在一个数据集中,您有关于链接的信息:原始页面、目标页面及其状态代码(如 301),但没有重定向页面指向的 URL。 另一方面,您拥有有关重定向及其最终目标的信息,但没有找到指向它们的链接的原始页面。
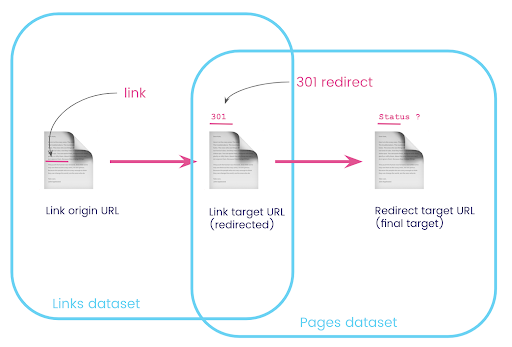
让我们分解一下:
首先,我们需要指向重定向的链接。 让我们把这个写下来。 我们想要:
- 起源。
- 目标。 目标必须具有 301 状态代码。
- 重定向的最终目标。
换句话说,在链接数据集中,我们想要:
- 链接的由来
- 链接的目标
在 pages 数据集中,我们想要:
- 重定向的所有目标
- 重定向的最终目标
这会给我们一个类似的查询:
从 `datascience-oncrawl.example_bigdata_exports.pages` 作为页面 WHERE status_code = 301 或 status_code = 302 选择 url、final_redirect_location、final_redirect_status
这应该给我等式的第一部分。
现在我需要所有链接到页面的链接,这些链接是我刚刚创建的查询的结果,为我的数据集使用别名,并将它们加入链接目标 URL 和页面 URL。 这对应于本节开头图表中两个数据集的重叠区域。
选择 链接.原点, pages.url, pages.final_redirect_location, pages.final_redirect_status 从 `datascience-oncrawl.example_bigdata_exports.pages` AS 页面 加入 `datascience-oncrawl.example_bigdata_exports.links` AS 链接 上 links.target = pages.url 在哪里 pages.status_code = 301 或 pages.status_code = 302 订购方式 原点 ASC
在查询结果中,我可以重命名列以使事情更清楚,但我已经可以看到我有一个来自第一列中的页面的链接,该链接转到第二列中的页面,而第二列中的页面又被重定向到第三列中的页面。 在第四列,我有最终目标的状态码: 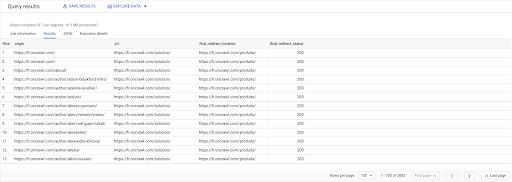
现在我可以知道哪些链接指向的重定向页面无法解析为 200 页。 例如,它们可能是 404,这为我提供了要更正的链接的优先级列表。
我们之前看到了如何保存查询。 我们还可以保存结果,最多可以保存 16000 行结果: 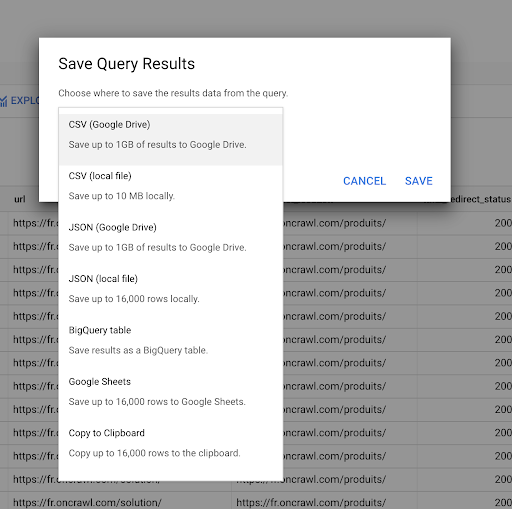
然后,我们可以以许多不同的方式使用这些结果。 这里有一些例子:
- 我们可以在本地将其保存为 CSV 或 JSON 文件。
- 我们可以将其保存为 Google 表格电子表格并与团队的其他成员共享。
- 我们也可以直接将其导出到 Data Studio。
数据作为战略优势
有了所有这些可能性,战略性地使用复杂问题的答案很容易。 您可能已经有将 BigQuery 结果连接到 Data Studio 或其他数据可视化平台的经验,或者您可能已经制定了将信息推送到工程团队甚至商业智能或数据分析工作流程的流程。
如果您已将本文中的步骤作为流程的一部分包含在内,请记住您可以自动执行 BigQuery 中的所有步骤:我们在本文中执行的所有操作也可以通过 BigQuery API 访问。 这意味着它们可以作为脚本或自定义工具的一部分以编程方式运行。
无论您下一步做什么,第一步始终是访问原始 SEO 和网站数据。 我们相信这种对数据的访问是技术分析中最重要的部分之一:使用 Oncrawl,您将始终可以完全访问您的原始数据。
访问数据还意味着您可以超越 Oncrawl 界面中的可能性,探索数据之间的所有关系,无论您提出的问题多么复杂。