
SEO日志文件分析介绍
已发表: 2021-05-17日志分析是分析搜索引擎如何读取我们网站的最彻底的方法。 SEO、数字营销人员和网络分析专家每天都使用显示流量、用户行为和转化图表的工具。 SEO 通常会尝试了解 Google 如何通过 Google Search Console 抓取他们的网站。
那么……为什么 SEO 应该分析其他工具来检查搜索引擎是否正确读取了网站? 好的,让我们从基础开始。
什么是日志文件?
日志文件是服务器 Web 为网站上机器人或用户请求的每个资源写入一行的文件。 每行包含有关请求的数据,其中可能包括:
调用方 IP、日期、所需资源(页面、.css、.js、……)、用户代理、响应时间……
一行看起来像这样:
66.249.**.** - - [13/Apr/2021:00:07:31 +0200] "GET /***/x_*** HTTP/1.1" 200 40960 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "www.***.it" "-"
可抓取性和可更新性
每个页面都有三种基本的 SEO 状态:
- 可抓取
- 可转位
- 可排序的
从日志分析的角度来看,我们知道一个页面,为了被索引,必须被机器人读取。 同样,必须重新抓取已被搜索引擎索引的内容,以便在搜索引擎的索引中进行更新。
不幸的是,在 Google Search Console 中,我们没有这个级别的详细信息:我们可以检查 Googlebot 在过去三个月内阅读了网站上的页面的次数以及网络服务器的响应速度。
我们如何检查机器人是否已阅读页面? 当然,通过使用日志文件和日志文件分析器。
为什么 SEO 需要分析日志文件?
日志文件分析允许 SEO(以及系统管理员)了解:
- 机器人读取的内容
- 机器人多久阅读一次
- 就花费的时间(毫秒)而言,爬网的成本是多少
日志分析工具可以通过按“路径”、文件类型或响应时间对信息进行分组来分析日志。 一个出色的日志分析工具还允许我们将从日志文件中获取的信息与其他数据源(如 Google Search Console(点击次数、展示次数、平均排名)或 Google Analytics)相结合。
Oncrawl 日志分析器
 学到更多
学到更多在日志文件中查找什么?
日志文件中的主要重要信息之一是日志文件中没有的信息。 真的,我不是在开玩笑。 了解为什么页面未编入索引或未更新到其最新版本的第一步是检查机器人(例如 Googlebot)是否已阅读它。
在此之后,如果页面经常更新,检查机器人读取页面或站点部分的频率可能很重要。
下一步是检查机器人最常阅读哪些页面。 通过跟踪它们,您可以检查这些页面是否:
- 值得经常阅读
- 或者经常被阅读,因为页面上的某些东西会导致不断的、失控的变化
例如,几个月前,我工作的一个网站在一个奇怪的 URL 上出现了非常高的 bot 阅读频率。 机器人发现这个页面来自一个由 JS 脚本创建的 URL,并且这个页面被标记了一些调试值,这些值在每次页面加载时都会改变……在这个启示之后,一个好的 SEO 肯定可以找到正确的解决方案来解决这个问题爬行预算漏洞。
抓取预算
抓取预算? 它是什么? 每个站点都有与搜索引擎及其机器人相关的隐喻预算。 是的:Google 为您的网站设置了一种预算。 这不会记录在任何地方,但您可以通过两种方式“计算”它:
- 检查 Google Search Console 抓取统计报告
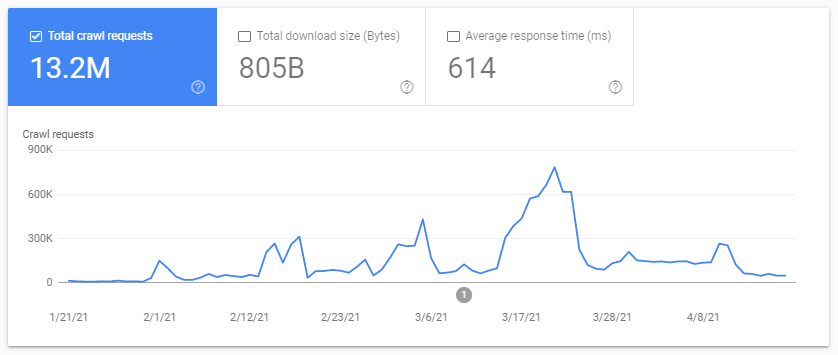
- 检查日志文件,通过包含“Googlebot”的用户代理对它们进行 grepping(过滤)(如果您确保这些用户代理与正确的 Google IP 匹配,您将获得最佳结果…… )
当网站更新有趣的内容、定期更新内容或网站收到良好的反向链接时,抓取预算会增加。
如何在您的网站上花费抓取预算可以通过以下方式管理:
- 内部链接(也关注/nofollow!)
- 无索引/规范
- robots.txt(小心:这会“阻止”用户代理)
僵尸页面
对我来说,“僵尸页面”是在相当长的一段时间内没有任何自然流量或机器人访问但有指向它们的内部链接的所有页面。
这种类型的页面可能会使用过多的抓取预算,并且由于内部链接可能会获得不必要的页面排名。 这种情况可以解决:
- 如果这些页面对访问该站点的用户有用,我们可以将它们设置为 noindex 并将指向它们的内部链接设置为 nofollow (或使用 disallow robots.txt,但要小心... )
- 如果这些页面对访问该站点的用户没有用,我们可以删除它们(并返回状态码 410 或 404)并删除所有内部链接。
使用 Oncrawl,我们可以根据以下内容创建“僵尸报告”:
- GSC 展示次数
- GSC 点击次数
- GA 会议
我们还可以使用日志事件来发现僵尸页面:例如,我们可以定义一个 0 事件过滤器。 最简单的方法之一是创建分段。 在下面的示例中,我使用以下条件过滤所有页面:没有 Googlebot 命中但具有 Inrank(这意味着这些页面具有指向它们的内部链接)。 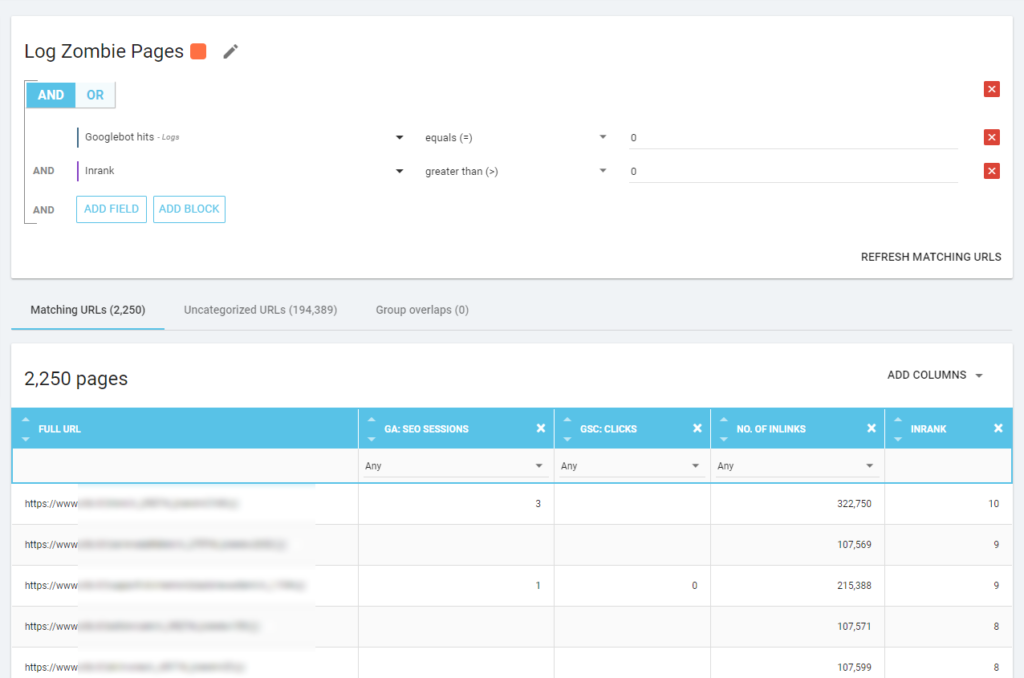
因此,现在我们可以在所有 Oncrawl 报告中使用此分段。 这让我们可以从任何图形中获得洞察力,例如:有多少“日志僵尸页面”返回 200 状态码? 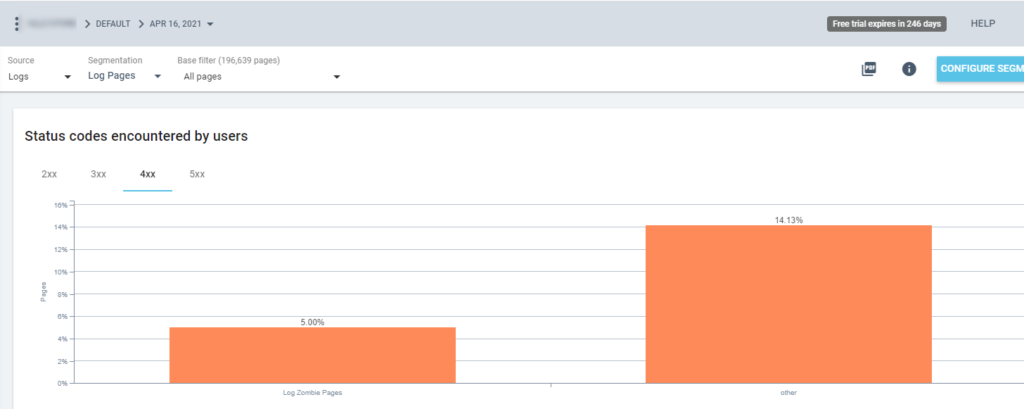
孤立页面
对我来说,值得仔细查看的“孤儿页面”是所有在重要指标(GA Session、GSC Impression、Log hits...)上具有高价值且没有任何内部链接指向它们以共享页面排名的页面并指出页面重要性。
与“僵尸页面”一样,要创建基于日志的报告,最好的方法是创建新的细分。 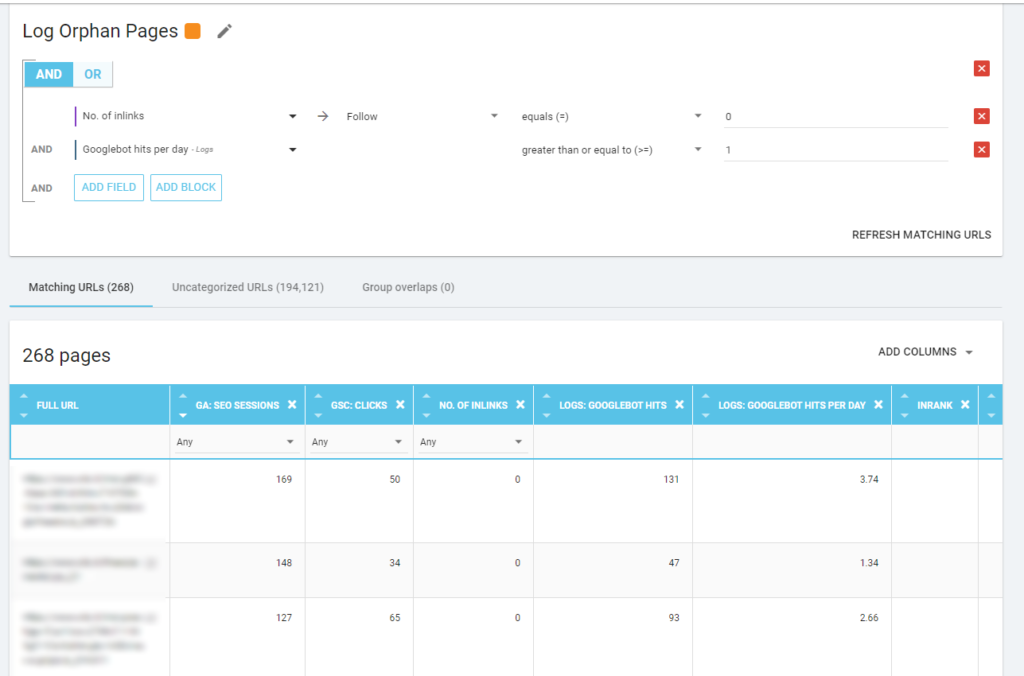
哇,有很多页面有会话和点击,没有链接!
在查看基于“零关注链接”的报告时,请注意抓取状态:Oncrawl 是能够抓取所有网站,还是只能抓取几页? 您可以在项目的主页上看到: 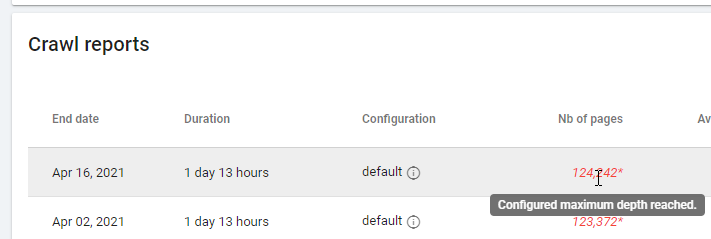
如果已达到最大深度:

- 检查您的爬网配置
- 检查您的网站结构
日志文件和 Oncrawl
Oncrawl 在其默认仪表板中提供什么?
实时日志
此仪表板对于检查有关机器人如何读取您的站点的关键信息非常有用,只要机器人访问该站点并且在完全处理来自日志文件的信息之前。 为了充分利用它,我建议经常上传日志文件:您可以通过 FTP、Amazon S3 等连接器进行上传,也可以通过 Web 界面手动上传。
第一个图表显示了您的网站被阅读的频率,以及被哪个机器人阅读。 在您可以在下面看到的示例中,我们可以检查桌面访问与移动访问。 在这种情况下,我们将仅为 Googlebot 过滤的日志文件发送到 Oncrawl: 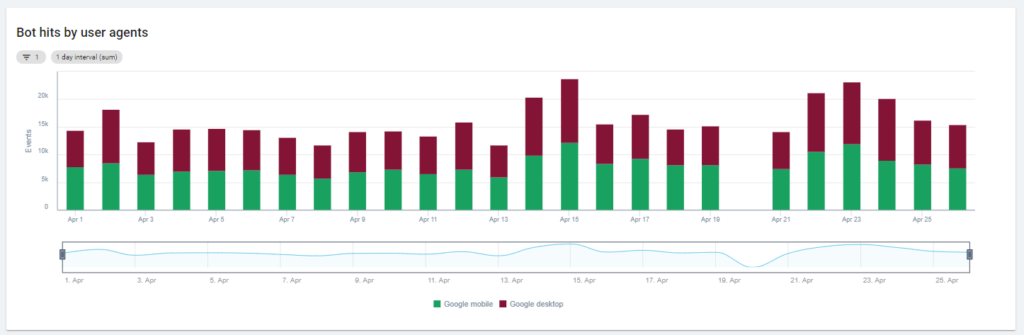
有趣的是,移动阅读量仍然很高:这是否正常? 这取决于... 我们正在分析的网站仍处于“移动优先索引”中,但它不是一个完全响应的网站:它是一个动态服务网站(正如 Google 所说),Google 仍然检查两个版本!
另一个有趣的图表是“Bot hits by page group”。 默认情况下,Oncrawl 基于 URL 路径创建组。 但是我们可以手动设置组,以便将最有意义的 URL 分组在一起进行分析。 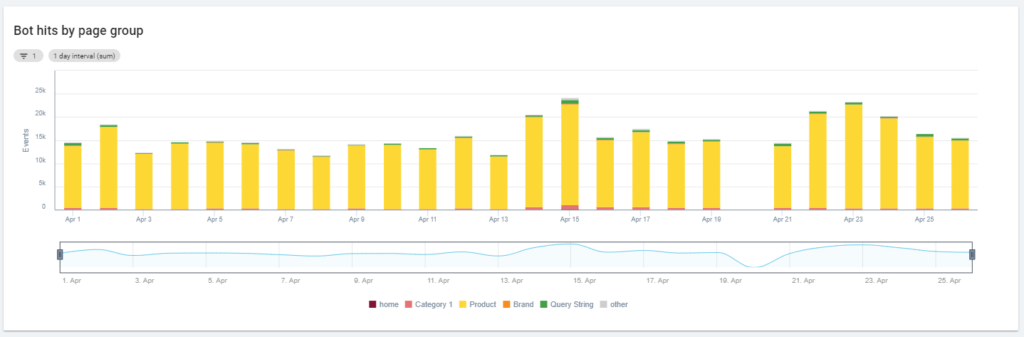
如您所见,黄色获胜! 它表示带有产品路径的 URL,因此它产生如此高的影响是正常的,特别是因为我们有 Google 付费购物广告系列。
而且……是的,我们刚刚确认 Google 使用标准 Googlebot 来检查与商家 Feed 相关的产品状态!
爬行行为
此仪表板显示与“实时日志”类似的信息,但此信息已完全处理并按天、周或月汇总。 在这里您可以设置一个日期时间段(开始/结束时间),该时间段可以随时返回。 有两个新图表可以进一步进行日志分析:
- 爬取行为:检查已爬取页面与新爬取页面的比例
- 每天的抓取频率
阅读这些图表的最佳方法是将结果与站点操作联系起来:
- 你移动页面了吗?
- 你更新了一些部分吗?
- 你发布新内容了吗?
搜索引擎优化影响
对于 SEO,监控优化的页面是否被机器人读取很重要。 正如我们所写的“孤立页面”,确保机器人读取最重要/更新的页面非常重要,以便搜索引擎可以使用最新的信息进行排名。
Oncrawl 使用“活动页面”的概念来指示从搜索引擎接收自然流量的页面。 从这个概念出发,它显示了一些基本的数字,例如:
- 搜索引擎优化访问
- SEO活动页面
- SEO活跃率(活跃页面占所有爬取页面的比例)
- Fresh Rank(机器人第一次阅读页面和第一次自然访问之间的平均时间)
- 未抓取的活动页面
- 新活动页面
- 每天活跃页面的抓取频率
正如 Oncrawl 的理念一样,只需单击一下,我们就可以深入信息湖,按我们点击的指标进行过滤! 例如:哪些是未爬取的活动页面? 一键... 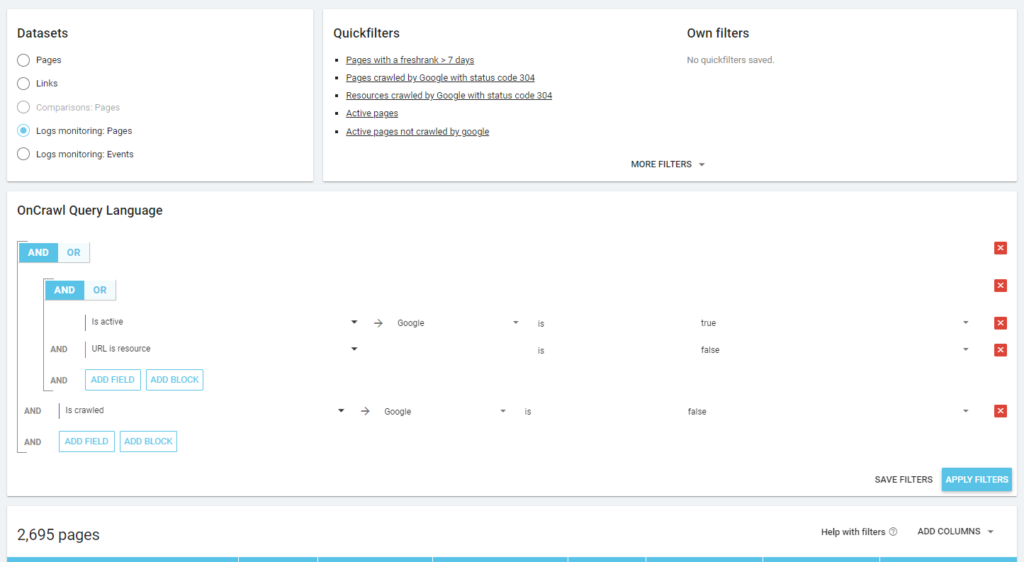
探索理智
最后一个仪表板允许我们检查 bo 的抓取质量,或者更准确地说,检查网站向搜索引擎展示自己的情况:
- 状态码分析
- 每日状态码分析
- 按页组的状态码分析
- 响应时间分析
良好的 SEO 工作必须:
- 减少来自内部链接的 301 响应的数量
- 从内部链接中删除 404/410 响应
- 优化响应时间,因为 Googlebot 抓取质量与响应时间直接相关:尝试将您网站上的响应时间减少一半,您会看到(几天后)抓取的页面数量会翻倍。
日志分析和 Oncrawl 的数据资源管理器的科学
到目前为止,我们已经看到了标准的 Oncrawl 报告以及如何使用它们通过分段和页面组获取自定义信息。
但是日志分析的核心是了解如何发现错误。 通常,分析的起点是检查峰值并将它们与流量和您的目标进行比较:
- 爬取次数最多的页面
- 最少抓取的页面
- 爬取次数最多的资源(不是页面)
- 按文件类型抓取频率
- 3xx / 4xx 状态码的影响
- 5xx 状态码的影响
- 爬取速度较慢的页面
- …
你想更深入吗? 好……您需要添加数据。 Oncrawl 提供了一个非常强大的工具,比如 Data Explorer。
正如您在之前的屏幕截图中看到的(未抓取的活动页面),您可以根据您的分析框架创建所有您想要的报告。
例如:
- 最糟糕的自然流量页面,被机器人抓取很多
- 机器人抓取过多的最佳自然流量页面
- 具有大量 SERP 印象的较慢页面
- …
下面你可以看到我是如何检查哪些是与 SEO 会话数量相关的最常被抓取的页面: 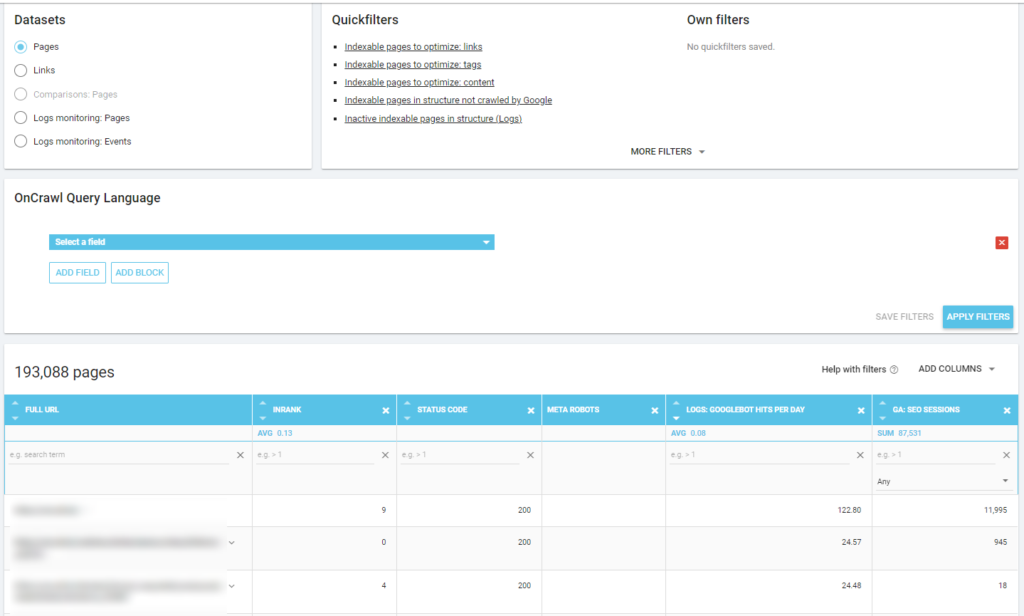
外卖
日志分析并非严格的技术性:要以最好的方式进行,我们需要结合技术技能、SEO 技能和营销技能。
很多时候,分析被排除在“搜索引擎优化清单”之外,因为我们的客户无权访问日志文件,或者因为它可能是一项昂贵的分析。
现实情况是,日志是真正检查机器人在我们网站上的位置以及了解我们的服务器如何响应它们的唯一来源。
像 Oncrawl 这样的工具可以大大降低技术要求:只需上传日志文件并开始分析它们!