
使用 OnCrawl 的 5 个省时技巧
已发表: 2017-06-21如何利用高级 OnCrawl 功能来提高日常 SEO 监控的效率。
OnCrawl 是一款功能强大的 SEO 工具,可帮助您监控和优化搜索引擎对电子商务网站、在线发布商或应用程序的可见性。 该工具是围绕一个简单的原则构建的:帮助流量经理在分析过程和日常 SEO 项目管理中节省时间。
除了作为现场审计工具,它基于一个结合所有网站数据的 API 支持的 SaaS 平台,同时也是一个日志分析器,可以简化从日志服务器文件中提取和分析数据。
OnCrawl 的可能性相当广泛,但需要掌握。 在本文中,我们将分享 5 个节省时间的技巧,供您日常使用我们的 SEO 爬虫和日志分析器。
1# 如何对 HTTP 和 HTTPS url 进行分类
HTTPS 迁移是 SEO 领域的热门话题。 为了完美地处理这个关键步骤,精确地跟踪两种协议上的机器人行为非常重要。
经验表明,机器人需要或多或少的时间才能完全从 HTTP 切换到 HTTPS。 平均而言,这种转变需要几周或几个月的时间,具体取决于与网站质量和迁移相关的外部和内部因素。
为了准确了解您的抓取预算受到严重影响的过渡阶段,监控机器人点击率是明智之举。 因此有必要分析服务器日志。 作为普通用户,该机器人会在他提出的每个页面、资源和请求上留下标记。 您的日志拥有传递这些调用的端口。 因此,您可以验证 HTTPS 网站的迁移质量。
设置专用 http vs https 页面组的方法
在您的高级项目主页上,您可以在右上角找到一个“设置”按钮。 然后,选择“配置页面组”菜单。 在这里,创建一个新的“创建组集”并将其命名为“HTTP vs HTTPS”。
为了访问您的日志,选择“我想在日志监控和交叉分析仪表板上使用此集”选项很重要。
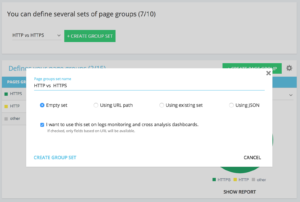
- HTTPS:“完整网址”/“开头”/https
- HTTP : “完整 url”/“不以开头”/https
保存后,您将访问 HTTPS 迁移的视图(如果您在日志行中添加了请求端口。您可以查看我们的指南。)
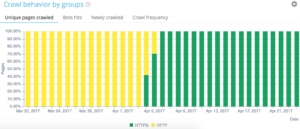
我们的快速过滤器可以在数据资源管理器中找到。 它们旨在简化对一些重要 SEO 指标的访问,例如指向 404、500 或 301/302 的链接,页面太慢或太差等。
以下是完整列表:
- 404 错误
- 5xx 错误
- 活动页面
- Google 未抓取的活动页面
- Google 遇到的状态代码不同于 200 的活动页面
- 规范不匹配
- 未设置规范
- 可索引页面
- 没有可索引的页面
- 孤立的活动页面
- 孤立页面
- Google 抓取的页面
- Google 和 OnCrawl 抓取的页面
- 结构中的页面未被 Google 抓取
- 指向 3xx 错误的页面
- 指向 4xx 错误的页面
- 指向 5xx 错误的页面
- h1 错误的页面
- h2 不好的页面
- 元描述错误的页面
- 标题错误的页面
- 存在 HTML 重复问题的页面
- 链接少于 10 个的页面
- 重定向 3xx
- 页面太重
- 页面太慢
但有时,这些 QuickFilters 并不能解决您的所有业务问题。 在这种情况下,您可以从其中一个开始,并通过在过滤器中添加片段并保存它们以在您连接到该工具时快速找到您的过滤器来创建您的“自己的过滤器”。
例如,从指向 4xx 的链接中,您可以选择过滤具有空锚点的链接:“Anchor”/“is”/“”并保存该过滤器。 保存后,可以根据需要多次修改。
您现在可以直接访问“Own”部分底部的“Select a Quickfilter”列表中的特定“Quickfilter”,如下面的屏幕截图所示。
3#如何设置DataLayer相关的自定义字段?
例如,当您定义分析工具标签时,您可以使用相关页面类型的细分。 该特定代码非常有趣,可以将来自 OnCrawl 的数据与您的外部数据进行分割或交叉。
为了让您为您的分析创建一个“关键列”,我们可以在抓取过程中提取这些代码片段并将它们作为您项目的一种数据带回来。
借助正则表达式或 XPath,“自定义字段”选项可以从源代码页中抓取任何元素。 这些语言有自己的定义和规则。 您可以在此处找到有关 XPath 的信息和有关 regex 的信息。
用例 1:从页面源代码中提取数据层数据
代码分析:


解决方案:使用“正则表达式”:s.prop2=”([^”]+)”/提取:单值/字段格式:值

- 查找 s.prop2=” 字符串
- 刮掉所有不是“的字符(要提取的数据后面的第一个字符)
- 要提取的字符串可以在“结束”之前找到
爬取后,在数据资源管理器中,您将在 sProp2、sProp3 列或您的字段名称中找到提取的数据:

使用 XPATH
代码分析:
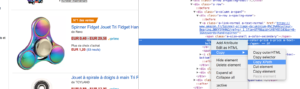
您只需要直接从 Chrome 代码分析器中复制/粘贴要抓取的 Xpath 元素。 请注意,如果代码是用 JavaScript 呈现的,您将需要设置一个自定义抓取项目。 Xpath 语言非常强大且难以操作,因此如果您需要帮助,请致电我们的专家。
用例 3:在接收阶段测试分析标签的存在
使用正则表达式
代码分析:

解决方案:使用“正则表达式”:'_setAccount','UA-364863-11' / 提取:检查是否存在
如果找到字符串,您将在 Data Explorer 中获得“true”,反之则为“false”。
4# 如何可视化您网站各个部分的 Google 抓取频率
抓取预算是任何 SEO 关注的核心。 它与“页面重要性”概念和 Google 的抓取调度密切相关。 我们知道这些原则,自 2012 年以来在谷歌专利中引入,让山景城社会优化专门用于网络爬虫的资源。
Google 不会在您网站的每个部分花费相同的精力。 它在您网站各个部分的抓取频率可让您准确了解您的网页在 Google 眼中的重要性。
谷歌机器人会更多地抓取重要页面,因为抓取预算与页面排名技巧密切相关。
OnCrawl Advanced 项目让您在“日志监控”/“Crawl Behavior”/“Crawl Behavior By Group”部分原生查看爬取预算。
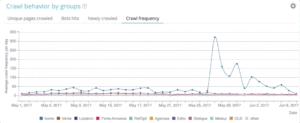
可以看到“首页”组的爬取频率最高。 这很正常,因为谷歌一直在寻找新文章,而且它们通常都列在主页上。 页面重要性理念与 Google Freshness 概念密切相关。 您的主页是确定您的 Google 抓取预算优先级的最重要的页面。 然后,针对深度和流行度将优化传播到其他页面。
然而,很难看到频率差异。 因此,您需要单击要删除的组(通过单击图例)并查看显示的数据。
5# 如何在迁移后从 URL 列表中测试状态代码
当您想从一组 URL 中快速测试状态代码时,可以修改新爬网的设置:
- 添加所有起始 URL(“添加起始 URL”按钮)
- 将最大深度定义为 1
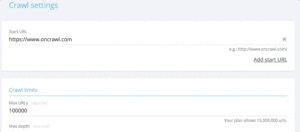
此自定义爬网将返回有关此 url 集的定性数据。
您将能够检查重定向是否设置良好,或者随着时间的推移跟踪状态代码的演变。 想想定期抓取的好处,您将能够自动关注旧网址。
您为什么不通过我们的 API 创建一个自动化仪表板,并在这些方面创建自动化测试监控。
我们希望这些技巧可以帮助您提高使用 OnCrawl 的效率。 我们还有许多高级技巧要向您展示。 例如,请在 Twitter 上与我们分享您的#oncrawlhacks,我们很高兴我们的用户可以像使用我们的工具一样获得乐趣。