
将抓取和日志数据结合起来的 5 个重要理由
已发表: 2018-03-27在 SEO 社区中,对 SEO 中的日志文件数据的了解越来越多。 日志文件实际上是网站上发生的事情的唯一定性表示。 但我们仍然需要能够让他们有效地说话。
准确的 SEO 访问和机器人行为存在于您的日志文件中。 另一方面,抓取报告中的数据可以很好地了解您的现场表现。 在分析您的网站时,您需要结合您的日志文件和抓取数据以突出显示新维度。
本文将向您展示组合爬网和日志文件数据的五种出色方法。 显然,您还可以使用更多。
1#孤页检测和爬取预算优化
什么是孤儿页面? 如果一个 URL 出现在日志中,但不在站点的体系结构中,则该 URL 称为孤立 URL。
谷歌有一个巨大的索引! 随着时间的推移,它会保留它已经在您的网站上发现的所有 URL,即使它们不再存在于架构中(slug 更改、删除的页面、完整的站点迁移、错误的外部链接或转换)。 显然,让 Google 抓取这些所谓的孤立页面会对优化您的抓取预算产生影响。 如果过时的 URL 消耗了您的抓取预算,这会阻止其他 URL 更频繁地被抓取,并且必然会对您的 SEO 产生影响。
在抓取您的网站时,OnCrawl 会遍历所有链接以逐层深入地发现您网站的完整架构。 另一方面,在日志文件监控期间,OnCrawl 编译来自 Google 机器人点击和 SEO 访问的数据。
Google 已知的 URL 与架构中链接的 URL 之间的区别可能非常重要。 旨在纠正被遗忘或损坏的链接并减少孤立页面的 SEO 优化是必不可少的。
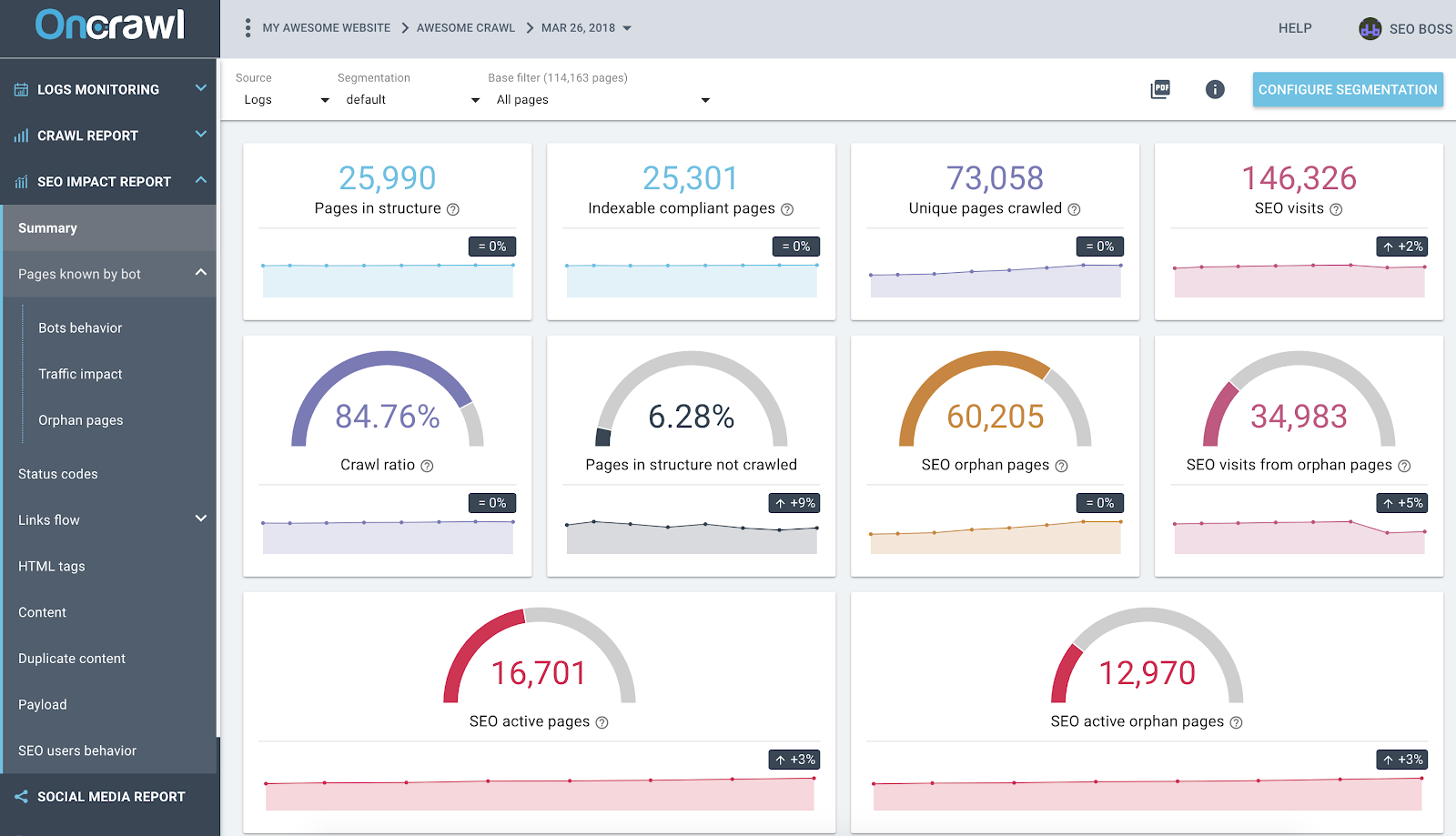
基于 Logs 和 Crawl 跨数据分析的 OnCrawl SEO 影响报告
上面的屏幕截图提供了最先进的日志和爬网数据。 您可以很快注意到:
- 结构中有 25,990 个页面——由我们的爬虫找到,并考虑了它在网站上跟踪的所有链接;
- Google 抓取了 73,058 个页面——这是结构中的 3 倍;
- 84%的爬取率——(OnCrawl爬取页面+来自日志的活跃页面+谷歌爬取页面)/谷歌爬取页面;
- 超过 6% 的内部页面未被抓取——只需点击黑桶即可在数据资源管理器中查看这些页面的列表;
- 60K 孤立页面——结构中的页面与 Google 抓取的页面之间的差异;
- 这些页面上的 34K SEO 访问 – 内部链接似乎存在问题!
最佳实践:OnCrawl 让您只需单击即可探索每个图表或指标背后的数据。 这样,您将获得一个可下载的 URL 列表,这些 URL 直接在您探索的范围内进行过滤。
2#找出哪些网址消耗最多(或最少)的抓取预算
来自 Google 机器人访问的所有事件都为 OnCrawl 数据平台所知。 这使您可以知道 - 对于每个 URL - 根据时间编译的所有数据。
在数据资源管理器中,您可以为每个 URL 添加 bot hits 列(超过 45 天)以及按天和按机器人的命中,这是每天的平均值。 这些信息对于评估 Google 抓取预算的消耗很有价值。 您经常会发现此预算在所有站点上并不统一。
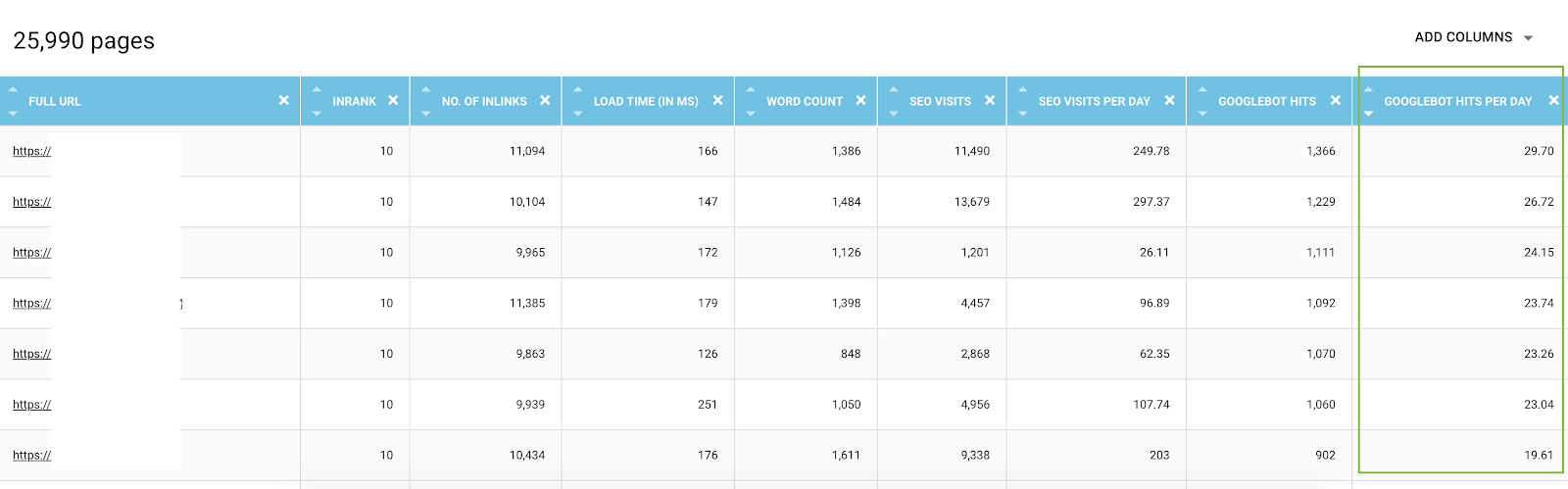
来自数据资源管理器的所有 URL 的列表,其中包含爬网指标并按每天的机器人点击量进行过滤
事实上,某些因素可以触发或减少爬网预算。 然后,我们在本文中建立了一个关于 Google 页面重要性的最重要指标的列表。 深度、指向页面的链接数量、关键字数量、页面速度、InRank(内部流行度)影响机器人的爬行。 您将在以下段落中了解更多信息。
3#了解你最好的SEO页面,你最差的SEO页面并确定页面的成功因素
使用数据资源管理器时,您可以访问有关页面的关键指标——但将数百行和指标放在一起比较可能会很复杂。 使用列来细分每天的机器人点击和每天的 SEO 访问是您数据挖掘的盟友。
- 下载 CS – Bot Hits by Day 和 CS – SEO visit by day JSON 文件;
- 将它们添加为新的分段。
事实上,您可以根据日志分析产生的这两个值创建分段,以便按组对您的页面进行第一次分布。 但您也可以过滤每组这些细分,以在每个 OnCrawl 报告中快速检测哪些页面未达到预期值。
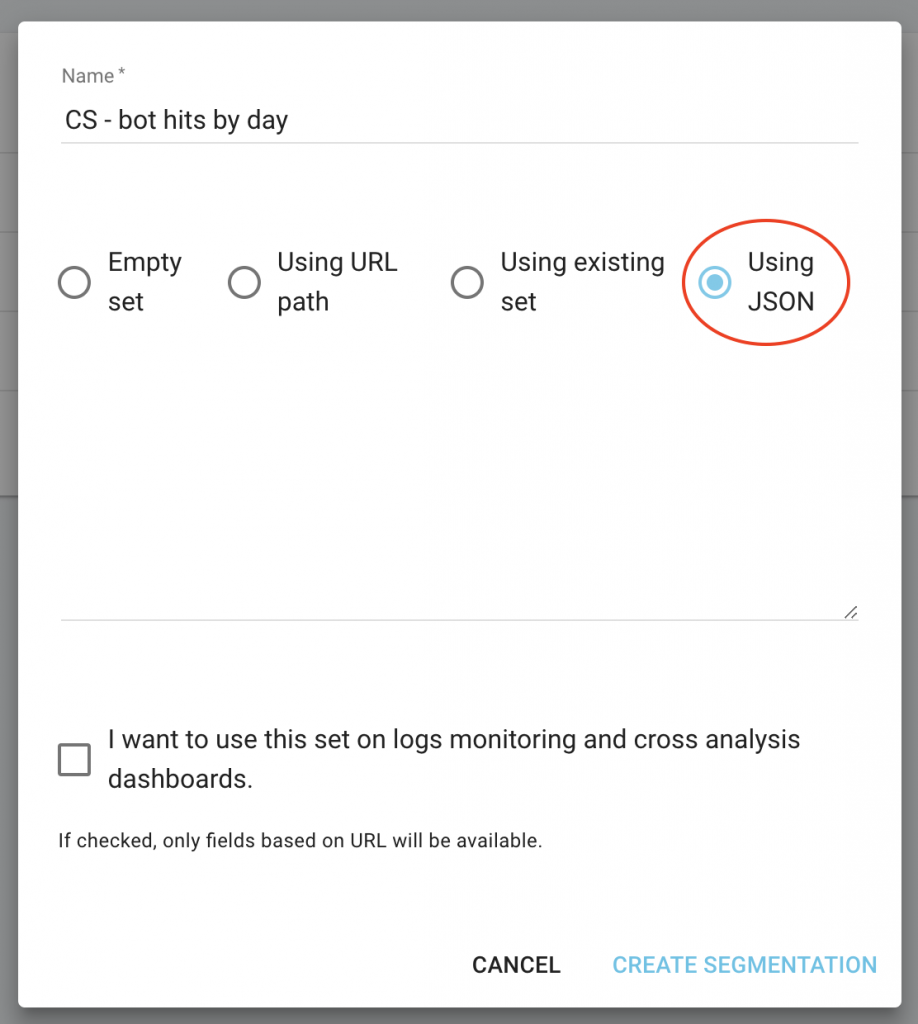
在您的项目主页上单击“配置分段”按钮。

然后创建一个新的细分

通过选择“使用 JSON”容量并复制/粘贴您下载的文件来使用 JSON 导入。
现在,您可以使用每个报告的顶部菜单切换细分。
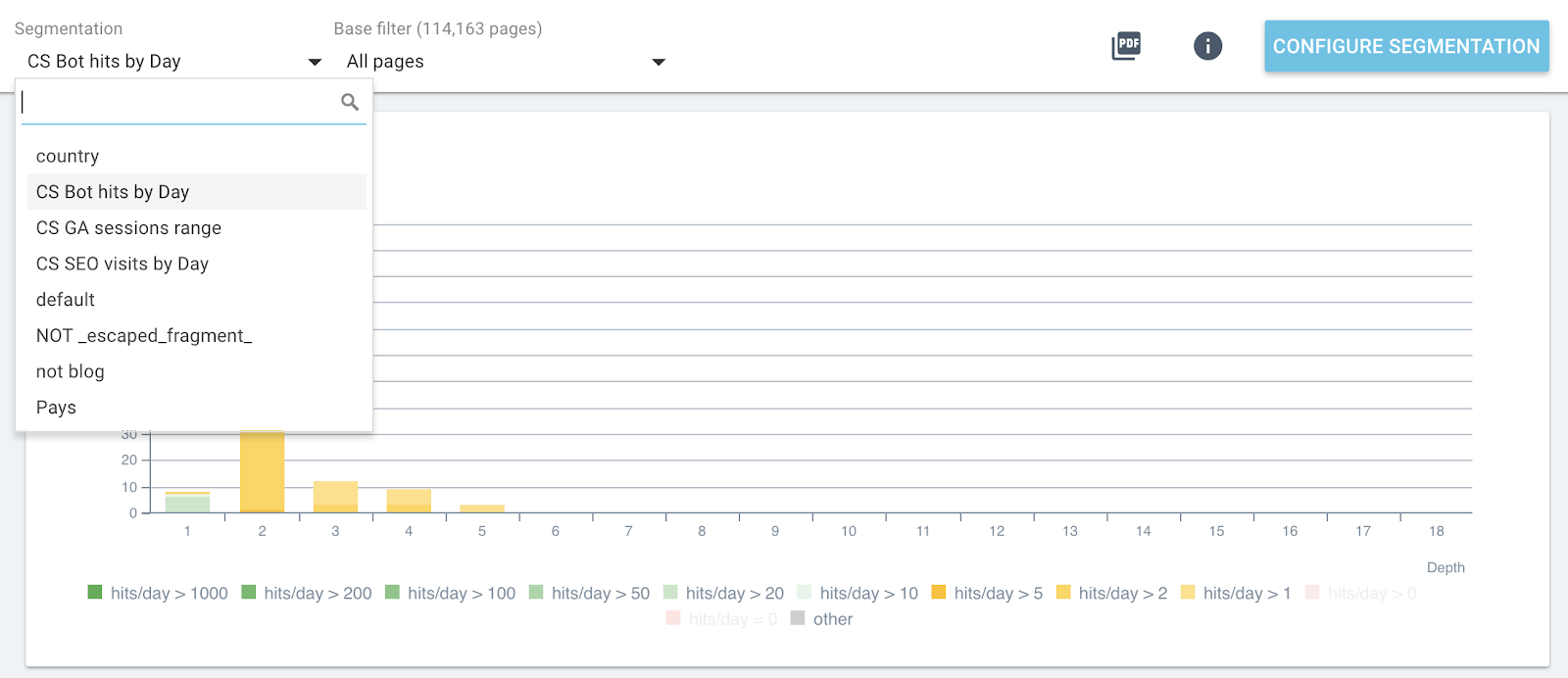
所有 OnCrawl 报告中的实时分段更改
这将为您在每个图形上提供您正在分析的指标的影响,并与按机器人点击或 SEO 访问分组的页面相关。

在以下示例中,我们使用这些细分来了解 InRank 内部流行度的影响——基于深度链接的力量。 此外,机器人点击和 SEO 访问在同一轴上相关。
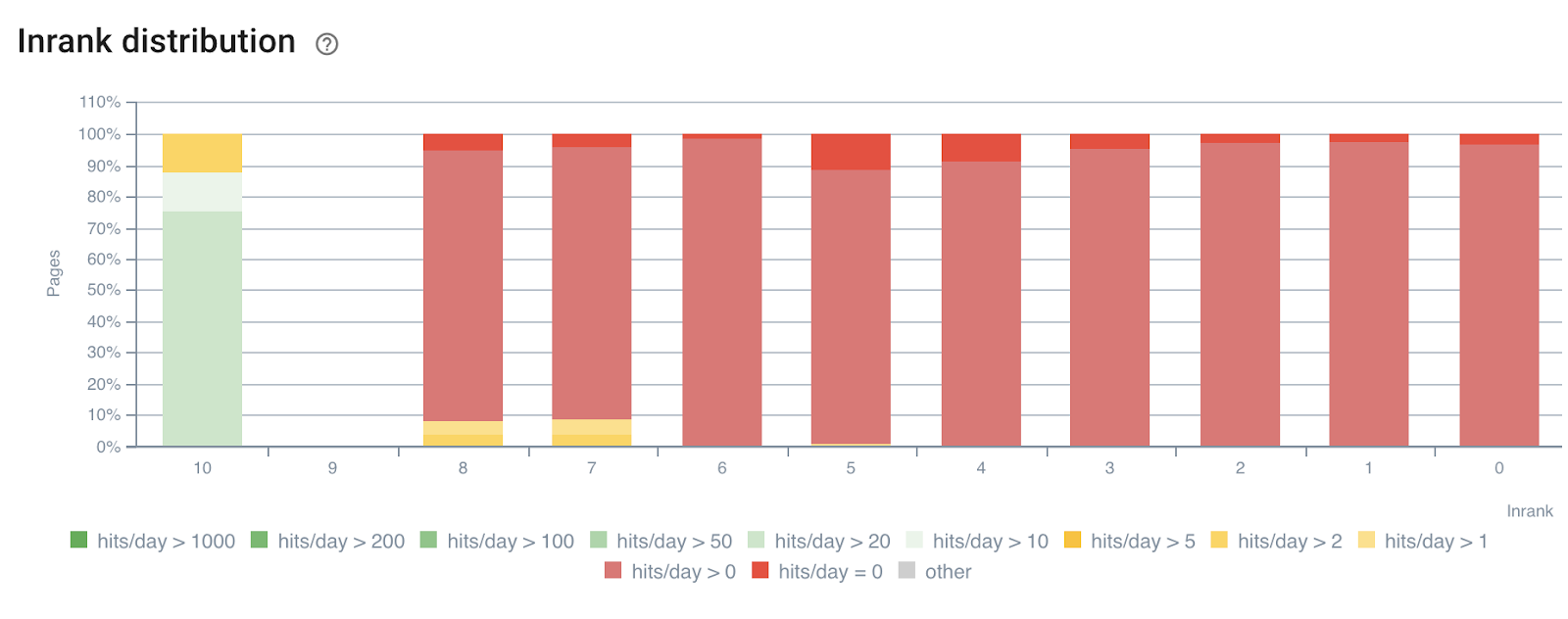
每天按机器人点击的 InRank 分布
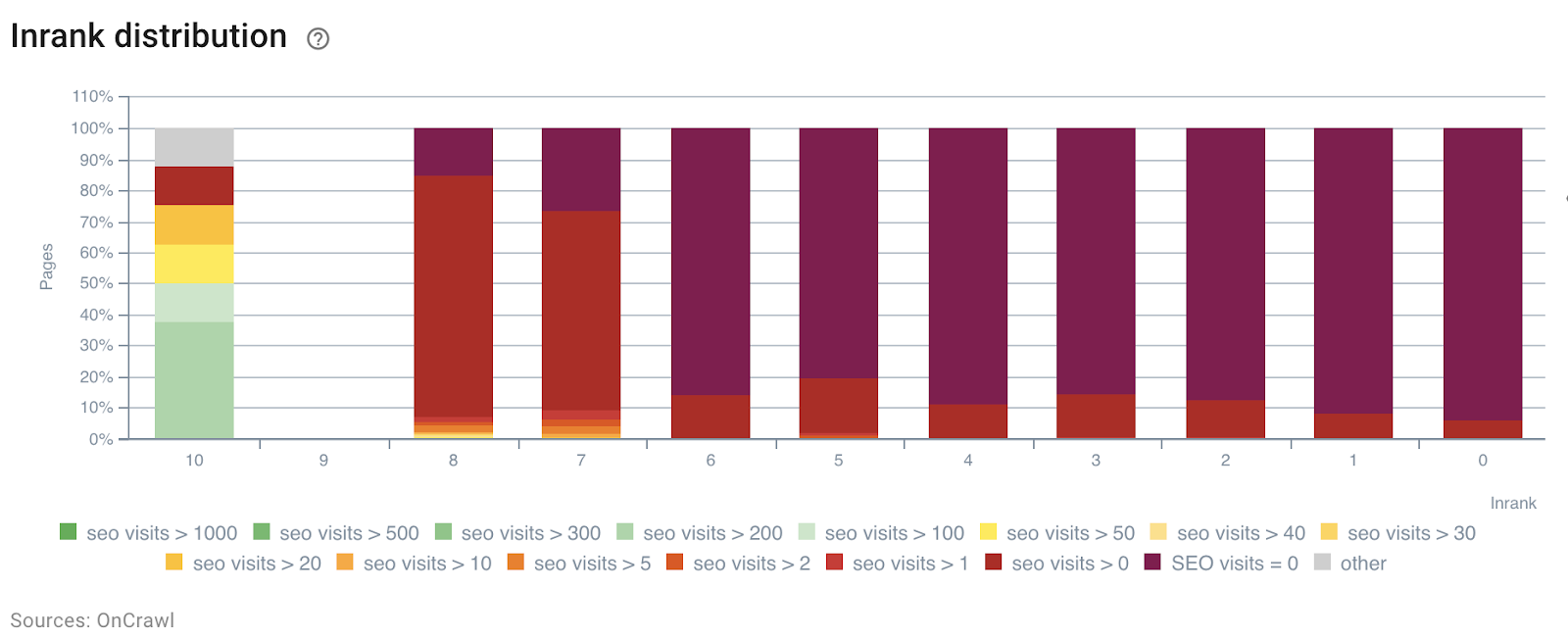
每天按 SEO 访问的 InRank 分布
深度(来自主页的点击次数)显然对机器人点击和 SEO 访问都有影响。
同样,可以独立选择每个页面组,以突出显示点击次数最多或访问次数最多的页面中的数据。
这允许快速检测在优化后可以表现更好的页面,例如页面中的单词数、深度或传入链接的数量。
只需选择正确的细分和您要分析的页面组。
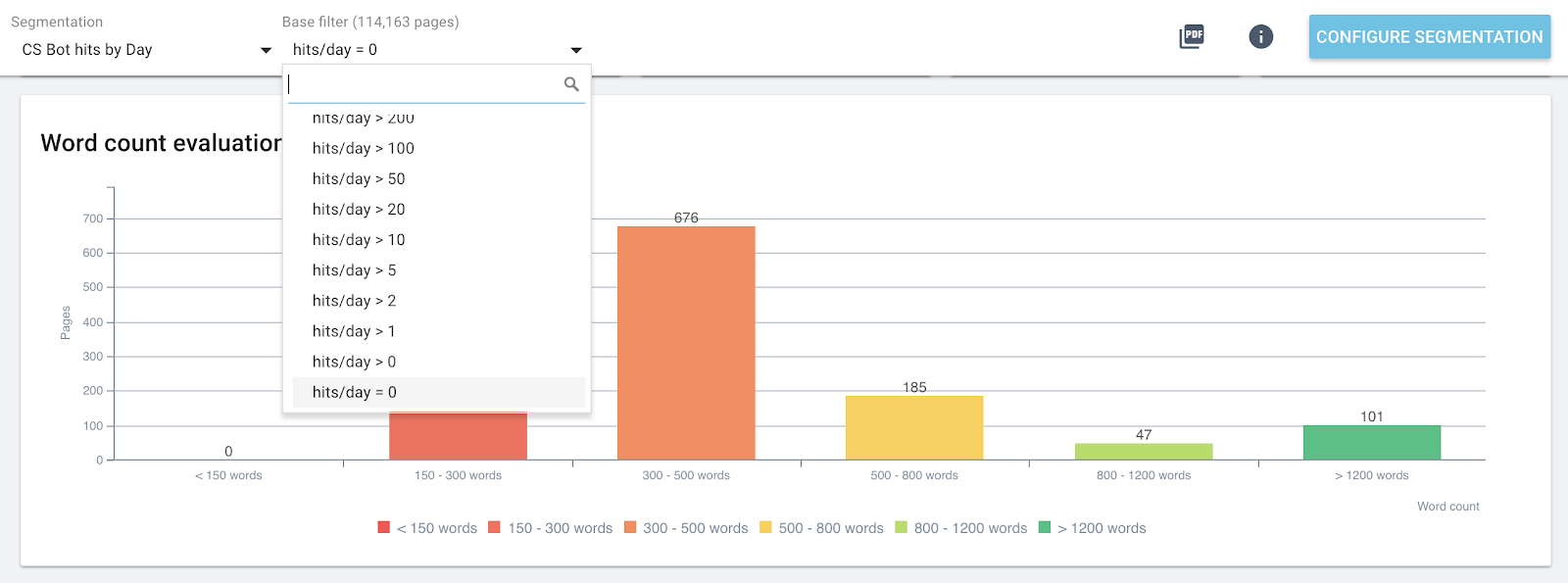
页面中包含每天命中 0 个机器人的组的单词分布
4# 确定阈值以最大化抓取预算和 SEO 访问
更进一步,SEO 影响报告——抓取和日志交叉数据分析——可以检测有助于增加 SEO 访问、抓取频率或页面发现的阈值。
字数对抓取频率的影响
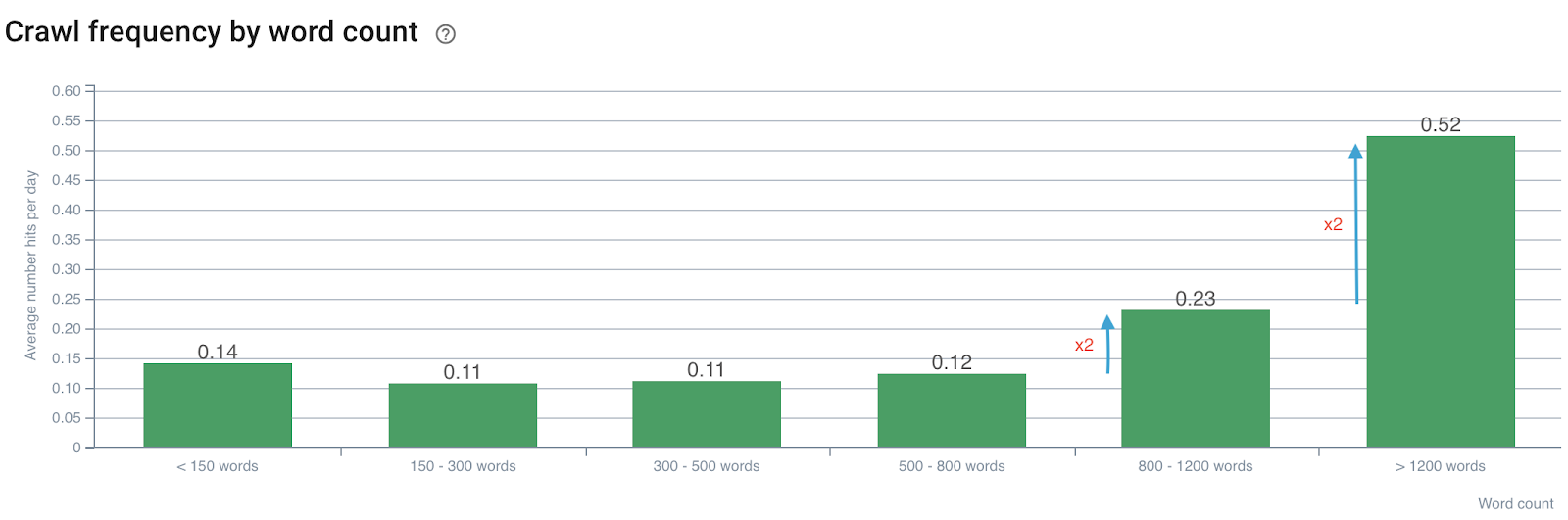
按字数的爬取频率
我们注意到,当字数超过 800 时,爬取频率翻倍。然后,当页面中的字数超过 1200 字时,它也翻倍。
链接数对爬取率的影响
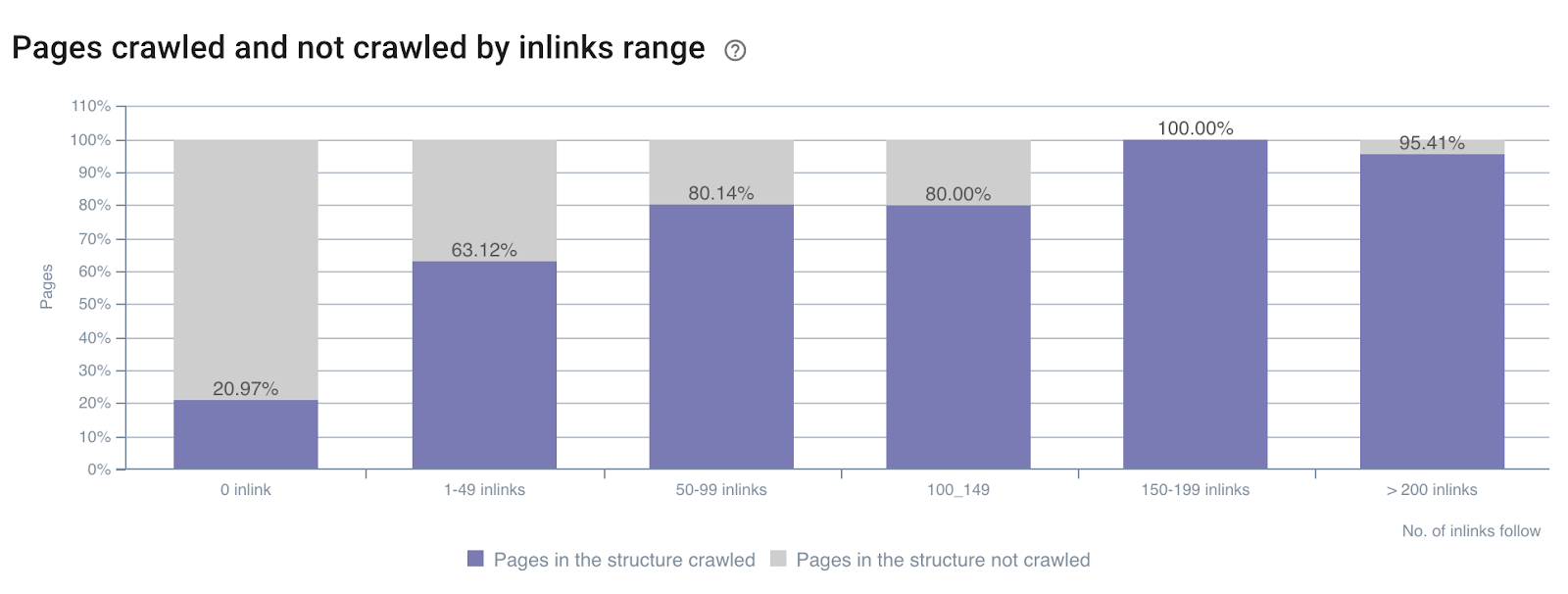
整个网站内链接数量的爬取率
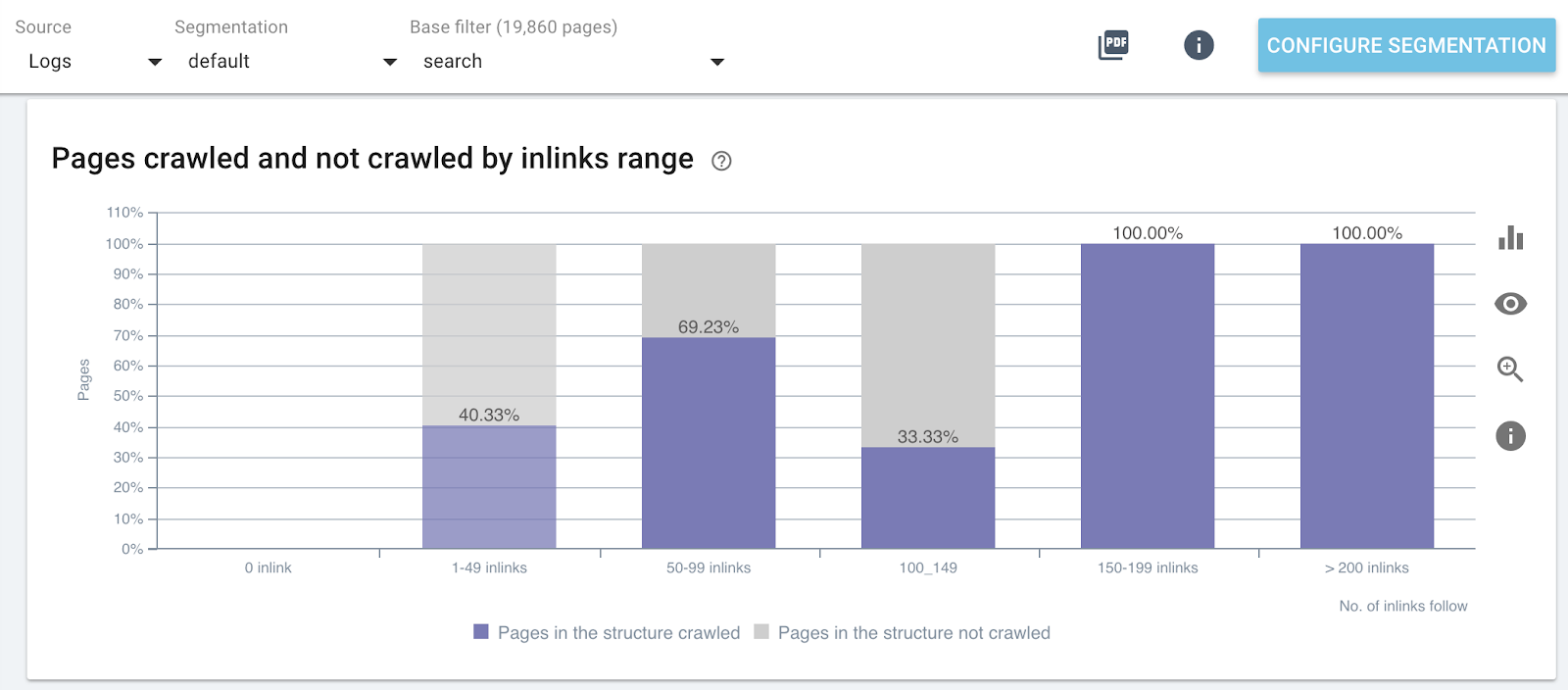
网站特定部分(搜索页面)的链接数量的抓取率
深度对页面活跃度的影响
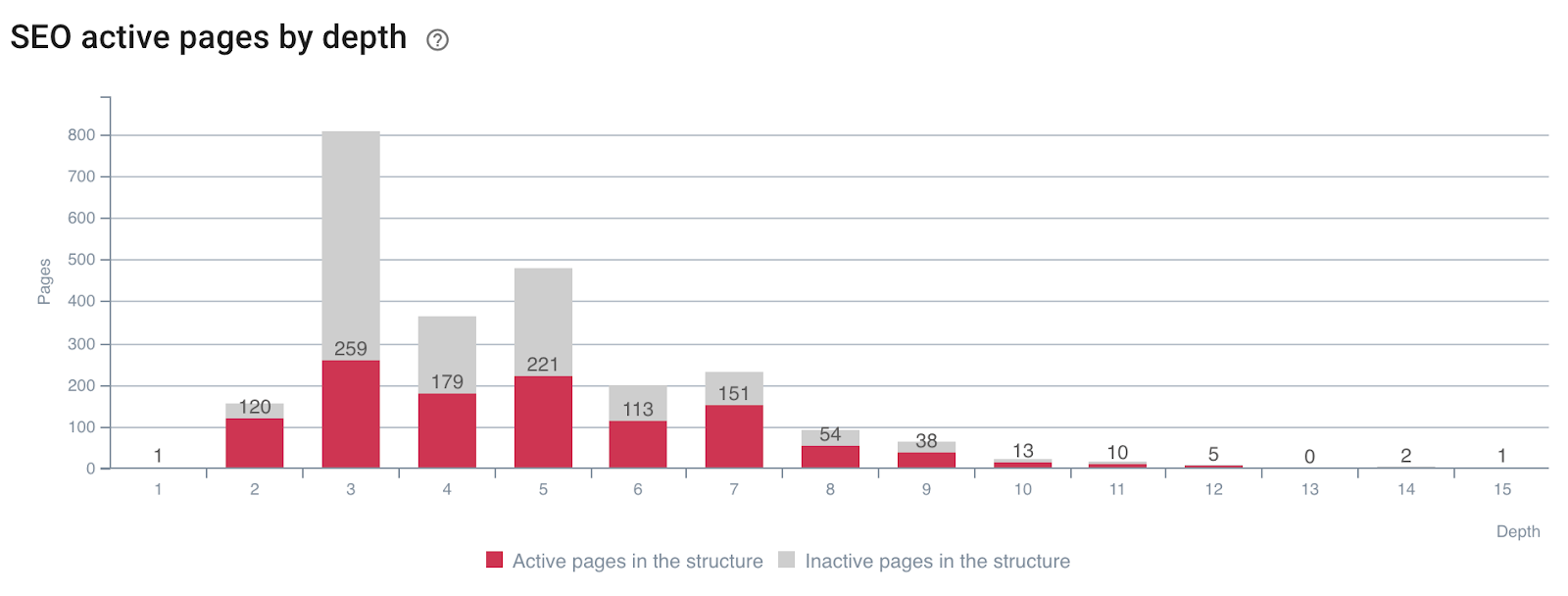
按深度生成(或不生成)SEO 访问的页面
您可以看到,在抓取和交叉日志数据期间拥有正确的网站指标可以让您立即检测到需要哪些 SEO 优化来操纵 Google 的抓取并改善您的 SEO 访问。
5# 确定 SEO 排名因素如何影响您的抓取频率
想象一下,如果您能知道最大化您的 SEO 的目标价值是什么? 这就是交叉数据分析的目的! 它允许您针对每个指标精确地确定在哪个阈值抓取频率、抓取速率或活跃度上最大化。
我们在上面(在关于每页字数和抓取频率的示例中)看到存在抓取频率触发值。 必须针对每种类型的页面分析和比较这些差距,因为我们正在寻找机器人行为或 SEO 访问中的峰值。
如下所示:
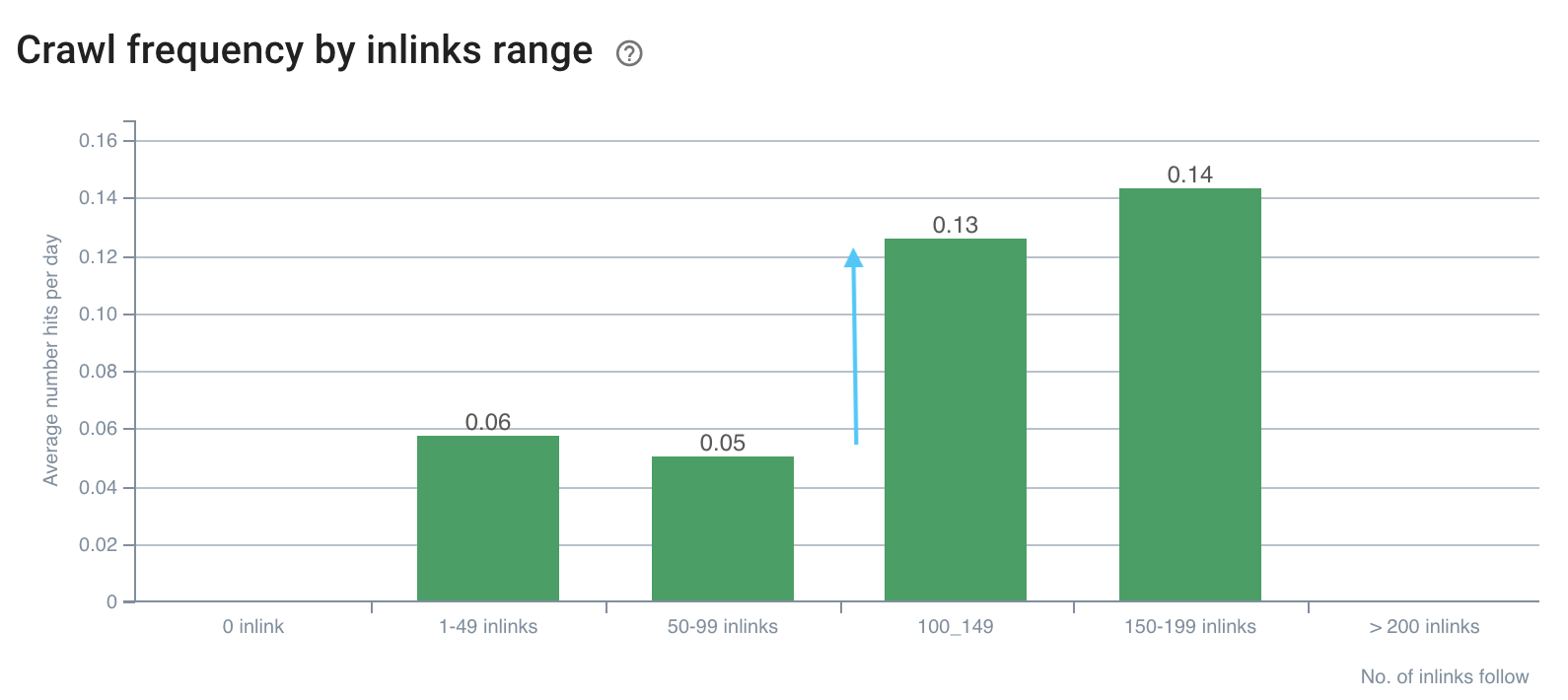
抓取频率在 100 多个链接上存在差距
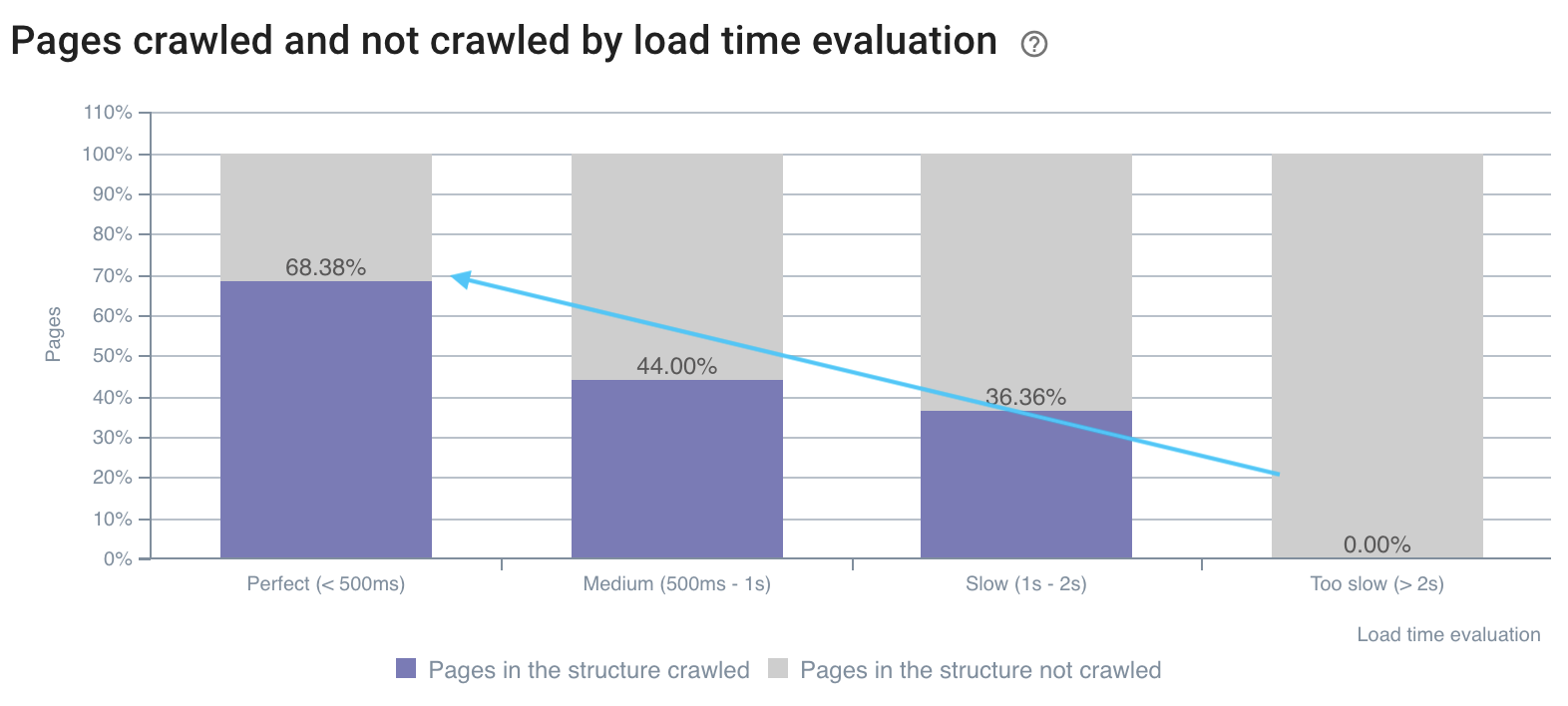
快速页面上的抓取速度更好
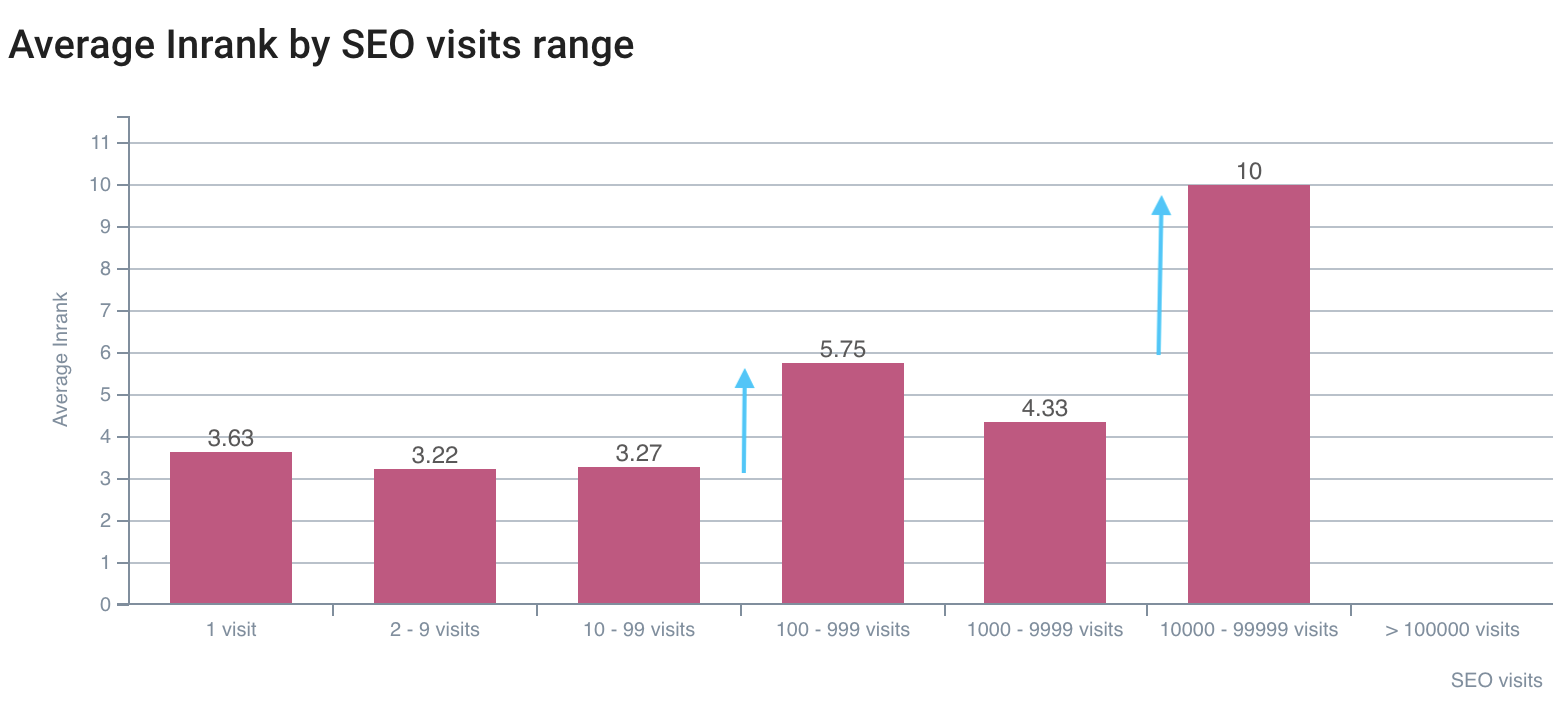
搜索引擎优化访问的第一个差距在 InRank 5,75 上,最好的是在 InRank 10(主页)上
结合抓取和日志数据,您可以打开 Google 黑盒并准确确定您的指标对机器人抓取和访问的影响。 在对这些分析进行优化时,您可以在每次发布时改进您的 SEO。 这种高级使用在时间上是持久的,因为您可以在每次交叉数据分析时检测到要达到的新值。
您还想分享其他有关跨数据分析的技巧吗?