57 个常见的 A/B 测试错误以及如何避免它们
已发表: 2021-06-15
您是否正在运行 A/B 测试,但不确定它们是否正常工作?
您想了解 A/B 测试时的常见错误,以免在失败的广告系列上浪费宝贵的时间吗?
嗯,好消息! 在本文中,我们将向您介绍我们看到的 57 个常见(有时不常见)的 A/B 测试错误,因此您可以避开它们或意识到它们何时发生并快速修复它们。
我们将这些分为 3 个关键部分:
- 开始测试前的错误,
- 测试过程中可能出现的问题,
- 测试完成后您可能会犯的错误。
你可以简单地通读一下,看看你是否自己做这些。
请记住:
每一次失败都是宝贵的一课,无论是在测试中还是在设置错误中。 关键是向他们学习!
所以让我们潜入...
- 甚至在您运行测试之前就可能犯的常见 A/B 测试错误
- #1。 在测试之前推送一些东西!
- #2。 没有运行实际的 A/B 测试
- #3。 不测试以查看该工具是否有效
- #4。 使用低质量工具和内容闪烁
- #5。 没有测试质量保证
- #6。 新的治疗/变化是否有效?
- #7。 不遵循假设,只是测试任何旧事物
- #8。 有一个不可检验的假设
- #9。 没有提前为你的测试设定一个明确的目标
- #10。 专注于表面指标
- #11。 只用量化数据形成测试思路
- #12。 复制你的竞争对手
- #13。 仅测试“行业最佳实践”
- #14。 当高影响大奖励/低悬的果实可用时,首先关注小影响任务
- #15。 一次测试多个事物,但不知道是哪个更改导致了结果
- #16。 未运行适当的预测试分析
- #17。 错误标记测试
- #18。 对错误的 URL 运行测试
- #19。 为您的测试添加任意显示规则
- #20。 为您的目标测试错误的流量
- #21。 未能将回访者排除在测试中并扭曲结果
- #22。 不从测试中删除您的 IP
- #23。 不分割控制组变量(网络效应)
- #24。 在季节性活动或主要站点/平台活动期间运行测试
- #25。 无视文化差异
- #26。 同时运行多个连接的活动
- #27。 不等的流量权重
- 您在测试期间可能犯的常见 A/B 测试错误
- #28。 没有运行足够长的时间来获得准确的结果
- #29。 直升机监控/窥视
- #30。 不跟踪用户反馈(如果测试影响直接、立即的操作,则尤其重要)
- #31。 在测试中进行更改
- #32。 在测试中更改流量分配百分比或删除表现不佳的人
- #33。 当您有准确的结果时不停止测试
- #34。 在情感上投入到失去变化中
- #35。 运行测试时间过长并且跟踪下降
- #36。 不使用允许您停止/实施测试的工具!
- 测试完成后可能犯的常见 A/B 测试错误
- #37。 一考就放弃!
- #38。 在测试所有版本之前放弃一个好的假设
- #39。 一直期待巨大的胜利
- #40。 测试后不检查有效性
- #41。 未正确读取结果
- #42。 不按细分查看结果
- #43。 不从结果中学习
- #44。 接受失败者
- #45。 不对结果采取行动
- #46。 不迭代和改进胜利
- #47。 不分享其他领域或部门的获奖结果
- #48。 不在其他部门测试这些变化
- #49。 单页迭代过多
- #50。 测试不够!
- #51。 不记录测试
- #52。 忘记误报,不仔细检查大型提升活动
- #53。 不跟踪下线结果
- #54。 未能考虑首要性和新颖性效应,这可能会使治疗结果产生偏差
- #55。 运行考虑期变化
- #56。 X 次后不再重新测试
- #57。 只测试路径而不测试产品
- 结论
甚至在您运行测试之前就可能犯的常见 A/B 测试错误
#1。 在测试之前推送一些东西!
您可能有一个很棒的新页面或网站设计,并且您真的很想在没有测试的情况下将其上线。
等一下!
首先运行一个快速测试,看看它是如何工作的。 您不想在没有获得一些数据的情况下推动彻底的变革,否则您可能会失去销售和转化。
有时,这种新变化可能会导致性能大幅下降。 所以先给它一个快速测试。
#2。 没有运行实际的 A/B 测试
A/B 测试通过将单个流量源运行到控制页面和该页面的变体来工作。 目标是确定您实施的更改是否使受众更好地转换并采取行动。
问题是,为了确保这个测试是可控的和公平的,我们需要使用特定的参数来运行这个测试。 我们需要在同一时间段内查看活动的相同流量来源,这样我们就没有任何外部因素影响一个测试而不影响另一个测试。
有些人犯了按顺序运行测试的错误。 他们将当前页面运行 X 时间,然后新版本运行 X 时间,然后测量差异。
这些结果并不完全准确,因为在这些测试窗口期间可能发生了许多事情。 您可能会获得大量新流量,举办活动,导致 2 个页面的受众和结果大相径庭。
因此,请确保您正在运行实际的 A/B 测试,在该测试中,您在 2 个版本之间分配流量并同时测试它们。
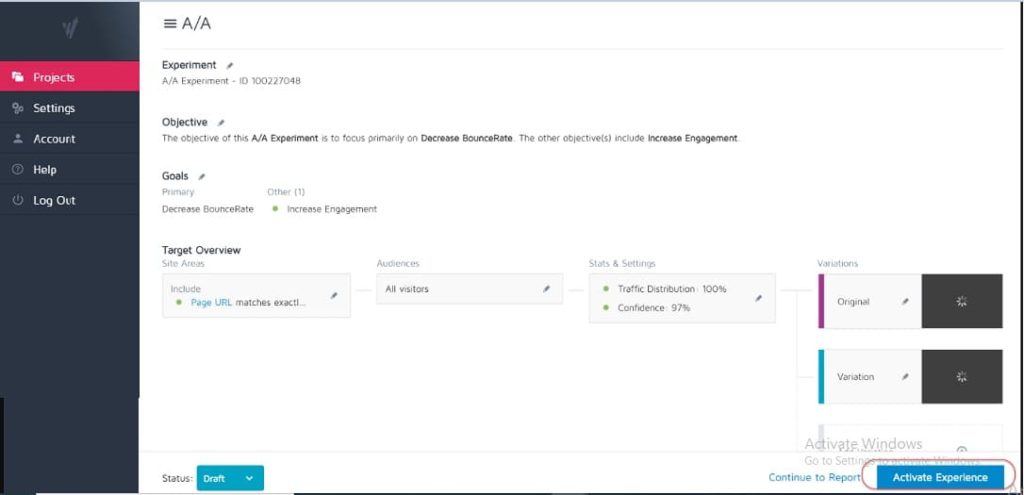
#3。 不测试以查看该工具是否有效
没有测试工具是 100% 准确的。 刚开始时您可以做的最好的事情是运行 A/A 测试以查看您的工具的精确度。
如何? 只需运行一个测试,在单个页面之间以 50:50 的比例分配流量。 (确保它是您的受众可以转换的页面,以便您可以衡量特定结果。)
为什么?
因为你的两组观众看到的是完全相同的页面,所以测试双方的转换结果应该是相同的,对吧?
好吧,有时它们不是,这意味着您的工具可能设置不正确。 因此,请在运行任何广告系列之前检查您的测试工具。
#4。 使用低质量工具和内容闪烁
有些工具不如其他工具好。 他们做这项工作,但在交通负荷或“眨眼”和闪烁下挣扎。

这实际上会导致您的测试失败,即使您有一个潜在的获胜变体。
假设您要拆分测试页面上的图像。 控制页面加载正常,但新测试图像和原始图像之间的变化仅在几分之一秒内闪烁。 (或者也许每次用户上下滚动页面时。)
这可能会分散注意力并导致信任问题,从而降低您的转化率。
事实上,您的新图像在理论上甚至可以更好地转换,但工具闪烁会降低结果,使您对该图像的测试不准确。
确保您有足够好的工具进行测试。
(这是一个非常重要的用户体验因素,以至于谷歌目前正在调整他们对没有闪烁或移动元素的网站的排名)。
#5。 没有测试质量保证
一个超级简单的错误,但你检查过一切正常吗?
- 你经历过销售过程吗?
- 有其他人吗? (在未缓存的设备上,因为有时浏览器中保存的内容与页面的外观不同。)
- 页面加载正常吗? 他们慢吗? 设计是否混乱?
- 所有按钮都有效吗?
- 收入跟踪是否有效?
- 您是否检查过该页面是否可以在多个设备上运行?
- 如果出现问题,您是否有错误报告?
在您开始为任何广告系列投放流量之前,这一切都值得一试。
获取我们的 A/B 测试质量保证清单。 这是一个可填写的 PDF,您每次对测试进行 QA 时都需要返回。
#6。 新的治疗/变化是否有效?
同样,在运行测试之前,您是否已经完成并测试了您的新变体是否有效?
这可能是 QA 测试中被忽视的一部分,但活动通常会在按钮损坏、旧链接等情况下运行。 先检查,再测试。
#7。 不遵循假设,只是测试任何旧事物
有些人只是在没有真正考虑过的情况下测试任何东西。
他们对更改有了想法并想对其进行测试,但没有真正分析页面当前的转换方式,甚至没有真正分析他们正在测试的更改为什么会产生影响。 (可能是他们降低了转化率但甚至不知道,因为他们还没有跟踪基线结果)。
形成一个关于问题所在、原因以及如何解决问题的假设将对您的测试程序产生巨大影响。

#8。 有一个不可检验的假设
并非所有假设都是正确的。 这可以。 事实上,这个词的字面意思是“我有一个基于 X 信息的想法,我认为 Y 可能发生在 Z 情况下”。
但是您需要一个可测试的假设,这意味着可以通过测试来证明或反驳它。 可检验的假设将创新付诸实践并促进积极的实验。 它们可能导致成功(在这种情况下你的预感是正确的)或失败——表明你一直都是错的。 但他们会给你洞察力。 这可能意味着您的测试需要更好地执行,您的数据不正确/读取错误,或者您发现了一些不起作用的东西,这通常可以让您深入了解可能会更好的新测试。
#9。 没有提前为你的测试设定一个明确的目标
一旦有了假设,您就可以使用它与您想要实现的特定结果保持一致。
有时人们只是运行一个活动,看看有什么变化,但如果你清楚地知道你想要提升哪个特定元素,你肯定会获得更多的潜在客户/转化或销售。
(这也阻止了你看到一个重要元素的下降,但认为测试是胜利,因为它“获得了更多的份额”。)
说到这个……
#10。 专注于表面指标
您的测试应始终与 Guardrail 指标或直接影响您的销售的某些元素相关联。 如果有更多潜在客户,那么您应该知道潜在客户的价值以及提高转化率的价值。
同时,通常应该避免与或驱动可衡量结果无关的指标。 更多的 Facebook 喜欢并不一定意味着更多的销售。 删除那些社交分享按钮,然后看看您获得了多少潜在客户。 警惕虚荣指标并记住,仅仅因为修复了一个泄漏并不意味着其他地方也没有另一个泄漏!
以下是 Ben Labay 的实验项目常见护栏指标列表:
#11。 只用量化数据形成测试思路
使用定量数据来获取想法很棒,但也存在一些缺陷。 特别是如果我们使用的唯一数据来自我们的分析。
为什么?
我们可以从我们的数据中知道有 X 人没有点击,但我们可能不知道为什么。
- 按钮是否在页面下方太低?
- 不清楚吗?
- 它与观众想要的一致吗?
- 它甚至工作吗?
最好的测试人员也会倾听他们的听众。 他们找出他们需要什么,是什么推动他们前进,是什么阻碍了他们,然后用它来制定新的想法、测试和书面副本。
有时,您的用户会因信任问题和自我怀疑而受阻。 其他时候,它的清晰度和破损的形式或糟糕的设计。 关键是这些是定量数据无法始终告诉您的事情,因此请始终询问您的听众并使用它来帮助您进行计划。
#12。 复制你的竞争对手
准备好秘密了吗?
很多时候,您的竞争对手只是随心所欲。 除非他们有长期开展提升活动的人,否则他们可能只是在尝试一些东西,看看什么是有效的,有时没有使用任何数据来表达他们的想法。
即便如此,对他们有用的东西,也可能对你不起作用。 所以,是的,用它们来激发灵感,但不要将你的测试想法限制在你看到它们所做的事情上。 你甚至可以走出你的行业寻找灵感,看看它是否会引发一些假设。
#13。 仅测试“行业最佳实践”
同样,对一个人有用的东西并不总是对另一个人有用。
例如,滑块图像通常具有糟糕的性能,但在某些网站上,它们实际上可以推动更多的转化。 测试一切。 你没有什么可失去的,也没有什么可得到的。
#14。 当高影响大奖励/低悬的果实可用时,首先关注小影响任务
我们都可能因专注于细节而感到内疚。 我们可能有一个想要更好地执行并测试布局设计和图像甚至按钮颜色的页面。 (我个人有一个处于第 5 次迭代的销售页面。)
问题是,现在可能有更重要的页面供您测试。
最重要的是优先考虑影响:
- 这个页面会直接影响销售吗?
- 销售过程中是否还有其他页面表现不佳?
如果是这样,请首先关注那些。
销售页面上 1% 的提升是很棒的,但是让他们到达那里的页面上 20% 的提升可能更重要。 (特别是如果该特定页面是您失去大部分观众的地方。)
有时我们不仅在寻找更多的提升,而是为了解决一些瓶颈问题。
测试和改进最大的影响,最低的挂果优先。 这就是代理机构所做的,这就是为什么他们执行与内部团队相同数量的测试,但具有更高的投资回报率。 代理机构在相同数量的测试中获得的胜利增加了 21%!
#15。 一次测试多个事物,但不知道是哪个更改导致了结果
一次更改多项内容并重新设计整个页面的激进测试并没有错。
事实上,这些彻底的重新设计有时会对您的投资回报率产生最大的影响,即使您是一个低流量的网站,尤其是当您处于平稳状态并且似乎无法获得更多提升时。
但请记住,并不是每个 A/B 测试都应该针对这样的彻底改变。 99% 的时间我们只是在测试单个事物的变化,比如
- 新头条
- 新图像
- 相同内容的新布局
- 新定价等
进行单元素测试时的关键就是这样。 让你的测试只改变一个元素,这样你就可以看到是什么造成了改变并从中学习。 改变太多,你不知道什么有效。
#16。 未运行适当的预测试分析
您的测试组中有足够的访客吗? 测试甚至值得你花时间吗?
算一算! 在运行测试之前确保您有足够的流量 - 否则只会浪费时间和金钱。 许多测试由于流量不足或灵敏度低(或两者兼而有之)而失败。
执行测试前分析以确定您的实验的样本量和最小可检测效应。 像 Convert's 这样的 A/B 测试意义计算器会告诉你测试的样本量和 MDE,这将帮助你决定是否值得运行。 您还可以使用此信息来确定测试应该运行多长时间以及在得出测试成功与否之前您不想错过的提升幅度。
#17。 错误标记测试
一个超级简单的错误,但它确实发生了。 您错误地标记测试,然后得到错误的结果。 变体获胜,但它被命名为控制,然后你永远不会实现胜利并留在失败者身边!
总是仔细检查!
#18。 对错误的 URL 运行测试
另一个简单的错误。 页面 URL 输入错误,或者测试正在运行到您进行更改的“测试站点”,而不是实时版本。
它对您来说可能看起来不错,但实际上不会为您的观众加载。
#19。 为您的测试添加任意显示规则
同样,你需要用你的治疗来测试一件事,而不是别的。
如果是图像,则测试图像。 其他一切都应该相同,包括人们可以看到两个页面的时间!
一些工具允许您测试一天中的不同时间,以了解流量在不同时间范围内的表现。 如果您想查看最佳流量何时出现在您的网站上,这很有帮助,但如果页面被谁看到它们并且有不同的变化,则没有帮助。
例如,我们自己的博客流量在周末下降(就像大多数商业博客一样)。
想象一下,如果我们在控制页面上的周一至周三运行测试,然后在治疗中显示来自周五至周日的流量? 测试的流量要低得多,而且结果可能会有所不同。
#20。 为您的目标测试错误的流量
理想情况下,在运行测试时,您希望确保只测试一部分受众。 通常,它是新的自然访问者,看看他们第一次在您的网站上的反应如何。

有时您可能想要测试重复访问者、电子邮件订阅者甚至付费流量。 诀窍是一次只测试其中一个,这样您就可以准确表示该组在该页面上的表现。
设置测试时,请选择您要使用的受众,并删除任何可能污染结果的其他受众,例如回访者。
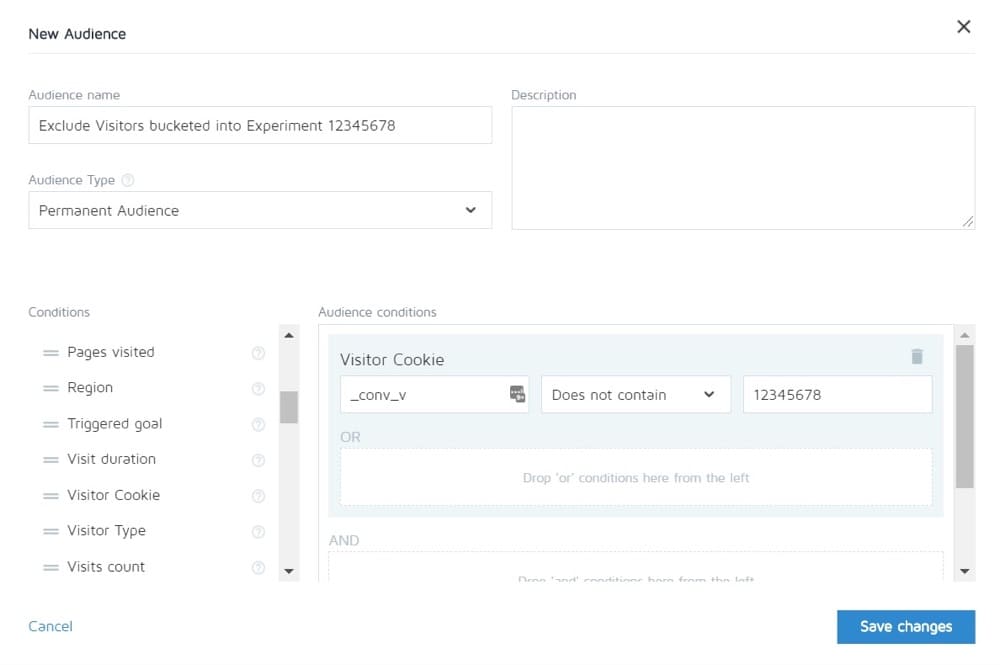
#21。 未能将回访者排除在测试中并扭曲结果
我们称之为样本污染。
基本上,如果访问者看到您网站的页面,返回并看到您的变体,那么他们的反应将与他们只看到其中一个时截然不同。
仅仅因为这些额外的交互,他们可能会感到困惑、反弹,甚至转换得更高。
问题是,它会导致您的数据受到污染且准确性降低。 理想情况下,您希望使用一种工具来随机化他们看到的页面,然后始终向他们显示相同的版本,直到测试结束。
#22。 不从测试中删除您的 IP
说到样本污染,这是污染数据的另一种方式(无论如何,这是一种很好的分析实践)。
确保从您的分析和测试工具中阻止您和您员工的 IP 地址。 您最不希望的事情是您或团队成员在页面上“签到”并在您的测试中被标记。
#23。 不分割控制组变量(网络效应)
另一种很少见但可能发生的污染选择,尤其是如果您有一个面向受众的网络。
这是一个例子。
假设您有一个平台可以让您的观众进行交流。 也许是 Facebook 页面或评论部分,但每个人都可以访问它。
在这种情况下,您可能让人们看到一个页面而其他人看到一个变化,但他们都在同一个社交网络上。 这实际上会扭曲您的数据,因为它们会影响彼此的选择以及与页面的交互。 在测试新功能以防止网络效应问题时,Linkedin 一直在对其受众进行细分。
理想情况下,您希望分离 2 个测试组之间的通信,直到测试完成。
#24。 在季节性活动或主要站点/平台活动期间运行测试
除非您正在测试季节性事件,否则您永远不想在假期或任何其他重大事件(例如特殊销售或世界事件发生)期间运行测试活动。
有时你无能为力。 您将进行一次测试运行,而 Google 只是实施了新的核心更新,并在广告系列中期*咳嗽*弄乱了您的流量来源。
最好的办法就是在一切都结束后重新运行。
#25。 无视文化差异
您可能有一个页面的目标,但同时也在运行一个全球广告系列,其中包含以不同语言和不同国家/地区显示的多种变体。
在运行测试时,您需要考虑到这一点。 可以全局进行一些更改,例如简单的布局转换或添加信任信号等。
其他时候,您需要考虑文化差异点。 人们如何看待布局、他们如何查看图像以及页面上的头像。
Netflix 使用他们所有节目的缩略图来做到这一点,测试可能吸引不同观众的不同元素(取而代之的是该国著名的特定演员)。

在一个国家/地区获得点击的内容在其他国家/地区可能会大不相同。 你不知道,直到你测试!
#26。 同时运行多个连接的活动
很容易兴奋并想要一次运行多个测试。
请记住:您可以同时针对销售流程中的相似点运行多个测试,但不要针对漏斗中的多个连接点运行多个测试。
这就是我的意思。
您可以同时在每个潜在客户生成页面上轻松运行测试。
但是,您不希望同时测试潜在客户页面、销售页面和结帐页面,因为这会在您的测试过程中引入许多不同的元素,需要大量的流量和转化才能获得任何有用的洞察力。
不仅如此,每个元素都会对下一页产生不同的影响,有好有坏。 除非您每周有成千上万的访问者,否则您可能很难获得准确的结果。
因此,请耐心等待,一次只测试一个阶段或过程中未连接的页面。
边注:
Convert 允许您将一个实验中的人排除在其他实验之外。 所以理论上你可以测试整个销售周期,然后只看到其他页面的控制。
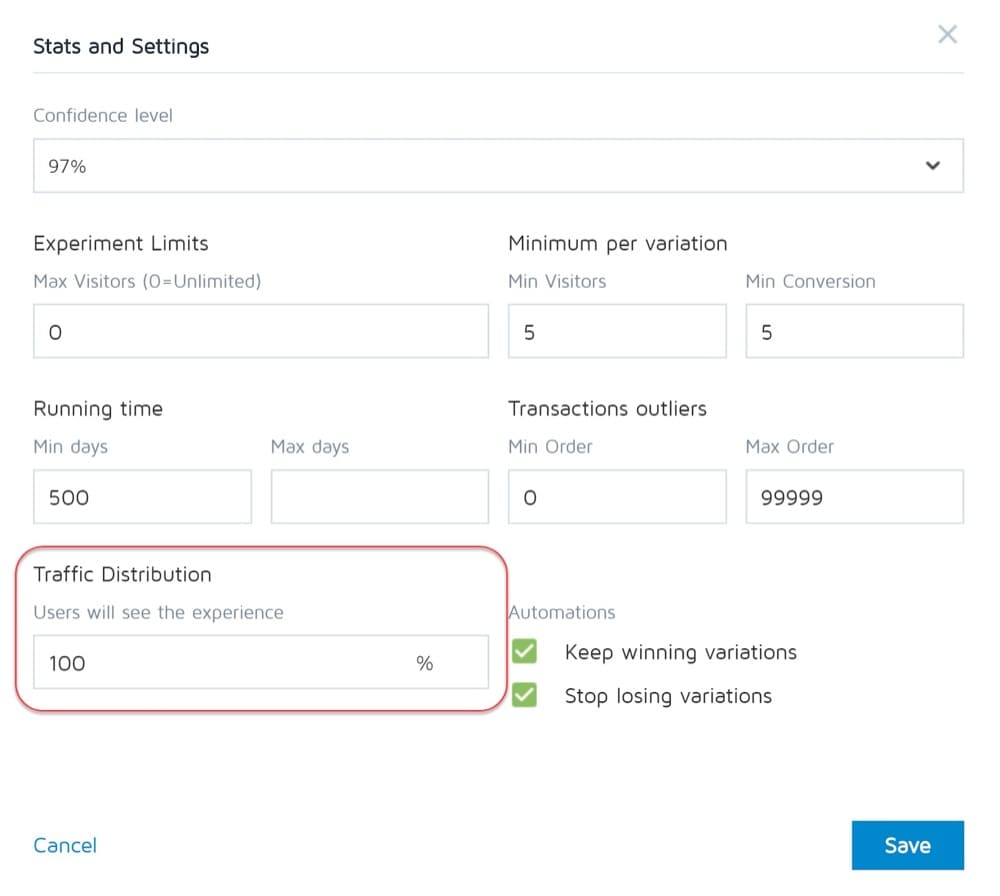
#27。 不等的流量权重
无论您运行的是 A/B、A/B/n 还是多变量测试,都没有关系。 您需要为每个版本分配相等的流量,以便获得准确的测量结果。
从一开始就将它们设置为相等。 大多数工具都允许您执行此操作。
您在测试期间可能犯的常见 A/B 测试错误
#28。 没有运行足够长的时间来获得准确的结果
当您想要测试并获得准确的结果时,需要考虑 3 个重要因素:
- 统计学意义,
- 销售周期,以及
- 样本量。
所以让我们分解一下。
大多数人在他们的测试工具告诉他们一个结果比另一个结果更好并且结果具有统计意义时结束测试,即如果测试继续像这样执行,那么这就是绝对的赢家。
问题是您有时只需少量流量即可快速点击“stat sig”。 随机地,所有转换都发生在一个页面上,而没有发生在另一页上。
不过不会一直这样。 可能是测试启动了,这是发薪日,那天你得到了一大笔销售额。
这就是为什么我们需要考虑销售周期。 销售和流量可能会根据一周中的某一天或一个月而波动。 为了更准确地表示测试的运行情况,理想情况下需要运行 2 到 4 周。
最后,您有样本量。
如果您运行测试一个月,那么您可能会获得足够的流量来获得准确的结果。 太少了,测试就无法给你一个信心水平,它会按应有的方式执行。
所以根据经验,
- 获得 95% 的置信度。
- 跑一个月。
- 提前确定您需要的样本量,并且在测试成功之前不要停止测试,或者您会得到一些惊人的结果,毫无疑问地证明您有赢家。
#29。 直升机监控/窥视
Peeking 是一个术语,用于描述测试人员何时查看他们的测试以了解其执行情况。
理想情况下,我们永远不想在运行后查看我们的测试,并且在它完成一个完整的周期、具有正确的样本量并且达到统计显着性之前,我们永远不会对其做出决定。
但是……如果测试没有运行怎么办?
如果有东西坏了怎么办?
好吧,在那种情况下,你真的不想等一个月才能看到它坏了,对吧? 这就是为什么我总是在设置运行 24 小时后检查测试是否在控制和变化中获得结果。
如果我可以看到他们都在接收流量并获得点击/转化,那么我就走开,让它做它的事情。 在测试完成之前,我不会做出任何决定。
#30。 不跟踪用户反馈(如果测试影响直接、立即的操作,则尤其重要)
假设测试正在获得点击并且流量已分配,所以它*看起来*像是在工作,但突然你开始收到人们无法填写销售表格的报告。 (或者更好的是,您会收到一个自动警报,表明护栏指标已降至可接受的水平以下。)
好吧,那么您的第一个想法应该是某些东西坏了。
并非总是如此。 您可能会从不与您的报价产生共鸣的受众那里获得点击,但以防万一,值得检查该表单。
如果它坏了,那么修复它并重新启动。
#31。 在测试中进行更改
从最后几点可能已经很清楚了,但是一旦测试上线,我们就不想对测试进行任何更改。
当然,有些东西可能会损坏,但这是我们应该做出的唯一改变。 我们不会更改设计、复制或任何东西。
如果测试有效,让它运行并让数据决定什么有效。
#32。 在测试中更改流量分配百分比或删除表现不佳的人
就像我们不会更改正在测试的页面一样,我们也不会删除任何变体或更改中间测试的流量分布。
为什么?
假设您正在运行一个 A/B/n 测试,其中包含一个控件和 3 个变体。 你开始测试,一周后你调皮地偷看一眼,发现有两个版本做得很好,一个做得很差。
现在很想关闭“丢失”的变体并在其他变体之间重新分配流量,对吗? 哎呀……你甚至可能想把额外的 25% 的流量发送给表现最好的人,但不要这样做。
为什么?
这种重新分配不仅会影响测试性能,还会直接影响结果以及它们在报告工具上的显示方式。
之前被分桶到已删除变体的所有用户都需要重新分配到一个变体,并且将在短时间内看到更改的网页,这可能会影响他们的行为和后续选择。
这就是为什么您永远不会在中途更改流量或关闭变化的原因。 (还有为什么你不应该偷看!)
#33。 当您有准确的结果时不停止测试
有时您只是忘记停止测试!
它会继续运行并将 50% 的受众提供给较弱的页面,并将 50% 提供给获胜者。 哎呀!
幸运的是,可以设置转换体验等工具来停止活动,并在达到特定标准(如样本量、统计信息、转换和时间范围)后自动显示获胜者。
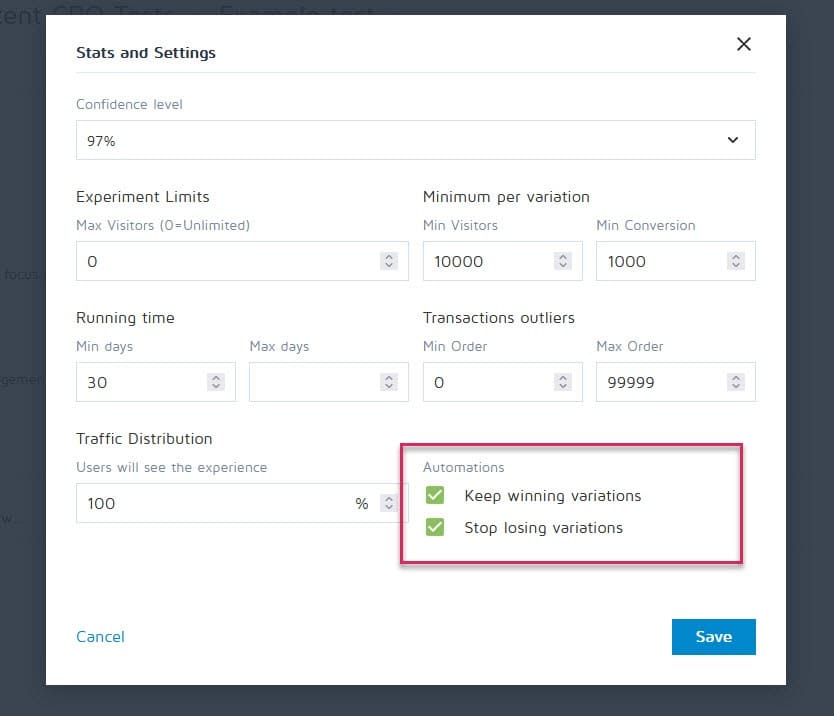
#34。 在情感上投入到失去变化中
作为测试人员,我们需要保持公正。 然而,有时你可能有一个你喜欢的特定设计或想法,并且相信它应该会赢,所以你不断地延长测试时间,看看它是否能领先。
把绷带拉下来。
您可能有一个需要改进的好主意,但在结束当前测试之前您不能这样做。
#35。 运行测试时间过长并且跟踪下降
这是另一个潜在的样本污染问题。
如果您运行测试超过 4 周,您可能会看到用户的 cookie 丢失。 这可能导致缺乏对事件的跟踪,但它们甚至可能再次返回并污染样本数据。
#36。 不使用允许您停止/实施测试的工具!
另一个罕见的问题。
一些测试程序坚持创建硬编码测试。 即开发人员和工程师从头开始构建活动。
但是,当测试结束并且您需要等待同一位开发人员将其关闭并安装获胜的变体时,这并不是很好。 这不仅令人沮丧,而且会严重减慢您可以运行的测试数量,甚至会降低页面在等待上线时的投资回报率。
测试完成后可能犯的常见 A/B 测试错误
#37。 一考就放弃!
10 个测试中有 9 个通常是失败的。
这意味着您需要运行 10 次测试才能获得获胜者。 这需要努力,但总是值得的,所以不要在一场运动之后停下来!
#38。 在测试所有版本之前放弃一个好的假设
失败可能仅仅意味着您的假设是正确的,但需要更好地执行。
尝试新的方式、新的设计、新的布局、新的图像、新的头像、新的语言。 你有这个想法,看看你是否可以更好地执行它。
CXL 花了 21 次迭代来改进客户的页面,但转化率从 12.1% 提高到了 79.3%。
#39。 一直期待巨大的胜利
事实是,每 10 次或更多获胜活动中,您可能只能获得一次巨大的胜利。
还行吧。 我们不断测试并不断改进,因为随着时间的推移,即使增加 1% 的化合物。 改进它并将其提高到 2%,您现在已经将效率提高了一倍。
哪种类型的测试产生最好的结果?
事实上,不同的实验有不同的效果。 根据 Jakub Linowski 对 300 多次测试的研究,布局实验往往会产生更好的结果。
最难优化的屏幕类型是什么? 同一项研究显示它是结帐屏幕(25 次测试的中位数效果为 +0.4%)。
#40。 测试后不检查有效性
这样测试就结束了。 你跑了足够长的时间,看到了结果,得到了 stat sig,但你能相信数据的准确性吗?
可能是在测试过程中出现了问题。 检查永远不会有害。
#41。 未正确读取结果
你的结果真正告诉你什么? 未能正确阅读它们很容易成为潜在的赢家,并且看起来像是彻底的失败。
- 深入分析您的分析。
- 查看您拥有的任何定性数据。
什么有效,什么无效? 为什么会这样?
你越了解你的结果越好。
#42。 不按细分查看结果
潜得更深一点总是值得的。
例如,一个新的变体似乎转化率很低,但在移动设备上,它的转化率提高了 40%!
您只能通过将其细分为您的结果来找到它。 看看使用的设备和那里的结果。 您可能会发现一些有价值的见解!
请注意您的分段大小的重要性。 您可能没有足够的流量到每个细分市场来完全信任它,但您始终可以运行仅限移动设备的测试(或任何渠道)并查看它的性能。
#43。 不从结果中学习
失败的测试可以让您深入了解需要进一步改进或进行更多研究的地方。 作为 CRO 最烦人的事情是看到拒绝从他们刚刚看到的东西中学习的客户。 他们有数据但不使用它……
#44。 接受失败者
或者更糟的是,他们接受了失败的变化。
也许他们更喜欢这种设计,转换率只有 1% 的差异,但随着时间的推移,这些影响会复合。 拿走那些小胜利!
#45。 不对结果采取行动
又更糟了?
获得胜利但不实施! 他们拥有数据,却什么也不做。 没有变化,没有洞察力,也没有新的测试。
#46。 不迭代和改进胜利
有时你可以搭便车,但还有更多。 就像我们之前说的,每场胜利都会给你带来两位数的提升是非常罕见的。
但这并不意味着您无法通过运行新的迭代和改进以及一次只提高 1% 的方式达到目标。
这一切都加起来所以继续改进!
#47。 Not sharing winning findings in other areas or departments
One of the biggest things we see with hyper-successful/mature CRO teams is that they share their winnings and findings with other departments in the company.
This gives other departments insights into how they can also improve.
- Find some winning sales page copy? Preframe it in your adverts that get them to the page!
- Find a style of lead magnet that works great? Test it across the entire site.
#48. Not testing those changes in other departments
And that's the key here. Even if you share insights with other departments, you should still test to see how it works.
A style design that gives lift in one area might give a drop in others, so always test!
#49. Too much iteration on a single page
We call this hitting the 'local maximum'.
The page you're running tests on has plateaued and you just can't seem to get any more lift from it.
You can try radical redesigns, but what next?
Simply move onto another page in the sales process and improve on that. (Ironically this can actually prove to give a higher ROI anyway.)
Taking a sales page from a 10% to 11% conversion can be less important than taking the page that drives traffic to it from 2% to 5%, as you will essentially more than double the traffic on that previous page.
If in doubt, find the next most important test on your list and start improving there. You may even find it helps conversion on that stuck page anyway, simply by feeding better prospects to it.
#50. Not testing enough!
Tests take time and there's just only so many that we can run at once.
所以,我们能做些什么?
Simply reduce the downtime between tests!
Complete a test, analyze the result, and either iterate or run a different test. (Ideally, have them queued up and ready to go).
This way you'll see a much higher return for your time investment.
#51. Not documenting tests
Another habit mature CRO teams have is creating an internal database of tests, which includes data about the page, the hypothesis, what worked, what didn't, the lift, etc.
Not only can you then learn from older tests, but it can also stop you from re-running a test by accident.
#52. Forgetting about false positives and not double-checking huge lift campaigns
Sometimes a result is just too good to be true. Either something was set up or recording wrong, or this just happens to be that 1 in 20 tests that gives a false positive.
所以,你可以做什么?
Simply re-run the test, set a high confidence level, and make sure you run them for long enough.
#53. Not tracking downline results
When tracking your test results, it's also important to remember your end goal and track downline metrics before deciding on a winner.
A new variant might technically get fewer clicks through but drives more sales from the people who do click.
In this instance, this page would actually be more profitable to run, assuming the traffic that clicks continues to convert as well…
#54. Fail to account for primacy and novelty effects, which may bias the treatment results
Let's say you're not just targeting new visitors with a change, but all traffic.
We're still segmenting them so 50% see the original and 50% see the new version, but we're allowing past visitors into the campaign. This means people who've seen your site before, read your content, seen your calls to action, etc.
Also, for the duration of the campaign, they only see their specific test version.
When you make a new change, it can actually have a novelty effect on your past audience.
Maybe they see the same CTA all the time and now just ignore it, right? In this case, a new CTA button or design can actually see a lift from past visitors, not because they want it more now, but because it's new and interesting.
Sometimes, you might even get more clicks because the layout has changed and they're exploring the design.
Because of this, you will usually get an initial lift in response, but which dies back down over time.
The key when running your test is to segment the audience after and see if the new visitors are responding as well as the old ones.
If it's much lower, then it could be a novelty effect with the old users clicking around. If it's on a similar level, you might have a new winner on your hands.
Either way, let it run for the full cycle and balance out.
#55。 运行考虑期变化
测试时要考虑的另一件事是任何可能改变观众考虑期的变体。
我是什么意思?
假设您通常不会立即获得销售。 潜在客户可能处于 30 天甚至更长的销售周期。
如果您正在测试直接影响他们考虑和购买时间的号召性用语,那将会扭曲您的结果。 一方面,您的控件可能会获得销售,但超出了测试期,因此您会错过它们。
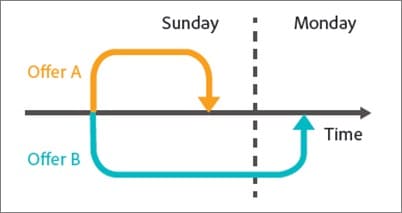
另一种情况是,如果你有一个提供交易的 CTA,一个让他们现在想要采取行动的任何其他东西的价格点,那么这几乎总是会扭曲你的结果,使这个版本看起来转换得更好。
请记住这一点,并在测试期间和之后仔细检查您的分析以确保。
#56。 X 次后不再重新测试
这不是关于某个页面或测试错误,而是更多关于测试理念。
是的,您可能有一个很棒的页面,是的,您可能已经对其进行了 20 次迭代才能达到今天的水平。
问题是几年后您可能需要再次检查整个页面。 环境变化,使用的语言和术语,产品可以调整。
随时准备好回到旧的广告系列并重新测试。 (拥有测试存储库的另一个原因很好。)
#57。 只测试路径而不测试产品
几乎我们所有人都专注于销售路径并为此进行测试。 但现实情况是,该产品还可以进行 A/B 测试和改进,甚至可以提供更高的提升。
想想 iPhone。

Apple 对其网站进行了测试并对其进行了改进,但产品的迭代和改进继续推动着更多的提升。
现在,您可能没有实体产品。 您可能有一个程序或数字报价,但是更多地了解您的受众的需求并对其进行测试,然后将其带回您的销售页面在提升方面可能是巨大的。
结论
所以你有它。 我们看到的 57 个常见和不常见的 A/B 测试错误以及如何避免它们。
您可以使用本指南来帮助您在未来的所有广告系列中回避这些问题。