
İçerik Stratejilerini Denetlemek için Python ve Site Haritalarını Kullanma
Yayınlanan: 2020-10-08Python Kütüphaneleri ile SEO adına neler yapılabileceğine olan ilgi artık bir sır değil. Bununla birlikte, programlama deneyimi az olan çoğu insan, çok sayıda kitaplığı içe aktarma ve kullanma veya zorlama konusunda zorluklar yaşar; sonuçlar, herhangi bir sıradan tarayıcı veya SEO aracının yapabileceğinin ötesindedir.
Bu nedenle SEO, SEM, SMO, SERP kontrolü ve içerik analizi için özel olarak oluşturulmuş bir Python kütüphanesi herkes için faydalıdır.
Bu yazıda, Elias Dabbas tarafından yaratılan ve geliştirilen ve SEO, PPC ve kodlama yeteneklerinde büyük bir potansiyel gördüğüm Advertools Python Library for SEO ile yapılabileceklerden birkaçına göz atacağız. Çok kısa bir süre içinde. Ayrıca özel Python betiklerini diğer Python kitaplıkları ile birlikte eğitici ve uyarlanabilir bir şekilde kullanacağız.
Elias Dabbas'ın XML site haritalarını indirmeye ve analiz etmeye yardımcı olan sitemap_to_df işlevi sayesinde bir site haritasından SEO için neler öğrenilebileceğini inceleyeceğiz (Site haritası, taranabilir ve dizine eklenebilir URL'leri Arama Motorlarına bildirmek için kullanılan XML biçiminde bir belgedir.)
Bu makale, farklı web sitelerini farklı yapılarına göre analiz etmek için nasıl özel Python kodları yazabileceğinizi, verileri SEO açısından nasıl yorumlayacağınızı ve içerik profilleri, URL'ler ve site yapıları söz konusu olduğunda nasıl bir arama motoru gibi düşünebileceğinizi gösterecektir. .
Bir Web Sitesinin İçerik Ölçeğini ve Stratejisini Site Haritasına Dayalı Analiz Etme
Site haritası, bir web sitesinin içeriği ne sıklıkta yayınladığı, içerik kategorileri, yayınlanma tarihleri, yazar bilgileri, içerik konusu gibi birçok farklı veri türünü yakalayabilen bir web sitesinin bir bileşenidir.
Normal şartlar altında scrapy ile bir site haritasını sıyırıp, Pandalar ile DataFrame'e çevirebilir, dilerseniz birçok farklı yardımcı kütüphane ile yorumlayabilirsiniz.
Ancak bu yazıda sadece Advertools ve bazı Pandas kütüphane yöntemlerini ve özelliklerini kullanacağız. Elde ettiğimiz verileri görselleştirmek için bazı kütüphaneler etkinleştirilecektir.
Hemen konuya girelim ve bazı önemli SEO içgörülerini sonuçlandırmak için site haritasını kullanmak üzere bir web sitesi seçelim.
Reklam Araçları ile Site Haritalarından Veri Çerçeveleri Çıkarma ve Oluşturma
Advertools'da, bir web sitesinin tüm site haritalarını tek bir kod satırıyla keşfedebilir, tarayabilir ve birleştirebilirsiniz.
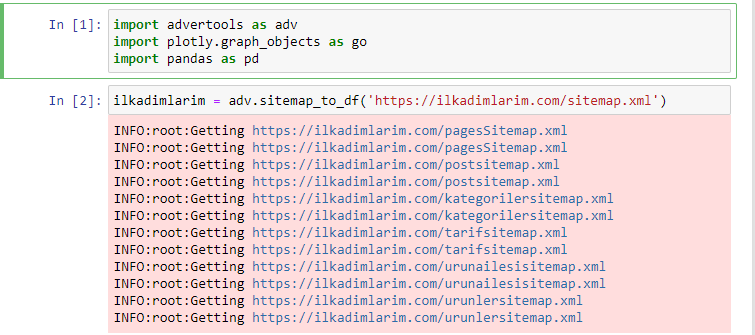
Normal bir kod düzenleyici veya IDE yerine Jupyter Notebook kullanmayı seviyorum.
İlk hücrede, verileri toplamak ve düzenlemek için Panda'ları ve Reklam araçlarını ve verileri görselleştirmek için Plotly.graph_objects'i içe aktardık.
adv.sitemap_to_df('site haritası adresi') komutu tüm site haritalarını toplar ve bunları bir DataFrame olarak birleştirir.
Aynı şeyi Pandalar ve Reklam Araçlarını kullanarak yaparsanız, hangi site haritasında hangi URL'nin mevcut olduğunu keşfedebilirsiniz.
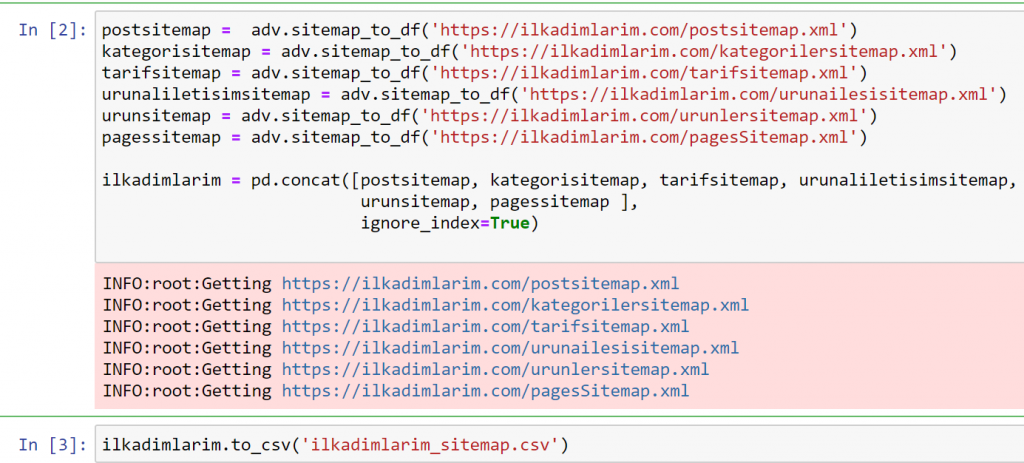
Yukarıdaki örnekte aynı site haritalarını ayrı ayrı çekip pd.concat komutuyla birleştirdik ve sonucu CSV'ye aktardık. Önceki örnek, site haritası dizin dosyasını kullandı; bu durumda işlev, diğer tüm site haritalarını almaya gider. Bu nedenle, web sitesinin belirli bir bölümüyle ilgileniyorsanız, burada yaptığımız gibi belirli site haritalarını seçme seçeneğiniz vardır.
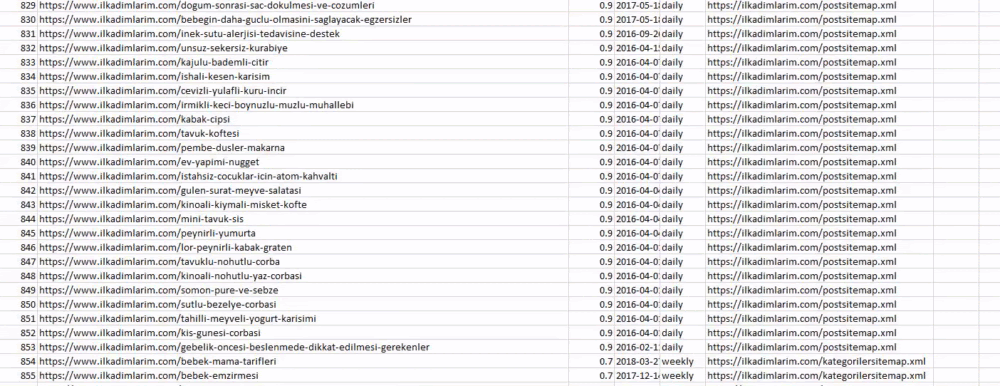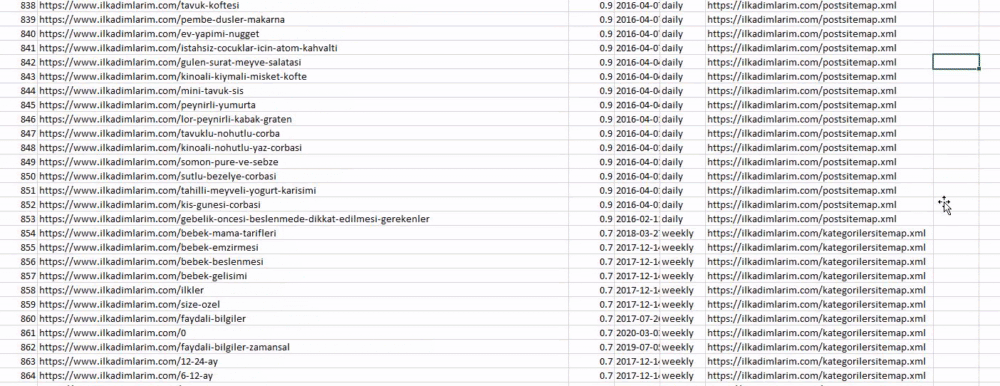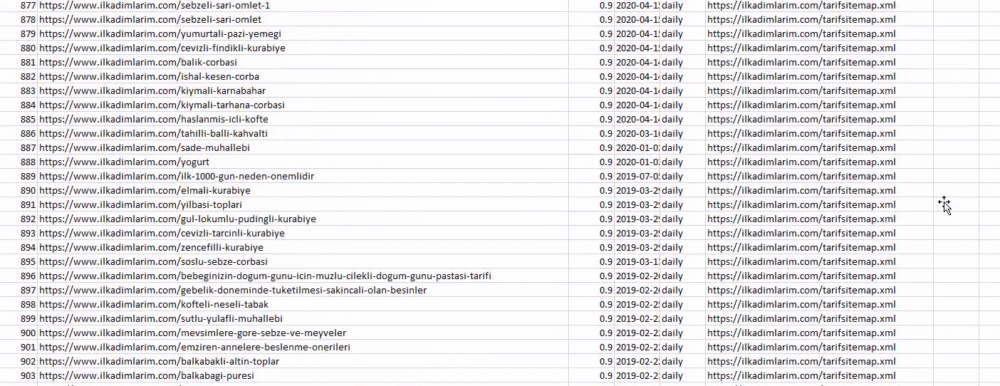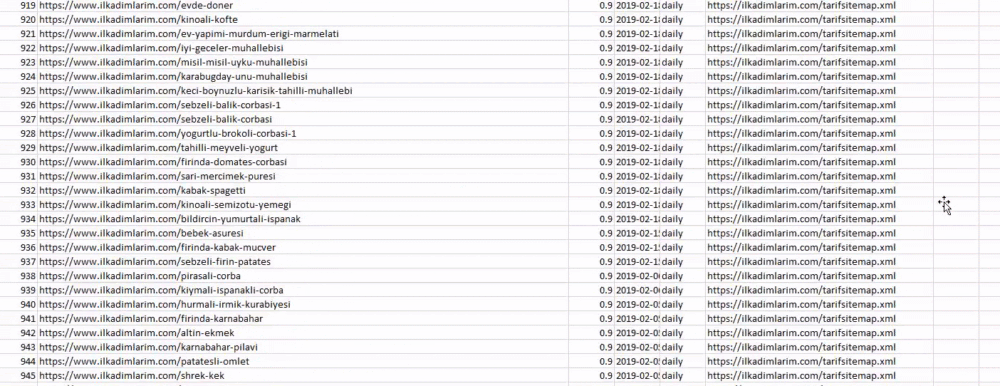
Yukarıda farklı site haritası adlarına sahip bir sütun görebilirsiniz. görmezden_index=True bölümü, birden çok veri çerçevesini birleştirdiyseniz, farklı DataFrame'lerin dizin numaralarının düzgün sıralanması içindir.
Tarama Verileri³
 Daha fazla bilgi edin
Daha fazla bilgi edinPython ile İçerik Analizi için Site Haritası Veri Çerçevesini Temizleme ve Hazırlama
Bir site haritası aracılığıyla bir web sitesinin içerik profilini anlamak için Advertools ile elde ettiğimiz DataFrame'i incelemek için onu hazırlamamız gerekiyor.
Verilerimizi şekillendirmek için Pandas kitaplığındaki bazı temel komutları kullanacağız:
İlkadımlarım = pd.read_csv('ilkadimlarım_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(sütunlar = 'Adsız: 0')
ilkadimlerim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
“İlkadımlarım” Türkçe'de “ilk adımlarım” anlamına geliyor ve tahmin edebileceğiniz gibi bebekler, hamilelik ve annelik için bir site.
Bu hatlarla üç işlem gerçekleştirdik.
- Adsız: DataFrame'den 0 adlı boş bir sütunu kaldırdık. Ayrıca, pd.to_csv() işleviyle 'index = False' kullanırsanız, başlangıçta bu 'Adsız 0' sütununu görmezsiniz.
- Son Değişiklik sütunundaki verileri Tarih Saat'e dönüştürdük.
- “lastmod” kolonunu index pozisyonuna getirdik.
Aşağıda DataFrame'in son halini görebilirsiniz.
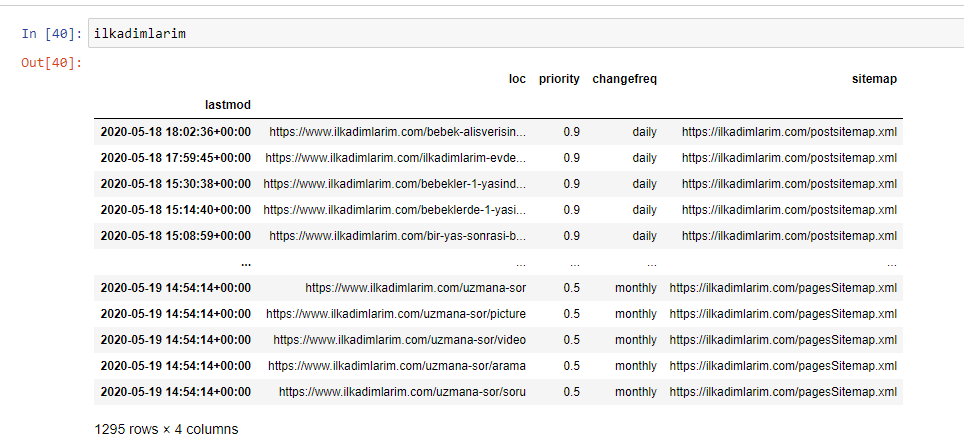
Google'ın site haritalarındaki öncelik ve değişiklik sıklığı bilgilerini kullanmadığını biliyoruz. Buna "gürültü torbası" diyorlar. Ancak diğer arama motorları için web sitenizin performansına önem veriyorsanız, onları da incelemenizde fayda var. Şahsen, bu verilerle pek ilgilenmiyorum, ancak yine de DataFrame'den kaldırmam gerekmiyor.
Site haritalarını başka bir sütunda kategorize etmek için bir kod satırına daha ihtiyacımız var.
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
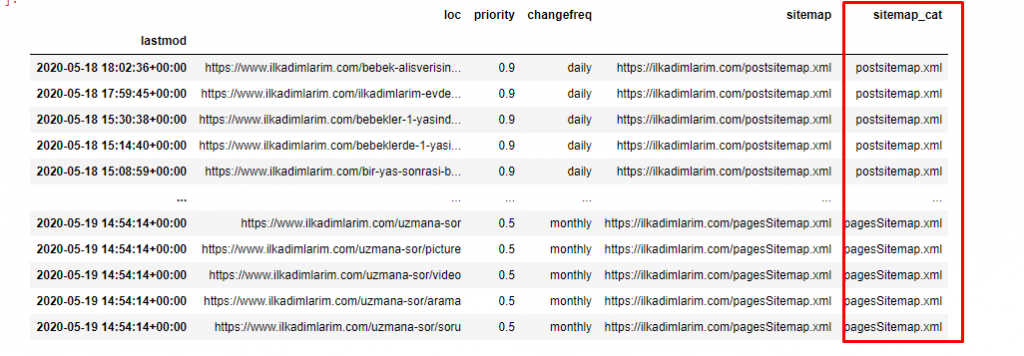
Pandalarda bir DataFrame'e yeni sütunlar veya satırlar ekleyebilir veya bunları kolayca güncelleyebilirsiniz. DataFrame['new_columns'] kod parçacığıyla yeni bir sütun oluşturduk. DataFrame['column_name'].str , bir sütundaki veri türünü değiştirerek farklı işlemler yapmamızı sağlar. .split ('/') ile ilgili sütundaki string datayı / karakterine bölüp bir liste haline getiriyoruz. .str [sayı] ile, o listede belirli bir öğeyi seçerek yeni sütunun içeriğini oluşturuyoruz.
Site Haritası Sayısı ve Çeşitlerine Göre İçerik Profili Analizi
Site haritalarını türlerine göre farklı bir sütuna yerleştirdikten sonra her bir site haritasındaki içeriklerin % kaçını kontrol edebiliriz. Böylece web sitesinin hangi bölümünün daha önemli olduğu konusunda da bir çıkarım yapabiliriz.
ilkadimlarım['sitemap_cat'].value_counts(normalize = True) * 100
- DataFrame['column_name'] işlemi yapmak istediğimiz kolonu seçiyoruz.
- value_counts() sütundaki değerlerin sıklığını sayar.
- normalize=True , değerlerin ondalık olarak oranını alır.
- Ondalık sayıları *100 ile büyüterek okumayı kolaylaştırıyoruz.
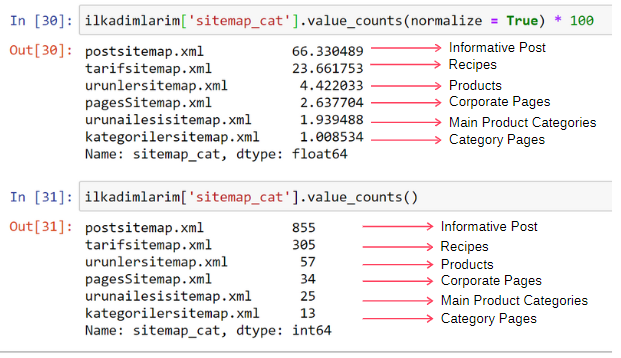
İçeriğin %65'inin Gönderi Site Haritasında ve %23'ünün Tarif Site Haritasında olduğunu görüyoruz. Ürün Site Haritası içeriğin yalnızca %2'sine sahiptir.
Bu, geniş bir kitleye kendi ürünlerini pazarlamak için bilgilendirici içerik oluşturması gereken bir web sitemiz olduğunu gösteriyor. Tezimizin doğru olup olmadığını kontrol edelim.
Devam etmeden önce ilkadımlarım['sitemap_cat'] sütununun adını aşağıdaki kod ile 'URL_Count' olarak değiştirmemiz gerekiyor:
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- rename() işlevi, verileri ve anlamını daha derin bir düzeyde bağlamak için sütunlarınızın veya dizinlerinizin adını değiştirmek için kullanışlıdır.
- 'inplace=True' özniteliği sayesinde sütun adını kalıcı olacak şekilde değiştirdik.
- İlkadimlarim.rename(str.capitalize, axis='columns', inplace=True) ile sütunlarınızın ve dizinlerinizin harf stillerini de değiştirebilirsiniz. Bu, İlkadımlarım'daki her sütunun sadece ilk harflerini büyük olarak yazar.

Şimdi, devam edebiliriz.
Bu bilgileri tek karede görmek için aşağıdaki kodu kullanabilirsiniz:
(ilkadımlarım['sitemap_cat']
.değer_sayısı()
.to_frame()
.assign(yüzde=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', yüzde='{:.1%}')))
- to_frame() , seçilen sütunda value_counts() tarafından ölçülen değerleri çerçevelemek için kullanılır.
- atama() , çerçeveye belirli değerler eklemek için kullanılır.
- lambda , Python'daki anonim işlevleri ifade eder.
- Burada Lambda işlevi ve site haritası türleri, Pandas div() yöntemiyle toplam site haritası sayısına bölünür.
- style() , belirtilen son değerlerin nasıl yazılacağını belirler.
- Burada format() metodu ile noktadan sonra kaç hane yazılacağını ayarlıyoruz.
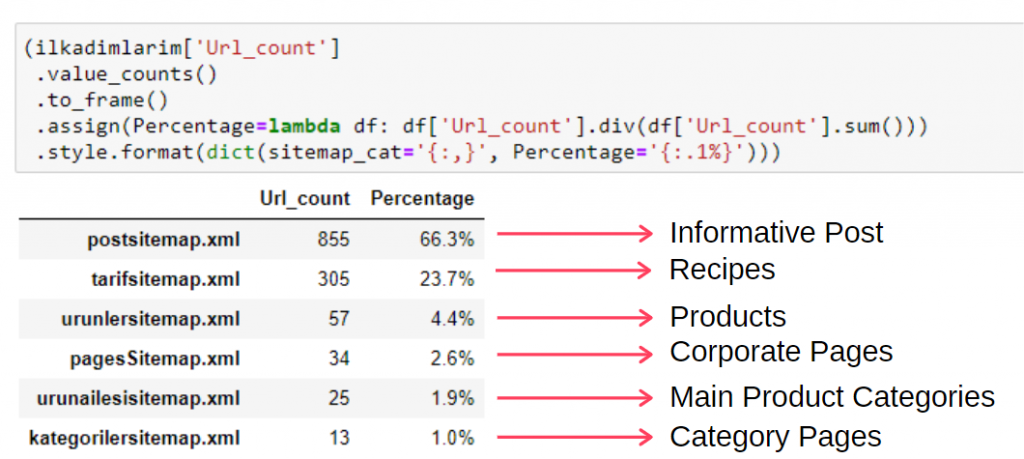
Bu nedenle, bu web sitesi için içerik pazarlamasının önemini görüyoruz. Durumlarını daha derinlemesine incelemek için iki tek satır kod ile yıllara göre makale yayınlama eğilimlerini de kontrol edebiliriz.
Site Haritaları ve Python ile İçerik Yayınlama Trendlerini Yıllara Göre İnceleme ve Görselleştirme
İncelenen web sitesinin içerik ve niyet eşleştirmesini site haritası kategorilerine göre yaptık ancak henüz zaman bazlı bir sınıflandırma yapmadık. Bunu gerçekleştirmek için resample() yöntemini kullanacağız.
post_per_month = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample, Pandas kitaplığındaki bir yöntemdir. resample('A') yıllık DataFrame için veri serilerini kontrol eder. Haftalarca 'W', aylarca 'M' kullanabilirsiniz.
Loc burada dizini sembolize eder; count, veri örneklerinin toplamını saymak istediğiniz anlamına gelir.
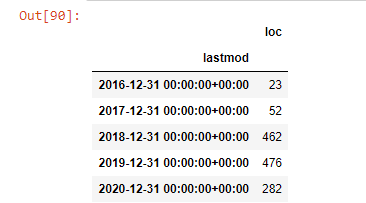
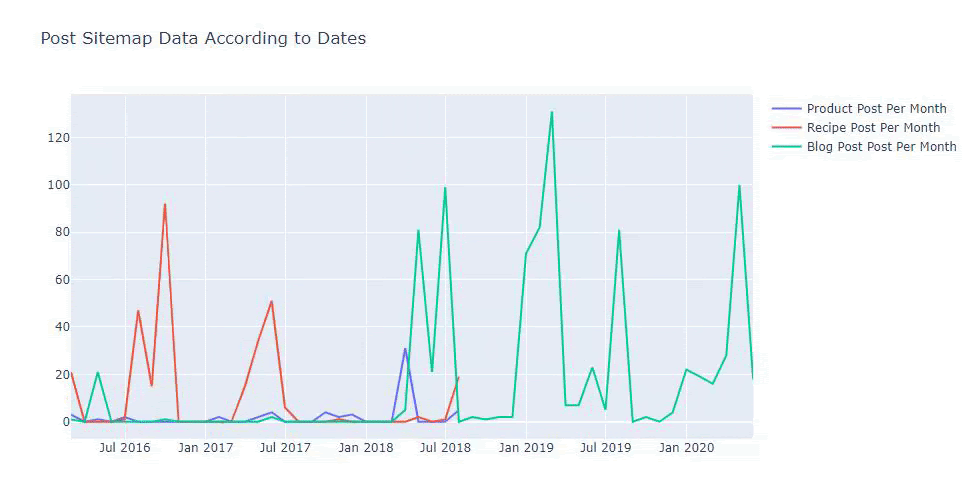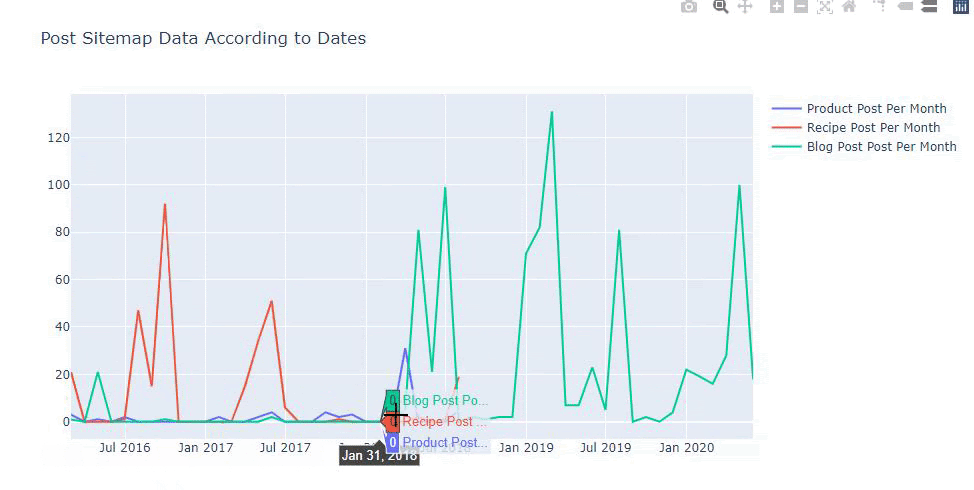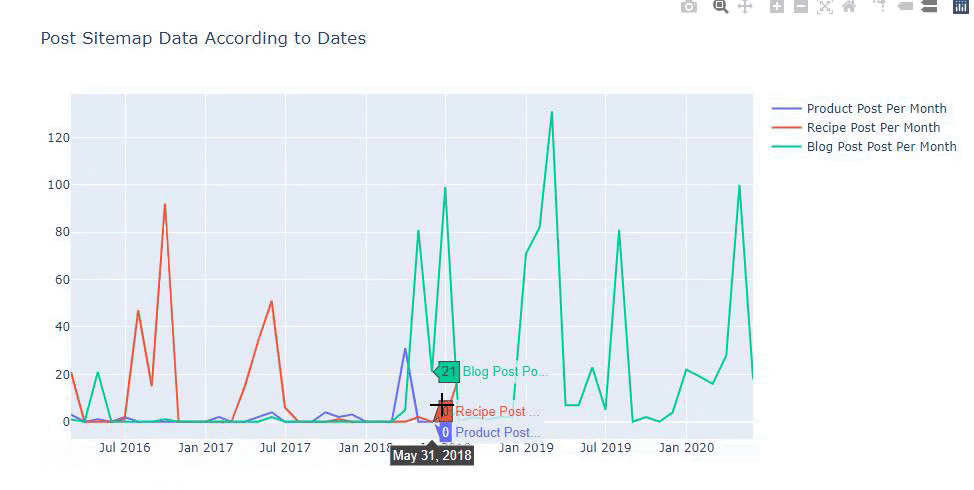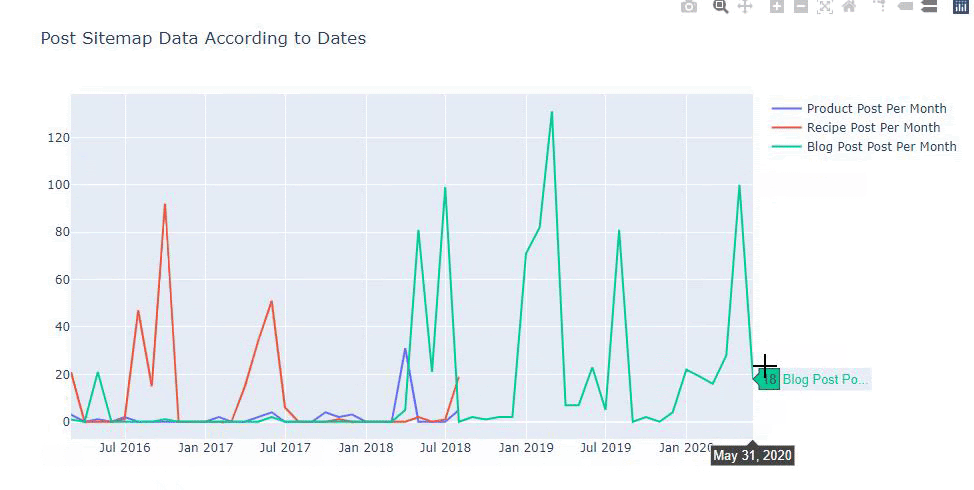
2016 yılında makale yayınlamaya başladıklarını ancak 2017'den sonra ana yayıncılık eğilimlerinin arttığını görüyoruz. Bunu Plotly Graph Objects yardımıyla da grafik haline getirebiliriz.
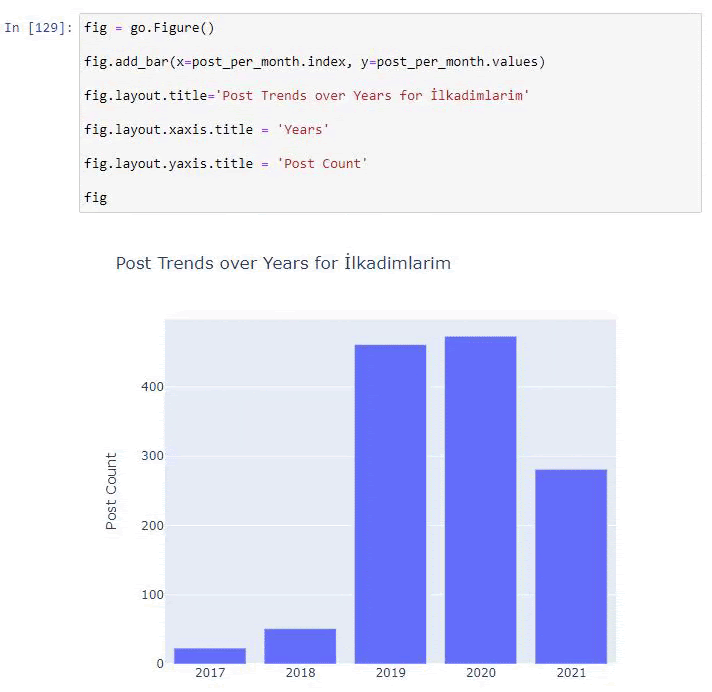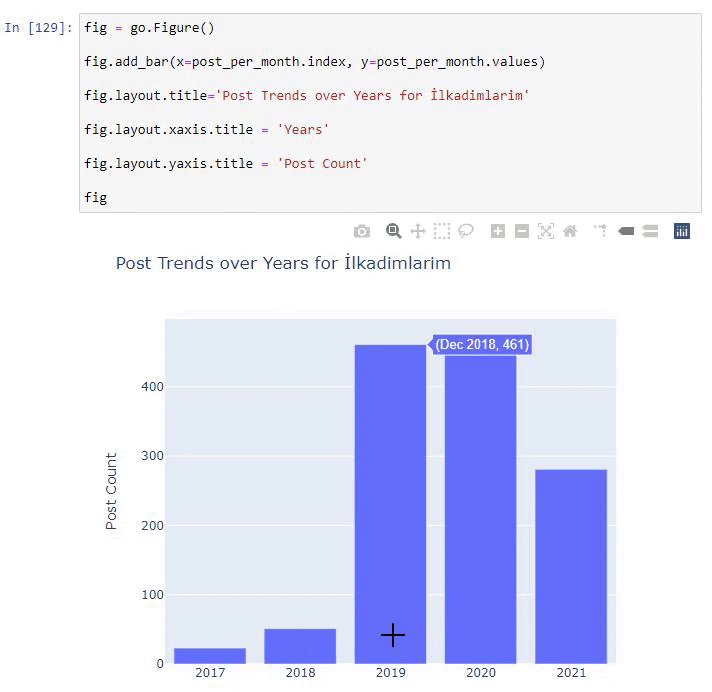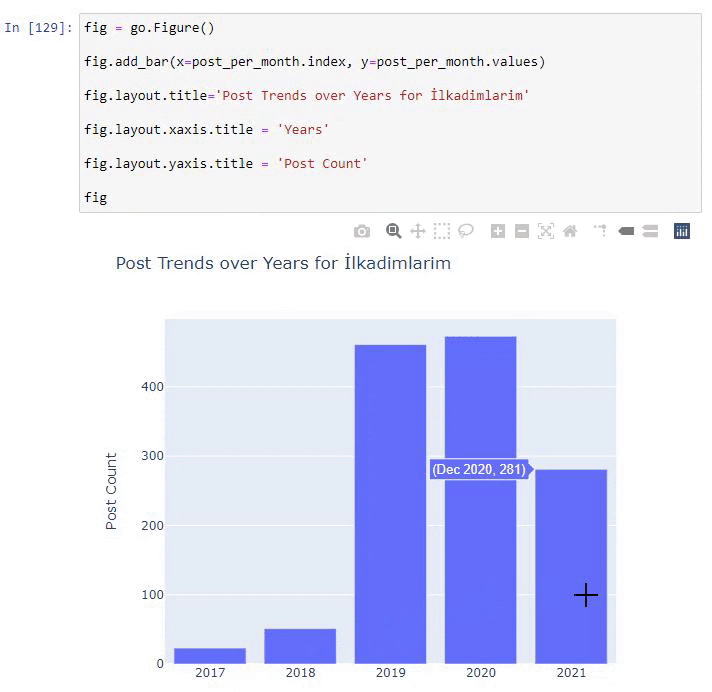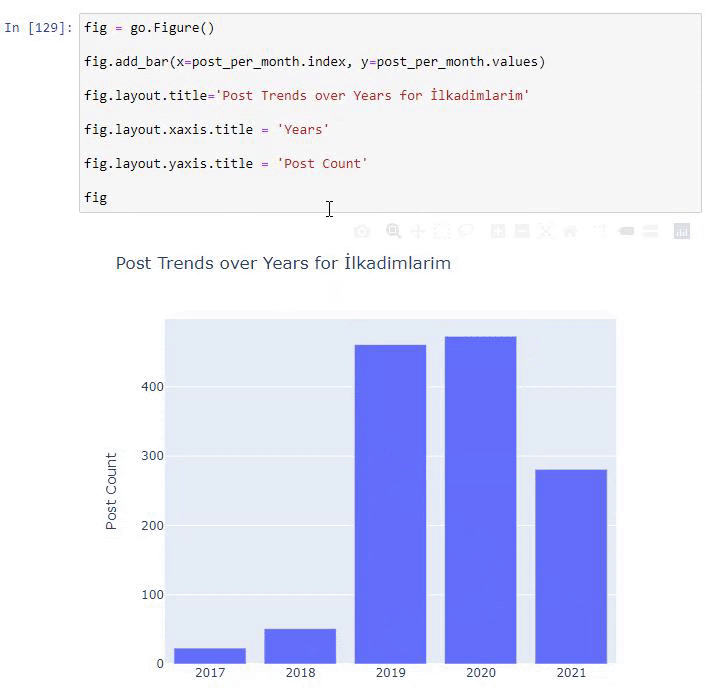
Bu Plotly Bar Plot kod parçacığının açıklaması:
- fig = go. Figure() bir figür oluşturmak içindir.
- fig.add_bar() , şekle bir barplot eklemek içindir. Ayrıca parantez içinde X ve Y eksenlerinin ne olacağını belirliyoruz.
- Fig.layout , şekil ve eksenler için genel bir başlık oluşturmak içindir.
- Son satırda ise go'ya eşit olan fig komutu ile oluşturduğumuz grafiği çağırıyoruz. Figure()
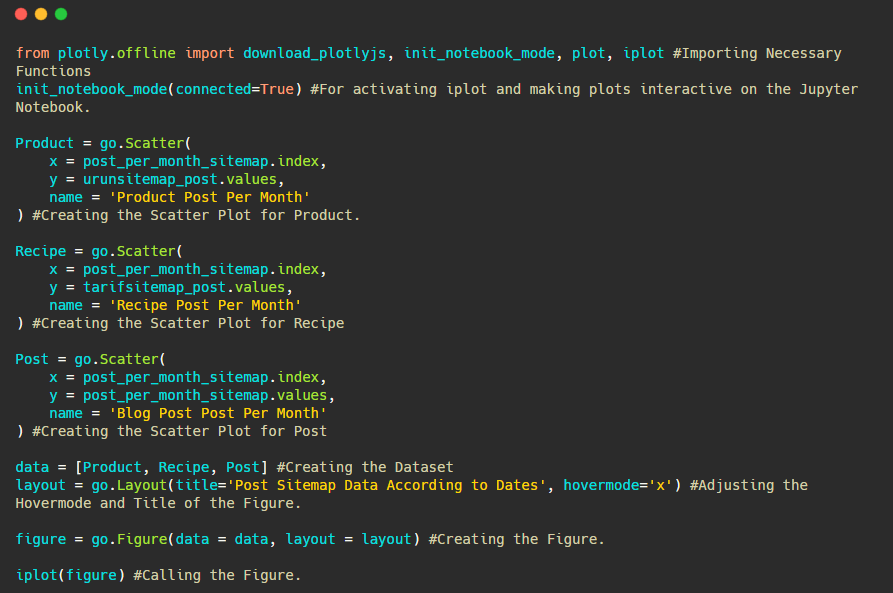
Aşağıda, dağılım grafiği ve barplot ile aynı verileri aya göre bulacaksınız:
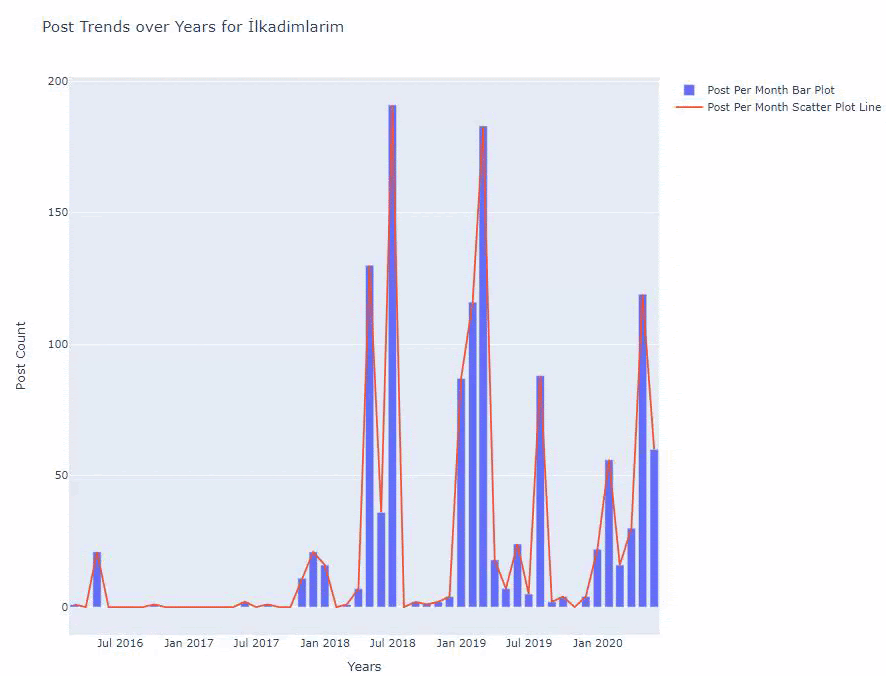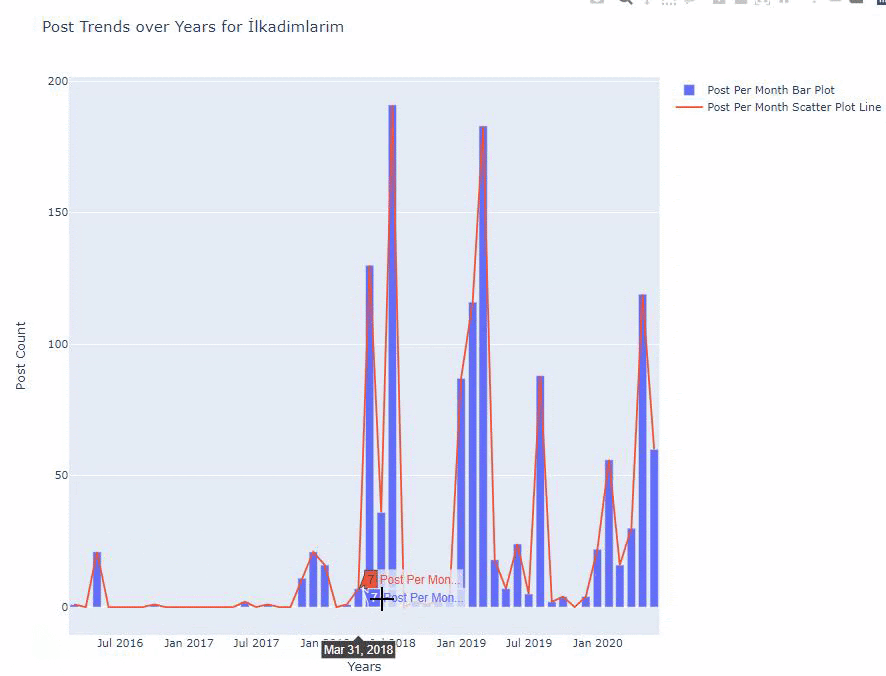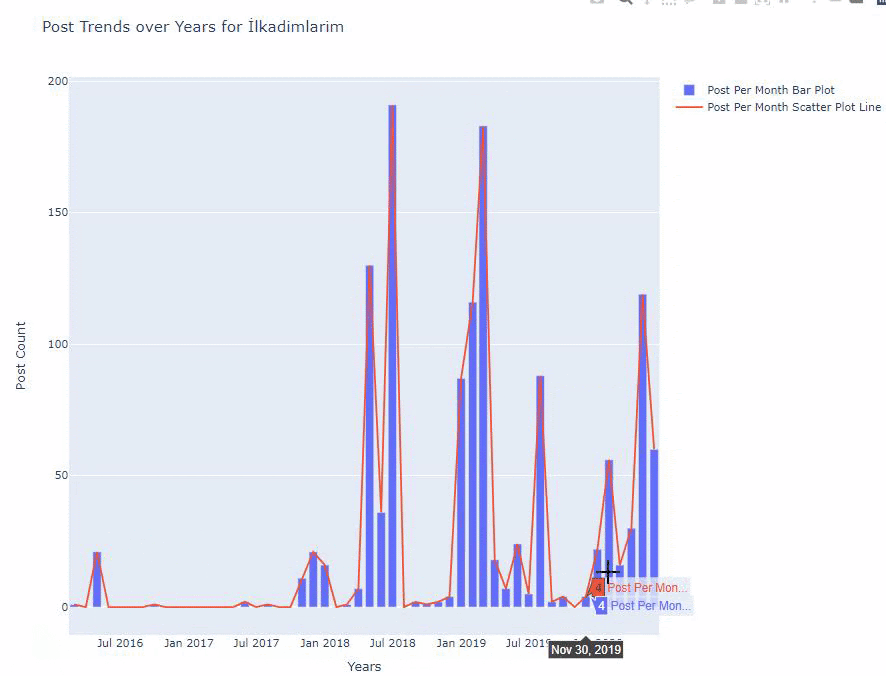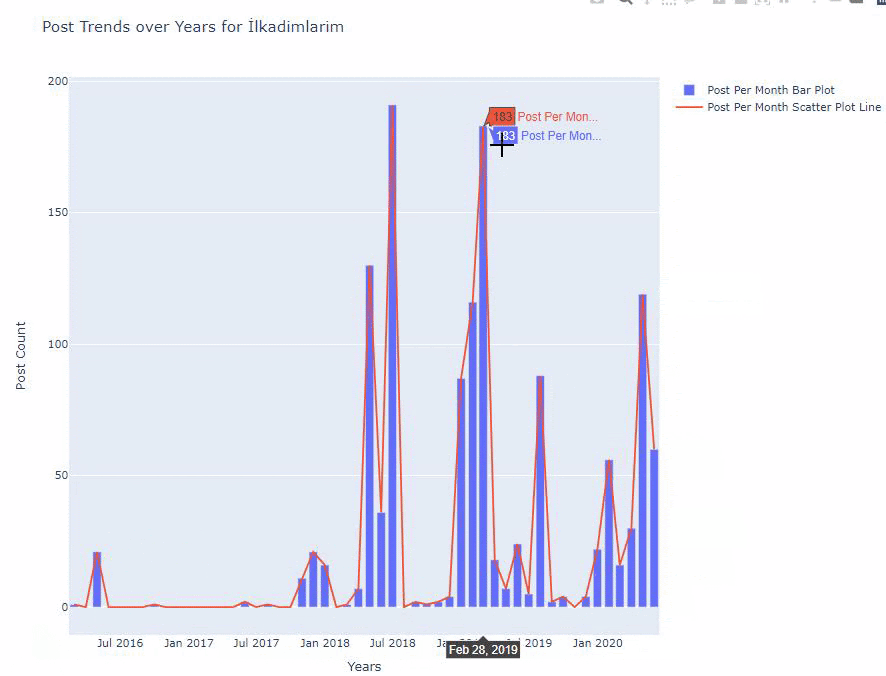
İşte bu rakamı oluşturmak için kodlar:
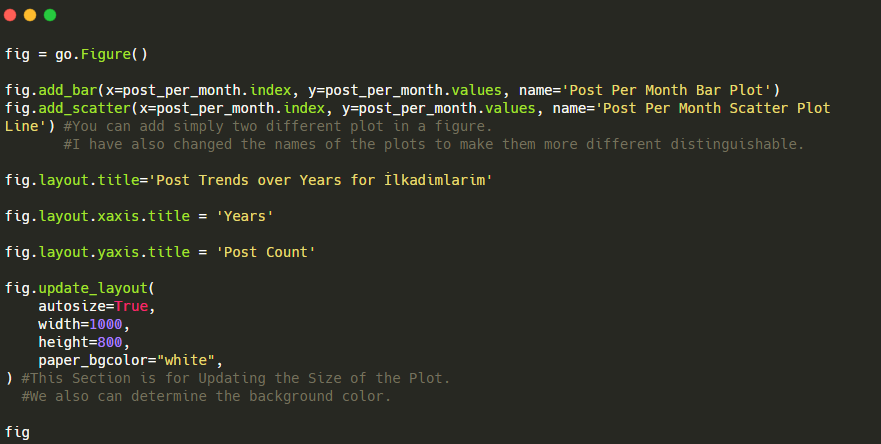
fig.add_scatter() ile ikinci bir arsa ekledik ve ayrıca name özniteliğini kullanarak isimleri değiştirdik. fig.update_layout() , grafiğin boyutunu ve arka plan rengini değiştirmek içindir.
Ayrıca vurgulu modunu, çubuklar arasındaki mesafeyi ve daha fazlasını değiştirebilirsiniz. Sadece kodları paylaşmak yeterli bence burada her bir kodu ayrı ayrı anlatmak asıl konudan uzaklaşmamıza neden olabilir.
Rakiplerin içerik yayınlama eğilimlerini aşağıdaki gibi kategorilere göre de karşılaştırabiliriz:
Bu çizelge ikinci yöntemle oluşturuldu, görebileceğiniz gibi aralarında hiçbir fark yok ama bir tanesi oldukça basit.
Üç ayrı site haritasından içerik yayınlama sıklığını ve trendini çizebilmek için en uzun aralığa sahip site haritasını X eksenine yerleştirmeliyiz. Böylece, incelediğimiz web sitesinin farklı arama amaçları için her farklı içerik türünü yayınlama sıklığını karşılaştırabiliriz.
Aşağıdaki ilgili kodları incelediğinizde yukarıdakilerden çok da farklı olmadığını göreceksiniz.
Birden fazla Y ekseni ile bir dağılım grafiği oluşturmak için aşağıdaki kodu kullanabilirsiniz.
Farklı site haritalarını birleştirmek ve dağılım grafiğinde birden çok Y Ekseni kullanmak için sütunlar için bir for döngüsü kullanmak gibi başka yöntemler de var, ancak böyle küçük bir site için buna ihtiyacımız yok. Çoğunlukla yüzlerce site haritası olan web sitelerinde bu yöntemi kullanmak daha mantıklı olacaktır.
Ayrıca, web sitesi küçük olduğu için grafik sığ görünebilir, ancak daha sonra milyonlarca URL'li bir web sitesindeki makalede göreceğiniz gibi, bu tür grafikler, farklı siteleri karşılaştırmanın yanı sıra farklı kategorileri karşılaştırmanın harika bir yoludur. aynı web sitesi.
Site Haritaları ve Python ile İçerik Kategorilerini, Amaç ve Yayınlama Trendlerini İnceleme ve Görselleştirme
Bu bölümde, makalenin başında söylediğimiz az sayıda ürünü pazarlamak için belirli bir bilgi alanında çok sayıda içerik yazıp yazmadıklarını kontrol edeceğiz. Bu sayede diğer markalarla içerik ortaklığı yapıp yapmadıklarını görebiliriz.
Site haritalarında başka neler bulunabileceğini göstermek için biraz daha kazmaya devam edeceğiz. Diğerleri gibi site haritasının 'loc' kısmından da bazı bilgiler alabiliriz.
İlkadımlarım'ın URL'lerinde kategori dökümü yoktur. Bir web sitesinin URL'lerinde kategori dökümü varsa, içerik dağıtımı hakkında çok daha fazla şey öğrenebiliriz. Değilse, aynı verilere ek kod yazarak erişebiliriz, ancak yalnızca daha az kesinlik ile.
Bu noktada, milyarlarca siteyi tarayan arama motorlarının web sitenizi anlamasını sağlayan URL dökümlerinin ne kadar az maliyetli olduğunu hayal edebilirsiniz.
a = ilkadımlarım['loc'].str.contains(“bebek|hamile|haftalik”)
bebek: bebeğim
hamile: hamile
Haftalık: haftalık veya “haftalık hamile”
baby_post_count = ilkadımlarım[a].resample('M')['loc'].count()
baby_post_count.to_frame()
Buradaki str() yöntemi yine belirli işlemleri seçtiğimiz sütunu ayarlamamıza izin veriyor.
include () metodu ile stringe dönüştürülen data içerisinde olup olmadığını kontrol etmek için datayı belirliyoruz.
Burada, “|” terimler arasında "veya" anlamına gelir.
Ardından filtrelediğimiz verileri bir değişkene atarız ve daha önce kullandığımız resample() yöntemini kullanırız.
sayma yöntemi ise hangi verinin kaç kez kullanıldığını ölçer.
count() ile elde edilen sonuç, yine to_frame() ile çevrelenir.
Ayrıca, str.contains() varsayılan olarak Regex değerlerini alır, bu da daha az kodla daha karmaşık filtreleme koşulları oluşturabileceğiniz anlamına gelir.
Yani bu noktada “bebek”, “haftalık”, “hamile” kelimelerini içeren URL'leri ilkadımlarımda bir değişkene atarız ve ardından URL'lerin yayınlanma tarihini bu filtre için uygun koşullara koyarız. bir çerçeve içinde oluşturulur.
Sonra aynısını 'aptamil' kelimesini içeren URL'ler için yapıyoruz. Aptamil, İlkadımlarım tarafından tanıtılan bir bebek beslenme ürününün adıdır. Dolayısıyla bilgilendirici ve ticari içeriklerin yayın yoğunluğuna da dikkat edebiliriz.
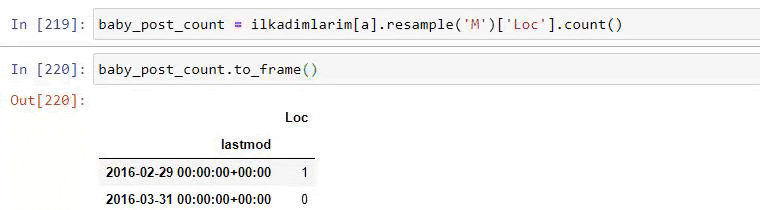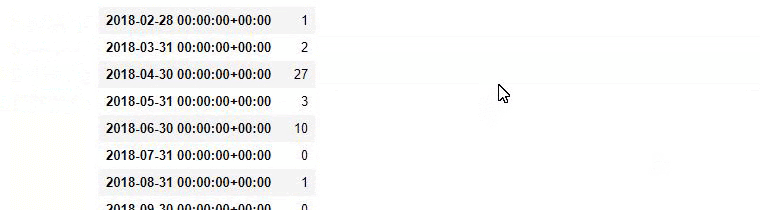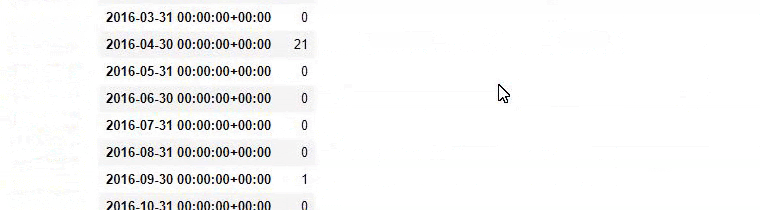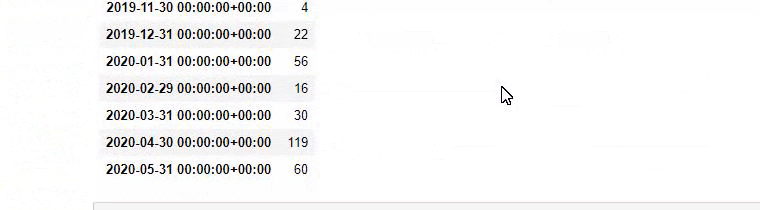
Ayrıca, URL'lerden daha kesin ve kesin bilgilerle farklı arama amaçları için yıllar boyunca programlar yayınlayan iki farklı içerik grubunun görebilirsiniz.
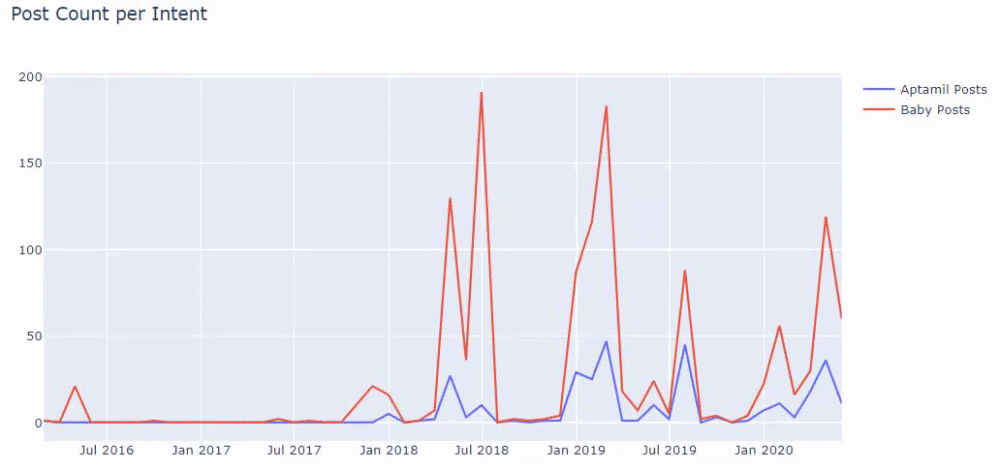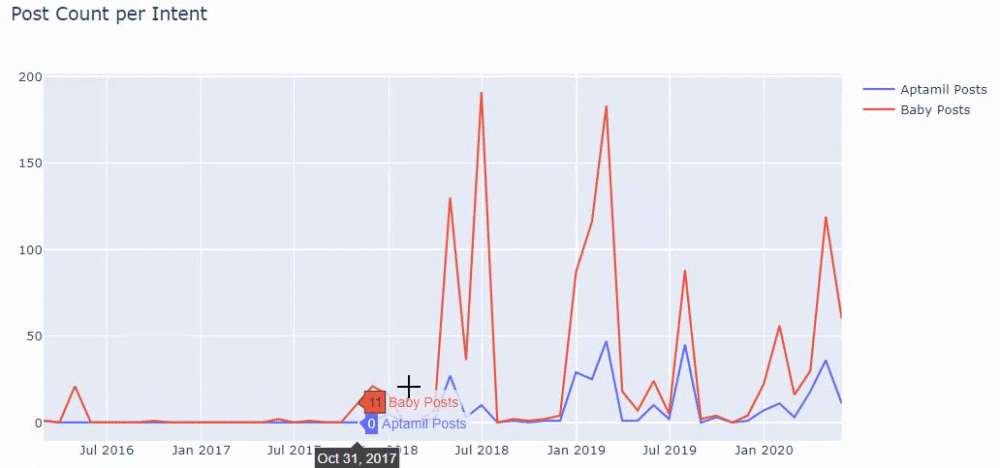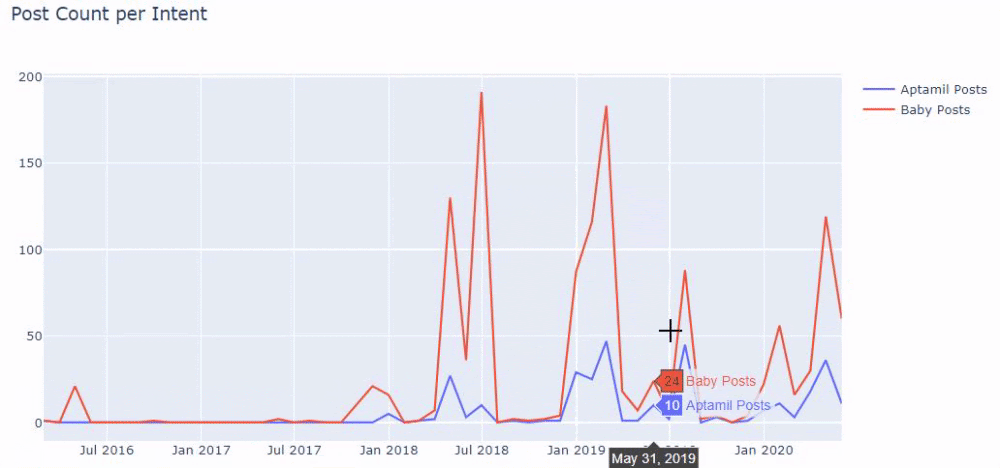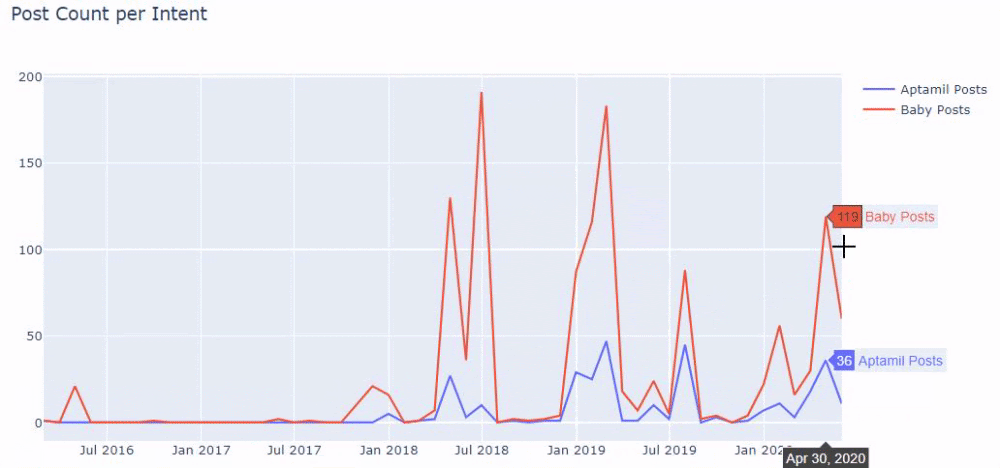
Bu grafiği oluşturacak kod, önceki grafik için kullanılan kodla aynı olduğu için paylaşılmadı.
Google'daki arama operatörleri yardımıyla İlkadimlarım.com'da Aptamil kelimesinin bağlantı metninde kullanıldığı sayfaları istediğimde 38 sonuç alıyorum. Bu sayfaların önemli bir kısmı bilgilendiricidir ve ticari içerikle bağlantılıdır.
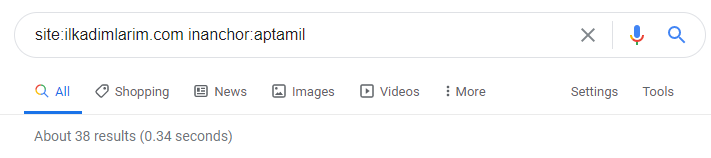
Tezimiz kanıtlanmıştır.
“İlk Adımlarım”, hedef kitlesine ulaşmak için annelik, bebek bakımı ve hamilelik hakkında yüzlerce bilgilendirici içerik kullanıyor. “İlkadımlarım” bu içerikten Aptamil ürünlerini içeren sayfalara link vererek kullanıcıları oraya yönlendirir.

Python ile Site Haritaları Aracılığıyla Karşılaştırmalı İçerik Profili Oluşturma ve İçerik Stratejisini Analiz Etme
Şimdi isterseniz aynı sektörden bir firma için aynısını yapalım ve bu sektörün genel durumunu ve bu iki marka arasındaki strateji farklarını anlamak için bir karşılaştırma yapalım.
İkinci örnek olarak Prima.com.tr'yi seçtim, yani Prima, Türkiye'de Prima markasını kullanıyor. Prima'nın tek bir site haritası olduğundan, site haritalarına göre sınıflandırma yapamayacağız, ancak en azından URL'lerinde farklı kesintiler var. Bu yüzden çok şanslıyız: daha az kod yazmamız gerekecek.
Anlaşılması zor bir site yaptığınızda Google'ın sizin için çalıştırması gereken algoritmaların ne kadar maliyetli olduğunu bir düşünün! Bu, tarama maliyeti hesaplamasını, yalnızca URL yapısıyla ilgili olarak bile, zihninizde daha somut hale getirmeye yardımcı olabilir.
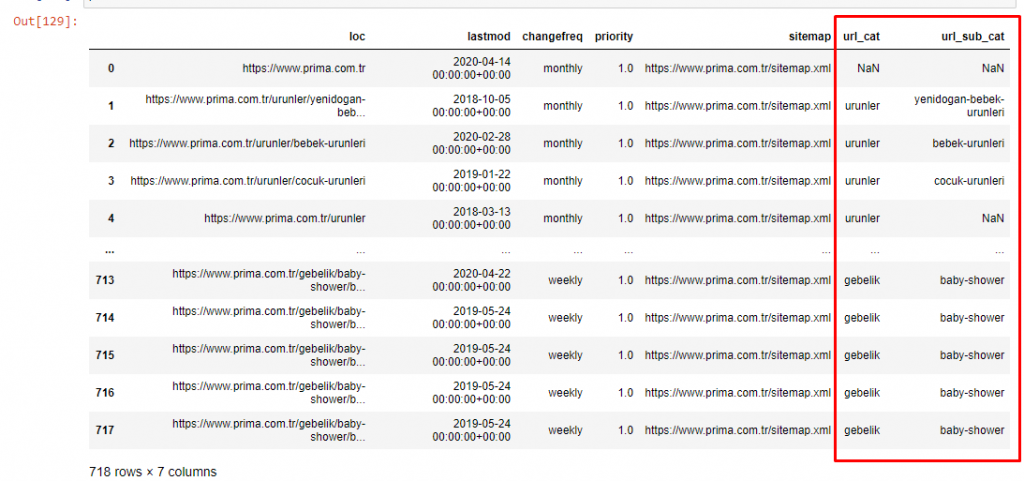
Yazının hacmini daha fazla büyütmemek için daha önce yaptığımız işlemlere benzer işlemlerin kodlarını koymuyoruz.
Artık içerik kategorisi dağılımlarını URL kategorilerine ve URL alt kategorilerine göre inceleyebiliriz. Kurumsal web sayfalarının çok fazla olduğunu görüyoruz. Bu kurumsal web sayfaları “prima-hakkinda” (“Prima Hakkında”) bölümünde yer almaktadır. Ama Python ile kontrol ettiğimde ürünlerini ve kurumsal web sayfalarını tek bir kategoride birleştirdiklerini görüyorum. İçerik dağılımlarını aşağıda görebilirsiniz:

Aynı işlemi aşağıdaki alt kategoriler için de yapabiliriz.
Prima'nın "hamilelik"in (Arapça hamilelik) bir çeşidi olan "gebelik"i (Türkçe hamilelik) kullanması ve her ikisinin de hamilelik dönemi anlamına gelmesi ilginçtir.

Şimdi içeriklerinde daha derin bir sınıflandırma görüyoruz. İçeriğin %9,2'si sağlıklı hamilelik, %7,3'ü bebeklerin büyüme süreci, %8,3'ü bebeklerle yapılabilecek aktiviteler, %0,7'si bebeklerin uyku düzeni hakkındadır. Hatta %3,9 ile diş çıkarma, %1,9 ile bebek güvenliği, %1,4 ile aileye hamileliği açıklamak gibi konular bile var. Gördüğünüz gibi, yalnızca URL'ler ve bunların dağıtım yüzdesi ile bir endüstriyi tanıyabilirsiniz.
Bu mükemmel bir sınıflandırma değil ama en azından rakiplerimizin zihniyet ve içerik pazarlama trendlerini ve web sitelerinin içeriklerini kategorilere göre görebiliyoruz. Şimdi içerik yayınlama sıklığını aylara göre kontrol edelim.
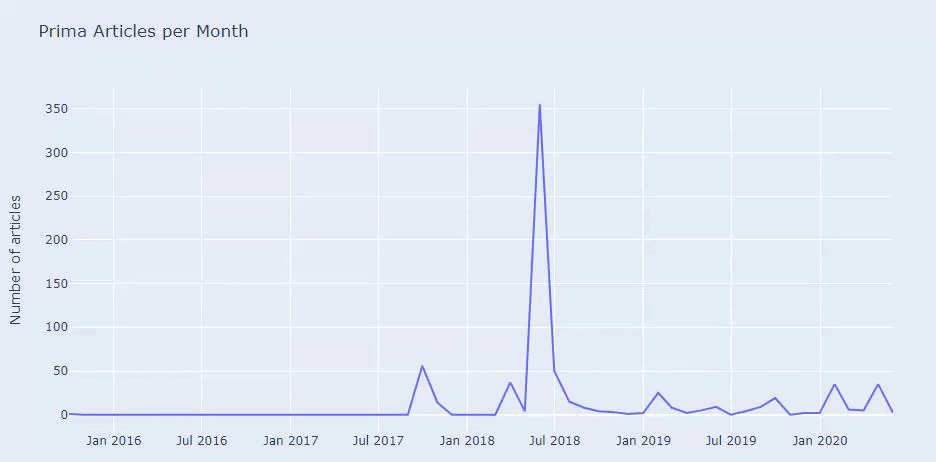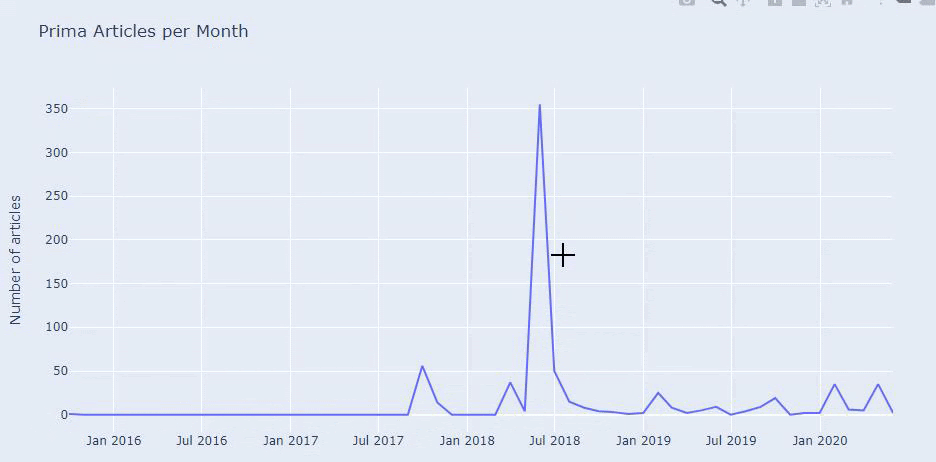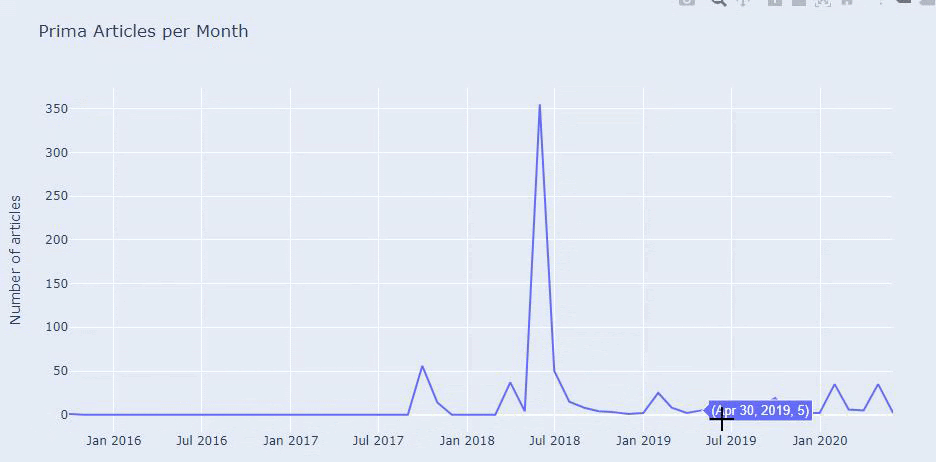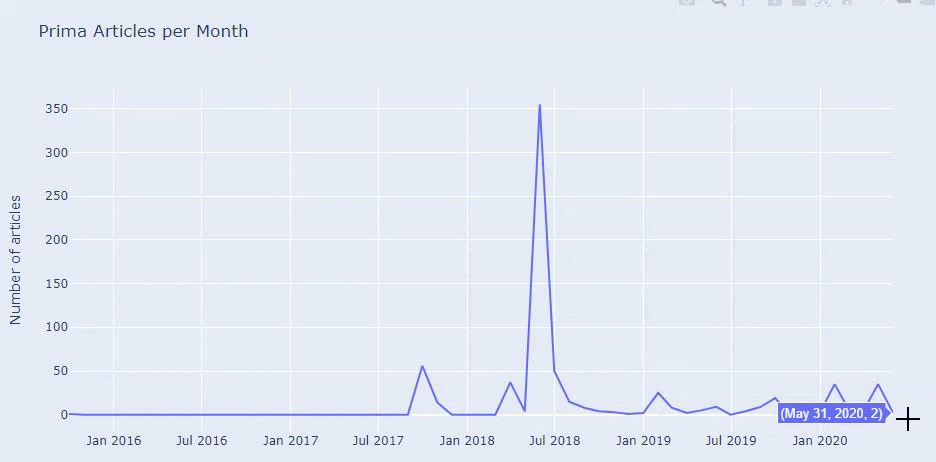
Temmuz 2018'de 355 makale yayınladıklarını ve Site Haritasına göre içeriklerinin o zamandan beri yenilenmediğini görüyoruz. Ayrıca içerik yayınlama eğilimlerini yıllar içinde kategorilere göre de karşılaştırabiliriz. Görüldüğü gibi içerikleri öncelikli olarak dört farklı kategoride yer alıyor ve çoğu aynı ayda yayınlanıyor.
Devam etmeden önce site haritası verilerinin her zaman doğru olmayabileceğini söylemeliyim. Örneğin, Lastmod verileri bu tarihte tüm site haritalarını yeniledikleri için tüm URL'ler için güncellenmiş olabilir. Bunu aşmak için, Wayback Machine'i kullanarak o zamandan beri içeriklerini değiştirmediklerini de kontrol edebiliriz.
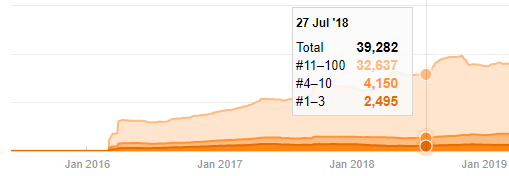
Şüpheli görünse bile bu veriler gerçek olabilir. Türkiye'de pek çok şirket bir an önce çok sayıda sipariş verme ve içerik yayınlama eğiliminde. Anahtar kelime sayılarını kontrol ettiğimde, bu zaman diliminde bir sıçrama görüyorum. Dolayısıyla karşılaştırmalı bir içerik profili ve strateji analizi yapıyorsanız bu konuları da düşünmelisiniz.
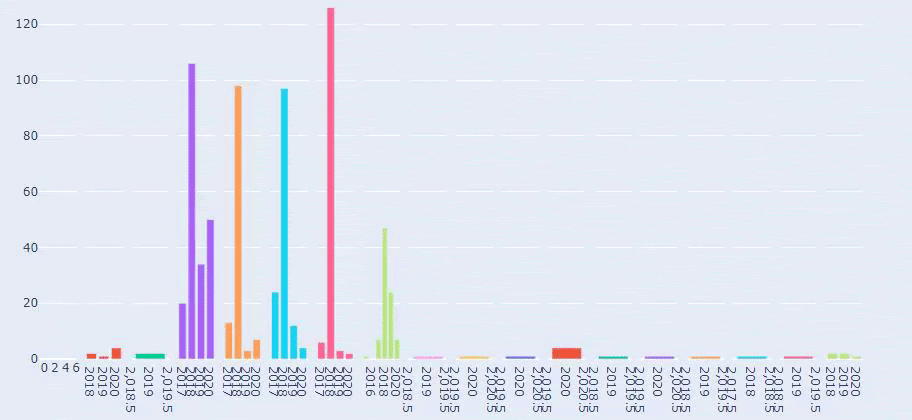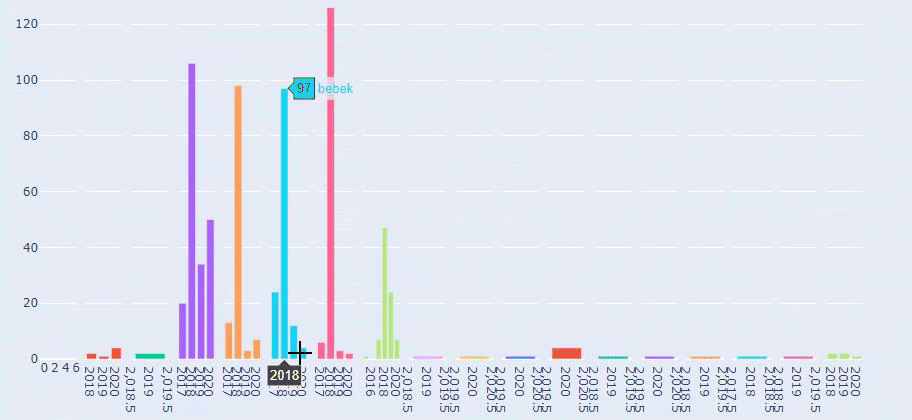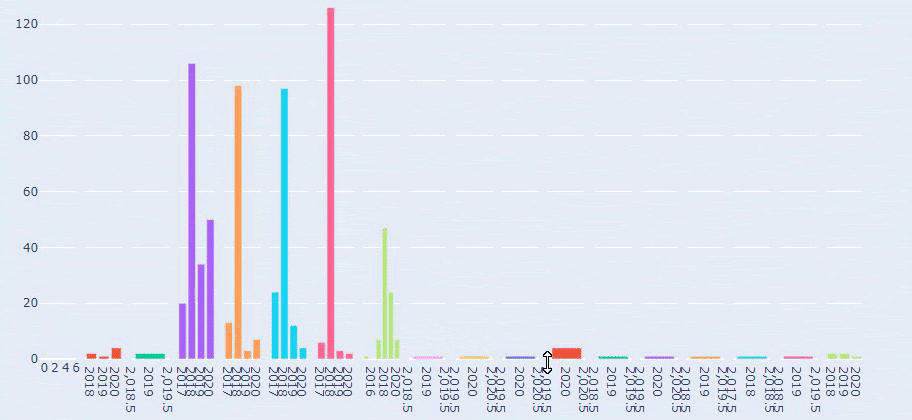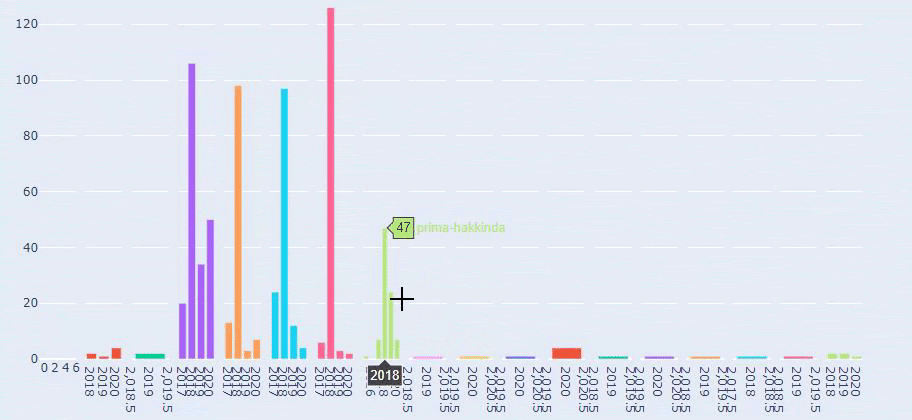
Bu, Prima.com.tr için her Kategorinin Yıllara Göre İçerik Yayınlama Trendinin bir karşılaştırmasıdır.
Artık iki farklı web sitesinin içerik kategorilerini ve yayıncılık eğilimlerini karşılaştırabiliriz.
Prima'nın bebek büyümesi, hamilelik ve annelik ile ilgili makale yayınlama sıklığına baktığımızda İlkadımlarım ile benzerlik görüyoruz:
- Makalelerin çoğu belirli bir zamanda yayınlandı.
- Uzun zamandır güncellenmemişlerdi.
- Ürün ve sayfa sayısı bilgilendirici içerik sayfalarına göre çok azdı.
- Son zamanlarda sitelerine yeni ürünler eklediler.
Bu dört özelliği sektörün varsayılan zihniyeti olarak görebilir ve bu zayıflıkları kampanyamız lehine kullanabiliriz. Ne de olsa kalite tazelik ister (Google Üyesi Amit Singhal tarafından belirtildiği gibi).
Bu noktada sektörün Googlebot'un davranışına aşina olmadığını da görüyoruz. Bir günde 250 içerik yükleyip bir yıl boyunca hiçbir değişiklik yapmamak yerine, periyodik olarak yeni içerik eklemek ve eski içeriği düzenli olarak güncellemek daha iyidir. Böylece içeriğin kalitesini koruyabilir, Googlebot sitenizi daha kolay anlayabilir ve tarama talep frekans değerleriniz rakiplerinizden daha yüksek olacaktır.
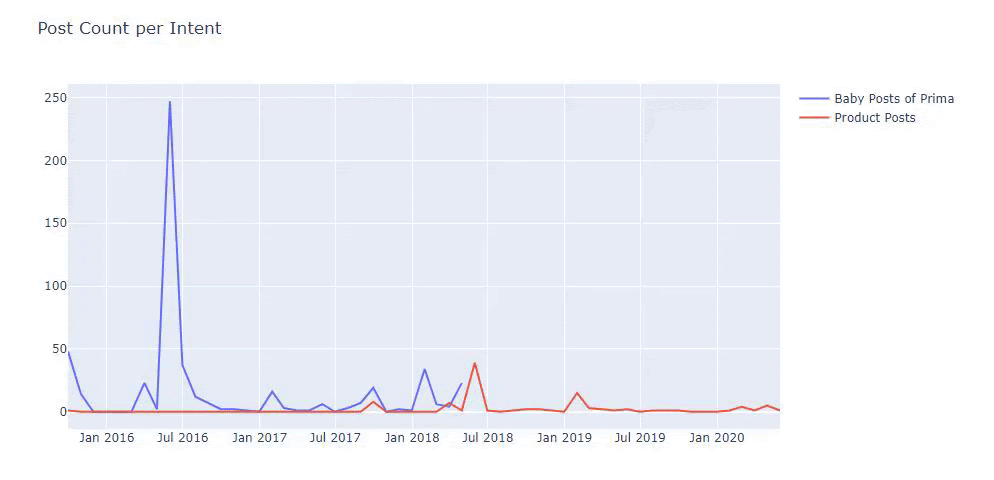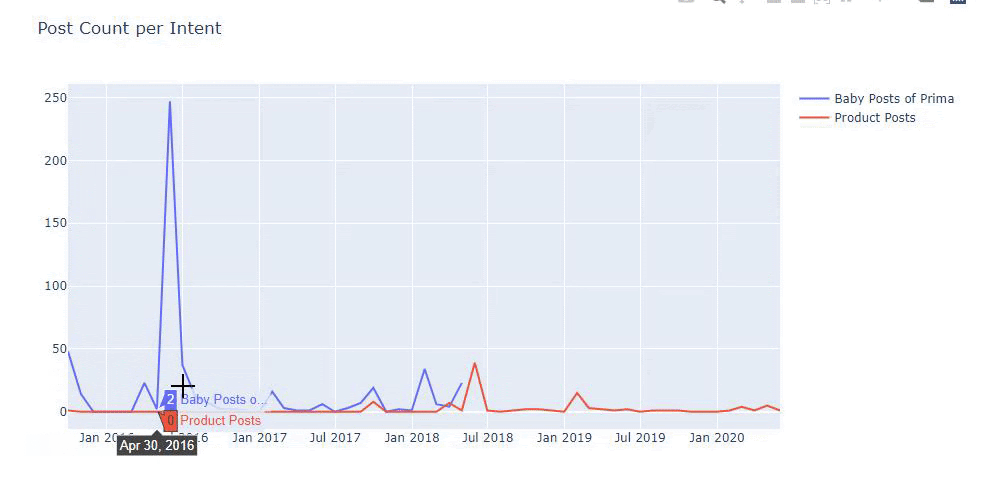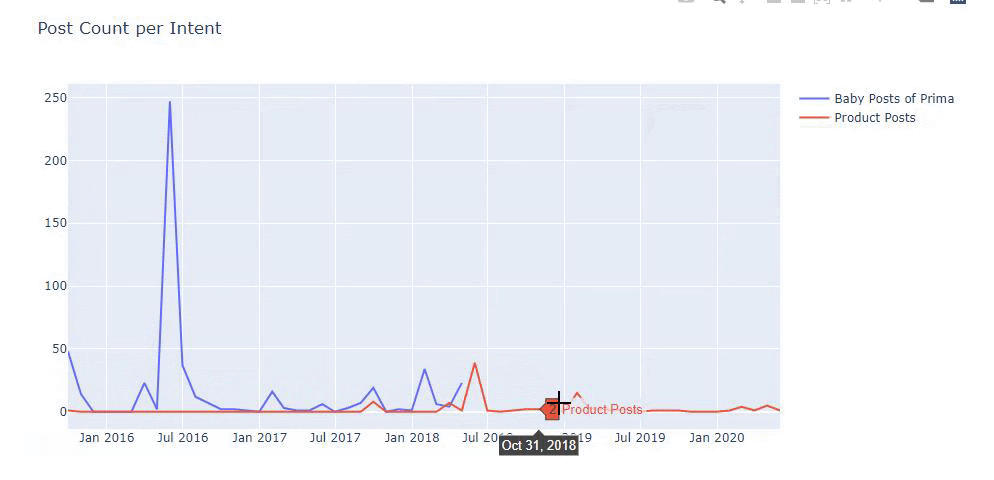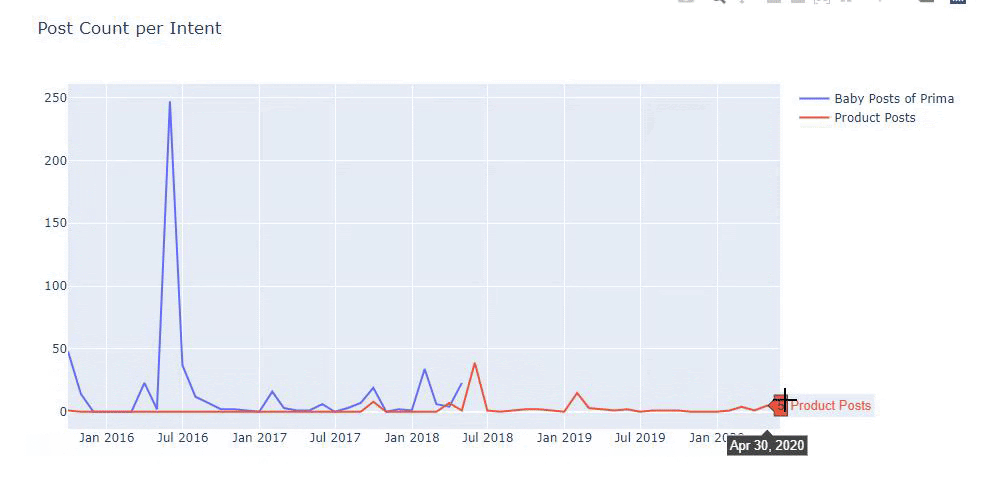
Ürün ve bilgilendirici içerik sayfaları arasında ayrım yapmak için önceki yöntemleri kullandım ve URL'lerde en çok kullanılan kelimelerin profilini çıkardım. Buradaki Bebek Gönderileri, bunların bilgilendirici içerik olduğu anlamına gelir.
Gördüğünüz gibi bir günde 247 içerik eklemişler. Ayrıca, bir yıldan fazla bir süredir bilgilendirici içerik yayınlamadılar veya yenilemediler ve ara sıra bazı yeni ürün sayfaları eklediler.
Şimdi yayıncılık eğilimlerini tek bir rakamda, ancak iki farklı grafikle karşılaştıralım. Bu figürü oluşturmak için aşağıdaki kodları kullandım:
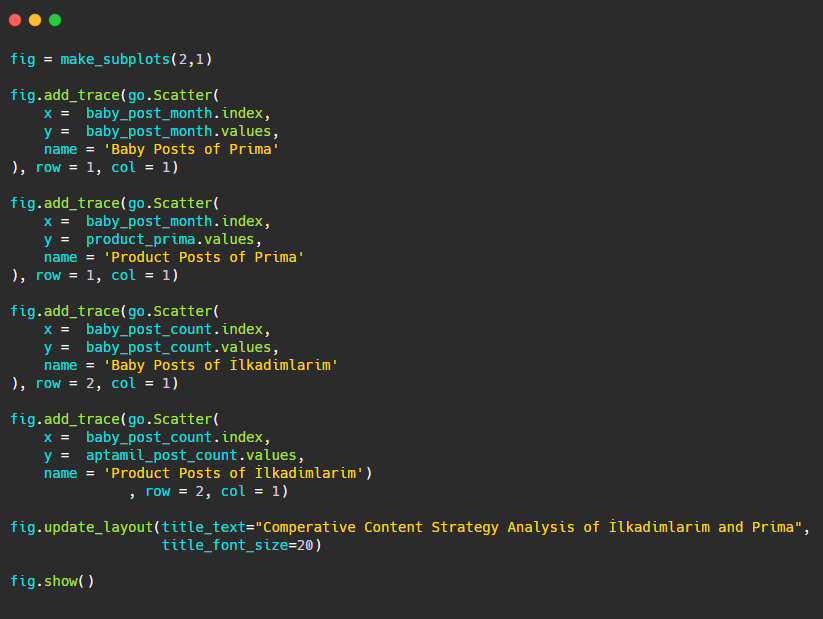
Bu grafik öncekilerden farklı olduğu için size kodu göstermek istedim. Burada, aynı şekilde iki ayrı parsel yerleştirilmiştir. Bunun için make_subplots yöntemi, plotly.subplots import make_subplots'tan gelen komutla çağrıldı.
make_subplots (2,1) ile iki satır ve tek sütun şeklinde oluşturulmuştur.
Bu nedenle izlerin sonuna col ve row yazılır ve konumları belirtilir. CSS'de grid sistemine aşina olan herkesin kolaylıkla tanıyabileceği bir sistemdir.
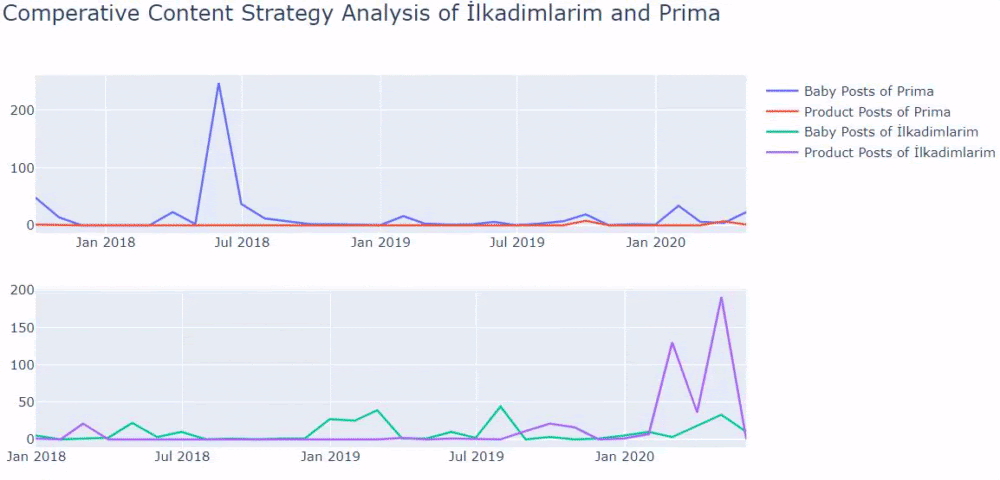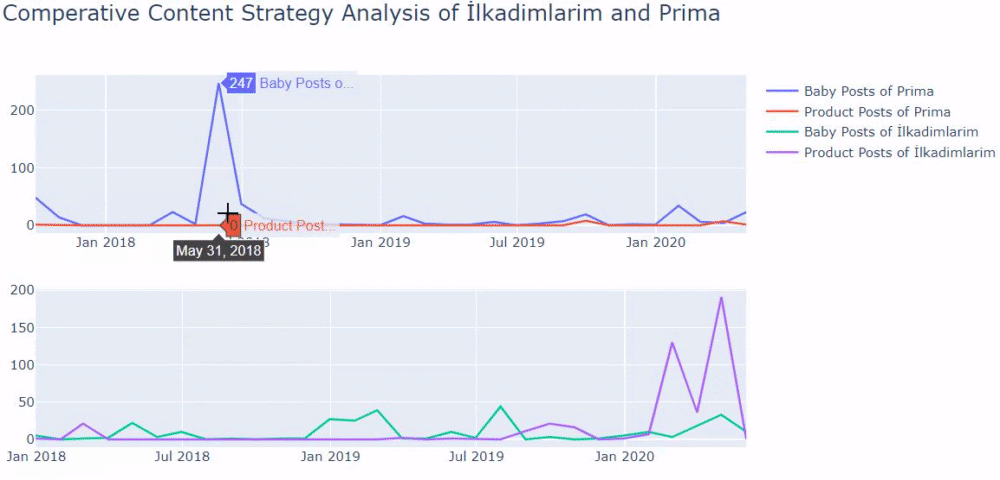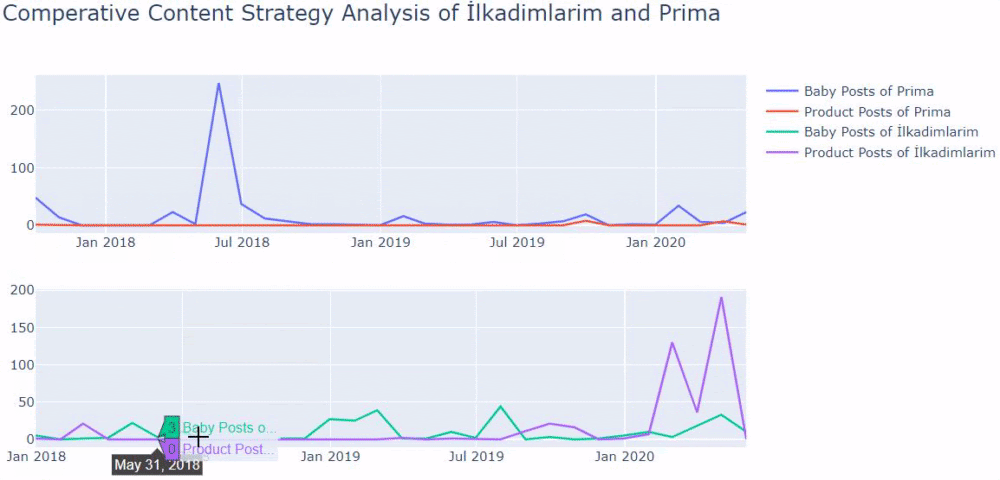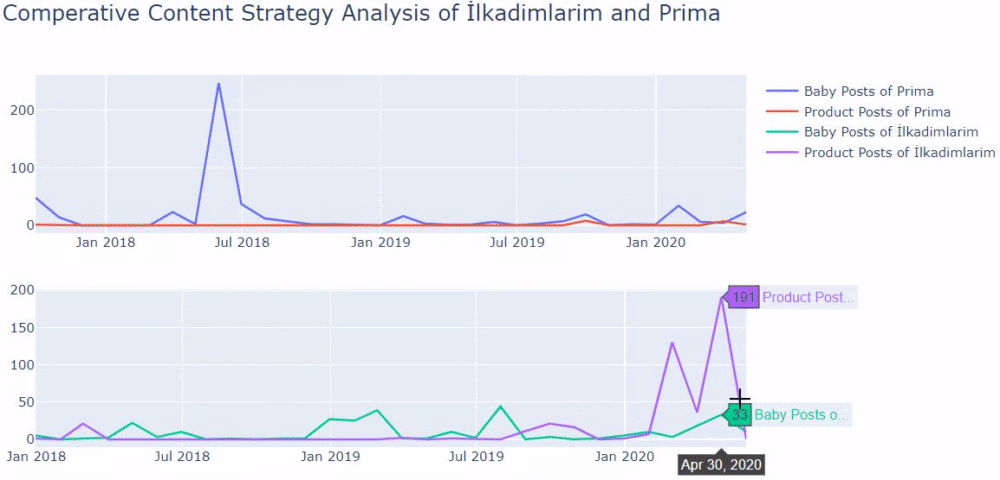
Aynı sektörde bir müşteriniz varsa, bu verileri bir içerik stratejisi oluşturmak, rakiplerinizin zayıf yönlerini ve SERP üzerinden sorgu/açılış sayfası ağını görmek için kullanabilirsiniz. Ayrıca, aynı bilgi alanında veya aynı kullanıcı amacı için ne kadar içerik yayınlamanız gerektiğini de anlayabilirsiniz.
İçerik stratejisi analizinin bir parçası olarak site haritalarından öğrenebileceklerimizi tamamlamadan önce, başka bir sektörden çok daha yüksek URL sayısına sahip son bir web sitesini inceleyebiliriz.
Python ve Site Haritaları ile Para Birimleri Üzerinden Haber Web Varlıklarının İçerik Stratejisi Analizi
Bu bölümde Seaborn'un ısı haritası grafiğini ve ayrıca bazı süslü çerçeveleme ve veri çıkarma yöntemlerini kullanacağız.

Elias Dabbas'ın Veri Bilimi ve SEO açısından ilginç ve gerçekten kullanışlı bir Kaggle Arşivi var. Bu ay, Advertools ile site haritaları üzerinden gerekli kodları yazmam ve içerik stratejisi analizi yapmam için Türkçe Haber Siteleri için yeni bir Kaggle Veri Kümesi Bölümü açtı.
Bu teknikleri Kaggle'da kullanmaya başlamadan önce, bu makalede aynı teknikleri daha büyük web varlıklarında kullanırsak ne olacağına dair bazı örnekler göstermek istiyorum.
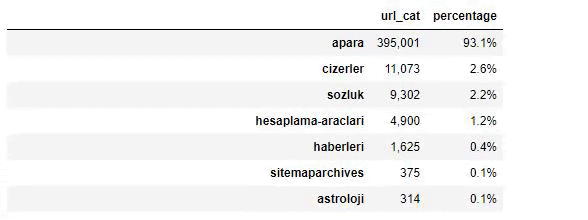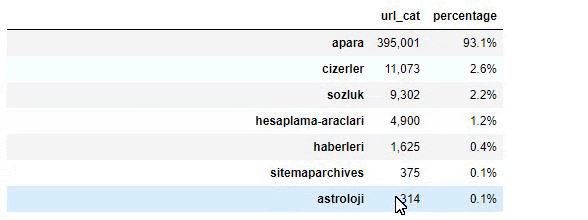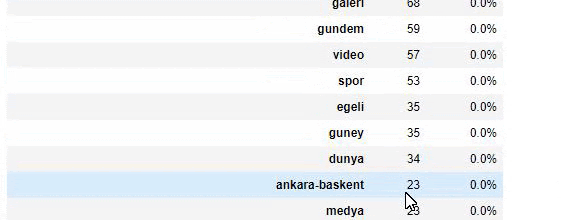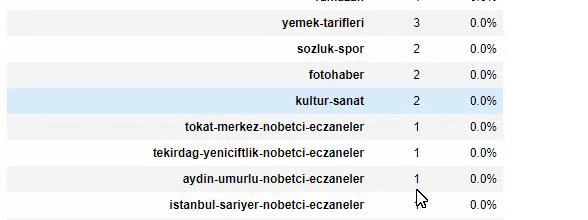
Sabah Gazetesi'nin içeriğini incelediğimizde içeriğinin önemli bir bölümünün (%81) “apara” olarak adlandırılan bir kategoride olduğunu görüyoruz. Ayrıca Astroloji, Hesaplama, Sözlük, Hava Durumu ve Dünya haberleri için bazı büyük kategorileri var. (Para Türkçe para demektir)
Sabah Gazetesi için sadece Advertools ile topladığımız site haritaları ile de içerik analizi yapabiliyoruz ancak söz konusu gazete çok büyük olduğu için site haritalarının çokluğu ve aynı URL'yi içeren farklı site haritalarının içeriği nedeniyle tercih etmedim. Kategori.
Aşağıda, Advertools ile site haritalarının fazlalığını da görebilirsiniz.
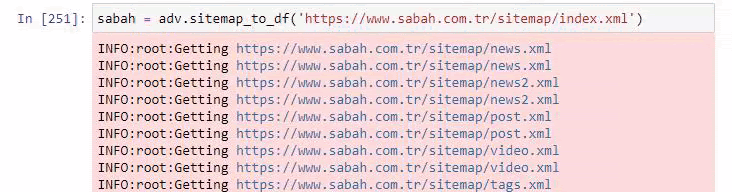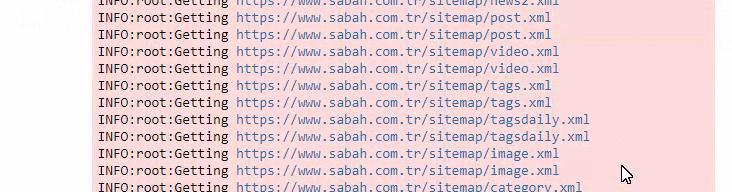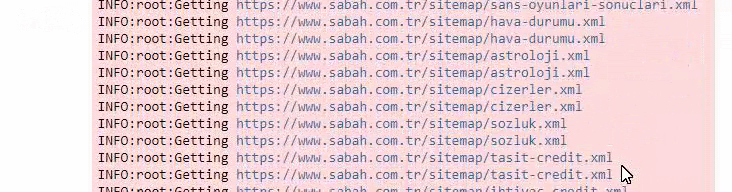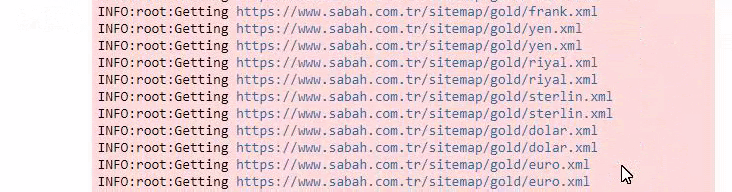
Altın, Kredi, Para Birimleri, Etiketler, Namaz Vakitleri ve Eczane Çalışma Saatleri gibi aynı URL Kategorileri için farklı site haritaları olduğunu görebiliriz…
Kısacası bu detayları URL'lerin alt kategorilerine odaklanarak elde edebiliriz. Değişkenler aracılığıyla farklı site haritalarını birleştirmek yerine. Bu yüzden tüm site haritalarını makalenin başındaki gibi Advertools'un sitemap_to_df() yöntemiyle birleştirdim.
Daha iyi veri çerçeveleri oluşturmak için Elias Dabbas tarafından oluşturulan başka bir işlev kümesini de kullanabiliriz. dataset_utitilites fonksiyonlarını kontrol ederseniz, bazı örnekler görebilirsiniz. Aşağıdaki kod, stilize ederek kümülatif toplamla birlikte belirtilen bir URL normal ifadesinin toplamını ve yüzdesini verir.
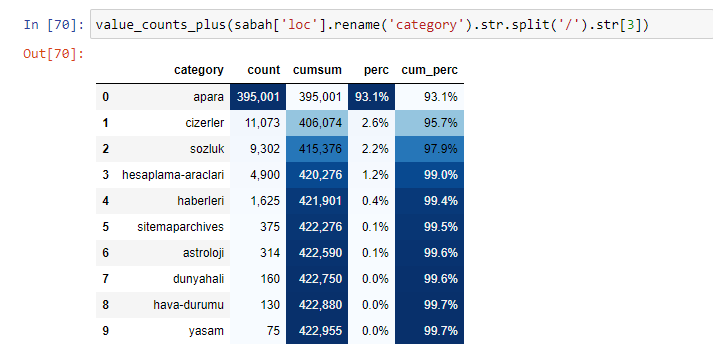
Aynısını Sabah Gazetesi'nin alt URL dökümü için de yaparsak aşağıdaki sonucu alırız.
Aşağıdaki satırı değiştirerek söz konusu fonksiyonun çıkaracağı satır sayısını artırabilirsiniz. Ayrıca fonksiyonun içeriğini incelerseniz daha önce kullandıklarımıza benzer olduğunu göreceksiniz.
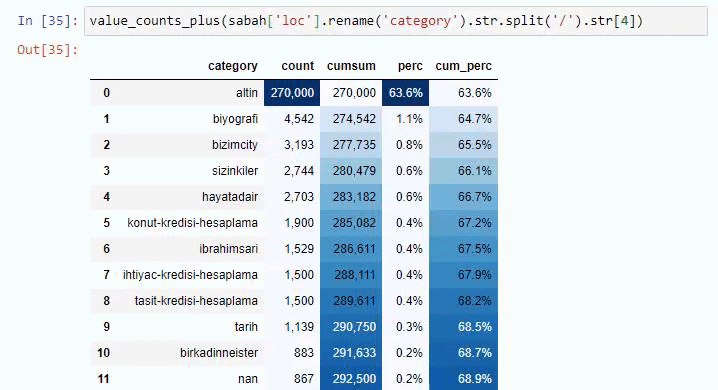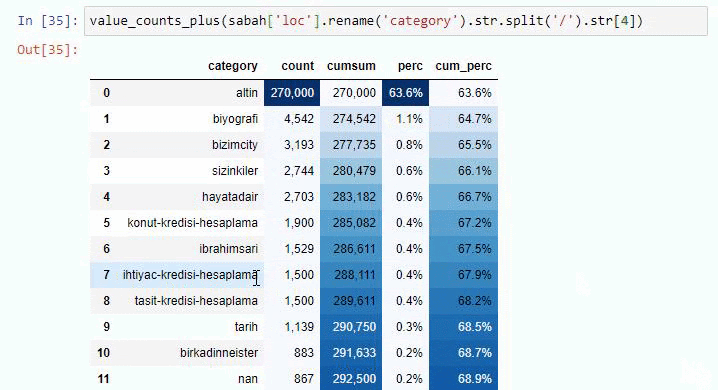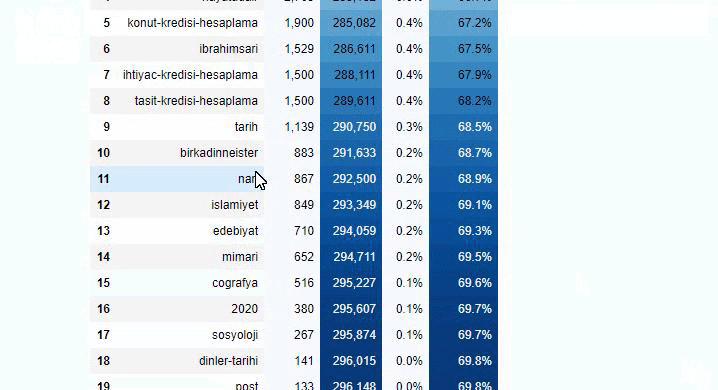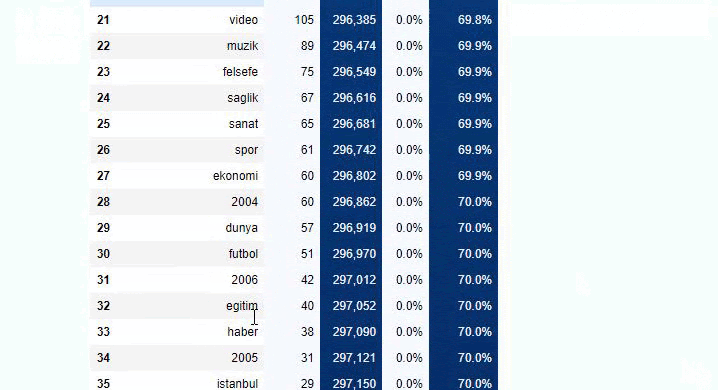
Alt kırılmalarda ise “Din Tarihi”, “Biyografi”, “Şehir Adları”, “Futbol”, “Bizimşehir (Karikatür)”, “İpotek Kredisi” gibi farklı kırılımlar görüyoruz. En büyük dağılım “Altın” kategorisinde.
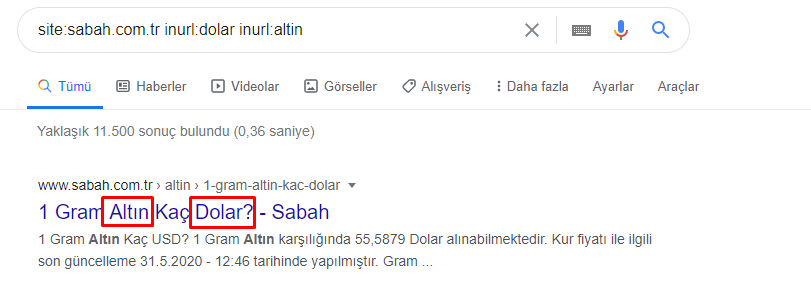
Peki bir gazetenin Altın Fiyatları için nasıl 295.000 URL'si olabilir?
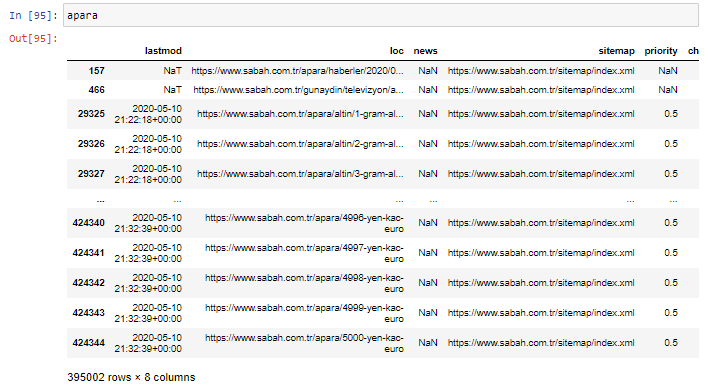
Öncelikle Sabah Gazetesi'nin ilk URL dökümünde “apara” geçen tüm URL'leri bir değişkene atıyorum.
apara = sabah[sabah['loc'].str.contains('apara')]
İşte sonuç:
Sütunları .filter() yöntemiyle de filtreleyebiliriz:
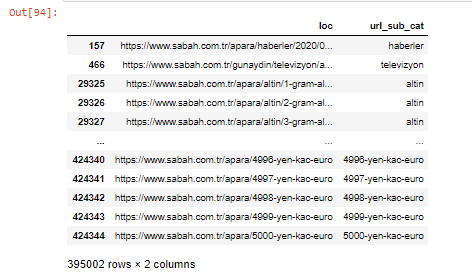
Sabah Gazetesi'nin 5000 Euro, 4999 Euro, 4998 Euro ve daha fazlası gibi her para birimi hesaplaması için farklı web sayfaları açtığı için neden bu kadar çok Apara URL'si olduğunu DataFrame'in alt kısmında görebiliriz…
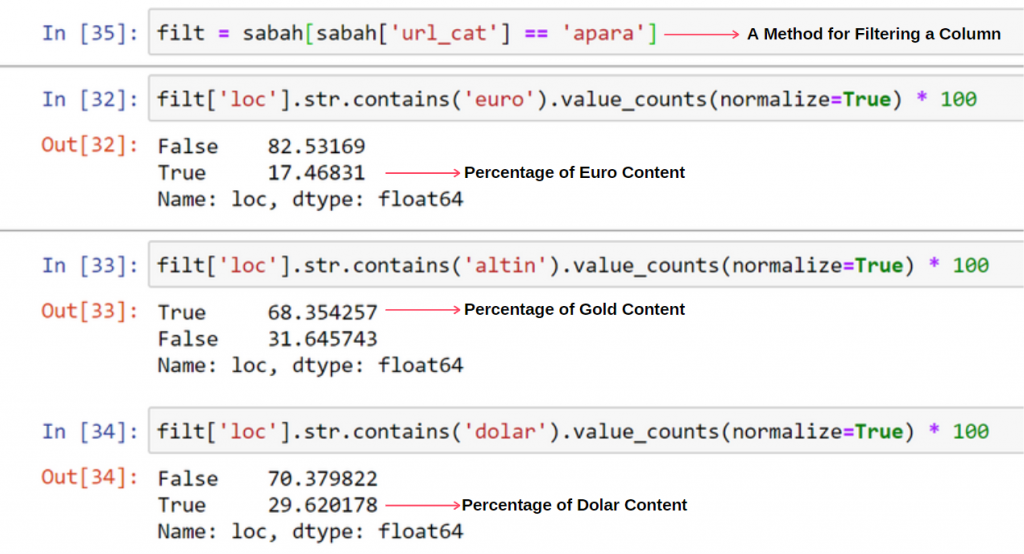
Ancak, herhangi bir sonuca varmadan önce, bu URL'lerin 250.000'den fazlası 'altın (altın)' kategorisine ait olduğundan emin olmamız gerekir.
apara.filter(['loc', 'url_sub_cat' ]).tail(60) bize bu Veri Çerçevesinin son 60 satırını gösterecektir:

Aynı şeyi Apara grubu içindeki altın URL dökümü için de yapabiliriz.
altın = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
Bu noktada Sabah Gazetesi'nin her bir para birimini Dolar, Euro, Altın ve TL'ye (Türk Lirası) çevirmek için 5000 farklı sayfa açtığını görüyoruz. 1 ile 5000 arasındaki her para birimi için ayrı bir hesaplama sayfası bulunmaktadır. Altın grubunun ilk 85 ve son 85 satırının örneğini aşağıda görebilirsiniz. Her gram altın fiyatı için ayrı bir sayfa açılmıştır.


Bu sayfaların gereksiz, mükerrer içerikli ve aşırı büyük olduğundan şüphemiz yok, ancak Sabah Gazetesi o kadar marka güçlü bir web sitesi ki, Google hemen hemen her sorguda, üst sıralarda göstermeye devam ediyor.
Bu noktada da otoritesi yüksek eski bir haber sitesi için Tarama Maliyeti Toleransının yüksek olduğunu görebiliriz.
Ancak bu, altın kategorisinin neden diğerlerinden daha fazla URL'ye sahip olduğunu açıklamaz.
Örtüşen değerlerin toplamının %100'den fazla olmasında garip bir şey görmüyorum.
Bir şey kaçırmıyorsam?
Fark edeceğiniz gibi tüm True Value'ları topladığımızda %115,16 sonucunu alıyoruz. Bunun nedeni aşağıdadır.
Ana grubun bile birbiriyle böyle bir kesişimi var. Bu kesişimleri de inceleyebiliriz ama başka bir yazının konusu olabilir.
Apara URL grubundaki içeriklerin %68'inin GOLD ile ilgili olduğunu görüyoruz.
Bu durumu daha iyi anlamak için yapmamız gereken ilk şey altın kırılmasındaki URL'leri taramak.
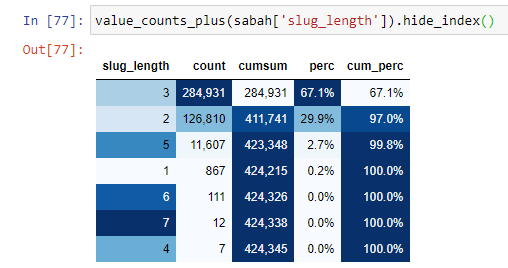
URL'leri kök bölümünden beri sahip oldukları '/' miktarına göre sınıflandırdığımızda, maksimum 3 kesmeli URL sayısının yüksek olduğunu görüyoruz. Bu URL'leri analiz ettiğimizde 3 slug_length URL'sinin 270.000'inin Altın kategorisinde olduğunu görüyoruz.
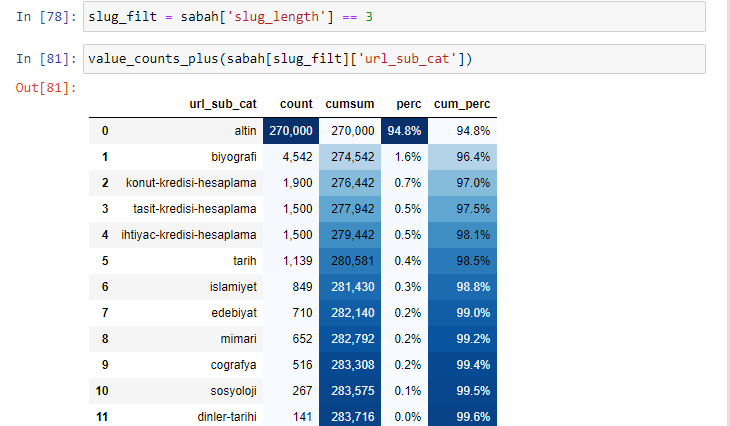
sabah_filt = sabah ['slug_length'] == 3 Bu, belirli bir veri çerçevesinin belirli bir sütunundaki int veri türünün veri grubundan yalnızca 3'e eşit olanları alacağınız anlamına gelir. Ardından, bu bilgilere dayanarak, koşula uygun olan URL'leri sayım, toplamlar ve toplama oranları ile kümülatif toplamlarla çerçeveliyoruz.
Altın URL'lerde en sık kullanılan kelimeleri çıkardığımızda, "tam", "cumhuriyet", "çeyrek", "gram", "yarım", "ata" yı temsil eden kelimelere rastlıyoruz. Ata ve Cumhuriyet altın çeşitleri Türkiye'ye özgüdür. Bunlardan biri Türk Egemenliğini temsil ediyor, diğeri ise Cumhuriyetin Kurucusu Kemal Atatürk. Bu nedenle sorgu arama hacimleri yüksektir.
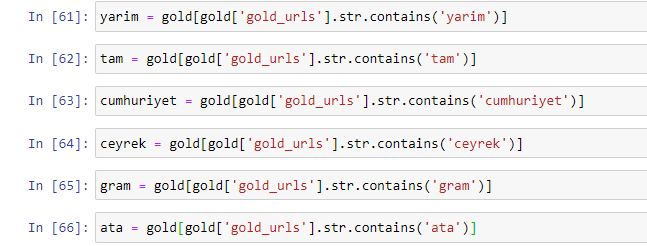
Öncelikle URL'lerde bulunan ortak kelimeleri kaldırdık ve bunları ayrı değişkenlere atadık. Daha sonra, türlerine özel sütunlar oluşturmak için bu değişkenleri Gold DataFrame'de kullanacağız.
Değişkenler aracılığıyla yeni sütunlar oluşturduktan sonra bunları boolean değerlerle birlikte filtrelememiz gerekir.
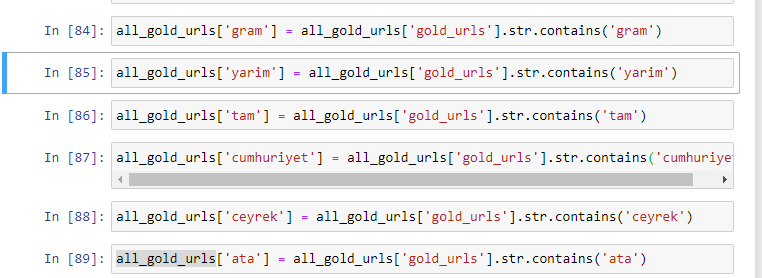
Gördüğünüz gibi tüm altın URL'leri 270.000 satır ve 6 sütunla kategorize edebildik. Altına özel sayfa sayısının fazla olmasının temel nedeni, Dolar veya Euro'nun ayrı bir türünün olmaması, altının ise ayrı türlerinin olmasıdır. Aynı zamanda altın ve farklı para birimleri arasında geçiş sayfalarının çeşitliliği, Türk insanına olan geleneksel güven nedeniyle diğer para birimlerine göre daha fazladır.
Bana göre her türlü altın sayfa eşit olarak dağıtılmalı, değil mi?
Bunu Seaborn'un Isı Haritası özelliği ile kolayca test edebiliriz.
seaborn'u sns olarak içe aktar
matplotlib.pyplot'u plt olarak içe aktar
plt.şekil(şekil=(10,8))
sns.heatmap(a,yticklabels=Yanlış,cbar=Yanlış,cmap=”viridis”)
plt.göster()
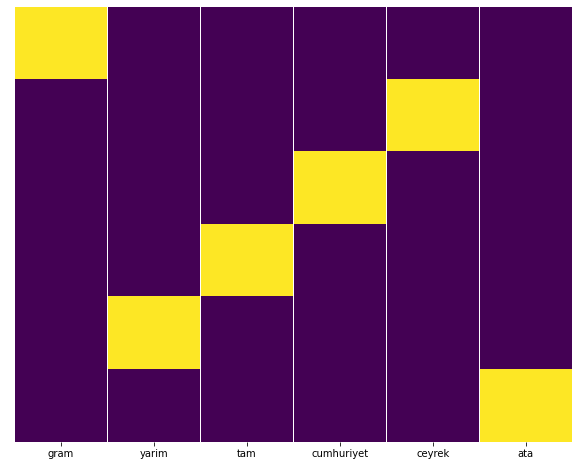
Burada Isı Haritasında, her sütundaki Doğrular basitçe işaretlenmiştir. Görüldüğü gibi, her birinin boyutu birbiriyle simetriktir ve harita üzerinde düzgün bir şekilde düzenlenmiştir.
Böylece Sabah.com.tr Gazetesi'nin Döviz ve Döviz Hesaplama ile ilgili içerik politikasına geniş bir bakış açısı getirdik.
Gelecekte, Elias Dabbas tarafından başlatılan Site Haritaları Kaggle'ı temel alan Türk Haber Siteleri ve içerik stratejilerini yazacağım, ancak bu yazıda site haritaları ile hem büyük hem de küçük web sitelerinde nelerin keşfedilebileceğinden yeterince bahsettik. .
Sonuç ve Çıkarımlar
Düzgün ve anlamsal bir URL yapısı sayesinde bir web sitesini anlamanın ne kadar kolay olduğunu gördüğümüzü düşünüyorum. Uygun bir URL yapısının Google için ne kadar değerli olabileceğini de unutmamalıyız.
Gelecekte, veri bilimine, veri görselleştirmeye, ön uç programlamaya ve daha fazlasına giderek daha fazla aşina olan çok sayıda SEO uzmanı göreceğiz… Bu süreci kaçınılmaz değişimin başlangıcı olarak görüyorum: SEO'lar ve geliştiriciler arasındaki boşluk tamamen kapanacak Birkaç yıl içinde.
Python ile bu tür bir analizi daha da ileri götürebilirsiniz: Bir haber sitesinin siyasi görüşlerini anlamaktan kimin ne hakkında, ne sıklıkla ve hangi duygularla yazdığına kadar veri elde etmek mümkündür. Bu süreçler SEO'dan daha çok saf veri bilimi ile ilgili olduğundan (ve bu makale zaten oldukça uzun olduğundan) buna burada girmemeyi tercih ediyorum.
Ancak ilgileniyorsanız, bir site haritasındaki URL'lerin durum kodlarını kontrol etmek gibi Site Haritaları ve Python aracılığıyla gerçekleştirilebilecek birçok başka denetim türü vardır.
Python ve Advertools ile yapabileceğiniz diğer SEO görevlerini denemek ve paylaşmak için sabırsızlanıyorum.