
Yapay Zekayı Anlamak: Bilgisayarlara doğal dili nasıl öğrettik?
Yayınlanan: 2023-11-28"Yapay zeka" ifadesi 1950'lerden bu yana bilgisayarlarla ilgili olarak kullanılıyordu, ancak geçen yıla kadar çoğu insan muhtemelen yapay zekanın teknolojik gerçeklikten çok bilim kurgu olduğunu düşünüyordu.
OpenAI'nin ChatGPT'sinin Kasım 2022'de ortaya çıkışı, insanların makine öğreniminin neler yapabileceğine dair algılarını aniden değiştirdi. Peki ChatGPT'de dünyanın ayağa kalkıp yapay zekanın büyük ölçüde burada olduğunu fark etmesini sağlayan şey tam olarak neydi?
Tek kelimeyle dil; ChatGPT'nin bu kadar dikkate değer bir ilerleme kaydetmesinin nedeni, daha önce hiçbir chatbot'un olmadığı kadar doğal dilde akıcı görünmesiydi.
Bu, bilgisayarların doğal dili yorumlama ve ikna edici yanıtlar verme yeteneği olan “doğal dil işlemenin” (NLP) dikkate değer yeni bir aşamasına işaret ediyor. ChatGPT, içeriği işleyebilen ve üretebilen büyük veri kümeleri üzerinde eğitilmiş derin öğrenmeyi kullanan bir tür sinir ağı olan "büyük dil modeli" (LLM) üzerine kurulmuştur.
“Bir bilgisayar programı bu kadar dilsel akıcılığa nasıl ulaştı?”
Ama buraya nasıl geldik? Bir bilgisayar programı bu kadar dilsel akıcılığa nasıl ulaştı? Kulağa nasıl bu kadar hatasız bir şekilde insani geliyor?
ChatGPT bir boşlukta yaratılmadı; son yıllardaki sayısız farklı yenilik ve keşif üzerine inşa edildi. ChatGPT'ye yol açan bir dizi çığır açıcı buluş, bilgisayar biliminde kilometre taşlarıydı, ancak bunların, insanların dili edinme aşamalarını taklit ettiğini görmek mümkün.
Dili nasıl öğreniriz?
Yapay zekanın bu aşamaya nasıl ulaştığını anlamak için dil öğrenmenin doğasını göz önünde bulundurmaya değer; tek kelimelerle başlıyoruz ve ardından karmaşık kavramları, fikirleri ve talimatları iletebilene kadar bunları daha uzun diziler halinde birleştirmeye başlıyoruz.
Örneğin çocuklarda dil ediniminin bazı yaygın aşamaları şunlardır:
- Holofrastik aşama: 9-18 ay arasında çocuklar, temel ihtiyaçlarını veya isteklerini tanımlayan tek sözcükleri kullanmayı öğrenirler. Tek bir kelimeyle iletişim kurmak, kavramsal bütünlükten ziyade açıklığa vurgu yapıldığı anlamına gelir. Eğer bir çocuk açsa, “Biraz yiyecek istiyorum” ya da “Açım” demeyecek, bunun yerine sadece “yiyecek” ya da “süt” diyecektir.
- İki kelimelik dönem: 18-24 aylıkken çocuklar iletişim becerilerini geliştirmek için basit iki kelimeli gruplamayı kullanmaya başlarlar. Artık “daha fazla yemek”, “kitap oku” gibi ifadelerle duygu ve ihtiyaçlarını dile getirebiliyorlar.
- Telgraf aşaması: 24-30 ay arasında çocuklar daha karmaşık ifadeler ve cümleler oluşturmak için birden fazla kelimeyi bir araya getirmeye başlar. Kullanılan kelime sayısı hala azdır ancak doğru kelime sıralaması ve daha fazla karmaşıklık ortaya çıkmaya başlar. Çocuklar “anneme göstermek istiyorum” gibi temel cümle kurmayı öğrenmeye başlarlar.
- Çok kelimeli dönem: 30 aydan sonra çocuklar çok kelimeli döneme geçmeye başlar. Bu aşamada çocuklar dil bilgisi açısından daha doğru, karmaşık ve çok cümleli cümleler kullanmaya başlarlar. Bu, dil ediniminin son aşamasıdır ve çocuklar sonunda “Yağmur yağarsa evde kalıp oyun oynamak isterim” gibi karmaşık cümlelerle iletişim kurarlar.
Dil ediniminin ilk önemli aşamalarından biri, tek kelimeleri çok basit bir şekilde kullanmaya başlayabilmektir. Dolayısıyla yapay zeka araştırmacılarının üstesinden gelmesi gereken ilk engel, basit kelime ilişkilendirmelerini öğrenecek modelleri nasıl eğitecekleriydi.
Model 1 – Word2Vec ile Tek Kelimeleri Öğrenmek (kağıt 1 ve kağıt 2)
Kelime ilişkilendirmelerini bu şekilde öğrenmeye çalışan ilk sinir ağı modellerinden biri, Tomaš Mikolov ve Google'dan bir grup araştırmacı tarafından geliştirilen Word2Vec'ti. 2013 yılında iki makale halinde yayımlandı (bu da bu alanda işlerin ne kadar hızlı geliştiğini gösteriyor).
Bu modeller, yaygın olarak birlikte kullanılan sözcükleri ilişkilendirmeyi öğrenerek eğitildi. Bu yaklaşım, anlamın kelime çağrışımından türetilebileceğini belirten John R. Firth gibi ilk dil öncülerinin sezgisine dayanıyordu: "Bir kelimeyi, içinde bulunduğu arkadaşlıktan bileceksin."
Buradaki fikir, benzer anlamsal anlamı paylaşan kelimelerin daha sık bir arada ortaya çıkma eğiliminde olmasıdır. "Kediler" ve "köpekler" kelimeleri genellikle "elma" veya "bilgisayarlar" gibi kelimelerle olduğundan daha sık bir arada kullanılır. Başka bir deyişle, "kedi" kelimesi "köpek" kelimesine, "kedi" kelimesinin "elma" veya "bilgisayar" kelimesine benzemesinden daha fazla benzemelidir.
Word2Vec ile ilgili ilginç olan şey, bu kelime çağrışımlarını öğrenmek için nasıl eğitildiğidir:
- Hedef kelimeyi tahmin edin: Modele, hedef kelime eksikken girdi olarak sabit sayıda kelime verilir ve modelin eksik hedef kelimeyi tahmin etmesi gerekir. Bu, Sürekli Kelime Çantası (CBOW) olarak bilinir.
- Çevreleyen kelimeleri tahmin edin: Modele tek bir kelime verilir ve ardından çevredeki kelimeleri tahmin etmesi istenir. Bu, Skip-Gram olarak bilinir ve çevredeki kelimeleri tahmin ettiğimiz için CBOW'un tersi bir yaklaşımdır.
Bu yaklaşımların bir avantajı, modeli eğitmek için herhangi bir etiketli veriye ihtiyacınız olmamasıdır; verileri etiketlemek, örneğin duygu analizini öğretmek için metni "olumlu" veya "negatif" olarak tanımlamak sonuçta yavaş ve zahmetli bir iştir.
Word2Vec ile ilgili en şaşırtıcı şeylerden biri, nispeten basit bir eğitim yaklaşımıyla yakaladığı karmaşık anlamsal ilişkilerdi. Word2Vec, giriş kelimesini temsil eden vektörlerin çıktısını alır. Yazarlar, bu vektörler üzerinde matematiksel işlemler gerçekleştirerek, kelime vektörlerinin sadece sözdizimsel olarak benzer öğeleri değil aynı zamanda karmaşık anlamsal ilişkileri de yakaladıklarını gösterebildiler.
Bu ilişkiler kelimelerin nasıl kullanıldığıyla ilgilidir. Yazarların belirttiği örnek, “Kral” ve “Kraliçe” ile “Erkek” ve “Kadın” gibi kelimeler arasındaki ilişkiydi.
Ancak ileriye doğru bir adım olsa da Word2Vec'in sınırları vardı. Kelime başına yalnızca bir tanımı vardı; örneğin hepimiz biliyoruz ki "banka", birini tutmayı mı yoksa birinden balık tutmayı mı planladığınıza bağlı olarak farklı anlamlara gelebilir. Word2Vec bunu umursamadı, sadece “banka” kelimesinin tek bir tanımı vardı ve bunu her bağlamda kullanıyordu.
Hepsinden önemlisi, Word2Vec talimatları ve hatta cümleleri işleyemiyordu. Giriş olarak yalnızca bir kelimeyi alabilir ve o kelime için öğrendiği bir "kelime yerleştirme" veya vektör gösterimini çıkarabilir. Bu tek kelimeli temelin üzerine inşa etmek için araştırmacıların iki veya daha fazla kelimeyi sırayla bir araya getirmenin bir yolunu bulması gerekiyordu. Bunu dil ediniminin iki kelimelik aşamasına benzer bir şey olarak düşünebiliriz.
Model 2 – RNN'ler ve Metin Dizileri ile kelime dizilerini öğrenme
Çocuklar tek kelime kullanımına hakim olmaya başladıktan sonra, daha karmaşık düşünce ve duyguları ifade etmek için kelimeleri bir araya getirmeye çalışırlar. Benzer şekilde NLP'nin geliştirilmesindeki bir sonraki adım, kelime dizilerini işleme yeteneğini geliştirmekti. Metin dizilerinin işlenmesindeki sorun, bunların sabit bir uzunluğunun olmamasıdır. Bir cümlenin uzunluğu birkaç kelimeden uzun bir paragrafa kadar değişebilir. Sıralamanın tümü genel anlam ve bağlam açısından önemli olmayacaktır. Ancak hangi parçaların en alakalı olduğunu bilmek için tüm sırayı işleyebilmemiz gerekir.
Tekrarlayan Sinir Ağlarının (RNN'ler) ortaya çıktığı yer burasıdır.
1990'larda geliştirilen bir RNN, girişini, önceki adımlardan elde edilen çıktının, dizideki her adım boyunca yinelenirken ağ üzerinden taşındığı bir döngüde işleyerek çalışır.
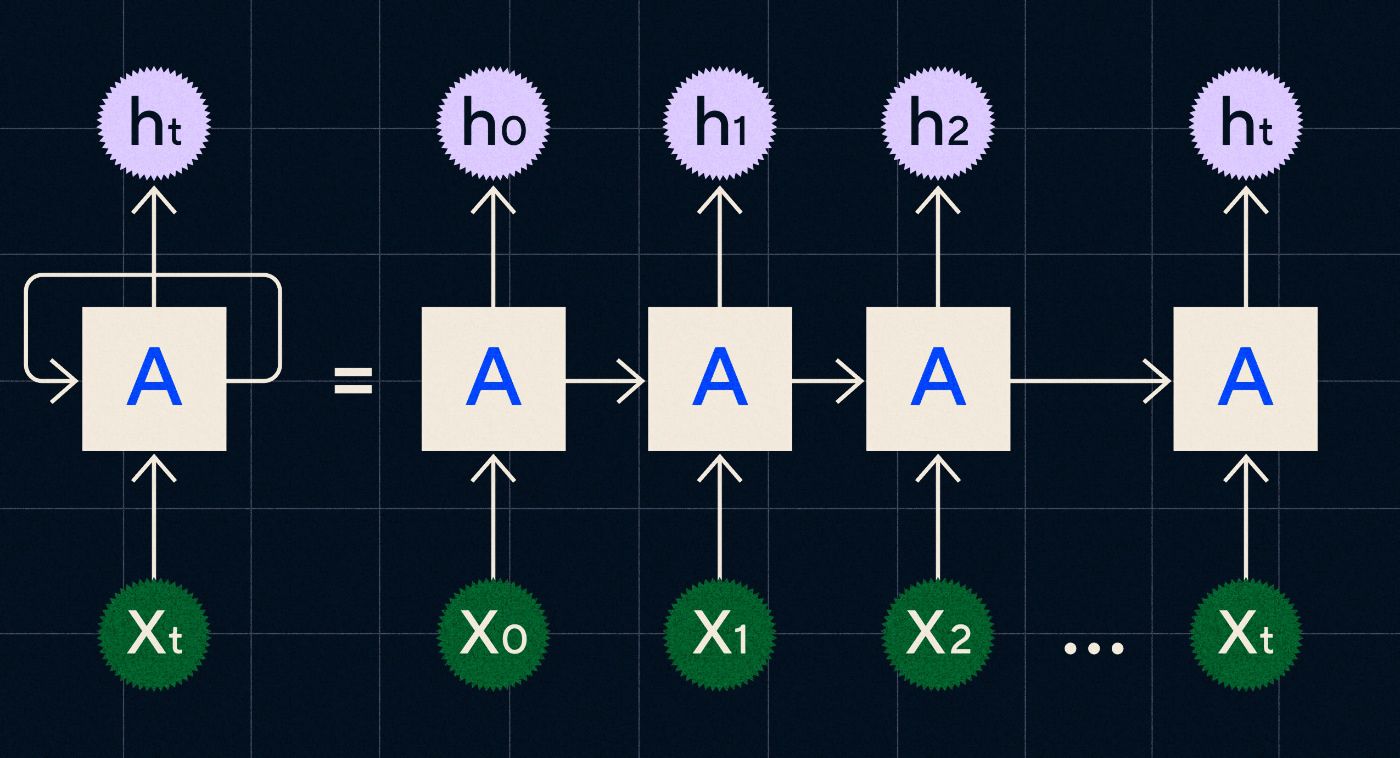
Kaynak: Christopher Olah'ın RNN'ler hakkındaki blog yazısı
Yukarıdaki şema, bir RNN'nin, önceki adımın çıktısının (h0, h1, h2…ht) bir sonraki adıma taşındığı bir dizi sinir ağı (A) olarak nasıl resmedileceğini gösterir. Her adımda ağ tarafından yeni bir giriş (X0, X1, X2… Xt) de işlenir.
RNN'ler (ve özellikle Uzun Kısa Süreli Bellek ağları veya LSTM'ler, Sepp Hochreiter ve Jurgen Schmidhuber tarafından 1997'de tanıtılan özel bir RNN türü), çeviri gibi daha karmaşık görevleri gerçekleştirebilecek sinir ağı mimarileri oluşturmamızı sağladı.
2014 yılında Google'da Ilya Sutskever (OpenAI'nin kurucu ortağı), Oriol Vinyals ve Quoc V Le tarafından Sıradan Sıraya (Seq2Seq) modellerini açıklayan bir makale yayınlandı. Bu makale, bir girdi metnini alıp bu metnin çevirisini döndürmek için bir sinir ağını nasıl eğitebileceğinizi gösterdi. Bunu, ona bir komut verdiğiniz ve bir yanıt döndürdüğü üretken sinir ağının erken bir örneği olarak düşünebilirsiniz. Ancak görev düzeltildi, dolayısıyla eğer çeviri konusunda eğitim almışsa, onu başka bir şey yapmaya "istemleyemezsiniz".
Önceki model olan Word2Vec'in yalnızca tek sözcükleri işleyebildiğini unutmayın. Yani eğer ona "dişçi dişimi çekti" gibi bir cümle aktarırsanız, sanki alakasızmış gibi her kelime için bir vektör üretecektir.
Ancak çeviri gibi görevlerde düzen ve bağlam önemlidir. Sadece tek tek kelimeleri çeviremezsiniz, kelime dizilerini ayrıştırmanız ve ardından sonucun çıktısını almanız gerekir. RNN'lerin Seq2Seq modellerinin kelimeleri bu şekilde işlemesini sağladığı yer burasıdır.
Seq2Seq modellerinin anahtarı, arka arkaya iki RNN kullanan sinir ağı tasarımıydı. Biri, metinden gelen girdiyi yerleştirmeye dönüştüren bir kodlayıcıydı, diğeri ise kodlayıcı tarafından çıkarılan yerleştirmeleri girdi olarak alan bir kod çözücüydü:
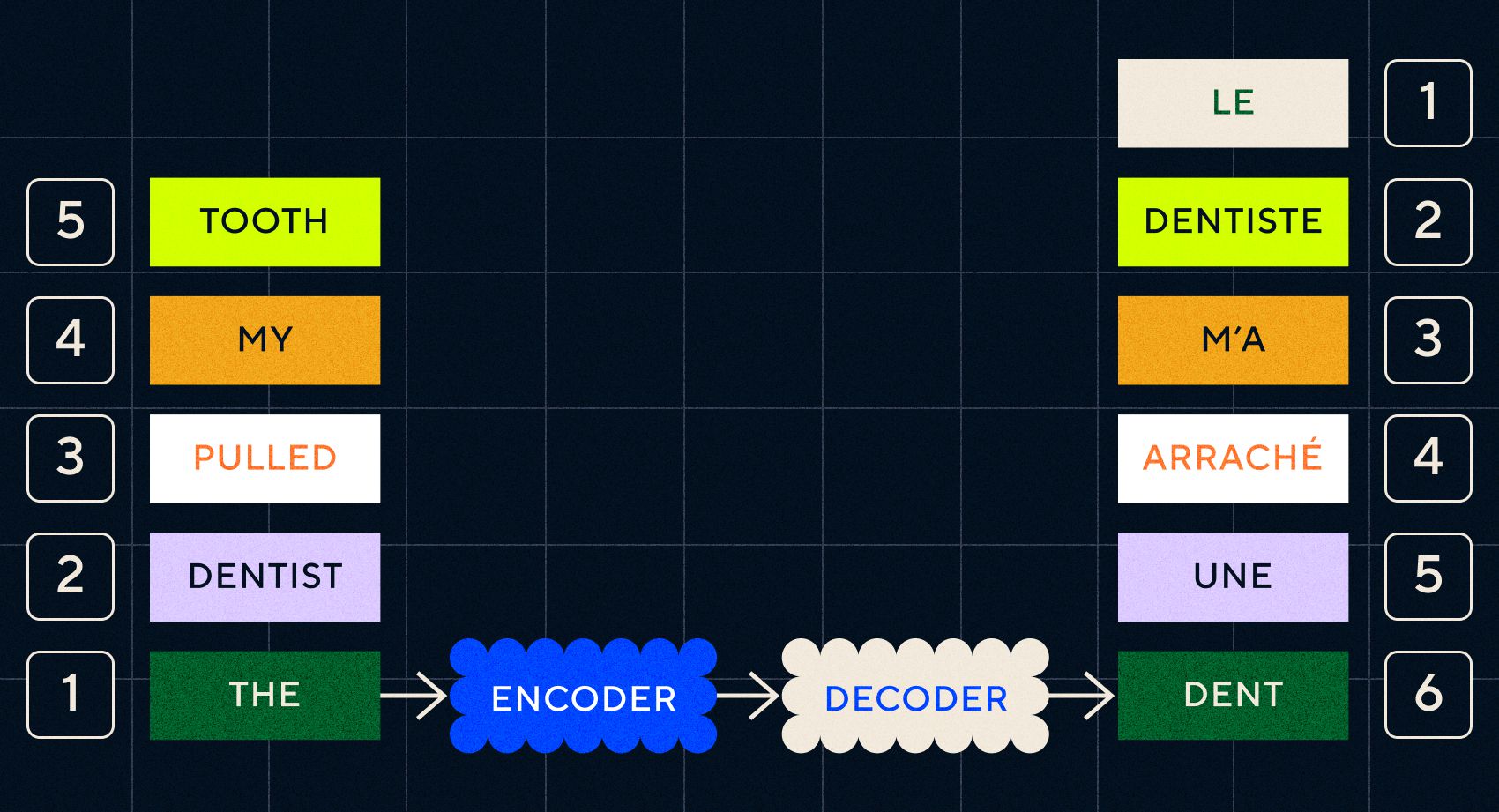
Kodlayıcı her adımda girdileri işledikten sonra çıktıyı kod çözücüye aktarmaya başlar ve bu da yerleştirmeleri çevrilmiş bir metne dönüştürür.
Bu modellerin gelişmesiyle birlikte, basit bir biçimde bugün ChatGPT'de gördüklerimize benzemeye başladıklarını görebiliriz. Ancak karşılaştırıldığında bu modellerin ne kadar sınırlı olduğunu da görebiliyoruz. Kendi dil gelişimimizde olduğu gibi, dil becerilerimizi gerçekten geliştirmek için, daha karmaşık ifadeler ve cümleler oluşturmak için tam olarak neye dikkat etmemiz gerektiğini bilmemiz gerekir.
Model 3 – Transformers ile dikkat ederek öğrenme ve ölçeklendirme
Daha önce telgraf aşamalarının çocukların iki veya daha fazla kelimeden oluşan kısa cümleler kurmaya başladığı dönem olduğunu belirtmiştik. Dil ediniminin bu aşamasının önemli bir yönü, çocukların doğru cümleleri nasıl kuracaklarını öğrenmeye başlamalarıdır.
RNN'ler ve Seq2Seq modelleri, dil modellerinin birden fazla kelime dizisini işlemesine yardımcı oldu ancak işleyebilecekleri cümle uzunlukları hâlâ sınırlıydı. Cümle uzunluğu arttıkça cümledeki çoğu şeye dikkat etmemiz gerekir.
Örneğin şu cümleyi ele alalım: “Odada o kadar gerilim vardı ki bıçakla kesilebilirdi”. Orada çok şey oluyor. Burada kelimenin tam anlamıyla bir şeyi bıçakla kesmediğimizi bilmek için cümlenin başındaki “kesmek” ile “gerginlik” arasında bağlantı kurmamız gerekiyor.
Cümle uzunluğu arttıkça doğru anlamı çıkarabilmek için hangi kelimenin hangisine atıfta bulunduğunu bilmek zorlaşır. RNN'lerin sınırlarla karşılaşmaya başladığı yer burasıdır ve dil ediniminin bir sonraki aşamasına geçmek için yeni bir modele ihtiyacımız vardı.
“Uzadıkça uzadıkça bir konuşmayı sabit bir sözcük sınırıyla özetlemeye çalıştığınızı düşünün. Her adımda giderek daha fazla bilgi kaybetmeye başlıyorsunuz”
2017 yılında Google'daki bir grup araştırmacı, modellerin bir metin parçasındaki önemli içeriğe daha iyi dikkat etmesini sağlayacak bir teknik öneren bir makale yayınladı.
Geliştirdikleri şey, dil modellerinin bir metin giriş dizisini işlerken ihtiyaç duydukları bağlamı daha kolay aramalarını sağlayacak bir yoldu. Bu yaklaşımı "transformatör mimarisi" olarak adlandırdılar ve bu, doğal dil işlemede bugüne kadarki en büyük atılımı temsil ediyordu.
Bu arama mekanizması, modelin önceki kelimelerden hangisinin işlenmekte olan geçerli kelimeye daha fazla bağlam sağladığını belirlemesini kolaylaştırır. RNN'ler, her adımda işlenmiş olan tüm kelimelerin toplu durumunu ileterek bağlam sağlamaya çalışır. Sabit bir kelime sınırıyla, uzadıkça uzadıkça bir konuşmayı özetlemeye çalışmayı düşünün. Her adımda giderek daha fazla bilgi kaybetmeye başlarsınız. Bunun yerine, dönüştürücüler kelimeleri (veya tam kelimeler değil, kelimelerin parçaları olan simgeleri) mevcut kelime açısından bağlam açısından önemlerine göre ağırlıklandırdılar. Bu, RNN'lerde görülen darboğaz olmadan giderek daha uzun kelime dizilerinin işlenmesini kolaylaştırdı. Bu yeni dikkat mekanizması aynı zamanda metnin RNN gibi sıralı olarak işlenmesi yerine paralel olarak işlenmesine de olanak sağladı.
Öyleyse “Hayvan çok yorgun olduğu için karşıdan karşıya geçmedi” gibi bir cümle düşünün. Bir RNN için her adımda önceki tüm kelimeleri temsil etmesi gerekir. "O" ve "hayvan" arasındaki kelimelerin sayısı arttıkça RNN'nin doğru bağlamı belirlemesi daha da zorlaşıyor.

Transformatör mimarisiyle model artık "o" anlamına gelmesi en muhtemel kelimeyi arama yeteneğine sahip. Aşağıdaki diyagram, dönüştürücü modellerin bir cümleyi işlemeye çalışırken metnin “hayvan” kısmına nasıl odaklanabildiklerini göstermektedir.
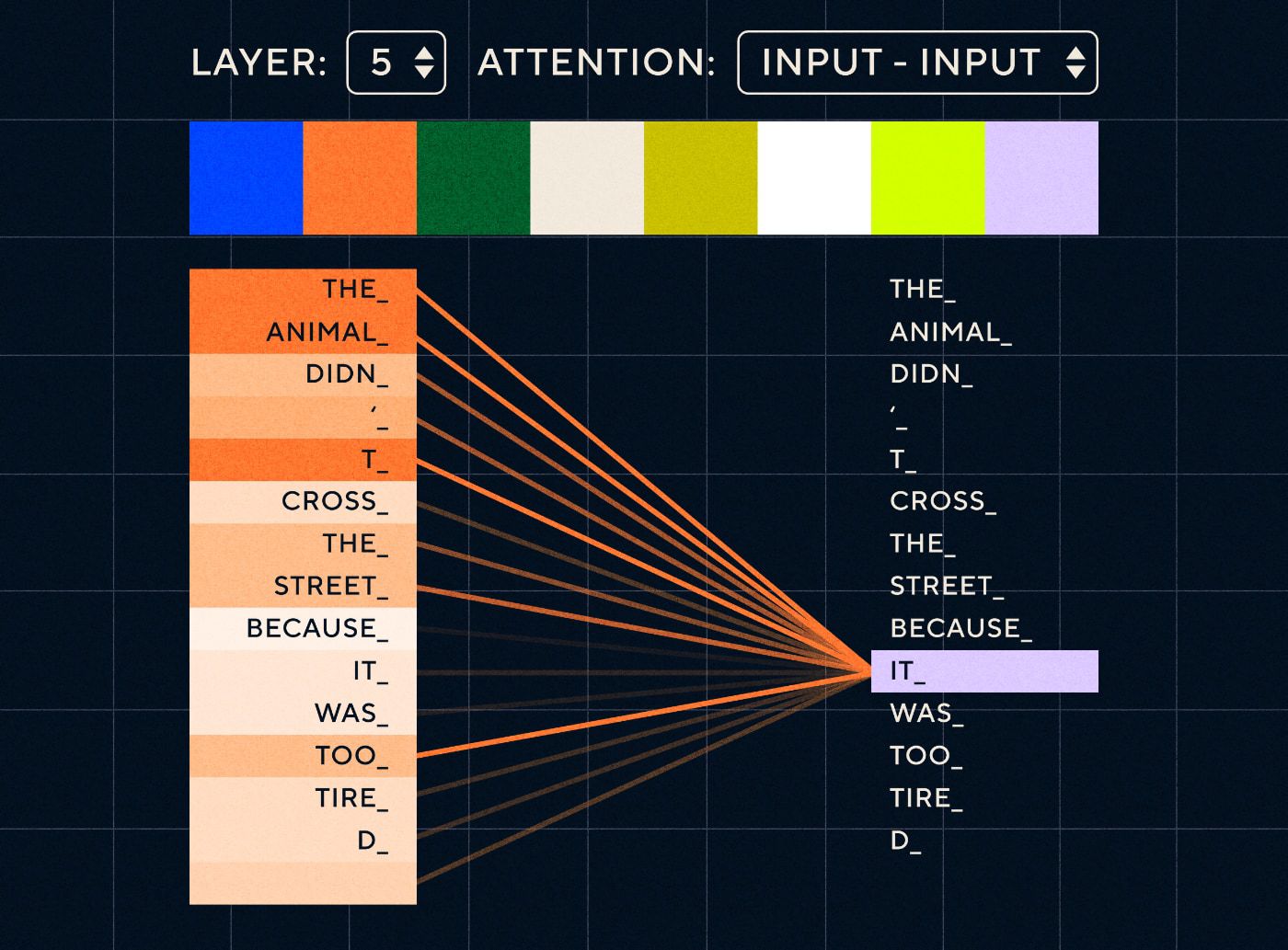
Kaynak: Resimli Transformatör
Yukarıdaki diyagram ağın 5. katmanındaki dikkati göstermektedir. Her katmanda model, cümleye ilişkin anlayışını geliştiriyor ve girdinin o sırada işlediği adımla daha alakalı olduğunu düşündüğü belirli bir kısmına "dikkat ediyor", yani "önemli olana" daha fazla dikkat ediyor. Bu katmandaki “o” için hayvan”. Kaynak: Resimli Transformatör
Bunu, büyük olasılıkla “o” ile ilgili olan en yüksek puana sahip kelimeyi alabileceği bir veritabanı gibi düşünün.
Bu gelişmeyle birlikte dil modelleri kısa metin dizilerinin ayrıştırılmasıyla sınırlı kalmadı. Bunun yerine girdi olarak daha uzun metin dizileri kullanabilirsiniz. Çocukları “etkili konuşma” yoluyla daha fazla kelimeyle tanıştırmanın dil gelişimlerini geliştirmeye yardımcı olduğunu biliyoruz.
Benzer şekilde, yeni dikkat mekanizmasıyla dil modelleri daha fazla ve çeşitli türde metin eğitimi verilerini ayrıştırabildi. Buna Wikipedia makaleleri, çevrimiçi forumlar, Twitter ve ayrıştırabileceğiniz diğer metin verileri dahildir. Çocukluk gelişiminde olduğu gibi, tüm bu kelimelere maruz kalmak ve bunların farklı bağlamlarda kullanılması, dil modellerinin yeni ve daha karmaşık dilsel yetenekler geliştirmesine yardımcı oldu.
İnsanların ne öğrenebileceklerini görmek için bu modellere giderek daha fazla veri attığı bir ölçeklendirme yarışını bu aşamada görmeye başladık. Bu verilerin insanlar tarafından etiketlenmesine gerek yoktu; araştırmacılar interneti tarayıp modele yükleyebilir ve ne öğrendiğini görebilirler.
"BERT gibi modeller mevcut tüm doğal dil işleme rekorlarını kırdı. Aslında bu görevler için kullanılan test veri setleri, bu transformatör modelleri için fazlasıyla basitti.”
BERT (Transformatörlerden Çift Yönlü Kodlayıcı Gösterimleri) modeli birkaç nedenden dolayı özel olarak anılmayı hak ediyor. Transformer mimarisinin özü olan dikkat özelliğinin kullanıldığı ilk modellerden biriydi. İlk olarak BERT, mevcut girişin hem solundaki hem de sağındaki metne bakabilmesi açısından çift yönlüydü. Bu, metni yalnızca soldan sağa sırayla işleyebilen RNN'lerden farklıydı. İkinci olarak, BERT ayrıca "maskeleme" adı verilen yeni bir eğitim tekniği kullandı; bu teknik, bir bakıma, modelin "hile yapamayacağından" emin olmak için rastgele belirteçleri "gizleyerek" veya "maskeleyerek" farklı girdilerin anlamını öğrenmeye zorladı. her yinelemede tek bir tokena odaklanın. Ve son olarak BERT, farklı NLP görevlerini yerine getirecek şekilde ince ayar yapılabilir. Bu görevler için sıfırdan eğitilmesine gerek yoktu.
Sonuçlar muhteşemdi. BERT gibi modeller mevcut tüm doğal dil işleme rekorlarını kırdı. Aslında bu görevler için kullanılan test veri kümeleri, bu transformatör modelleri için fazlasıyla basitti.
Artık yeni doğal dil işleme görevleri için temel model görevi gören büyük dil modellerini eğitme olanağına sahiptik. Daha önce insanlar çoğunlukla modellerini sıfırdan eğitiyorlardı. Ancak artık BERT ve ilk GPT modelleri gibi önceden eğitilmiş modeller o kadar iyiydi ki bunu kendi başınıza yapmanın bir anlamı yoktu. Aslında bu modeller o kadar iyi insanlar tarafından keşfedildi ki nispeten az sayıda örnekle yeni görevleri yerine getirebildiler; tıpkı çoğu insanın yeni kavramları kavramak için çok fazla örneğe ihtiyaç duymamasına benzer şekilde "birkaç adımda öğrenenler" olarak tanımlandılar.
Bu, bu modellerin ve dilsel yeteneklerinin geliştirilmesinde büyük bir dönüm noktasıydı. Artık talimatlar hazırlama konusunda daha iyi olmamız gerekiyordu.
Model 4 – InstructGPT ile öğrenme talimatları
Dil ediniminin son aşaması olan çok kelimeli aşamada çocukların öğrendikleri şeylerden biri, cümledeki bilgi taşıyan öğeleri birbirine bağlamak için işlev sözcüklerini kullanma becerisidir. İşlev sözcükleri bize bir cümledeki farklı sözcükler arasındaki ilişkiyi anlatır. Talimatlar oluşturmak istiyorsak, dil modellerinin karmaşık ilişkileri yakalayan içerik sözcükleri ve işlev sözcükleriyle cümleler oluşturabilmesi gerekir. Örneğin, aşağıdaki talimatta fonksiyon kelimeleri kalın harflerle vurgulanmıştır:
- “Bir mektup yazmanı istiyorum …”
- “ Bana yukarıdaki metin hakkında ne düşündüğünü söyle”
Ancak dil modellerini talimatları takip edecek şekilde eğitmeden önce, talimatlar hakkında tam olarak ne bildiklerini anlamamız gerekiyordu.
OpenAI'nin GPT-3'ü 2020'de piyasaya sürüldü. Bu modellerin neler yapabileceğine dair bir fikirdi ancak yine de bu modellerin temel yeteneklerini nasıl ortaya çıkaracağımızı anlamamız gerekiyordu. Farklı görevleri yerine getirmelerini sağlamak için bu modellerle nasıl etkileşime girebiliriz?
Örneğin, GPT-3, model boyutunun ve eğitim verilerinin arttırılmasının, yazarların "meta-öğrenme" olarak adlandırdığı şeyi mümkün kıldığını gösterdi; bu, dil modelinin, çoğu beklenmedik olan geniş bir dilsel yetenekler kümesini geliştirdiği ve bunları kullanabileceği yerdir. Verilen bir görevi anlama becerisi.
"Model, yalnızca bir sonraki kelimeyi tahmin etmek yerine talimatın amacını anlayıp görevi yerine getirebilecek mi?"
Unutmayın, GPT-3 ve önceki dil modelleri bu becerileri geliştirmek için tasarlanmamıştı; çoğunlukla bir metin dizisindeki bir sonraki kelimeyi tahmin etmek için eğitilmişlerdi. Ancak RNN'ler, Seq2Seq ve dikkat ağlarındaki ilerlemeler sayesinde bu modeller daha fazla metni daha uzun dizilerde işleyebildi ve ilgili bağlama daha iyi odaklanabildi.
GPT-3'ü bunu ne kadar ileri götürebileceğimizi görmek için bir test olarak düşünebilirsiniz. Modelleri ne kadar büyük yapabiliriz ve onu ne kadar metinle besleyebiliriz? Daha sonra bunu yaptıktan sonra, modele tamamlaması için bir miktar giriş metni vermek yerine, giriş metnini talimat olarak kullanabiliriz. Model, yalnızca bir sonraki kelimeyi tahmin etmek yerine talimatın amacını anlayıp görevi yerine getirebilecek mi? Bir bakıma bu modellerin dil ediniminde hangi aşamaya geldiğini anlamaya çalışmak gibiydi.
Şimdi bunu "teşvik" olarak tanımlıyoruz, ancak 2020'de, makalenin çıktığı dönemde bu çok yeni bir kavramdı.
Halüsinasyonlar ve hizalama
GPT-3'ün sorunu, artık bildiğimiz gibi, giriş metnindeki talimatlara sıkı sıkıya bağlı kalmanın pek iyi olmamasıydı. GPT-3 talimatları takip edebilir ancak dikkati kolayca kaybeder, yalnızca basit talimatları anlayabilir ve bir şeyler uydurma eğilimindedir. Başka bir deyişle modeller niyetimizle “uyumlu” değil. Dolayısıyla artık sorun, modellerin dil becerilerini geliştirmekten ziyade talimatları takip etme becerilerini geliştirmekle ilgili.
GPT-3'ün hiçbir zaman talimatlar konusunda eğitilmediğini belirtmekte fayda var. Bir talimatın ne olduğu, diğer metinlerden ne kadar farklı olduğu ya da talimatları nasıl takip etmesi gerektiği anlatılmadı. Bir bakıma, diğer metin dizileri gibi bir istemi "tamamlaması" sağlanarak talimatları takip etmesi yönünde "kandırıldı". Sonuç olarak OpenAI'nin talimatları insan gibi daha iyi takip edebilen bir model yetiştirmesi gerekiyordu. Ve bunu, 2022'nin başlarında yayınlanan İnsan geri bildirimiyle talimatları takip etmek için dil modellerini eğitmek başlıklı uygun bir makalede yaptılar. InstructGPT, aynı yılın ilerleyen dönemlerinde ChatGPT'nin öncüsü olduğunu kanıtlayacaktı.
Bu makalede özetlenen adımlar aynı zamanda ChatGPT'yi eğitmek için de kullanıldı. Talimat eğitimi 3 ana adımı takip etti:
- 1. Adım - GPT-3'te İnce Ayar Yapın: GPT-3 birkaç adımda öğrenme konusunda çok iyi performans gösterdiğinden, yüksek kaliteli eğitim örneklerine göre ince ayar yapılmasının daha iyi olacağı düşünüldü. Amaç, talimattaki amacı oluşturulan yanıtla uyumlu hale getirmeyi kolaylaştırmaktı. Bunu yapmak için OpenAI, insan etiketleyicilerin GPT-3 kullanan kişiler tarafından gönderilen bazı istemlere yanıtlar oluşturmasını sağladı. Yazarlar, gerçek talimatları kullanarak, kullanıcıların GPT-3'ü gerçekleştirmeye çalıştığı görevlerin gerçekçi bir "dağılımını" yakalamayı umuyorlardı. Bunlar, GPT-3'ün hızlı yanıt yeteneğini geliştirmesine yardımcı olmak amacıyla ince ayar yapmak için kullanıldı.
- Adım 2 – İnsanların yeni ve geliştirilmiş GPT-3'ü sıralamasını sağlayın: Etiketleyiciler, yeni talimatta ince ayar yapılmış GPT-3'ü değerlendirmek için artık modelin performansını önceden tanımlanmış bir yanıt olmadan farklı istemlerde derecelendirdi. Sıralama, yararlı olmak, dürüst olmak, zehirli, önyargılı veya zararlı olmamak gibi önemli uyum faktörleriyle ilgiliydi. Bu nedenle modele bir görev verin ve performansını bu ölçümlere göre derecelendirin. Bu sıralama çalışmasının çıktısı daha sonra etiketleyicilerin muhtemelen hangi çıktıları tercih edeceğini tahmin etmek için ayrı bir model eğitmek için kullanıldı. Bu model ödül modeli (RM) olarak bilinir.
- Adım 3 – Daha fazla örnek üzerinde eğitim vermek için RM'yi kullanın: Son olarak, RM, insan tercihleriyle uyumlu yanıtları daha iyi üretmek amacıyla yeni öğretim modelini eğitmek için kullanıldı.
İnsan Geri Bildiriminden Takviyeli Öğrenme (RLHF), ödül modelleri, politika güncellemeleri vb. ile burada neler olup bittiğini tam olarak anlamak zordur.
Bunu düşünmenin basit bir yolu, insanların talimatları nasıl takip edeceklerine dair daha iyi örnekler oluşturmalarını sağlamanın bir yolu olduğudur. Örneğin, bir çocuğa teşekkür etmeyi nasıl öğreteceğinizi düşünün:
- Ebeveyn: “Birisi sana X verdiğinde teşekkür edersin”. Bu, istemlerin ve uygun yanıtların örnek bir veri kümesi olan 1. adımdır.
- Ebeveyn: “Şimdi burada Y'ye ne diyorsun?”. Bu, çocuktan bir yanıt oluşturmasını istediğimiz ve ardından ebeveynin bunu derecelendireceği 2. adımdır. "Evet bu iyi."
- Son olarak, sonraki karşılaşmalarda ebeveyn, gelecekte benzer senaryolarda verilecek iyi veya kötü yanıt örneklerine göre çocuğunu ödüllendirecektir. Bu, pekiştirme davranışının gerçekleştiği 3. adımdır.
OpenAI, kendi adına, yaptığı tek şeyin GPT-3 gibi modellerde zaten mevcut olan, ancak gazetede belirtildiği gibi "yalnızca hızlı mühendislik yoluyla ortaya çıkarılması zor olan" yeteneklerin kilidini açmak olduğunu iddia ediyor.
Başka bir deyişle, ChatGPT aslında " yeni " yetenekler öğrenmiyor, yalnızca bunları kullanmak için daha iyi bir dilsel " arayüz " öğreniyor.
Dilin büyüsü
ChatGPT ileriye doğru sihirli bir adım gibi görünse de aslında onlarca yıldır süren özenli teknolojik ilerlemenin sonucudur.
Son on yılda yapay zeka ve NLP alanında yaşanan bazı önemli gelişmelere bakarak ChatGPT'nin nasıl "devlerin omuzlarında durduğunu" görebiliriz. Daha önceki modeller ilk önce kelimelerin anlamlarını tanımlamayı öğrenmişti. Daha sonra sonraki modeller bu kelimeleri bir araya getiriyor ve onları çeviri gibi görevleri yerine getirecek şekilde eğitebiliyoruz. Cümleleri işleyebildiklerinde, bu dil modellerinin giderek daha fazla metni işlemesine ve bu öğrendiklerini yeni ve öngörülemeyen görevlere uygulama becerisini geliştirmesine olanak tanıyan teknikler geliştirdik. Daha sonra ChatGPT ile talimatlarımızı doğal dil formatında belirterek bu modellerle daha iyi etkileşim kurma yeteneğini geliştirdik.
“Dil, düşüncelerimizin aracı olduğuna göre, bilgisayarlara dilin tüm gücünü öğretmek, bağımsız yapay zekaya yol açacak mı?”
Ancak NLP'nin evrimi, genellikle kör olduğumuz daha derin bir büyüyü ortaya çıkarıyor: dilin büyüsü ve biz insanlar olarak onu nasıl kazandığımız.
Çocukların dili ilk etapta nasıl öğrendikleri konusunda hala birçok açık soru ve tartışma var. Ayrıca tüm dillerin altında yatan ortak bir yapının olup olmadığı konusunda da sorular var. İnsanlar dili kullanacak şekilde mi evrimleşti yoksa tam tersi mi?
İlginç olan şu ki, ChatGPT ve onun soyundan gelenler dilsel gelişimlerini geliştirdikçe, bu modeller bu önemli soruların bazılarının yanıtlanmasına yardımcı olabilir.
Son olarak, dil düşüncelerimizin aracı olduğuna göre, bilgisayarlara dilin tüm gücünü öğretmek bağımsız yapay zekaya yol açacak mı? Hayatta her zaman olduğu gibi öğrenecek çok şey var.
