
Wikipedia ve Google Language API ile Konu Grafiğinin Hacklenmesi
Yayınlanan: 2019-08-27Son on yılda en sevdiğim slayt destelerinden biri, 2014 yılında Mark Johnstone tarafından Distilled ile birlikteyken yapıldı. Destenin adı Daha İyi İçerik Fikirleri Nasıl Üretilirdi ve onu içerik tanıtımının zor işini yapacak ekipler oluştururken birkaç yıl boyunca kutsal kitabım olarak kullandım.
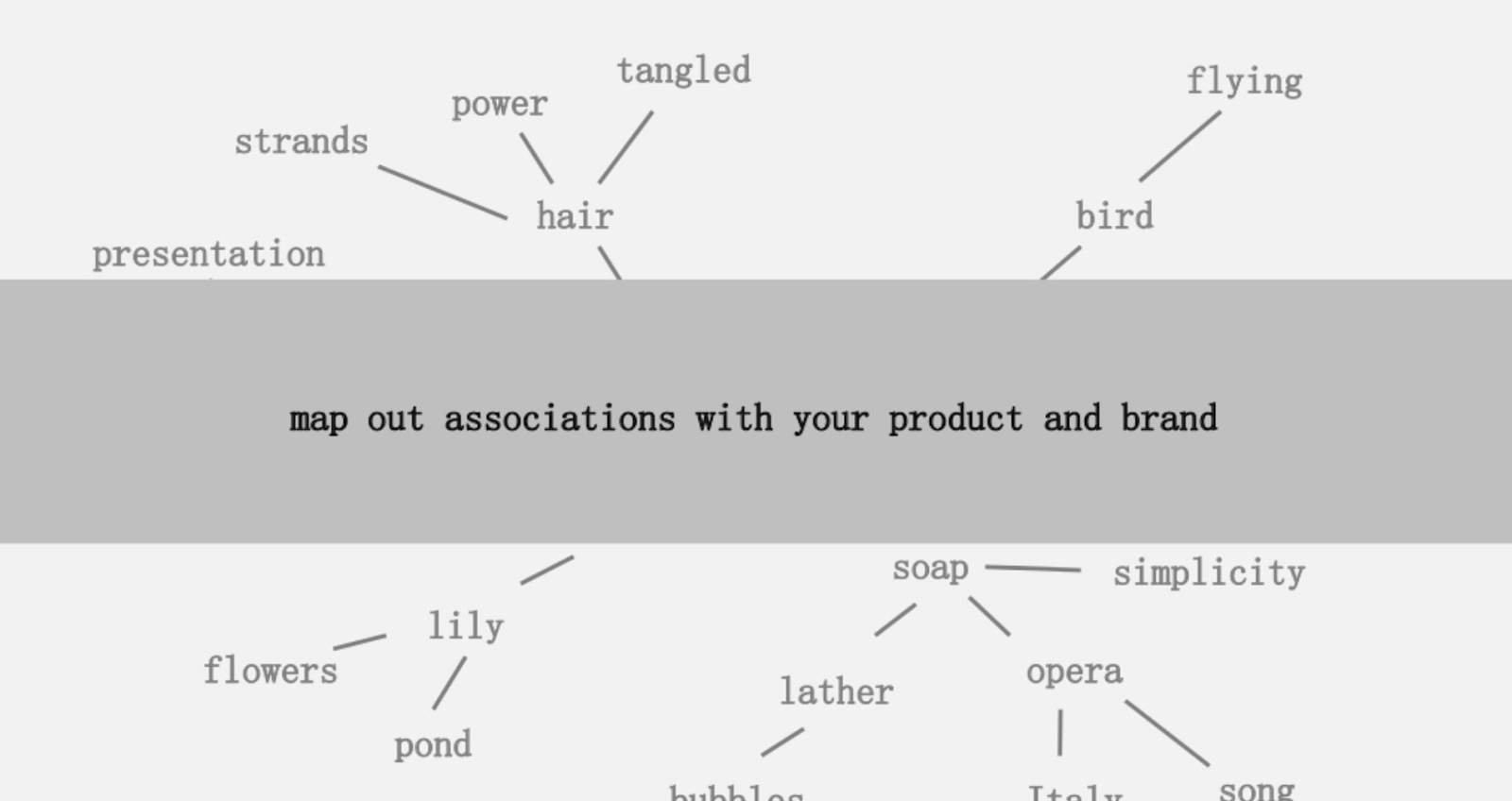
Sunulan fikirlerden biri, geri çekilebilmeniz ve çağrışımları ilginç bir şeyle birleştirmenin yollarını arayabilmeniz için ürününüzle veya markanızla ilişkili kelimelerin bağlantılarının görsel bir haritasını oluşturmaktı. Amaç, “ önceden bağlantısız unsurların değer katacak şekilde yeni bir kombinasyonu” olarak tanımladığı fikirlerin üretilmesidir.
Bu makalede, bir çekirdek konudan var olan varlık ilişkilerini keşfetmek için Wikipedia ile birlikte Google'ın Dil API'si Python'u kullanarak çok daha sol beyin yaklaşımını benimsiyoruz. Amaç, konu grafiği boyunca varlık ilişkilerinin üst düzey bir görünümüdür. Bu makale ortalama bir okuyucu için değildir. Python'a aşina olan ve en azından temel düzeyde kodlama becerisine sahip olan okuyucular onu çok daha öğretici bulacaktır.
Fikir
Mark Johnstone'un haritalama fikrini takip ederek, Google ve Wikipedia'nın bir çekirdek konudan veya web sayfasından başlayarak bir konu yapısı tanımlamasına izin vermenin ilginç olacağını düşündüm. Amaç, bağlantıları aramak ve muhtemelen içerik fikirleri oluşturmak için gözden geçirilebilecek ağaç benzeri bir grafikte, ana konuyla ilişkilerin haritasını görsel olarak oluşturmaktır. Aşağıdaki görüntü, ilk tasarım fikrini temsil etmektedir.
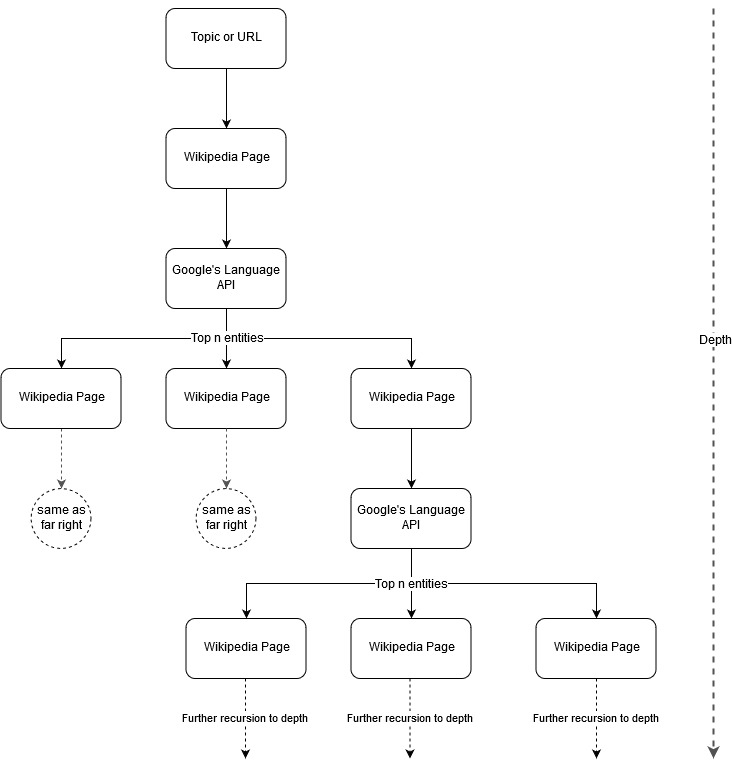
Esasen, araca bir konu veya URL veriyoruz ve Google'ın Dil API'sinin her varlık sayfası için en üst n (örneklerimizde 3) varlığı (Wikipedia URL'lerini içeren) seçmesine izin veriyoruz ve bulunan her varlık için yinelemeli olarak bir ağ grafiği oluşturmaya devam ediyoruz. maksimum derinliğe kadar.
Kullanılan Araçların Arka Planı
Google Dil API'sı
Google'ın Dil API'si, düz metin veya HTML iletmenize izin verir ve içerikle ilişkili tüm çeşitli varlıkları sihirli bir şekilde döndürür. API bundan daha fazlasını yapar, ancak bu analiz için yalnızca bu kısma odaklanacağız. Döndürdüğü varlık türlerinin listesi:
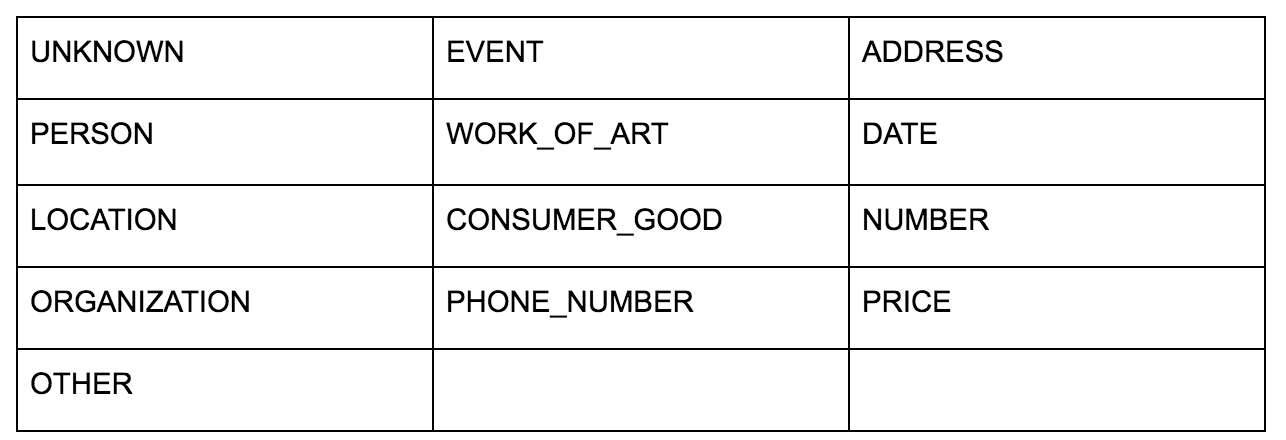
Varlık tanımlama, uzun süredir Doğal Dil İşleme'nin (NLP) temel bir parçası olmuştur ve görev için doğru terminoloji Adlandırılmış Varlık Tanıma'dır (NER). NER zor bir iştir, çünkü birçok kelimenin kullanılan bağlama göre farklı anlamları vardır, bu nedenle NLP araçları veya API'ler, onları belirli bir varlık olarak doğru bir şekilde tanımlayabilmek için terimleri çevreleyen tam bağlamı anlamalıdır.
Bu makaleyi bitirmeden önce bazı bağlamları yakalamak istiyorsanız, opensource.com'daki bir makalede bu API'ye ve özellikle varlıklara oldukça ayrıntılı bir genel bakış verdim.
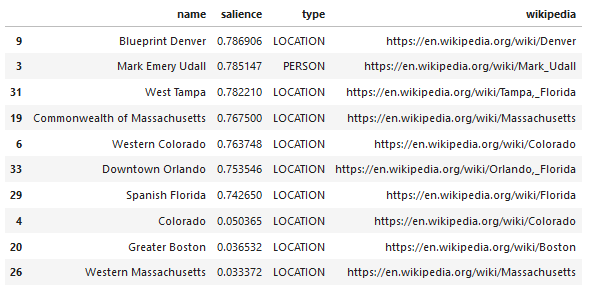
Google'ın Dil API'sinin ilginç bir özelliği, ilgili varlıkları bulmanın yanı sıra, bunların genel belgeyle (belirginlik) ne kadar ilgili olduklarını da işaret etmesi ve bazıları için varlığı temsil eden ilgili bir Wikipedia (bilgi grafiği) makalesi sağlamasıdır.
API'nin ne döndürdüğüne ilişkin örnek bir çıktı aşağıdadır (dikkat derecesine göre sıralanmıştır):
Oncrawl Geliştirici
 Daha fazla bilgi edin
Daha fazla bilgi edinpiton
Python, büyük veri kümelerini almayı, temizlemeyi, değiştirmeyi ve analiz etmeyi kolaylaştıran geniş ve büyüyen bir kitaplık kümesi nedeniyle veri bilimi alanında popüler hale gelen bir yazılım dilidir. Ayrıca, kullanıcıların kodlarını zahmetsiz bir şekilde kolayca test etmelerine ve açıklama eklemelerine olanak tanıyan Jupyter not defterleri adı verilen ortak çalışma ortamından da yararlanır.
Bu inceleme için, Google'ın NLP verileriyle bazı ilginç şeyler yapmamızı sağlayacak birkaç anahtar kitaplık kullanacağız.
- Pandalar: Elektronik tabloları okumak, kaydetmek, ayrıştırmak veya yeniden düzenlemek için Microsoft Excel'i komut dosyası oluşturabildiğinizi düşünün ve Pandaların ne yaptığı hakkında bir fikir edinirsiniz. Pandalar harika. (bağlantı)
- Networkx: Networkx, düğümler arasındaki ilişkileri tanımlayan düğüm ve kenarların grafiklerini oluşturmak için bir araçtır. Ayrıca grafikleri görselleştirmek için dahili desteğe sahiptir, böylece görselleştirmeleri kolaydır. (bağlantı)
- Pywikibot: Pywikibot, her bir Wikipedia sitesinin tüm içeriğiyle birlikte arama yapmak, düzenlemek, ilişkileri bulmak vb. için Wikipedia ile etkileşime girmenize izin veren bir kitaplıktır. (bağlantı)
Süreç
Takip etmek için kullanılabilecek bir Google Colab not defterini burada paylaşıyoruz. (Makalede ve bu defterde akıl sağlığı kontrolü için Tyler Reardon'a özel teşekkürler.)
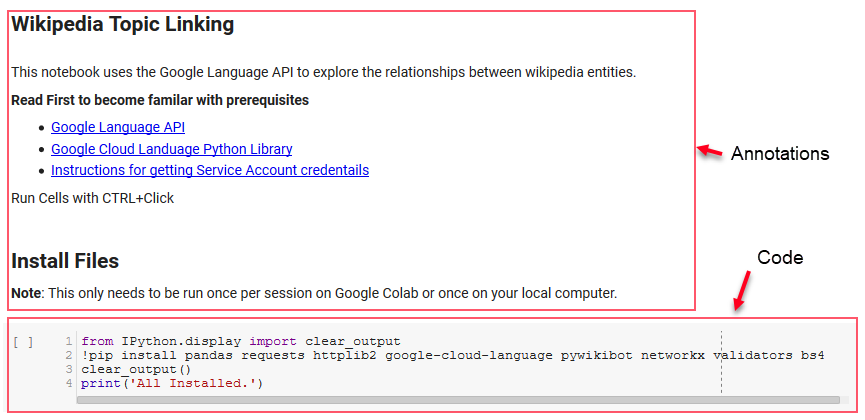
kurulum
Not defterindeki ilk birkaç hücre, bazı kitaplıkları kurmak, bu kitaplıkları Python için kullanılabilir hale getirmek ve sırasıyla Google'ın Dil API'si ve Pywikibot için bir kimlik bilgileri ve yapılandırma dosyası sağlamakla ilgilenir. Aracın çalışabilmesi için yüklememiz gereken tüm kitaplıklar şunlardır:
- pandalar
- istekler
- httplib2
- google-cloud-dili
- pywikibot
- ağx
- doğrulayıcılar
- BS4
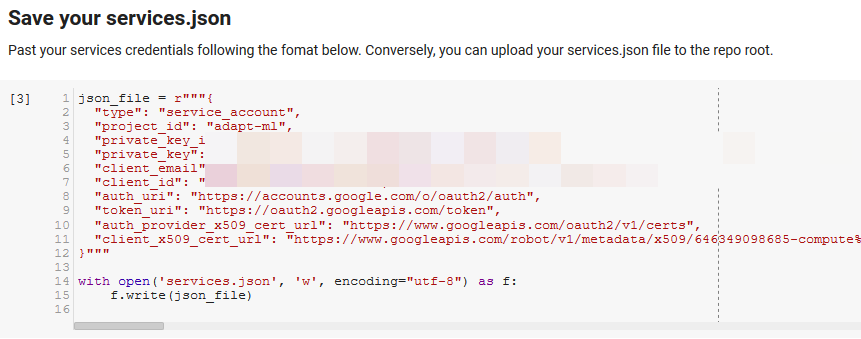
Not: Bu not defterini çalıştırabilmenin en zor kısmı, API'lerine erişmek için Google'dan kimlik bilgilerini almaktır. Bu konuda tecrübesiz olanlar için, bunu anlaması bir saat kadar sürecektir. Size yardımcı olmak için dizüstü bilgisayarın üst kısmındaki Hizmet Hesabı kimlik bilgilerini alma talimatlarını birbirine bağladık. Aşağıda bizimkileri nasıl dahil ettiğimize bir örnek verilmiştir.
Kazanmak için Fonksiyonlar
"Google NLP için bazı işlevleri tanımlayın" ile belirtilen hücrede, Dil API'sini sorgulama, Wikipedia ile etkileşim kurma, web sayfası metnini çıkarma ve grafikler oluşturma ve çizme gibi şeyleri işleyen sekiz işlev geliştirdik. Fonksiyonlar aslında bazı ayar verilerini alan, bazı işler yapan ve bir şeyler üreten küçük kod birimleridir. Tüm fonksiyonlar, aldıkları değişkenleri ve ne ürettiklerini anlatmak için yorumlanmıştır.

API'yi test etme
Aşağıdaki iki hücre bir URL alır, metni URL'den çıkarır ve varlıkları Google'ın Dil API'sinden çeker. Biri yalnızca Wikipedia URL'leri olan varlıkları, diğeri ise tüm varlıkları o sayfadan çeker.
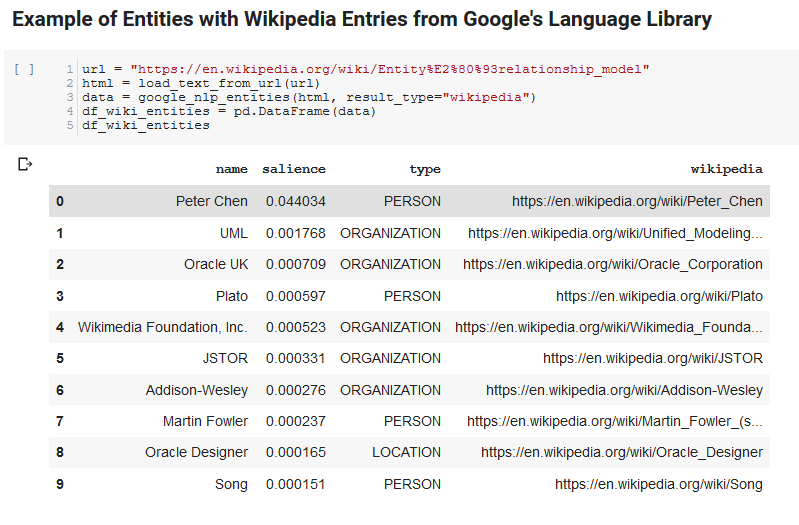
Bu, yalnızca içerik çıkarma bölümünü doğru hale getirmek ve Dil API'sinin nasıl çalıştığını ve verileri nasıl döndürdüğünü anlamak için önemli bir ilk adımdı.
ağx
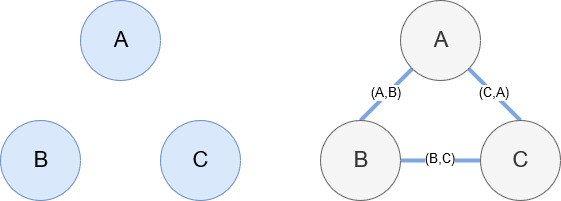
Networkx, daha önce de belirtildiği gibi, oynaması oldukça sezgisel olan harika bir kütüphanedir. Esasen, düğümlerinizin ne olduğunu ve düğümlerin nasıl bağlandığını söylemelisiniz. Örneğin, aşağıdaki resimde Networkx'e üç düğüm (A,B,C) veriyoruz. Daha sonra Networkx'e düğümler arasındaki ilişkileri tanımlayan (A,B), (B,C), (C,A) kenarlarıyla bağlı olduklarını söyleriz. Bizim kullanımımız için, Wikipedia URL'leri olan varlıklar düğümler olacak ve kenarlar, mevcut bir varlık sayfasında bulunan yeni varlıklar tarafından tanımlanıyor. Dolayısıyla, Varlık A için Wikipedia sayfasını inceliyorsak ve bu sayfada Varlık B keşfedilirse, bu, Varlık A ile Varlık B arasında bir kenardır.
Hepsini bir araya koy
Not defterinin sonraki bölümü, URL'ye göre Wikipedia Konu Dallandırması olarak adlandırılır. Sihir yapılan yer burasıdır. Google'ın dil API'si tarafından tanımlanan yeni varlıkları takiben Wikipedia'daki sayfalarda yinelenen özel bir işlev (recurse_entities) daha önce tanımlamıştık. Ayrıca Stack Overflow'tan kaldırdığımız ve çok sayıda düğüm içeren ağaç benzeri bir grafik sunma konusunda iyi bir iş çıkaran, anlaşılması güç bir işlev (hierarchy_pos) ekledik. Aşağıdaki hücrede girdiyi “Arama Motoru Optimizasyonu” olarak tanımlıyoruz ve derinliği 3 (yinelemeli olarak kaç sayfa takip ediyor) ve 3 limiti (sayfa başına kaç varlık çektiğini) belirliyoruz.
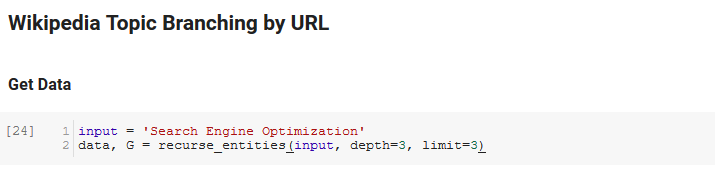
"Arama Motoru Optimizasyonu" terimi için çalıştırırken, Wikipedia'nın Arama Motoru Optimizasyonu sayfasından (Seviye 0) başlayarak ve belirtilen maksimum derinliğe kadar sayfaları tekrar tekrar izleyerek, aracın izlediği aşağıdaki yolu görebiliriz (3).

Daha sonra bulunan tüm varlıkları alıp Pandas DataFrame'e ekliyoruz, bu da CSV olarak kaydetmeyi gerçekten kolaylaştırıyor. Bu verileri belirginliğe göre sıralarız (varlığın bulunduğu sayfa için ne kadar önemlidir), ancak bu puan bu bağlamda biraz yanıltıcıdır çünkü varlığın orijinal teriminizle ne kadar ilişkili olduğunu söylemez (“ Arama motoru optimizasyonu"). Daha sonraki çalışmaları okuyucuya bırakacağız.

Son olarak, tüm varlıkların bağlantılılığını göstermek için araç tarafından oluşturulan grafiği çiziyoruz. Aşağıdaki hücrede, fonksiyona iletebileceğiniz parametreler şunlardır: ( G : recurse_entities fonksiyonu tarafından önceden oluşturulmuş Grafik, w: grafiğin genişliği, h: grafiğin yüksekliği, c: dairenin yüzde çemberi arsa ve dosya adı: görüntüler klasörüne kaydedilen PNG dosyası.)

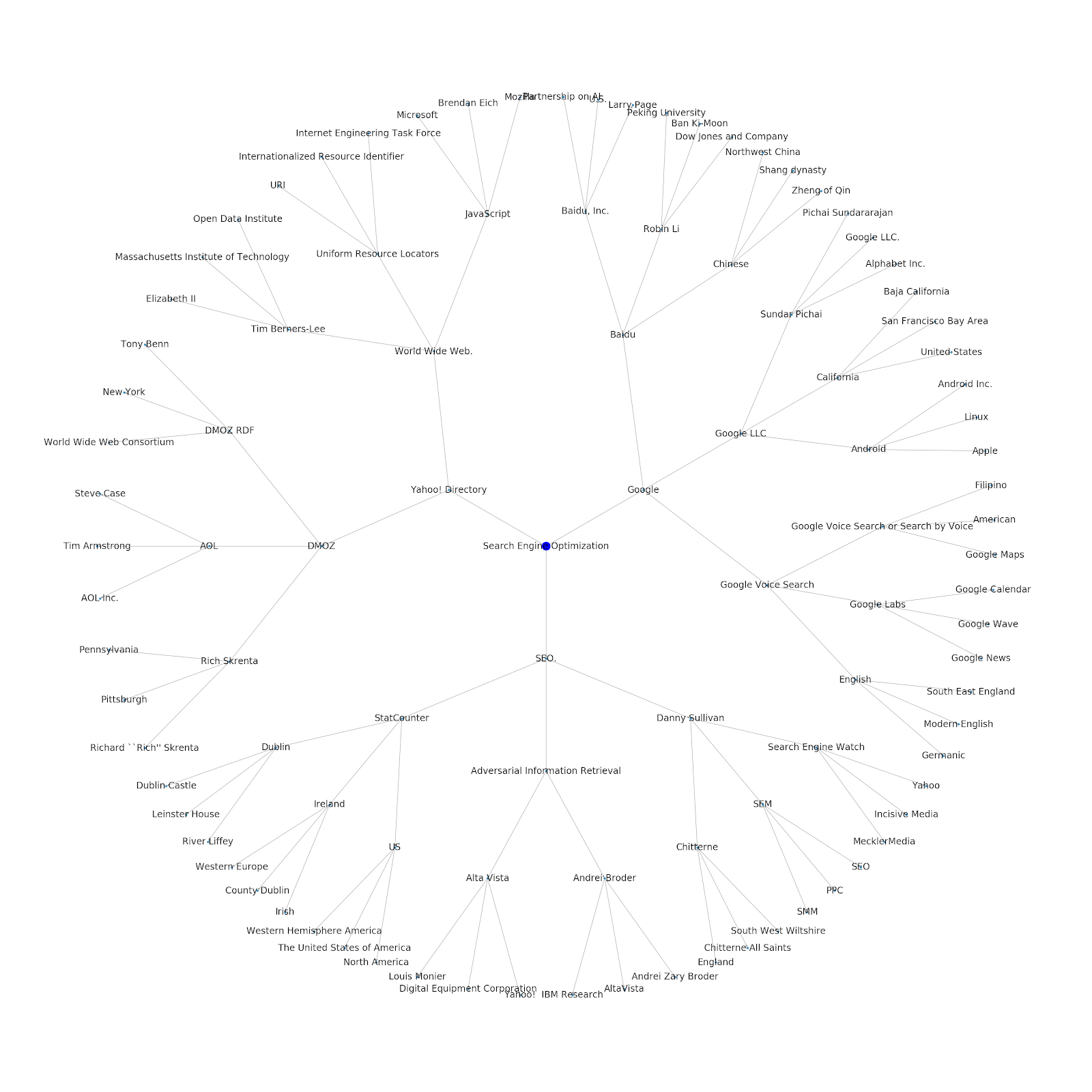
Bir başlangıç konusu veya bir başlangıç URL'si verme özelliğini ekledik. Bu örnekte, Google'ın Dizine Ekleme Sorunları Devam Ediyor Ama Bu Farklı Olan makalesiyle ilişkili varlıklara bakıyoruz.
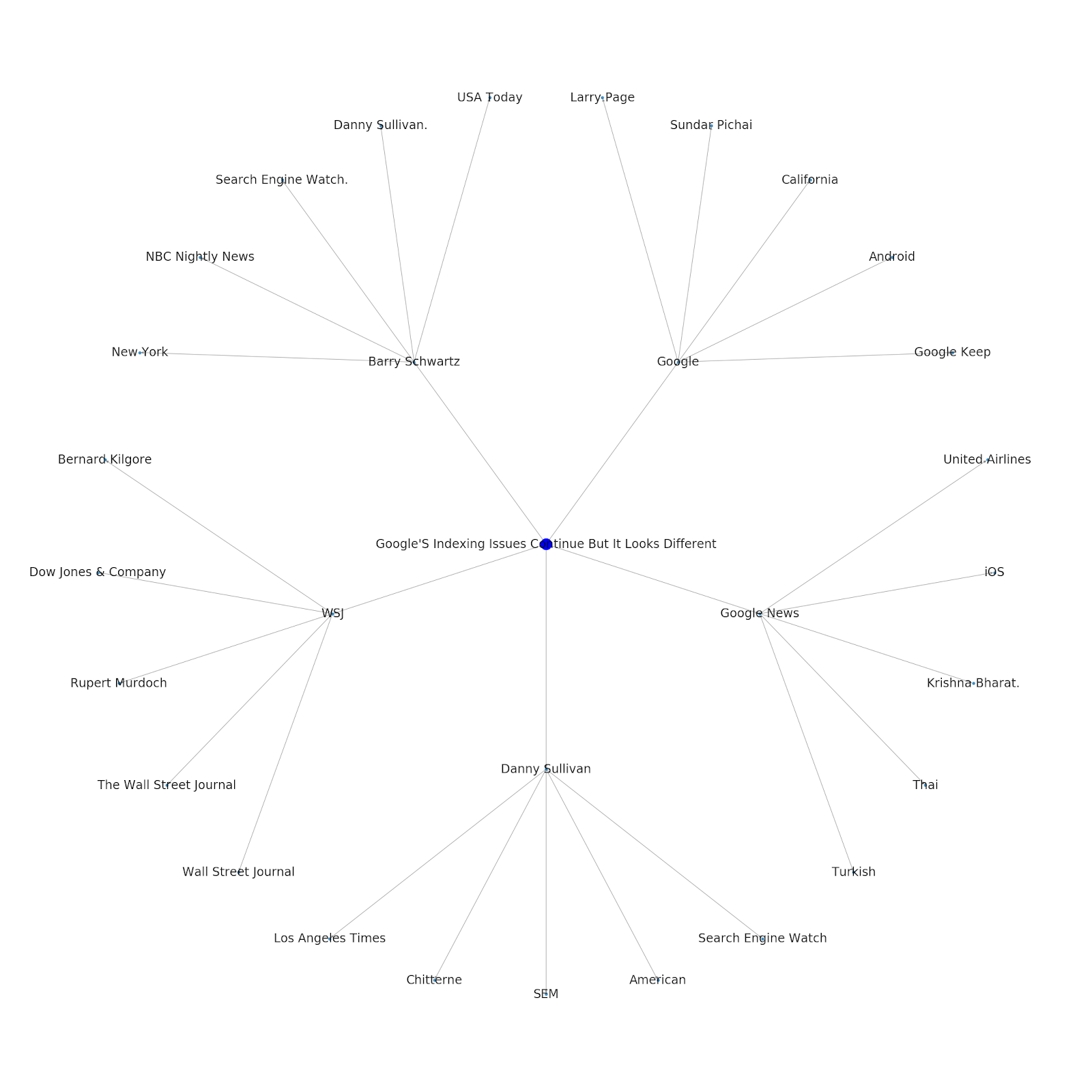
İşte Python için Google/Wikipedia varlık grafiği.
Bu ne anlama geliyor
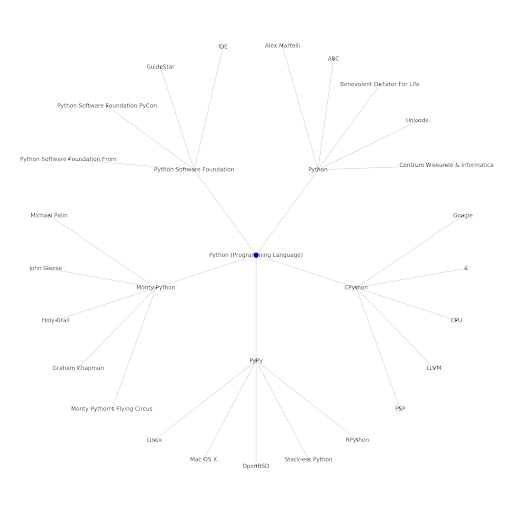
İnternetin konu katmanını anlamak, SEO açısından ilginçtir, çünkü sizi yalnızca bireysel sorgular üzerinde değil, işlerin nasıl bağlantılı olduğu açısından düşünmeye zorlar. Google, bu katmanı, Google Discover yeniden girişinde belirtildiği gibi, bireysel kullanıcı yakınlıklarını konularla eşleştirmek için kullandığından, veri odaklı SEO'lar için daha önemli bir iş akışı haline gelebilir. Yukarıdaki “Python” grafiğinde, bir kullanıcının bir başlangıç konusuyla ilgili konulara aşinalığının, çekirdek konuyla ilgili uzmanlık düzeylerinin makul bir göstergesi olabileceği çıkarımı yapılabilir.
Aşağıdaki örnek, ilgili konularla tarihsel ilgilerini veya yakınlıklarını gösteren yeşil vurgulu iki kullanıcıyı göstermektedir. Soldaki kullanıcı, bir IDE'nin ne olduğunu anlayan ve PyPy ve CPython'un ne anlama geldiğini anlayan, Python konusunda onun bir dil olduğunu bilen birinden çok daha deneyimli bir kullanıcı olacaktır, ancak başka bir şey değil. Bunu, her konu için, her kullanıcı için sayısal puanlara dönüştürmek kolay olacaktır.

Çözüm
Bugünkü amacım, Jupyter Notebook'ları kullanarak çeşitli araçların veya API'lerin etkinliğini test etmek ve gözden geçirmek için geçirdiğim oldukça standart bir sürecin ne olduğunu paylaşmaktı. Konu grafiğini keşfetmek inanılmaz derecede ilginç ve umarız paylaşılan araçları kendiniz keşfetmeye başlamanız için gereken avantajı size verir. Bu araçlarla, yalnızca Google'ın Dil API'sinin kotası (günde 800.000 olan) ile sınırlı olmak üzere, birçok ilişki düzeyini araştıran konu grafikleri oluşturabilirsiniz. (Güncelleme: Fiyatlandırma, API'ye gönderilen 1.000 unicode karakter birimine dayalıdır ve 5 bin birime kadar ücretsizdir. Wikipedia makaleleri uzun olabileceğinden, harcamanızı izlemek isteyebilirsiniz. Bunu belirtmesi için John Murch'e şapka çıkartın.) Not defterini geliştirirseniz veya ilginç vakalar bulursanız, umarım bana haber verirsiniz. Beni Twitter'da @jroakes'te bulabilirsiniz.