
Çalışan bir Robots.txt oluşturmanın anahtarları
Yayınlanan: 2020-02-18Tarayıcılar veya Örümcekler olarak da bilinen botlar, bağlantıları yol olarak kullanarak Web'de otomatik olarak web sitesinden web sitesine "seyahat eden" programlardır. Robot.txt dosyaları her zaman belirli tuhaflıklar sunmuş olsalar da çok etkili araçlar olabilir. Google ve Bing gibi arama motorları, web içeriğini taramak için botları kullanır. robots.txt dosyası, farklı botlara sitenizde hangi sayfaları taramamaları gerektiği konusunda rehberlik sağlar. Ayrıca robots.txt dosyasından XML site haritanıza bağlantı vererek botun taraması gereken her sayfanın bir haritasına sahip olmasını sağlayabilirsiniz.
robots.txt neden yararlıdır?
robots.txt, arama motoru botları söz konusu olduğunda, bir botun taraması ve dizine eklemesi gereken sayfaların miktarını sınırlar. Google'ın yönetici sayfalarını taramasını önlemek istiyorsanız, bir sayfayı Google sunucularının dışında tutmak için robots.txt dosyanızda engelleyebilirsiniz.
Sayfaların dizine eklenmesini engellemenin yanı sıra robots.txt, tarama bütçesini optimize etmek için harikadır. Tarama bütçesi, Google'ın sitenizde tarayacağını belirlediği sayfa sayısıdır. Genellikle daha fazla yetkiye ve daha fazla sayfaya sahip web sitelerinin, az sayıda sayfaya ve düşük yetkiye sahip web sitelerinden daha büyük bir tarama bütçesi vardır. Sitemize ne kadar tarama bütçesi tahsis edildiğini bilmediğimiz için indekslenmesini istemediğimiz sayfaları taramak yerine Googlebot'un en önemli sayfalara ulaşmasına izin vererek bu zamanı en iyi şekilde değerlendirmek istiyoruz.
robots.txt hakkında bilmeniz gereken çok önemli bir ayrıntı, Google robots.txt tarafından engellenen sayfaları taramayacak olsa da, sayfa başka bir web sitesinden bağlandıysa dizine eklenebilir. Sayfalarınızın dizine eklenmesini ve Google Arama sonuçlarında görünmesini engellemek için sunucunuzdaki dosyaları şifreyle korumanız, noindex meta etiketini veya yanıt başlığını kullanmanız veya sayfayı tamamen kaldırmanız (404 veya 410 ile yanıt verin) gerekir. Tarama ve indekslemeyi kontrol etme hakkında daha fazla bilgi için OnCrawl'ın robots.txt kılavuzunu okuyabilirsiniz.
[Örnek Olay] Google'ın bot taramasını yönetme
 Örnek olayı okuyun
Örnek olayı okuyunDoğru Robots.txt Sözdizimi
Farklı tarayıcılar sözdizimini farklı yorumladığından robots.txt sözdizimi bazen biraz zor olabilir. Ayrıca, saygın olmayan bazı tarayıcılar, robots.txt yönergelerini, uymaları gereken kesin bir kural olarak değil, öneri olarak görür. Sitenizde gizli bilgileriniz varsa, robots.txt kullanarak tarayıcıları engellemenin yanı sıra parola koruması kullanmanız da önemlidir.
Aşağıda, robots.txt dosyanız üzerinde çalışırken aklınızda bulundurmanız gereken birkaç şeyi listeledim:
- robots.txt dosyasının bir alt dizin altında değil, etki alanı altında yaşaması gerekir. Tarayıcılar, alt dizinlerdeki robots.txt dosyalarını kontrol etmez.
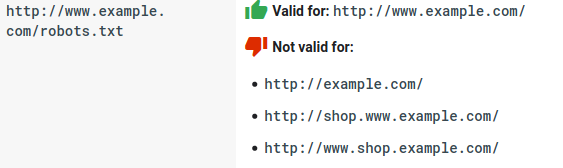
- Her alt etki alanının kendi robots.txt dosyasına ihtiyacı vardır:
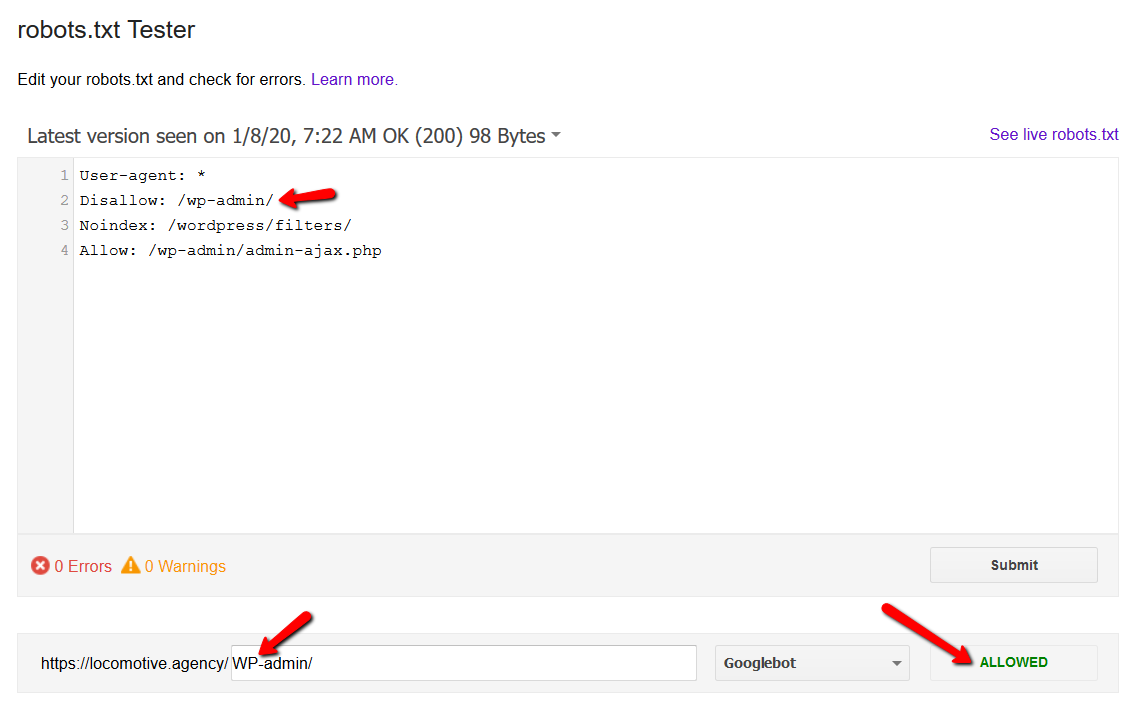
- Robots.txt büyük/küçük harf duyarlıdır:
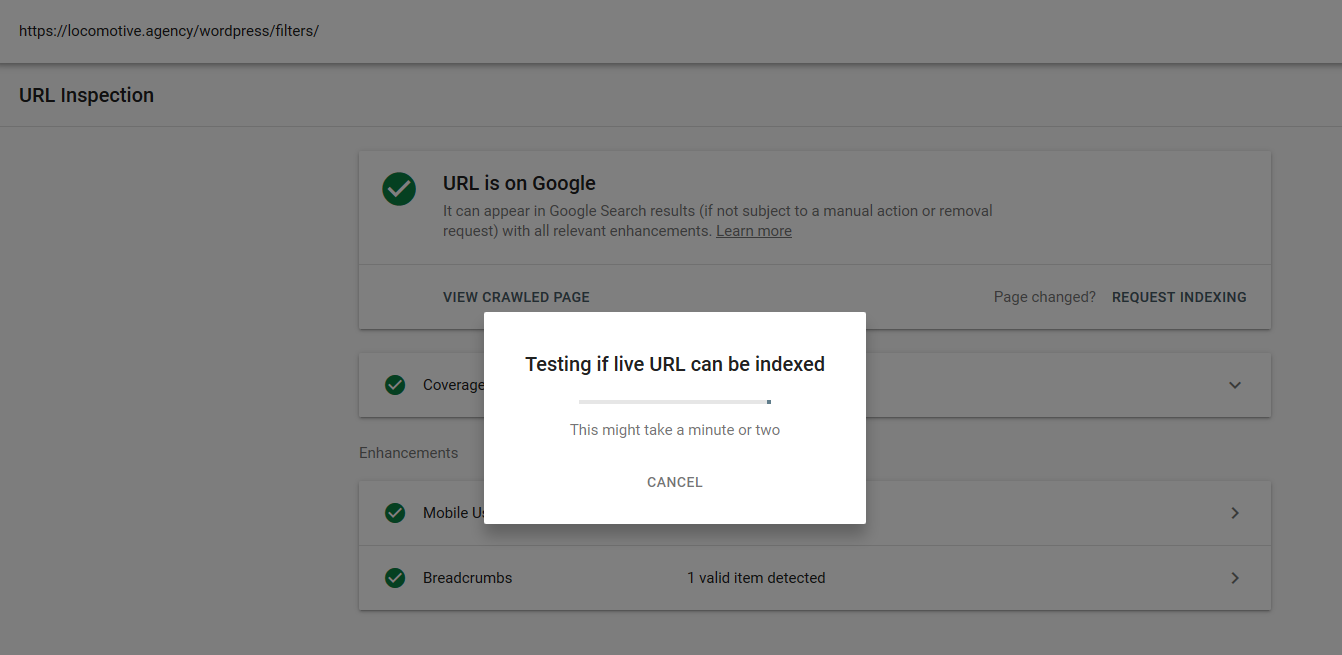
- noindex yönergesi: robots.txt dosyasında noindex kullandığınızda, disallow ile aynı şekilde çalışır. Google, sayfayı taramayı durduracak, ancak onu dizininde tutacaktır. @jroakes ve ben /wordpress/filters/ makalesinde Noindex yönergesini kullandığımız ve sayfayı Google'a gönderdiğimiz bir test oluşturduk. Aşağıdaki ekran görüntüsünde URL'nin engellendiğini görebilirsiniz:
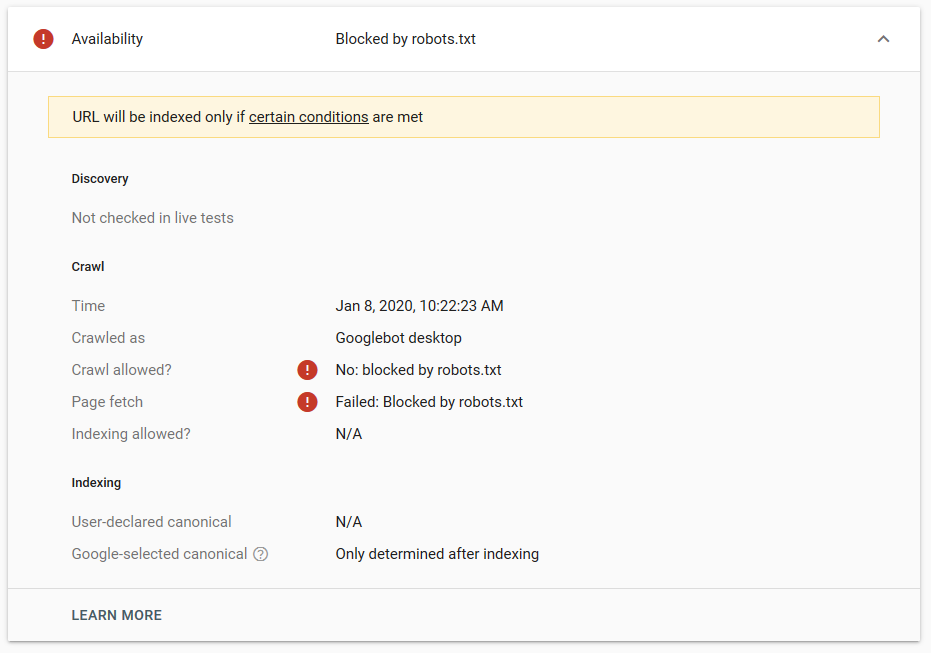
Google'da birkaç test yaptık ve sayfa dizinden hiçbir zaman kaldırılmadı:

Geçen yıl robots.txt'te çalışan noindex yönergesi hakkında, Google dışında sayfaları kaldıran bir tartışma vardı. İşte Gary Illyes'in uzaklaştığını belirttiği bir konu. Bu testte, noindex yönergesi sayfayı arama sonuçlarından kaldırmadığı için Google'ın çözümünün yerinde olduğunu görebiliriz.
Geçenlerde, Christian Oliveira'dan twitter'da robots.txt'niz üzerinde çalışırken dikkate alınması gereken birkaç ayrıntıyı paylaştığı ilginç bir ileti dizisi daha vardı.
- Yalnızca Googlebot için genel kurallara ve kurallara sahip olmak istiyorsak, Kullanıcı aracısı: Google bot kuralları kümesi altındaki tüm genel kuralları çoğaltmamız gerekir. Dahil edilmezlerse, Googlebot tüm kuralları yok sayar:

- Bir diğer kafa karıştırıcı davranış, kuralların önceliğinin (aynı Kullanıcı-aracı grubu içinde) sıralarına göre değil, kuralın uzunluğuna göre belirlenmesidir.
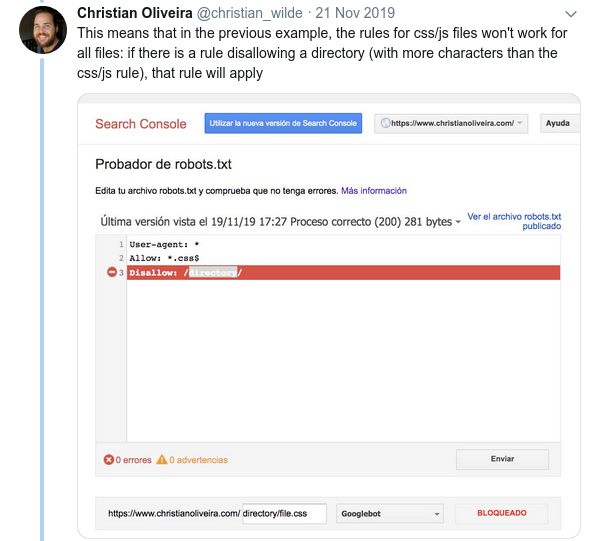
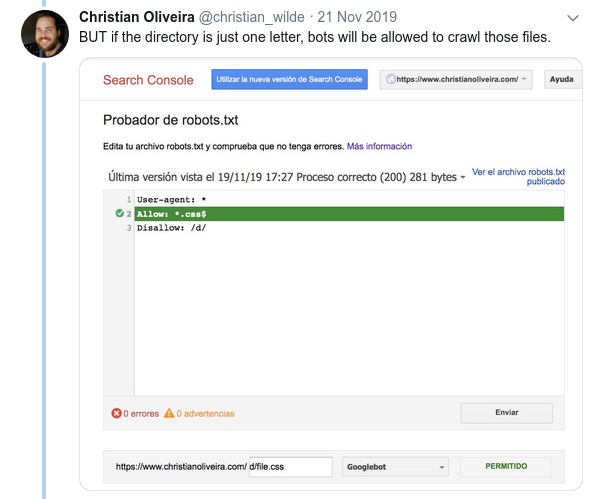
- Şimdi, aynı uzunlukta ve zıt davranışa sahip iki kuralınız olduğunda (biri taramaya izin verir ve diğeri buna izin vermez), daha az kısıtlayıcı olan kural uygulanır:
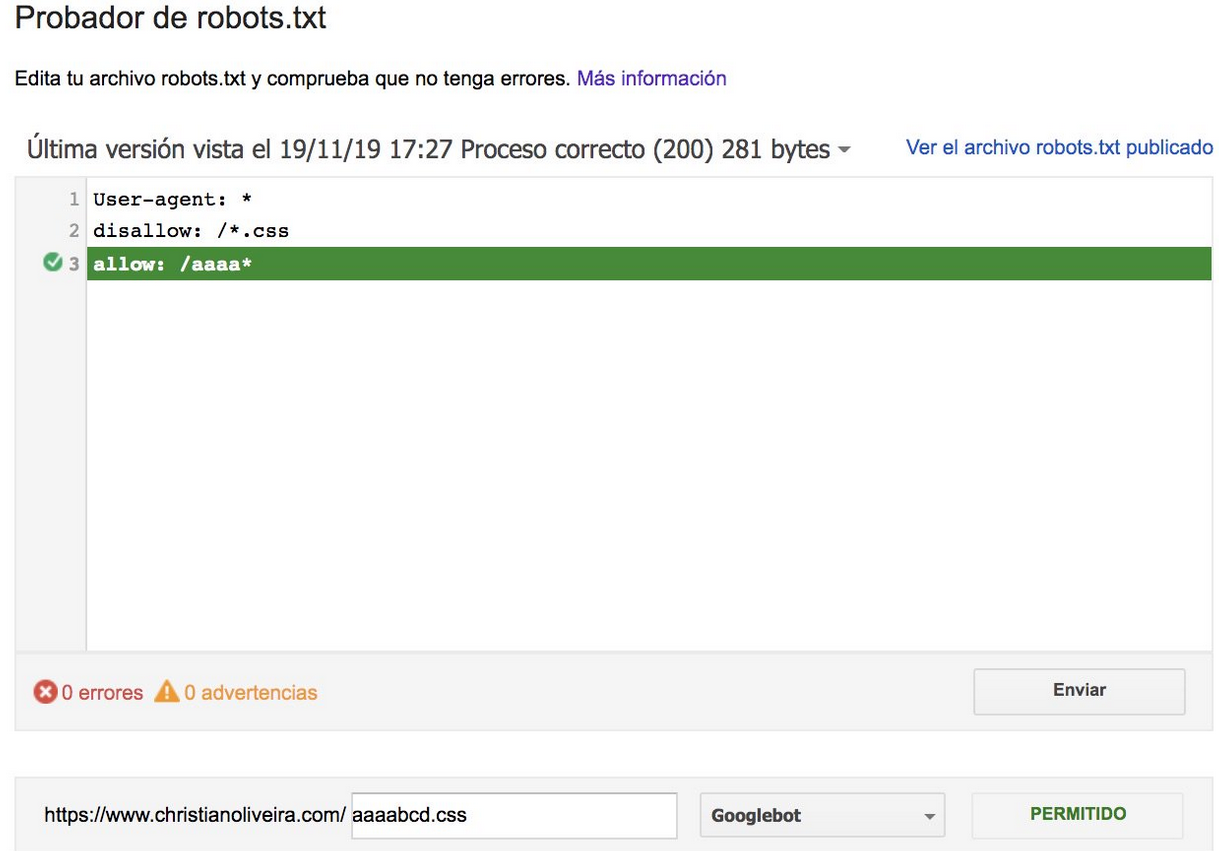
Daha fazla örnek için lütfen Google tarafından sağlanan robots.txt özelliklerini okuyun.
Robots.txt dosyanızı test etmek için araçlar
Robots.txt dosyanızı test etmek istiyorsanız, size yardımcı olabilecek birkaç araç ve kendi dosyanızı oluşturmak istiyorsanız birkaç github deposu vardır:
- damıtılmış
- Google, eski Google Arama Konsolundan robots.txt test aracını burada bıraktı
- Python'da
- C++'da
Örnek Sonuçlar: e-ticaret için bir Robots.txt dosyasının etkin kullanımı
Aşağıda, robots.txt dosyası olmayan bir Magento sitesiyle çalıştığımız bir durumu ekledim. Magento ve diğer CMS'de, Google'ın taramasını istemediğimiz dosyaları içeren yönetici sayfaları ve dizinleri vardır. Aşağıda, robots.txt dosyasına eklediğimiz bazı dizinlerin bir örneğini ekledik:
# # Genel Magento dizinleri İzin verme: / uygulama / İzin verme: / indirici / İzin verme: / hatalar / İzin verme: / içerir / İzin verme: / lib / İzin verme: / pkginfo / İzin verme: / kabuk / İzin verme: / var / # # Arama sayfasını ve optimize edilmemiş bağlantı kategorilerini dizine eklemeyin İzin verme: /catalog/product_compare/ İzin verme: /katalog/kategori/görünüm/ İzin verme: /katalog/ürün/görünüm/ İzin verme: /katalog/ürün/galeri/ İzin verme: /catalogsearch/
Taranması gerekmeyen çok sayıda sayfa, tarama bütçelerini etkiliyordu ve Googlebot, sitedeki tüm ürün sayfalarını tarayamıyordu.
Robots.txt'nin uygulandığı 25 Ekim'den sonra dizine eklenen sayfaların nasıl arttığını aşağıdaki görselde görebilirsiniz:
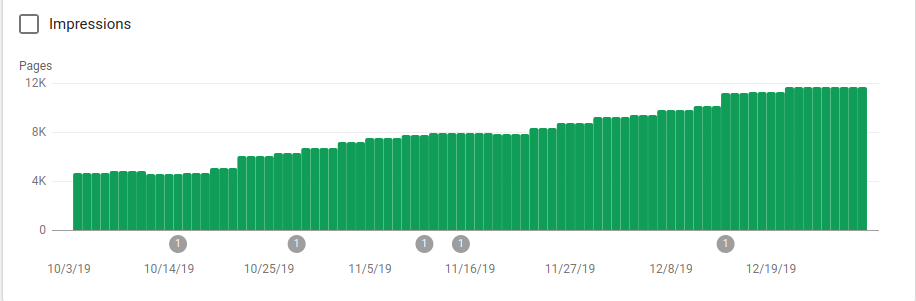
Robotlar, taranması amaçlanmayan birkaç dizini engellemenin yanı sıra, site haritalarına bir bağlantı da içeriyordu. Aşağıdaki ekran görüntüsünde, indekslenen sayfaların sayısının, hariç tutulan sayfalara göre nasıl arttığını görebilirsiniz:
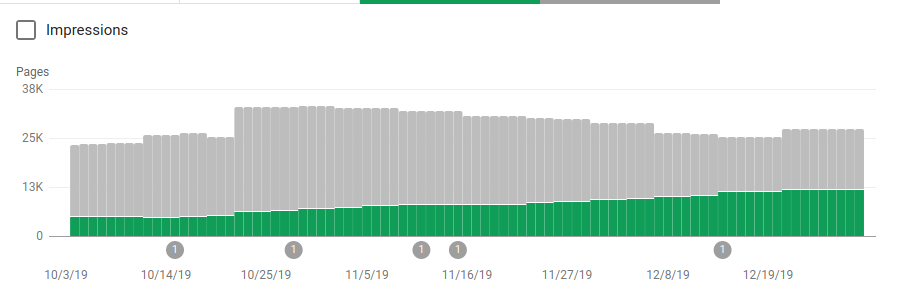
Yeşil çubuklarla gösterildiği gibi dizine eklenmiş geçerli sayfalarda olumlu bir eğilim ve gri çubuklarla temsil edilen hariç tutulan sayfalarda olumsuz bir eğilim vardır.
toparlamak
Robots.txt dosyasının önemi bazen hafife alınabilir ve bu gönderiden de görebileceğiniz gibi, bir tane oluştururken dikkate alınması gereken birçok ayrıntı vardır. Ancak yapılan işin karşılığını alıyor: Bir robots.txt dosyasını doğru bir şekilde kurmaktan elde edebileceğiniz bazı olumlu sonuçları gösterdim.