
Python'da Semantik Anahtar Kelime Kümeleme
Yayınlanan: 2021-04-19Dijital pazarlama mitleriyle dolu bir dünyada, ihtiyacımız olan şeyin günlük sorunlara pratik çözümler bulmak olduğuna inanıyoruz.
PEMAVOR'da, dijital pazarlama tutkunlarının ihtiyaçlarını karşılamak için her zaman uzmanlığımızı ve bilgimizi paylaşıyoruz. Bu nedenle, yatırım getirinizi artırmanıza yardımcı olmak için genellikle ücretsiz Python komut dosyaları yayınlarız.
Python ile SEO Anahtar Kelime Kümelememiz, yalnızca 50 satırdan daha az Python koduyla büyük SEO projeleri için yeni bilgiler edinmenin yolunu açtı.
Bu betiğin arkasındaki fikir, anahtar kelimeleri 'abartılı ücretler' ödemeden gruplandırmanıza izin vermekti… iyi, kim olduğunu biliyoruz…
Ancak bu senaryonun tek başına yeterli olmadığını anladık. Anahtar kelimelerinizi daha iyi anlayabilmeniz için başka bir komut dosyasına ihtiyaç vardır: Anahtar kelimeleri anlam ve anlamsal ilişkilere göre gruplayabilmeniz gerekir. ”
Şimdi SEO için Python'u bir adım daha ileri götürmenin zamanı geldi.
Tarama Verileri³
 Daha fazla bilgi edin
Daha fazla bilgi edinAnlamsal kümelemenin geleneksel yolu
Bildiğiniz gibi, semantik için geleneksel yöntem, word2vec modelleri oluşturmak, ardından anahtar kelimeleri Word Mover's Distance ile kümelemektir.
Ancak bu modelleri inşa etmek ve eğitmek çok zaman ve çaba gerektirir. Bu nedenle, size daha basit bir çözüm sunmak istiyoruz. 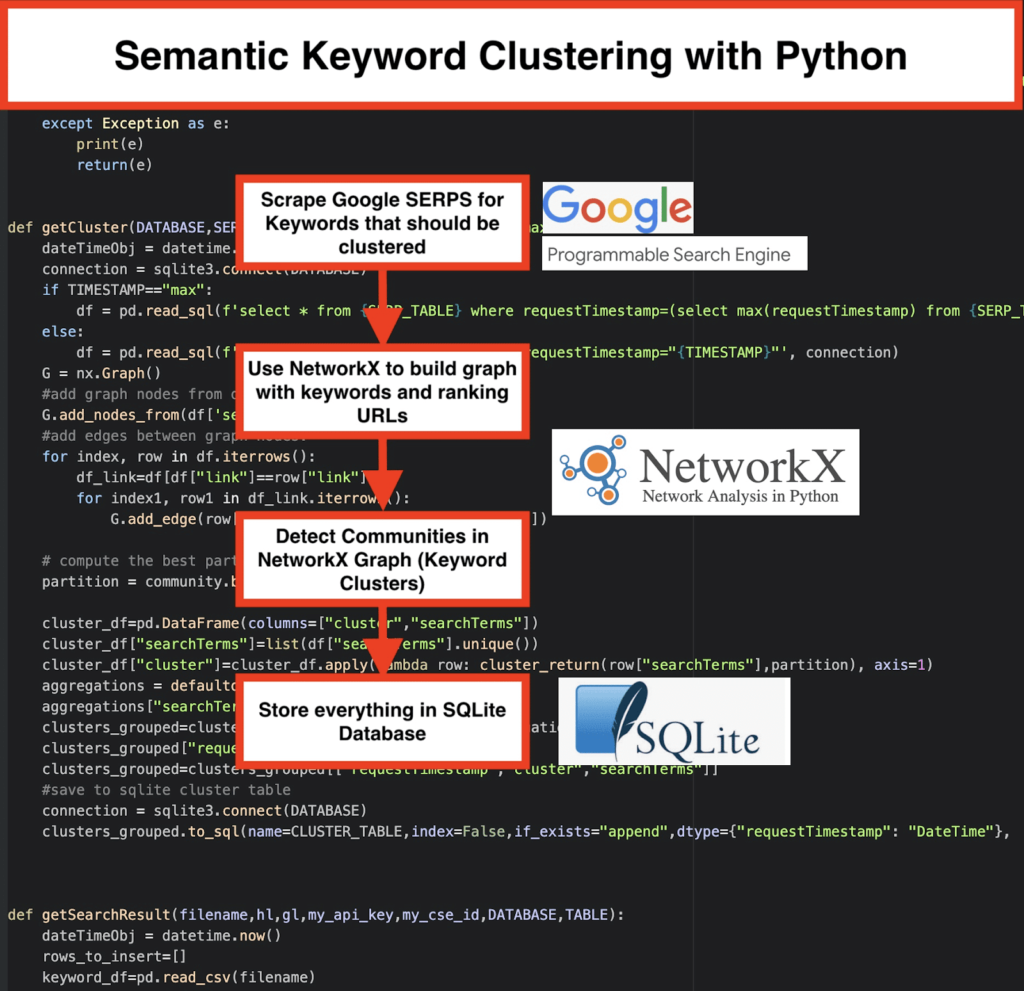
Google SERP sonuçları ve semantiği keşfetme
Google, en iyi arama sonuçlarını sunmak için NLP modellerini kullanır. Bu, Pandora'nın kutusunun açılması gibi ve biz bunu tam olarak bilmiyoruz.
Ancak, modellerimizi oluşturmak yerine, bu kutuyu anahtar kelimeleri anlam ve anlamlarına göre gruplamak için kullanabiliriz.
İşte bunu nasıl yapıyoruz:
️ İlk olarak, bir konu için bir anahtar kelime listesi oluşturun .
️ Ardından, her bir anahtar kelime için SERP verilerini kazıyın .
️ Ardından, sıralama sayfaları ve anahtar kelimeler arasındaki ilişki ile bir grafik oluşturulur .
️ Aynı sayfalar farklı anahtar kelimeler için sıralandığı sürece, birbirleriyle ilişkili oldukları anlamına gelir. Bu, anlamsal anahtar kelime kümeleri oluşturmanın arkasındaki temel ilkedir .
Python'da her şeyi bir araya getirme zamanı
Python Komut Dosyası aşağıdaki işlevleri sunar:
- Google'ın özel arama motorunu kullanarak, anahtar kelime listesi için SERP'leri indirin. Veriler bir SQLite veritabanına kaydedilir. Burada özel bir arama API'sı kurmalısınız.
- Ardından, günlük 100 isteklik ücretsiz kotadan yararlanın. Ancak beklemek istemiyorsanız veya büyük veri kümeleriniz varsa, 1000 görev başına 5 ABD doları tutarında ücretli bir plan da sunarlar.
- Aceleniz yoksa SQLite çözümlerini kullanmak daha iyidir – SERP sonuçları her çalıştırmada tabloya eklenecektir. (Ertesi gün tekrar kotanız olduğunda, 100 anahtar kelimelik yeni bir dizi alın.)
- Bu arada, bu değişkenleri Python Script'te ayarlamanız gerekir.
- CSV_FILE=”keywords.csv” => anahtar kelimelerinizi burada saklayın
- DİL = “tr”
- ÜLKE = “tr”
- API_KEY=”xxxxxxx”
- CSE_ID=”xxxxxxx”
-
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)SERP sonuçları veritabanına yazılacaktır. - Kümeleme, networkx ve topluluk algılama modülü tarafından yapılır. Veriler SQLite veritabanından alınır – kümeleme
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)ile çağrılır - Kümeleme sonuçları SQLite tablosunda bulunabilir – değiştirmediğiniz sürece, ad varsayılan olarak “keyword_clusters” şeklindedir.
Aşağıda, tam kodu göreceksiniz:
# Pemavor.com'dan Semantik Anahtar Kelime Kümeleme # Yazar: Stefan Neefischer ([email protected]) googleapiclient.discovery içe aktarma yapısından pandaları pd olarak içe aktar Levenshtein'i içe aktar tarih saatinden içe aktarma tarih saatinden fuzzywuzzy import fuzz'dan urllib.parse'den urlparse'ı içe aktar tld'den içe aktar get_tld ithalat json'u içe aktar pandaları pd olarak içe aktar numpy'yi np olarak içe aktar networkx'i nx olarak içe aktar ithalat topluluğu sqlite3'ü içe aktar ithalat matematik io'yu içe aktar koleksiyonlardan import defaultdict def cluster_return(searchTerm,partition): geri dönüş bölümü[searchTerm] def dil_algılama(str_lan): lan=langid.classify(str_lan) dönüş yolu[0] def Extract_domain(url, remove_http=Doğru): uri = urlparse(url) eğer remove_http: domain_name = f"{uri.netloc}" başka: domain_name = f"{uri.netloc}://{uri.netloc}" alan_adı döndür def Extract_mainDomain(url): res = get_tld(url, as_object=Doğru) dönüş res.fld tanım bulanık_ratio(str1,str2): fuzz.ratio(str1,str2) döndür def fuzzy_token_set_ratio(str1,str2): fuzz.token_set_ratio(str1,str2) döndür def google_search(search_term, api_key, cse_id,hl,gl, **kwargs): denemek: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=Yanlış) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute() dönüş res e olarak İstisna hariç: yazdır(e) dönüş(e) def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs): denemek: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=Yanlış) res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute() dönüş res e olarak İstisna hariç: yazdır(e) dönüş(e) def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"): dateTimeObj = datetime.now() bağlantı = sqlite3.connect(VERİTABANI) TIMESTAMP=="maks" ise: df = pd.read_sql(f'select * {SERP_TABLE}'dan burada requestTimestamp=({SERP_TABLE}'dan max(requestTimestamp) seçin)', bağlantı) başka: df = pd.read_sql(f'select * {SERP_TABLE}'dan burada requestTimestamp="{TIMESTAMP}"', bağlantı) G = nx.Graph() #dataframe sütunundan grafik düğümleri ekle G.add_nodes_from(df['searchTerms']) #grafik düğümleri arasına kenar ekle: dizin için, df.iterrows() içindeki satır: df_link=df[df["bağ"]==satır["bağ"]] index1, satır1 için df_link.iterrows(): G.add_edge(satır["aramaTermleri"], satır1['aramaTermleri']) # topluluk (kümeler) için en iyi bölümü hesaplayın bölüm = topluluk.best_partition(G) cluster_df=pd.DataFrame(sütunlar=["cluster","searchTerms"]) cluster_df["searchTerms"]=list(df["searchTerms"].unique()) cluster_df["cluster"]=cluster_df.apply(lambda satırı: cluster_return(satır["searchTerms"],partition), axis=1) toplamalar = defaultdict() toplamalar["searchTerms"]=' | '.katılmak clusters_grouped=cluster_df.groupby("cluster").agg(toplamalar).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]] #sqlite küme tablosuna kaydet bağlantı = sqlite3.connect(VERİTABANI) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=bağlantı) def getSearchResult(dosya adı,hl,gl,my_api_key,my_cse_id,VERİTABANI,TABLO): dateTimeObj = datetime.now() rows_to_insert=[] keyword_df=pd.read_csv(dosya adı) keywords=keyword_df.iloc[:,0].tolist() anahtar kelimelerde sorgu için: hl=="varsayılan" ise: sonuç = google_search_default_language(sorgu, my_api_key, my_cse_id,gl) başka: sonuç = google_search(sorgu, my_api_key, my_cse_id,hl,gl) sonuçta "öğeler" ve sonuçta "sorgular" varsa: aralıktaki konum için (0,len(sonuç["öğeler"])): sonuç["öğeler"][konum]["konum"]=konum+1 sonuç["items"][konum]["main_domain"]= extract_mainDomain(sonuç["items"][konum]["bağ"]) sonuç["items"][konum]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][konum]["title"],sorgu) sonuç["items"][konum]["snippet_matchScore_token"]=fuzzy_token_set_ratio(sonuç["items"][konum]["snippet"],sorgu) sonuç["öğeler"][konum]["title_matchScore_order"]=fuzzy_ratio(sonuç["itemler"][konum]["başlık"],sorgu) sonuç["items"][konum]["snippet_matchScore_order"]=fuzzy_ratio(sonuç["items"][konum]["snippet"],sorgu) sonuç["items"][konum]["snipped_language"]=language_detection(result["items"][konum]["snippet"]) aralıktaki konum için (0,len(sonuç["öğeler"])): rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl, "totalResults":result["sorgular"]["request"][0]["totalResults"],"link":result["items"][konum]["bağ"], "displayLink":result["items"][konum]["displayLink"],"main_domain":result["items"][konum]["main_domain"], "konum":sonuç["öğeler"][konum]["konum"],"parçacık":sonuç["öğeler"][konum]["parçacık"], "snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"], "snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][konum]["title"], "title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][position]["title_matchScore_token"], }) df=pd.DataFrame(rows_to_insert) #ser sonuçlarını sqlite veritabanına kaydet bağlantı = sqlite3.connect(VERİTABANI) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=bağlantı) ################################################# ################################################# ######################################### #Beni Oku: # ################################################# ################################################# ######################################### #1- Bir google özel arama motoru kurmanız gerekiyor. # # Lütfen API Anahtarını ve SearchId'yi sağlayın. # # Ayrıca SERP Sonuçlarını izlemek istediğiniz ülke ve dilinizi ayarlayın. # # Henüz bir API Anahtarınız ve Arama Kimliğiniz yoksa, # # bu sayfadaki Ön Koşullar bölümündeki adımları takip edebilirsiniz https://developers.google.com/custom-search/v1/overview#preconditions # # # #2- Sonuçları kaydetmek için kullanılacak veritabanı, serp tablosu ve küme tablosu adlarını da girmeniz gerekir. # # # #3- serp için kullanılacak anahtar kelimeleri içeren csv dosya adını veya tam yolunu girin # # # #4- Anahtar kelime kümeleme için, kümeleme için kullanılacak serp sonuçları için zaman damgasını girin. # # Son serp sonuçlarını kümelemeniz gerekiyorsa, zaman damgası için "max" girin. # # veya "2021-02-18 17:18:05.195321" gibi belirli bir zaman damgası girebilirsiniz # # # #5- Sqlite programı için DB tarayıcısı üzerinden sonuçlara göz atın # ################################################# ################################################# ######################################### serp için anahtar kelimeleri içeren #csv dosya adı CSV_FILE="keywords.csv" # dili belirle DİL = "tr" #detrmine şehir ÜLKE = "tr" #google özel arama json API anahtarı API_KEY="ANAHTARI BURAYA GİRİN" #Arama motoru kimliği ÖAM_ #sqlite veritabanı adı DATABASE="keywords.db" serp sonuçlarını kaydetmek için #table adı SERP_TABLE="keywords_serps" # anahtar kelimeler için serp'i çalıştırın getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) küme sonuçlarının kendisine kaydedeceği #tablo adı. CLUSTER_TABLE="keyword_clusters" #Belirli bir zaman damgası için kümeler oluşturmak istiyorsanız lütfen zaman damgasını girin #Son serp sonucu için kümeler oluşturmanız gerekiyorsa, "max" değeriyle gönderin #TIMESTAMP="2021-02-18 17:18:05.195321" TIMESTAMP = "maks" #Ağlara ve topluluk algoritmalarına göre anahtar kelime kümeleri çalıştırın getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,ZAMAN DAMGASI)

Google SERP sonuçları ve semantiği keşfetme
Anahtar kelimelerinizi anlamsal modellere dayanmadan anlamsal kümeler halinde gruplandırma kısayoluyla bu komut dosyasını beğendiğinizi umuyoruz. Bu modeller genellikle hem karmaşık hem de pahalı olduğundan, anlamsal özellikleri paylaşan anahtar kelimeleri belirlemenin başka yollarına bakmak önemlidir.
Anlamsal olarak alakalı anahtar kelimeleri bir arada ele alarak, bir konuyu daha iyi ele alabilir, sitenizdeki makaleleri birbirine daha iyi bağlayabilir ve belirli bir konu için web sitenizin sıralamasını artırabilirsiniz.