
Nedensel Etki Tahminlerinin Kalitesini Değerlendirmek
Yayınlanan: 2022-02-15CausalImpact, SEO denemelerinde kullanılan en popüler paketlerden biridir. Popülaritesi anlaşılabilir.
SEO denemesi, SEO'ların çalışmalarının değeri hakkında rapor vermeleri için heyecan verici bilgiler ve yollar sağlar.
Yine de, herhangi bir makine öğrenimi modelinin doğruluğu, kendisine verilen girdi bilgilerine bağlıdır.
Basitçe söylemek gerekirse, yanlış girdi yanlış tahmin verebilir.
Bu yazıda, CausalImpact'in ne kadar güvenilir (ve güvenilmez) olabileceğini göstereceğiz. Ayrıca deneylerinizin sonuçlarından nasıl daha emin olacağınızı da öğreneceğiz.
İlk olarak, CausalImpact'in nasıl çalıştığına dair kısa bir genel bakış sunacağız. Daha sonra CausalImpact tahminlerinin güvenilirliğini tartışacağız. Son olarak, kendi SEO deney sonuçlarınızı tahmin etmek için kullanılabilecek bir metodoloji öğreneceğiz.
Nedensel Etki Nedir ve Nasıl Çalışır?
CausalImpact, bir deneyin yokluğunda bir olayın etkisini tahmin etmek için Bayes istatistiklerini kullanan bir pakettir. Bu tahmine nedensel çıkarım denir.
Nedensel çıkarım, gözlemlenen bir değişikliğin belirli bir olaydan kaynaklanıp kaynaklanmadığını tahmin eder.
Genellikle SEO deneylerinin performansını değerlendirmek için kullanılır.
Örneğin, bir olayın tarihi verildiğinde, CausalImpact (CI), müdahaleden sonraki veri noktalarını tahmin etmek için müdahaleden önceki veri noktalarını kullanacaktır. Ardından, tahmini gözlemlenen verilerle karşılaştıracak ve belirli bir güven eşiği ile farkı tahmin edecektir.
Ayrıca, tahminleri daha doğru hale getirmek için kontrol grupları kullanılabilir.
Farklı parametrelerin de tahminin doğruluğu üzerinde etkisi olacaktır:
- Test verilerinin boyutu.
- Deneyden önceki dönemin uzunluğu.
- Karşılaştırılacak kontrol grubunun seçimi.
- Mevsimsellik hiperparametreleri.
- Yineleme sayısı.
Tüm bu parametreler, modele daha fazla bağlam sağlamaya ve güvenilirliğini artırmaya yardımcı olur.
Oncrawl BI
 Keşfetmek
KeşfetmekSEO Deneylerinin Doğruluğunu Değerlendirmek Neden Önemlidir?
Geçtiğimiz yıllarda birçok SEO denemesini analiz ettim ve bir şey beni etkiledi.
Çoğu kez, aynı test setlerinde ve müdahale tarihlerinde farklı kontrol grupları ve zaman çerçeveleri kullanmak farklı sonuçlar verdi.
Örnek olarak, aşağıda aynı olaydan iki sonuç verilmiştir.
İlki istatistiksel olarak anlamlı bir düşüş döndürdü. 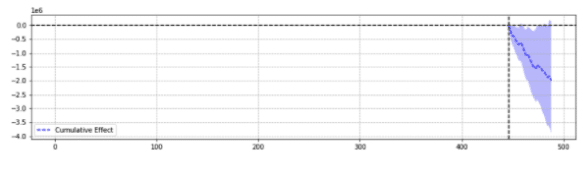
İkincisi istatistiksel olarak anlamlı değildi. 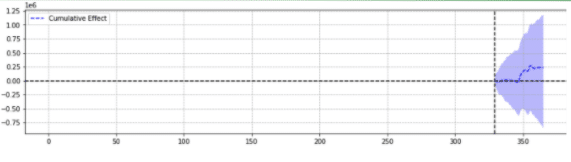
Basitçe söylemek gerekirse, aynı olay için seçilen parametrelere göre farklı sonuçlar döndürüldü.
Hangi tahminin doğru olduğunu merak etmek gerekiyor.
Sonuç olarak, "istatistiksel olarak anlamlı"nın tahminlerimize olan güveni artırması gerekmiyor mu?
Tanımlar
SEO deneylerinin dünyasını daha iyi anlamak için okuyucunun SEO deneylerinin temel kavramlarının farkında olması gerekir:
- Deney : Bir hipotezi test etmek için gerçekleştirilen bir prosedür. Nedensel çıkarım durumunda, belirli bir başlangıç tarihi vardır.
- Test grubu : bir değişikliğin uygulandığı verilerin bir alt kümesi. Tüm bir web sitesi veya sitenin bir kısmı olabilir.
- Kontrol grubu : hiçbir değişiklik uygulanmayan verilerin bir alt kümesi. Bir veya birden fazla kontrol grubunuz olabilir. Bu, aynı sektördeki ayrı bir site veya aynı sitenin farklı bir bölümü olabilir.
Aşağıdaki örnek bu kavramları açıklamaya yardımcı olacaktır:
Başlığın (deneyin) değiştirilmesi, beş şehirdeki (test grubu) ürün sayfalarının organik TO'sunu %1 (hipotez) oranında artırmalıdır. Tahminler, diğer tüm şehirlerde (kontrol grubu) değişmeyen bir başlık kullanılarak geliştirilecektir.
Doğru SEO Deneyi Tahmininin Temelleri
- Basit olması için, deneylerin doğruluğunu nasıl geliştireceklerini öğrenen SEO uzmanları için birkaç ilginç bilgi derledim:
- CausalImpact'teki bazı girdiler, istatistiksel olarak anlamlı olsa bile yanlış tahminler verecektir. Buna “yanlış pozitifler” ve “yanlış negatifler” diyoruz.
- Bir test setine karşı hangi kontrolün kullanılacağını yöneten genel bir kural yoktur. Belirli bir test seti için kullanılacak en iyi kontrol verilerini tanımlamak için bir deney gereklidir.
- CausalImpact'i doğru kontrol ve doğru uzunluktaki ön dönem verileriyle kullanmak, ortalama hata %0,1 kadar düşük olmakla birlikte çok kesin olabilir.
- Alternatif olarak, CausalImpact'i yanlış kontrolle kullanmak, güçlü bir hata oranına yol açabilir. Kişisel deneyler, aslında hiçbir değişiklik olmamasına rağmen, istatistiksel olarak %20'ye varan önemli farklılıklar gösterdi.
- Her şey test edilemez. Bazı test grupları neredeyse hiçbir zaman doğru tahminler döndürmez.
- Kontrol grupları olan veya olmayan deneyler, müdahaleden önce farklı uzunluklarda verilere ihtiyaç duyar.
Tüm Test Grupları Doğru Tahminler Vermeyecek
Bazı test grupları her zaman yanlış tahminler verir. Deneme amaçlı kullanılmamalıdırlar.
Büyük anormal trafik varyasyonlarına sahip test grupları genellikle güvenilmez sonuçlar verir.
Örneğin aynı yıl bir web sitesi site geçişi yaşamış, covid pandemisinden etkilenmiş ve sitenin bir kısmı teknik bir hata nedeniyle 2 hafta boyunca “noindexed” edilmiştir. O sitede deneyler yapmak güvenilmez sonuçlar verecektir.
Yukarıdaki çıkarımlar, aşağıda açıklanan metodoloji kullanılarak yapılan kapsamlı bir dizi test yoluyla toplanmıştır.
Kontrol Grupları Kullanılmadığında
- Basit bir ön post yerine bir kontrol kullanmak, tahminin kesinliğini 18 kata kadar artırabilir.
- Önceki 16 aylık verileri kullanmak, 3 yıllık verileri kullanmak kadar kesindi.
Kontrol Gruplarını Kullanırken
- Doğru kontrolü kullanmak çoğu zaman birden fazla kontrol kullanmaktan daha iyidir. Ancak, tek bir kontrol, kontrol trafiğinin çok değiştiği durumlarda hatalı tahmin riskini artırır.
- Doğru kontrolün seçilmesi hassasiyeti 10 kat artırabilir (örneğin, biri +%3,1 ve diğeri +%4,1 rapor ederken aslında +%3).
- Test verileri ve kontrol verileri arasındaki en bağlantılı trafik kalıpları, mutlaka daha iyi tahminler anlamına gelmez.
- Önceki 16 aylık verileri kullanmak, 3 yıllık verileri kullanmak kadar kesin DEĞİLDİR.
Deneylerden Önce Verilerin Uzunluğuna Dikkat Edin
İlginç bir şekilde, kontrol gruplarıyla deney yaparken, 16 aylık veriyi kullanmak çok yoğun bir hata oranına neden olabilir.
Aslında, hatalar, gerçek bir değişiklik olmadığında trafikte 3 kat artış tahmin etmek kadar büyük olabilir.
Ancak, 3 yıllık verilerin kullanılması bu hata oranını ortadan kaldırdı. Bu, hata oranının 16 aydan 36 aya çıkarılarak bu hata oranının artırılmadığı basit ön-son deneylerle tezat oluşturuyor.
Bu, kontrolleri kullanmanın kötü olduğu anlamına gelmez. Tam tersi.
Sadece kontrol eklemenin tahminleri nasıl etkilediğini gösterir.

Kontrol grubunda büyük farklılıklar olduğunda durum böyledir.
Bu paket servis, özellikle geçen yıl anormal trafik değişiklikleri (kritik teknik hata, COVID pandemisi vb.) olan web siteleri için önemlidir.
Nedensel Etki Tahmini Nasıl Değerlendirilir?
Şimdi, CausalImpact kitaplığında yerleşik bir doğruluk puanı yok. Yani, başka türlü anlaşılmalıdır.
Diğer makine öğrenimi modellerinin tahminlerinin doğruluğunu nasıl tahmin ettiğine bakılabilir ve Kareler Toplamının (SSE) çok yaygın bir ölçüm olduğunu fark edebilirsiniz.
Hataların kareleri toplamı veya kalan kareler toplamı, beklentiler (yi) ile gerçek sonuçlar (f(xi)), karesi arasındaki tüm (n) farkların toplamını hesaplar. 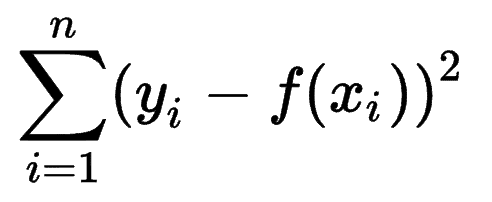
SSE ne kadar düşükse, sonuç o kadar iyi olur.
Buradaki zorluk, SEO trafiğiyle ilgili önceden yapılan denemelerde gerçek sonuçların olmamasıdır.
Sitede herhangi bir değişiklik yapılmamasına rağmen, kontrolünüz dışında bazı değişiklikler olmuş olabilir (örn. Google Algoritma güncellemesi, yeni rakip vb.). SEO trafiği de sabit bir sayıya göre değişmez, ancak kademeli olarak yukarı ve aşağı değişir.
SEO uzmanları, zorluğun nasıl üstesinden gelineceğini merak edebilir.
Sahte Varyasyonlarla Tanışın
Bir olayın neden olduğu varyasyonun boyutundan emin olmak için, deneyci zaman içinde farklı noktalarda sabit varyasyonlar sunabilir ve CausalImpact'in değişikliği başarılı bir şekilde tahmin edip etmediğini görebilir.
Daha da iyisi, SEO uzmanı farklı test ve kontrol grupları için süreci tekrarlayabilir.
Python kullanılarak, veriye farklı müdahale tarihlerinde sonraki dönem için sabit varyasyonlar getirildi.
Daha sonra, CausalImpact tarafından bildirilen varyasyon ile tanıtılan varyasyon arasında kareler toplamı tahmin edildi.
Fikir şöyle devam ediyor:
- Bir test ve kontrol verisi seçin.
- Farklı tarihlerde gerçek verilere sahte müdahaleler yapın (örn. %5 artış).
- CausalImpact tahminlerini, tanıtılan varyasyonların her biriyle karşılaştırın.
- Kareler Hatalarının Toplamını (SSE) hesaplayın.
- Birden fazla kontrolle 1. adımı tekrarlayın.
- Gerçek dünya deneyleri için en küçük SSE'ye sahip kontrolü seçin
Metodoloji
Aşağıdaki metodolojiyle, farklı zamanlarda hangi kontrolün en iyi ve en kötü hata oranlarına sahip olduğunu belirlemek için kullanabileceğim bir tablo oluşturdum.
İlk olarak, bir test ve kontrol verisi seçin ve -%50 ile %50 arasındaki varyasyonları tanıtın.
Ardından, CausalImpact'i (CI) çalıştırın ve CI tarafından bildirilen varyasyonları, gerçekte tanıttığınız varyasyondan çıkarın.
Daha sonra bu farkların karelerini hesaplayın ve tüm değerleri toplayın.
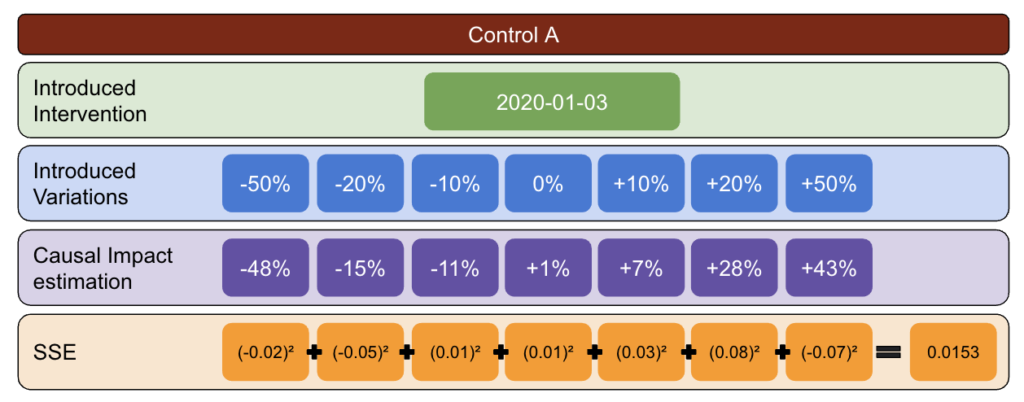
Ardından, belirli bir tarihteki gerçek bir varyasyonun neden olduğu sapma riskini azaltmak için aynı işlemi farklı tarihlerde tekrarlayın.
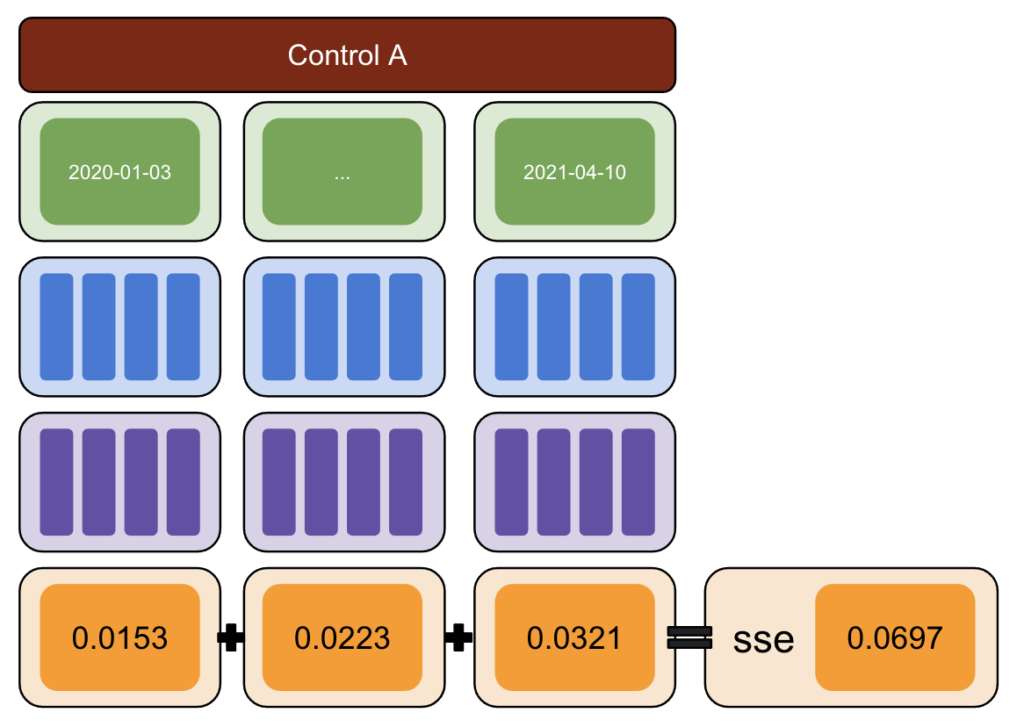
Yine, birden fazla kontrol grubuyla tekrarlayın.
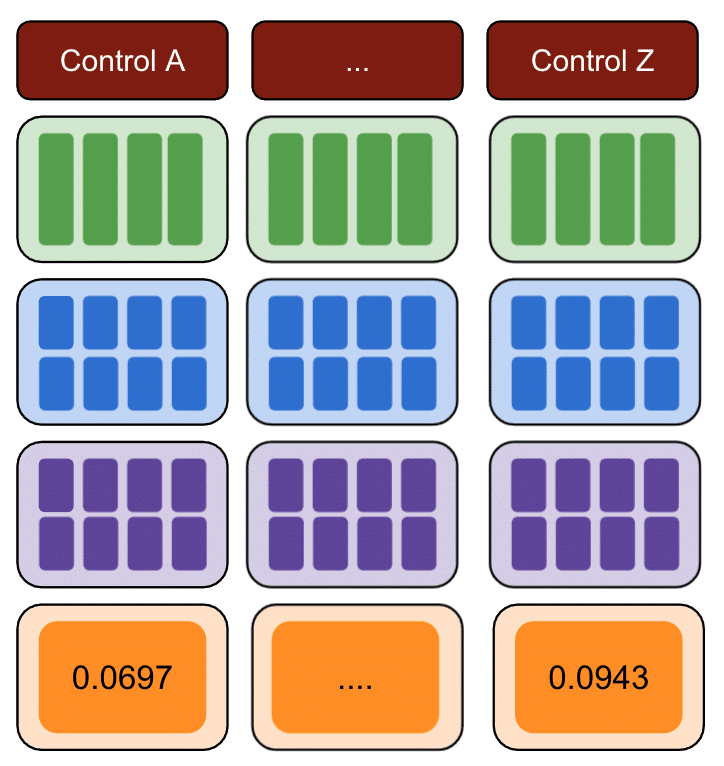
Son olarak, en küçük kareler toplamı hatalarına sahip kontrol, test verileriniz için kullanılacak en iyi kontrol grubudur.
Her bir test veriniz için adımların her birini tekrarlarsanız, sonuç değişecektir.
Sonuç tablosunda her satır bir kontrol grubunu, her sütun bir test grubunu temsil eder. İçindeki veriler SSE'dir.
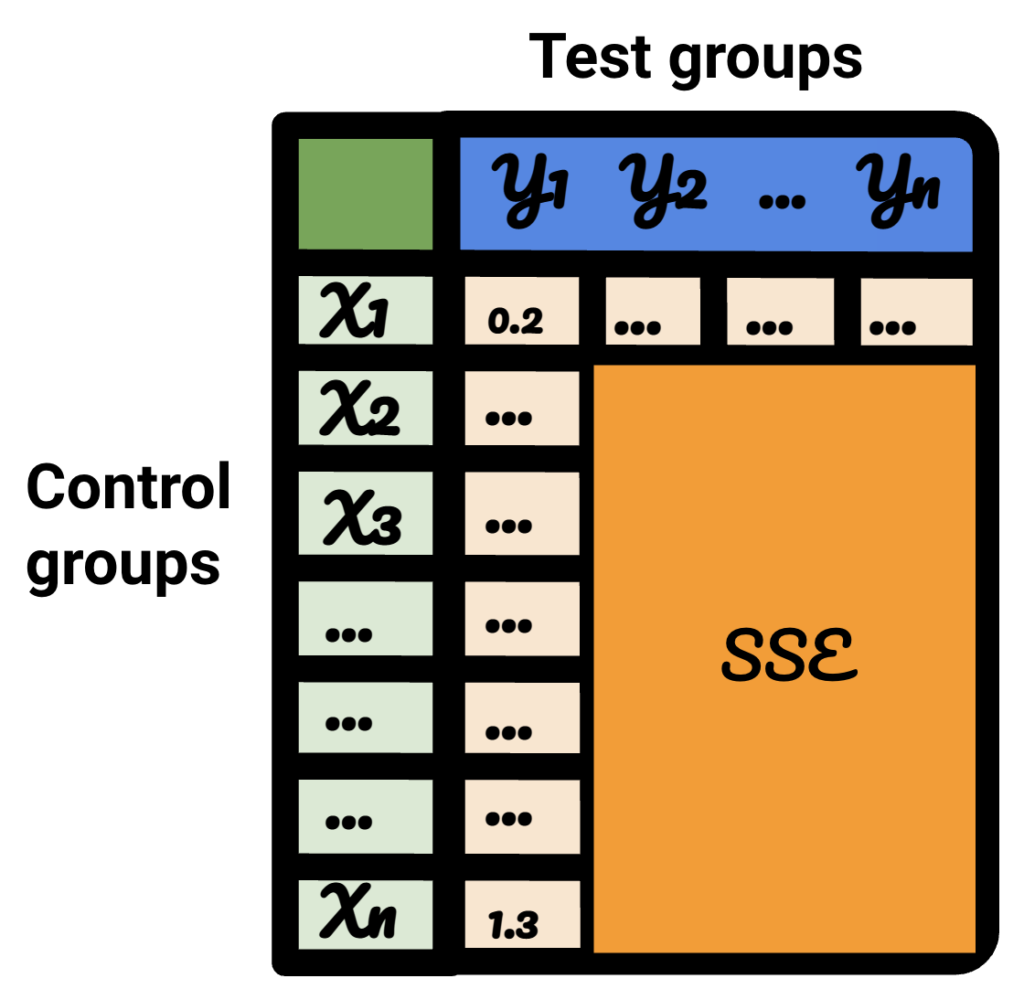
Bu tabloyu sıralayarak, artık test gruplarının her biri için bunun için en iyi kontrol grubunu seçebileceğimden eminim.
Kontrol Gruplarını Kullanmalı mıyız, Kullanmamalı mıyız?
Kanıtlar, kontrol gruplarının kullanılmasının, basit ön yazıdan daha iyi tahminlere sahip olmaya yardımcı olduğunu göstermektedir.
Ancak bu ancak doğru kontrol grubunu seçersek doğrudur.
Tahmin Süresi Ne Kadar Olmalıdır?
Bunun cevabı, seçtiğimiz kontrollere bağlıdır.
Bir kontrol kullanılmadığında, 16 ay önceki deney yeterli görünüyor.
Bir kontrol kullanırken sadece 16 ay kullanmak büyük hata oranlarına neden olabilir. 3 yıl kullanmak yanlış yorumlama riskini azaltmaya yardımcı olur.
1 Kontrol veya Çoklu Kontroller Kullanmalı mıyız?
Bu sorunun cevabı test verilerine bağlıdır.
Çok kararlı test verileri, çoklu kontrollerle karşılaştırıldığında iyi performans gösterebilir. Bu durumda, bu iyidir çünkü çok fazla kontrol kullanmak, modelin kontrollerden birindeki beklenmedik dalgalanmalardan daha az etkilenmesini sağlar.
Diğer veri kümelerinde birden fazla kontrol kullanmak, modeli tek bir kontrol kullanmaktan 10-20 kat daha az hassas hale getirebilir.
SEO Topluluğunda İlginç Çalışmalar
CausalImpact, SEO testi için kullanılabilecek tek kitaplık değildir ve yukarıdaki metodoloji, doğruluğunu test etmek için tek çözüm değildir.
Alternatif çözümler öğrenmek için SEO topluluğundaki insanlar tarafından paylaşılan inanılmaz makalelerden bazılarını okuyun.
İlk olarak, Andrea Volpini, Nedensel Etki Analizini kullanarak SEO etkinliğini ölçmek üzerine ilginç bir yazı yazdı.
Ardından Daniel Heredia, Prophet ve Python ile SEO trafiğini tahmin etmek için Facebook'un Prophet paketini ele aldı.
Peygamber kütüphanesi deneylerden ziyade tahmin için daha uygun olsa da, kehanet dünyasını sağlam bir şekilde kavramak için çeşitli kütüphaneleri öğrenmeye değer.
Son olarak, Sandy Lee'nin Brighton SEO'da SEO Testi için Veri Bilimi hakkındaki görüşlerini paylaştığı ve SEO testinin bazı tuzaklarını gündeme getirdiği sunumundan çok memnun kaldım.
SEO Deneyleri Yaparken Dikkat Edilmesi Gerekenler
- Üçüncü taraf SEO bölünmüş test araçları harikadır ancak yanlış da olabilir. Çözümünüzü seçerken dikkatli olun.
- Geçmişte bunun hakkında yazmış olsam da, sunucu tarafı olmadıkça Google Etiket Yöneticisi ile SEO bölünmüş testi deneyleri yapamazsınız. En iyi yol, CDN'ler aracılığıyla dağıtmaktır.
- Test ederken cesur olun. Küçük değişiklikler genellikle CausalImpact tarafından algılanmaz.
- SEO testi her zaman ilk tercihiniz olmamalıdır.
- Başlık etiketleri gibi daha küçük değişiklikleri test etmenin alternatifleri vardır. Google Ads A/B testleri veya platformda A/B testleri. Gerçek A/B testleri, SEO bölünmüş testinden daha doğrudur ve genellikle başlıklarınızın kalitesi hakkında daha fazla bilgi sağlar.
Tekrarlanabilir Sonuçlar
Bu derste, kodlama bilmenin yükü olmadan SEO deneylerinin doğruluğunu nasıl geliştirebileceğimize odaklanmak istedim. Ayrıca, verilerin kaynağı değişebilir ve her site farklıdır.
Bu nedenle, bu içeriği oluşturmak için kullandığım Python kodu bu makalenin kapsamında değildi.
Ancak mantıkla yukarıdaki deneyleri çoğaltabilirsiniz.
Çözüm
Bu makaleden alacağınız tek bir çıkarımınız olsaydı, o da CausalImpact analizinin çok doğru olabileceği, ancak her zaman çok uzak olabileceği olurdu.
Bu paketi kullanmak isteyen SEO'ların neyle uğraştıklarını anlamaları çok önemlidir. Kendi yolculuğumun sonucu, önce giriş verilerinde modelin doğruluğunu test etmeden CausalImpact'e güvenmemem oldu.