
Web tarayıcısına giriş
Yayınlanan: 2016-03-08İnsanlarla ne yaptığım ve SEO'nun ne olduğu hakkında konuştuğumda, genellikle oldukça hızlı bir şekilde anlıyorlar veya yaptıkları gibi davranıyorlar. İyi bir web sitesi yapısı, iyi bir içerik, iyi destekleyici geri bağlantılar. Ama bazen, biraz daha teknik hale geliyor ve sonunda web sitenizi tarayan arama motorlarından bahsediyorum ve genellikle onları kaybediyorum…
Bir web sitesi neden taranır?
Web taraması, interneti ve her bir web sitesinin birbirine nasıl bağlandığını haritalamakla başladı. Ayrıca, yeni çevrimiçi sayfaları keşfetmek ve dizine eklemek için arama motorları tarafından da kullanıldı. Web tarayıcıları, bir web sitesini test ederek ve herhangi bir sorun tespit edilip edilmediğini analiz ederek web sitesinin güvenlik açığını test etmek için de kullanıldı.
Artık size bilgi sağlamak için web sitenizi tarayan araçlar bulabilirsiniz. Örneğin, OnCrawl, içeriğiniz ve site içi SEO veya bir sayfaya işaret eden tüm bağlantılarla ilgili öngörüler sağlayan Majestic ile ilgili veriler sağlar.
Tarayıcılar, daha sonra belgeleri sınıflandırmak ve toplanan veriler hakkında bilgi sağlamak için kullanılabilecek ve işlenebilecek bilgileri toplamak için kullanılır.
Bir tarayıcı oluşturmaya biraz kod bilen herkes erişebilir. Ancak verimli bir tarayıcı yapmak daha zordur ve zaman alır.
O nasıl çalışır ?
Bir web sitesini veya web'i taramak için önce bir giriş noktasına ihtiyacınız vardır. Robotların web sitenizin var olduğunu bilmeleri gerekir ki gelip bakabilsinler. O günlerde, web sitenizin çevrimiçi olduğunu söylemek için web sitenizi arama motorlarına gönderirdiniz. Artık web sitenize kolayca birkaç bağlantı oluşturabilirsiniz ve işte bu döngüdesiniz!
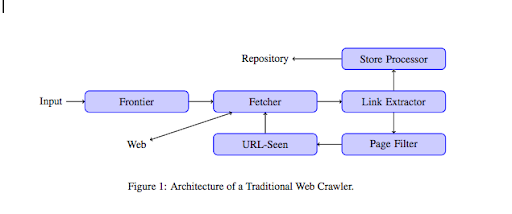
Bir tarayıcı web sitenize ulaştığında, tüm içeriğinizi satır satır analiz eder ve sahip olduğunuz dahili veya harici bağlantıların her birini takip eder. Ve böylece, daha fazla bağlantı olmayan bir sayfaya gelene veya 404, 403, 500, 503 gibi hatalarla karşılaşana kadar.
Daha teknik bir bakış açısından, bir tarayıcı bir URL çekirdeği (veya listesi) ile çalışır. Bu, bir sayfanın içeriğini alacak olan bir Getiriciye iletilir. Bu içerik daha sonra HTML'yi ayrıştıracak ve tüm bağlantıları çıkaracak bir Bağlantı çıkarıcıya taşınır. Bu bağlantılar, adından da anlaşılacağı gibi, bunları depolayacak olan bir Mağaza işlemcisine gönderilir. Bu URL'ler ayrıca, tüm ilginç bağlantıları URL'de görülen bir modüle gönderecek bir Sayfa filtresinden geçer. Bu modül, URL'nin daha önce görülüp görülmediğini tespit eder. Değilse, sayfanın içeriğini alacak olan Getiriciye gönderilir vb.
Flash gibi bazı içeriklerin örümceklerin taramasının imkansız olduğunu unutmayın. Javascript artık GoogleBot tarafından düzgün bir şekilde taranıyor, ancak arada sırada hiçbirini taramaz. Görseller, Google'ın teknik olarak tarayabileceği içerik değildir, ancak onları anlamaya başlayacak kadar akıllı hale geldi!
Robotlara aksi söylenmezse her şeyi tararlar. Robots.txt dosyasının çok kullanışlı hale geldiği yer burasıdır. Tarayıcılara (her tarayıcıya özel olabilir, örneğin GoogleBot veya MSN Bot – botlar hakkında daha fazla bilgiyi burada bulabilirsiniz) hangi sayfaları tarayamayacaklarını söyler. Örneğin, fasetleri kullanan bir navigasyonunuz olduğunu varsayalım, robotların çok az katma değeri olduğundan ve tarama bütçesini kullanacaklarından hepsini taramasını istemeyebilirsiniz. Bu basit çizgiyi kullanmak, herhangi bir robotun onu taramasını önlemenize yardımcı olacaktır.
Kullanıcı aracısı: *
İzin verme: /klasör-a/
Bu, tüm robotlara A klasörünü taramamalarını söyler.
Kullanıcı aracısı: GoogleBot
İzin verme: /repertuar-b/
Öte yandan bu, yalnızca Google Bot'un B klasörünü tarayamayacağını belirtir.
Ayrıca, robotlara rel=”nofollow” etiketini kullanarak belirli bir bağlantıyı takip etmemelerini söyleyen HTML'deki göstergeyi de kullanabilirsiniz. Bazı testler, bir bağlantıda rel=”nofollow” etiketinin kullanılmasının bile Googlebot'un onu izlemesini engellemediğini göstermiştir. Bu, amacına aykırıdır, ancak diğer durumlarda faydalı olacaktır.
[Örnek Olay] Googlebot için web sitesi taranabilirliğini geliştirerek görünürlüğü artırın
 Örnek olayı okuyun
Örnek olayı okuyun
Tarama bütçesinden bahsettiniz ama nedir?
Diyelim ki arama motorları tarafından keşfedilen bir web siteniz var. Web sitenizde herhangi bir güncelleme yapıp yapmadığınızı ve yeni sayfalar oluşturup oluşturmadığınızı düzenli olarak görmeye gelirler.
Her web sitesinin, web sitenizin sahip olduğu sayfa sayısı ve akıl sağlığı (örneğin, çok fazla hatası varsa) gibi çeşitli faktörlere bağlı olarak kendi tarama bütçesi vardır. Search Console'a giriş yaparak tarama bütçeniz hakkında kolayca fikir sahibi olabilirsiniz.
Tarama bütçeniz, bir robotun her ziyaret için web sitenizde taradığı sayfa sayısını sabitler. Web sitenizdeki sayfaların sayısıyla orantılı olarak bağlantılıdır ve zaten taramıştır. Bazı sayfalar, özellikle düzenli olarak güncelleniyorsa veya önemli sayfalardan bağlantı veriliyorsa, diğerlerinden daha sık taranır.
Örneğin eviniz, çok sık taranacak ana giriş noktanızdır. Bir blogunuz veya kategori sayfanız varsa, ana navigasyona bağlıysa, bunlar genellikle taranır. Bir blog da düzenli olarak güncellendiğinden sık sık taranır. Bir blog gönderisi ilk yayınlandığında sık sık taranabilir, ancak birkaç ay sonra muhtemelen güncellenmez.
Bir sayfa ne kadar sık taranırsa, robot diğer sayfalara kıyasla o kadar önemli olduğunu düşünür. Bu, tarama bütçenizi optimize etmeye başlamanız gereken zamandır.
Tarama bütçenizi optimize etme
Bütçenizi optimize etmek ve en önemli sayfalarınızın hak ettikleri ilgiyi görmesini sağlamak için sunucu günlüklerinizi analiz edebilir ve web sitenizin nasıl tarandığına bakabilirsiniz:
- En iyi sayfalarınız ne sıklıkla taranıyor?
- Daha az önemli sayfaların diğerlerinden daha önemli tarandığını görebiliyor musunuz?
- Robotlar web sitenizi tararken genellikle 4xx veya 5xx hatası alıyor mu?
- Robotlar herhangi bir örümcek kapanıyla karşılaşır mı? (Matthew Henry onlar hakkında harika bir makale yazdı)
Günlüklerinizi analiz ederek, daha az önemli olduğunu düşündüğünüz sayfaların çok fazla tarandığını göreceksiniz. Daha sonra dahili bağlantı yapınızı daha derine inmeniz gerekir. Taranıyorsa, ona işaret eden çok sayıda bağlantı olmalıdır.
OnCrawl ile tüm bu hataları (4xx ve 5xx) düzeltmeye de çalışabilirsiniz. Kullanıcı deneyiminin yanı sıra taranabilirliği de geliştirecek, bu bir kazan-kazan durumu.
Tarama VS Kazıma?
Tarama ve kazıma, farklı amaçlar için kullanılan iki farklı şeydir. Bir web sitesini taramak, bir sayfaya inmek ve içeriği taradığınızda bulduğunuz bağlantıları takip etmektir. Bir tarayıcı daha sonra başka bir sayfaya geçer ve bu böyle devam eder.
Öte yandan kazıma, bir sayfayı taramak ve sayfadan belirli verileri toplamaktır: başlık etiketi, meta açıklama, h1 etiketi veya web sitenizin belirli bir alanı, bu tür bir fiyat listesi. Sıyırıcılar genellikle “insan” gibi davranırlar, robots.txt dosyasındaki, formlardaki dosyadaki tüm kuralları görmezden gelirler ve algılanmamak için bir tarayıcı kullanıcı aracısı kullanırlar.
Arama motoru tarayıcıları genellikle sıyırıcı görevi görür ve sıralama algoritmaları için işlemek için veri toplamaları gerekir. Sıyırıcıya kıyasla belirli verileri aramazlar, sadece sayfadaki tüm mevcut verileri ve hatta daha fazlasını kullanırlar (yükleme süresi bir sayfadan alamayacağınız bir şeydir). Arama motoru tarayıcıları, bir web sitesinin sahibinin web sitesini en son ne zaman ziyaret ettiğini bilmesi için kendilerini her zaman tarayıcı olarak tanımlar. Bu, gerçek kullanıcı etkinliğini izlediğinizde çok yardımcı olabilir.
Artık tarama, nasıl çalıştığı ve neden önemli olduğu hakkında biraz daha bilgi sahibi olduğunuza göre, bir sonraki adım sunucu günlüklerini analiz etmeye başlamaktır. Bu size robotların web sitenizle nasıl etkileşime girdiği, hangi sayfaları sıklıkla ziyaret ettikleri ve web sitenizi ziyaret ederken ne kadar hatayla karşılaştıklarına dair derin bilgiler sağlayacaktır.
Web tarayıcısı hakkında daha fazla teknik ve tarihsel bilgi için “Web Tarayıcılarının Kısa Tarihi”ni okuyabilirsiniz.