
Python ile URL konumuna göre markasız organik trafik geliri nasıl tahmin edilir?
Yayınlanan: 2022-05-24SEO tahmini nedir?
SEO tahmini veya organik trafik tahmini, sitenizin gelecekteki organik trafiğini, SEO gelirini ve SEO yatırım getirisini tahmin etmek için kendi sitenizin verilerini veya üçüncü taraf verilerini kullanma sürecidir. Bu tahmin, verilerimize dayalı olarak birçok farklı yöntem kullanılarak hesaplanabilir.
Bu öğreticide, URL konumlarımıza ve mevcut gelirlerine dayalı olarak markasız organik gelirimizi ve markasız organik trafiğimizi tahmin etmek istiyoruz. Bu, SEO uzmanları olarak diğer paydaşlardan daha fazla katılım elde etmemize yardımcı olabilir: artan aylık, üç aylık veya yıllık bütçeden ürün ve geliştirme ekibinden daha fazla çalışma saatine kadar.
Bu öğreticinin yalnızca markasız organik trafik için geçerli olmadığını unutmayın; Birkaç değişiklik yaparak ve Python'u bilerek, onu hedef sayfalarınızın trafiğini tahmin etmek için kullanabilirsiniz.
Sonuç olarak aşağıdaki görseldeki gibi bir Google Sheet üretebiliriz.
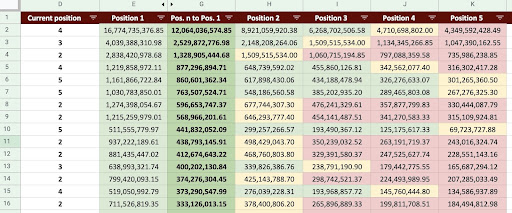
Google E-Tablolar Resmi
Markasız SEO trafik tahmini
Tanıtımı okuduktan sonra sorabileceğiniz ilk soru “Markasız organik trafiği neden hesaplamalısınız?” olacaktır.
Amazon gibi bir şirket düşünelim. Bir kitap veya maske satın almak istediğinizde, "maske amazon satın al" aramanız yeterlidir.
Markalar çoğu zaman akıllara gelir ve bir şey satın almak istediğinizde tercihiniz ihtiyacınız olan şeyleri bu firmalardan almaktır. Her sektörde, kullanıcıların Google aramalarındaki davranışlarını etkileyen markalı şirketler vardır.
Amazon'un Google Arama Konsolu (GSC) verilerini kontrol edecek olsaydık, büyük olasılıkla markalı sorgulardan çok fazla trafik aldığını ve çoğu zaman markalı sorguların ilk sonucunun o markanın sitesi olduğunu görürdük.
Benim gibi bir SEO uzmanı olarak, muhtemelen birçok kez “SEO'muza yalnızca markamız yardımcı olur!” sözünü duymuşsunuzdur. “Hayır, durum bu değil” diyip marka dışı sorguların trafiğini ve gelirini nasıl gösterebiliriz?
Bunu kanıtlamak daha da karmaşık çünkü Google'ın algoritmalarının çok karmaşık olduğunu ve markalı aramaları markasız aramalardan ayırt etmenin zor olduğunu biliyoruz. Ancak SEO olarak yaptığımız şeyi daha da önemli kılan da bu.
Bu eğitimde, size iki markalı ve markasız olanı nasıl ayırt edeceğinizi göstereceğim ve size SEO'nun ne kadar güçlü olabileceğini göstereceğim.
Şirketiniz markalı olmasa bile bu makaleden hala çok şey kazanabilirsiniz: Sitenizin organik verilerini nasıl tahmin edeceğinizi öğrenebilirsiniz.
Trafik tahminine dayalı SEO yatırım getirisi
Nerede olursanız olun veya ne yaparsanız yapın, kaynaklarda bir sınırlama vardır; ister bir bütçe, ister sadece iş günündeki saat sayısı olsun. Kaynaklarınızı en iyi nasıl tahsis edeceğinizi bilmek, genel olarak ve SEO yatırım getirisinde (ROI) önemli bir rol oynar.
Bir CMO, bir pazarlama başkan yardımcısı veya bir performans pazarlamacısının hepsinin farklı KPI'ları vardır ve hedeflerine ulaşmak için farklı kaynaklara ihtiyaç duyarlar. İhtiyacınız olanı almanızı sağlamanın en iyi yolu, şirkete getireceği getirileri ortaya koyarak gerekliliğini kanıtlamaktır. SEO yatırım getirisi farklı değil. Bütçe tahsis zamanı geldiğinde ve ekibiniz daha büyük bir bütçe talep etmek istediğinde, SEO yatırım getirinizi tahmin etmek size pazarlıkta üstünlük sağlayabilir. Markasız trafik tahminini hesapladıktan sonra, istenen sonuçları elde etmek için gereken bütçeyi daha iyi değerlendirebilirsiniz.
SEO tahmininin SEO stratejisine etkisi
Bildiğimiz gibi, her 3 veya 6 ayda bir SEO stratejimizi gözden geçirir ve elimizden gelen en iyi sonuçları elde etmek için onu ayarlarız. Ama şirketiniz için en fazla kârın nerede olduğunu bilmediğinizde ne olur? Kararlar verebilirsiniz , ancak bunlar site trafiğini daha kapsamlı bir şekilde incelediğinizde alınan kararlar kadar etkili olmayacaktır.
Markasız organik trafik gelir tahmini, bir SEO yöneticisi veya SEO stratejisti olarak daha iyi stratejiler geliştirmenize yardımcı olacak büyük bir resim sağlamak için açılış sayfalarınız ve sorgu segmentasyonu ile birleştirilebilir.
Organik trafiği tahmin etmenin farklı yolları
Gelecekteki organik trafiği tahmin etmek için SEO topluluğunda birçok farklı yöntem ve genel komut dosyası vardır.
Bu yöntemlerden bazıları şunlardır:
- Tüm sitede organik trafik tahmini
- Belirli sayfalarda (blog, ürünler, kategoriler vb.) veya tek bir sayfada organik trafik tahmini
- Belirli sorgular (sorgular "satın alma", "nasıl yapılır" vb. içerir) veya bir sorgu üzerinde organik trafik tahmini
- Belirli dönemler için organik trafik tahmini (özellikle mevsimsel olaylar için)
Benim yöntemim belirli sayfalar içindir ve zaman çerçevesi bir aydır.
[Örnek Olay] Sayfa içi SEO ile yeni pazarlarda büyüme sağlamak
 Örnek olayı okuyun
Örnek olayı okuyunOrganik trafik geliri nasıl hesaplanır?
Doğru yol, Google Analytics (GA) verilerinize dayanmaktadır. Siteniz yepyeni ise 3. parti araçlar kullanmanız gerekecektir. Kendi verileriniz olduğunda bu tür araçları kullanmaktan kaçınmayı tercih ederim.
Verilerindeki olası hataları bulmak için kullandığınız 3. taraf verilerini bazı gerçek sayfa verilerinize karşı test etmeniz gerektiğini unutmayın.
Python ile markasız SEO trafik geliri nasıl hesaplanır
Şimdiye kadar, organik trafik ve gelir tahminimizin farklı yönlerini daha iyi anlamak için aşina olmamız gereken birçok teorik kavramı ele aldık. Şimdi, bu makalenin pratik kısmına dalacağız.
İlk olarak, TO eğrimizi hesaplayarak başlayacağız. Oncrawl ile ilgili CTR eğrisi makalemde iki farklı yöntemi ve ayrıca kodumda birkaç değişiklik yaparak kullanabileceğiniz diğer yöntemleri anlatıyorum. Önce tıklama eğrisi makalesini okumanızı tavsiye ederim; bu makale hakkında size fikir verir.
Bu makalede, trafik tahmininde istediğimiz belirli sonuçları elde etmek için kodumun bazı bölümlerinde ince ayar yapıyorum. Ardından, GA'dan verilerimizi alacağız ve gelirimizi tahmin etmek için GA gelir boyutunu kullanacağız.
Python ile marka dışı organik trafik gelirini tahmin etme: Başlarken
Herhangi bir Python bilmeden bu kodu kendiniz çalıştırabilirsiniz. Ancak, bu tahmin kodunda kullanacağım Python kitaplıkları hakkında biraz Python sözdizimi ve temel bilgiler hakkında bilgi sahibi olmanızı tercih ederim. Bu, kodumu daha iyi anlamanıza ve sizin için yararlı olacak şekilde özelleştirmenize yardımcı olacaktır.
Bu kodu çalıştırmak için Visual Studio Code'u Microsoft'un “Jupyter” uzantısını içeren Python uzantısı ile kullanacağım. Ancak Jupyter not defterinin kendisini kullanabilirsiniz.
Tüm süreç için şu Python kitaplıklarını kullanmamız gerekiyor:
- Dizi
- pandalar
- olay örgüsü
Ayrıca, bazı Python standart kitaplıklarını içe aktaracağız:
- JSON
- pprint
# İşlemimiz için ihtiyacımız olan kütüphaneleri import ediyoruz json'u içe aktar pprint'ten içe aktarma pprint numpy'yi np olarak içe aktar pandaları pd olarak içe aktar plotly.express'i px olarak içe aktar
1. Adım: Göreli TO eğrisini hesaplama (Göreceli tıklama eğrisi)
İlk adımda, göreli TO eğrimizi hesaplamak istiyoruz. Ancak, göreli TO eğrisi nedir?
Göreli TO eğrisi nedir?
Önce 'mutlak TO eğrisinden' bahsederek başlayalım. Mutlak TO eğrisini hesapladığımızda, birinci konumun medyan TO'sunun (veya ortalama TO'sunun) %36 ve ikinci konumun %20 olduğunu söylüyoruz vb.
Göreceli TO eğrisinde, yüzde anlık, her konumun medyanını ilk konumun TO'suna böleriz. Örneğin, ilk konumun göreli TO eğrisi 0,36 / 0,36 = 1, ikincisi 0,20 / 0,36 = 0,55 olur ve bu böyle devam eder.
Belki de bunu hesaplamanın neden yararlı olduğunu merak ediyorsunuz? %44 TO'ya sahip birinci konumda yer alan bir sayfa düşünün. Bu sayfa ikinci konuma giderse, TO eğrisi %20'ye düşmez, TO'nun %44 * 0,55 = %24,2'ye düşmesi daha olasıdır.
1. GSC'den markalı ve markasız organik trafik verilerinin alınması
Hesaplama işlemimiz için GSC'den verilerimizi almamız gerekiyor. İlk seferde tüm veriler markalı sorgulara dayalı olacak ve bir sonraki sefer tüm veriler markasız sorgulara dayalı olacak.
Bu verileri almak için farklı yöntemler kullanabilirsiniz: Python komut dosyalarından veya "E-Tablolar için Arama Analizi" Google E-Tablolar eklentisinden. GSC API gezginini kullanacağım.
Bu verilerin çıktısı, her sayfanın performansını gösteren iki JSON dosyasıdır. Bir JSON dosyası, markalı sorgulara dayalı olarak açılış sayfalarının performansını, diğeri ise markalı olmayan sorgulara dayalı olarak açılış sayfalarının performansını gösterir.
GSC API gezgininden veri almak için şu adımları izleyin:
- https://developers.google.com/webmaster-tools/v1/searchanalytics/query adresine gidin.
- Sayfanın sağ üst köşesindeki API gezginini büyütün.
- “
siteUrl” alanına alan adınızı girin. Örneğin “https://www.example.com” veya “http://your-domain.com”. - İstek gövdesinde öncelikle “
startDate” ve “endDate” parametrelerini tanımlamamız gerekiyor. Tercihim son 30 gün. - Daha sonra “
dimensions” ekliyoruz ve bu liste için “page” seçiyoruz. - Şimdi sorgularımızı filtrelemek için “
dimensionFilterGroups” ekliyoruz. Markalı sorgular için bir kez ve markasız sorgular için bir saniye. - Sonunda “
rowLimit”imizi 25.000 olarak belirledik. Her ay organik trafik alan site sayfalarınız 25K'dan fazlaysa, istek gövdesini değiştirmelisiniz. - Her isteği yaptıktan sonra JSON yanıtını kaydedin. Markalı performans için JSON dosyasını “
branded_data.json” olarak kaydedin ve markalı olmayan performans için JSON dosyasını “non_branded_data.json” olarak kaydedin.
İstek gövdemizdeki parametreleri anladıktan sonra, yapmanız gereken tek şey istek gövdelerinin altına kopyalayıp yapıştırmak. Marka adlarınızı “ brand variation names ” ile değiştirmeyi düşünün.
Marka adlarını bir ardışık düzen veya “ | ”. Örneğin, “ amazon|amazon.com|amazn ”.
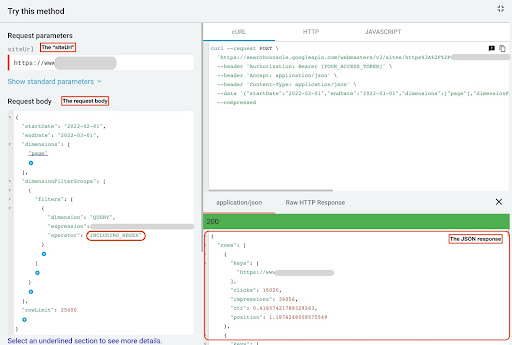
GSC API Gezgini
Markalı istek gövdesi:
{
"başlangıçTarihi": "2022-02-01",
"bitiş Tarihi": "2022-03-01",
"boyutlar": [
"sayfa"
],
"boyutFilterGroups": [
{
"filtreler": [
{
"boyut": "SORGU",
"ifade": "marka varyasyon adları",
"operatör": "INCLUDING_REGEX"
}
]
}
],
"satırLimit": 25000
}
Markasız istek gövdesi:
{
"başlangıçTarihi": "2022-02-01",
"bitiş Tarihi": "2022-03-01",
"boyutlar": [
"sayfa"
],
"boyutFilterGroups": [
{
"filtreler": [
{
"boyut": "SORGU",
"ifade": "marka varyasyon adları",
"operatör": "HARİÇ_REGEX"
}
]
}
],
"satırLimit": 25000
}
2. Verileri Jupyter not defterimize aktarma ve site dizinlerini çıkarma
Şimdi, değiştirebilmek ve ondan istediğimizi çıkarabilmek için verilerimizi Jupyter not defterimize yüklememiz gerekiyor. Yukarıda kaldığımız yerden devam edelim.
Markalı verileri yüklemek için şu kod bloğunu çalıştırmanız gerekir:
# Web sitesi URL'lerinin marka üzerindeki performansı ve markalı sorgular için bir DataFrame oluşturma
open("./branded_data.json") ile json_file olarak:
branded_data = json.loads(json_file.read())["satırlar"]
branded_df = pd.DataFrame(branded_data)
# 'Anahtarlar' sütununu 'açılış sayfası' sütunu olarak yeniden adlandırma ve 'açılış sayfası' listesini bir URL'ye dönüştürme
branded_df.rename(sütunlar={"anahtarlar": "açılış sayfası"}, inplace=Doğru)
branded_df["açılış sayfası"] = branded_df["açılış sayfası"].apply(lambda x: x[0])
Açılış sayfalarının markasız performansı için şu kod bloğunu çalıştırmanız gerekir:
# Markasız sorgularda web sitesi URL'lerinin performansı için bir DataFrame oluşturma
open("./non_branded_data.json") ile json_file olarak:
non_branded_data = json.loads(json_file.read())["satırlar"]
non_branded_df = pd.DataFrame(non_branded_data)
# 'Anahtarlar' sütununu 'açılış sayfası' sütunu olarak yeniden adlandırma ve 'açılış sayfası' listesini bir URL'ye dönüştürme
non_branded_df.rename(sütunlar={"anahtarlar": "açılış sayfası"}, inplace=Doğru)
non_branded_df["açılış sayfası"] = non_branded_df["açılış sayfası"].apply(lambda x: x[0])
Verilerimizi yüklüyoruz, ardından dizinlerini çıkarmak için site adımızı tanımlamamız gerekiyor.
# Site adınızı tırnak işaretleri arasında tanımlama. Örneğin, 'https://www.example.com/' veya 'http://mydomain.com/' SITE_NAME = "https://www.alan_adiniz.com/"
Sadece markasız performanstan dizinleri çıkarmamız gerekiyor.
# Her bir açılış sayfası (URL) dizinini alma
non_branded_df["dizin"] = non_branded_df["açılış sayfası"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
Daha sonra bu işlem için hangilerinin önemli olduğunu seçmek için dizinlerin çıktısını alıyoruz. Siteniz hakkında daha iyi bilgi edinmek için tüm dizinleri seçmek isteyebilirsiniz.

# Çıktıdaki tüm dizinleri almak için Panda seçeneklerini değiştirmemiz gerekiyor
pd.set_option("display.max_rows", Yok)
# Web sitesi dizinleri
non_branded_df["dizin"].value_counts()
Burada, sizin için önemli olan dizinleri ekleyebilirsiniz.
""" TO eğrilerini almak için hangi dizinlerin önemli olduğunu seçin.
Dizinleri 'önemli_dizinler' değişkenine ekleyin.
Örneğin, 'ürün,etiket,ürün-kategori,mag'. Dizin değerlerini virgülle ayırın.
"""
IMPORTANT_DIRECTORIES = "your_important_directories"
IMPORTANT_DIRECTORIES = IMPORTANT_DIRECTORIES.split(",")
3. Sayfaları konumlarına göre etiketleme ve ilgili TO eğrisini hesaplama
Şimdi açılış sayfalarımızı konumlarına göre etiketlememiz gerekiyor. Bunu yapıyoruz çünkü açılış sayfasının konumuna göre her bir dizin için göreli TO eğrisini hesaplamamız gerekiyor.
# Markalı olmayan konumların etiketlenmesi
i aralığında (1, 11):
non_branded_df.loc[
(non_branded_df["position"] >= i) & (non_branded_df["position"] < i + 1),
"konum etiketi",
] = ben
Ardından, açılış sayfalarını dizinlerine göre gruplandırıyoruz.
# Açılış sayfalarını 'dizin' değerlerine göre gruplandırma non_brand_grouped_df = non_branded_df.groupby(["dizin"])
Göreli TO eğrisini hesaplayacak işlevi tanımlayalım.
defeach_dir_relative_ctr_curve(dir_df, anahtar):
"""İşlev, her IMPORTANT_DIRECTORIES göreli TO eğrisini hesaplar.
"""
# "non_brand_grouped_df"yi "konum etiketi" değerine göre gruplandırma
dir_grouped_df = dir_df.groupby(["konum etiketi"])
# Her konumun medyan TO'sunu kaydetmek için bir liste
median_ctr_list = []
# Her dizini bir anahtar olarak saklamak ve değer olarak "median_ctr_list"
directoryies_median_ctr = {}
# Her "dir_grouped_df" grubu üzerinde döngü yapın
i aralığında (1, 11):
# Örneğin bir dizinin 4. konum için herhangi bir veriye sahip olmadığı durumları ele almak dışında bir deneme
denemek:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"]))
hariç:
median_ctr_list.append(0)
# Göreli TO eğrisini hesaplama
directoryies_median_ctr[anahtar] = np.array(median_ctr_list) / np.array(
[median_ctr_list[0]] * 10
)
dizinler_median_ctr döndür
Fonksiyonu tanımladıktan sonra çalıştırıyoruz.
# Dizinler üzerinde dolaşmak ve 'each_dir_relative_ctr_curve' işlevini yürütmek
directoryies_median_ctr_dict = dict()
anahtar için non_brand_grouped_df içindeki öğe:
IMPORTANT_DIRECTORIES'de anahtar varsa:
directoryies_median_ctr_dict.update(each_dir_relative_ctr_curve(item, key))
pprint(directories_median_ctr_dict)
Şimdi, markalı ve markasız açılış sayfalarımızı, performansımızı yükleyeceğiz ve marka dışı verilerimiz için göreli TO eğrisini hesaplayacağız. Bunu neden yalnızca marka dışı veriler için yapıyoruz? Çünkü marka dışı organik trafiği ve geliri tahmin etmek istiyoruz.
2. Adım: Markasız organik trafik gelirini tahmin etme
Bu ikinci adımda, gelir verilerimizi nasıl alacağımıza ve gelirimizi nasıl tahmin edeceğimize gireceğiz.
1. Markalı ve markasız organik verilerin birleştirilmesi
Şimdi markalı ve markasız verilerimizi birleştireceğiz. Bu, tüm trafiğe kıyasla her açılış sayfasındaki markasız organik trafiğin yüzdesini hesaplamamıza yardımcı olacaktır.
# 'main_df', 'tüm site verileri' ve 'marka dışı veriler' DataFrame'lerinin birleşimidir.
# Bu DataFrame'i kullanarak, tıklama ve gösterimlerimizin çoğunun nerede olduğunu öğrenebilirsiniz.
# markalı olmayan sorgulardan gelir.
main_df = non_branded_df.merge(
branded_df, on="açılış sayfası", sonekler=("_non_brand", "_branded")
)
Ardından, gereksiz olanları kaldırmak için sütunları değiştiririz.
# 'main_df' sütunlarını ihtiyacımız olanlarla değiştirmek
main_df = ana_df[
[
"Açılış sayfası",
"clicks_non_brand",
"ctr_non_brand",
"dizin",
"konum etiketi",
"clicks_branded",
]
]
Şimdi, bir açılış sayfasının toplam tıklamalarına göre markasız tıklama yüzdesini hesaplayalım.
# Açılış sayfalarına dayalı olarak markalı olmayan sorguların tıklama yüzdesinin tüm açılış sayfası tıklamalarına hesaplanması
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x: x["clicks_non_brand"] / (x["clicks_non_brand"] + x["clicks_branded"]),
eksen=1,
)
[Ebook] Oncrawl ile SEO'yu Otomatikleştirme
 e-kitabı okuyun
e-kitabı okuyun2. Organik trafik gelirinin yüklenmesi
Tıpkı GSC verilerini almak gibi, GA verilerini almanın birkaç yolu var: "Google Analytics Sayfaları eklentisini" veya GA API'sini kullanabiliriz. Bu eğitimde, basitliği nedeniyle Google Data Studio'yu (GDS) kullanmayı tercih ediyorum.
GA verilerini GDS'den almak için şu adımları izleyin:
- GDS'de yeni bir rapor veya gezgin ve bir tablo oluşturun.
- Boyut için "açılış sayfası" ve metrik için "Gelir" eklemeliyiz.
- Ardından, kaynak ve ortama dayalı olarak GA'da özel bir segment oluşturmanız gerekir. "Google/organik" trafiği filtreleyin. Segment oluşturulduktan sonra GDS'deki segment bölümüne ekleyin.
- Son adımda, tabloyu dışa aktarın ve “
landing_pages_revenue.csv” olarak kaydedin.
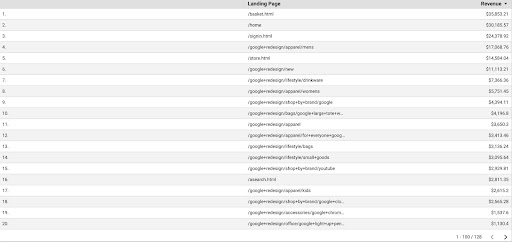
Açılış sayfaları geliri csv dışa aktarma
Verilerimizi yükleyelim.
Organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
Şimdi, site adımızı GA açılış sayfalarının URL'lerine eklememiz gerekiyor.
Verilerimizi GA'dan dışa aktardığımızda, açılış sayfaları göreceli formdadır ancak GSC verilerimiz mutlak formdadır.
GA açılış sayfaları verilerinizi kontrol etmeyi unutmayın. Çalıştığım veri kümelerinde, GA verilerinin her seferinde biraz temizlenmesi gerektiğini buldum.
# GA açılış sayfası URL'lerini SITE_NAME ile birleştirme.
# Ayrıca sütunları yeniden adlandırmak
Organic_revenue_df.loc[:, "Açılış Sayfası"] = (
SITE_NAME[:-1] + Organic_revenue_df[organic_revenue_df.columns[0]]
)
Organic_revenue_df.rename(columns={"Açılış Sayfası": "açılış sayfası", "Gelir": "gelir"}, inplace=Doğru)
Şimdi GSC verilerimizi GA verileriyle birleştirelim.
# Bu adımda, 'main_df' ile marka dışı sorgu verilerinin yüzdesini içeren 'dk_organic_revenue_df' DataFrame'i birleştiriyorum main_df = main_df.merge(organik_revenue_df, on="açılış sayfası", how="sol")
Bu bölümün sonunda DataFrame sütunlarımızda küçük bir temizlik yapıyoruz.
# 'main_df' DataFrame'in biraz temizlenmesi
main_df = ana_df[
[
"Açılış sayfası",
"clicks_non_brand",
"ctr_non_brand",
"dizin",
"konum etiketi",
"clicks_non_brand_percentage",
"gelir",
]
]
3. Markasız gelirin hesaplanması
Bu bölümde, aradığımız bilgileri çıkarmak için verileri işleyeceğiz.
Ancak her şeyden önce, açılış sayfalarımızı “ IMPORTANT_DIRECTORIES ” temelinde filtreleyelim:
# "IMPORTANT_DIRECTORIES" içinde yer almayan diğer dizin açılış sayfalarını kaldırma
ana_df = (
main_df[main_df["dizin"].isin(ÖNEMLİ_DIRECTORIES)]
.dropna(subset=["gelir"])
.reset_index(drop=Doğru)
)
Şimdi markasız organik gelir trafiğini hesaplayalım.
Kolayca hesaplayamayacağımız bir metrik tanımladım ve bu, bizi ona bir sayı atamaya yönlendiren her şeyden daha fazla sezgidir.
“ brand_influence ” metriği markanızın gücünü gösterir. Marka olmayan aramaların işletmenize daha az satış getirdiğine inanıyorsanız, bu sayıyı düşürün; örneğin 0.8 gibi bir şey.
# Markanız o kadar güçlüyse, markanız olmadan sorgulamak, markanızla sorgulamak kadar satabilirse, o zaman 1 sizin için iyidir.
# Sorgunuzda marka adı olmayan bir kitap aramayı düşünün. Amazon'u gördüğünüzde başka pazar yerlerinden veya mağazalardan satın alıyor musunuz?
brand_influence = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
lambda x: x["gelir"] * x["clicks_non_brand_percentage"] * brand_influence, axis=1
)
Önemli dizinlere dayalı olarak markasız gelir hakkında biraz fikir edinmek için bir pasta grafiği çizelim.
# Bu hücrede, marka olmayan tüm açılış sayfalarının gelirlerini dizine göre almak istiyorum
non_branded_directory_dist_revenue_df = pd.pivot_table(
ana_df,
indeks = "dizin",
değerler=["non_brand_revenue"],
aggfunc={"non_brand_revenue": "toplam"},
)
pie_fig = px.pie(
non_branded_directory_dist_revenue_df,
değerler = "non_brand_revenue",
isimler=non_branded_directory_dist_revenue_df.index,
title="Web sitesi dizinlerine dayalı markasız gelir",
)
pie_fig.update_traces(textposition="iç", textinfo="percent+label")
pasta_fig.göster()
Bu grafik, IMPORTANT_DIRECTORIES dosyanızdaki markalı olmayan sorguların dağılımını gösterir.
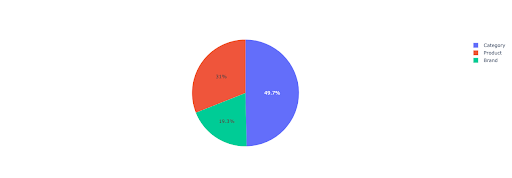
Markasız sorgu dağıtımı
CTR eğrisi verilerime dayanarak, 5'ten yüksek pozisyonlar için CTR'ye güvenemeyeceğimi görüyorum. Bu nedenle verilerimi pozisyona göre filtreliyorum.
Aşağıdaki kod bloğunu verilerinize göre değiştirebilirsiniz.
# CTR eğrimizdeki CTR doğruluğu nedeniyle, konumu 5'ten fazla olan açılışları atlayabileceğimizi düşünüyorum. Bu nedenle, diğer açılış sayfalarını filtreledim. main_df = main_df[main_df["konum etiketi"] < 6].reset_index(drop=True)
4. "Tıklama Başına Gelir" (RPC) Hesaplama
Burada özel bir metrik oluşturdum ve buna "Tıklama Başına Gelir" veya RPC adını verdim. Bu bize, markasız her tıklamanın oluşturduğu geliri gösterir.
Bu metriği farklı şekillerde kullanabilirsiniz. RPC'si yüksek, ancak tıklamaları düşük bir sayfa buldum. Sayfayı kontrol ettiğimde, bir haftadan daha kısa bir süre önce dizine eklendiğini öğrendim ve sayfayı optimize etmek için farklı yöntemler kullanabiliriz.
# Her tıklama ile elde edilen gelirin hesaplanması (RPC: Tıklama Başına Gelir)
main_df["rpc"] = main_df.apply(
lambda x: x["non_brand_revenue"] / x["clicks_non_brand"], eksen=1
)
5. Geliri tahmin etmek!
Sona geliyoruz, markasız organik gelirimizi tahmin etmek için şimdiye kadar bekledik.
Son kod bloklarını çalıştıralım.
# Farklı pozisyonlara göre geliri hesaplamanın ana işlevi
dizin için, main_df.iterrows() içindeki satır_değerleri:
# Dizinler arasında geçiş yap TO listesi
ctr_curve = directoryes_median_ctr_dict[row_values["dizin"]]
# 1'den 5'e kadar olan konumlar arasında dolaşın ve geliri TO'daki artış veya düşüşe göre hesaplayın
i aralığında (1, 6):
if i == row_values["konum etiketi"]:
main_df.loc[index, i] = row_values["non_brand_revenue"]
başka:
# main_df.loc[index, i + 1] ==
main_df.loc[index, i] = (
satır_değerleri["non_brand_revenue"]
* (ctr_curve[i - 1])
/ ctr_curve[int(row_values["konum etiketi"] - 1)]
)
# "N'den 1'e" metriğinin hesaplanması. Bu, sıralamanız "N"den "1"e yükseldiğinde gelirinizdeki artışı gösterir.
main_df.loc[index, "N'den 1'e"] = main_df.loc[index, 1] - main_df.loc[index, row_values["konum etiketi"]]
Nihai çıktıya baktığımızda, yeni sütunlarımız var. Bu sütunların adları “1”, “2”, “3”, “4”, “5” şeklindedir.
Bu isimler ne anlama geliyor? Örneğin, 3. konumda bir sayfamız var ve konumunu geliştirirse gelirini tahmin etmek istiyoruz veya sıralamada düşersek ne kadar kaybedeceğimizi bilmek istiyoruz.
"1" ve "2" sütunları, bu sayfanın ortalama konumu iyileştiğinde sayfanın gelirini gösterir ve "4" ve "5" sütunları, sıralamada düştüğümüzde bu sayfanın gelirini gösterir.
Bu örnekteki "3" sütunu, sayfanın mevcut gelirini gösterir.
Ayrıca "N'den 1'e" adında bir metrik oluşturdum. Bu, bu sayfanın ortalama konumunun "3" (veya N) konumundan "1" konumuna geçip geçmediğini ve bu hareketin geliri ne kadar etkileyebileceğini gösterir.
toparlamak
Bu yazıda çok şey anlattım ve şimdi ellerinizi kirletme ve markasız organik trafik gelirinizi tahmin etme sırası sizde.
Bu tahmini kullanmanın en basit yolu budur. Bu algoritmayı daha karmaşık hale getirebilir ve bazı ML modelleriyle birleştirebiliriz, ancak bu makaleyi daha karmaşık hale getirir.
Bu verileri bir CSV dosyasına kaydetmeyi ve bir Google E-Tablosuna yüklemeyi tercih ediyorum. Veya, ekibimin veya organizasyonun diğer üyeleriyle paylaşmayı planlıyorsam, excel ile açıp sütunları, okunması daha kolay olacak şekilde renkler kullanarak biçimlendireceğim.
Bu verilere dayanarak, markasız organik trafik yatırım getirinizi tahmin edebilir ve pazarlık sürecinizde kullanabilirsiniz.