
Peygamber ve Python ile SEO trafiğini tahmin etme
Yayınlanan: 2021-03-16Hedefler belirlemek ve zaman içinde başarıyı değerlendirmek, neyi başarabileceğimizi ve kullandığımız stratejinin etkili olup olmadığını anlamak için çok ilginç bir alıştırmadır. Ancak, bu hedefleri belirlemek genellikle o kadar kolay değildir çünkü önce bir tahminde bulunmamız gerekecektir.
Tahmin oluşturmak zahmetsiz bir şey değildir, ancak bazı mevcut tahmin prosedürleri, CPU'muz ve bazı programlama becerilerimiz sayesinde karmaşıklığını oldukça azaltabiliriz. Bu yazımda size nasıl doğru tahminlerde bulunabileceğimizi ve bunu SEO'ya nasıl uygulayabileceğinizi Python ve kütüphane Prophet kullanarak ve falcı süper güçlerine sahip olmadan göstereceğim.
Peygamber hakkında hiç bir şey duymadıysanız, bunun ne olduğunu merak edebilirsiniz. Kısaca Prophet, Facebook'un Core Data Science ekibi tarafından Python ve R'de mevcut olan ve aykırı değerler ve mevsimsel etkilerle çok iyi ilgilenen bir tahmin prosedürüdür.
doğru ve hızlı tahminler sunar.
Tahmin hakkında konuştuğumuzda, iki şeyi göz önünde bulundurmamız gerekir:
- Sahip olduğumuz daha fazla tarihsel veri, modelimiz ve dolayısıyla tahminlerimiz daha doğru olacaktır.
- Tahmine dayalı model, yalnızca iç faktörlerin aynı kalması ve onu etkileyen herhangi bir dış faktör olmaması durumunda geçerli olacaktır. Bu, örneğin, haftada bir gönderi yayınlıyorsak ve haftada iki gönderi yayınlamaya başlarsak, bu model, bu strateji değişikliğinin sonucunun ne olacağını tahmin etmek için geçerli olmayabilir. Öte yandan algoritma güncellemesi varsa model de geçerli olmayabilir. Modelin geçmiş verilere dayalı olarak oluşturulduğunu unutmayın.
Bunu SEO'ya uygulamak için yapacağımız şey, sonraki adımları izleyerek önümüzdeki ay için SEO oturumlarını tahmin etmektir:
- Belirli bir süre için organik oturumlar hakkında Google Analytics'ten veri almak.
- Modelimizi eğitmek.
- Önümüzdeki ay için SEO trafiğini tahmin etmek.
- Ortalama mutlak hata ile modelimizin ne kadar iyi olduğunu değerlendirmek.
Bu tahmin prosedürünün nasıl çalıştığı hakkında daha fazla bilgi edinmek ister misiniz? Hadi başlayalım o zaman!
Google Analytics'ten veri alma
Google Analytics'ten veri çıkarmaya iki şekilde yaklaşabiliriz: normal arayüzden bir Excel dosyasını dışa aktarmak veya bu verileri almak için API'yi kullanmak.
Verileri bir Excel dosyasından içe aktarma
Bu verileri Google Analytics'ten almanın en kolay yolu, yan çubuktaki Kanallar bölümüne giderek Organik'e tıklayıp sayfanın üst kısmındaki buton ile verileri dışa aktarmaktır. Grafiğin üst kısmındaki açılır menüden analiz etmek istediğiniz değişkeni, bu durumda Sessions'ı seçtiğinizden emin olun.
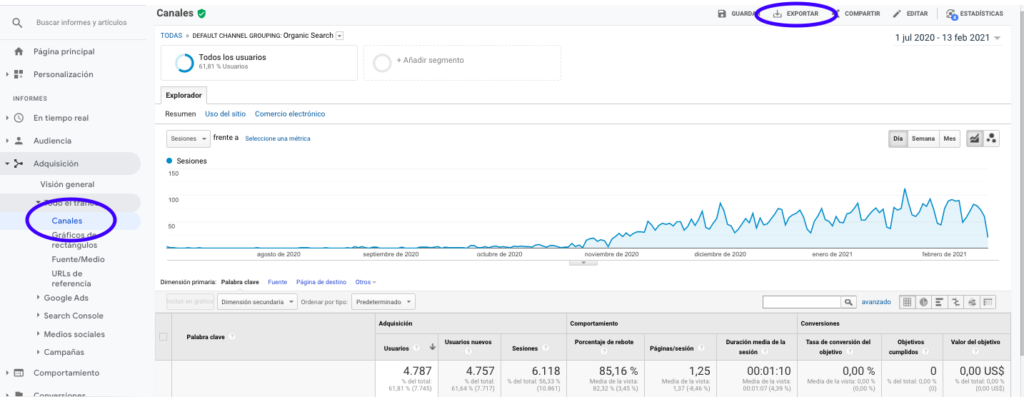
Verileri Excel dosyası olarak dışa aktardıktan sonra Pandalar ile not defterimize aktarabiliriz. Bu tür verileri içeren Excel dosyasının farklı sekmeler içereceğini unutmayın, bu nedenle aylık trafiği içeren sekmenin aşağıdaki kod parçasında bir argüman olarak belirtilmesi gerekir. Ayrıca, modelimizi bozacak toplam oturum miktarını içerdiğinden son satırı da siliyoruz.
pandaları pd olarak içe aktar
df = pd.read_excel ('.xlsx', sayfa_adı = "")
df = df.drop(len(df) - 1)
Matplotlib ile verilerin nasıl göründüğünü çizebiliriz:
matplotlib'den import pyplot
df["Oturumlar"].plot(title = "Oturumlar")
pyplot.show() 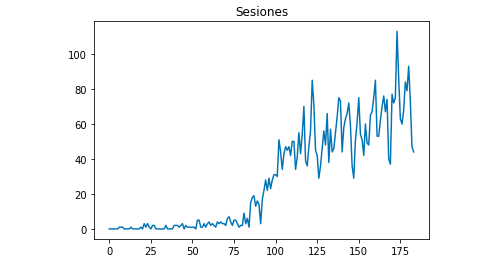
Google Analytics API'sini Kullanma
Öncelikle Google Analytics API'sinden faydalanmak için Google'ın geliştirici konsolunda bir proje oluşturmamız, Google Analytics Raporlama hizmetini etkinleştirmemiz ve kimlik bilgilerini almamız gerekiyor. Jean-Christophe Chouinard bu makalede bunun nasıl kurulacağını çok iyi açıklıyor.
Kimlik bilgileri alındıktan sonra, talebimizi yapmadan önce kimlik doğrulamamız gerekir. Kimlik doğrulamanın, başlangıçta Google'ın geliştirici konsolundan alınan kimlik bilgileri dosyasıyla yapılması gerekir. Ayrıca kullanmak istediğimiz mülkün GA View ID'sini de kodumuza yazmamız gerekecek.
apiclient.discovery içe aktarma yapısından
oauth2client.service_account'tan ServiceAccountCredentials'ı içe aktarın
KAPSAMLAR = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = ''
GÖRÜŞ_
kimlik bilgileri = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, KAPSAMLAR)
analytics = build('analyticsreporting', 'v4', kimlik bilgileri=kimlik bilgileri)Kimlik doğrulamasından sonra, sadece istekte bulunmamız gerekiyor. Her gün için organik oturumlarla ilgili verileri almak için kullanmamız gereken:
yanıt = analytics.reports().batchGet(body={
'raporTalepleri': [{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
'metrikler': [
{"ifade": "ga:oturumlar"}
], "boyutlar": [
{"ad": "ga:tarih"}
],
"filtersExpression":"ga:channelGrouping=~Organik",
"includeEmptyRows": "doğru"
}]}).uygulamak()DateRanges'da zaman aralığını seçtiğimizi unutmayın. Benim durumumda 1 Eylül'den 31 Ocak'a kadar olan verileri alacağım: [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
Bundan sonra, organik oturumları olan günleri bir listeye eklemek için yalnızca yanıt dosyasını getirmemiz gerekir:
liste_değerleri = [] yanıt olarak x için["raporlar"][0]["veri"]["satırlar"]: list_values.append([x["boyutlar"][0],x["metrikler"][0]["değerler"][0]])
Gördüğünüz gibi Google Analytics API'yi kullanmak oldukça basittir ve birçok amaç için kullanılabilir. Bu yazıda, düşük performans gösteren sayfaları tespit etmek için uyarılar oluşturmak için Google Analytics API'yi nasıl kullanabileceğinizi açıkladım.

Listeleri Veri Çerçevelerine Uyarlama
Prophet'i kullanmak için, “ds” ve “y” olarak adlandırılması gereken iki sütunlu bir Dataframe girmemiz gerekiyor. Verileri bir Excel dosyasından içe aktardıysanız, buna zaten bir Veri Çerçevesi olarak sahibiz, bu nedenle yalnızca sütunları "ds" ve "y" olarak adlandırmanız gerekir:
df.columns = ['ds', 'y']
Verileri almak için API'yi kullanmanız durumunda, listeyi bir veri çerçevesine dönüştürmemiz ve sütunları gerektiği gibi adlandırmamız gerekir:
pandalardan DataFrame'i içe aktar df_sessions = DataFrame(list_values,columns=['ds','y'])
Modeli eğitmek
Gerekli formatta Dataframe'e sahip olduğumuzda, modelimizi aşağıdakilerle çok kolay bir şekilde belirleyebilir ve eğitebiliriz:
fbpeygamberi içe aktar fbpeygamberden import Prophet model = Peygamber() model.fit(df_sessions)
tahminlerimizi yapmak
Sonunda modelimizi eğittikten sonra tahmin etmeye başlayabiliriz! Tahminlere devam etmek için önce tahmin etmek istediğimiz zaman aralığına sahip bir liste oluşturmamız ve tarih saat biçimini ayarlamamız gerekecek:
pandalardan içe aktarma to_datetime tahmin_günleri = [] aralıktaki x için(1, 28): tarih = "2021-02-" + str(x) tahmin_günleri.append([tarih]) tahmin_günleri = DataFrame(tahmin_günleri) tahmin_days.columns = ['ds'] tahmin_days['ds']= to_datetime(forecast_days['ds'])
Bu örnekte, Şubat ayından itibaren tüm günleri içerecek bir veri çerçevesi oluşturacak bir döngü kullanıyorum. Ve şimdi sadece daha önce eğitilmiş modeli kullanma meselesi:
tahmin = model.tahmin(tahmin_günleri)
Öngörülen süreyi vurgulayan bir arsa çizebiliriz:
matplotlib'den import pyplot model.plot(tahmin) pyplot.show()
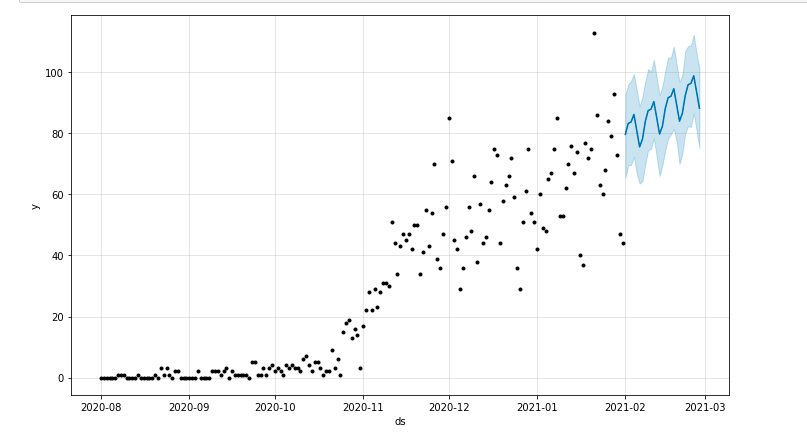
Modelin Değerlendirilmesi
Son olarak, modeli eğitmek için kullanılan verilerden bazı günleri çıkararak, o günler için oturumları tahmin ederek ve ortalama mutlak hatayı hesaplayarak modelimizin ne kadar doğru olduğunu değerlendirebiliriz.
Örnek olarak, yapacağım şey, Ocak ayının son 12 gününü orijinal veri çerçevesinden çıkarmak, her gün için oturumları tahmin etmek ve gerçek trafiği tahmin edilen trafikle karşılaştırmak.
İlk olarak, pop ile son 12 günü orijinal veri çerçevesinden çıkarıyoruz ve yalnızca tahmin için kullanılacak olan 12 günü içerecek yeni bir veri çerçevesi oluşturuyoruz:
tren = df_sessions.drop(df_sessions.index[-12:]) gelecek = df_sessions.loc[df_sessions["ds"]> train.iloc[len(tren)-1]["ds"]]["ds"]
Şimdi modeli eğitiyoruz, tahminde bulunuyoruz ve ortalama mutlak hatayı hesaplıyoruz. Sonunda, gerçek tahmin edilen değerler ile gerçek değerler arasındaki farkı gösterecek bir grafik çizebiliriz. Bu, Jason Brownlee tarafından yazılan bu makaleden öğrendiğim bir şey.
sklearn.metrics'den ortalama_absolute_error'ı içe aktarın
numpy'yi np olarak içe aktar
numpy içe aktarma dizisinden
#Modeli eğitiyoruz
model = Peygamber()
model.fit(tren)
#Tahmin günleri için kullanılan veri çerçevesini Peygamber'in gerekli formatına uyarlayın.
gelecek = liste(gelecek)
gelecek = DataFrame(gelecek)
gelecek = future.rename(sütunlar={0: 'ds'})
# Tahmini biz yaparız
tahmin = model.predict(gelecek)
# Gerçek değerler ile tahmin edilen değerler arasındaki MAE'yi hesaplıyoruz
y_true = df_sessions['y'][-12:].values
y_pred = tahmin['yhat'].değerler
mae = ortalama_mutlak_hata(y_true, y_pred)
# Görsel bir anlayış için nihai çıktıyı çiziyoruz
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true, label='Gerçek')
pyplot.plot(y_pred, label='Öngörülen')
pyplot.legend()
pyplot.show()
yazdır(mae) 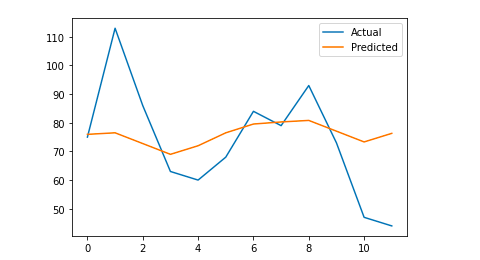
Ortalama mutlak hatam 13'tür; bu, tahmin edilen modelimin her güne gerçek olanlardan 13 fazla oturum atadığı anlamına gelir ve bu kabul edilebilir bir hata gibi görünmektedir.
Hepsi bu kadar millet! Umarım bu makaleyi ilginç bulmuşsunuzdur ve hedefler belirlemek için SEO tahminlerinizi yapmaya başlayabilirsiniz.
Daha da ileri gitmek: OnCrawl Labs
Bu yöntemle trafiğinizi tahmin etmekten keyif aldıysanız, SEO iş akışlarınız için önceden kodlanmış projeler sunan OnCrawl'ın veri bilimi ve makine öğrenimi laboratuvarı OnCrawl Labs ile de ilgileneceksiniz.
SEO tahmininde OnCrawl Labs, SEO projeksiyonlarınızı hassaslaştırmanıza yardımcı olacaktır:
- Facebook Prophet algoritmasının arkasındaki teorileri ve süreci daha iyi anlayın
- Yalnızca uzun kuyruklu anahtar kelimelerdeki trafik veya yalnızca markalı anahtar kelimelerdeki trafik gibi bir trafik segmentini analiz edin…
- Etkilerini ve tekrarlanma olasılıklarını ayarlayarak tarihi olayları ayarlamak için adım adım bir süreci takip edin.