
Bir HTML sayfasından ilgili metin içeriği nasıl çıkarılır?
Yayınlanan: 2021-10-13Bağlam
Oncrawl'ın Ar-Ge departmanında, web sayfalarınızın anlamsal içeriğine giderek daha fazla değer katmak istiyoruz. Doğal dil işleme (NLP) için makine öğrenimi modellerini kullanarak, SEO için gerçek katma değeri olan görevleri gerçekleştirmek mümkündür.
Bu görevler aşağıdaki gibi etkinlikleri içerir:
- Sayfalarınızın içeriğine ince ayar yapın
- Otomatik özetler yapma
- Makalelerinize yeni etiketler ekleme veya mevcut etiketleri düzeltme
- İçeriği Google Arama Konsolu verilerinize göre optimize etme
- vb.
Bu maceradaki ilk adım, bu makine öğrenme modellerinin kullanacağı web sayfalarının metin içeriğini çıkarmaktır. Web sayfaları hakkında konuştuğumuzda, buna HTML, JavaScript, menüler, medya, üstbilgi, altbilgi,… İçeriği otomatik ve doğru şekilde çıkarmak kolay değildir. Bu makale aracılığıyla, sorunu keşfetmeyi ve bu görevi başarmak için bazı araçları ve önerileri tartışmayı öneriyorum.
Sorun
Bir web sayfasından metin içeriği çıkarmak basit görünebilir. Birkaç satır Python ile, örneğin, birkaç normal ifade (regexp), BeautifulSoup4 gibi bir ayrıştırma kitaplığı ve bitti.
Gittikçe daha fazla sitenin Vue.js veya React gibi JavaScript oluşturma motorlarını kullandığı gerçeğini birkaç dakika göz ardı ederseniz, HTML'yi ayrıştırmak çok karmaşık değildir. Taramalarınızda JS tarayıcımızdan yararlanarak bu sorunu çözmek istiyorsanız “JavaScript'te site nasıl taranır?” başlıklı makaleyi okumanızı öneririm.
Ancak, anlamlı, mümkün olduğunca bilgilendirici bir metin çıkarmak istiyoruz. Örneğin, John Coltrane'in ölümünden sonraki son albümü hakkında bir makale okuduğunuzda, menüleri, altbilgiyi görmezden gelirsiniz… ve açıkçası, HTML içeriğinin tamamını görüntülemiyorsunuzdur. Neredeyse tüm sayfalarınızda görünen bu HTML öğelerine ortak metin adı verilir. Ondan kurtulmak ve sadece bir kısmını tutmak istiyoruz: ilgili bilgileri taşıyan metin.
Bu nedenle, işleme için makine öğrenimi modellerine geçmek istediğimiz yalnızca bu metindir. Bu yüzden ekstraksiyonun mümkün olduğu kadar kaliteli olması önemlidir.
Çözümler
Genel olarak, ana metinde "takılan" her şeyden kurtulmak istiyoruz: menüler ve diğer kenar çubukları, iletişim öğeleri, altbilgi bağlantıları, vb. Bunu yapmanın birkaç yöntemi vardır. Daha çok Python veya JavaScript'teki Açık Kaynak projeleriyle ilgileniyoruz.
jusText
jusText, bir doktora tezinden Python'da önerilen bir uygulamadır: “Web Corpora'dan Ortak Plakayı ve Yinelenen İçeriği Kaldırma”. Yöntem, HTML'den gelen metin bloklarının farklı buluşsal yöntemlere göre "iyi", "kötü", "çok kısa" olarak sınıflandırılmasına izin verir. Bu buluşsal yöntemler çoğunlukla kelime sayısına, metin/kod oranına, bağlantıların varlığına veya yokluğuna vb. dayanır. Algoritma hakkında daha fazla bilgiyi belgelerde okuyabilirsiniz.
trafik
Python'da da oluşturulan trafilatura, hem HTML öğesi türü hem de içeriği hakkında buluşsal yöntemler sunar, örneğin metin uzunluğu, öğenin HTML'deki konumu/derinliği veya sözcük sayısı. trafilatura ayrıca bazı işlemleri gerçekleştirmek için jusText kullanır.
okunabilirlik
Firefox'un URL çubuğundaki düğmeyi hiç fark ettiniz mi? Bu, Okuyucu Görünümüdür: Yalnızca ana metin içeriğini tutmak için, HTML sayfalarından standart metni kaldırmanıza olanak tanır. Haber siteleri için kullanımı oldukça pratik. Bu özelliğin arkasındaki kod JavaScript'te yazılmıştır ve Mozilla tarafından okunabilirlik olarak adlandırılır. Arc90 laboratuvarı tarafından başlatılan çalışmaya dayanmaktadır.
France Musique web sitesindeki bir makale için bu özelliğin nasıl oluşturulacağına dair bir örnek. 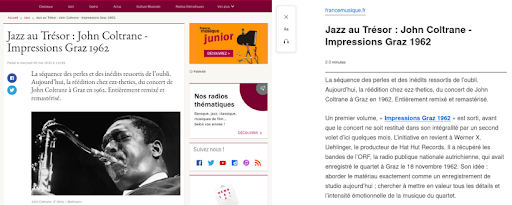
Solda, orijinal makaleden bir alıntıdır. Sağda, Firefox'ta Okuyucu Görünümü özelliğinin bir görüntüsüdür.
Diğerleri
HTML içerik çıkarma araçlarıyla ilgili araştırmamız, başka araçları da düşünmemize yol açtı:
- gazete: daha çok haber sitelerine adanmış bir içerik çıkarma kitaplığı (Python). Bu kitaplık, OpenWebText2 korpusundan içerik çıkarmak için kullanıldı.
- kazanpy3, kazan borusu kitaplığının bir Python bağlantı noktasıdır.
- dragnet Python kütüphanesi de kazan borusundan esinlenmiştir.
Tarama Verileri³
 Daha fazla bilgi edin
Daha fazla bilgi edinDeğerlendirme ve öneriler
Farklı araçları değerlendirmeden ve karşılaştırmadan önce, NLP topluluğunun bu araçlardan bazılarını kendi külliyatlarını (geniş belgeler seti) hazırlamak için kullanıp kullanmadığını öğrenmek istedik. Örneğin, GPT-Neo'yu eğitmek için kullanılan The Pile adlı veri kümesinde Wikipedia, Openwebtext2, Github, CommonCrawl, vb.'den +800 GB'lık İngilizce metinler bulunur. BERT gibi GPT-Neo da tür dönüştürücüler kullanan bir dil modelidir. GPT-3 mimarisine benzer bir açık kaynak uygulaması sunar.

"Yığın: Dil Modelleme için 800 GB'lık Farklı Metin Veri Kümesi" makalesi, CommonCrawl'dan derlemlerinin büyük bir kısmı için jusText kullanımından bahseder. Bu araştırmacı grubu aynı zamanda farklı ekstraksiyon araçlarının bir karşılaştırmasını yapmayı da planlamıştı. Ne yazık ki kaynak yetersizliğinden planladıkları işi yapamadılar. Sonuçlarında şunlara dikkat edilmelidir:
- jusText bazen çok fazla içeriği kaldırdı ama yine de iyi kalite sağladı. Sahip oldukları veri miktarı göz önüne alındığında, bu onlar için bir sorun değildi.
- trafilatura, HTML sayfasının yapısını korumada daha iyiydi, ancak çok fazla bilgi kaynağı tutuyordu.
Değerlendirme yöntemimiz için yaklaşık otuz web sayfası aldık. Ana içeriği “manuel” olarak çıkardık. Daha sonra, farklı araçların metin çıkarımını bu "referans" içerikle karşılaştırdık. Ağırlıklı olarak otomatik metin özetlerini değerlendirmek için kullanılan ROUGE skorunu metrik olarak kullandık.
Ayrıca bu araçları, HTML ayrıştırma kurallarına dayalı "ev yapımı" bir araçla karşılaştırdık. Trafilatura, jusText ve ev yapımı aracımızın bu ölçüm için diğer araçların çoğundan daha iyi olduğu ortaya çıktı.
İşte ROUGE puanının ortalamaları ve standart sapmaları tablosu:
| Aletler | Kastetmek | standart |
|---|---|---|
| trafik | 0.783 | 0.28 |
| tarama | 0.779 | 0.28 |
| jusText | 0.735 | 0.33 |
| kazan3 | 0.698 | 0.36 |
| okunabilirlik | 0.681 | 0.34 |
| ağ | 0.672 | 0.37 |
Standart sapmaların değerleri göz önüne alındığında, ekstraksiyonun kalitesinin büyük ölçüde değişebileceğini unutmayın. HTML'nin uygulanma şekli, etiketlerin tutarlılığı ve dilin uygun kullanımı, çıkarma sonuçlarında çok fazla varyasyona neden olabilir.
En iyi performansı gösteren üç araç, durum için “oncrawl” adlı şirket içi aracımız trafilatura ve jusText'tir. jusText, trafilatura tarafından yedek olarak kullanıldığından, ilk tercihimiz olarak trafilatura kullanmaya karar verdik. Ancak, ikincisi başarısız olduğunda ve sıfır kelime çıkardığında, kendi kurallarımızı kullanırız.
Trafilatura kodunun ayrıca birkaç yüz sayfada bir kıyaslama sunduğunu unutmayın. Çıkarılan içerikte belirli öğelerin bulunup bulunmadığına bağlı olarak kesinlik puanlarını, f1 puanını ve doğruluğu hesaplar. İki araç öne çıkıyor: trafilatura ve kaz3. Ayrıca okumak isteyebilirsiniz:
- Web'den içerik çıkarmak için doğru aracı seçme (2020)
- Github deposu: makale çıkarma kıyaslaması: açık kaynaklı kitaplıklar ve ticari hizmetler
Sonuçlar
HTML kodunun kalitesi ve sayfa türünün heterojenliği, kaliteli içeriğin çıkarılmasını zorlaştırır. The Pile ve GPT-Neo'nun arkasındaki EleutherAI araştırmacılarının keşfettiği gibi, mükemmel araçlar yoktur. Tüm genel bilgiler kaldırılmadığında, bazen kesilen içerik ile metinde kalan gürültü arasında bir değiş tokuş vardır.
Bu araçların avantajı, içerikten bağımsız olmalarıdır. Bu, içeriği çıkarmak için bir sayfanın HTML'sinden başka herhangi bir veriye ihtiyaç duymadıkları anlamına gelir. Oncrawl'ın sonuçlarını kullanarak, sitenin tüm sayfalarında belirli HTML bloklarının ortaya çıkma sıklıklarını kullanarak bunları standart olarak sınıflandırmak için hibrit bir yöntem hayal edebiliriz.
Web'de karşılaştığımız kıyaslamalarda kullanılan veri kümelerine gelince, bunlar genellikle aynı tür sayfalardır: haber makaleleri veya blog gönderileri. Metin içeriğinin çıkarılmasının bazen daha karmaşık olduğu sigorta, seyahat acentesi, e-ticaret vb. siteleri mutlaka içermezler.
Kıyaslamamızla ilgili olarak ve kaynak eksikliği nedeniyle, puanların daha ayrıntılı bir görünümünü elde etmek için otuz kadar sayfanın yeterli olmadığının farkındayız. İdeal olarak, kıyaslama değerlerimizi hassaslaştırmak için daha fazla sayıda farklı web sayfamız olmasını isteriz. Ayrıca goose3, html_text veya inscriptis gibi diğer araçları da dahil etmek istiyoruz.