
Python'da veri analizi için Google Arama Konsolu API'sinden veri ayıklayın
Yayınlanan: 2022-03-01Google Arama Konsolu (GSC), dizin kapsamı ve özellikle şu anda sıralamada olduğunuz sorgular hakkında bilgi edinmenize olanak sağladığı için SEO Uzmanları için kesinlikle en kullanışlı araçlardan biridir. Bunu bilen birçok insan, elektronik tabloları kullanarak GSC verilerini analiz eder ve programlama dilleri gibi araçlarla iyileştirme için çok daha fazla yer olduğunu anladığınız sürece sorun değil.
Ne yazık ki, GSC arayüzü hem görüntülenen satırlar (sadece 5000) hem de sadece 16 ay olan kullanılabilir süre açısından oldukça sınırlıdır. Bunun, bilgi edinme yeteneğinizi ciddi şekilde sınırlayabileceği ve daha büyük web siteleri için uygun olmadığı açıktır.
Python, GSC verilerini kolaylıkla almanıza ve geleneksel elektronik tablo yazılımında çok daha fazla çaba gerektiren daha karmaşık hesaplamaları otomatikleştirmenize olanak tanır.
Bu, Excel'deki en büyük sorunlardan biri olan satır sınırı ve hızı için çözümdür. Günümüzde, verileri analiz etmek için eskisinden çok daha fazla alternatifiniz var ve işte tam bu noktada Python devreye giriyor.
Bu öğreticiyi takip etmek için herhangi bir gelişmiş kodlama bilgisine ihtiyacınız yok, yalnızca bazı temel kavramları anlamanız ve Google Colab ile biraz pratik yapmanız yeterli.
Google Arama Konsolu API'sini kullanmaya başlama
Başlamadan önce, Google Arama Konsolu API'sini kurmak önemlidir. İşlem oldukça basit, tek ihtiyacınız olan bir Google hesabı. Adımlar aşağıdaki gibidir:
- Google Cloud Platform'da yeni bir proje oluşturun. Bir Google hesabınız olmalı ve eminim ki bir hesabınız var. Konsola gidin ve ardından yeni bir proje oluşturmak için en üstte bir seçenek bulmalısınız.
- Soldaki menüye tıklayın ve “API ve hizmetler”i seçin, başka bir ekrana gideceksiniz.
- En üstteki arama çubuğundan "Google Arama Konsolu API'sini" arayın ve etkinleştirin.
- Ardından “Kimlik Bilgileri” sekmesine geçin, API'yi kullanmak için bir tür izne ihtiyacınız var.
- Zorunlu olduğu için “rıza” ekranını yapılandırın. Kamuya açık olup olmaması, yapacağımız kullanım için önemli değil.
- Uygulama türü olarak “Masaüstü Uygulaması”nı seçebilirsiniz.
- Bu eğitim için OAuth 2.0 kullanacağız, bir json dosyası indirmelisiniz ve şimdi işiniz bitti.
Bu aslında çoğu insan için, özellikle de Google API'lerine alışkın olmayanlar için en zor kısımdır. Merak etmeyin, sonraki adımlar çok daha kolay ve daha az sorunlu olacak.
Python ile Google Arama Konsolu API'sinden veri alma
Benim tavsiyem, Jupyter Notebook veya Google Colab gibi bir not defteri kullanmanızdır. Gereksinimler hakkında endişelenmenize gerek olmadığı için ikincisi daha iyidir. Bu nedenle anlatacaklarım Google Colab'ı temel alıyor.
Başlamadan önce json dosyanızı aşağıdaki kodla Google Colab'a güncelleyin:
google.colab içe aktarma dosyalarından dosyalar.upload()
Ardından analizimiz için ihtiyaç duyacağımız tüm kütüphaneleri kuralım ve bu kod parçacığı ile daha iyi tablo görselleştirmesi yapalım:
%%ele geçirmek #gerekeni yükle !pip git+https://github.com/joshcarty/google-searchconsole yükleyin pandaları pd olarak içe aktar numpy'yi np olarak içe aktar matplotlib.pyplot'u plt olarak içe aktar google.colab'dan data_table'ı içe aktar !git klonu https://github.com/jroakes/querycat.git !pip kurulumu -r querycat/requirements_colab.txt !pip kurulum umap-öğren data_table.enable_dataframe_formatter() #daha iyi tablo görselleştirmesi için
Son olarak, uzun fonksiyonlara güvenmeden bunu yapmanın en kolay yolunu sunan searchconsole kitaplığını yükleyebilirsiniz. Kullandığım argümanlarla aşağıdaki kodu çalıştırın ve client_config dosyasının yüklenen json dosyasıyla aynı ada sahip olduğundan emin olun.
arama konsolunu içe aktar hesap = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', flow='console')
Uygulamayı yetkilendirmek için bir Google sayfasına yönlendirileceksiniz, Google hesabınızı seçin ve ardından alacağınız kodu kopyalayıp Google Colab çubuğuna yapıştırın.
Henüz bitirmedik, veriye ihtiyaç duyacağınız mülkü seçmelisiniz. Ne seçmeniz gerektiğini görmek için mülklerinizi account.webproperties aracılığıyla kolayca kontrol edebilirsiniz.
property_name = input('GSC'de listelendiği gibi web sitenizin adını girin: ')
web mülkü=hesap[str(özellik_adı)]
İşiniz bittiğinde, verilerimizi içeren bir nesne oluşturmak için özel bir işlev çalıştıracaksınız.
def extract_gsc_data(web özelliği, başlat, durdur, *args):
web özelliği Yok değilse:
print(f'{webproperty}' için veri ayıklanıyor)
gsc_data = webproperty.query.range(start, stop).dimension(*args).get()
gsc_data'yı döndür
başka:
print('Web özelliği bulunamadı, lütfen doğru olanı seçin')
dönüş Yok
Fonksiyonun fikri, daha önce tanımladığınız özelliği ve bir zaman çerçevesini, boyutlarla birlikte başlangıç ve bitiş tarihleri şeklinde almaktır.
Boyutları seçebilme seçimi, SEO Uzmanları için çok önemlidir çünkü belirli bir ayrıntı düzeyine ihtiyacınız olup olmadığını anlamanıza olanak tanır. Örneğin, bazı durumlarda tarih boyutunu almakla ilgilenmeyebilirsiniz.
Benim önerim, her zaman sorgu ve sayfa seçmektir, çünkü Google Arama Konsolu arayüzü bunları ayrı ayrı dışa aktarabilir ve her seferinde bunları birleştirmek çok can sıkıcıdır. Bu, Search Console API'sinin bir başka avantajıdır.
Bizim durumumuzda, zamanı hesaba katmanız gereken bazı ilginç senaryoları göstermek için doğrudan tarih boyutunu da alabiliriz.
ex = Extract_gsc_data(web özelliği, '2021-09-01', '2021-12-31', 'sorgu', 'sayfa', 'tarih')
Daha büyük mülkler için çok fazla beklemeniz gerekeceğini göz önünde bulundurarak uygun bir zaman dilimi seçin. Bu örnek için, ortalama olarak çoğu veri kümesinden değerli bilgiler elde etmek için yeterli olan 3 aylık bir zaman aralığını düşünüyorum.
Çok büyük miktarda veriyle uğraşıyorsanız bir haftayı bile seçebilirsiniz, bizim umursadığımız süreç.
Burada göstereceğim şey ya sentetik verilere dayanmaktadır ya da örneklere uygun olması adına değiştirilmiş gerçek verilere dayanmaktadır. Sonuç olarak, burada gördükleriniz tamamen gerçekçi ve gerçek dünya senaryolarını yansıtabilir.
Veri temizleme
Bilmeyenler için, verilerimizi olduğu gibi kullanamayız, doğru çalıştığımızdan emin olmak için bazı ekstra adımlar var. Her şeyden önce, nesnemizi Python'da veri analizinin temeli olduğu için aşina olmanız gereken bir veri yapısı olan Pandas veri çerçevesine dönüştürmeliyiz.
df = pd.DataFrame(veri=eski) df.head()
Head yöntemi, veri kümenizin ilk 5 satırını gösterebilir, verilerinizin nasıl göründüğüne bir göz atmak çok kullanışlıdır. Basit bir fonksiyon kullanarak kaç sayfamız olduğunu sayabiliriz.
Kopyaları kaldırmanın iyi bir yolu, bir nesneyi bir kümeye dönüştürmektir, çünkü kümeler yinelenen öğeler içeremez.
Kod parçacıklarının bazıları Hamlet Batista'nın defterinden ve bir diğeri Masaki Okazawa'dan esinlenmiştir.
Markalı terimleri kaldırma
Yapılacak ilk şey, markalı anahtar kelimeleri kaldırmaktır, markalı terimlerimizi içermeyen sorguları arıyoruz. Bunu özel bir işlevle yapmak oldukça basittir ve genellikle bir dizi markalı terime sahip olursunuz.
Gösteri amaçlı olarak hepsini filtrelemeniz gerekmez, ancak lütfen gerçek analizler için yapın. SEO'daki en önemli veri temizleme adımlarından biridir, aksi takdirde yanıltıcı sonuçlar sunma riskiniz vardır.
domain_name = str(input('Marka terimlerini virgülle ayırın: '))).replace(',', '|')
yeniden içe aktar
domain_name = re.sub(r"\s+", "", domain_name)
print('RegEx kullanarak tüm boşlukları kaldırın:\n')
df['Marka/Markasız'] = np.where(
df['query'].str.contains(domain_name), 'Marka', 'Markasız'
)
İki sınıf arasındaki farkı tanımak için veri setimize yeni bir sütun ekleyeceğiz. Toplam sorgu sayısını ne kadar hesapladıklarını tablolar veya barplotlar aracılığıyla görselleştirebiliriz.
Çok basit olduğu için size barplot'u göstermeyeceğim ve bu durumda bir tablonun daha iyi olduğunu düşünüyorum.
brand_count_df = df['Marka/Markasız'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['Yüzde'] = brand_count_df['sayımlar']/sum(brand_count_df['sayımlar'])
pd.options.display.float_format = '{:.2%}'.format
brand_count_df
Veri kümenizden ne kadar çıkaracağınız konusunda bir fikir edinmek için markalı ve markasız anahtar kelimeler arasındaki oranı hızlıca görebilirsiniz. Burada ideal bir oran yoktur, ancak kesinlikle markasız anahtar kelimelerin yüzdesinin daha yüksek olmasını isteyebilirsiniz.
Ardından, markalı olarak işaretlenen tüm satırları bırakıp diğer adımlara geçebiliriz.
#yalnızca markalı olmayan anahtar kelimeleri seçin df = df.loc[df['Marka/Markasız'] == 'Markasız']
Eksik değerlerin doldurulması ve diğer adımlar
Veri kümenizde eksik değerler (veya jargonda NA'lar) varsa, birkaç seçeneğiniz vardır. En yaygın olanları ya hepsini bırakmak ya da 0 gibi bir yer tutucu değeri veya o sütunun ortalaması ile doldurmaktır.
Doğru bir cevap yoktur ve her iki yaklaşımın da artıları ve eksileri ile riskleri vardır. Google Arama Konsolu verileri için en iyi tavsiyem, bazı metriklerin etkisini hafife almak için 0 gibi bir yer tutucu değeri koymaktır.
df.fillna(0, yerinde = Doğru)
Gerçek veri analizine geçmeden önce, özelliklerimizi yani veri setimizin sütunlarını ayarlamamız gerekiyor. Bazı havalı pivot tablolar için kullanmak istediğimizden, konum özellikle ilgi çekicidir.
Konumu, amacımıza hizmet eden bir tam sayı olacak şekilde yuvarlayabiliriz.
df['position'] = df['position'].round(0).astype('int64')
Yukarıda açıklanan diğer tüm temizlik adımlarını izlemeli ve ardından tarih sütununu ayarlamalısınız.
Pandaların yardımıyla ayları ve yılları çıkarıyoruz. Daha kısa bir zaman dilimiyle çalışıyorsanız bu kadar spesifik olmanıza gerek yok, bu yarım yılı hesaba katan bir örnek.
#tarihi uygun biçime dönüştür df['date'] = pd.to_datetime(df['date']) #ayı çıkar df['ay'] = df['tarih'].dt.ay #yıl ayıklayın df['yıl'] = df['tarih'].dt.yıl
[Ebook] Veri SEO'su: Sonraki Büyük Macera
 e-kitabı okuyun
e-kitabı okuyunKeşfedici Veri Analizi
Python'un en büyük avantajı, Excel'de yaptığınız şeyleri çok daha fazla seçenekle ve daha kolay yapabilmenizdir. Her analistin çok iyi bildiği bir şeyle başlayalım: pivot tablolar.
Konum grubu başına ortalama TO'yu analiz etme
Ort. Konum grubu başına TO, bir web sitesinin genel durumunu anlamanıza izin verdiği için en anlayışlı etkinliklerden biridir. Pivotu uygulayın ve sonra çizelim.
pd.options.display.float_format = '{:.2%}'.format
sorgu_analiz = df.pivot_table(index=['konum'], değerler=['ctr'], aggfunc=['ortalama'])
query_analysis.sort_values(by=['position'], artan=True).head(10)
ax = query_analysis.head(10).plot(tür='bar')
ax.set_xlabel('Ort. Konum')
ax.set_ylabel('TO')
ax.set_title('Ort. konuma göre TO')
ax.grid('açık')
ax.get_legend().remove()
plt.xticks(döndürme=0)
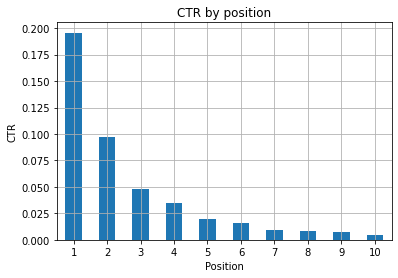
Şekil 1: Anormallikleri tespit etmek için konuma göre TO'yu temsil etme.
Buradaki ideal senaryo, grafiğin sol tarafında daha iyi bir TO'ya sahip olmaktır, çünkü normalde Konum 1'in sonuçları çok daha yüksek bir TO'ya sahip olmalıdır. Yine de dikkatli olun, ilk 3 noktanın beklenenden daha düşük TO'ya sahip olduğu bazı durumlarla karşılaşabilirsiniz ve araştırmanız gerekir.
Lütfen, örneğin 11. konumun birinci olmaktan daha iyi olduğu durumlar gibi uç durumları da göz önünde bulundurun. Search Console için Google belgelerinde açıklandığı gibi, bu ölçüm ilk başta düşündüğünüz sırayı takip etmiyor.
Ayrıca, bağlantının konumu her seferinde değiştiğinden ve %100 doğruluk elde etmenin imkansız olduğu için bu metriğin bir ortalama olduğunu da ekliyor.
Bazen sayfalarınız üst sıralarda yer alır ancak yeterince inandırıcı değildir, bu nedenle başlığı düzeltmeyi deneyebilirsiniz. Bu üst düzey bir genel bakış olduğundan, ayrıntılı farklılıklar görmeyeceksiniz, bu nedenle bu sorun büyük ölçekteyse hızlı hareket etmeyi bekleyin.
Ayrıca, daha düşük konumlardaki bir grup sayfanın, daha iyi noktalardaki sayfalardan daha yüksek bir ortalama TO'ya sahip olduğunu unutmayın.
Bu nedenle, garip kalıpları tespit etmek için analizinizi 15 veya daha fazla konuma genişletmek isteyebilirsiniz.
Konum başına sorgu sayısı ve SEO çabalarının ölçülmesi
Sıraladığınız sorgulardaki artış her zaman iyi bir sinyaldir, ancak gelecekte daha iyi sıralamalar anlamına gelmez. Sorgu sayısı, sıraladığınız sorgu sayısını sayma işlemidir ve GSC verileriyle yapabileceğiniz en önemli görevlerden biridir.
Pivot tablolar bir kez daha çok yardımcı oluyor ve sonuçları çizebiliriz.
rank_queries = df.pivot_table(index=['konum'], değerler=['sorgu'], aggfunc=['say']) rank_queries.sort_values(by=['position']).head(10)
Bir SEO Uzmanı olarak istediğiniz şey, en sol tarafta, en üst noktalarda daha yüksek bir sorgu sayısına sahip olmaktır. Bunun nedeni oldukça doğaldır, yüksek konumlar ortalama olarak daha iyi TO elde eder ve bu da sayfanızı daha fazla kişinin tıklamasına neden olabilir.
balta = rank_queries.head(10).plot(tür='bar')
ax.set_ylabel('Sorgu sayısı')
ax.set_xlabel('Konum')
ax.set_title('Sıralama dağılımı')
ax.grid('açık')
ax.get_legend().remove()
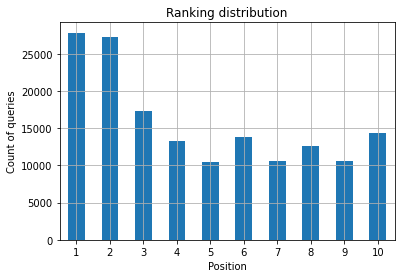
Şekil 2: Pozisyona göre kaç tane sorgum var?
Önemsediğiniz şey, zaman geçtikçe en üst sıralardaki sorgu sayısını artırmaktır.
Tarih boyutuyla oynama
Belirli bir zaman aralığında tıklamaların nasıl değiştiğini görelim, önce tıklamaların toplamını alalım:
clicks_sum = df.groupby('date')['tıklamalar'].sum()
Verileri tarih boyutuna göre gruplandırıyoruz ve her biri için tıklamaların toplamını alıyoruz, bu bir tür özetleme.
Artık elimizde olanı çizmeye hazırız, kod görselleştirmeyi geliştirmek için oldukça uzun olacak, korkmayın.
# Dönem boyunca tıklamaların toplamı
%config InlineBackend.figure_format = 'retina'
matplotlib.pyplot ithalat rakamından
şekil(şekil=(8, 6), dpi=80)
balta = clicks_sum.plot(color='red')
ax.grid('açık')
ax.set_ylabel('Tıklamaların toplamı')
ax.set_xlabel('Ay')
ax.set_title('Tıklamaların aylık olarak nasıl değiştiği')
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('italik')
xlab.set_size(10)
ylab.set_style('italik')
ylab.set_size(10)
ttl = ax.başlık
ttl.set_weight('kalın')
ax.spines['sağ'].set_color((.8,.8,.8))
ax.spines['top'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords(-.15, .50)
ax.fill_between(clicks_sum.index, clicks_sum.values, facecolor='sarı')
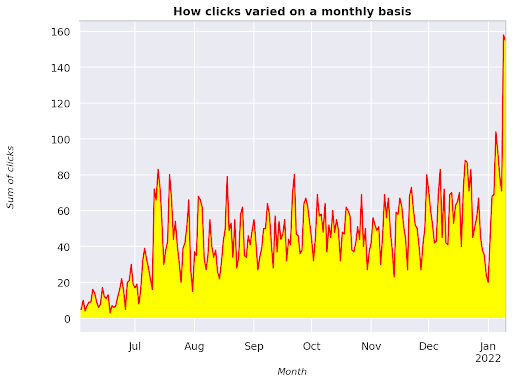

Şekil 3: Ay değişkenine göre tıklamaların toplamını çizme
Bu, Haziran 2021'den başlayıp doğrudan Ocak 2022'nin yarısına giden bir örnektir. Yukarıda gördüğünüz tüm satırlar bu görselleştirmeyi daha güzel hale getirme rolüne sahiptir, ne olduğunu görmek için onunla oynamayı deneyebilirsiniz.
Konum başına sorgu sayısı, aylık anlık görüntü
Python'da çizebileceğimiz bir başka harika görselleştirme, basit bir çubuk grafiğinden bile daha görsel olan ısı haritasıdır. Size zaman içinde ve konumuna göre sorgu sayısını nasıl görüntüleyeceğinizi göstereceğim.
seaborn'u sns olarak içe aktar sns.set_theme() df_new = df.loc[(df['position'] <= 10) & (df['year'] != 2022),:] # Örnek uçuş veri setini yükleyin ve uzun forma dönüştürün df_heat = df_new.pivot_table(index = "konum", sütunlar = "ay", değerler = "sorgu", aggfunc='count') # Her hücredeki sayısal değerlerle bir ısı haritası çizin f, ax = plt.subplots(figsize=(20, 12)) x_axis_labels = ["Eylül", "Ekim", "Kasım", "Aralık"] sns.heatmap(df_heat, annot=True, linewidths=.5, ax=ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'Ay', ylabel='Konum', başlık = 'Konum başına sorgu sayısı zamanla nasıl değişir') #rotate Etiketleri daha okunaklı hale getirmek için Konumlandırın plt.yticks(döndürme=0)
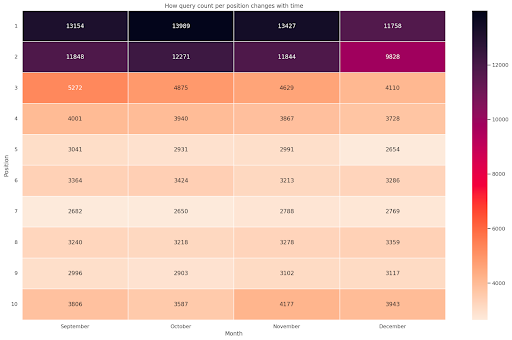
Şekil 4: Konum ve aya göre sorgu sayımının ilerlemesini gösteren ısı haritası.
Bu benim favorilerimden biri, ısı haritaları bu örnekte olduğu gibi pivot tabloları görüntülemek için oldukça etkili olabilir. Dönem 4 ayı kapsıyor ve yatay olarak okursanız zaman geçtikçe sorgu sayısının nasıl değiştiğini görebilirsiniz. 10. konum için Eylül'den Aralık'a kadar biraz artış var, ancak 2. konum için mor renkle gösterildiği gibi çarpıcı bir düşüş var.
Aşağıdaki senaryoda, çarpıcı biçimde olağandışı olabilen sorguların çoğu en üst sıralarda yer almaktadır. Böyle bir durumda, varsa olası markalı terimleri arayarak geri dönüp veri çerçevesini analiz etmek isteyebilirsiniz.
Koddan da görebileceğiniz gibi, mantığı anladığınız sürece karmaşık çizimler yapmak o kadar da zor değil.
“Doğru” şeyleri yapıyorsanız, sorgu sayısı zamanla artmalıdır ve farkı iki farklı zaman diliminde çizebiliriz. Sağladığım örnekte, özellikle daha yüksek bir TO'ya sahip olmanız gereken en üst konumlar için olduğu gibi, durumun böyle olmadığı açıktır.
Bazı temel NLP kavramlarının tanıtılması
Doğal Dil İşleme (NLP), SEO için bir nimettir ve temel algoritmaları uygulamak için uzman olmanıza gerek yoktur. N-gramlar, size GSC verileriyle içgörü kazandırabilecek en güçlü ancak basit fikirlerden biridir.
N-gramlar, bitişik harf, hece veya kelime dizileridir. Analizimiz için ölçü birimi kelimeler olacaktır. Bir n-gram, bitişik elemanlar iki (bir çift) olduğunda bigram ve üç ise trigram vb. olarak adlandırılır. Farklı kombinasyonlarla denemenizi ve en fazla 5 grama kadar çıkmanızı öneririm.
Bu sayede rakiplerinizin sayfalarında en sık kullanılan cümleleri tespit edebilir veya kendinizinkini değerlendirebilirsiniz. Google, kelime öbeği tabanlı dizine eklemeye güvenebileceğinden, bu konuyu içeren Google patentlerinin gösterdiği gibi, tek tek anahtar kelimeler yerine cümleler için optimize etmek daha iyidir.
Yukarıdaki sayfada Bill Slawski'nin kendisi tarafından belirtildiği gibi, ilgili terimleri anlamanın değeri, optimizasyon ve kullanıcılarınız için çok değerlidir.
nltk kütüphanesi, NLP uygulamaları için çok ünlüdür ve bize İngilizce gibi belirli bir dilde durdurma kelimelerini kaldırma imkanı verir. Bunları kaldırmak istediğiniz gürültü olarak düşünün, aslında makaleler ve çok sık kullanılan kelimeler bir metni anlamada herhangi bir değer katmaz.
nltk'yi içe aktar
nltk.download('durdurma sözcükleri')
nltk.corpus'tan stopwords içe aktarma
stoplist = stopwords.words('ingilizce')
sklearn.feature_extraction.text'ten CountVectorizer'ı içe aktarın
c_vec = CountVectorizer(stop_words=stoplist, ngram_range=(2,3))
# ngram matrisi
ngrams = c_vec.fit_transform(df['sorgu'])
# ngramların sıklığı
say_değerleri = ngrams.toarray().sum(axis=0)
# ngram listesi
kelime hazinesi = c_vec.vocabulary_
df_ngram = pd.DataFrame(sorted([(count_values[i],k) for k,i in vocab.items()], reverse=True)
.rename(sütunlar={0: 'sıklık', 1:'bigram/trigram'})
df_ngram.head(20).style.background_gradient()
Sorgu sütununu alırız ve bigramları ve bunların oluşum sayılarını depolayan bir veri çerçevesi oluşturmak için bigramların sıklığını sayarız.
Bu adım aslında rakiplerin web sitelerini de analiz etmek için çok önemlidir. Yüksek dereceli sayfalarda farklı desenler görüp görmediğinizi görmek için her seferinde n'yi ayarlayarak metinlerini kazıyabilir ve en yaygın n-gramların neler olduğunu kontrol edebilirsiniz.
Bunu bir an için düşünürseniz, tek bir anahtar kelime size bağlam hakkında hiçbir şey söylemediğinden çok daha mantıklı olur.
Düşük asılı meyveler
Yapılabilecek en güzel şeylerden biri, iyi sonuçları olabildiğince erken görmek için kolayca geliştirebileceğiniz sayfalar olan düşük sarkan meyveleri kontrol etmektir. Bu, paydaşlarınızı ikna etmek için her SEO projesinin ilk adımlarında çok önemlidir. Bu nedenle, bu tür sayfalardan yararlanma fırsatı varsa, sadece yapın!
Bir sayfayı bu şekilde değerlendirme kriterlerimiz, gösterimler ve TO için niceliklerdir. Başka bir deyişle, gösterimlerin ilk %80'inde yer alan, ancak en düşük TO'yu alan %20'de bulunan satırları filtreliyoruz. Bu satırlar, geri kalanın %80'inden daha kötü bir TO'ya sahip olacak.
top_impressions = df[df['gösterimler'] >= df['gösterimler'].quantile(0.8)]
(top_impressions[top_impressions['ctr'] <= top_impressions['ctr'].quantile(0.2)].sort_values('gösterimler', artan = Yanlış))
Artık, Gösterimlere göre azalan düzende sıralanmış tüm fırsatları içeren bir listeniz var.
Düşük asılı bir meyvenin ne olduğunu tanımlamak için web sitenizin ihtiyaçlarına ve boyutuna göre başka kriterler düşünebilirsiniz.
Daha küçük web siteleri için daha yüksek yüzdeler aramayı düşünebilirsiniz, oysa büyük web sitelerinde kullandığım kriterlerle zaten bol miktarda bilgi edinmiş olmalısınız.
[Ebook] Teknik bilgisi olmayanlar için Teknik SEO
 e-kitabı okuyun
e-kitabı okuyunQuerycat ile tanışın: sınıflandırma ve ilişkilendirmeler
Querycat, anahtar kelimeleri kümelemek için birliktelik kuralı madenciliği ve çok daha fazlasını içeren basit ama güçlü bir kitaplıktır. Bu tür analizlerde sadece çağrışımları daha değerli oldukları için göstereceğim.
Querycat GitHub deposuna göz atarak bu harika kitaplık hakkında daha fazla bilgi edinebilirsiniz.
Birliktelik kuralı öğrenme hakkında kısa tanıtım
Birliktelik kuralı öğrenme, öğe kümeleri arasında ilişkileri ve birlikte oluşumları tanımlayan kuralları bulmak için bir yöntemdir. Bu, kümeleme adı verilen başka bir denetimsiz makine öğrenimi yönteminden biraz farklıdır.
Nihai hedef aynı, web sitemizin bazı konularda nasıl çalıştığını anlamak için anahtar kelime kümeleri elde etmek.
Querycat size iki algoritma arasında seçim yapma imkanı verir: Apriori ve FP-Growth. Daha iyi performans için ikincisini seçeceğiz, böylece birinciyi görmezden gelebilirsiniz.
FP-Growth, veri kümelerinde sık görülen kalıpları bulmak için Apriori'nin geliştirilmiş bir sürümüdür. Birliktelik kuralı öğrenme, e-ticaret işlemleri için de çok faydalıdır, örneğin insanların birlikte ne satın aldıklarını anlamak ilginizi çekebilir.
Bu durumda, tüm odak noktamız sorgular, ancak bahsettiğim diğer uygulama, Google Analytics verileri için başka bir yararlı fikir olabilir.
Bu algoritmaları veri yapısı perspektifinden açıklamak oldukça zor ve bence SEO görevleriniz için gerekli değil. Parametrelerin ne anlama geldiğini anlamak için bazı temel kavramları açıklayacağım.
2 algoritmanın 3 ana unsuru şunlardır:
- Destek – Bir öğenin veya bir öğe kümesinin popülerliğini ifade eder. Teknik bir deyişle, X sorgusu ve Y sorgusunun birlikte göründüğü işlem sayısının toplam işlem sayısına bölümüdür.
Ayrıca, seyrek görülen öğeleri kaldırmak için eşik olarak kullanılabilir. İstatistiksel önemi ve performansı artırmak için çok kullanışlıdır. İyi bir minimum destek belirlemek çok iyidir. - Güven – bunu terimlerin birlikte ortaya çıkma olasılığı olarak düşünebilirsiniz.
- Artış – (1. terim ve 2. terim) desteği ile 1. terimin desteği arasındaki oran. Terimler arasındaki ilişki hakkında fikir edinmek için değerine bakabiliriz. 1'den büyükse terimler bağıntılıdır; 1'den küçükse, terimlerin bir ilişkisi olması olası değildir: eğer artış tam olarak 1 (veya yakın) ise, anlamlı bir ilişki yoktur.
Kütüphanenin yazarı tarafından yazılan querycat hakkında bu makalede daha fazla ayrıntı verilmiştir.
Şimdi pratik kısma geçmeye hazırız.
sorgu kedisini içe aktar
query_cat = querycat.Categorize(df, 'query', min_support=10, alg='fpgrowth')
dfgrouped = df.groupby('category').agg(sumclicks = ('tıklamalar', 'sum')).sort_values('sumclicks', artan=Yanlış)
#15 tıklamadan az olan kategorileri filtrelemek için grup oluştur (keyfi sayı)
filtre grubu = dfgrouped[dfgrouped['sumclicks'] > 15]
filtre grubu
#filtre uygula
df = df.merge(filtre grubu, on=['kategori','kategori'], nasıl='iç')
Süreçte daha az sıklıkta kategorileri filtreledik, benim durumumda bir kriter olarak 15 seçtim. Bu sadece keyfi bir sayıdır, arkasında hiçbir kriter yoktur.
Aşağıdaki snippet ile kategorilerimizi kontrol edelim:
df['kategori'].value_counts()
Peki ya en çok tıklanan 10 kategori? Her biri için kaç tane sorgumuz olduğunu kontrol edelim.
df.groupby('category').sum()['tıklamalar'].sort_values(artan=Yanlış).head(10)
Seçilecek sayı isteğe bağlıdır, iyi bir grup yüzdesini filtreleyen birini seçtiğinizden emin olun. Potansiyel bir fikir, küçük grupları hariç tutmak istemeniz koşuluyla, gösterimlerin medyanını elde etmek ve en düşük %50'yi düşürmektir.
Kümeleri alma ve çıktıyla ne yapılacağı
Benim tavsiyem, FP-Growth'u tekrar çalıştırmaktan kaçınmak için yeni veri çerçevenizi dışa aktarmanız, lütfen faydalı zamandan tasarruf etmek için yapın.
Kümeleriniz olur olmaz, hangi alanların en fazla iyileştirmeye ihtiyaç duyduğunu değerlendirmek için her biri için tıklamaları ve gösterimleri bilmek istersiniz.
grouped_df = df.groupby('category')[['tıklamalar', 'gösterimler']].agg('toplam')
Bazı veri manipülasyonlarıyla ilişkilendirme sonuçlarımızı iyileştirebilir ve her küme için tıklamalar ve gösterimler elde edebiliriz.
group_ex = df.groupby(['category'])['query'].apply(' | '.join).reset_index()
#yinelenen sorguları kaldırın ve ardından bunları alfabetik olarak sıralayın
group_ex['query'] = group_ex['query'].apply(lambda x: ' | '.join(sorted(list(set(x.split('|'))))))
df_final = group_ex.merge(grouped_df, on=['category', 'category'], how='inner')
df_final.head()
Artık, tıklamalar ve gösterimlerle birlikte tüm anahtar kelime kümelerinizi içeren bir CSV dosyanız var.
#csv dosyasını kaydedin ve yerel makinenize indirin. Safari kullanıyorsanız, çalışmayabileceğinden bu dosyaları indirmek için lütfen Chrome'a geçmeyi düşünün.
df_final.to_csv('clusters_queries.csv')
files.download('clusters_queries.csv')
Aslında, kümeleme için daha iyi yöntemler var, bu sadece, anında kullanım için birden çok görevi gerçekleştirmek için querycat'i nasıl kullanabileceğinize dair bir örnek. Buradaki ana amaç, özellikle çok fazla bilgiye sahip olmadığınız yeni web siteleri için mümkün olduğunca çok bilgi edinmektir.
Şu anda en iyi yaklaşımlar anlambilim içerir, bu nedenle kümelemeye odaklanmak istiyorsanız, grafikleri veya yerleştirmeleri öğrenmeyi düşünmenizi öneririm.
Ancak, acemi iseniz bunlar ileri düzey konulardır ve çevrimiçi olarak sunulan önceden oluşturulmuş bazı Streamlit uygulamalarını deneyebilirsiniz.
Tarama Verileri³
 Daha fazla bilgi edin
Daha fazla bilgi edinSonuç ve sırada ne var
Python, web sitenizi analiz etmede önemli bir yardım sunabilir ve veri temizleme, görselleştirme ve analizi tek bir yerde birleştirmenize yardımcı olabilir. GSC API'den veri çıkarmak, daha gelişmiş görevler için kesinlikle gereklidir ve veri otomasyonuna "yumuşak" bir giriştir.
Python ile çok daha gelişmiş hesaplamalar yapabilirsiniz ama benim tavsiyem SEO değeri açısından neyin mantıklı olduğunu kontrol etmenizdir.
Örneğin, web sitenizin daha fazla sorgu için dikkate alınmasını istediğinizden, Sorgu Sayısı uzun vadede bir bütün olarak çok daha önemlidir.
Not defterlerini kullanmak, kodları yorumlarla paketlemek için büyük bir yardımcıdır ve bu, Google Colab'a alışmanızı önermemin ana nedenidir.
En iyi fikirler farklı veri kümelerinin birleştirilmesinden geldiğinden, bu veri analizinin size sunabileceklerinin yalnızca başlangıcıdır.
Google Arama Konsolu başlı başına güçlü bir araçtır ve tamamen ücretsizdir, ondan alabileceğiniz pratik bilgi miktarı emin ellerde neredeyse sınırsızdır.