
A/B Testinin İstatistiksel Önemi: Bir Test Nasıl ve Ne Zaman Sonlandırılır
Yayınlanan: 2020-05-22
Convert müşterileri tarafından yürütülen 28.304 denemeyi içeren son analizimizde, denemelerin yalnızca %20'sinin % 95 istatistiksel anlamlılık düzeyine ulaştığını gördük. Econsultancy, 2018 optimizasyon raporunda da benzer bir eğilim keşfetti. Katılımcıların üçte ikisi, deneylerinin yalnızca %30'unda veya daha azında "açık ve istatistiksel olarak anlamlı bir kazanan" görüyor.
Bu nedenle çoğu deney (%70-80) ya sonuçsuzdur ya da erken durdurulmuştur.
Bunlardan, erken durdurulanlar, optimize ediciler uygun gördüklerinde deneyleri sonlandırma çağrısını aldıkları için ilginç bir durum oluşturuyor. Bunu, açık bir kazanan (veya kaybeden) veya açıkça önemsiz bir testi "görebildiklerinde" yaparlar. Genellikle, bunu haklı çıkaracak bazı verileri de vardır.
Optimize edicilerin %50'sinin deneyleri için standart bir "durma noktası" olmadığı göz önüne alındığında, bu çok şaşırtıcı gelmeyebilir. Çoğu için, belirli bir test hızını (XXX test/ay) sürdürme baskısı ve rekabette üstünlük sağlama yarışı sayesinde bunu yapmak bir zorunluluktur.
Ayrıca olumsuz bir denemenin gelire zarar verme olasılığı da vardır. Kendi araştırmamız, kazanmayan deneylerin ortalama olarak dönüşüm oranında %26'lık bir düşüşe neden olabileceğini göstermiştir!
Tüm söylenenler, deneyleri erken bitirmek hala riskli…
… doğru örneklem boyutuyla desteklenen deneyi amaçlanan uzunlukta çalıştırma olasılığını bıraktığından, sonucu farklı olabilirdi.
Peki deneyleri erken bitiren ekipler, onları bitirme zamanının geldiğini nasıl biliyor? Çoğu için cevap, kaliteden ödün vermeden karar vermeyi hızlandıran durdurma kuralları tasarlamakta yatar.
Geleneksel durma kurallarından uzaklaşmak
Web deneyleri için 0,05'lik bir p değeri standart olarak hizmet eder. Bu yüzde 5 hata toleransı veya %95 istatistiksel anlamlılık düzeyi, optimize edicilerin testlerinin bütünlüğünü korumalarına yardımcı olur. Sonuçların tesadüfi değil, gerçek sonuçlar olmasını sağlayabilirler.
Sabit ufuk testi için geleneksel istatistiksel modellerde - test verilerinin belirli bir zamanda veya belirli sayıda ilgili kullanıcıda yalnızca bir kez değerlendirildiği - p-değeriniz 0,05'ten düşük olduğunda bir sonucun önemli olduğunu kabul edersiniz. Bu noktada, kontrol ve tedavinizin aynı olduğu ve gözlemlenen sonuçların tesadüfi olmadığı şeklindeki sıfır hipotezini reddedebilirsiniz.
Verilerinizi toplandıkça değerlendirme olanağı sağlayan istatistiksel modellerin aksine, bu tür test modelleri, çalışırken denemenizin verilerine bakmanızı yasaklar. Peeking olarak da bilinen bu uygulama, bu tür modellerde önerilmez çünkü p değeri neredeyse her gün dalgalanır. Bir deneyin bir gün önemli olacağını ve ertesi gün p değerinin artık önemli olmadığı bir noktaya yükseleceğini göreceksiniz.
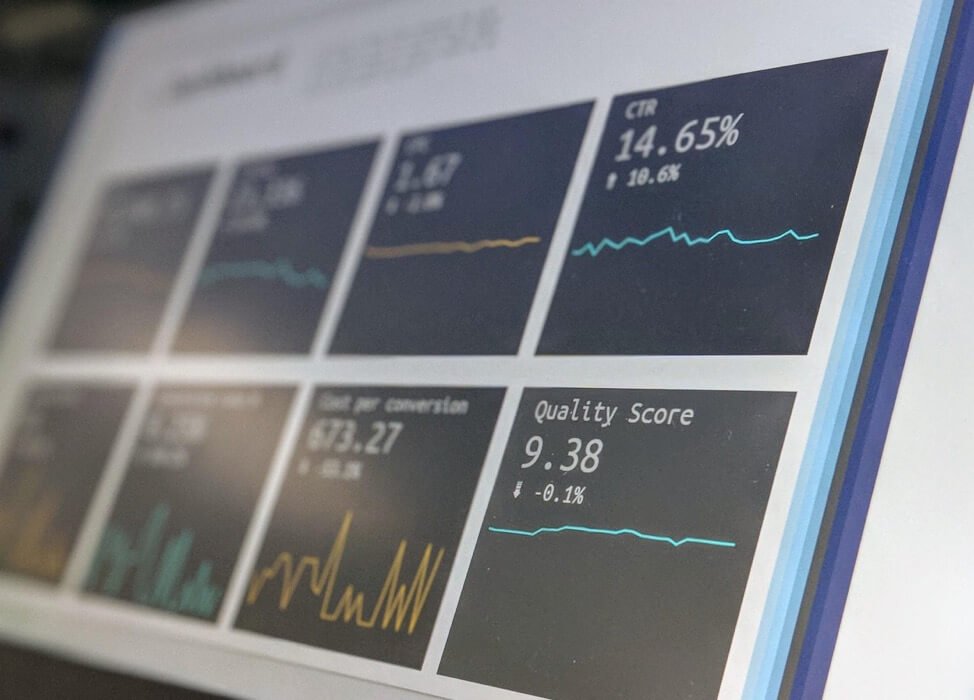
Yüz (20 günlük) deney için çizilen p değerlerinin simülasyonları; sadece 5 deney 20 günlük işarette gerçekten önemli olurken, çoğu zaman ara sıra <0,05 kesme noktasına ulaştı.
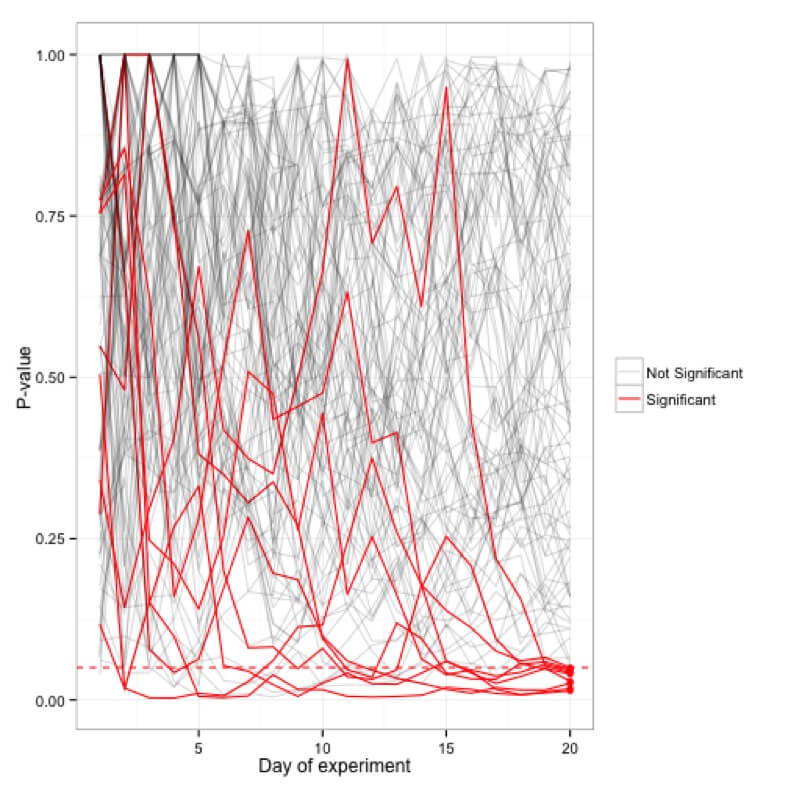
Arada deneylerinize göz atmak, var olmayan sonuçları gösterebilir. Örneğin, aşağıda 0,1 anlamlılık düzeyi kullanan bir A/A testiniz var. A/A testi olduğu için kontrol ve tedavi arasında fark yoktur. Bununla birlikte, devam eden deney sırasında 500 gözlemden sonra, bunların farklı olduğu ve sıfır hipotezinin reddedilebileceği sonucuna varma şansı %50'nin üzerindedir:
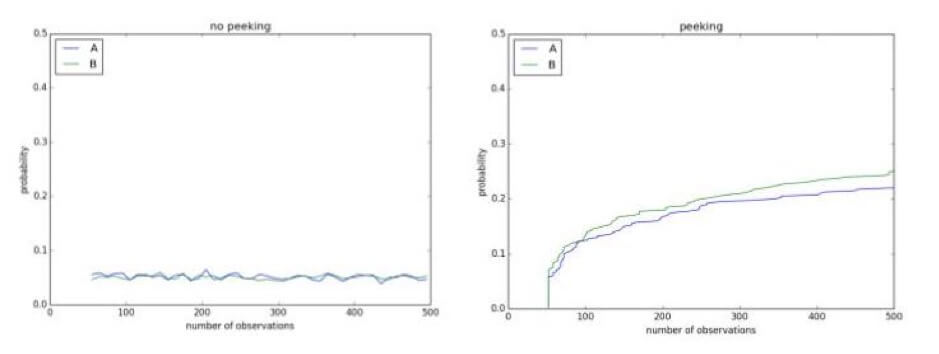
Burada, p-değerinin, ara dönemde birden çok kez anlamlılık bölgesine düştüğü ve sonunda sınırdan çok daha fazla olduğu 30 günlük bir A/A testinden bir tane daha var:
Sabit bir ufuk denemesinden bir p-değerini doğru şekilde raporlamak, önceden sabit bir numune boyutu veya test süresi taahhüt etmeniz gerektiği anlamına gelir. Bazı ekipler, bu deneme durdurma ölçütüne ve amaçlanan uzunluğa belirli sayıda dönüşüm de ekler.
Ancak buradaki sorun, bu standart uygulamayı kullanarak optimum durdurma için her bir deneyi beslemek için yeterli test trafiğine sahip olmanın çoğu web sitesi için zor olmasıdır.
İsteğe bağlı durdurma kurallarını destekleyen sıralı test yöntemlerinin kullanılması burada yardımcı olur.
Daha hızlı kararlar alınmasını sağlayan esnek durdurma kurallarına doğru ilerlemek
Sıralı test yöntemleri, esnek durdurma kurallarıyla, deneylerinizin verilerini göründüğü gibi kullanmanıza ve kazananları daha erken tespit etmek için kendi istatistiksel anlamlılık modellerinizi kullanmanıza olanak tanır.
En yüksek CRO olgunluğu seviyelerindeki optimizasyon ekipleri, bu tür testleri desteklemek için genellikle kendi istatistiksel metodolojilerini tasarlar. Bazı A/B test araçları da bunu içlerine yerleştirir ve bir sürümün kazanıyor gibi görünüp görünmediğini önerebilir. Bazıları, özel değerlerinizle ve daha fazlasıyla istatistiksel anlamlılığınızın nasıl hesaplanmasını istediğiniz konusunda size tam kontrol sağlar. Böylece devam eden bir deneyde bile kazananı görebilir ve belirleyebilirsiniz.

A/B testi istatistikleri üzerine popüler CXL kursunun istatistikçisi, yazarı ve eğitmeni olan Georgi Georgiev, ara analizlerin sayısı ve zamanlamasında esneklik sağlayan bu tür sıralı test yöntemlerinde uzmandır:
“ Sıralı testler, kazanan bir varyantı erken devreye alarak kârınızı en üst düzeye çıkarmanıza ve aynı zamanda bir kazanan üretme olasılığı düşük olan testleri mümkün olduğunca erken durdurmanıza olanak tanır. İkincisi, kalitesiz varyantlardan kaynaklanan kayıpları en aza indirir ve varyantların kontrolden daha iyi performans gösterme olasılığının düşük olduğu durumlarda testi hızlandırır. İstatistiksel olarak titizlik her durumda korunur. ”
Georgiev, bir deney devam ederken bir kazananı tespit edebilecek bir model için ekiplerin sabit örnek test modellerini atmasına yardımcı olan bir hesap makinesi üzerinde bile çalıştı. Modeli birçok istatistiği hesaba katar ve kaliteden ödün vermeden standart istatistiksel anlamlılık hesaplamalarından yaklaşık %20-80 daha hızlı testleri çağırmanıza yardımcı olur.
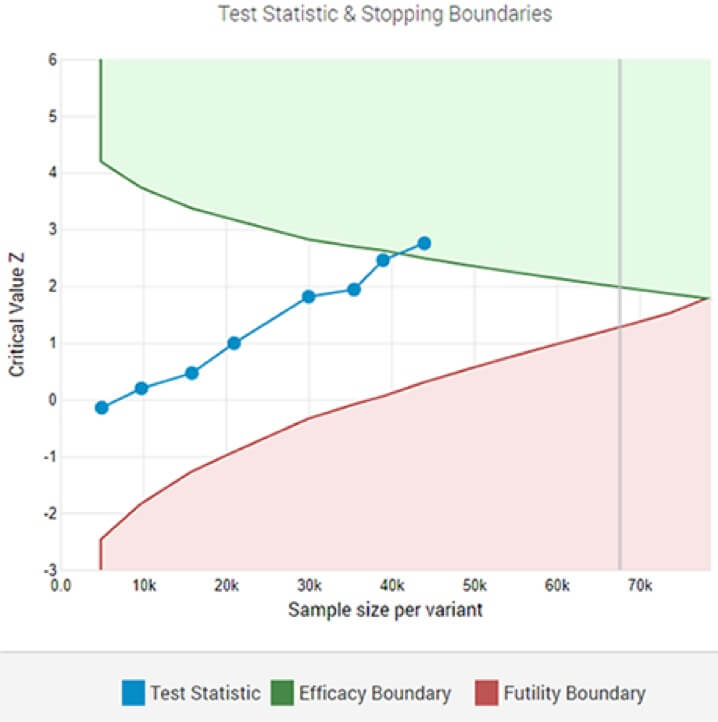
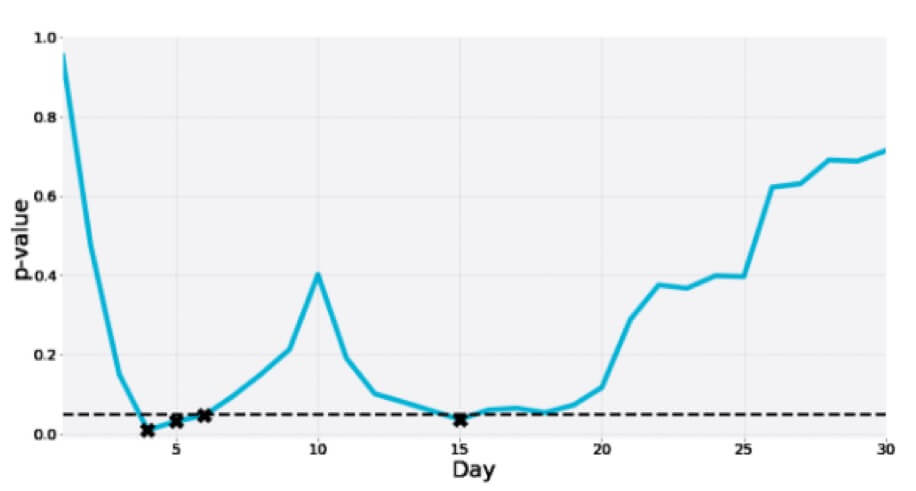
8. ara analizden sonra belirlenen anlamlılık eşiğinde istatistiksel olarak anlamlı bir kazananı gösteren uyarlanabilir bir A/B testi.
Bu tür testler, karar verme sürecinizi hızlandırabilse de, ele alınması gereken önemli bir husus vardır: deneyin gerçek etkisi . Arada bir deneyi bitirmek, onu fazla tahmin etmenize neden olabilir.
Georgiev, etki büyüklüğü için düzeltilmemiş tahminlere bakmak tehlikeli olabilir, diye uyarıyor. Bunu önlemek için onun modeli, ara izleme nedeniyle oluşan önyargıyı hesaba katan ayarlamaları uygulamak için yöntemler kullanır. Çevik analizlerinin "durma aşamasına ve istatistiğin gözlenen değerine (varsa, aşma) bağlı olarak" tahminleri nasıl ayarladığını açıklıyor. Aşağıda, yukarıdaki testin analizini görebilirsiniz: (Tahmini kaldırmanın gözlemlenenden nasıl daha düşük olduğuna ve aralığın bunun etrafında ortalanmadığına dikkat edin.)
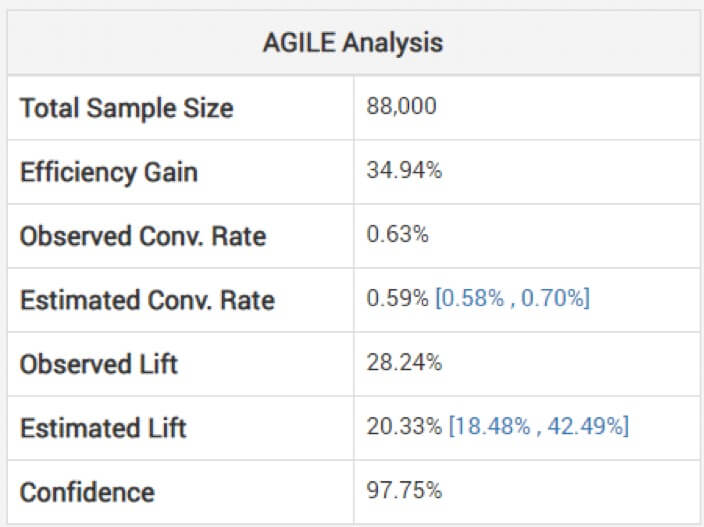
Bu nedenle, amaçlanandan daha kısa olan denemenize dayanarak bir kazanç göründüğü kadar büyük olmayabilir.
Kaybın da hesaba katılması gerekiyor, çünkü yine de hatalı bir şekilde kazananı çok erken aramış olabilirsiniz. Ancak bu risk, sabit ufuk testinde bile mevcuttur. Bununla birlikte, deneyleri daha uzun süre devam eden sabit bir ufuk testine kıyasla erken çağırırken dış geçerlilik daha büyük bir endişe kaynağı olabilir. Ancak bu, Georgiev'in açıkladığı gibi, “ daha küçük örneklem boyutunun ve dolayısıyla test süresinin basit bir sonucudur. “
Sonunda… Kazananlar veya kaybedenlerle ilgili değil…
… ama Chris Stucchio'nun dediği gibi daha iyi iş kararları hakkında.
Veya Tom Redman'ın (Veriye Yönelik: En Önemli İş Varlığınızdan Kâr Etmek kitabının yazarı) iş dünyasında şunu iddia ettiği gibi: “ genellikle istatistiksel anlamlılıktan daha önemli kriterler vardır. Önemli olan soru şudur: “ Kısa bir süreliğine de olsa sonuç piyasada duruyor mu? ”'
Georgiev, " istatistiksel olarak anlamlıysa ve dış geçerlilik hususları tasarım aşamasında tatmin edici bir şekilde ele alındıysa", büyük olasılıkla kısa bir süre için değil, olacaktır.
Deneyin özü, ekiplerin daha bilinçli kararlar vermesini sağlamaktır. Yani sonuçları - deneylerinizin verilerinin işaret ettiği - daha erken iletebilirseniz, neden olmasın?
Pratik olarak "yeterli" örnek boyutu elde edemediğiniz küçük bir UI deneyi olabilir. Ayrıca, meydan okuyucunuzun orijinali ezdiği bir deney olabilir ve sadece bu bahsi alabilirsiniz!
Jeff Bezos'un Amazon'un hissedarlarına yazdığı mektupta yazdığı gibi, büyük deneyler büyük zaman kazandırır:
“ Yüzde on şansla 100 kez geri ödeme yapıldığında, her seferinde bu bahsi almalısınız. Ama yine de onda dokuzunda yanılacaksın. Hepimiz biliyoruz ki, eğer çitler için sallanırsanız, çok fazla vuracaksınız, ama aynı zamanda bazı ev koşularına da vuracaksınız. Bununla birlikte, beyzbol ve iş arasındaki fark, beyzbolun kesik bir sonuç dağılımına sahip olmasıdır. Salladığınızda, topla ne kadar iyi bağlanırsanız bağlanın, alabileceğiniz en fazla koşu sayısı dörttür. İş dünyasında, arada bir, plakaya çıktığınızda 1.000 koşu atabilirsiniz. Bu uzun kuyruklu getiri dağılımı, cesur olmanın önemli olmasının nedenidir. Büyük kazananlar bu kadar çok deney için para ödüyor. “
Deneyleri büyük ölçüde erken yapmak, her gün sonuçlara bakmak ve iyi bir bahsi garanti eden bir noktada durmak gibidir.

