
Derin Öğrenme ve Makine Öğrenimi – farkı nasıl anlarız?
Yayınlanan: 2020-03-10Son yıllarda Makine Öğrenimi, Derin Öğrenme ve Yapay Zeka moda sözcükleri haline geldi. Sonuç olarak, bunları pazarlama materyallerinde ve giderek daha fazla şirketin reklamlarında bulabilirsiniz.
Peki Makine Öğrenimi ve Derin Öğrenme nedir? Ayrıca, aralarındaki farklar nelerdir? Bu yazıda, bu soruları cevaplamaya çalışacağım ve size Deep ve Machine Learning uygulamalarının bazı örneklerini göstereceğim.
Makine Öğrenimi Nedir?
Makine Öğrenimi , Bilgisayar Biliminin, gerçek dünya olaylarını veya nesnelerini verilere dayalı olarak matematiksel modellerle temsil etmeyle ilgilenen bir parçasıdır. Bu modeller, modelin genel yapısını eğitim verilerine uyacak şekilde uyarlayan özel algoritmalarla oluşturulmuştur. Çözülmekte olan sorunun türüne bağlı olarak, denetimli ve denetimsiz Makine Öğrenimi ve Makine Öğrenimi algoritmaları tanımlarız.
Denetimli ve denetimsiz Makine Öğrenimi
Denetimli Makine Öğrenimi, eldeki veriler hakkında zaten sahip olduğumuz bilgileri yeni verilere aktarabilecek modeller oluşturmaya odaklanır. Yeni veriler, eğitim aşamasında model oluşturma (eğitim) algoritması tarafından görülmez. Algoritmanın onlardan sonuç çıkarmayı öğrenmesi gereken (hedef değişken olarak adlandırılan) karşılık gelen değerlerle birlikte özelliklerin verilerini içeren bir algoritma sağlıyoruz.
Denetimsiz Makine Öğreniminde sadece algoritmaya özellikler sağlıyoruz. Bu, yapılarını ve/veya bağımlılıklarını kendi başına çözmesini sağlar. Belirtilen net bir hedef değişken yok. Denetimsiz öğrenme kavramını ilk başta kavramak zor olabilir, ancak aşağıdaki dört çizelgede verilen örneklere bir göz atmak bu fikri netleştirecektir.
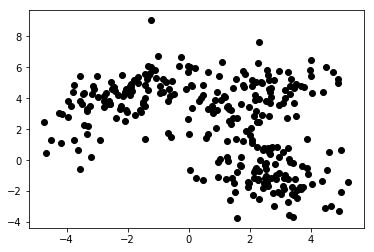
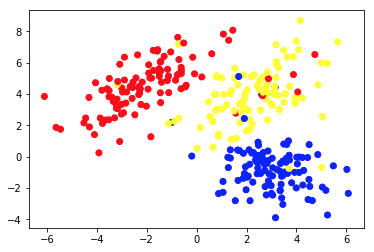

Grafik 1a, x ve y eksenlerinde 2 özellik ile açıklanan bazı verileri sunmaktadır. 1b olarak işaretlenen, aynı verileri renkli olarak gösterir. Bu noktaları 3 kümede gruplamak için K-araç kümeleme algoritmasını kullandık ve onları buna göre renklendirdik. Bu, denetimsiz Makine Öğrenimi algoritmasının bir örneğidir. Algoritmaya sadece özellikler verildi ve etiketler (küme numaraları) çözülecekti.
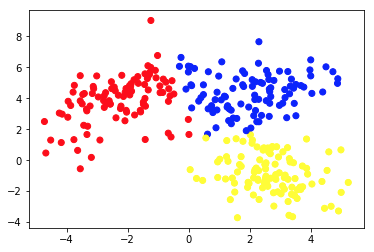
İkinci resim, farklı bir etiketlenmiş (ve buna göre renklendirilmiş) veri seti sunan Grafik 2a'yı göstermektedir. Veri noktalarının her birinin a priori ait olduğu grupları biliyoruz. Veri noktalarını bu gruplara en iyi uyacak şekilde nasıl böleceğimizi bize gösterecek 2 düz çizgi bulmak için bir SVM algoritması kullanıyoruz. Bu bölünme mükemmel değil, ancak düz çizgilerle yapılabileceklerin en iyisi bu. Yeni, etiketlenmemiş bir veri noktasına bir grup atamak istiyorsak, düzlemde nerede olduğunu kontrol etmemiz yeterlidir. Bu, denetimli bir Makine Öğrenimi uygulaması örneğidir.
Makine Öğrenimi modellerinin uygulamaları
Verileri tablo biçiminde işlemek için standart Makine Öğrenimi algoritmaları oluşturulur. Bu, onları kullanmak için bir tür masaya ihtiyacımız olduğu anlamına gelir. Bu tür tablolarda satırlar, modellenen nesnenin örnekleri olarak düşünülebilir (örneğin, bir ödünç). Aynı zamanda, sütunlar bu belirli örneğin özellikleri (özellikleri) olarak görülmelidir (örneğin, kredinin aylık ödemesi, borçlunun aylık geliri).

Makine Öğrenimi geliştirmeyi mi merak ediyorsunuz?
Daha fazla bilgi edinTablo 1. bu tür verilere çok kısa bir örnektir. Elbette bu, saf verinin kendisinin tablo halinde ve yapılandırılmış olması gerektiği anlamına gelmez. Ancak bazı veri kümelerine standart bir Makine Öğrenimi algoritması uygulamak istiyorsak, genellikle onu temizlememiz, karıştırmamız ve bir tabloya dönüştürmemiz gerekir. Denetimli öğrenmede, hedef değeri içeren özel bir sütun da vardır (örneğin, kredinin temerrüde düşmesi durumunda bilgi).
Eğitim algoritması, modelin genel yapısını bu verilere uydurmaya çalışır. Bahsedilen algoritma bunu modelin parametrelerini değiştirerek yapar. Bu, verilen veriler ile hedef değişken arasındaki ilişkiyi mümkün olduğunca doğru bir şekilde tanımlayan bir modelle sonuçlanır.
Modelin sadece verilen eğitim verilerine iyi uyması değil, aynı zamanda genelleme yapabilmesi de önemlidir. Genelleme, eğitim sırasında kullanılmayan örnekler için hedefi çıkarmak için modeli kullanabileceğimiz anlamına gelir. Aynı zamanda kullanışlı bir modelin çok önemli bir özelliğidir. İyi genelleyici bir model oluşturmak kolay bir iş değildir. Genellikle karmaşık doğrulama teknikleri ve kapsamlı model testi gerektirir.
| kredi_kimliği | ödünç alan_yaş | gelir_aylık | kredi miktarı | aylık ödeme | varsayılan |
| 1 | 34 | 10.000 | 100.000 | 1.200 | 0 |
| 2 | 43 | 5.700 | 25.000 | 800 | 0 |
| 3 | 25 | 2.500 | 24.000 | 400 | 0 |
| 4 | 67 | 4.600 | 40.000 | 2.000 | 1 |
| 5 | 38 | 35.000 | 2.500.000 | 10.000 | 0 |
Tablo 1. Tablo şeklinde kredi verileri
İnsanlar, çeşitli uygulamalarda Makine Öğrenimi algoritmalarını kullanır. Tablo 2., derin olmayan Makine Öğrenimi algoritmalarına ve model uygulamasına izin veren bazı iş kullanım senaryolarını sunar. Ayrıca potansiyel verilerin, hedef değişkenlerin ve seçilen uygulanabilir algoritmaların kısa açıklamaları da vardır.
| Kullanım durumu | Veri örnekleri | Hedef (modellenmiş) değer | Kullanılan algoritma/model |
| Bir blog sitesindeki makale önerileri | Kullanıcılar tarafından okunan makalelerin kimlikleri, her biri için harcanan zaman | Kullanıcıların makalelere yönelik tercihleri | Değişen En Küçük Kareler ile İşbirlikçi Filtreleme |
| Mortgage kredi notu | İşlem ve kredi geçmişi, potansiyel bir borçlunun gelir verileri | Bir kredinin tamamen geri ödenip ödenmeyeceğini veya temerrüde düşeceğini gösteren ikili değer | LightGBM |
| Bir mobil oyunun premium kullanıcılarının sayısını tahmin etme | Günlük oynamaya harcanan zaman, ilk lansmandan bu yana geçen süre, oyunda ilerleme | Bir kullanıcının gelecek ay aboneliği iptal edip etmeyeceğini gösteren ikili değer | XGBoost |
| Kredi kartı dolandırıcılığı tespiti | Geçmiş kredi kartı işlemleri verileri – miktar, yer, tarih ve saat | Bir kredi kartı işleminin sahte olup olmadığını gösteren ikili değer | rastgele orman |
| Bir internet mağazasının müşterilerinin segmentasyonu | Sadakat programı üyelerinin satın alma geçmişi | Her müşteriye atanan segment numarası | K-araçları |
| Bir makine parkının kestirimci bakımı | Performans, sıcaklık, nem vb. sensörlerden gelen veriler | Aşağıdaki sınıflardan biri – 'ince', 'gözlemlemek', 'bakım gerektirir' | Karar ağacı |
Tablo 2. Makine Öğrenimi kullanım örneklerine ilişkin örnekler
Derin Öğrenme ve Derin Sinir Ağları
Derin Öğrenme, derin yapay sinir ağları (YSA) olarak adlandırılan belirli bir türdeki modelleri kullandığımız Makine Öğreniminin bir parçasıdır. Yapay sinir ağları ortaya çıktıklarından bu yana kapsamlı bir evrim sürecinden geçmiştir. Bu, bazıları çok karmaşık olan bir dizi alt türe yol açtı. Ancak onları tanıtmak için temel biçimlerinden birini - çok katmanlı bir algılayıcıyı (MPL) açıklamak en iyisidir.
çok katmanlı algılayıcı
Basitçe söylemek gerekirse, bir MLP, köşelerin (nöronlar olarak da adlandırılır) ve kenarların (ağırlık olarak adlandırılan sayılarla temsil edilir) bir grafiği (ağ) biçimine sahiptir. Nöronlar katmanlar halinde düzenlenir ve ardışık katmanlardaki nöronlar birbirine bağlanır. Veriler ağ üzerinden girdiden çıktı katmanına akar. Veriler daha sonra nöronlarda ve bunların arasındaki kenarlarda dönüştürülür. Bir veri noktası tüm ağdan geçtiğinde, çıktı katmanı nöronlarında tahmin edilen değerleri içerir.
Eğitim verilerinin bir parçası ağdan her geçtiğinde, tahminleri karşılık gelen gerçek değerlerle karşılaştırırız. Bu, tahminleri daha iyi hale getirmek için modelin parametrelerini (ağırlıklarını) uyarlamamızı sağlar. Geri yayılım adı verilen bir algoritma ile yapabiliriz. Birkaç yinelemeden sonra, modelin yapısı, eldeki Makine Öğrenimi sorununu çözmek için özel olarak iyi tasarlanmışsa.
Yüksek doğruluklu bir model elde etme
Yeterli veri ağdan birden çok kez geçtiğinde, yüksek doğruluklu bir model elde ederiz. Pratikte, nöronlarda uygulanabilecek birçok dönüşüm vardır. Bu, YSA'ları çok esnek ve güçlü kılar. Yine de YSA'ların gücünün bir bedeli var. Genellikle, modelin yapısı ne kadar karmaşıksa, onu yüksek doğrulukla eğitmek için o kadar fazla veri ve zaman gerekir.
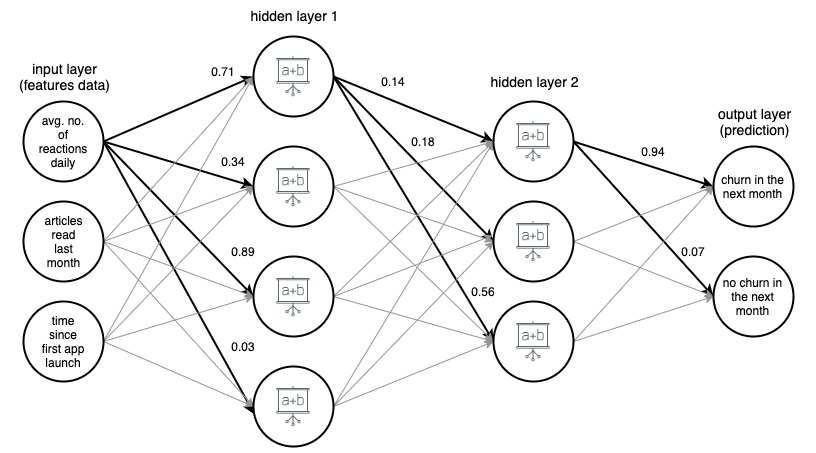
Resim 1. (draw.io) 4 katmanlı yapay sinir ağının yapısı, üç basit özelliğe dayalı olarak bir haber uygulaması kullanıcısının gelecek ay çalışıp çalışmayacağını tahmin ediyor.
Anlaşılır olması için, ağırlıklar yalnızca seçilen (kalın) kenarlar için işaretlenmiştir, ancak her kenarın kendi ağırlığı vardır. Veriler, ortadaki 2 gizli katmandan geçerek giriş katmanından çıkış katmanına akar. Her kenarda, bir girdi değeri, kenarın ağırlığı ile çarpılır ve elde edilen ürün, kenarın bittiği düğüme gider. Daha sonra, gizli katmanlardaki düğümlerin her birinde, kenarlardan gelen sinyaller toplanır ve daha sonra bir fonksiyonla dönüştürülür. Bu dönüşümlerin sonucu daha sonra bir sonraki katmana girdi olarak değerlendirilir.
Çıktı katmanında, gelen veriler tekrar toplanır ve dönüştürülür, sonuç iki sayı şeklinde verilir - bir kullanıcının bir sonraki ay uygulamadan ayrılma olasılığı ve yapmama olasılığı.
Gelişmiş sinir ağları türleri
Daha gelişmiş tipteki sinir ağlarında, katmanlar çok daha karmaşık bir yapıya sahiptir. Yalnızca MLP'lerden bilinen tek işlemli nöronlara sahip basit yoğun katmanlardan değil, aynı zamanda evrişimli ve tekrarlayan katmanlar gibi çok daha karmaşık, çok işlemli katmanlardan oluşurlar.
Evrişimsel ve yinelenen katmanlar
Konvolüsyonel katmanlar çoğunlukla bilgisayarla görü uygulamalarında kullanılır. Görüntünün piksel temsili üzerinde kayan küçük sayı dizilerinden oluşurlar. Piksel değerleri bu sayılarla çarpılır ve daha sonra toplanarak görüntünün yeni, yoğunlaştırılmış temsili elde edilir.
Tekrarlayan katmanlar, zaman serileri veya metin gibi sıralı sıralı verileri modellemek için kullanılır . Sıra öğeleri arasındaki bağımlılıkları bulmaya çalışarak, gelen verilere çok karmaşık çoklu argüman dönüşümleri uygularlar. Bununla birlikte, ağın türü ve yapısı ne olursa olsun, her zaman bazı (bir veya daha fazla) giriş ve çıkış katmanı ve verilerin ağ üzerinden aktığı kesin olarak tanımlanmış yollar ve yönler vardır.
Genel olarak Derin Sinir Ağları, çok katmanlı YSA'lardır. Aşağıdaki 1, 2 ve 3 numaralı görseller, seçilmiş derin yapay sinir ağlarının mimarilerini göstermektedir. Hepsi Google'da geliştirildi ve eğitildi ve herkesin kullanımına sunuldu. Günümüzde kullanılan karmaşık yüksek doğruluklu derin yapay ağların ne kadar karmaşık olduğu hakkında bir fikir veriyorlar.
Bu ağların çok büyük boyutları vardır. Örneğin, Resim 3'te kısmen gösterilen InceptionResNetV2, 572 katmana ve toplamda 55 milyondan fazla parametreye sahiptir! Hepsi görüntü sınıflandırma modelleri olarak geliştirilmiştir (belirli bir görüntüye 'araba' gibi bir etiket atarlar) ve 14 milyondan fazla etiketli görüntüden oluşan ImageNet setinden görüntüler üzerinde eğitilmiştir.

Resim 2. NASNetMobile'ın Yapısı (keras paketi)

Resim 3. XCeption Yapısı (keras paketi)

Resim 4. InceptionResNetV2'nin (keras paketi) bir parçasının yapısı (yaklaşık %25)
Son yıllarda Derin Öğrenme ve uygulamalarında büyük gelişmeler gözlemledik. Akıllı telefonlarımızın ve uygulamalarımızın 'akıllı' özelliklerinin çoğu bu ilerlemenin meyvesidir. YSA fikri yeni olmasa da, bu son patlama birkaç koşulun karşılanmasının bir sonucudur. Her şeyden önce, GPU hesaplamanın potansiyelini keşfettik. Grafik işlem birimlerinin mimarisi, paralel hesaplama için harikadır ve verimli Derin Öğrenmede çok faydalıdır.
Ayrıca, bulut bilişim hizmetlerinin yükselişi, yüksek verimli donanıma erişimi çok daha kolay, daha ucuz ve çok daha büyük ölçekte mümkün kıldı. Son olarak, en yeni mobil cihazların hesaplama gücü, Derin Öğrenme modellerini uygulamak için yeterince büyüktür ve DNN güdümlü özelliklerin potansiyel kullanıcılarından oluşan büyük bir pazar yaratır.
Derin Öğrenme modellerinin uygulamaları
Derin Öğrenme modelleri genellikle, görüntü sınıflandırması veya dil çevirisi gibi basit bir satır-sütun yapısına sahip olmayan verilerle ilgilenen problemlere uygulanır, çünkü bunlar yapılandırılmamış ve bu görevlerin ele aldığı karmaşık yapıdaki verilerde (resimler, metinler) çalışmakta harikadır. , ve ses. Bu tür ve boyutlardaki verilerin klasik Makine Öğrenimi algoritmaları ile işlenmesinde sorunlar yaşanmakta ve bu sorunlara bazı derin sinir ağları oluşturularak uygulanması, görüntü tanıma, konuşma tanıma, metin sınıflandırma ve dil çevirisi alanlarında büyük gelişmelere neden olmuştur. son birkaç yıl.
Derin Öğrenmenin bu problemlere uygulanması, DNN'lerin tensör adı verilen çok boyutlu sayı tablolarını hem girdi hem de çıktı olarak kabul etmesi ve elemanları arasındaki uzamsal ve zamansal ilişkileri izleyebilmesi nedeniyle mümkün olmuştur. Örneğin, bir görüntüyü 3 boyutlu bir tensör olarak sunabiliriz, burada boyut bir ve iki dijital görüntünün çözünürlüğünü temsil eder (sırasıyla görüntü genişliği ve yüksekliği boyutları da vardır) ve üçüncü boyut RGB rengini temsil eder. piksellerin her birinin kodlanması (yani üçüncü boyut 3 boyutundadır).
Bu, yalnızca görüntü hakkındaki tüm bilgileri bir tensörde temsil etmemize değil, aynı zamanda başarılı görüntü sınıflandırma ve tanıma ağlarında çok önemli olan evrişimli katmanların uygulanmasında çok önemli olduğu ortaya çıkan pikseller arasındaki uzamsal ilişkileri de korumamıza izin verir.
Giriş ve çıkış yapılarındaki sinir ağı esnekliği, dil çevirisi gibi diğer görevlerde de yardımcı olur. Metin verileriyle uğraşırken, derin sinir ağlarını, metindeki görünümlerine göre sıralanmış kelimelerin sayı temsilleriyle besleriz. Her kelime, farklı kelimelere karşılık gelen vektörler arasındaki ilişkilerin kelimelerin kendi ilişkilerini taklit etmesi için (genellikle farklı bir sinir ağı kullanılarak) hesaplanan yüz veya birkaç yüz sayıdan oluşan bir vektör ile temsil edilir. Gömmeler olarak adlandırılan bu vektör dili temsilleri, bir kez eğitildikten sonra birçok mimaride yeniden kullanılabilir ve sinir ağı dil modellerinin merkezi bir yapı taşıdır.
Derin Öğrenme modellerinin kullanım örnekleri
Tablo 3. Derin Öğrenme modellerini gerçek hayat problemlerine uygulama örnekleri içermektedir. Gördüğünüz gibi, Derin Öğrenme algoritmaları tarafından ele alınan ve çözülen sorunlar, Tablo 1'de sunulanlar gibi standart Makine Öğrenimi teknikleriyle çözülen görevlerden çok daha karmaşıktır.
Bununla birlikte, Makine Öğreniminin günümüzde işletmelere yardımcı olabileceği kullanım durumlarının çoğunun bu kadar karmaşık yöntemler gerektirmediğini ve standart modellerle daha verimli (ve daha yüksek doğrulukla) çözülebileceğini hatırlamak önemlidir. Tablo 3. ayrıca kaç farklı türde yapay sinir ağı katmanı olduğu ve bunlarla kaç farklı kullanışlı mimarinin oluşturulabileceği hakkında bir fikir vermektedir.
| Kullanım durumu | Veri | Modelin hedefi/sonucu | Kullanılan algoritma/model |
| Görüntü sınıflandırması | Görüntüler | Bir resme atanan etiket | Evrişimli Sinir Ağı (CNN) |
| Kendi kendini süren arabalarla görüntü algılama | Görüntüler | Görüntülerde tanımlanan nesnelerin etrafındaki etiketler ve sınırlayıcı kutular | Hızlı R-CNN |
| Duygusallık analizi bir çevrimiçi mağazada yorumlar | Çevrimiçi yorumların metni | Her yoruma atanan duygu etiketi (ör. pozitif, nötr, negatif) | Çift Yönlü Uzun-Kısa Süreli Bellek (LSTM) Ağı |
| Bir melodinin armonizasyonu | Bir melodi ile MIDI dosyası | Bu melodi ile uyumlu hale getirilmiş MIDI dosyası | Üretken Düşman Ağı |
| Sonraki kelime tahmini bir internet üzerinden e-posta editör | Çok büyük metin yığını (örneğin, İngilizce'deki tüm Wikipedia makalelerinin dökümü) | Şimdiye kadar yazılan metinden sonrakine uyan bir kelime | Gömme katmanına sahip Tekrarlayan Sinir Ağı (RNN) |
| Başka bir dile metin çevirisi | Lehçe Metin | Aynı metin İngilizce'ye çevrildi | Kodlayıcı – Tekrarlayan sinir ağı (RNN) katmanlarıyla oluşturulmuş Kod Çözücü Ağı |
| Monet stilinin herhangi bir görüntüye aktarılması | Monet'nin resimlerinden oluşan bir dizi resim ve bir dizi başka resim | Monet tarafından boyanmış gibi görünecek şekilde değiştirilmiş resimler | Üretken Düşman Ağı |
Tablo 3. Derin Öğrenme kullanım örneklerine ilişkin örnekler
Derin Öğrenme modellerinin avantajları
Üretken Düşman Ağları
Derin Sinir Ağlarının en etkileyici uygulamalarından biri, Üretken Düşman Ağlarının (GAN'lar) yükselişiyle geldi. 2014 yılında Ian Goodfellow tarafından tanıtıldılar ve onun fikri o zamandan beri birçok araca dahil edildi, bazıları şaşırtıcı sonuçlarla.
GAN'lar, fotoğraflarda bizi daha yaşlı gösteren, görüntüleri van Gogh tarafından boyanmış gibi gösterecek şekilde dönüştüren, hatta birden fazla enstrüman grubu için melodileri uyumlu hale getiren uygulamaların varlığından sorumludur. Bir GAN'ın eğitimi sırasında iki sinir ağı rekabet eder. Bir üreteç ağı rastgele girdiden bir çıktı üretirken, ayırıcı gerçek olanlardan oluşturulan örnekleri söylemeye çalışır. Eğitim sırasında, jeneratör ayrımcıyı nasıl başarılı bir şekilde 'kandıracağını' öğrenir ve sonunda gerçekmiş gibi görünen çıktılar yaratabilir.
Mobil uygulamalarda güçlü derin sinir ağları
Derin bir sinir ağını eğitmek, hesaplama açısından çok pahalı bir görev olsa ve uzun zaman alabilse de, özellikle bir veya daha fazla kişiye uygulanıyorsa, belirli bir görevi yapmak için eğitimli bir ağ uygulamak olmak zorunda değildir. aynı anda birkaç vaka. Aslında bugün akıllı telefonlarımızdaki mobil uygulamalarda güçlü derin sinir ağlarını çalıştırabiliyoruz.
Mobil cihazlara uygulandığında verimli olması için özel olarak tasarlanmış bazı ağ mimarileri bile vardır (örneğin, Resim 1'de sunulan NASNetMobile). Son teknoloji ağlara kıyasla boyut olarak çok daha küçük olmalarına rağmen, yine de yüksek doğrulukta bir tahmin performansı elde edebiliyorlar.
Öğrenimi aktarın
Derin Öğrenme modellerinin yaygın olarak kullanılmasını sağlayan yapay sinir ağlarının bir diğer çok güçlü özelliği de transfer öğrenmedir . Bazı veriler üzerinde eğitilmiş bir modelimiz olduğunda (kendimiz tarafından oluşturulmuş veya halka açık bir depodan indirilmiş), özel kullanım durumumuzu çözen bir model elde etmek için tamamını veya bir kısmını geliştirebiliriz. Örneğin, bir görüntüye bir etiket atayan, yapısının üstünde bazı küçük değişiklikler yapan, yeni etiketli görüntü kümesiyle daha fazla eğiten ve devasa ImageNet veri kümesi üzerinde eğitilmiş önceden eğitilmiş bir NASNetLarge modelini kullanabiliriz. belirli türdeki nesneleri etiketlemek için kullanın (örneğin, yaprağının görüntüsüne dayalı bir ağaç türü).
Transfer öğreniminin avantajları
Transfer öğrenimi çok faydalıdır, çünkü genellikle bazı pratik, faydalı görevleri gerçekleştirecek derin bir sinir ağını eğitmek büyük miktarda veri ve büyük hesaplama gücü gerektirir. Bu, genellikle milyonlarca etiketli veri örneği ve haftalarca çalışan yüzlerce grafik işleme birimi (GPU) anlamına gelebilir.
Herkesin bu tür varlıklara parası yetmeyebilir veya bunlara erişemez; bu da, diyelim ki görüntü sınıflandırması için sıfırdan yüksek doğrulukta özel bir çözüm oluşturmayı çok zorlaştırabilir. Neyse ki, bazı önceden eğitilmiş modeller (özellikle görüntü sınıflandırması için ağlar ve dil modelleri için önceden eğitilmiş yerleştirme matrisleri) açık kaynaklıdır ve ücretsiz olarak kolayca uygulanabilir bir biçimde (örn. Keras'ta bir Model örneği olarak, bir sinirsel ağ API'si).
Uygulamanız için doğru Makine Öğrenimi modeli nasıl seçilir ve oluşturulur?
Bir iş sorununu çözmek için Makine Öğrenimi uygulamak istediğinizde, muhtemelen modelin türüne hemen karar vermeniz gerekmez. Genellikle test edilebilecek birkaç yaklaşım vardır. İlk başta en karmaşık modellerle başlamak genellikle cazip gelebilir, ancak basitten başlamaya ve uygulanan modellerin karmaşıklığını kademeli olarak artırmaya değer. Daha basit modeller genellikle kurulum, hesaplama süresi ve kaynaklar açısından daha ucuzdur. Ayrıca, sonuçları daha gelişmiş yaklaşımları değerlendirmek için harika bir ölçüttür.
Bu tür kıyaslamalara sahip olmak, veri bilimcilerinin modellerini geliştirdikleri yönün doğru olup olmadığını değerlendirmelerine yardımcı olabilir. Diğer bir avantaj, daha önce oluşturulmuş modellerin bazılarını yeniden kullanma ve bunları daha yenileriyle birleştirerek sözde bir topluluk modeli oluşturma olasılığıdır. Farklı türdeki modelleri karıştırmak, genellikle birleştirilmiş modellerin her birinin tek başına sahip olacağından daha yüksek performans ölçütleri verir. Ayrıca, transfer öğrenimi yoluyla kullanılabilecek ve iş durumunuza uyarlanabilecek önceden eğitilmiş bazı modeller olup olmadığını kontrol edin.
Daha pratik ipuçları
Her şeyden önce, hangi modeli kullanırsanız kullanın, verilerin doğru şekilde işlendiğinden emin olun. 'Çöp gir, çöp çıkar' kuralını aklınızda bulundurun. Modele sağlanan eğitim verilerinin kalitesi düşükse veya uygun şekilde etiketlenip temizlenmemişse, ortaya çıkan modelin de kötü performans göstermesi çok olasıdır. Ayrıca modelin - karmaşıklığı ne olursa olsun - modelleme aşamasında kapsamlı bir şekilde doğrulandığından ve sonunda görünmeyen verilere iyi genelleme yapıp yapmadığının test edildiğinden emin olun.
Daha pratik bir not olarak, oluşturulan çözümün mevcut altyapı üzerinde üretimde uygulanabileceğinden emin olun. Ve işletmeniz gelecekte modelinizi geliştirmek için kullanılabilecek daha fazla veri toplayabilirse, kolayca güncellenmesini sağlamak için bir yeniden eğitim hattı hazırlanmalıdır. Böyle bir işlem hattı, modeli önceden tanımlanmış bir zaman frekansıyla otomatik olarak yeniden eğitmek için bile kurulabilir.
Son düşünceler
İş ortamı çok dinamik olduğundan, modelin üretime dağıtımından sonra performansını ve kullanılabilirliğini takip etmeyi unutmayın. Verilerinizdeki bazı ilişkiler zamanla değişebilir ve yeni fenomenler ortaya çıkabilir. Bu nedenle, modelinizin verimliliğini değiştirebilirler ve uygun şekilde ele alınmaları gerekir. Ek olarak, yeni, güçlü modeller icat edilebilir. Bir yandan çözümünüzü nispeten zayıf hale getirebilirler, ancak diğer yandan size işinizi daha da geliştirme ve en yeni teknolojiden yararlanma fırsatı verirler.
Dahası, Makine ve Derin Öğrenme modelleri, işiniz ve uygulamalarınız için güçlü araçlar oluşturmanıza ve müşterilerinize olağanüstü bir deneyim sunmanıza yardımcı olabilir . Bu 'akıllı' özellikleri oluşturmak büyük çaba gerektirse de, potansiyel faydalar buna değer. Siz ve Veri Bilimi ekibinizin uygun modelleri denediğinden ve iyi uygulamaları takip ettiğinden emin olun; işinizi ve uygulamalarınızı son teknoloji Makine Öğrenimi çözümleriyle güçlendirmek için doğru yolda olacaksınız.
Kaynaklar:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/deep-learning
- https://keras.io/applications/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning- three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidirectional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/applications/
- https://arxiv.org/pdf/1707.07012.pdf