
CTR eğrisi nedir ve Python ile nasıl hesaplanır?
Yayınlanan: 2022-03-22TO eğrisi veya başka bir deyişle konuma dayalı organik tıklama oranı, bir Arama Motoru Sonuç Sayfasındaki (SERP) kaç mavi bağlantının konumlarına göre TO elde ettiğini gösteren verilerdir. Örneğin, çoğu zaman SERP'deki ilk mavi bağlantı en fazla TO'yu alır.
Bu öğreticinin sonunda, sitenizin dizinlerine göre TO eğrisini hesaplayabilecek veya TO sorgularına göre organik TO'yu hesaplayabileceksiniz. Python kodumun çıktısı, site TO eğrisini açıklayan anlayışlı bir kutu ve çubuk grafiğidir.
Yeni başlayan biriyseniz ve TO tanımını bilmiyorsanız, bir sonraki bölümde daha fazla açıklayacağım.
Organik TO veya Organik Tıklama Oranı nedir?
TO, organik tıklamaların gösterimlere bölünmesiyle elde edilir. Örneğin, 100 kişi "elma" için arama yaparsa ve 30 kişi ilk sonuca tıklarsa, ilk sonucun TO'su 30 / 100 * 100 = %30'dur.
Bu, her 100 aramadan %30'unu aldığınız anlamına gelir. Google Arama Konsolu'ndaki (GSC) gösterimlerin, web site bağlantınızın arama yapan görünümündeki görünümüne bağlı olmadığını unutmamak önemlidir. Sonuç, arama yapan SERP'de görünüyorsa, aramaların her biri için bir gösterim alırsınız.
TO eğrisinin kullanım alanları nelerdir?
SEO'da önemli konulardan biri organik trafik tahminleridir. Bazı anahtar kelimelerdeki sıralamaları iyileştirmek için, daha fazla pay almak için binlerce ve binlerce dolar ayırmamız gerekiyor. Ancak bir şirketin pazarlama düzeyindeki soru genellikle “Bu bütçeyi ayırmamız maliyet açısından verimli mi?” şeklindedir.
Ayrıca SEO projeleri için bütçe tahsisi konusunun yanı sıra, gelecekte organik trafik artış veya azalışımızın bir tahminini almamız gerekiyor. Örneğin, SERP sıralama konumumuzda rakiplerimizden birinin bizi değiştirmeye çalıştığını görürsek, bunun bize maliyeti ne olur?
Bu durumda veya diğer birçok senaryoda sitemizin CTR eğrisine ihtiyacımız var.
Neden CTR eğrisi çalışmalarını ve verilerimizi kullanmıyoruz?
Basitçe cevap, SERP'de sitenizin özelliklerine sahip başka bir web sitesi yok.
Farklı sektörlerde ve farklı SERP özelliklerinde TO eğrileri için çok fazla araştırma var, ancak verileriniz olduğunda, siteleriniz neden üçüncü taraf kaynaklara güvenmek yerine TO hesaplamıyor?
Bunu yapmaya başlayalım.
Python ile TO eğrisini hesaplama: Başlarken
Google'ın konuma dayalı tıklama oranı hesaplama sürecine dalmadan önce, temel Python sözdizimini bilmeniz ve Pandalar gibi yaygın Python kitaplıkları hakkında temel bir anlayışa sahip olmanız gerekir. Bu, kodu daha iyi anlamanıza ve kendi yolunuza göre özelleştirmenize yardımcı olacaktır.
Ayrıca bu işlem için Jupyter notebook kullanmayı tercih ediyorum.
Pozisyona göre organik TO'yu hesaplamak için şu Python kitaplıklarını kullanmamız gerekiyor:
- pandalar
- olay örgüsü
- kaleido
Ayrıca, şu Python standart kitaplıklarını kullanacağız:
- işletim sistemi
- json
Söylediğim gibi, TO eğrisini hesaplamanın iki farklı yolunu keşfedeceğiz. Her iki yöntemde de bazı adımlar aynıdır: Python paketlerini içe aktarma, bir çizim görüntüleri çıktı klasörü oluşturma ve çıktı çizim boyutlarını ayarlama.
# Sürecimiz için gerekli kitaplıkları içe aktarıyoruz işletim sistemini içe aktar json'u içe aktar pandaları pd olarak içe aktar plotly.express'i px olarak içe aktar plotly.io'yu pio olarak içe aktar ithal kaleido
Burada arsa görüntülerimizi kaydetmek için bir çıktı klasörü oluşturuyoruz.
# Arsa görüntüleri çıktı klasörü oluşturma
os.path.exists değilse('./output plot images'):
os.mkdir('./çıktı çizim görüntüleri')
Aşağıdaki çıktı grafiği görüntülerinin yüksekliğini ve genişliğini değiştirebilirsiniz.
# Çıktı arsa görüntülerinin genişliğini ve yüksekliğini ayarlama pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
Sorgu TO'sunu temel alan ilk yöntemle başlayalım.
İlk yöntem: Tüm bir web sitesi veya belirli bir URL özelliği için TO eğrisini, sorgu TO'larına göre hesaplayın
Her şeyden önce, tüm sorgularımızı CTR, ortalama konum ve izlenim ile almamız gerekiyor. Geçen aya ait tam bir aylık verileri kullanmayı tercih ederim.
Bunu yapmak için Google Data Studio'daki GSC site gösterim veri kaynağından sorgu verileri alıyorum. Alternatif olarak, bu verileri, örneğin GSC API veya "E-Tablolar için Arama Analizi" Google E-Tablolar eklentisi gibi tercih ettiğiniz herhangi bir yolla elde edebilirsiniz. Bu şekilde, blogunuzun veya ürün sayfalarınızın özel bir URL özelliği varsa, bunları GDS'de veri kaynağı olarak kullanabilirsiniz.
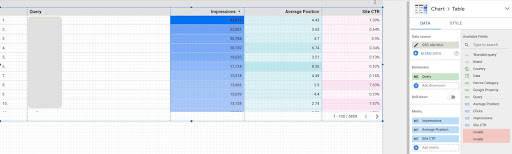
1. Google Data Studio'dan (GDS) sorgu verilerinin alınması
Bunu yapmak için:
- Bir rapor oluşturun ve buna bir tablo grafiği ekleyin
- Sitenizin "Site gösterimi" veri kaynağını rapora ekleyin
- Boyut için "sorgu"yu ve metrik için "ktr", "ortalama konum" ve "gösterim"i seçin
- Bir filtre oluşturarak marka adını içeren sorguları filtreleyin (Markaları içeren sorgular daha yüksek tıklama oranına sahip olacak ve bu da verilerimizin doğruluğunu azaltacaktır)
- Tabloya sağ tıklayın ve Dışa Aktar'a tıklayın
- Çıktıyı CSV olarak kaydedin
2. Verilerimizi yükleme ve sorguları konumlarına göre etiketleme
İndirilen CSV'yi değiştirmek için Panda'ları kullanacağız.
Projemizin klasör yapısı için en iyi uygulama, tüm verilerimizi kaydettiğimiz bir 'data' klasörüne sahip olmaktır.
Burada, öğreticideki akıcılık adına bunu yapmadım.
sorgu_df = pd.read_csv('./downloaded_data.csv')
Ardından sorgularımızı konumlarına göre etiketliyoruz. 1'den 10'a kadar olan konumları etiketlemek için bir 'for' döngüsü oluşturdum.
Örneğin, bir sorgunun ortalama konumu 2,2 veya 2,9 ise, "2" olarak etiketlenecektir. Ortalama konum aralığını manipüle ederek arzu ettiğiniz doğruluğa ulaşabilirsiniz.
i aralığında (1, 11):
query_df.loc[(query_df['Ortalama Konum'] >= i) & (
query_df['Ortalama Konum'] < i + 1), 'konum etiketi'] = i
Şimdi, sorguları konumlarına göre gruplayacağız. Bu, sonraki adımlarda her konum sorgusu verilerini daha iyi bir şekilde işlememize yardımcı olur.
query_grouped_df = query_df.groupby(['konum etiketi'])
3. TO eğrisi hesaplaması için sorguları verilerine göre filtreleme
CTR eğrisini hesaplamanın en kolay yolu, tüm sorgu verilerini kullanmak ve hesaplamayı yapmaktır. Yine de; Verilerinizde ikinci konumda bir gösterimi olan bu sorguları düşünmeyi unutmayın.
Deneyimlerime dayanan bu sorgular, nihai sonuçta çok fazla fark yaratıyor. Ama en iyi yol, kendin denemek. Veri kümesine bağlı olarak, bu değişebilir.
Bu adıma başlamadan önce, çubuk grafiği çıktımız için bir liste ve manipüle edilmiş sorgularımızı depolamak için bir DataFrame oluşturmamız gerekiyor.
# 'query_df' manipüle edilmiş verileri depolamak için bir DataFrame oluşturma modifiye_df = pd.DataFrame() # Çubuk grafiğimiz için her konumun ortalamasını kaydetmek için bir liste ortalama_ctr_list = []
Ardından, query_grouped_df grupları üzerinde döngü yaparız ve gösterimlere dayalı olarak ilk %20'lik sorguyu modified_df DataFrame'e ekleriz.
TO'yu yalnızca en çok gösterime sahip sorguların ilk %20'sine göre hesaplamak sizin için en iyisi değilse, bunu değiştirebilirsiniz.
Bunu yapmak için, .quantile(q=your_optimal_number, interpolation='lower')] değiştirerek onu artırabilir veya azaltabilirsiniz ve your_optimal_number 0 ile 1 arasında olmalıdır.
Örneğin, sorgularınızın ilk %30'unu elde etmek istiyorsanız, your_optimal_num 1 ile 0,3 (0,7) arasındaki farktır.
i aralığında (1, 11):
# Bir dizinin bazı konumlar için verisi olmadığı durumları ele almak dışında bir deneme
denemek:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['gösterimler'] >= query_grouped_df.get_group(i)['gösterimler']
.quantile(q=0.8, enterpolasyon='düşük')]
ortalama_ctr_list.append(tmp_df['ctr'].mean())
modifiye_df = modifiye_df.append(tmp_df, yok say_index=Doğru)
KeyError hariç:
ortalama_ctr_list.append(0)
# Bellek kullanımını azaltmak için 'tmp_df' DataFrame siliniyor
del [tmp_df]
4. Bir kutu grafiği çizme
Bu adım, beklediğimiz şeydi. Grafikler çizmek için, Matplotlib için bir sarmalayıcı olarak seaborn olan Matplotlib'i veya Plotly'yi kullanabiliriz.
Kişisel olarak, verileri keşfetmeyi seven pazarlamacılar için Plotly kullanmanın en uygun seçeneklerden biri olduğunu düşünüyorum.
Mathplotlib ile karşılaştırıldığında, Plotly'nin kullanımı çok kolaydır ve sadece birkaç satır kod ile güzel bir arsa çizebilirsiniz.
# 1. Kutu arsa
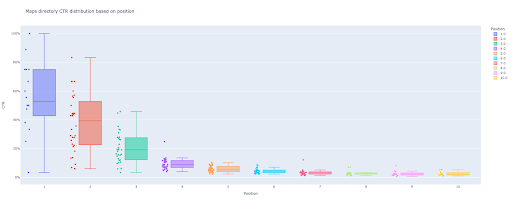
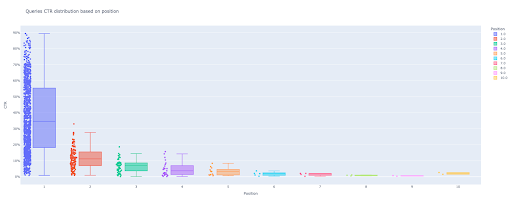
box_fig = px.box(modified_df, x='konum etiketi', y='Site TO'su', title='Konuma dayalı sorgular TO dağılımı',
point='tümü', color='konum etiketi', etiketler={'konum etiketi': 'Konum', 'Site TO'su': 'TO'})
# Tüm on x ekseni kenelerini gösterme
box_fig.update_xaxes(tickvals=[aralıktaki i için i(1, 11)])
# y ekseni onay biçimini yüzde olarak değiştirme
box_fig.update_yaxes(tickformat=".0%")
# Çizimi 'çıktı çizimi görüntüleri' dizinine kaydetme
box_fig.write_image('./çıktı çizim görüntüleri/Sorgular kutu çizimi CTR eğrisi.png')
Sadece bu dört satır ile güzel bir kutu grafiği elde edebilir ve verilerinizi keşfetmeye başlayabilirsiniz.
Bu sütunla etkileşim kurmak istiyorsanız, yeni bir hücre çalıştırmasında:
box_fig.show()
Artık çıktıda etkileşimli çekici bir kutu grafiğiniz var.
Çıktı hücresindeki etkileşimli bir grafiğin üzerine geldiğinizde, ilgilendiğiniz önemli sayı her konumun "adamı"dır.
Bu, her bir pozisyon için ortalama TO'yu gösterir. Ortalama önemi nedeniyle, hatırladığınız gibi, her pozisyonun ortalamasını içeren bir liste oluşturuyoruz. Ardından, her konumun ortalamasına dayalı bir çubuk grafiği çizmek için bir sonraki adıma geçeceğiz.
5. Bir çubuk grafiği çizme
Bir kutu grafiği gibi, çubuk grafiğini çizmek çok kolaydır. px.bar() title argümanını değiştirerek grafiklerin title değiştirebilirsiniz.
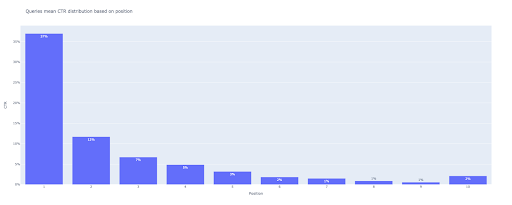
# 2. Çubuk arsa
bar_fig = px.bar(x=[aralıktaki konum için konum (1, 11)], y=mean_ctr_list, title='Sorgular, konuma dayalı TO dağılımı anlamına gelir',
etiketler={'x': 'Konum', 'y': 'TO'}, text_auto=Doğru)
# Tüm on x ekseni kenelerini gösterme
bar_fig.update_xaxes(tickvals=[i için aralıktaki i(1, 11)])
# y ekseni onay biçimini yüzde olarak değiştirme
bar_fig.update_yaxes(tickformat='.0%')
# Çizimi 'çıktı çizimi görüntüleri' dizinine kaydetme
bar_fig.write_image('./çıktı çizim görüntüleri/Sorgular çubuk çizimi TO eğrisi.png')
Çıktıda şu grafiği elde ederiz:
Kutu grafiğinde olduğu gibi, bar_fig.show() çalıştırarak bu çizimle etkileşime girebilirsiniz.
Bu kadar! Birkaç satır kodla, sorgu verilerimizle konum bazında organik tıklama oranını elde ederiz.
Alt alan adlarınızın veya dizinlerinizin her biri için bir URL özelliğiniz varsa, bu URL özellikleri sorgularını alabilir ve bunlara ilişkin TO eğrisini hesaplayabilirsiniz.
[Örnek Olay] Günlük dosyaları analizi ile sıralamaları, organik ziyaretleri ve satışları iyileştirme
 Örnek olayı okuyun
Örnek olayı okuyunİkinci yöntem: Her bir dizin için açılış sayfası URL'lerine dayalı olarak TO eğrisini hesaplama
İlk yöntemde, organik TO'muzu sorguların TO'suna göre hesapladık, ancak bu yaklaşımla tüm açılış sayfası verilerimizi elde ediyor ve ardından seçilen dizinlerimiz için TO eğrisini hesaplıyoruz.

Bu yolu seviyorum. Bildiğiniz gibi, ürün sayfalarımızın TO'su blog yazılarımızdan veya diğer sayfalarımızdan çok farklı. Her dizinin, konuma dayalı olarak kendi TO'su vardır.
Daha gelişmiş bir şekilde, her bir dizin sayfasını kategorilere ayırabilir ve bir dizi sayfa için konuma dayalı olarak Google organik tıklama oranını elde edebilirsiniz.
1. Açılış sayfası verilerini alma
Tıpkı ilk yöntemde olduğu gibi, Google Arama Konsolu (GSC) verilerini almanın birkaç yolu vardır. Bu yöntemde, https://developers.google.com/webmaster-tools/v1/searchanalytics/query adresindeki GSC API Explorer'dan açılış sayfası verilerini almayı tercih ettim.
Bu yaklaşımda ihtiyaç duyulanlar için GDS, sağlam açılış sayfası verileri sağlamaz. Ayrıca, "E-Tablolar için Arama Analizi" Google E-Tablolar eklentisini de kullanabilirsiniz.
Google API Explorer'ın 25K sayfadan daha az veri içeren siteler için uygun olduğunu unutmayın. Daha büyük siteler için, açılış sayfası verilerini kısmen alabilir ve bunları bir araya getirebilir, tüm verilerinizi GSC'den çıkarmak için 'for' döngüsüne sahip bir Python betiği yazabilir veya üçüncü taraf araçları kullanabilirsiniz.
Google API Explorer'dan veri almak için:
- "Arama Analizi: sorgu" GSC API dokümantasyon sayfasına gidin: https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- Sayfanın sağ tarafında bulunan API Gezgini'ni kullanın
- "siteUrl" alanına,
https://www.example.comgibi URL mülk adresinizi girin. Ayrıca, alan mülkünüzü şu şekilde ekleyebilirsinizsc-domain:example.com - "Request body" alanına
startDateveendDateekleyin. Geçen ayın verilerini almayı tercih ederim. Bu değerlerin formatıYYYY-MM-DDşeklindedir. -
dimensionekleyin ve değerlerinipageayarlayın - Bir "dimensionFilterGroups" oluşturun ve sorguları marka varyasyon adlarıyla filtreleyin (
brand_variation_namesmarka adlarınızı RegExp ile değiştirin) -
rawLimitekleyin ve 25000 olarak ayarlayın - Sonunda 'YÜRÜT' düğmesine basın
Ayrıca istek gövdesini aşağıya kopyalayıp yapıştırabilirsiniz:
{
"başlangıçTarihi": "2022-01-01",
"bitiş Tarihi": "2022-02-01",
"boyutlar": [
"sayfa"
],
"boyutFilterGroups": [
{
"filtreler": [
{
"boyut": "SORGU",
"ifade": "brand_variation_names",
"operatör": "HARİÇ_REGEX"
}
]
}
],
"satırLimit": 25000
}
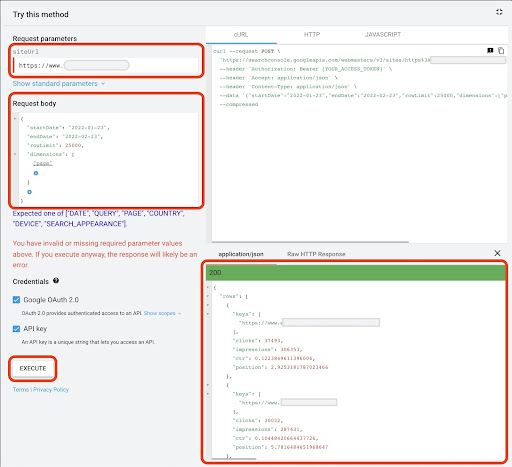
İstek yürütüldükten sonra kaydetmemiz gerekiyor. Yanıt formatı nedeniyle, bir JSON dosyası oluşturmamız, tüm JSON yanıtlarını kopyalamamız ve onu downloaded_data.json dosya adıyla kaydetmemiz gerekiyor.
Siteniz bir SASS şirket sitesi gibi küçükse ve açılış sayfası verileriniz 1000 sayfanın altındaysa, GSC'de tarihinizi kolayca ayarlayabilir ve "SAYFALAR" sekmesi için açılış sayfası verilerini bir CSV dosyası olarak dışa aktarabilirsiniz.
2. Açılış sayfası verilerinin yüklenmesi
Bu öğretici uğruna, Google API Explorer'dan veri aldığınızı ve bir JSON dosyasına kaydettiğinizi varsayacağım. Bu verileri yüklemek için aşağıdaki kodu çalıştırmamız gerekiyor:
# İndirilen veriler için bir DataFrame oluşturma
open('./downloaded_data.json') ile json_file olarak:
Landings_data = json.loads(json_file.read())['rows']
Landings_df = pd.DataFrame(landings_data)
Ek olarak, daha fazla anlam vermek için bir sütun adını değiştirmemiz ve açılış sayfası URL'lerini doğrudan "açılış sayfası" sütununda almak için bir işlev uygulamamız gerekiyor.
# 'Anahtarlar' sütununu 'açılış sayfası' sütunu olarak yeniden adlandırma ve 'açılış sayfası' listesini bir URL'ye dönüştürme
Landings_df.rename(columns={'anahtarlar': 'açılış sayfası'}, inplace=True)
Landings_df['açılış sayfası'] = Landings_df['açılış sayfası'].apply(lambda x: x[0])
3. Tüm açılış sayfalarının kök dizinlerini alma
Öncelikle site ismimizi tanımlamamız gerekiyor.
# Site adınızı tırnak işaretleri arasında tanımlama. Örneğin, 'https://www.example.com/' veya 'http://mydomain.com/' site_adı = ''
Ardından, kök dizinlerini almak ve onları seçmek için çıktıda görmek için açılış sayfası URL'lerinde bir işlev çalıştırırız.
# Her bir açılış sayfası (URL) dizinini alma
Landings_df['directory'] = Landings_df['açılış sayfası'].str.extract(pat=f'((?<={site_name})[^/]+)')
# Çıktıdaki tüm dizinleri almak için Panda seçeneklerini değiştirmemiz gerekiyor
pd.set_option("display.max_rows", Yok)
# Web sitesi dizinleri
Landings_df['dizin'].value_counts()
Ardından, CTR eğrilerini elde etmemiz gereken dizinleri seçiyoruz.
Dizinleri important_directories değişkenine ekleyin.
Örneğin, product,tag,product-category,mag . Dizin değerlerini virgülle ayırın.
önemli_dizinler = ''
önemli_dizinler = önemli_dizinler.split(',')
4. Açılış sayfalarını etiketleme ve gruplama
Sorgular gibi, açılış sayfalarını da ortalama konumlarına göre etiketliyoruz.
# Açılış sayfaları konumunu etiketleme
i aralığında (1, 11):
Landings_df.loc[(landings_df['position'] >= i) & (
Landings_df['position'] < i + 1), 'konum etiketi'] = i
Ardından, açılış sayfalarını "dizinlerine" göre gruplandırıyoruz.
# Açılış sayfalarını 'dizin' değerlerine göre gruplandırma inişler_grouped_df = inişler_df.groupby(['dizin'])
5. Dizinlerimiz için kutu ve çubuk grafikleri oluşturma
Önceki yöntemde, grafikleri oluşturmak için bir fonksiyon kullanmadık. Yine de; farklı açılış sayfaları için CTR eğrisini otomatik olarak hesaplamak için bir fonksiyon tanımlamamız gerekiyor.
# Her bir dizin tablosunu oluşturma ve kaydetme işlevi
def each_dir_plot(dir_df, anahtar):
# Dizin açılış sayfalarını 'konum etiketi' değerlerine göre gruplama
dir_grouped_df = dir_df.groupby(['konum etiketi'])
# 'dir_grouped_df' manipüle edilmiş verileri depolamak için bir DataFrame oluşturma
modifiye_df = pd.DataFrame()
# Çubuk grafiğimiz için her konumun ortalamasını kaydetmek için bir liste
ortalama_ctr_list = []
'''
'query_grouped_df' grupları üzerinde dolaşmak ve gösterimlere dayalı olarak ilk %20'lik sorguyu 'modified_df' DataFrame'e eklemek.
TO'yu yalnızca en çok gösterime sahip sorguların ilk %20'sine göre hesaplamak sizin için en iyisi değilse, bunu değiştirebilirsiniz.
Bunu değiştirmek için, '.quantile(q=your_optimal_number, interpolation='lower')]' öğesini değiştirerek artırabilir veya azaltabilirsiniz.
'you_optimal_number' 0 ile 1 arasında olmalıdır.
Örneğin, sorgularınızın ilk %30'unu almak istiyorsanız, 'optimal_sayınız' 1 ile 0,3 (0,7) arasındaki farktır.
'''
i aralığında (1, 11):
# Bir dizinin bazı konumlar için verisi olmadığı durumları ele almak dışında bir deneme
denemek:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['gösterimler'] >= dir_grouped_df.get_group(i)['gösterimler']
.quantile(q=0.8, enterpolasyon='düşük')]
ortalama_ctr_list.append(tmp_df['ctr'].mean())
modifiye_df = modifiye_df.append(tmp_df, yok say_index=Doğru)
KeyError hariç:
ortalama_ctr_list.append(0)
# 1. Kutu arsa
box_fig = px.box(modified_df, x='konum etiketi', y='ctr', title=f'{key} konuma dayalı dizin TO dağılımı',
point='tümü', color='konum etiketi', etiketler={'konum etiketi': 'Konum', 'ctr': 'TO'})
# Tüm on x ekseni kenelerini gösterme
box_fig.update_xaxes(tickvals=[aralıktaki i için i(1, 11)])
# y ekseni onay biçimini yüzde olarak değiştirme
box_fig.update_yaxes(tickformat=".0%")
# Çizimi 'çıktı çizimi görüntüleri' dizinine kaydetme
box_fig.write_image(f'./çıktı çizim görüntüleri/{anahtar} dizin-Kutu çizim TO eğrisi.png')
# 2. Çubuk arsa
bar_fig = px.bar(x=[aralıktaki konum için konum (1, 11)], y=mean_ctr_list, title=f'{key} dizin konuma dayalı ortalama TO dağılımı',
etiketler={'x': 'Konum', 'y': 'TO'}, text_auto=Doğru)
# Tüm on x ekseni kenelerini gösterme
bar_fig.update_xaxes(tickvals=[i için aralıktaki i(1, 11)])
# y ekseni onay biçimini yüzde olarak değiştirme
bar_fig.update_yaxes(tickformat='.0%')
# Çizimi 'çıktı çizimi görüntüleri' dizinine kaydetme
bar_fig.write_image(f'./çıktı çizim görüntüleri/{anahtar} dizin-Çubuk çizim TO eğrisi.png')
Yukarıdaki işlevi tanımladıktan sonra, CTR eğrisini almak istediğimiz dizin verileri üzerinde döngü oluşturmak için bir 'for' döngüsüne ihtiyacımız var.
# Dizinler üzerinde dolaşmak ve 'each_dir_plot' işlevini yürütmek
anahtar için, lands_grouped_df içindeki öğe:
önemli_dizinlerde anahtar varsa:
her_dir_plot(öğe, anahtar)
Çıktıda, output plot images klasöründeki arsalarımızı alıyoruz.
Gelişmiş ipucu!
Ayrıca sorgular açılış sayfasını kullanarak farklı dizinlerin TO eğrilerini de hesaplayabilirsiniz. İşlevlerdeki birkaç değişiklikle, sorguları açılış sayfaları dizinlerine göre gruplandırabilirsiniz.
API Explorer'da bir API isteği yapmak için aşağıdaki istek gövdesini kullanabilirsiniz (25.000 satır sınırlamasını unutmayın):
{
"başlangıçTarihi": "2022-01-01",
"bitiş Tarihi": "2022-02-01",
"boyutlar": [
"sorgu",
"sayfa"
],
"boyutFilterGroups": [
{
"filtreler": [
{
"boyut": "SORGU",
"ifade": "brand_variation_names",
"operatör": "HARİÇ_REGEX"
}
]
}
],
"satırLimit": 25000
}
Python ile CTR eğrisini hesaplamayı özelleştirmeye yönelik ipuçları
CTR eğrisini hesaplamak için daha doğru veriler elde etmek için üçüncü taraf araçları kullanmamız gerekiyor.
Örneğin, hangi sorguların öne çıkan bir snippet'e sahip olduğunu bilmenin yanı sıra, daha fazla SERP özelliğini keşfedebilirsiniz. Ayrıca, üçüncü taraf araçları kullanıyorsanız, SERP özelliklerine dayalı olarak o sorgu için açılış sayfası sıralamasına sahip sorgu çiftini alabilirsiniz.
Ardından, açılış sayfalarını kök (ana) dizini ile etiketleme, sorguları dizin değerlerine göre gruplandırma, SERP özelliklerini dikkate alma ve son olarak sorguları konuma göre gruplandırma. TO verileri için, GSC'den alınan TO değerlerini eş sorgularıyla birleştirebilirsiniz.